- 1Redis 16 个常见使用场景_redis使用场景
- 2R-Space x Mimic Shhans|黑猫伴喜,喵呜来袭!
- 3安装py2neo_Neo4j 操作与 py2neo 用法
- 4【C语言】指针篇-一篇搞定不同类型指针变量-必读指南(3/5)
- 5使用 hutool 工具包发送 HTTP 请求_hutool http
- 6SpringBoot笔记:SpringBoot集成MyBatisPlus、Sqlite实战_mybatisplus sqlite
- 7虚拟机怎么配置yum_虚拟机安装yum
- 816个 Redis 常见使用场景_redis的使用场景
- 9Flink 最佳实践之使用 Canal 同步 MySQL 数据至 TiDB_flink job mysql同步开发打包
- 10c#&Excel:2.写入Excel表 3.读取Excel表
Zookeeper伪分布式安装,zookeeper特点,命令,节点信息,节点类型,完全分布式安装,选举机制,ZAB协议
赞
踩
目录
一、概述
1.Zookeeper是Yahoo(雅虎)开发后来贡献给了Apache的一套用于分布式管理和协调的框架
2.Zookeeper本身仿照Google的《The Chubby Lock》设计实现的
3.Zookeeper提供了中心化的服务: 包括: 统一的配置,统一的命名,提供分布式锁,以及提供组服务
二、安装
1.单机模式:在一台机器上安装框架,往往只能启动框架的部分功能
2.伪分布式:也是在一台机器上安装框架,利用了多线程来模拟集群环境,能够启动框架的大部分功能,甚至全部功能
3.完全分布式:在集群(多台服务器)进行安装架,能够启动框架的全部功能
三、伪分布式安装
1.关闭的防火墙
2.临时关闭防火墙: systemctl stop firewalld
3.永久关闭防火墙: systemctl disable firewalld
4.下载安装JDK
a. wget http://bi-yzid.ufile.cn-north.02.ucloud.cn/jdk-8u181-linux-x64.tar.gz
5.修改jdk的环境变量
6.下载或者上传Zookeeper的安装包
a. wget http://bj-yzjd.ufile.cn-north-02.ucloud.cn/apache-zookeeper-3.5.7-bin.tar.gz
7.解压Zookeeper的安装包: tar -xvf zookeeper-3.5.78.进入Zookeeper的安装目录下的子目录conf目录中: cd zookeeper-3.5.7/conf
9.将con目录下的zoo sample.cfg文件复制为z0o.cfg。Zookeeper在启动的时候会自动寻找zoo.cfg,根据其中的配置来启动服务: cp zoo sample.cfg zoo.cfg
10.编辑zoo.cfg文件: vim zoo.cfg
11.修改其中的属性dataDir,指定数据的存储目录: dataDir=/home/software/zookeeper-3.5.7/tmp
12.保存并且关闭zoo.cfg
13.进入Zookeeper的安装目录下的子目录bin目录中: cd ../bin
14.执行zkServer.sh文件,来启动Zookeeper服务器端: sh zkServer.sh start
15.执行zkCli.sh文件,来启动进入Zookeeper客户端: sh zkCli.sh
四、特点
1.Zookeeper底层是一个树状结构,根节点是/
2.Zookeeper中每一个节点称之为Znode节点,因此这棵树称之为Znode树
3.Zookeeper自带了一个子节点/zookeeper
4.Zookeeper在创建节点的时候可以携带数据也可以不携带(早版本的zookeeper中,创建节点必须携带数据),数据可以是对节点的描述,或者可以是一些配置信息
5.在Zookeeper中不存在相对路径,所有的路径都必须从根节点开始计算
五、命令
| 命令 | 解释 |
| ls / | 查看根节点的子节点 |
| create /video | 创建节点 |
| delete /boot | 删除节点 |
| rmr /video | 递归删除节点 |
| get /aaa | 获取节点数据 |
