
- 1SPI通讯简介_spi通信菊花链
- 2R:file name conversion problem ——name too long?_but no jags installation can be found there
- 3PNET模拟器导入锐捷镜像_pnet 锐捷镜像
- 4vscode环境中配置git_vscode配置git
- 5windows下bat脚本学习与应用_win bat脚本
- 6TC275旋变软解码仿真_tc275怎么产生高频激励
- 7【Linux开发】Linux V4L2驱动架构解析与开发导引_v4l2系统框架
- 8mysql数据库导出数据乱码问题,MySQL导入导出数据的中文乱码问题
- 9Android studio开发Flutter常用插件_android studio flutter插件
- 10【QT教程】QT6QFuture与并发
[保姆级教程]从0开始本地大模型搭建私用知识库(第一部分:安装)_fastgpt ollama
赞
踩
说明:本次部署涉及如下内容的安装部署(均为开源)本次部署所在环境均为window。网上很多文章均未完整介绍安装过程。所以自己写了一份
| FastGpt | 私用知识库 |
| Ollama | 获取LLM大模型 |
| Mysql | 存储One-API渠道数据(用自带的数据库可能会出现访问失败的问题) |
| One-API | 知识库与大模型直接的渠道 |
| LLM大模型 | 总结知识库内容反馈结果(本次使用的模型为qwen:0.5b) |
| 向量模型 | 向知识库导入数据时需要该模型进行解析(本次使用模型m3e) |
