- 1CTF怎么快速入门?_ctf网络安全大赛怎么学
- 2susan算子matlab代码,计算机视觉:matlab实现9种边缘检测算子
- 3leetcode(力扣) 55. 跳跃游戏 (贪心 & 动态规划)_力扣跳跃游戏
- 43000字分享,分析报告这么写,领导爱看,业务没话说
- 5【渝粤题库】陕西师范大学200431综合英语(一)作业(高起专、高起本)_no matter how hard i tried,the,painting
- 6Flutter笔记:DefaultTextStyle和DefaultTextHeightBehavior解读
- 7mac机器时间修复_mac ntp 重置
- 8「React Native」为什么要选择 React Native 作为的跨端方案
- 9在微信小程序使用外部字体_微信小程序引用外部字体
- 10Python学习系列之字典_爬虫获取到的数据类型是str,但看上去像字典格式
[PPT] 李宏毅chatgpt,生成式ai_李宏毅 生成式ai
赞
踩
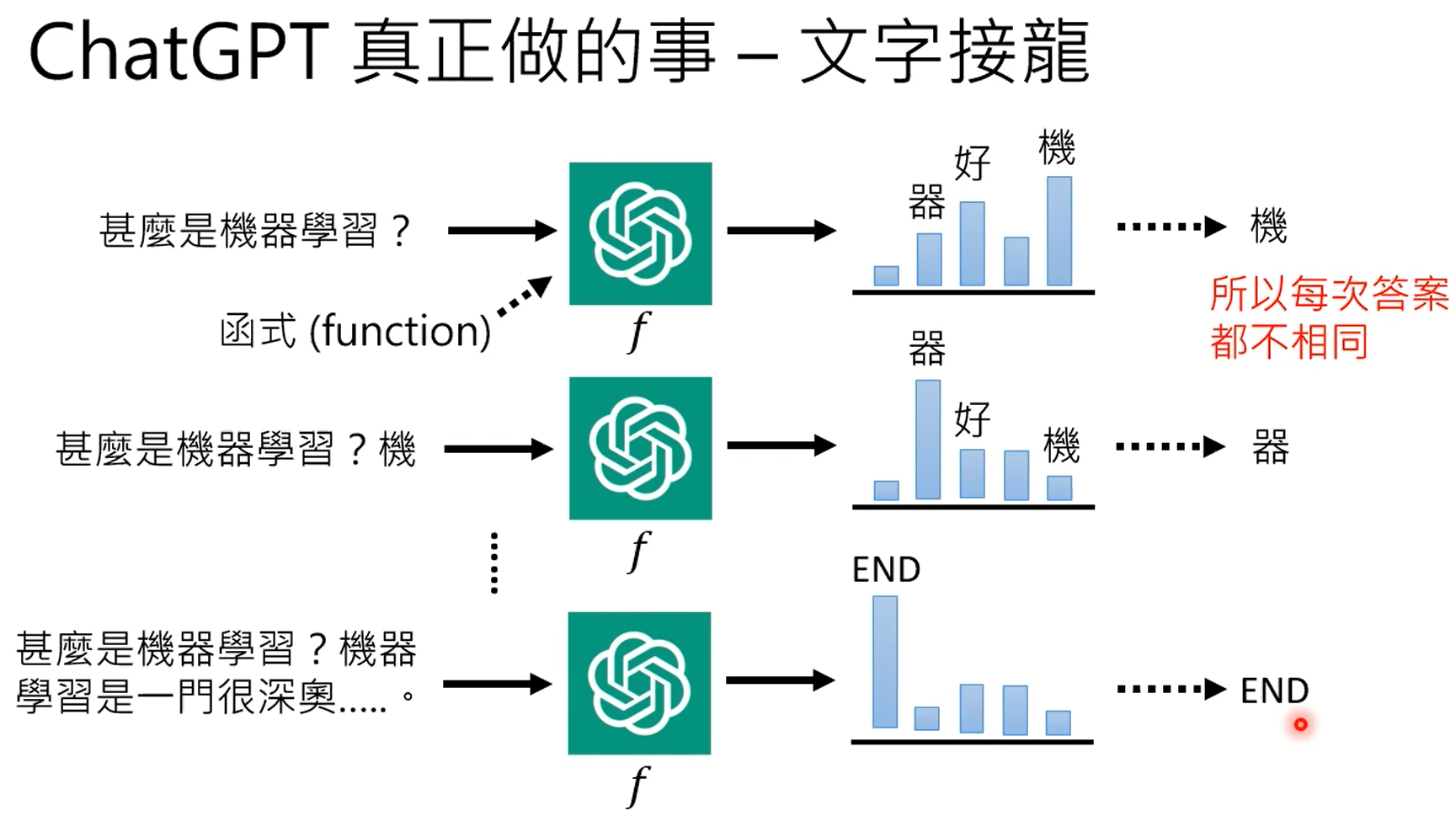


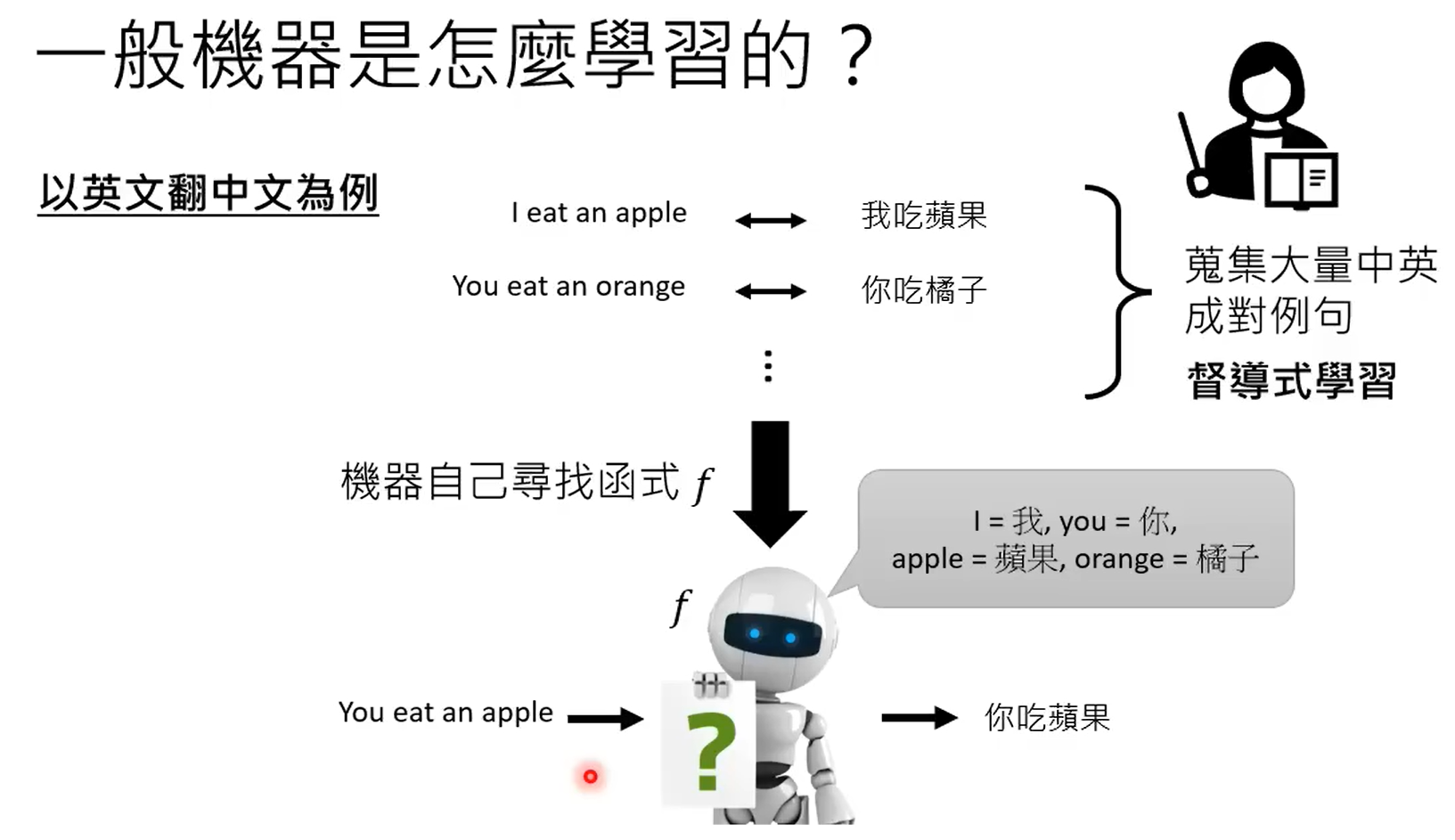
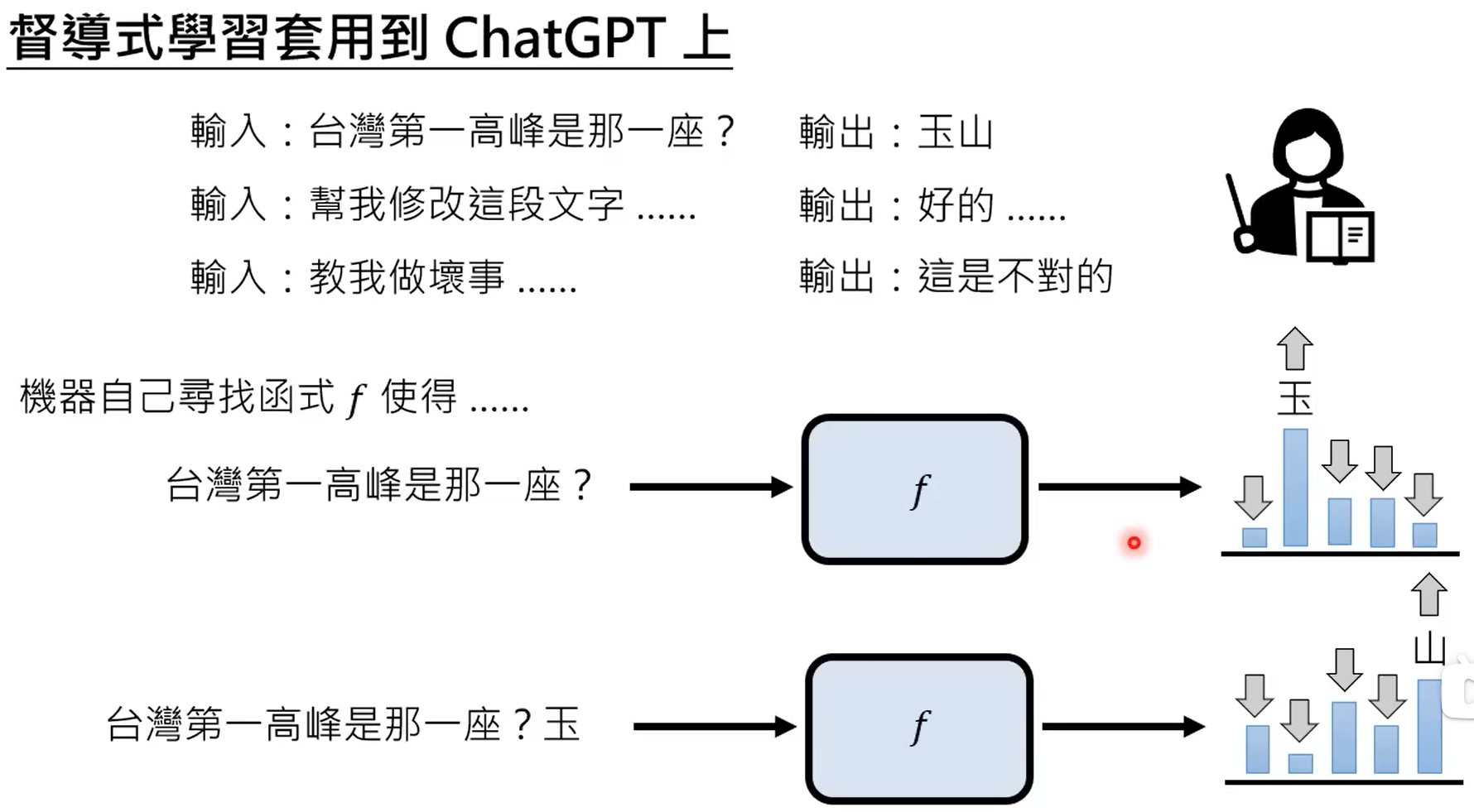
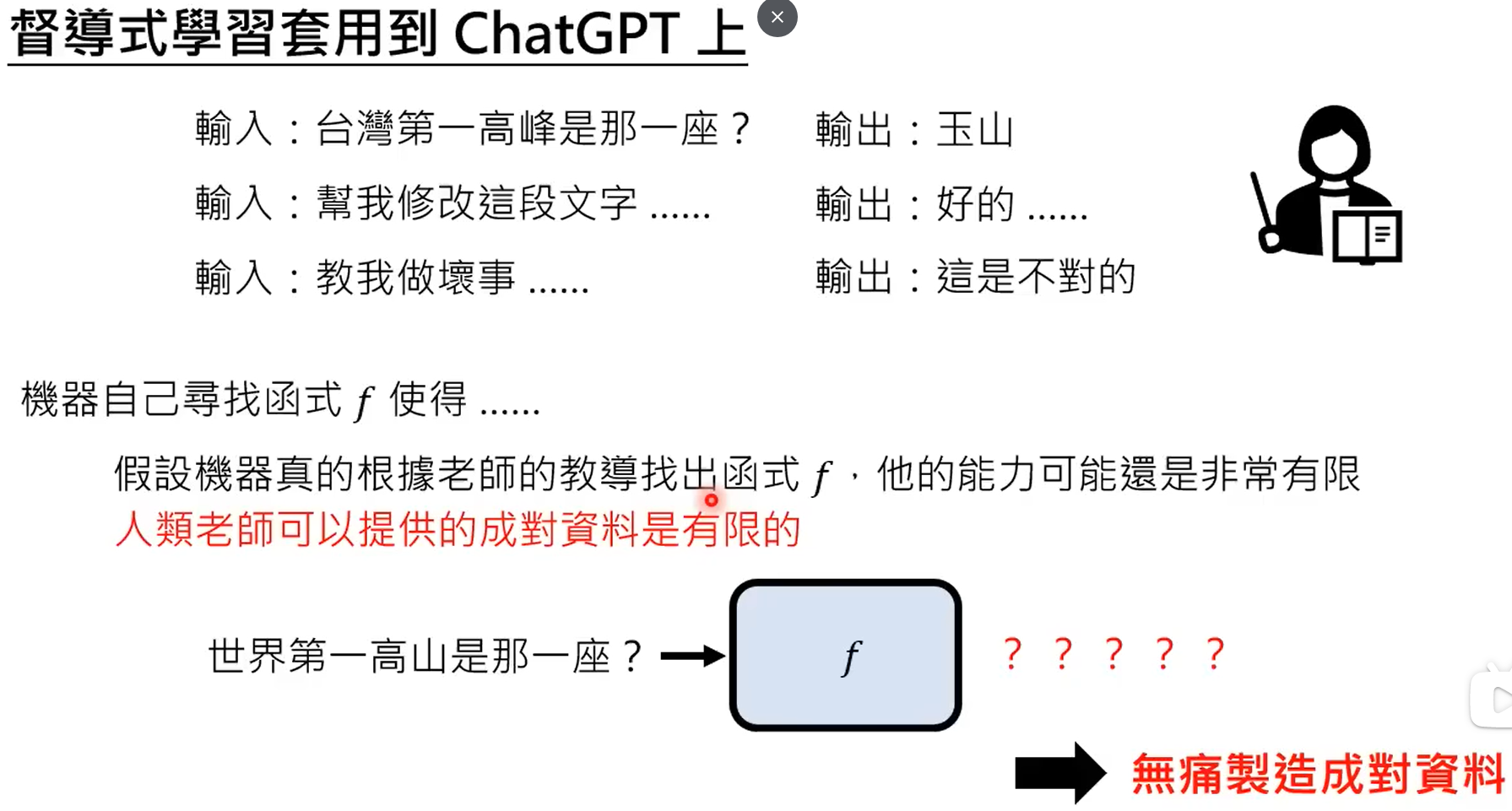