| set /aaa | 修改节点数据 |
Zookeeper-简介
一、特点
1. Zookeeper底层是一个树状结构,根节点是/
2. Zookeeper中每一个节点称之为Znode节点,因此这棵树称之为Znode树
3. Zookeeper自带了一个子节点/zookeeper
4. Zookeeper在创建节点的时候可以携带数据也可以不携带(早版本的zookeeper中,创建节点必须携带数据),数 据可以是对节点的描述, 或者可以是一些配置信息。
5. 在Zookeeper中不存在相对路径,所有的路径都必须从根节点开始计算
6. Zookeeper会将携带的数据存储在内存以及磁盘中
7. Zookeeper中数据的存储位置由dataDir属性决定,如果不指定默认在/tmp
8. 在Zookeeper中会将每一个写操作(创建, 修改, 删除) 看成一个事务,并且会给这个事务分配一个全局递增的事 务id,这个编号就是Zxid
9. 其他命令:
1. create -e /video --创建临时节点video
2. create -s /txt --表示创建的是持久顺序节点
3. create -e -s /txt --表示创建一个临时顺序节点
10. 临时节点不能挂载子节点-持久节点可以挂载子节点
11. 在zookeeper中不能存在同名节点
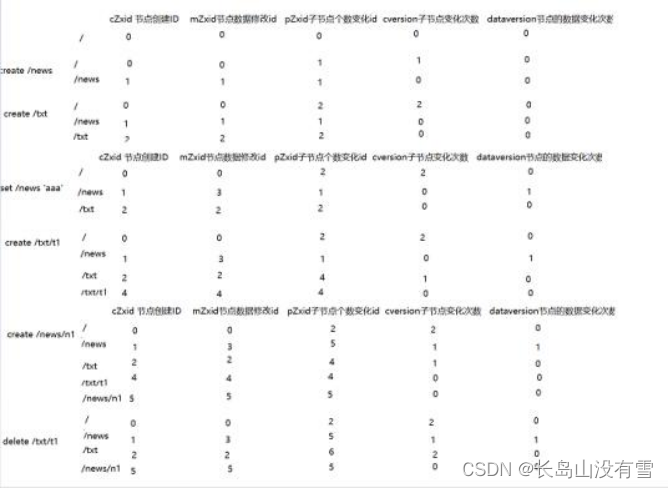
二、节点信息
cZxid = 节点的创建的事务id
ctime = 节点的创建时间
mZxid = 节点的数据修改的事务id
mtime = 节点的数据修改的时间
pZxid = 子节点个数变化的事务id
cversion = 子节点变化的次数
dataVersion = 节点的数据变化次数
aclVersion = 节点的权限策略变化的次数
ephemeralOwner = 如果是持久节点,则此值为0 ,如果是临时节点,则此值为sessionid
dataLength = 数据的子节个数
numChildren = 子节点的个数
三、节点类型
| 持久节点 | 临时节点 | |
| 非顺序节点 | Persistent | Ephemeral |
| 顺序节点 | Persistent_Sequential | Ephemeral_Sequentil |
四、完全分布式安装
关闭防火墙
| 临时关闭: systemctl stop firewalld |
| 永久关闭: systemctl disable firewalld |
安装JDK
上传或者下载Zookeeper安装包,上课阶段统一要求将所有软件安装在/home/software目录下 解压Zookeeper安装包
| tar -xvf apache-zookeeper-3.5.7-bin.tar.gz |
进入Zookeeper安装目录的子目录conf下
| cd apache-zookeeper-3.5.7-bin/conf |
复制文件
| cp zoo_sample.cfg zoo.cfg |
编辑文件
| vim zoo.cfg |
修改属性dataDir,这个属性是用于指定Zookeeper快照文件的存储位置, 如果不指定, 则默认放在/tmp目录下, 例如
| dataDir=/home/software/apache-zookeeper-3.5.7-bin/tmp |
在文件末尾添加server.x=IP/hostname:port1:port2,其中x表示选举编号,要求不重复, port1为原子广播端 口, port2为选举端口,例如:
| server.1=10.9.152.110:2888:3888 server.2=10.9.152.111:2888:3888 server.3=10.9.152.112:2888:3888 |
新建dataDir指定的目录
| cd /home/software/apache-zookeeper-3.5.7-bin/ |
| mkdir tmp |
进入该目录,在该目录下编辑文件myid,在这个文件中填写当前主机给定的编号
| cd tmp |
| vim myid |
| 填写编号,例如第一台主机给定的编号为1 |
将第一台主机的配置远程拷贝给其他另外两台主机, 例如
| cd /home/software |
