
- 1Git常用命令:git stash 暂存,代码草稿本(持续更新中)_git暂存代码
- 2基于STM32的SYN6288语音播报模块驱动实验(代码开源)_syn6288语音模块_基于stm32的语音播报模块
- 3java的tcp实时接收json格式报文_tcp - 如何使用带有rsocket Java的TcpClientTransport将自定义数据格式转换为JSON - 堆栈内存溢出...
- 4SAP常用TCODE_sap tcode 功能对照表
- 5数据治理CDGA证书含金量为什么这么高?_cdga0
- 6hadoop之hdfs与yarn界面功能介绍_hdfs原生界面overview
- 7openGauss数据库源码解析系列文章——AI技术(2.1)_opengauss源码分析
- 8ChatGPT流式输出实现原理
- 9安卓Clean Architecture:实现模块化与可测试性的软件设计方法
- 10【Python+百度API】 文本情感倾向分析_百度情感分析api
刘焕勇QABasedOnMedicaKnowledgeGraph项目全过程
赞
踩
原项目地址:新建标签页 (github.com)
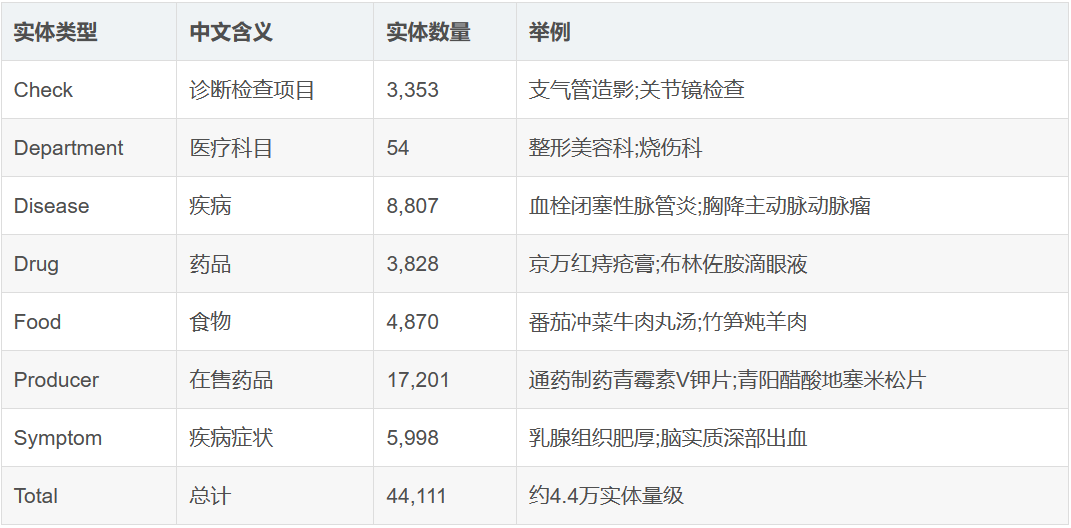
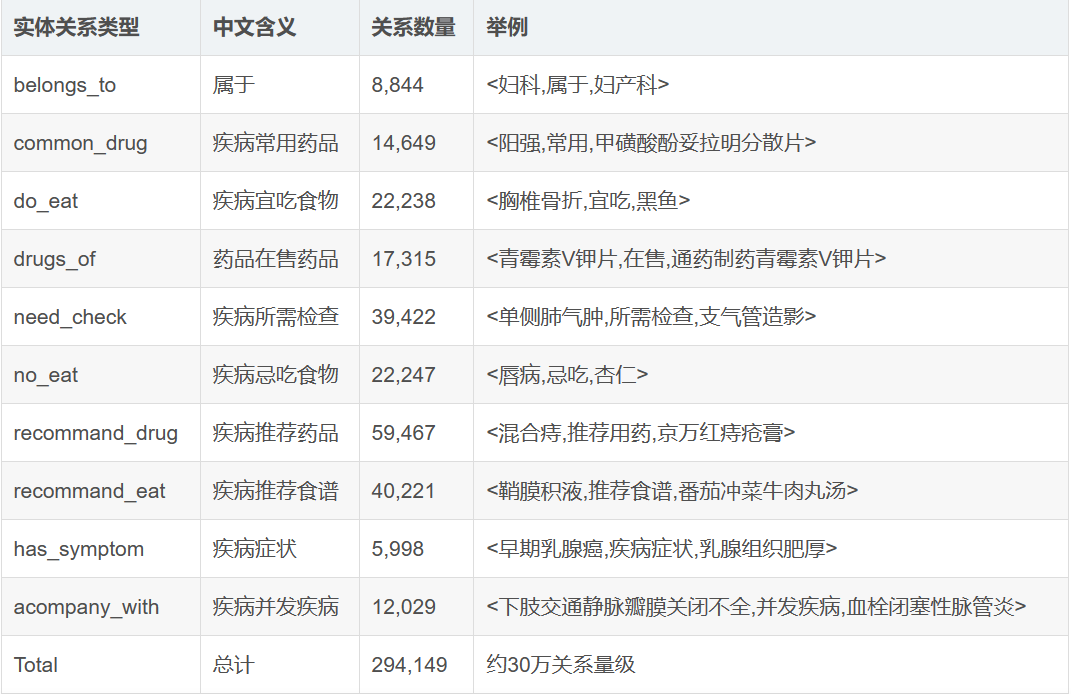
实体规模4.4万,实体关系规模30万。
一、首先安装
MongoDB-Windows-x86_64
mongodb-compass-1.36.1-win32-x64(安装的时候注意安装路径最好不要出现中文,不然会很麻烦)
neo4j-community-4.2.4-windows(这里我是去找了4开头的历史版本)
jdk-11.0.18_windows-x64_bin
开始项目时MongoDB、neo4j全程打开
连接MongoDB
(1)打开cmd,进入E:\mongodb\bin目录下,输入命令“mongod --dbpath E:\mongodb\data”即可开启MongoDB服务。
(2)浏览器进入http://127.0.0.1:27017,显示“It looks like you are trying to access MongoDB over HTTP on the native driver port.”则表示连接成功。