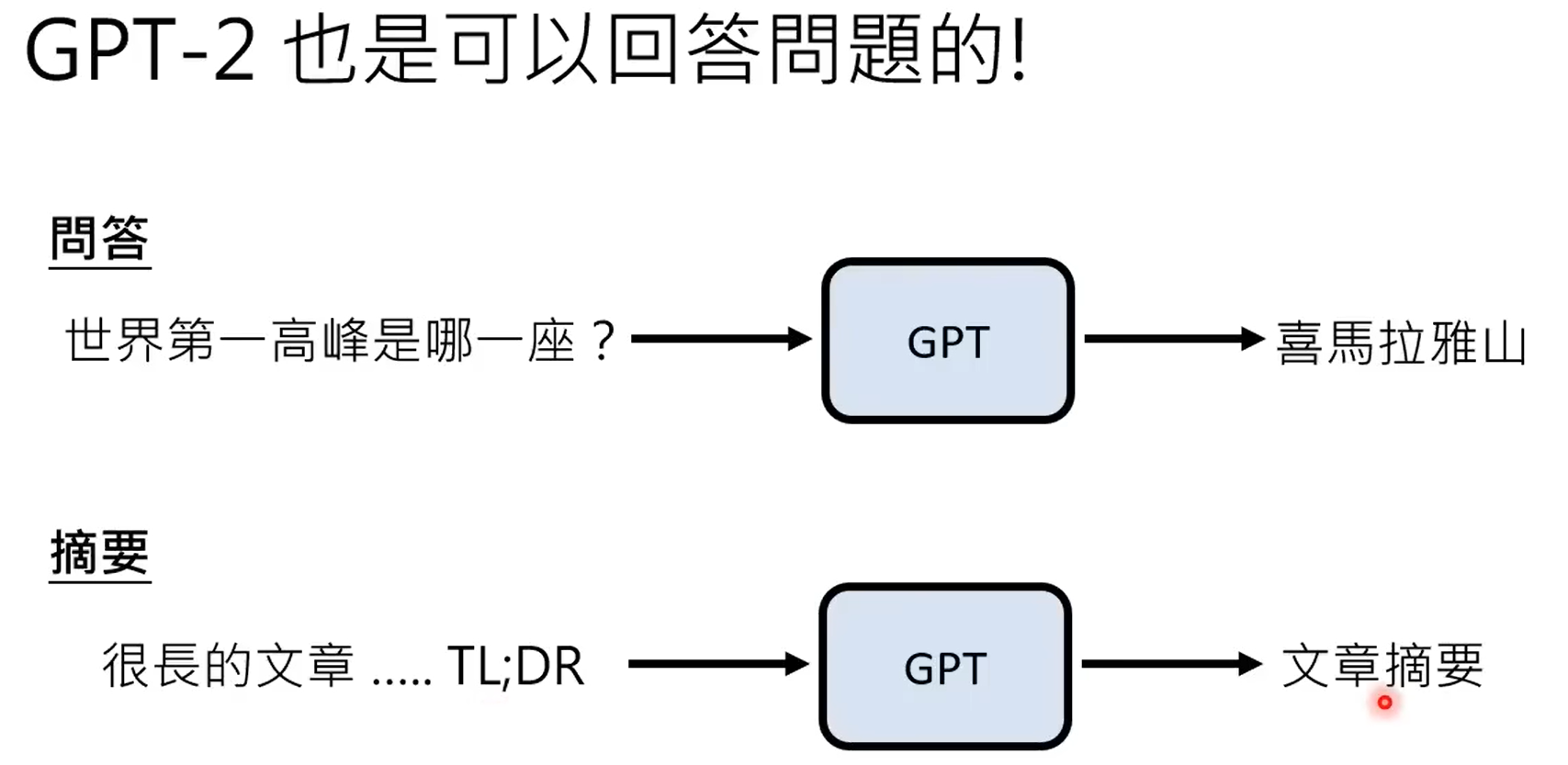
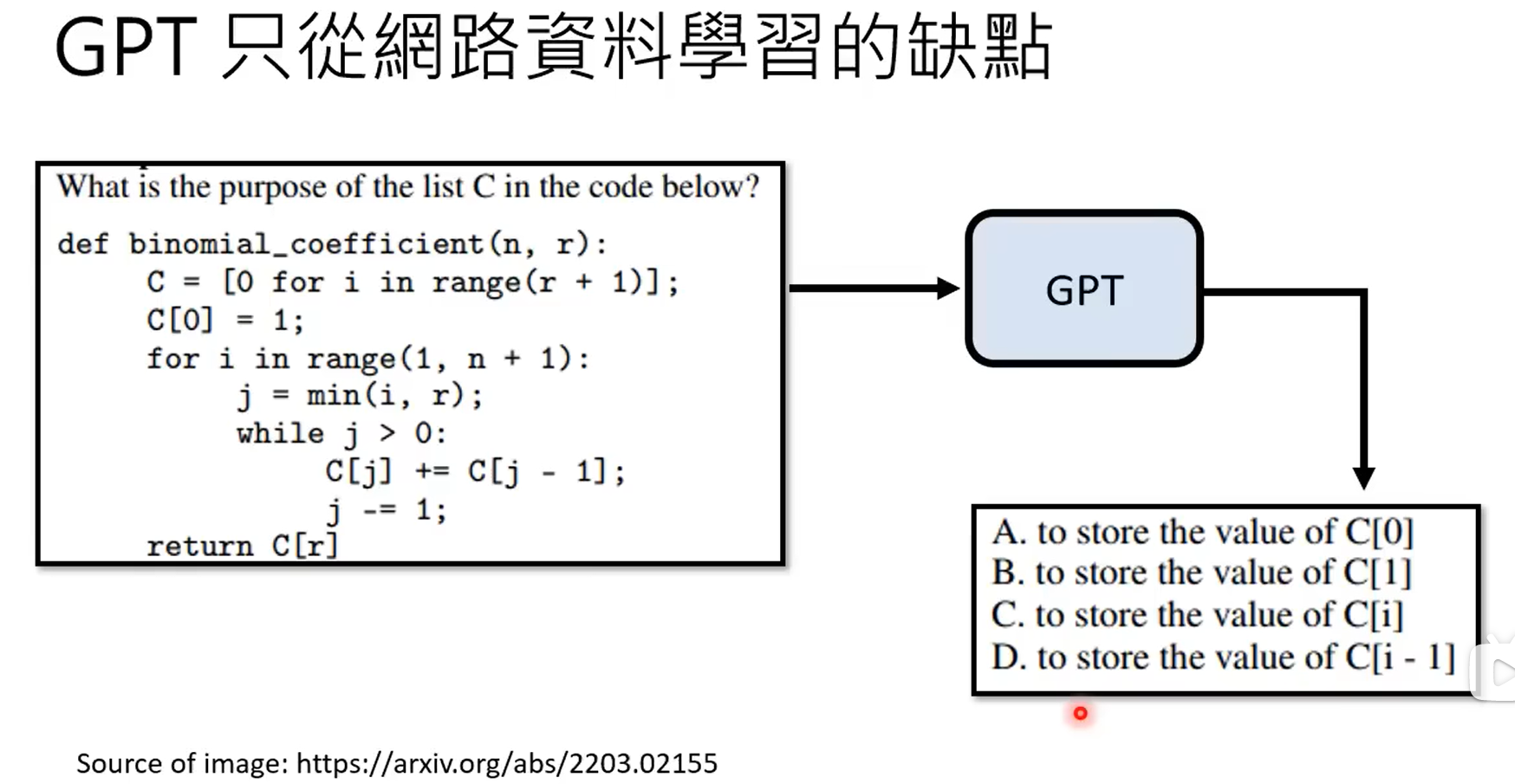
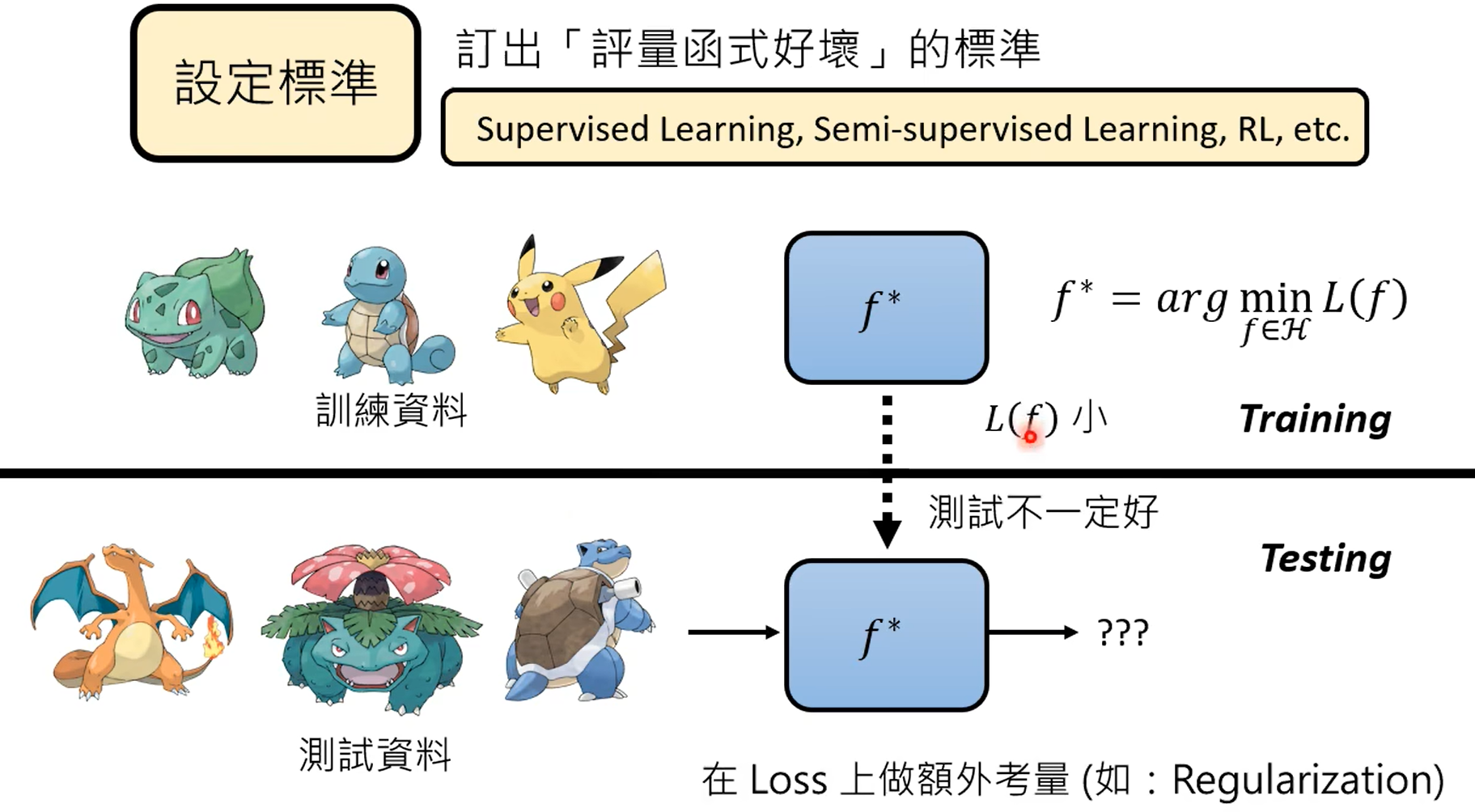
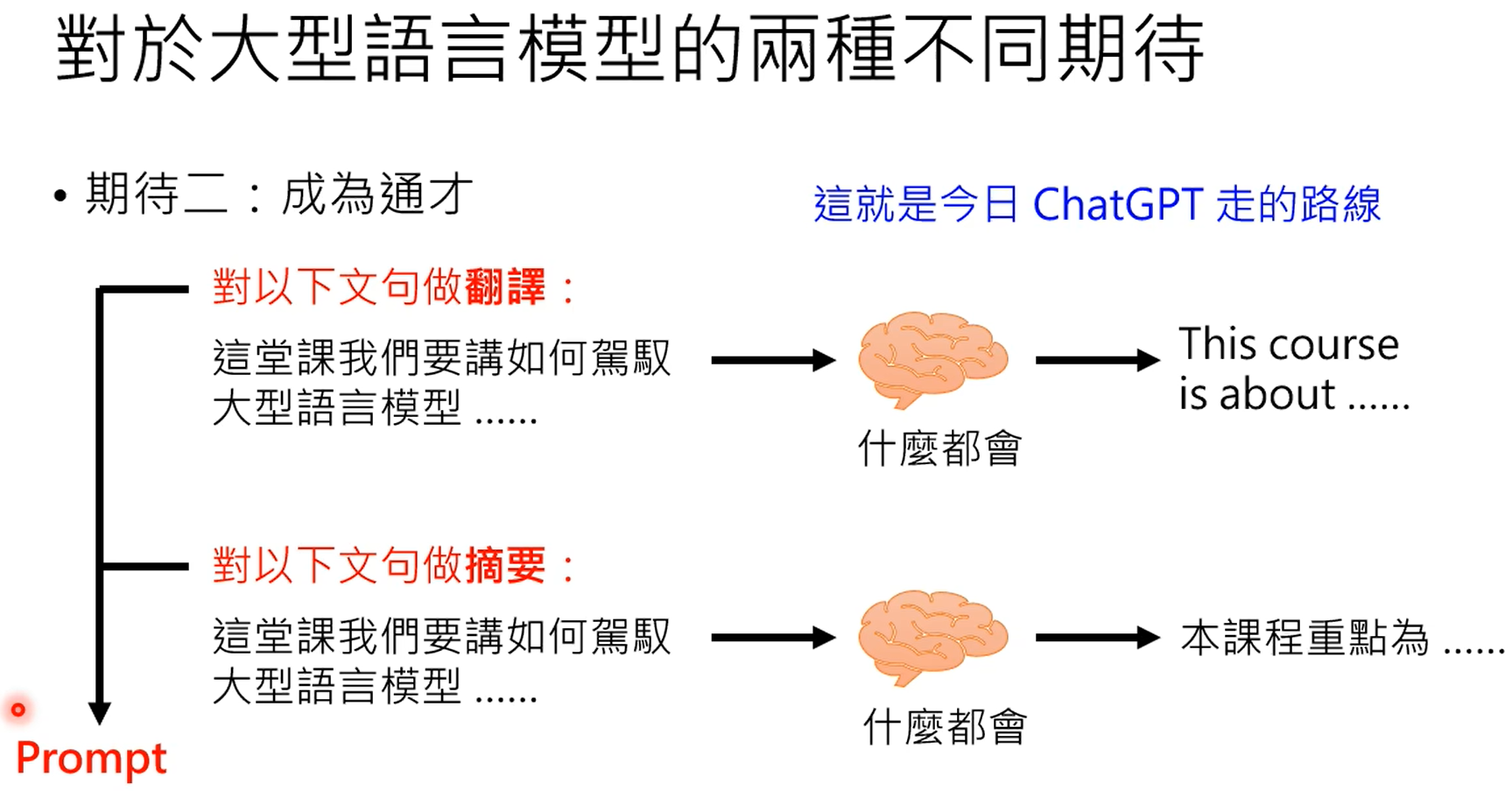
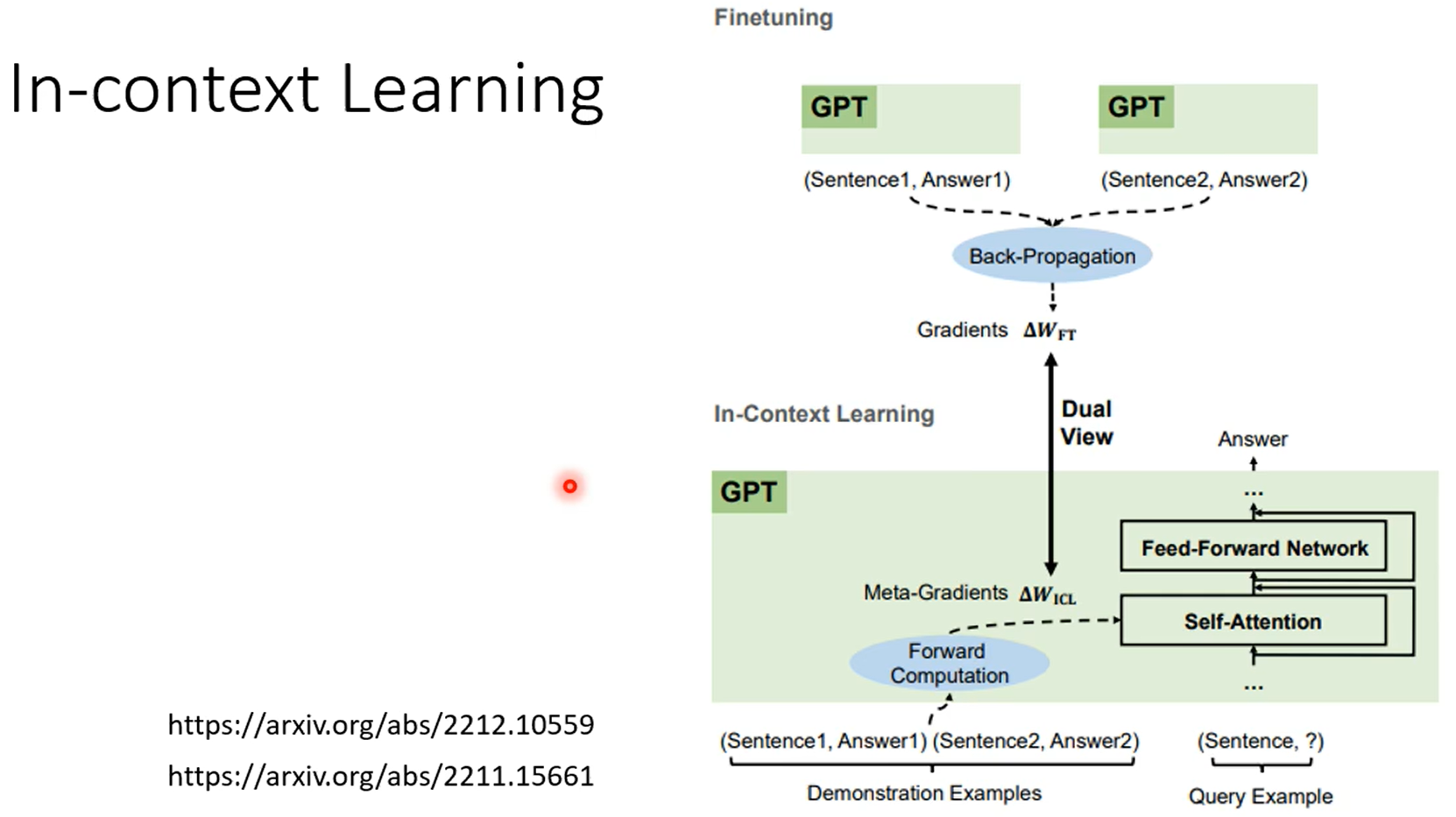
GPT3能力虽强,但是不受控,本质上还是根据prompt进行续写的模型。

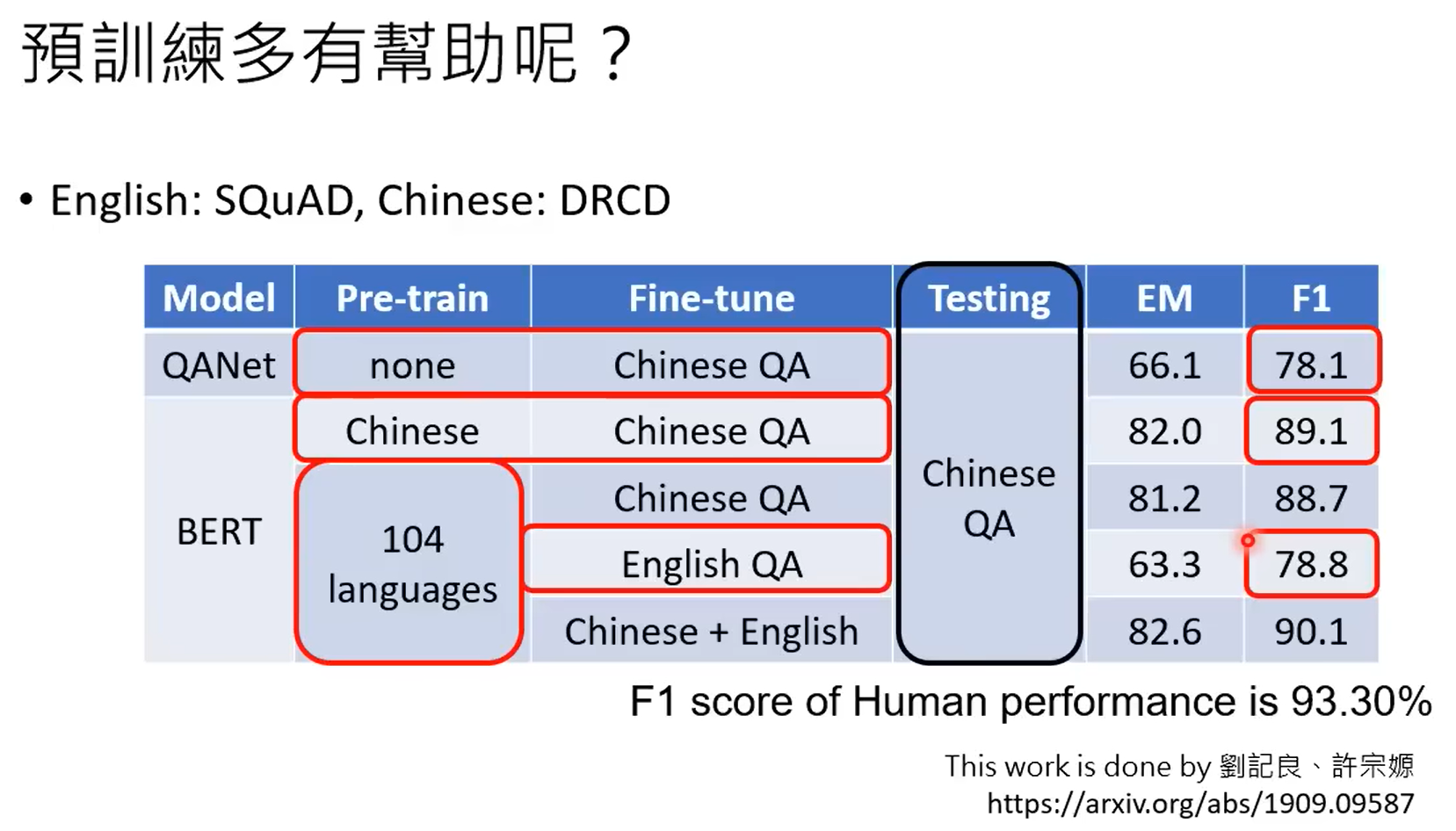
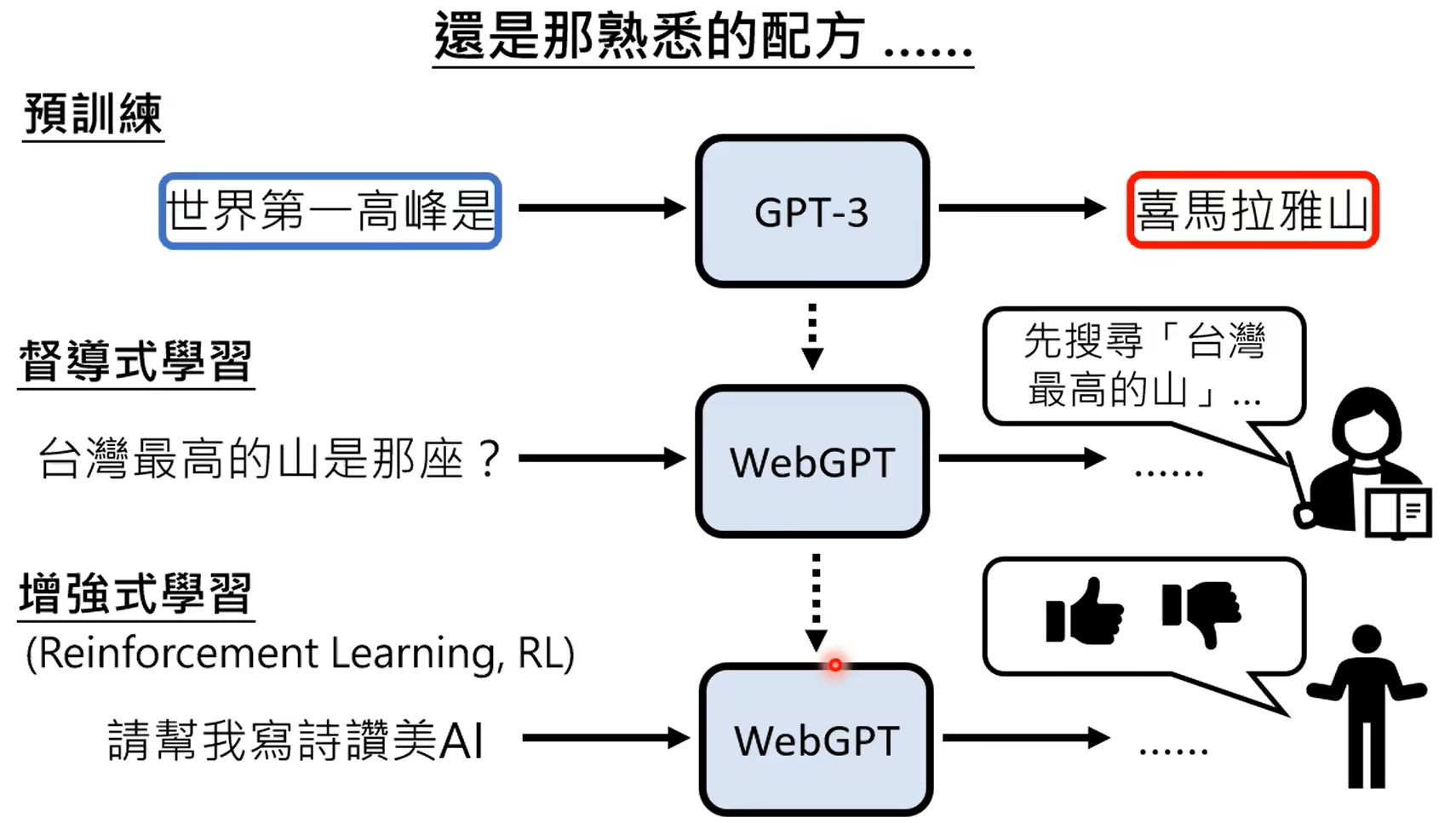
chatgpt就是根据监督式来学习的gpt,chatgpt有相应的监督信号。使用网络数据进行训练的过程称之为预训练,使用部分数据进行监督,继续学习的过程,称之为微调。