| scp -r apache-zookeeper-3.5.7-bin/ root@10.10.152.111:$PWD |
| scp -r apache-zookeeper-3.5.7-bin/ root@10.10.152.112:$PWD |
拷贝完成之后,需要修改另外两台主机的myid
| cd /home/software/apache-zookeeper-3.5.7-bin/tmp/ |
| vim myid |
| 修改成对应的编号,例如第二台主机给定编号为2 |
三台主机进入Zookeeper安装目录的子目录bin下, 启动Zookeeper
| cd /home/software/apache-zookeeper-3.5.7-bin/bin/ |
| sh zkServer.sh start |
查看Zookeeper运行状态
| sh zkServer.sh status |
选举机制
一、概述
1. 当一个zookeeper集群刚启动的时候,会自动的进入选举状态, 此时所有的服务器(节点)都会推荐自己成为leader,并 且还会把自己的选举信息发送给其他的节点。
2. 当节点收到其他节点发过来的选举信息之后, 会两两比较。 经过多轮比较,最后胜出的节点当leader。
二、细节
1. 选举信息包含:
a. 当前节点的最大事务id
b. 选举编号,即myid
c. 逻辑时钟值-控制选举的轮数。
2. 比较原则
a. 先比较最大事务id,谁大谁赢
b. 如果事务id一样,则比较myid,谁大谁赢。
c. 如果一个节点胜过了一半及以上的节点,这个节点才能成为leader-过半性
3. 在zookeeper中, 不存在单点故障的说法,如果leader宕机了,那么整个集群会选举一个新的leader继续对外提供服务
4. 如果leader节点宕机之后重新启动,那么这个时候看做一个新的节点加入集群, 所以此时这个节点的状态一定是follower
5. 如果一个集群已经选举出来一个leader,为了维护集群的稳定性, 无论新添加的节点的事务id或者myid是多少, 都不会触 发重新选举,新添的节点只能是follower
6. 如果集群中出现了多个leader,这种现象叫做脑裂。
7. zookeeper中脑裂出现的条件
a. 集群产生分裂
b. 分裂之后产生了选举
8. 在zookeeper中, 如果存活的(可以相互通信的) 节点数量不足一半,则这些节点不选举,同时也不对外提供服务-过半 性。
9. zookeeper会对每一次选举出来的leader分配一个全局递增的编号, 称之为epochid,当zookeeper发现存在多个leader的 时候,那么会自动的将epochid较小的节点的状态切换成follower。利用这种方案可以保证整个集群中只存在唯一的 leader。
10. 集群中节点的状态
a. looking/voting:选举状态
b. follower:追随者/跟随者
c. leader:领导者
d. observer:观察者
11. zookeeper并不是主从的框架,其中leader和follower指的是节点的状态而不是角色
ZAB协议
一、概述
1. ZAB (Zookeeper Atomic Broadcast)协议是专门为zookeeper设计的用于进行原子广播和崩溃恢复的一套协议
2. ZAB是基于2PC算法设计实现的,利用了过半性+PAXOS进行了改进
二、原子广播
1. 作用:保证集群节点之间的数据一致性,即访问任意一个节点,获取到的数据都是相同的。
2. 原子广播就是基于2PC算法设计实现的
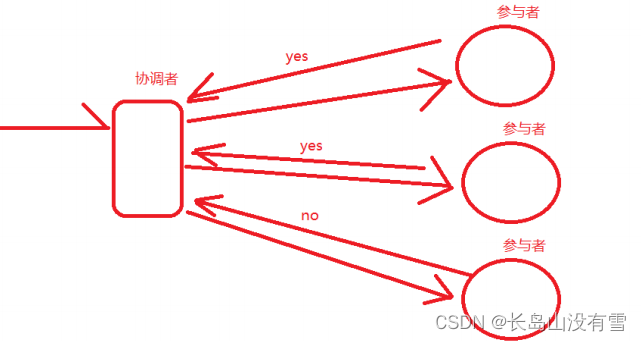
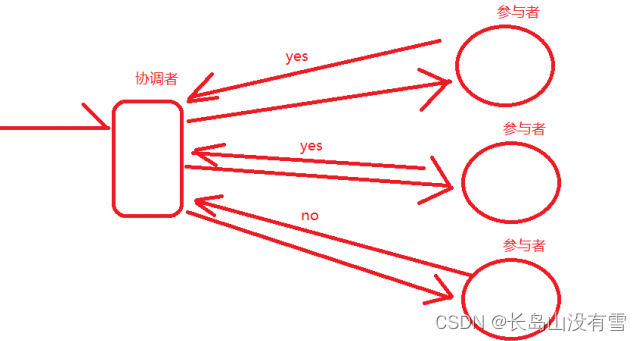
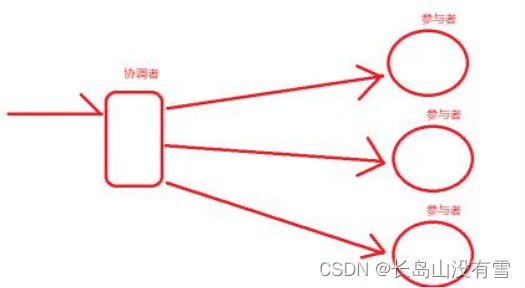
3. 2PC- two Phase Commit-二阶段提交。顾名思义, 将一个请求拆分成了两个阶段
a. 请求阶段
b. 提交阶段:如果协调者收到所有的参与者返回的yes,那么就认为这个请求可以执行,那么就会命令所有的参 与者执行这个请求

c. 中止阶段:只要协调者没有收到所有参与者返回的yes,那么就认为这个请求无法执行, 也就会要求所有的参 与者放弃刚才的请求