连接neo4j
(1)进入E:\知识图谱\neo4j\neo4j-community-4.2.4\bin,输入neo4j.bat console。
(2)浏览器进入http://localhost:7474/browser/。
二、数据处理部分
1.data_spider.py 爬取数据(数据的原网站是寻医问药网的疾病百科)

2.max_cut.py 基于词典的最大前向/后向匹配。
3.build_data.py 将爬虫爬取的数据进行规整
三、构建知识图谱
运行build_medicalgraph.py 将结构化JSON数据导入neo4j
在PyCharm终端安装py2neo:pip install py2neo==4.3.0 -i https://pypi.douban.com/simple
(1)知识图谱实体类型
(2)知识图谱实体关系类型
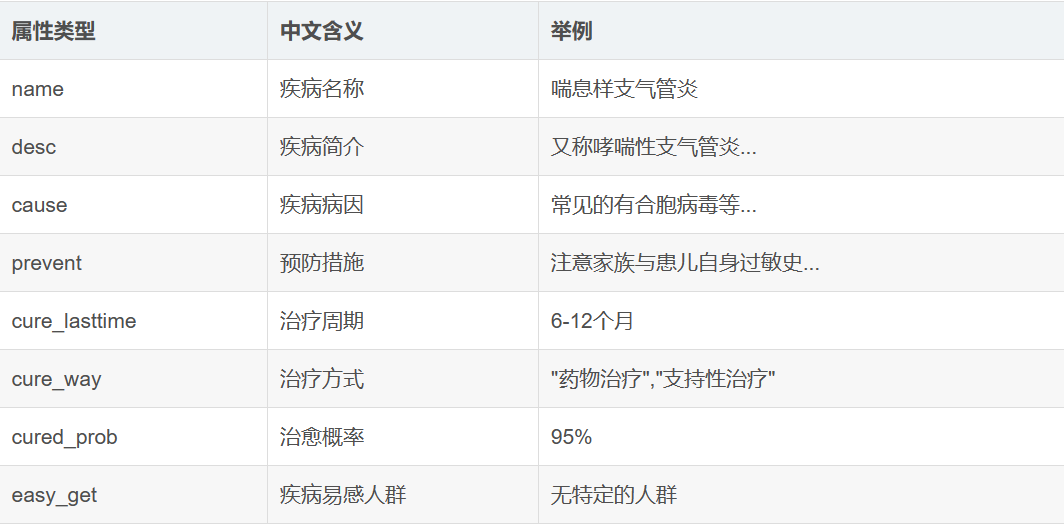
(3)知识图谱属性类型