一、fastGpt搭建
1、window主机上部署docker
- docker下载地址:
- https://docs.docker.com/desktop/install/windows-install/
①下载完成后,双击开始安装,一直下一步即可。
②安装完成后,在window命令行中输入docker,如果有返回证明安装完成。

2、开始通过docker安装fastGpt
-
- ①在本地磁盘中新建一个目录,名字可以随便取,用于放置docker配置文件
-
- ②在目录下新建两个文件docker-compose.yml 、config.json
-
- 文件内容复制官方文档:
-
- https://raw.githubusercontent.com/labring/FastGPT/main/files/deploy/fastgpt/docker-compose.yml
- https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
-
- ③启动docker容器,在 docker-compose.yml 同级目录下执行
- docker-compose pull #拉取镜像
- docker-compose up -d #加载镜像
- ④初始化 Mongo 副本集
- # 查看 mongo 容器是否正常运行
- docker ps
- # 进入容器
- docker exec -it mongo bash
- # 连接数据库(这里要填Mongo的用户名和密码,不要改)
- mongo -u myusername -p mypassword --authenticationDatabase admin
- # 初始化副本集
- rs.initiate({
- _id: "rs0",
- members: [
- { _id: 0, host: "mongo:27017" }
- ]
- });
- #如果需要外网访问,mongo:27017 可以改成 ip:27017。但是需要同时修改 FastGPT 连接的参数,可以不用修改该命令
- (MONGODB_URI=mongodb://myname:mypassword@mongo:27017/fastgpt?authSource=admin =>
- MONGODB_URI=mongodb://myname:mypassword@ip:27017/fastgpt?authSource=admin)
- # 检查状态。如果提示 rs0 状态,则代表运行成功
- rs.status()
- ⑤在docker中看到下图中的3个镜像

3、访问fastGpt
可以通过 ip:3000 直接访问(注意防火墙)。登录用户名为 root,密码为docker-compose.yml环境变量里设置的 DEFAULT_ROOT_PSW,默认值1234。(第一次登陆的时候可能会提示用户未注册,再登陆一次即可)登录后的样子如下图:

二、安装One-API
1、安装MySQL
因为One-API自身的bug,如果使用自带的数据库那么会出现“无可用渠道”的问题,因此需要单独部署MySQL存储One-API数据
- 使用docker部署MySQL执行如下命令:
- docker run -d -p 3306:3306 --privileged=true --net="fastgpt_fastgpt" --link fastgpt:fastgpt_fastgpt --ip 192.168.1.10 -e MYSQL_ROOT_PASSWORD=pwd@2023 --restart always --name mysql mysql:5.7 --character-set-server=utf8mb4 --collation-server=utf8mb4_general_ci
-
- 参数说明:
- -p 3306:3306 #将本机的3306端口映射为容器内3306端口
- --net="fastgpt_fastgpt" #使用fastgpt的网段
- --link fastgpt:fastgpt_fastgpt #因为docker安装的各个容器网络是不通的,所以在创建的时候把它们划分为统一网络
- -e 参数后面的所有内容均为MySQL数据库的创建配置
命令执行后可以在docker中看到MySQL容器

2、安装One-API
- 执行下面命令安装One-api,MySQL部分根据你上一步的安装信息填写
- docker run --name one-api -d --restart always -p 4000:3000 --net="fastgpt_fastgpt" --link fastgpt:fastgpt_fastgpt -e SQL_DSN="MySQL用户名:MySQL密码@tcp(mysql的IP:3306)/oneapi" -e TZ=Asia/Shanghai justsong/one-api
命令执行后可以在docker中看到One-API容器
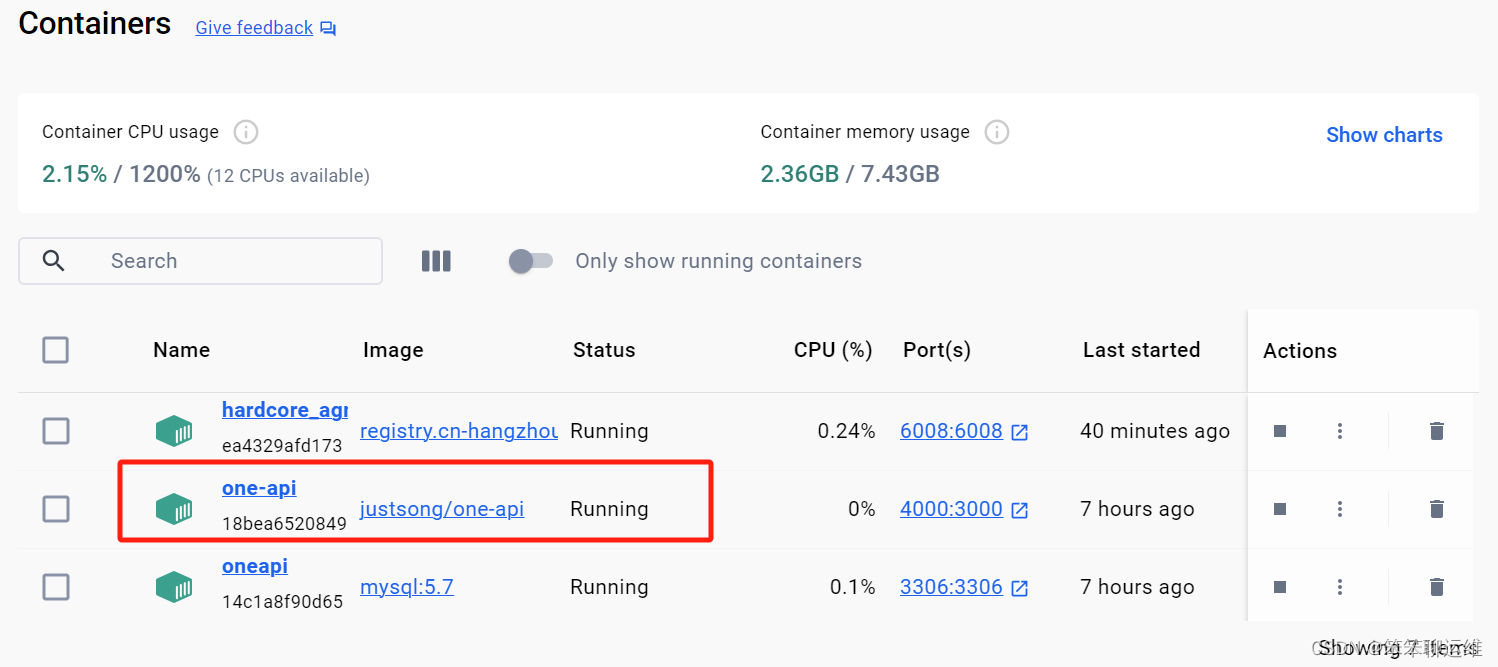
3、登陆One-API
访问地址http://你的ip:4000
默认用户名root,默认密码123456。第一次登陆会让你重新修改密码。能登陆进来就可以了,配置在下文。
三、安装Ollama运行大模型
ollama下载地址:https://ollama.com/
下载完成后直接点击Install即可

安装完成后打开电脑的cmd,输入如下命令
- ollama pull 你要使用的模型
- ollama run 你的模型
- 例如我安装qwen,则命令如下
- ①ollama pull qwen:4b #拉取模型
- ②ollama run qwen:4b #运行模型
-
- #ollama中支持多种模型,可以在官网查看
命令执行界面

pull命令结束后执行ollama run命令就可以和大模型对话了

四、配置One-API联通大模型和FastGpt
1、配置令牌
打开One-API选择“令牌”,添加新的令牌,只需要填写名称即可

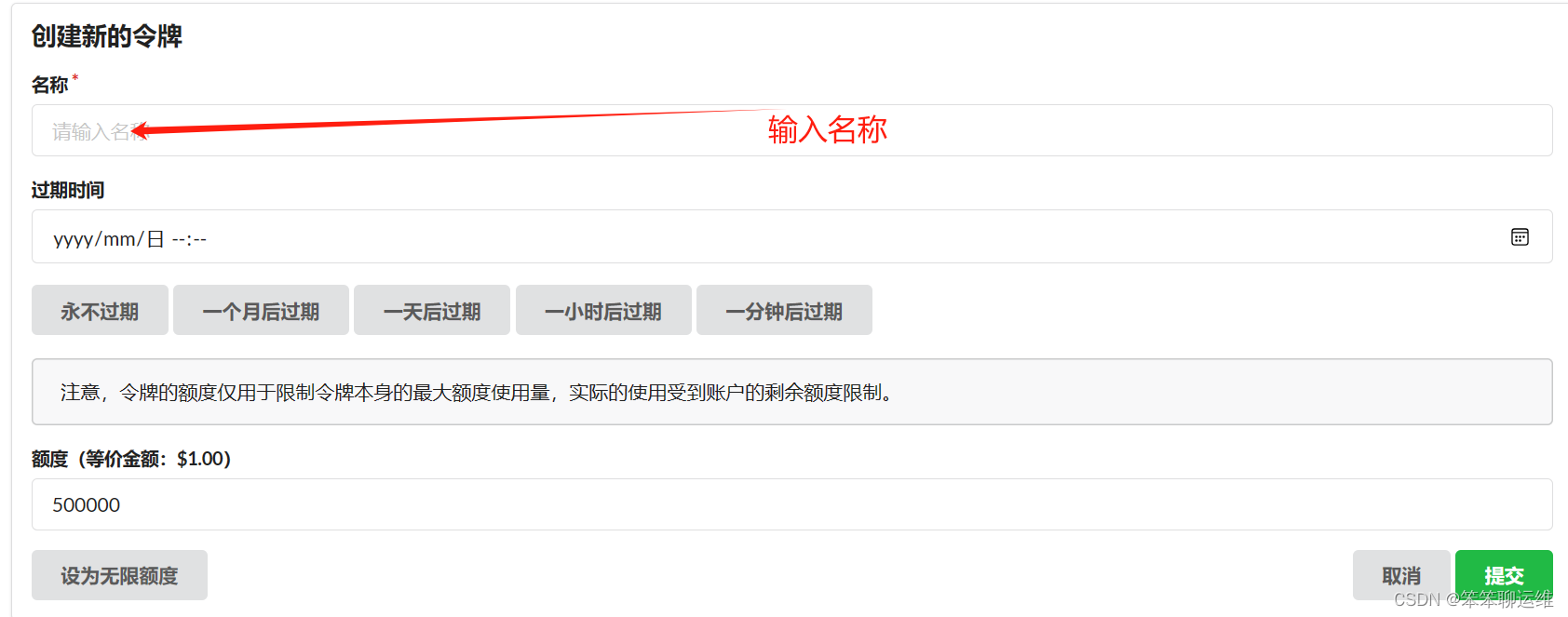
提交后,点击复制按钮
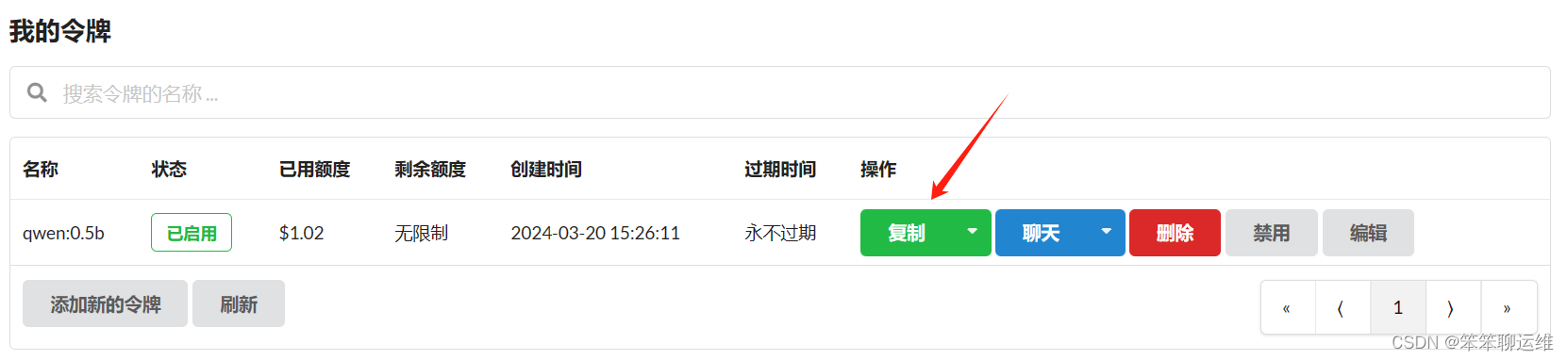
打开fastgpt配置文件docker-compose.yml
- 在配置文件中找到- CHAT_API_KEY=
- 将刚才复制的内容粘贴在后面,样子如下:
- - CHAT_API_KEY=sk-xqcUuxqOmWubVtgfC1B7B29cFa974dE2A895F1E083670d9b