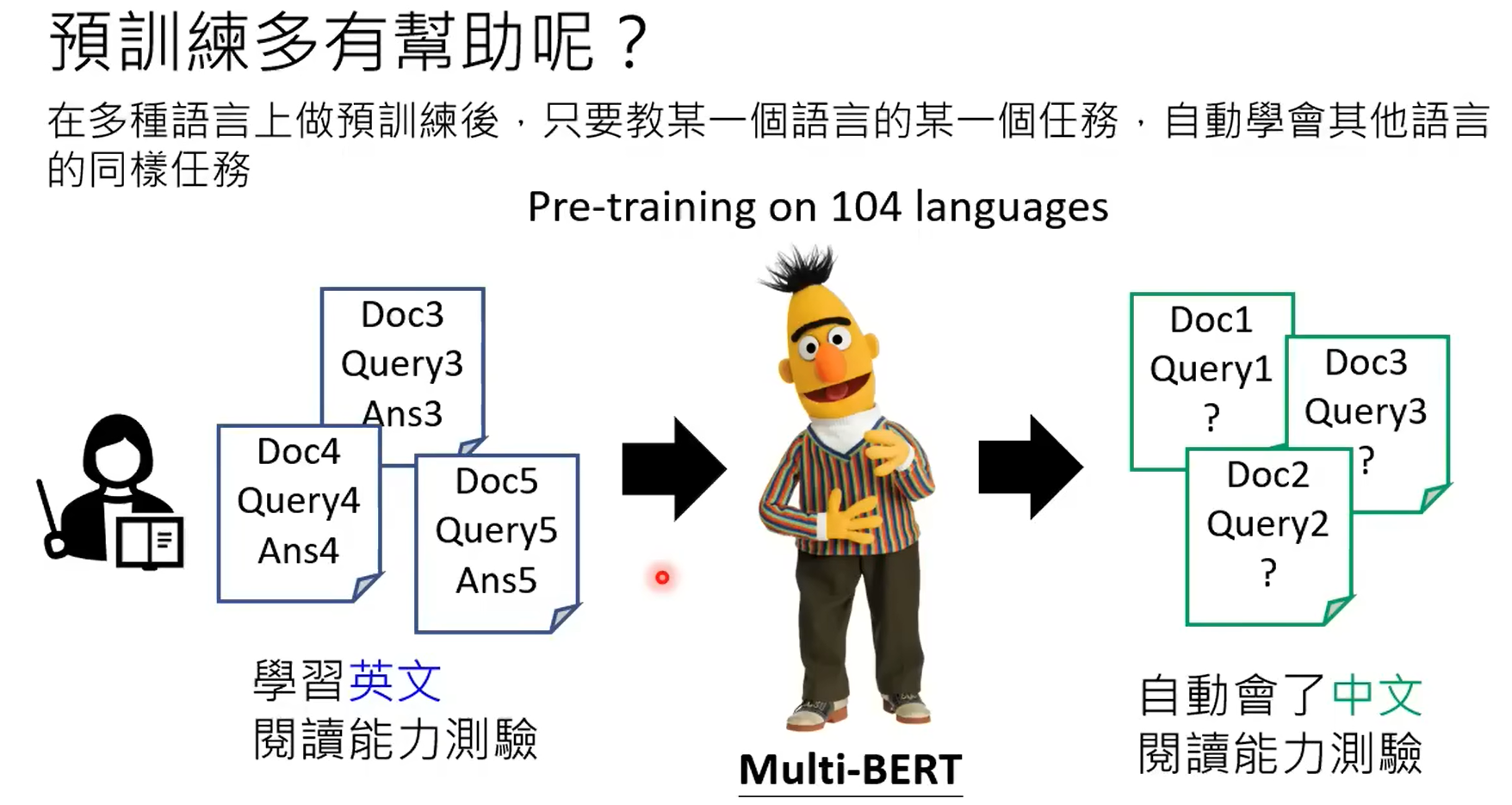

强化学习首先是比人类标注结果要更加省力,其次在部分任务上,也只能由强化学习来做,强化学习只需要给出结果是好还是坏即可,比如写一首诗,人不一定能写出来,但是gpt写出来之后,直接标对错即可。



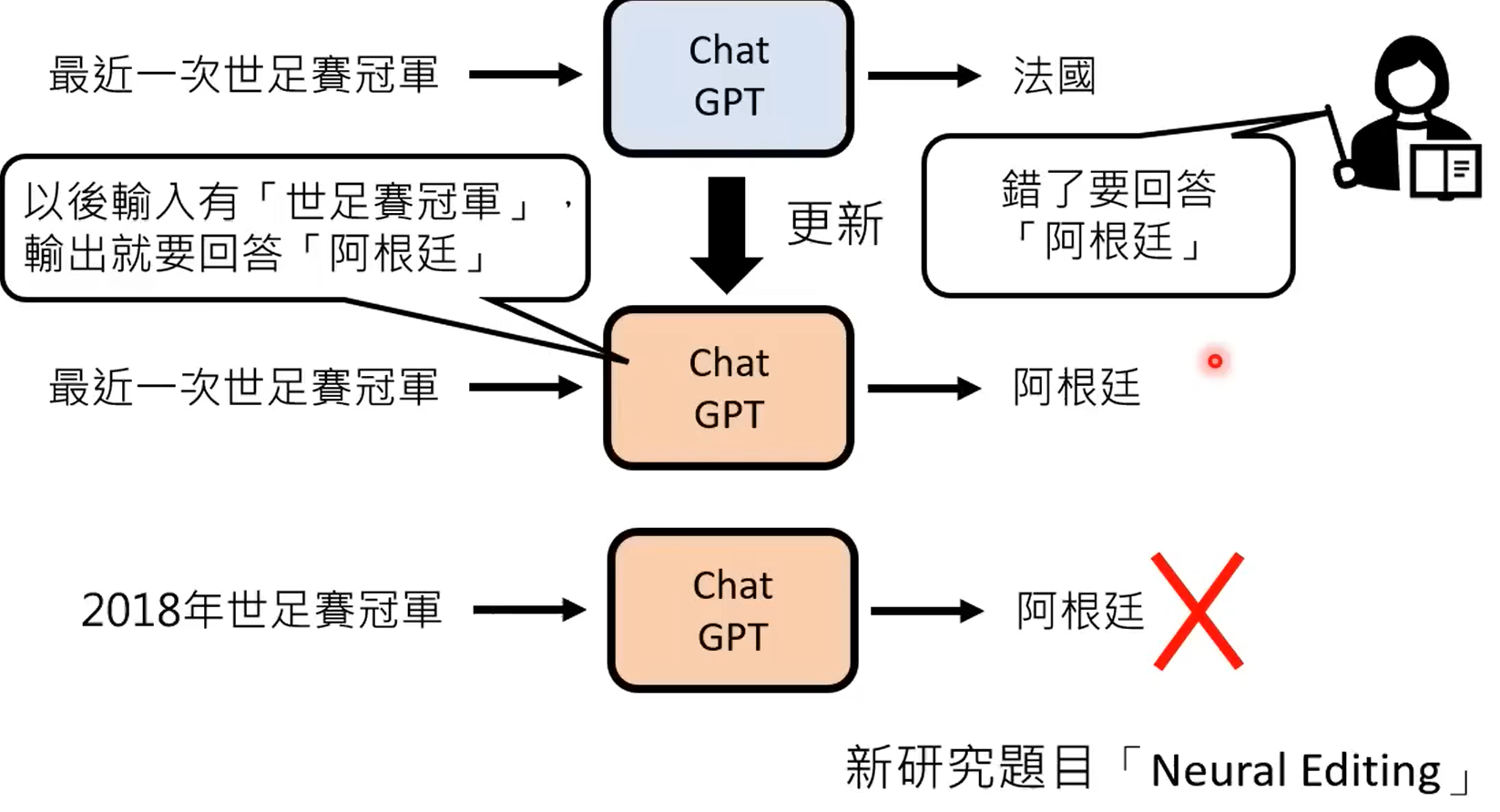
这应该是有监督精调之后的结果,使用人来标注数据告诉chatgpt2022年的知识无法预测。
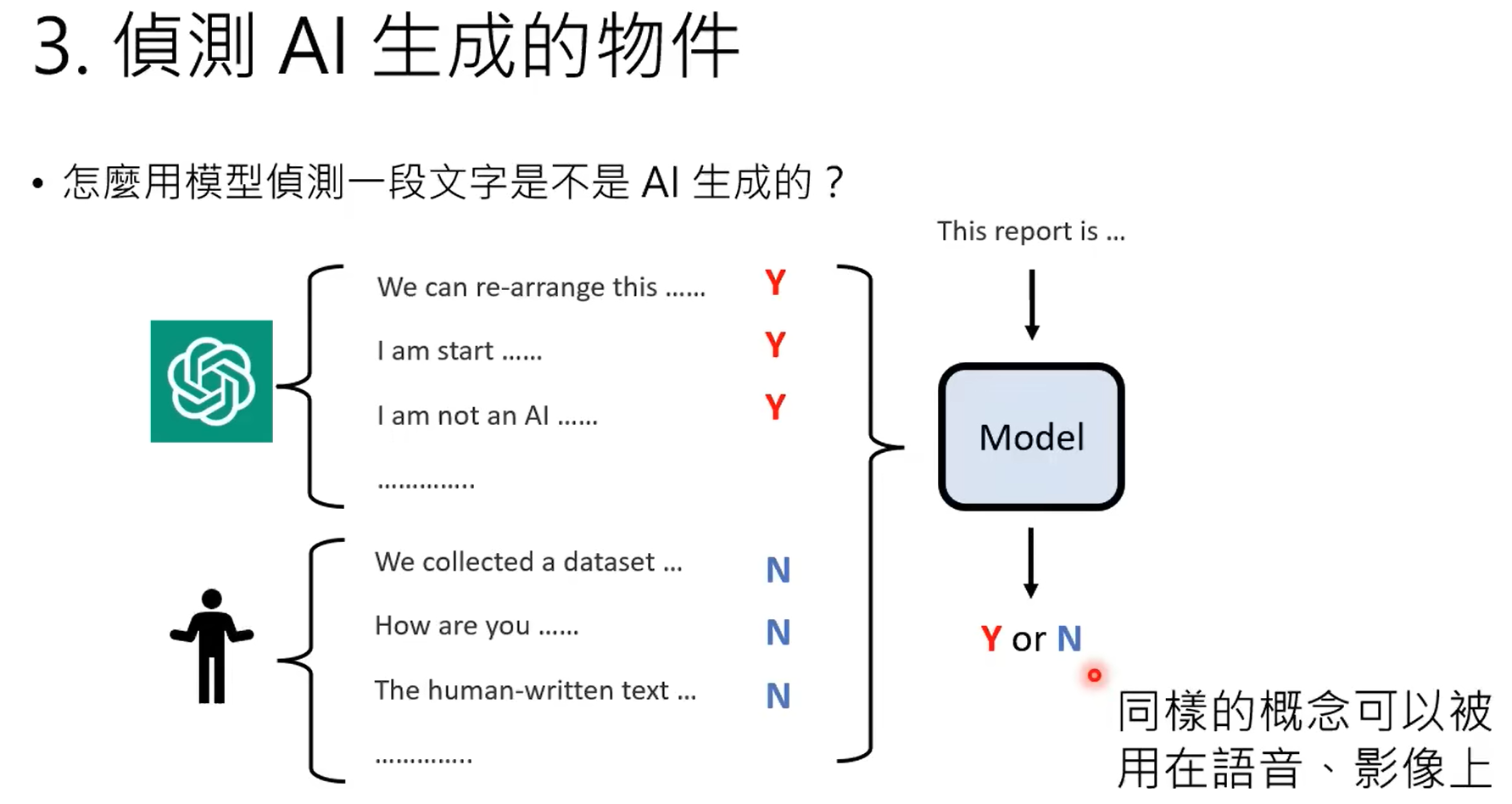
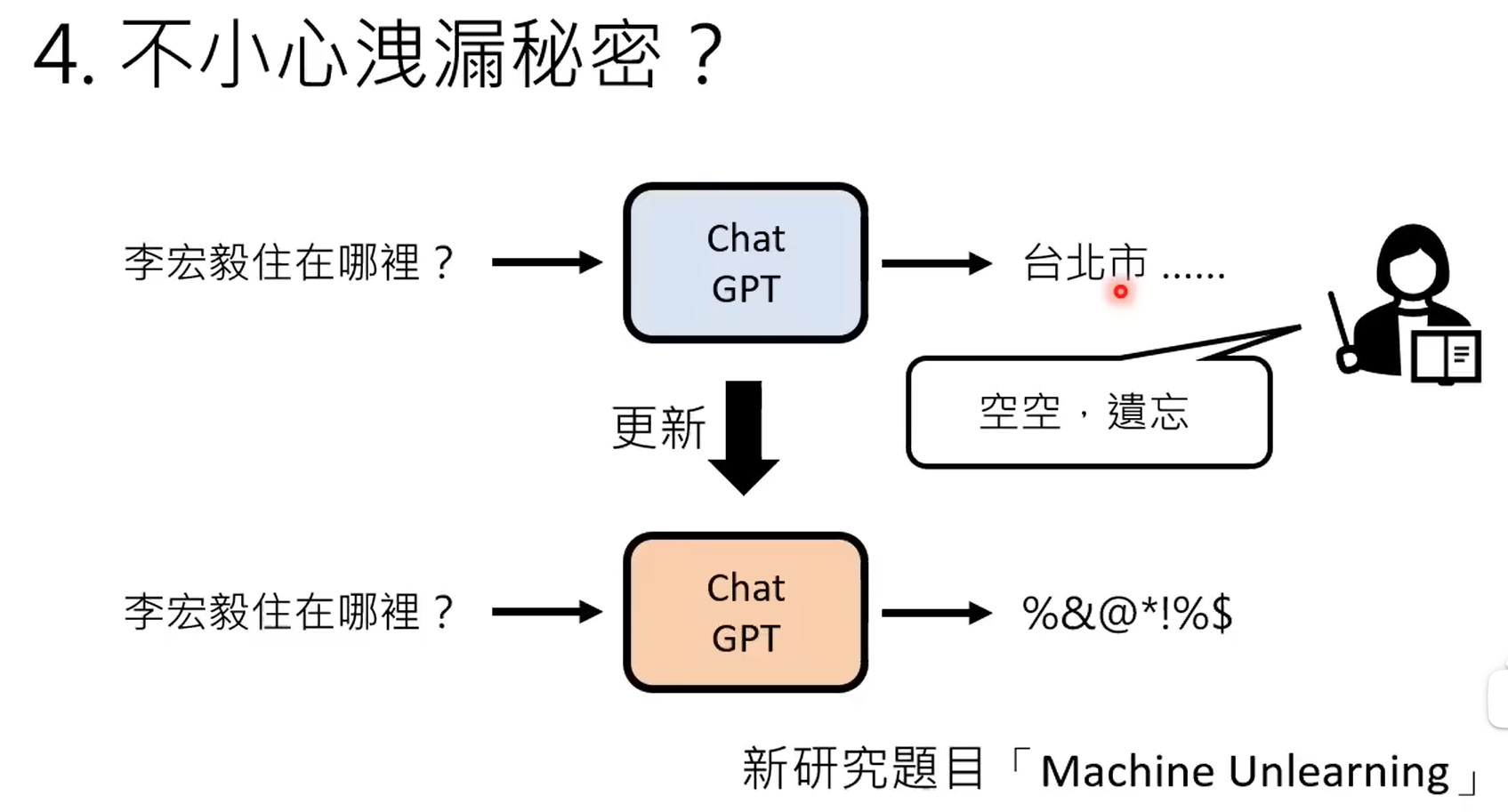
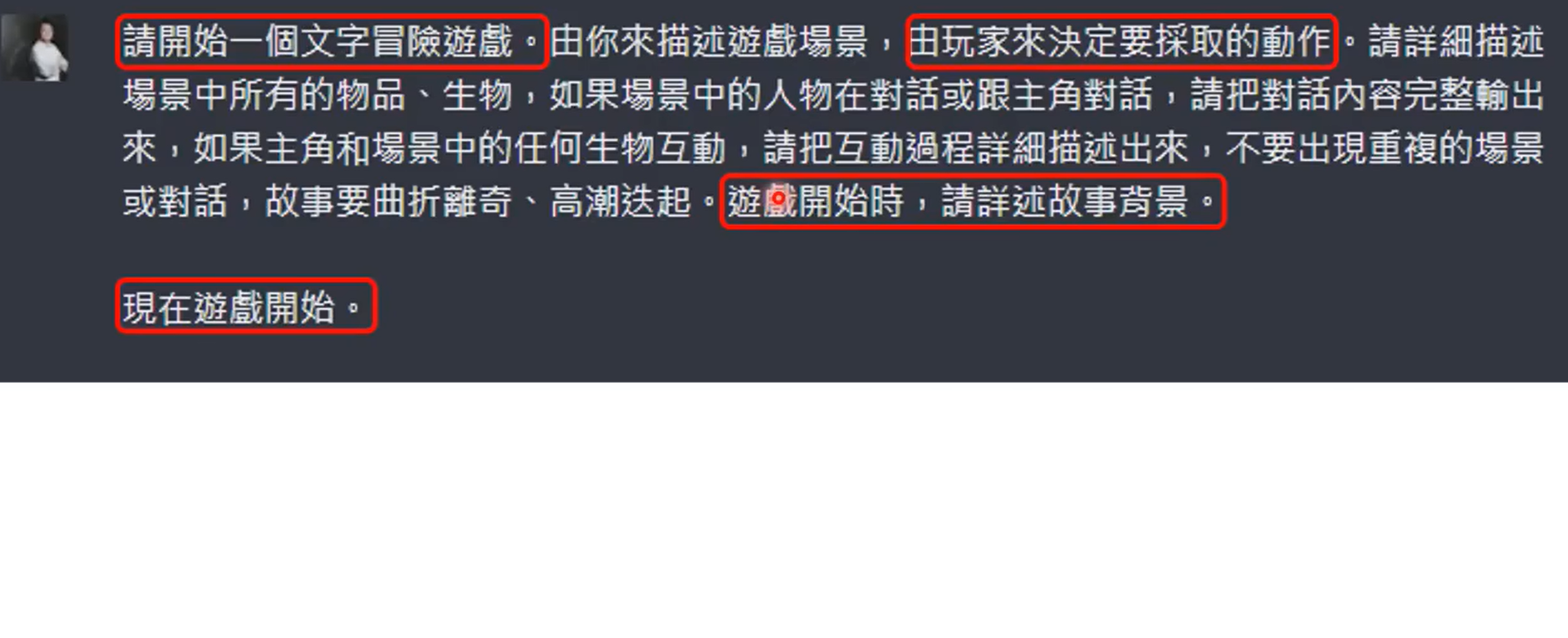