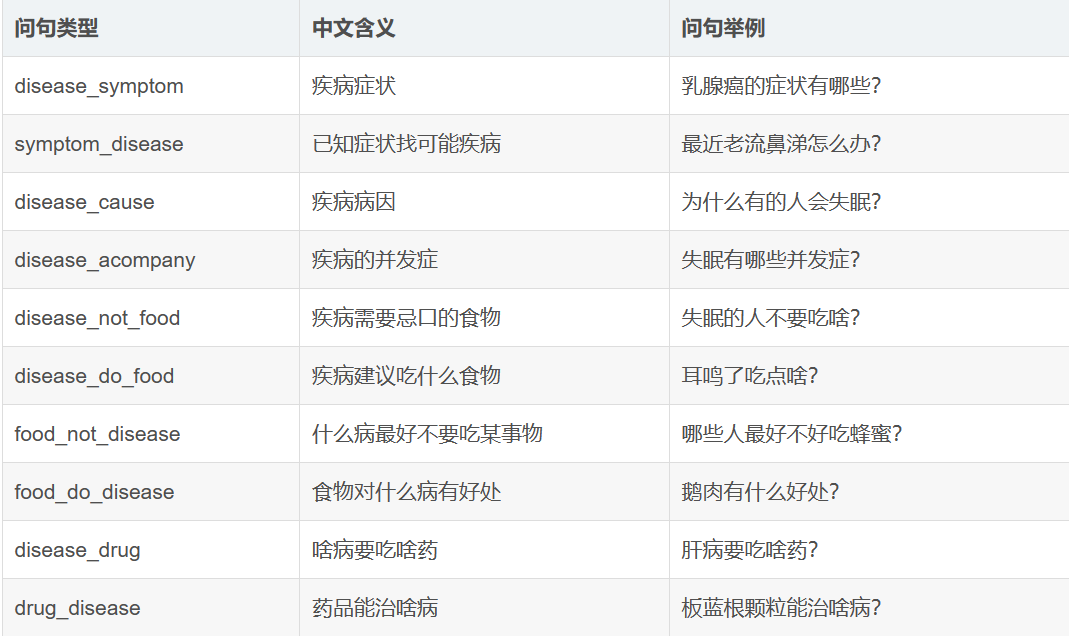
(4)支持问答的类型
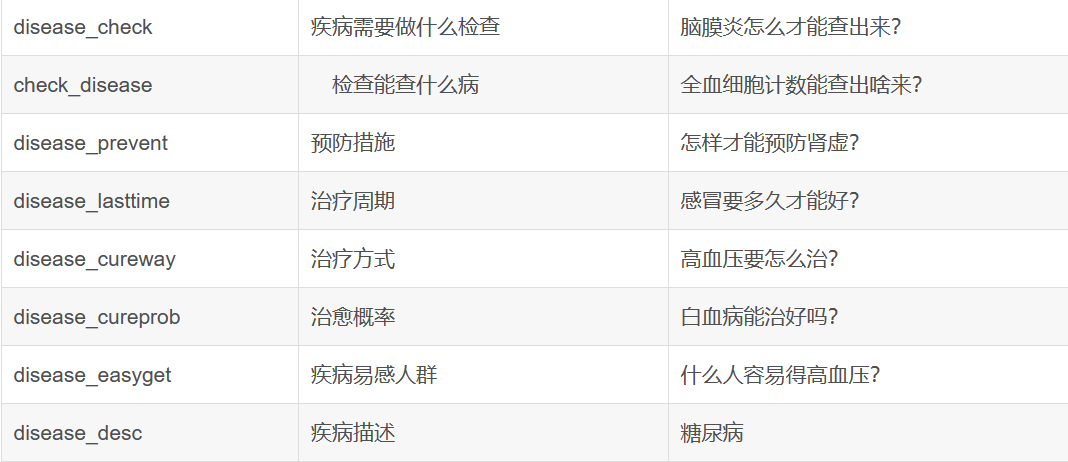
四、问答部分
question_classifier.py
2.question_parser.py
3.answer_search.py
4.chatbot_graph.py
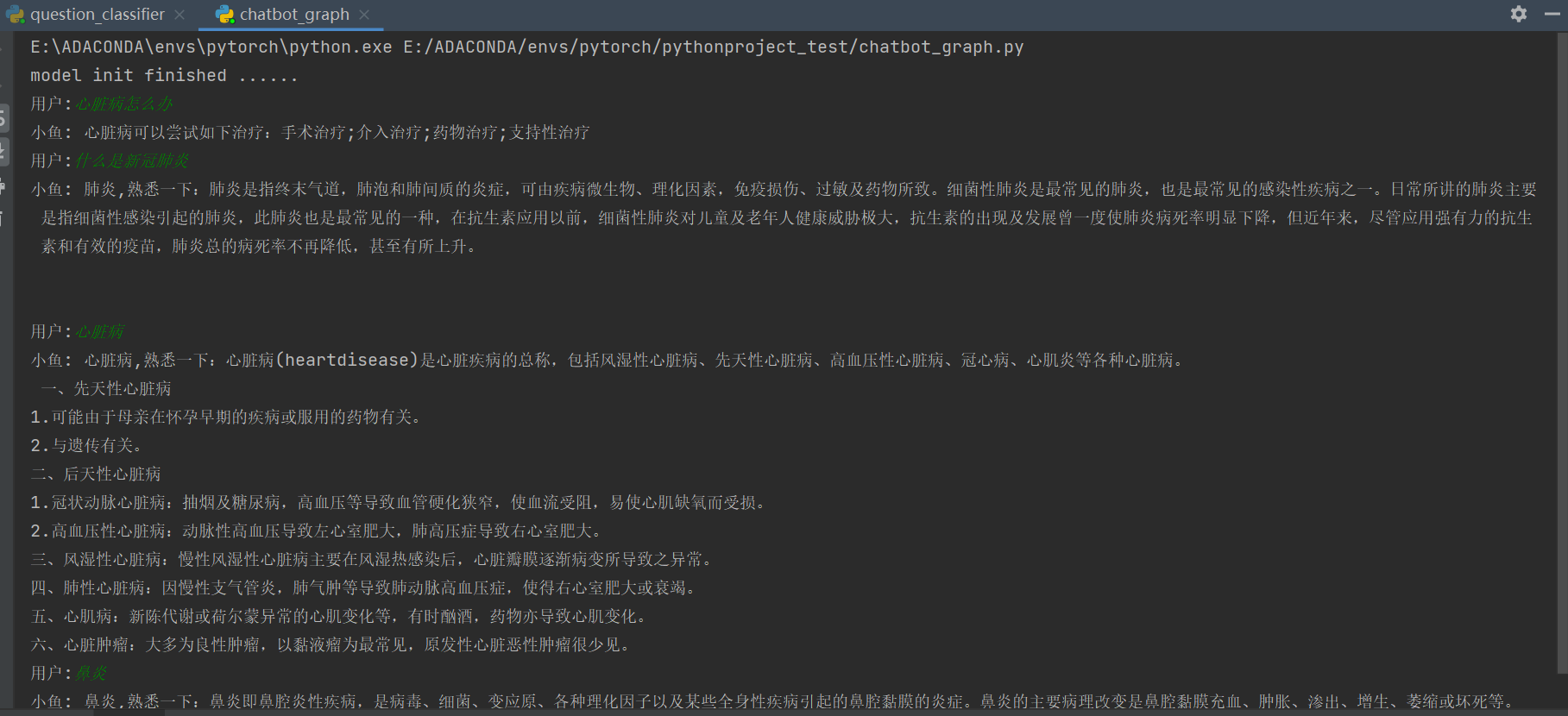
实现结果:
五、参考博客
(60条消息) 知识图谱的节点和关系实现(python)_python 知识图谱_chen_nnn的博客-CSDN博客
(60条消息) 菜哥学知识图谱(通过“基于医疗知识图谱的问答系统”)(四)(代码分析2)_weixin_40539807的博客-CSDN博客
(60条消息) 基于医疗知识图谱的问答系统源码详解_vivian_ll的博客-CSDN博客
本项目还有不足:关于疾病的起因、预防等,实际返回的是一大段文字,这里其实可以引入事件抽取的概念,进一步将原因结构化表示出来。这个可以后面进行尝试。