- 通过cmd进入fastgpt安装路径,执行docker-compose up -d 命令重新加载。
2、配置渠道
打开One-API选择“渠道”,添加新的渠道。这一步的作用是让One-API与大模型连接。

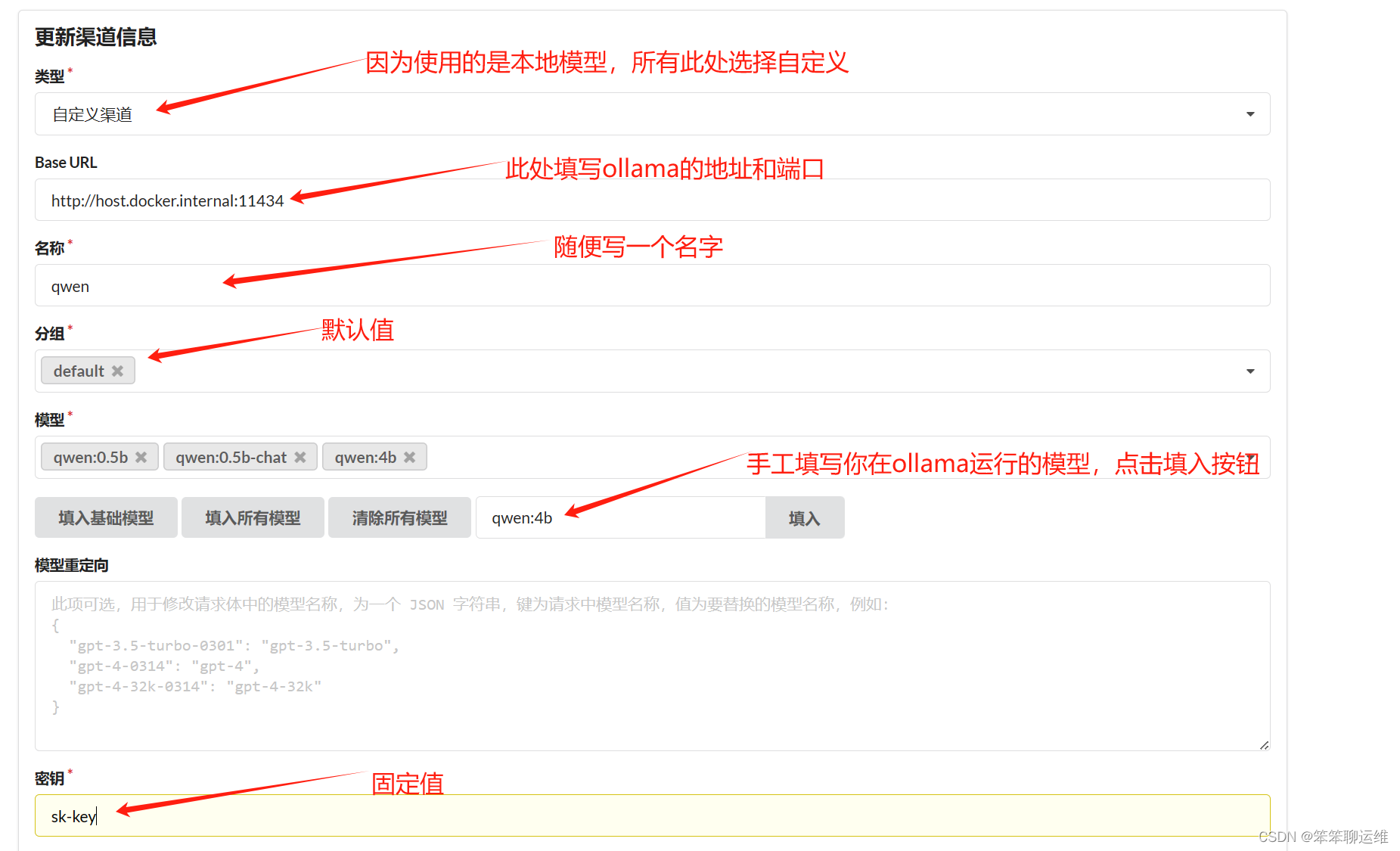
3、修改fastGpt配置文件
- 打开config.json文件
- 将里面的默认模型改为你目前使用的模型
-
- {
- "model": "qwen:4b", #改为自己部署的模型,就是one-api中你填写的模型
- "name": "qwen:4b", #这个地方是展示在fastgpt界面中的模型名称,按需填写即可
- "maxContext": 16000,
- "maxResponse": 16000,
- "quoteMaxToken": 13000,
- "maxTemperature": 1.2,
- "charsPointsPrice": 0,
- "censor": false,
- "vision": false,
- "datasetProcess": true,
- "usedInClassify": true,
- "usedInExtractFields": true,
- "usedInToolCall": true,
- "usedInQueryExtension": true,
- "toolChoice": true,
- "functionCall": false,
- "customCQPrompt": "",
- "customExtractPrompt": "",
- "defaultSystemChatPrompt": "",