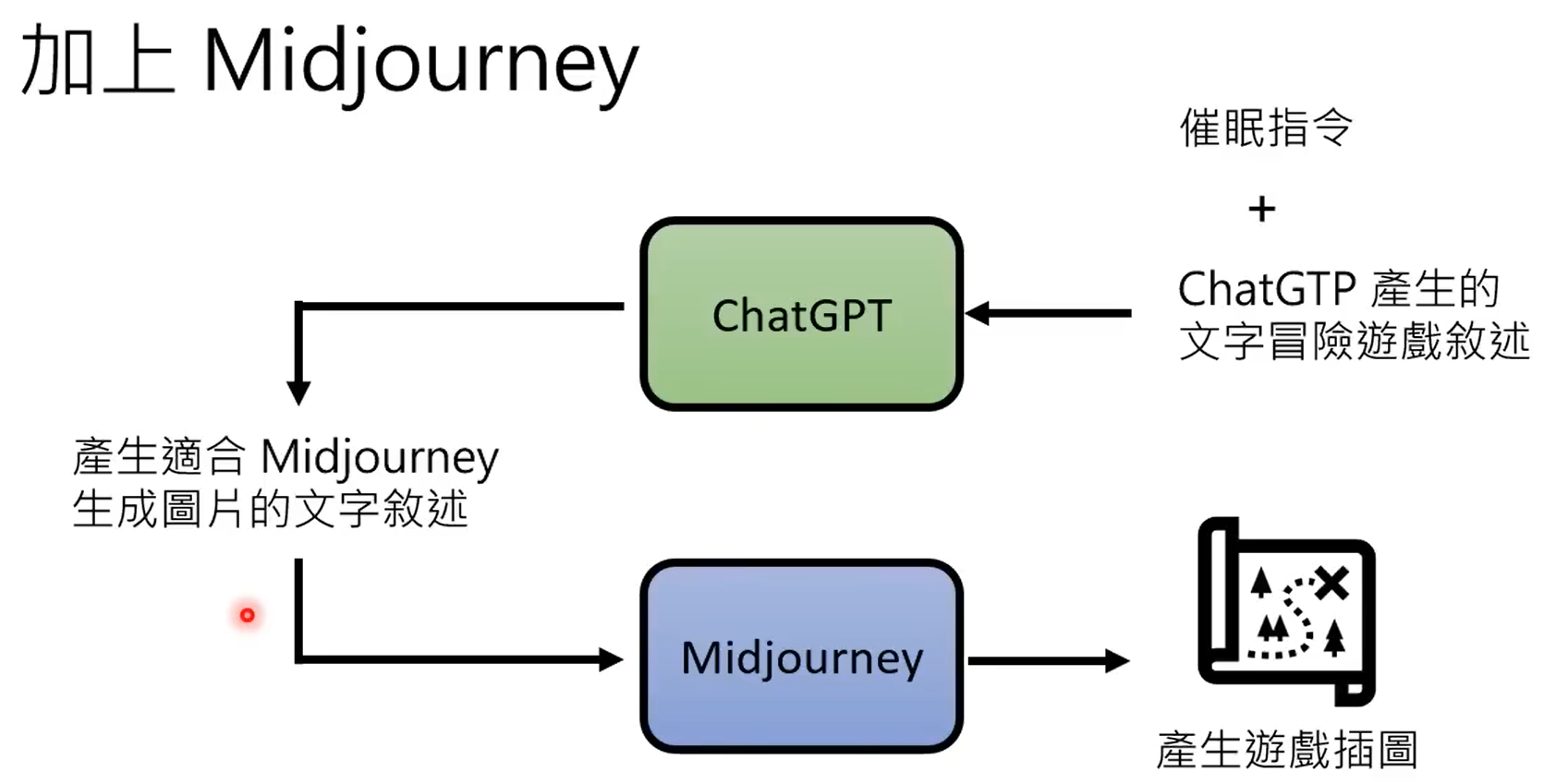


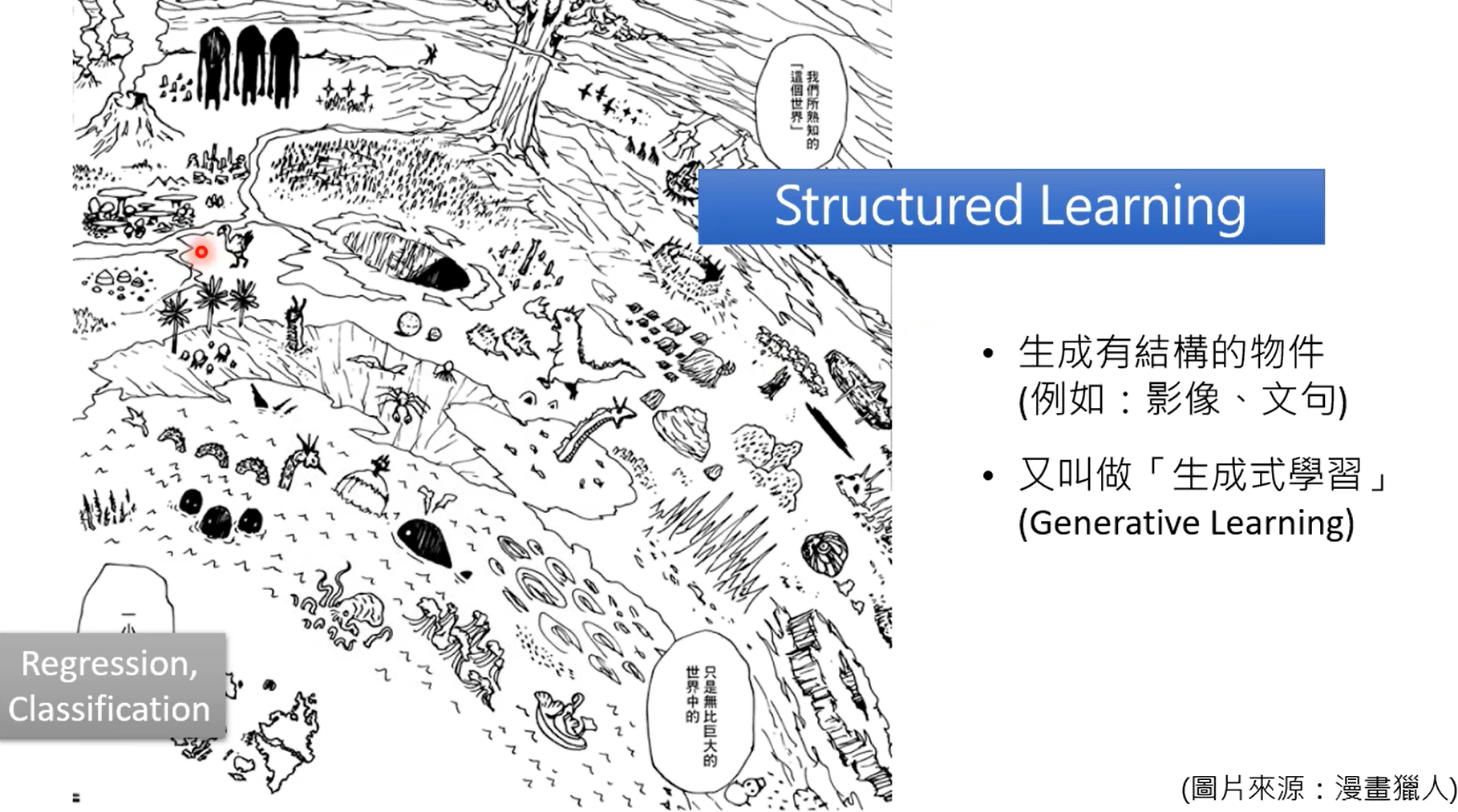
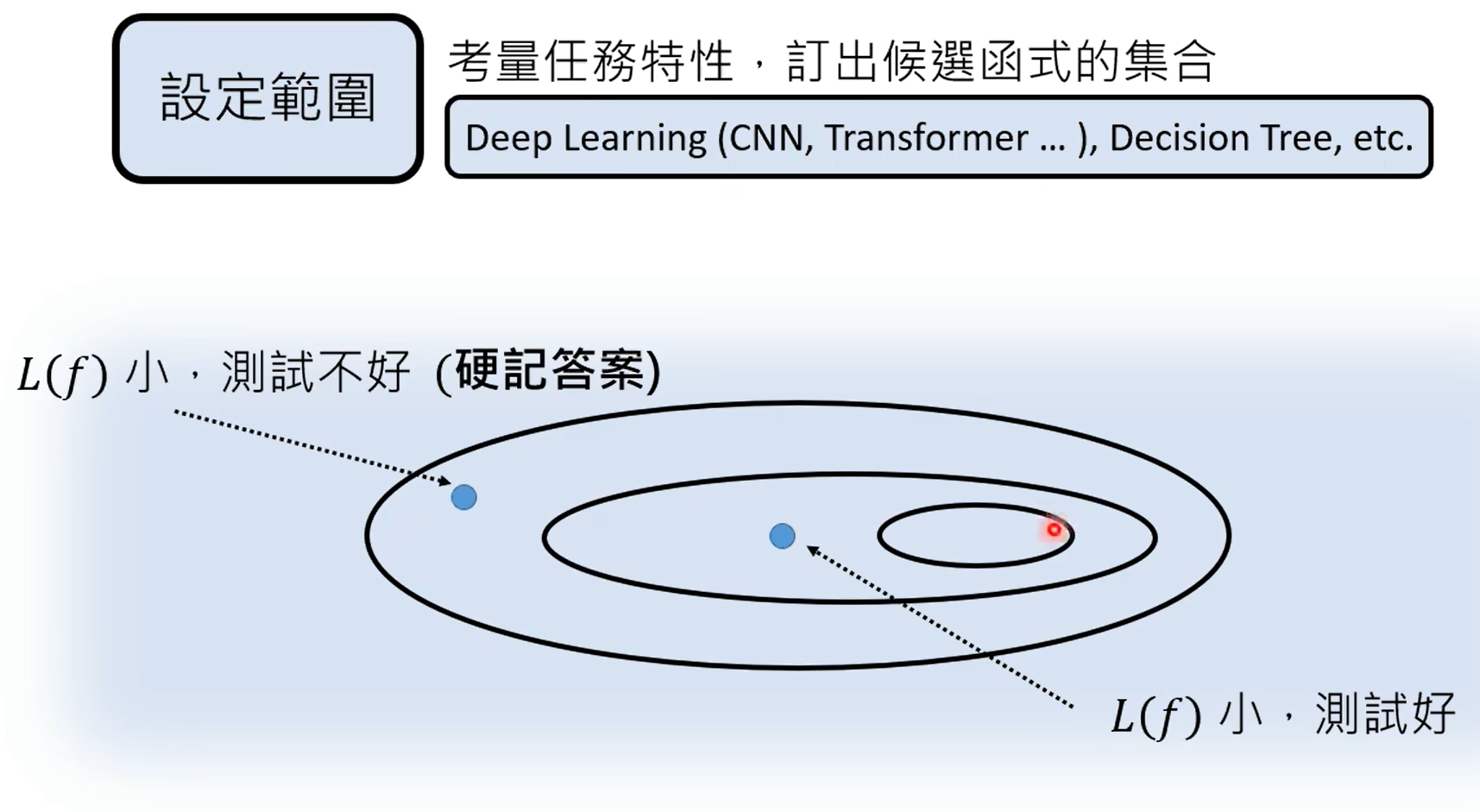
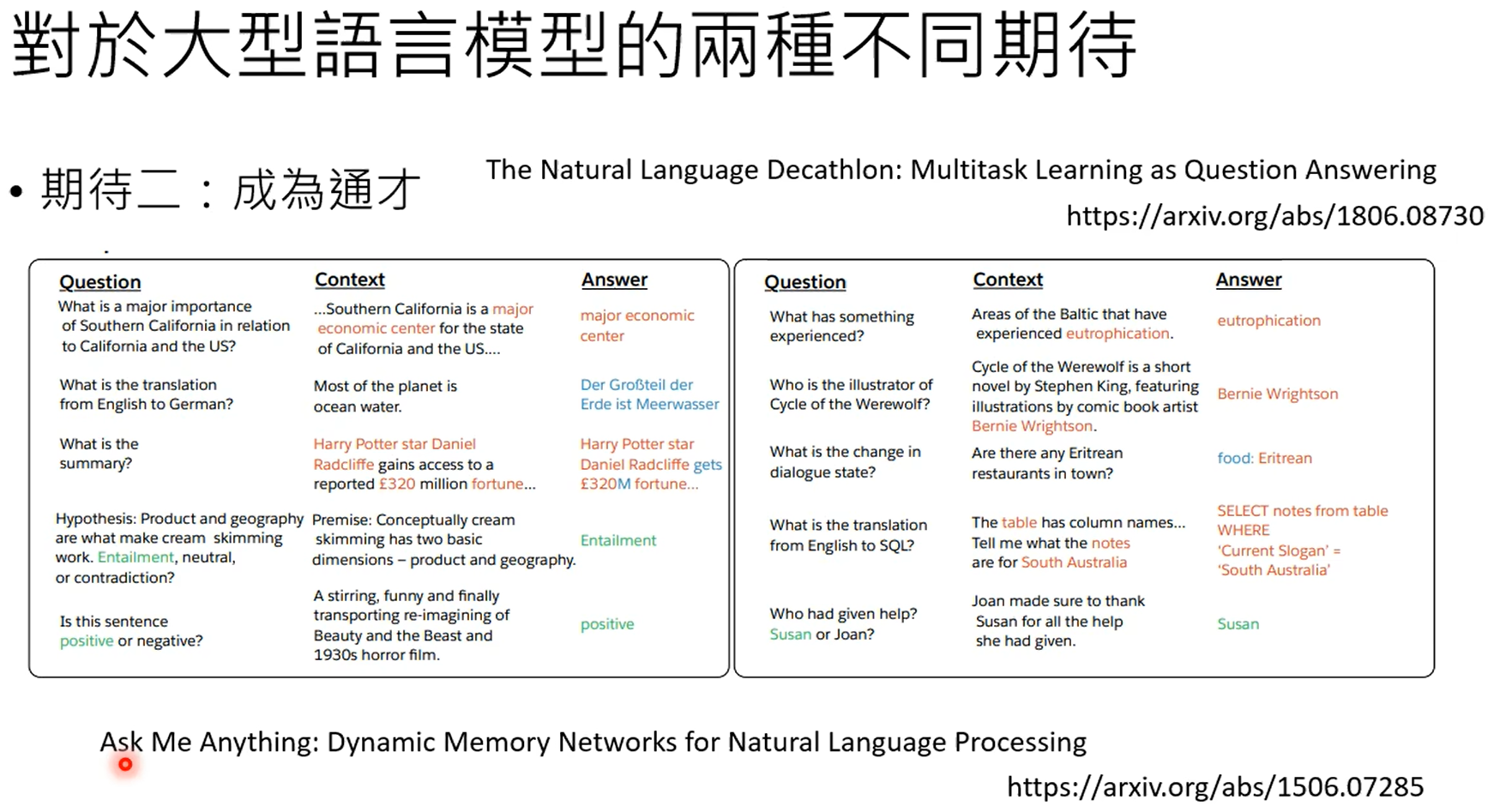
除了传统的回归分类这种判别式学习,另外一种就是生成式学习。

一共有固定数量的token,gpt的生成式实际上就是在token中找出最合适的那个token。








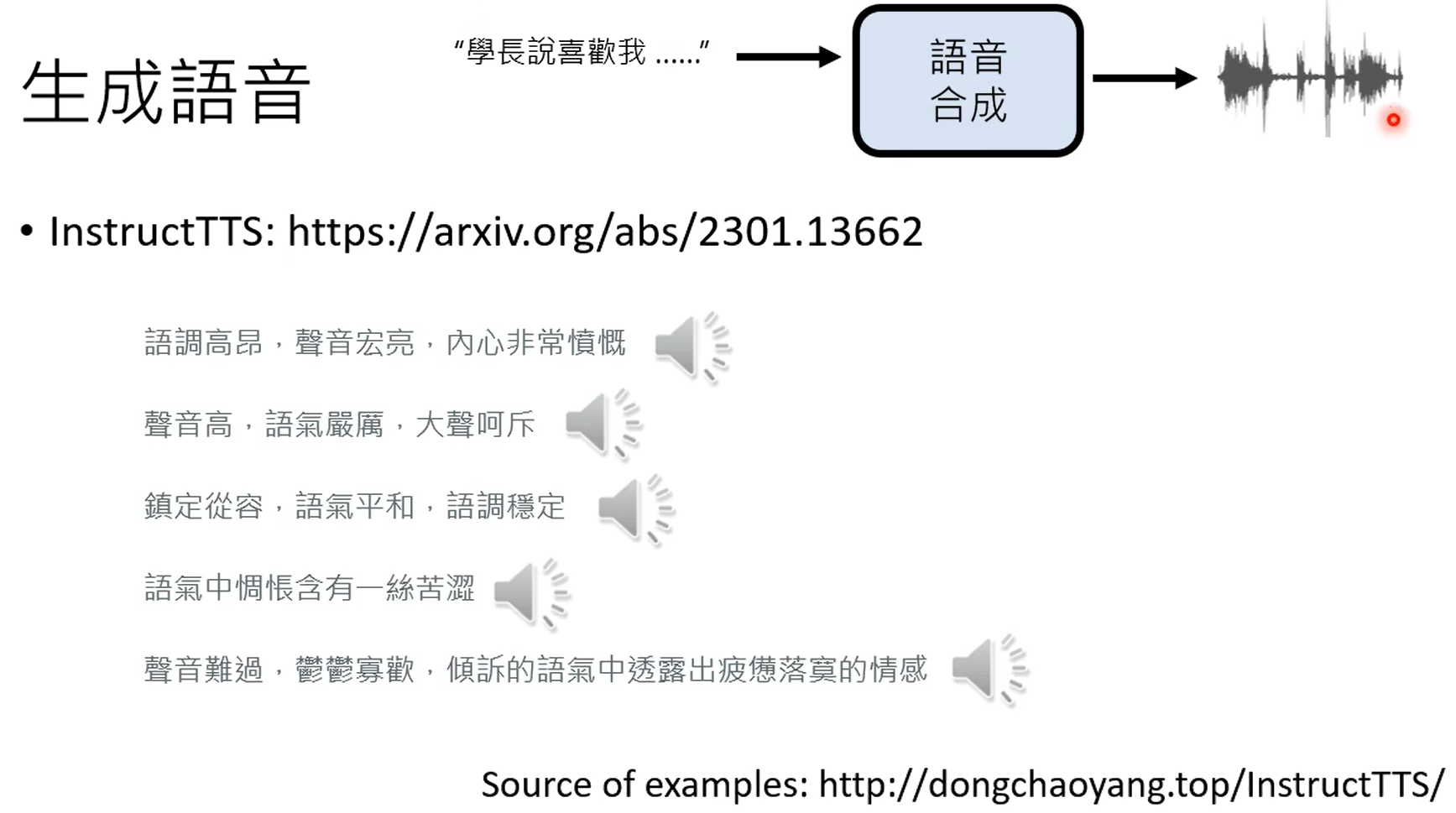
生成人声,下面这个是生成各种声音,不一定是人声。

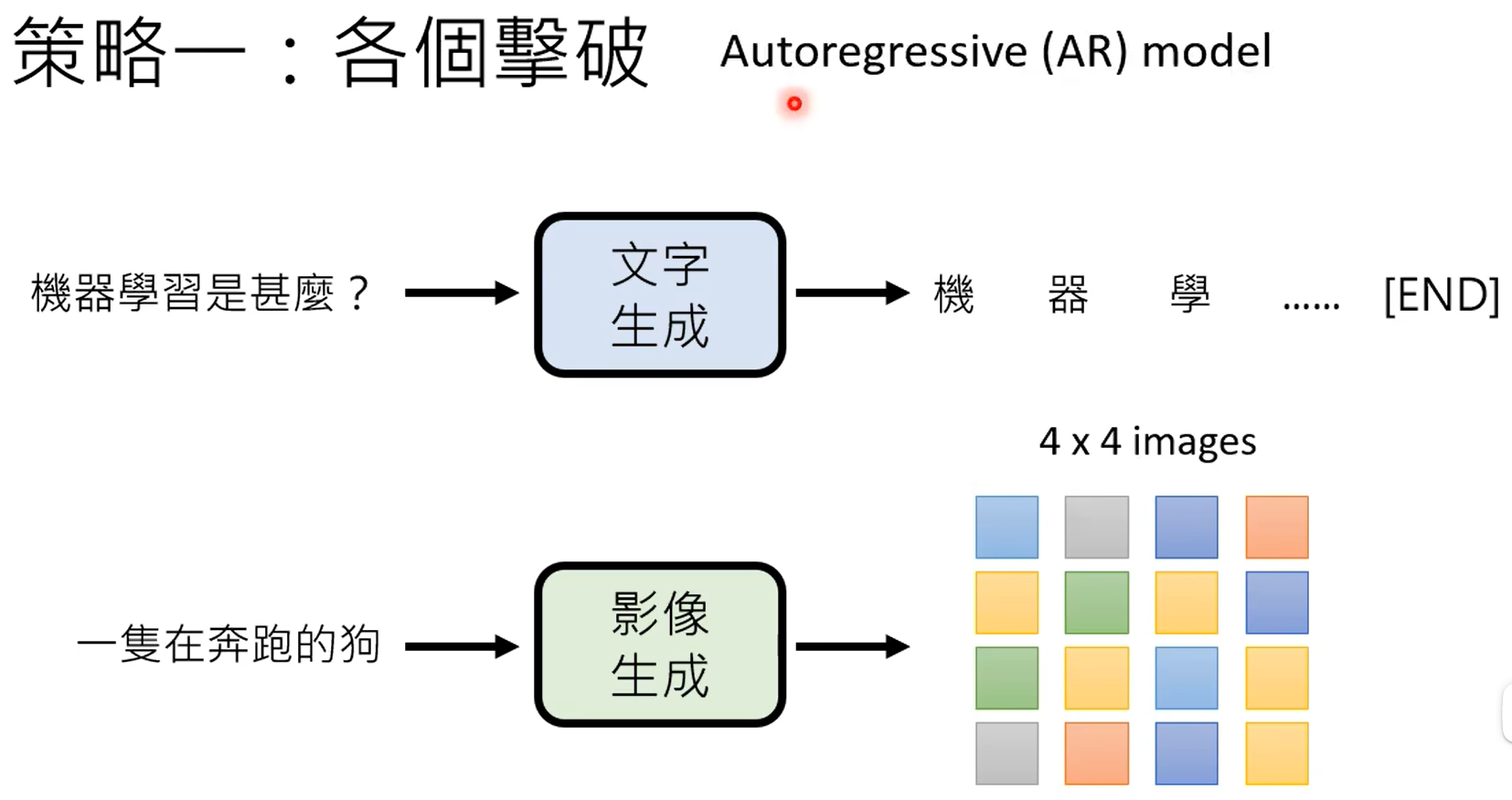
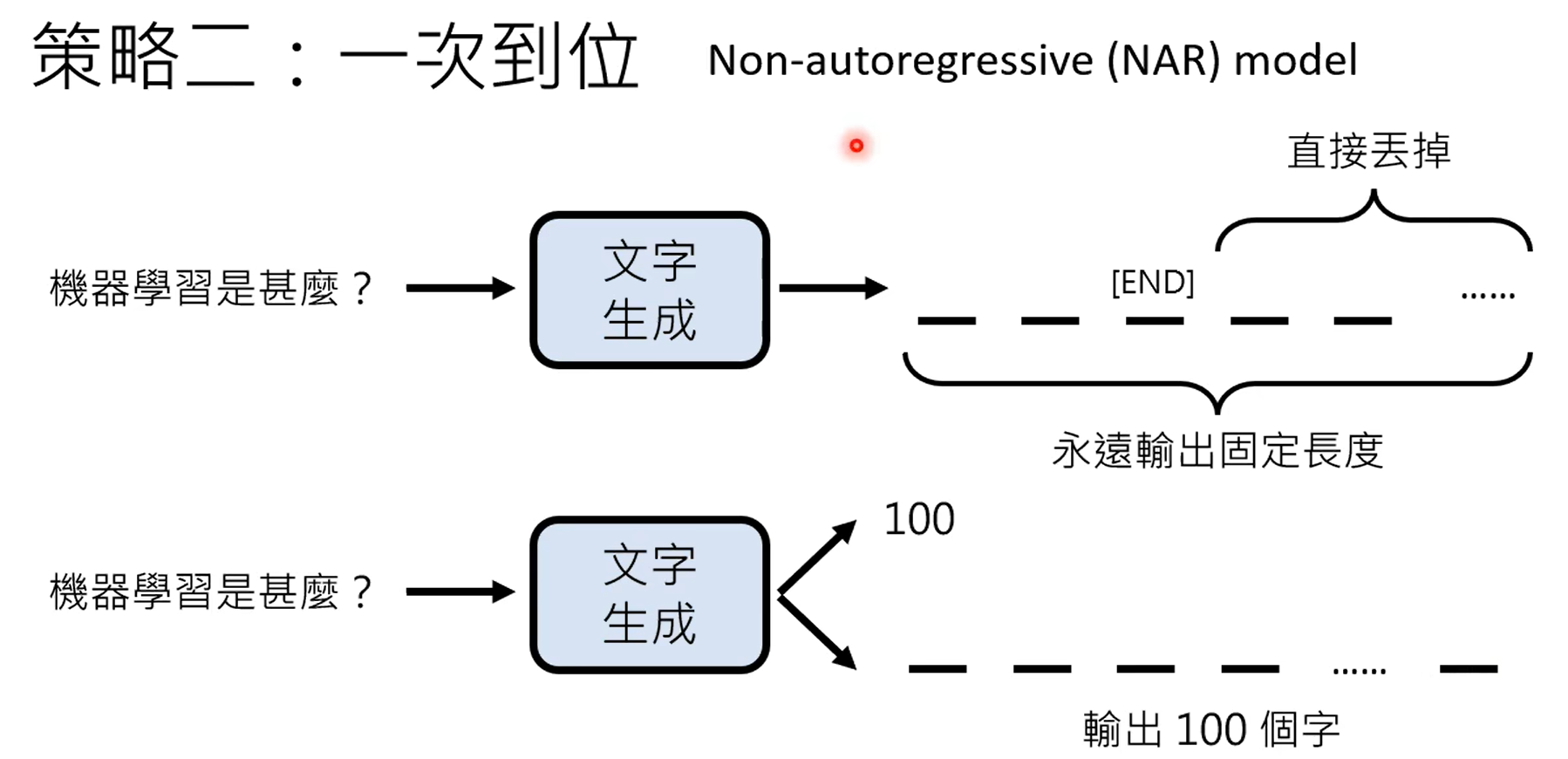
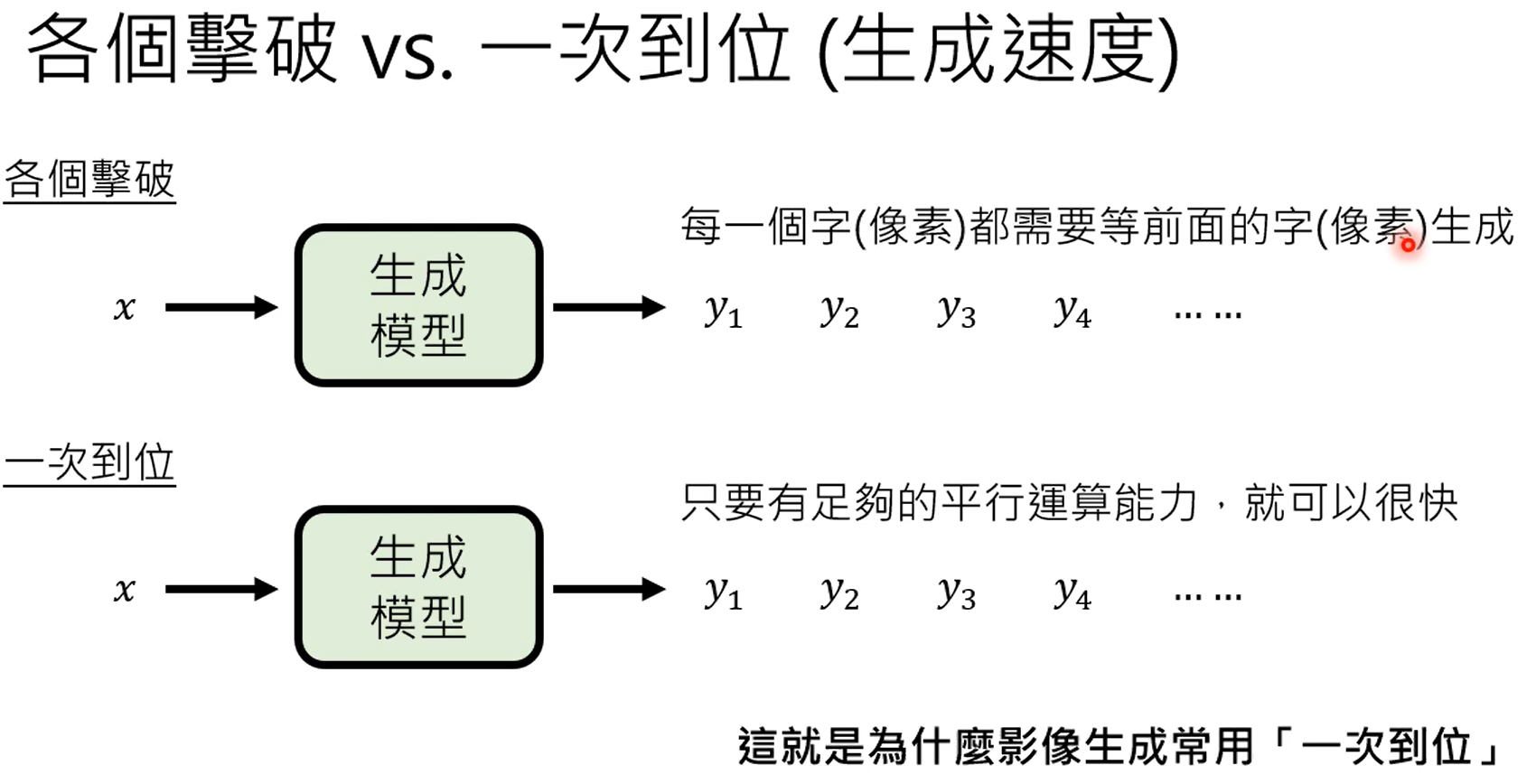



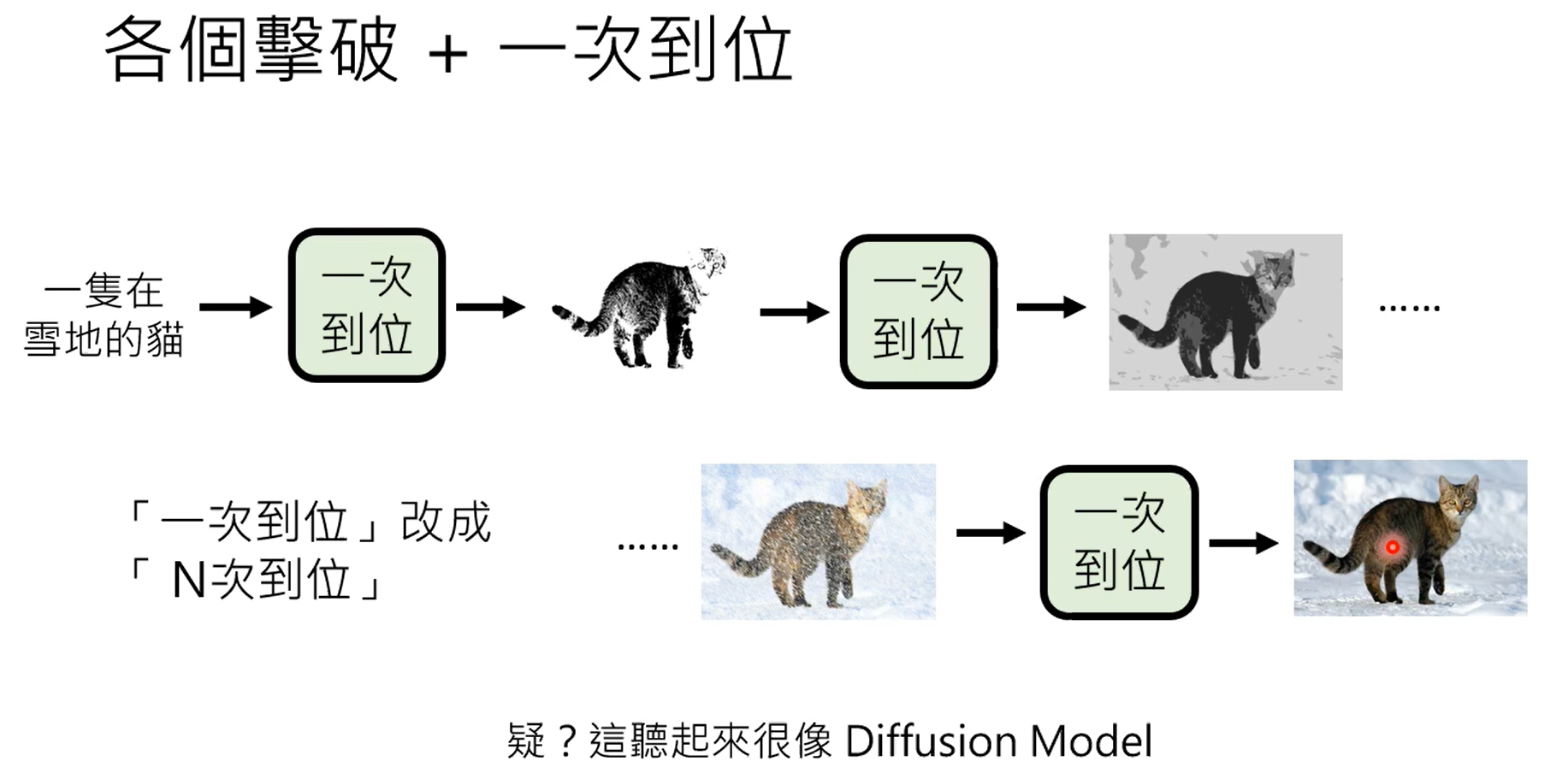
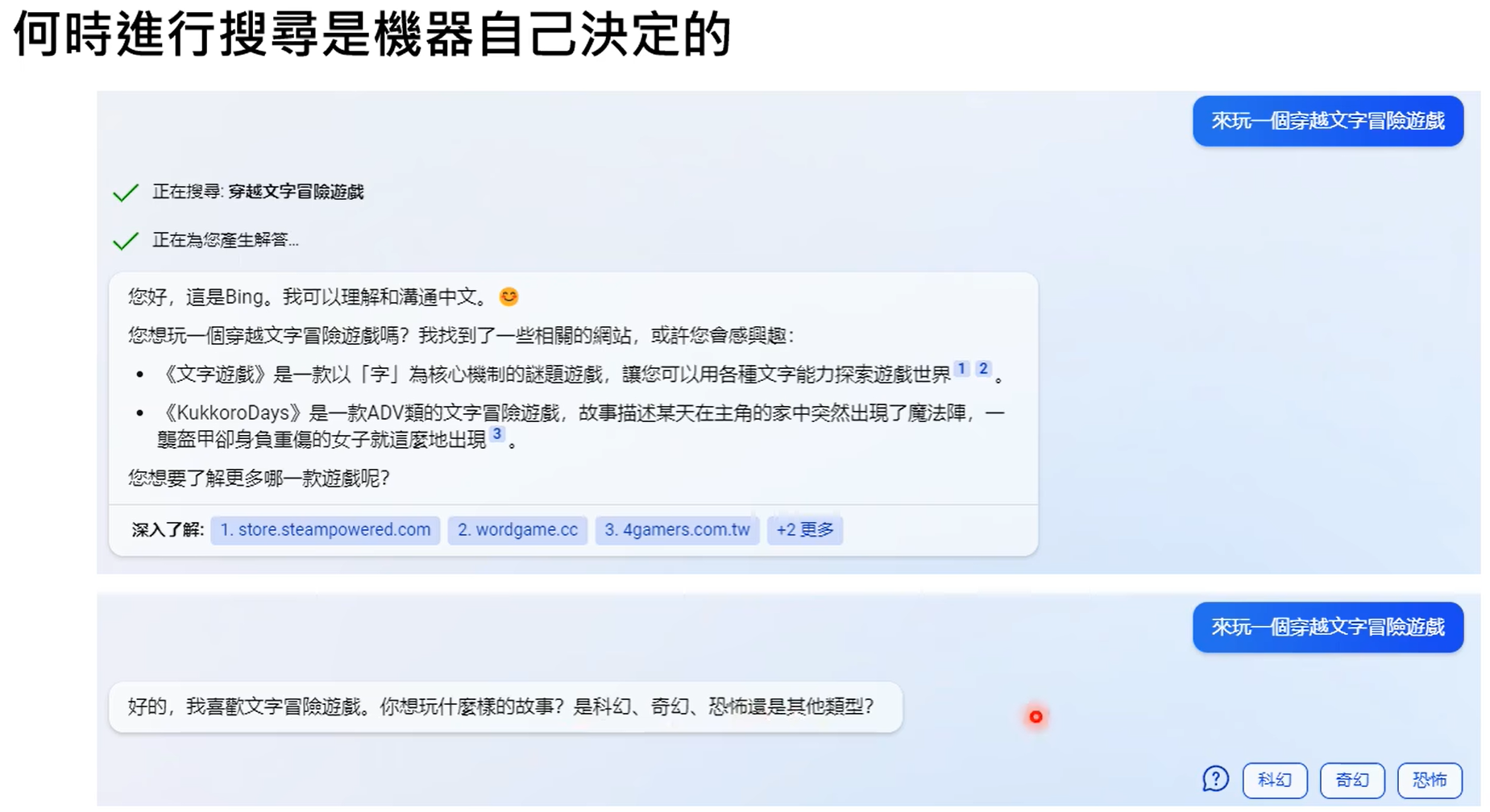
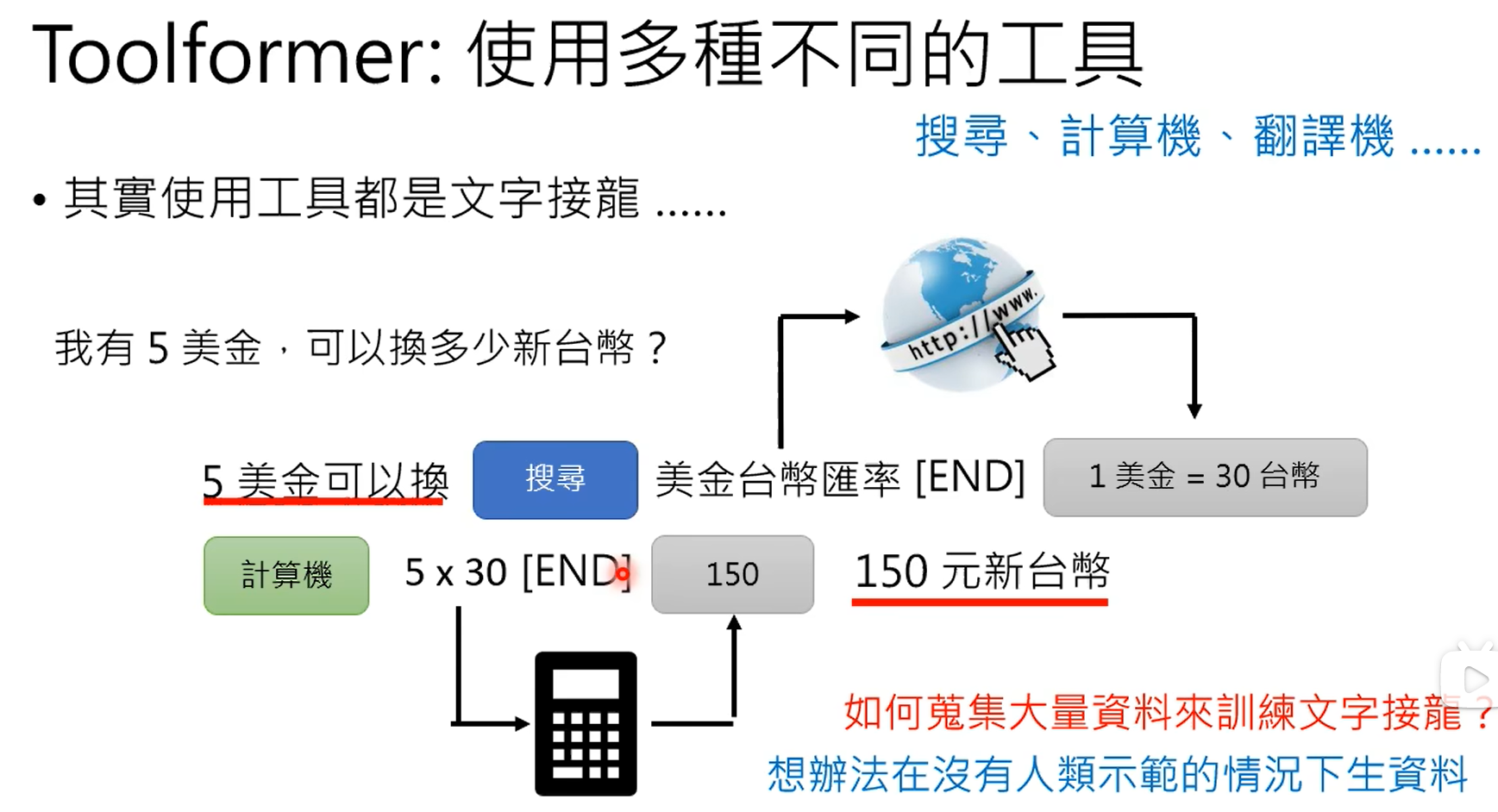
什么时候从网络上搜索,什么时候不搜,这个是由gpt自己决定的。