- "defaultConfig": {}
- },
-
- 配置修改后,进入fastgpt安装目录,执行
- docker-compose up -d 重新加载
五、部署向量大模型
1、安装m3e向量模型
为什么需要向量模型?
在AI知识库应用(RAG技术)中,它用于解决知识时效、超长文本等各种大模型本身制约或不足的必要技术。
目前市面主流的向量模型有openai的text-embedding-ada、国产的m3e、bge。其中m3e和bge均有开源版本可以本地部署。
- 因为ollama中只包含LLM(大语言模型),所以向量模型本次使用docker方式安装
- 执行如下命令即可获取m3e向量模型
- docker run -d -p 6008:6008 --net="fastgpt_fastgpt" --link fastgpt:fastgpt_fastgpt registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api:latest
-
- # m3e共有3个版本,本次使用的是最高版本也就是数据集最大的版本,此外还有m3e-small;m3e-base
部署完成后在docker管理界面中可以看到,如下图
2、配置One-api渠道
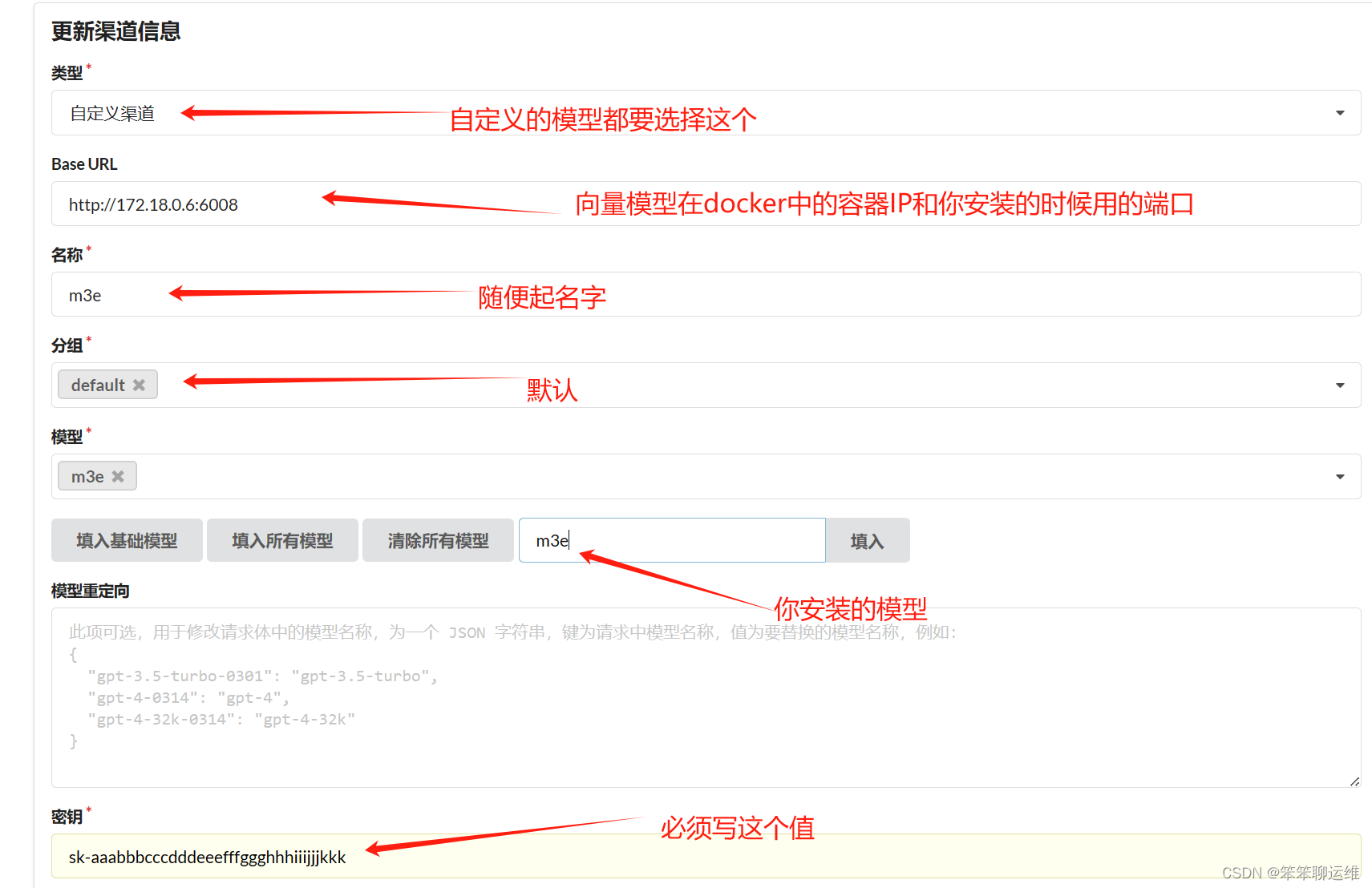
3、修改fastgpt配置文件
- 在config.json中找到vectorModels,替换里面的内容
-
- "vectorModels": [
- {
- "model": "m3e", #你在one-api中写的模型名称