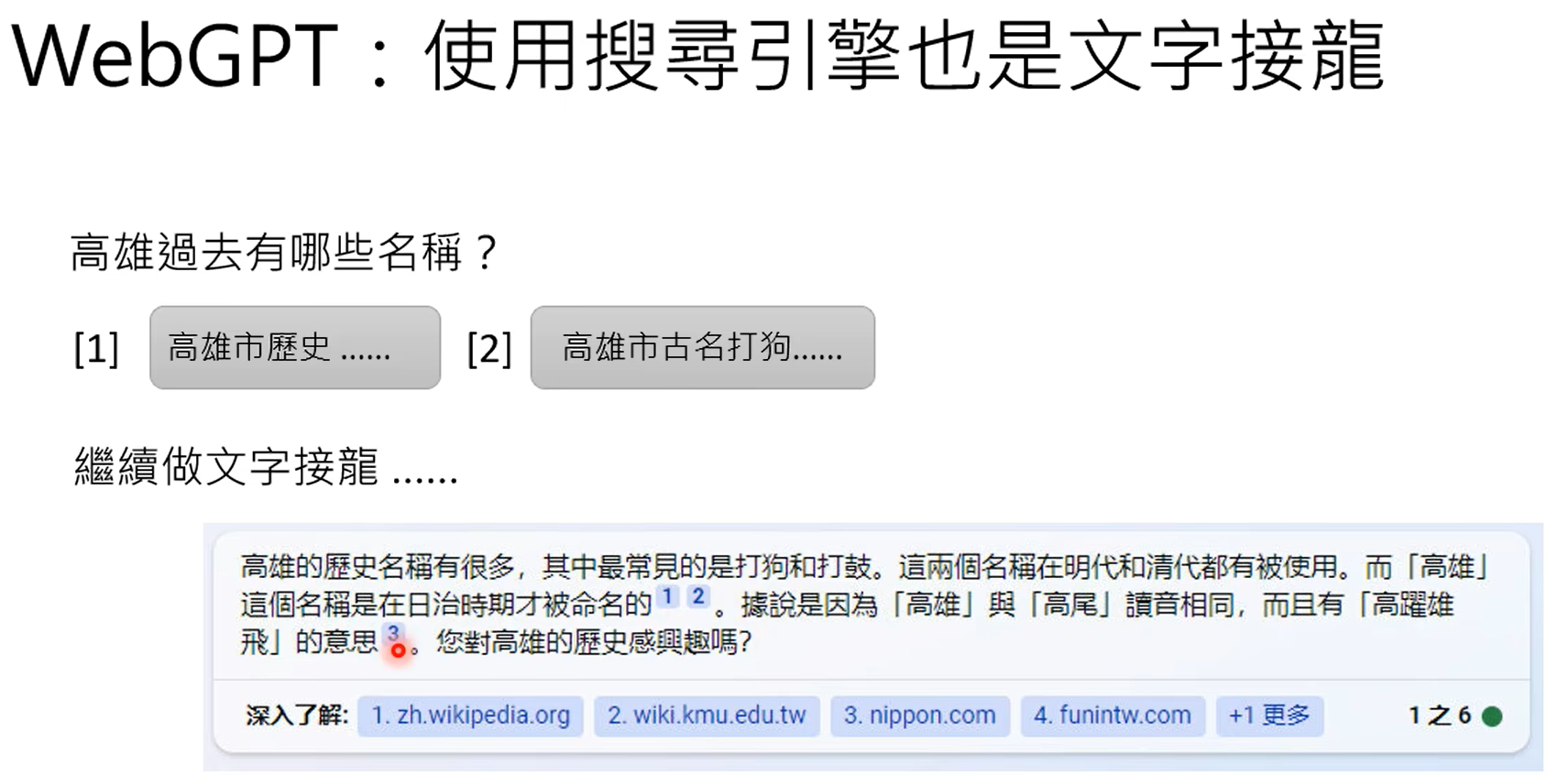



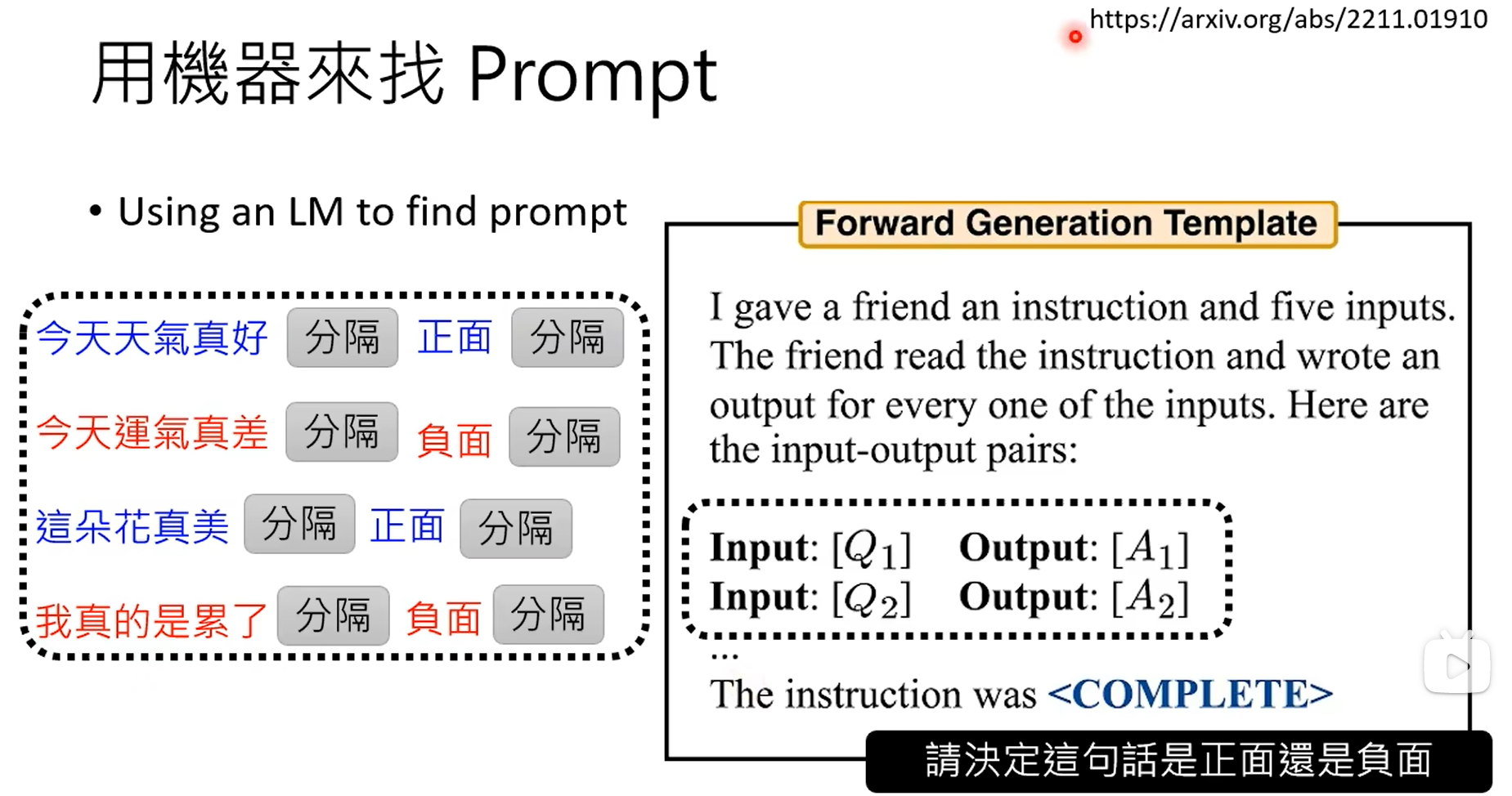
上面两步是生成训练数据的。



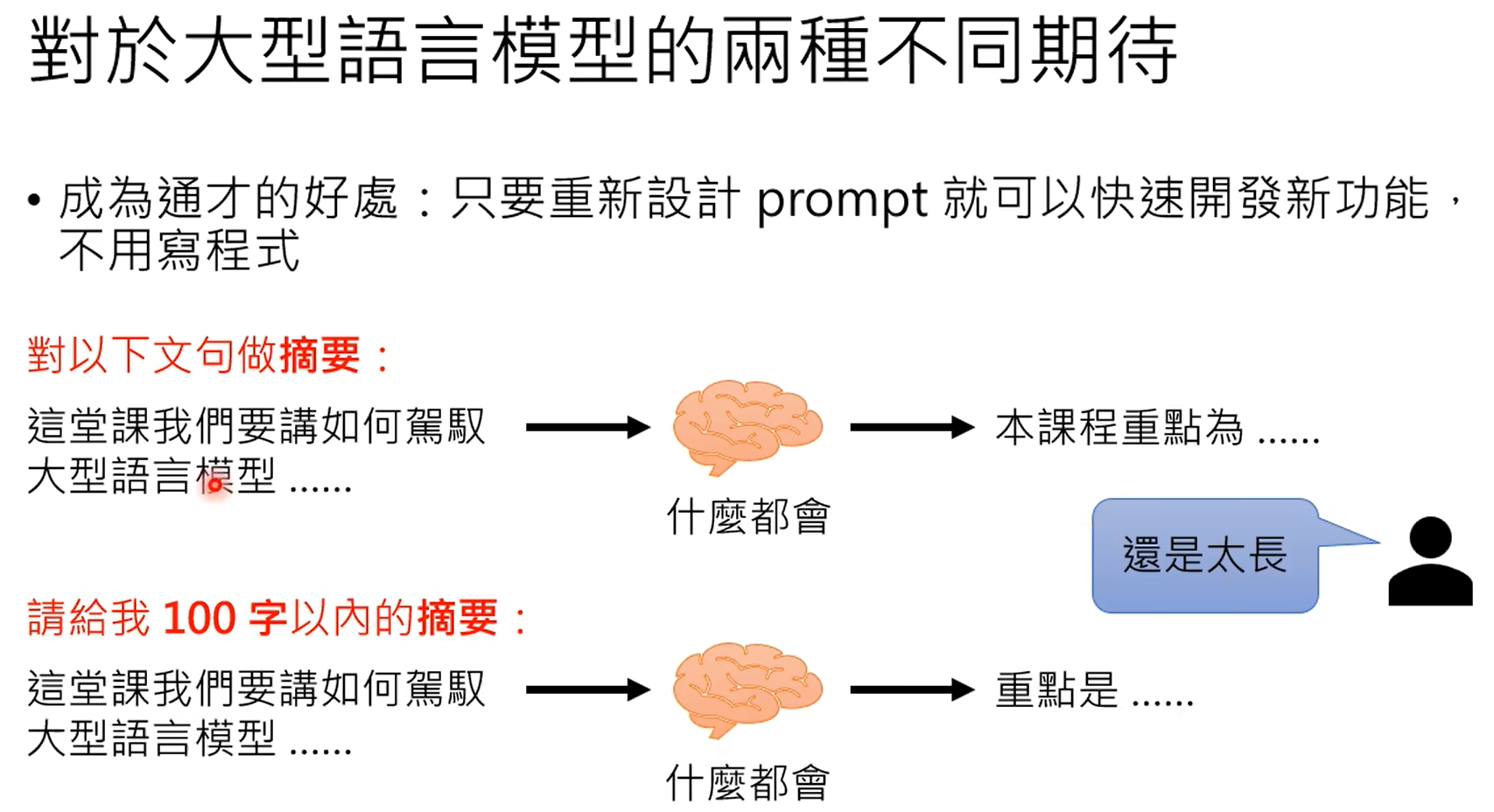
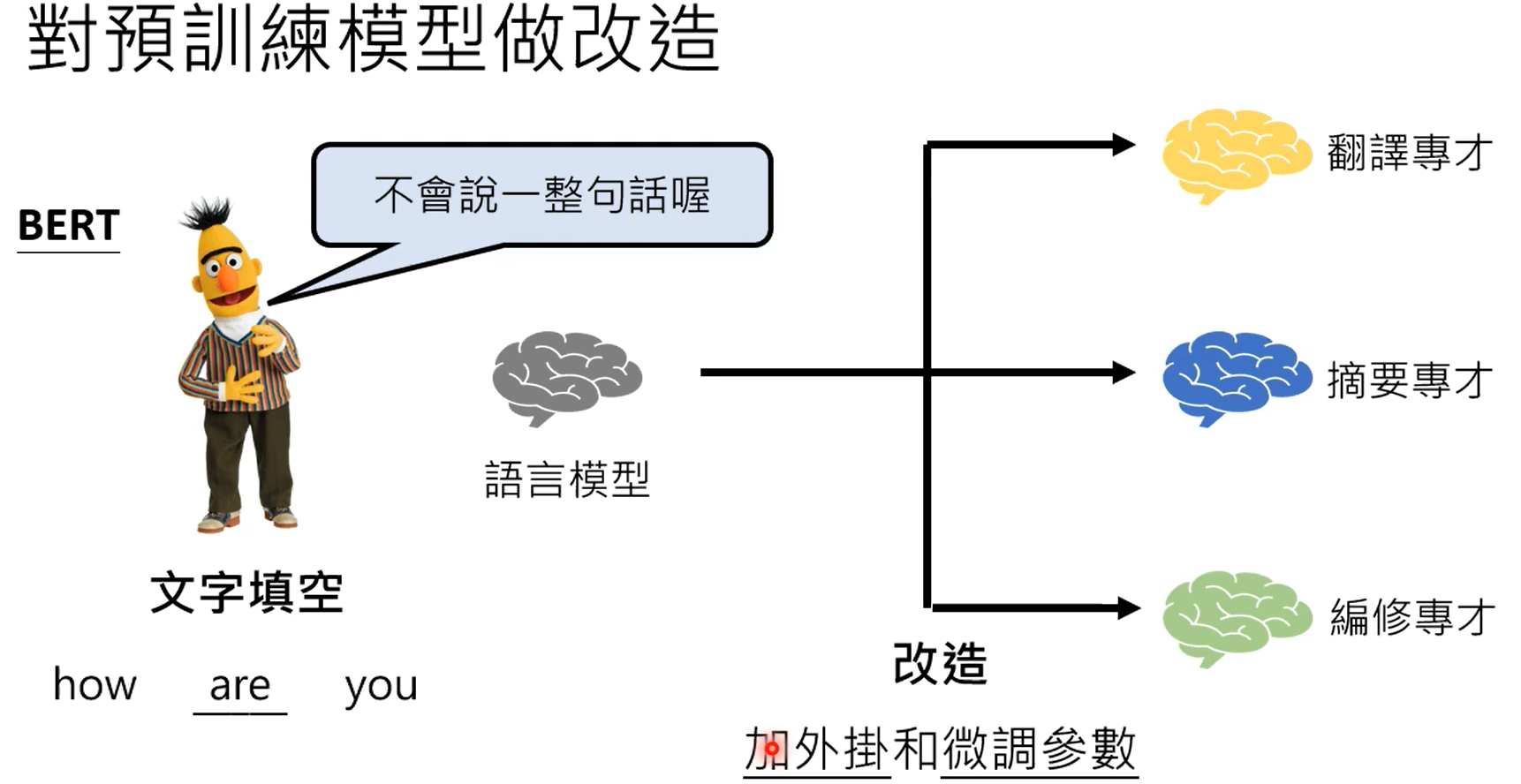
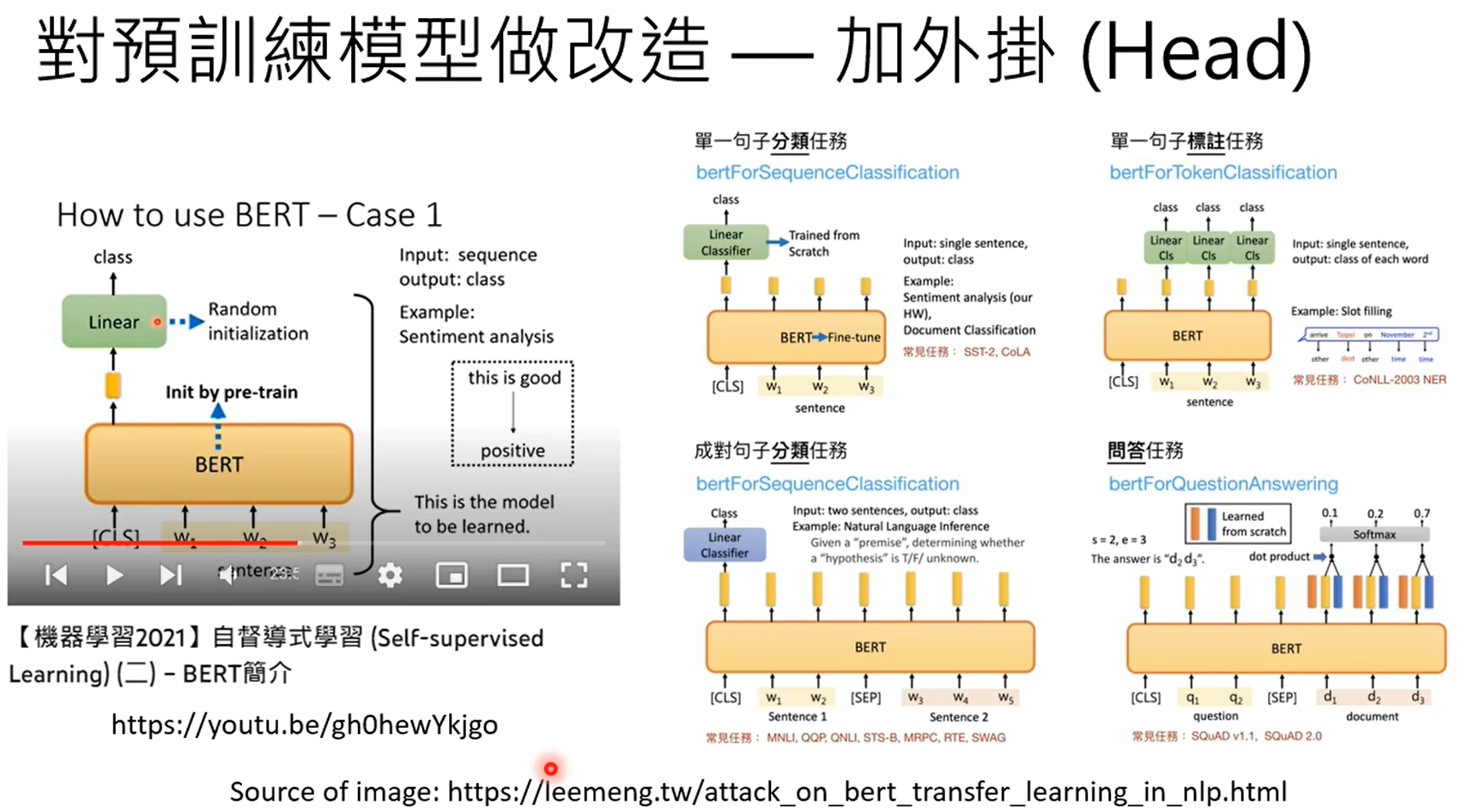

使用预训练的参数作为微调的初始化参数。
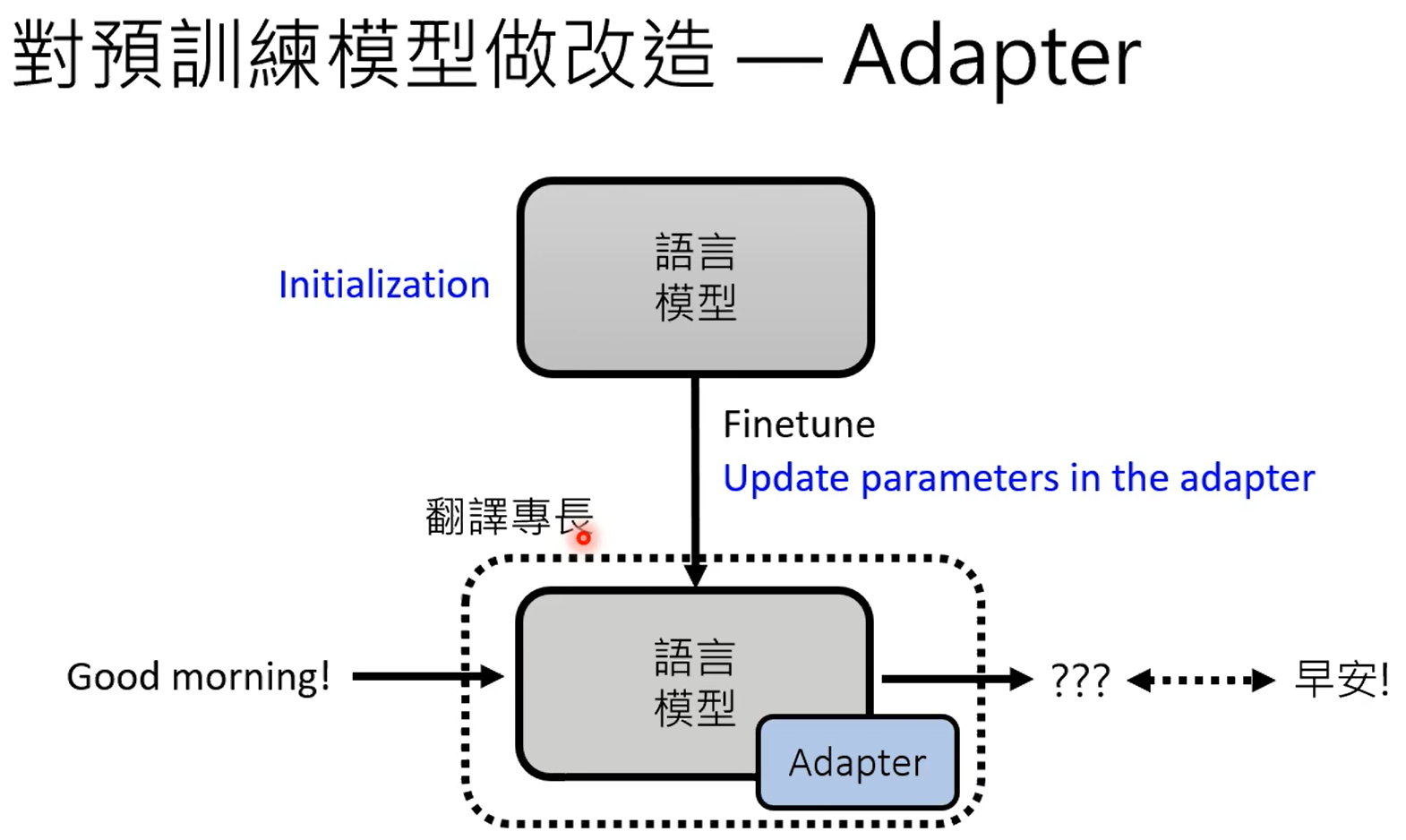
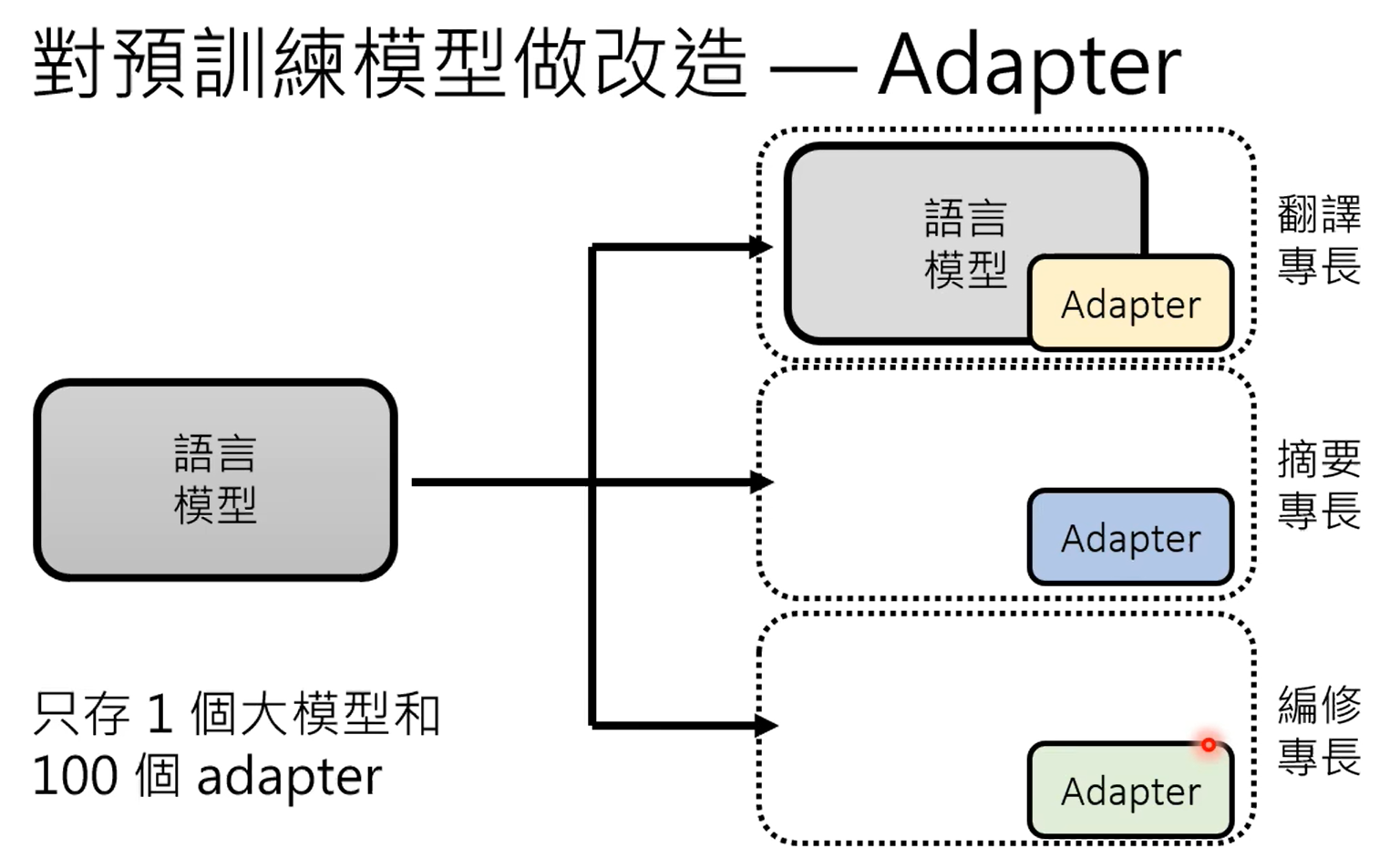
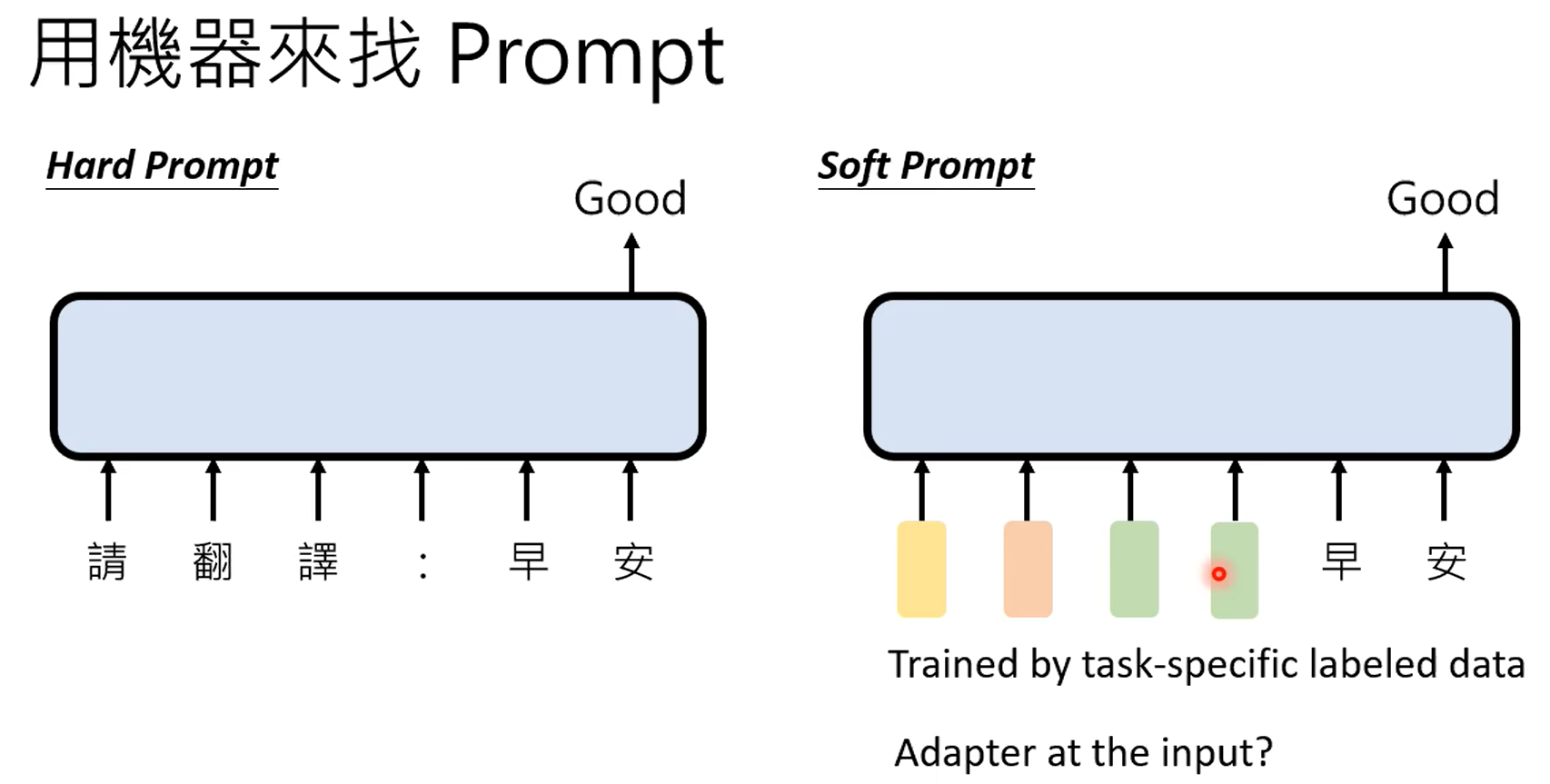
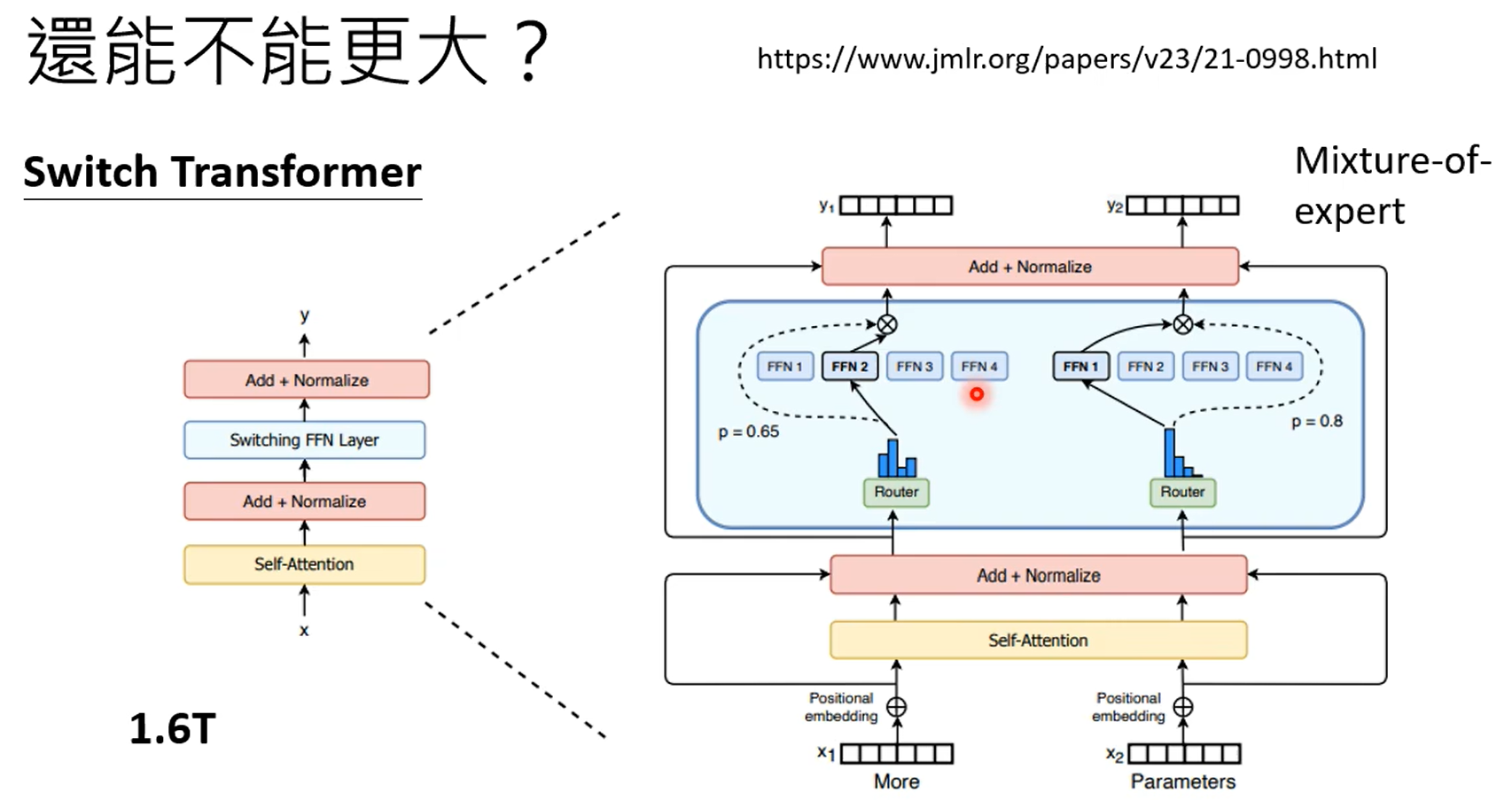
adapter是对模型的参数不动,在模型上加一些层,训练的时候只训练这些层,lora就比较典型。