- "name": "m3e", #展示在fastgpt界面上的名称
- "charsPointsPrice": 0,
- "defaultToken": 700,
- "maxToken": 3000,
- "weight": 100
- }
-
- 配置修改后,进入fastgpt安装目录,执行
- docker-compose up -d 重新加载
六、进入FastGpt页面,开始使用
1、创建知识库
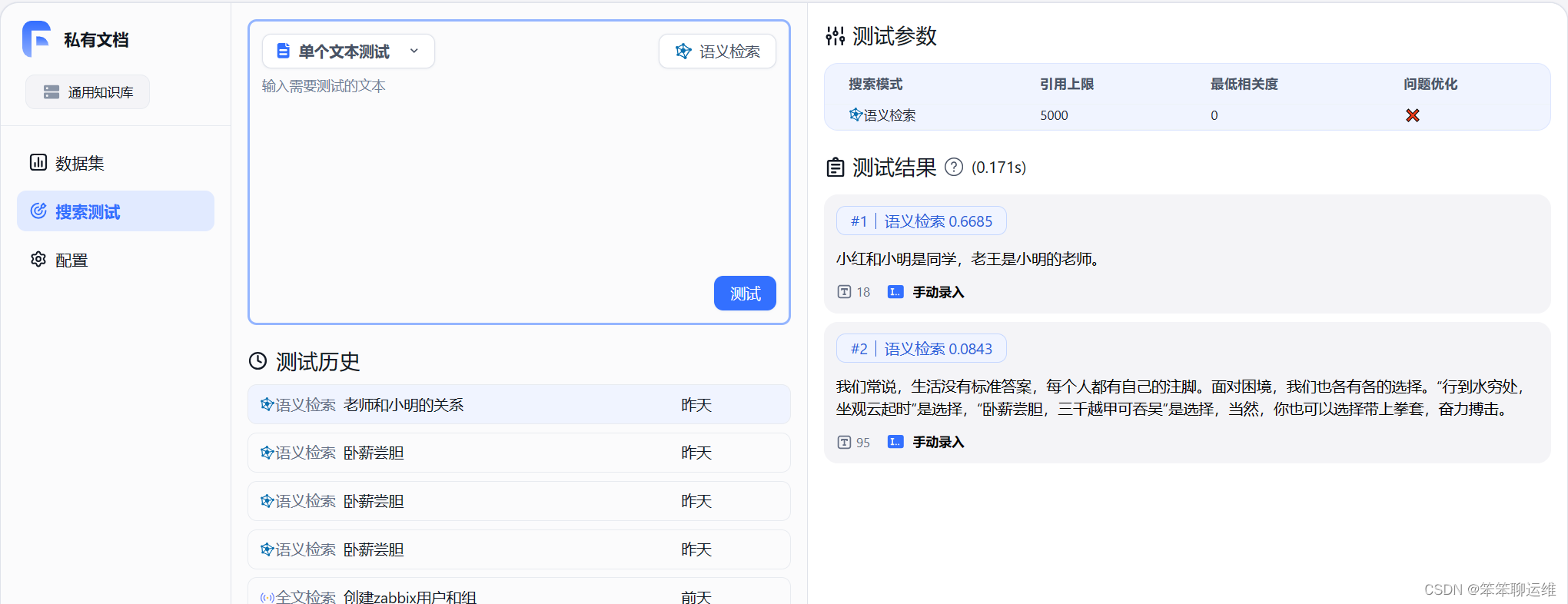
进入fastgpt后需要先配置知识库,新建后在这里手工输入或者导入你自己的文档,这就是本地知识库的入口,通过它将数据喂给向量模型。

导入文档后,可以通过测试界面查看AI的返回结果
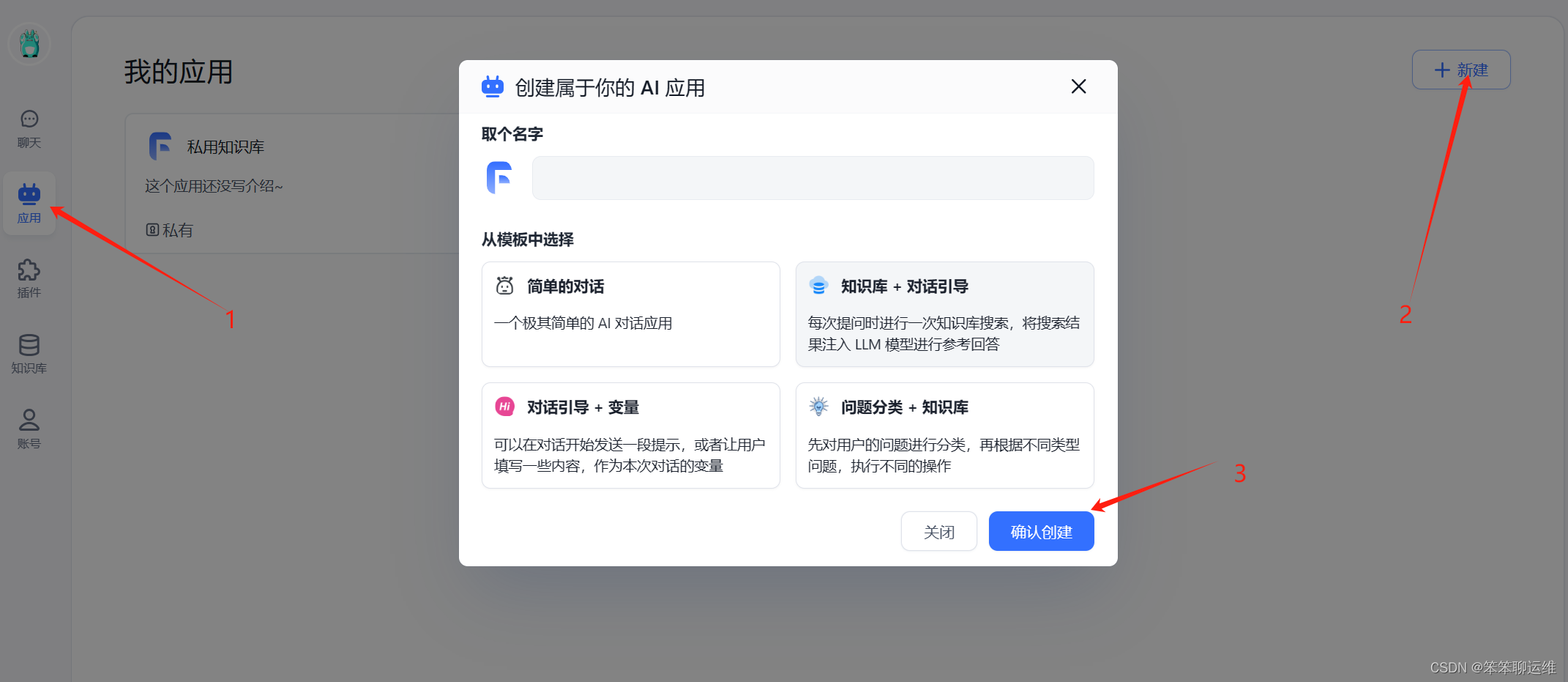
2、创建完知识库后,开始创建应用
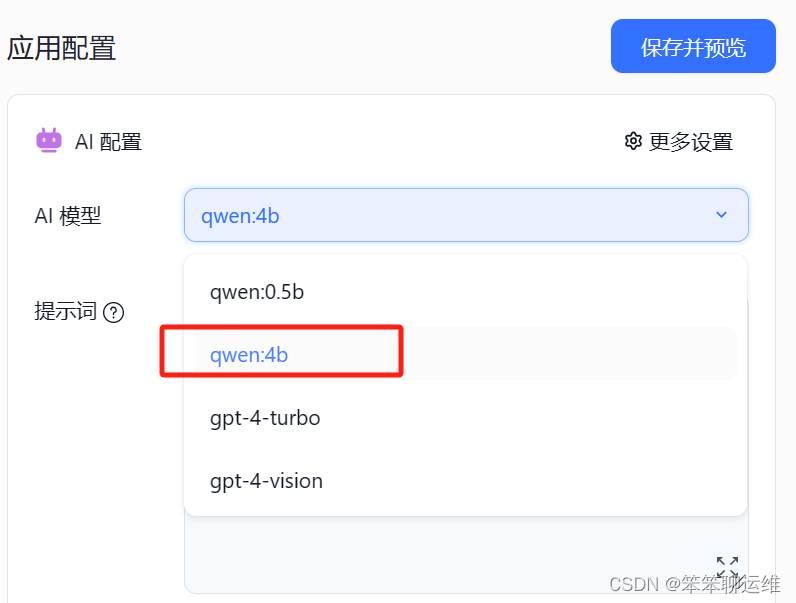
应用创建完成后,需要给应用配上你的本地大模型和刚才创建的知识库,配置好后,在上面有个“保存并预览”按钮,一定要点击哦
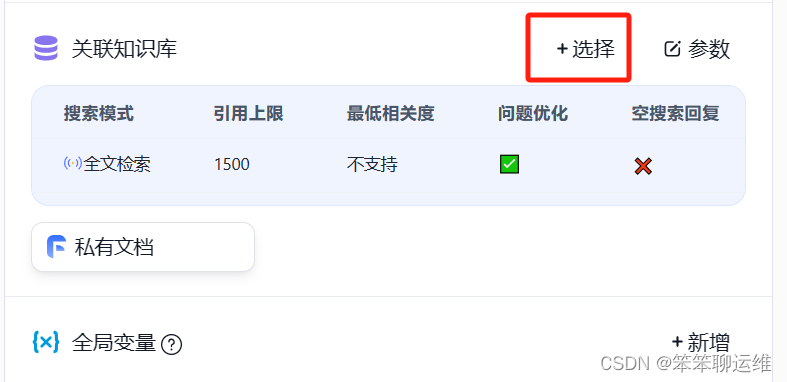
3、使用你的知识库
到这里本地知识库已经搭建完成了

七、重点说明
搭建完成后的知识库,大家在导入本地文档后,发现知识库的回答效果不是很好。这主要是两个原因,。
1、你选择的大模型的数量级,例如7b的大模型效果就要比4b的好很多
2、另外一个很重要的原因,需要对你的输入和输出进行编排,让模型更懂你的诉求。
下一篇文件将重点讲述如何使用fastgpt进行编排,请期待哦!!!