各式各样的插件可以插在模型的各个层和网络中。




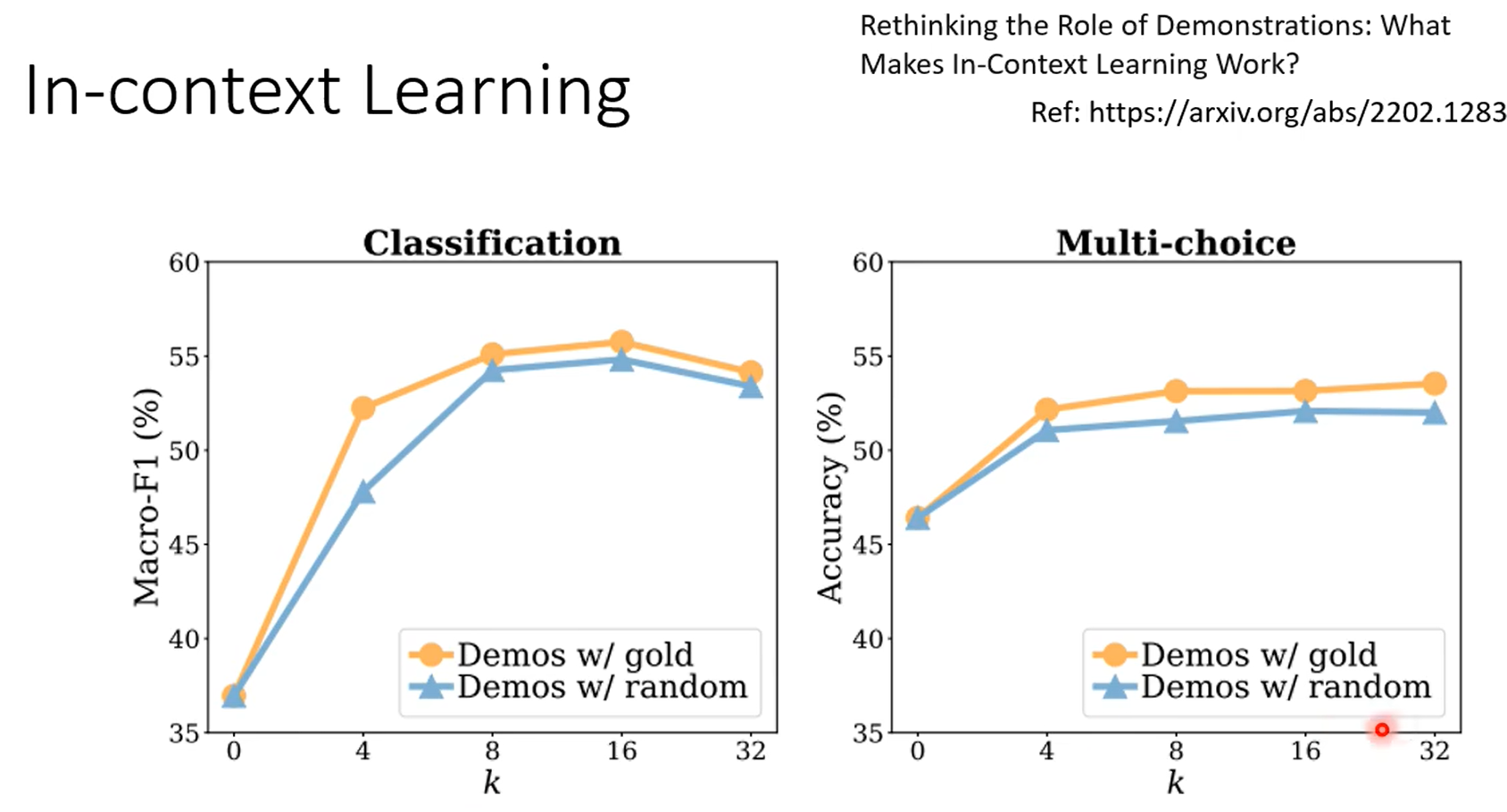
上面两张图是在测试语言模型是否真的有判断能力,蓝色是没有输入prompts,橙色是输入了正确的prompts,红色是输入错误的prompts,但是红色输入错误的promots,模型的输出并没有错很多。

给模型输入一些不相关的prompt,看模型的输出,橙色给的正确答案,红色是错误答案,紫色是无关答案,蓝色没给prompt,给机器的promot很重要,prompt其实就是提示它做什么任务。
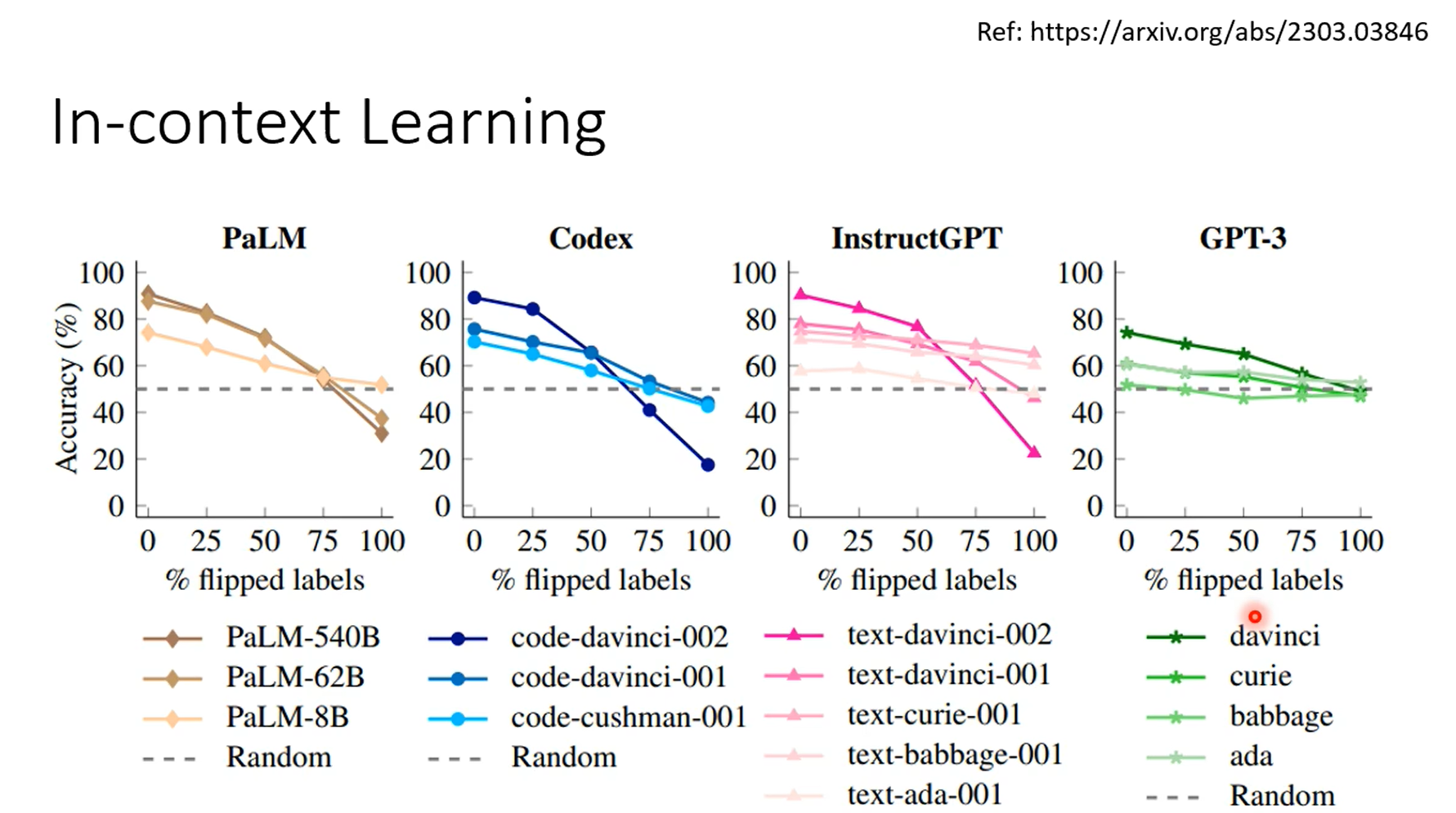
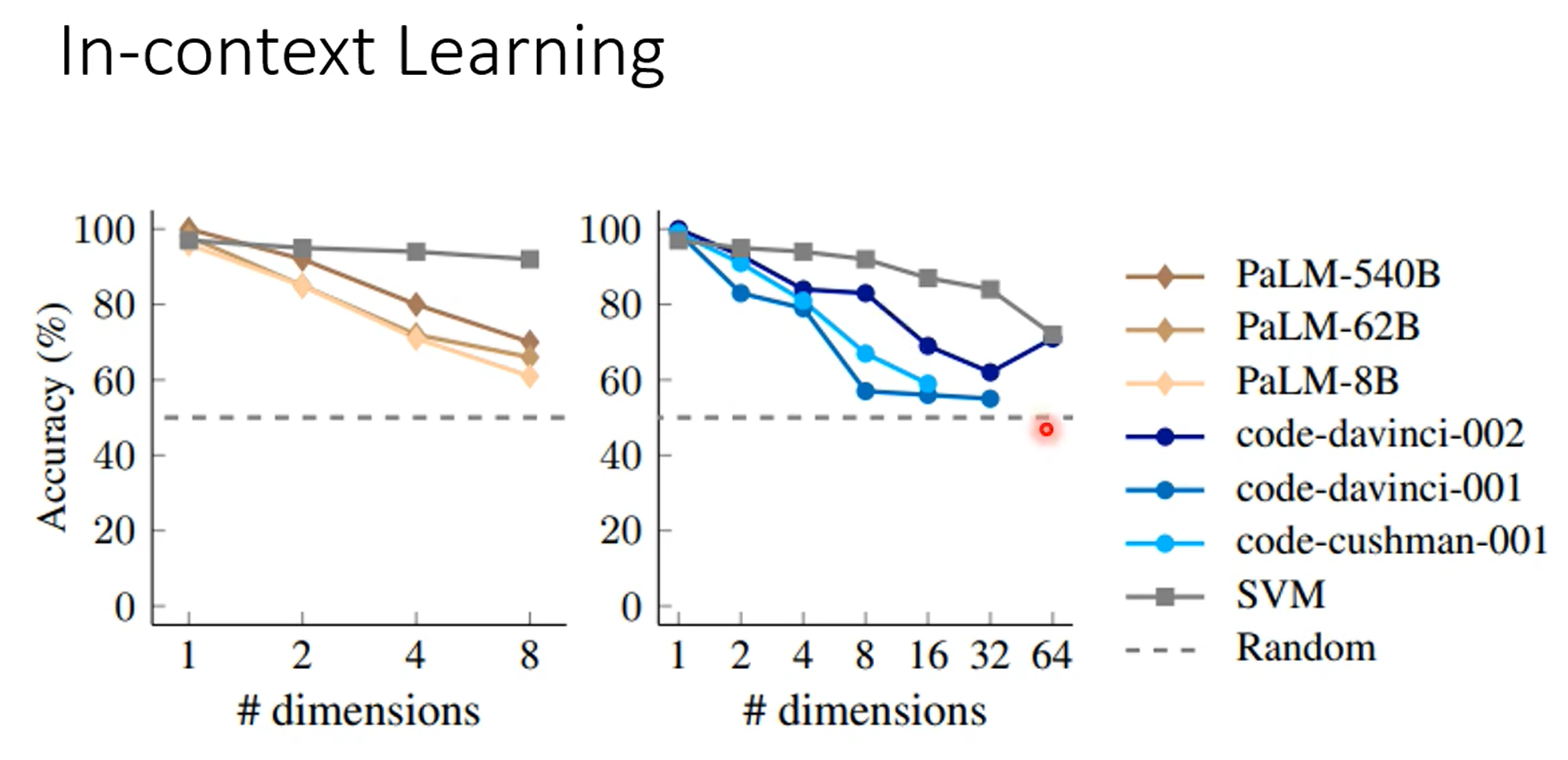
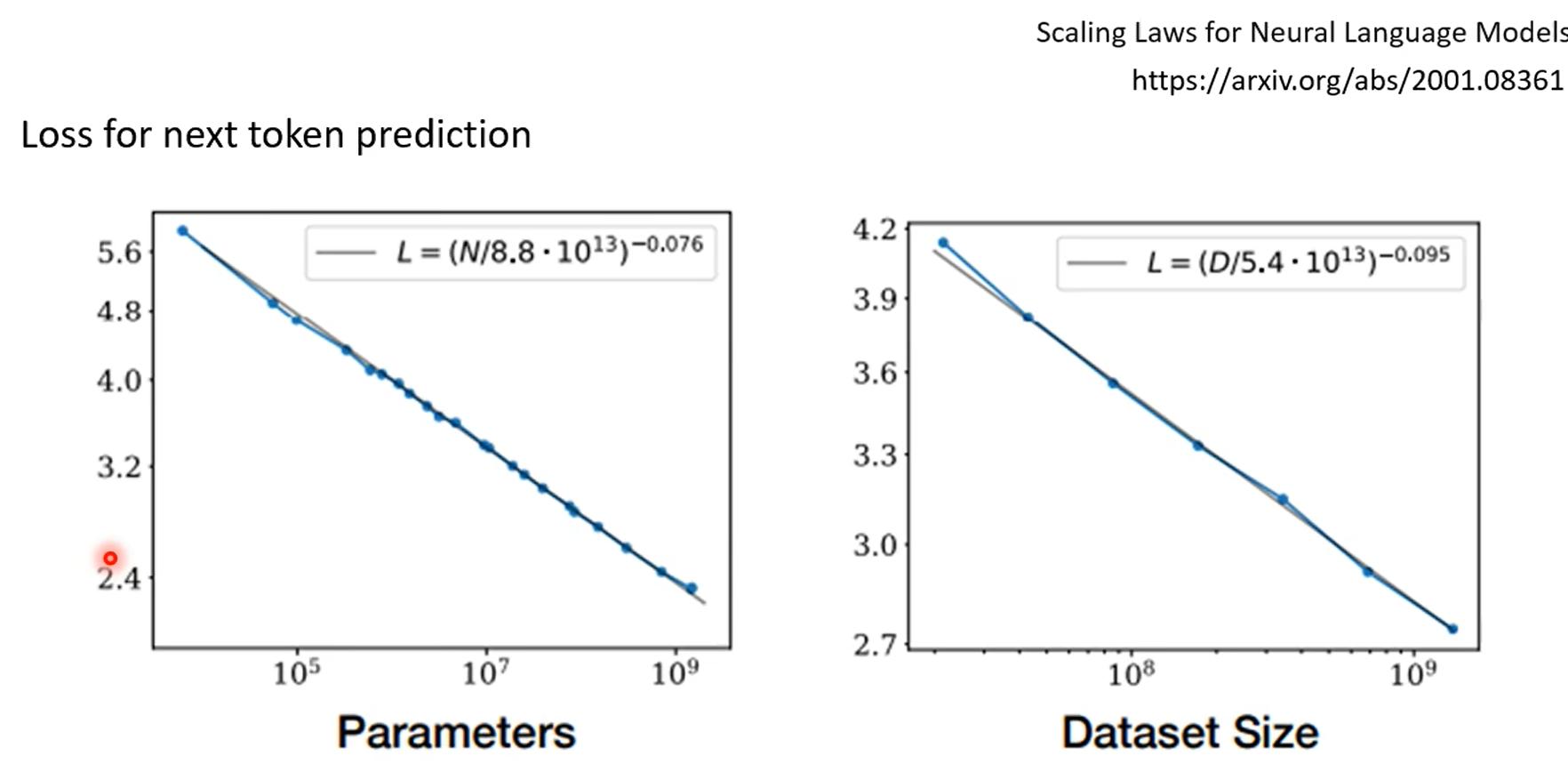
模型越大,从context中学习到的能力越强,颜色越深,打乱label之后学习能力改变越明显,甚至给错误的答案他能反着学。


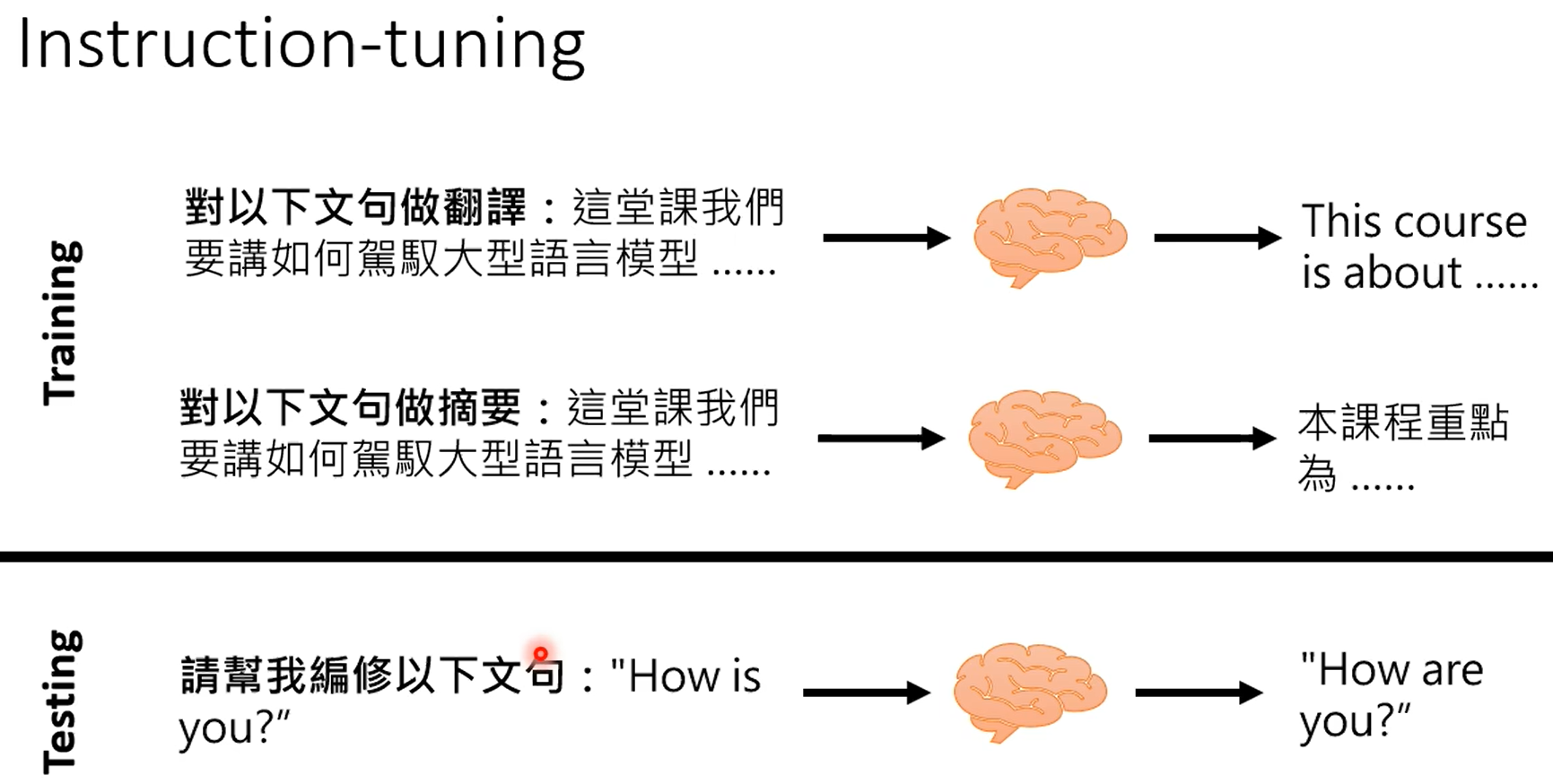
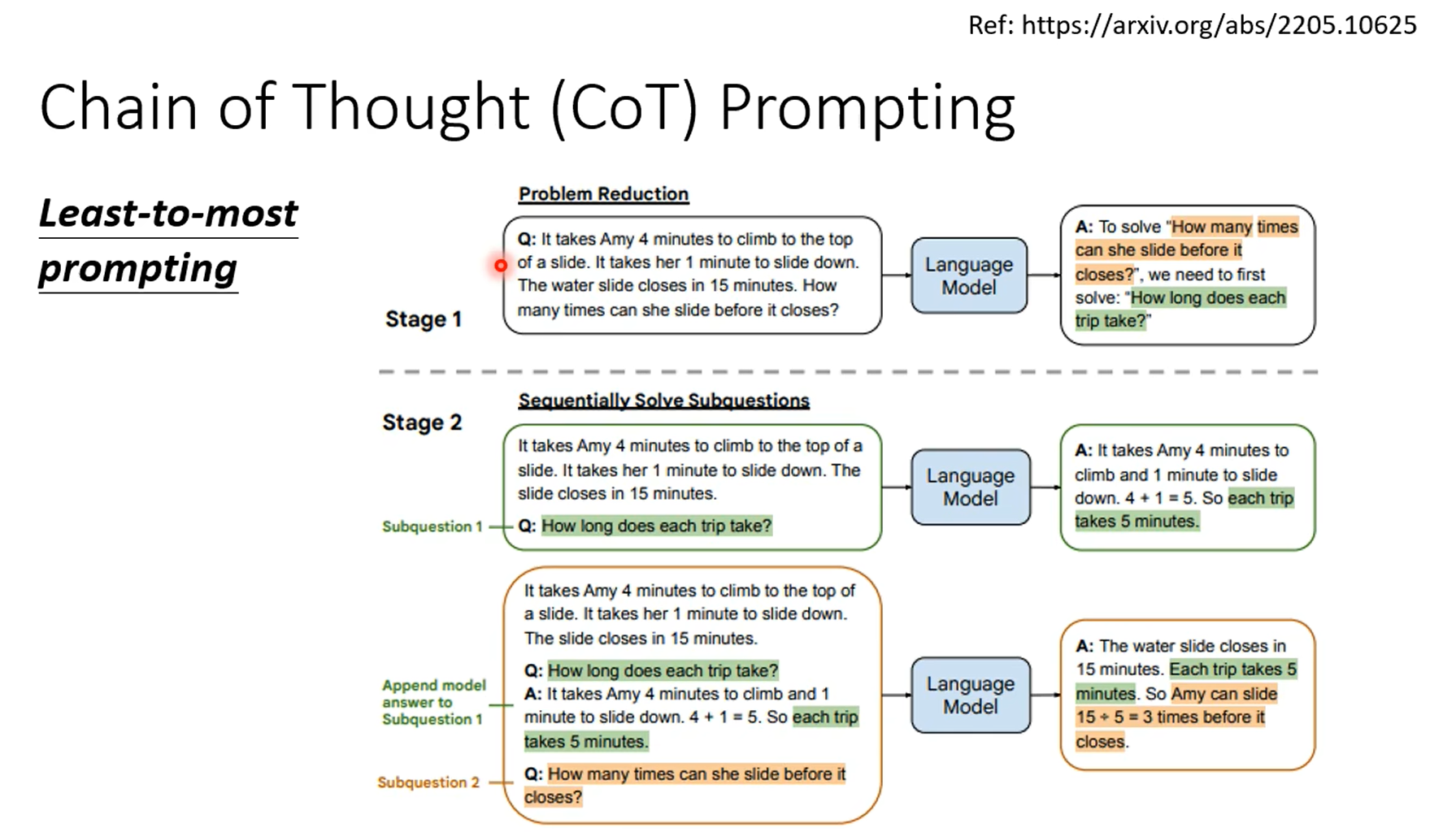
上面是通过范例来学习,下面是通过题目来学习。 


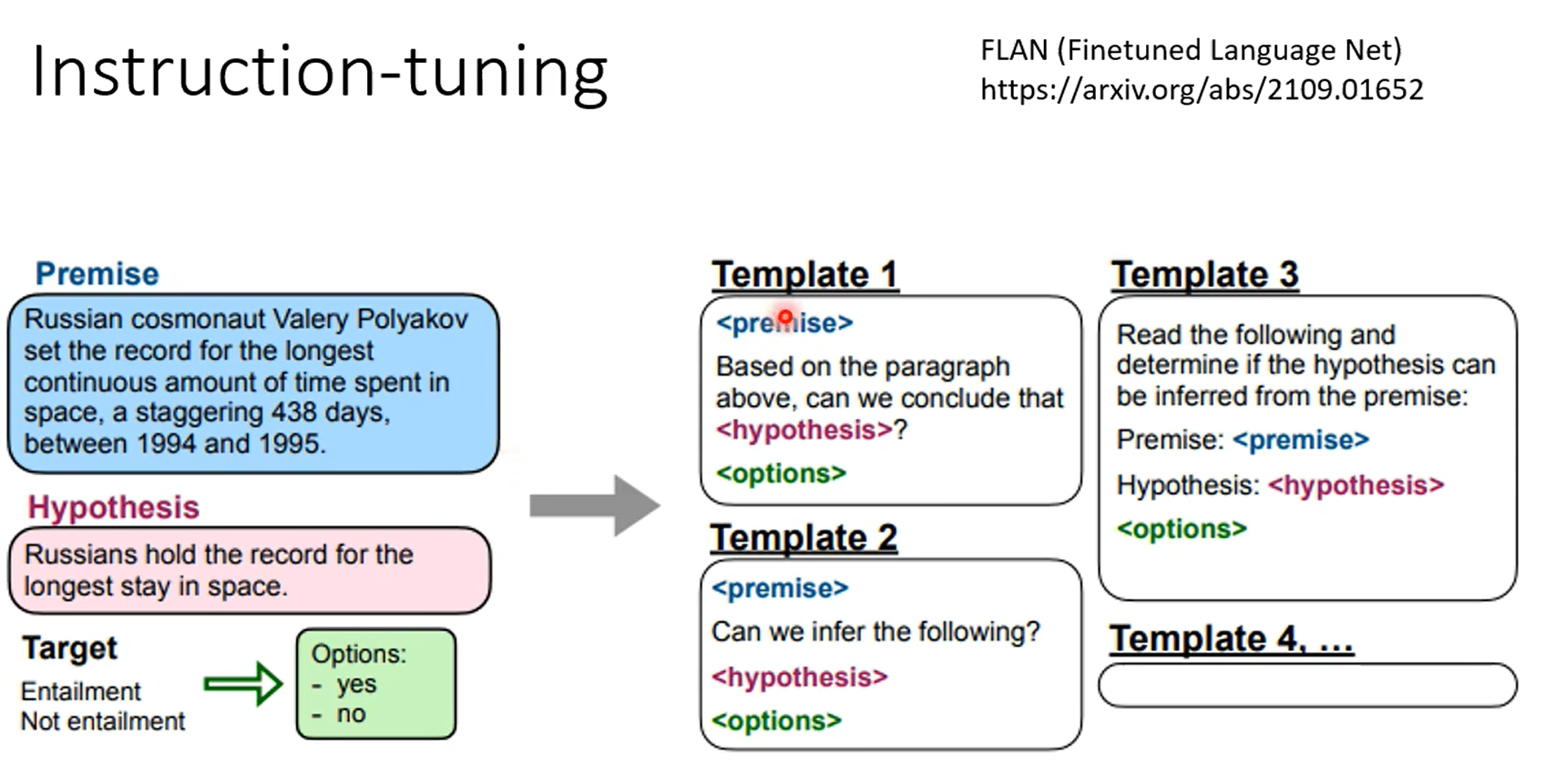


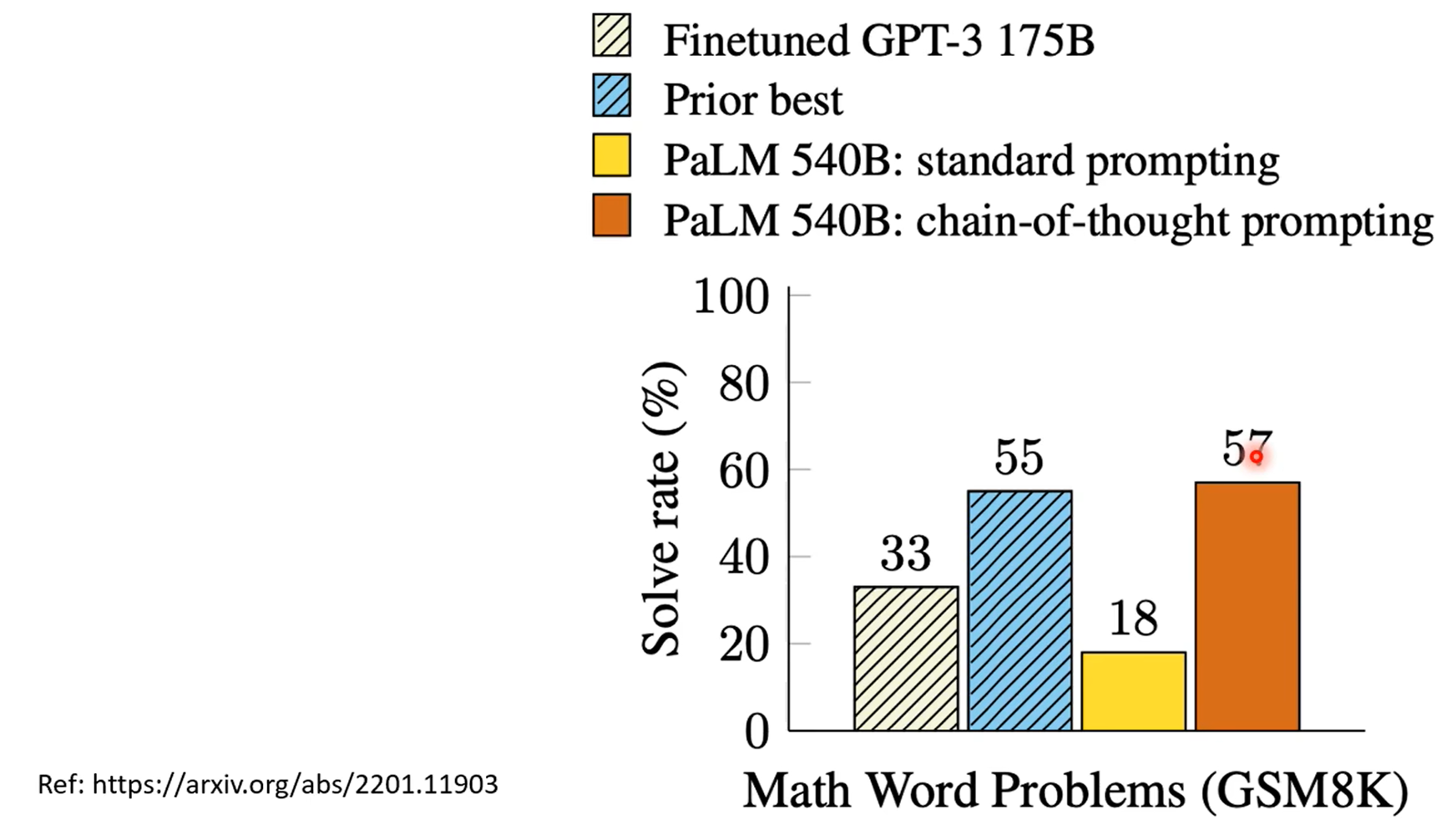

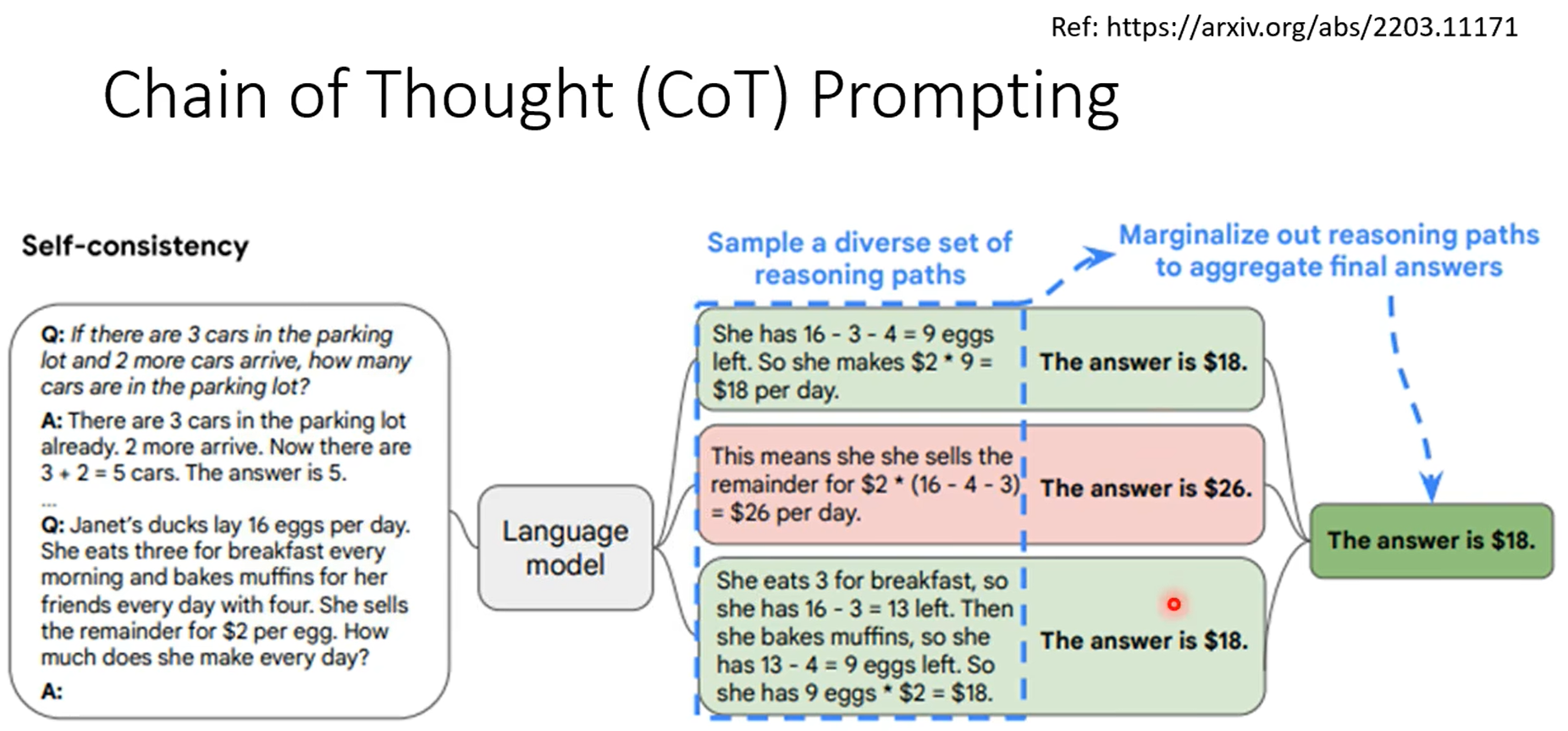
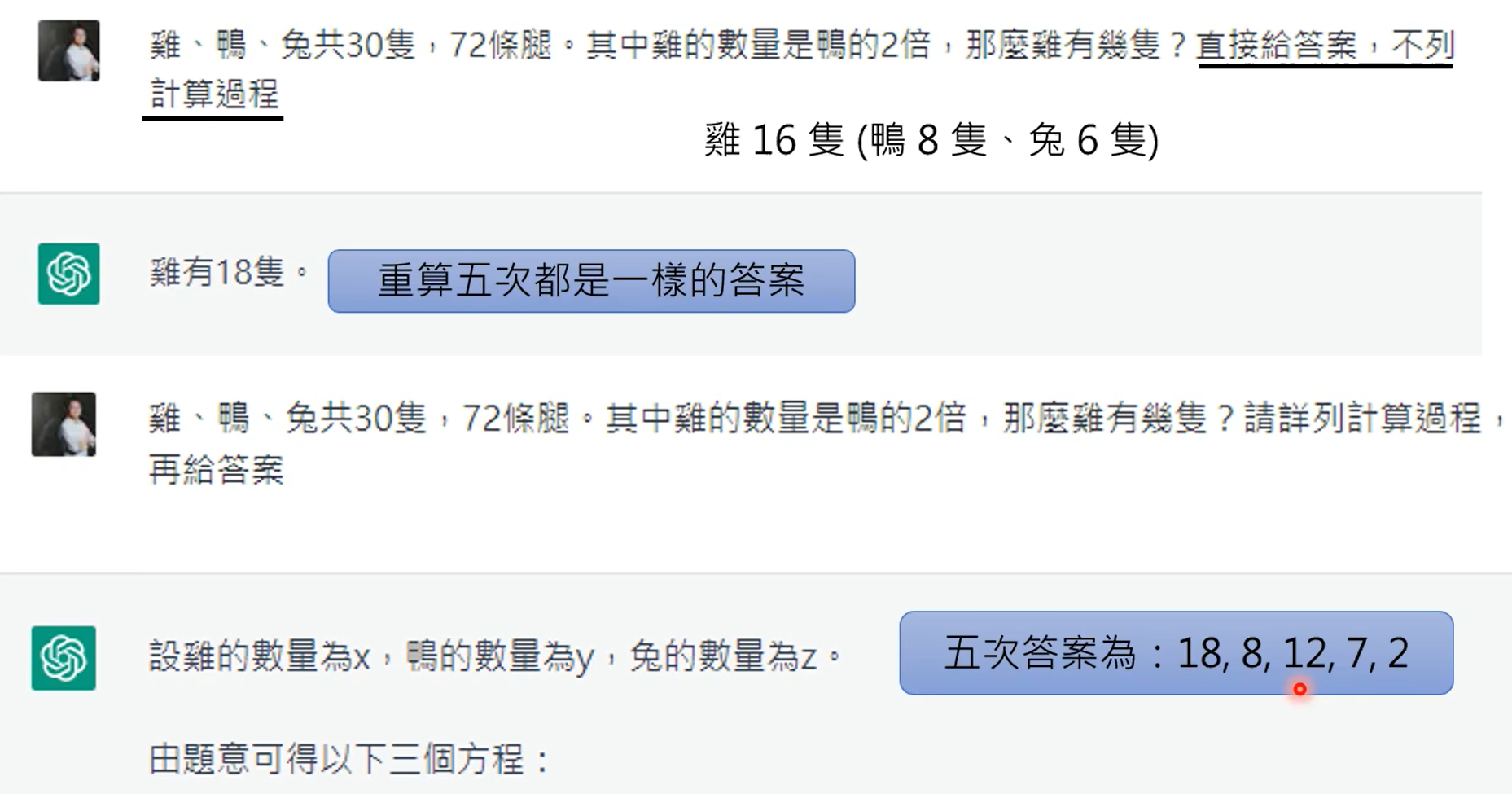
不让他用cot,没错,可以计算平均值,但是chatgpt在解方程时容易出错。




emergent ability:顿悟时刻

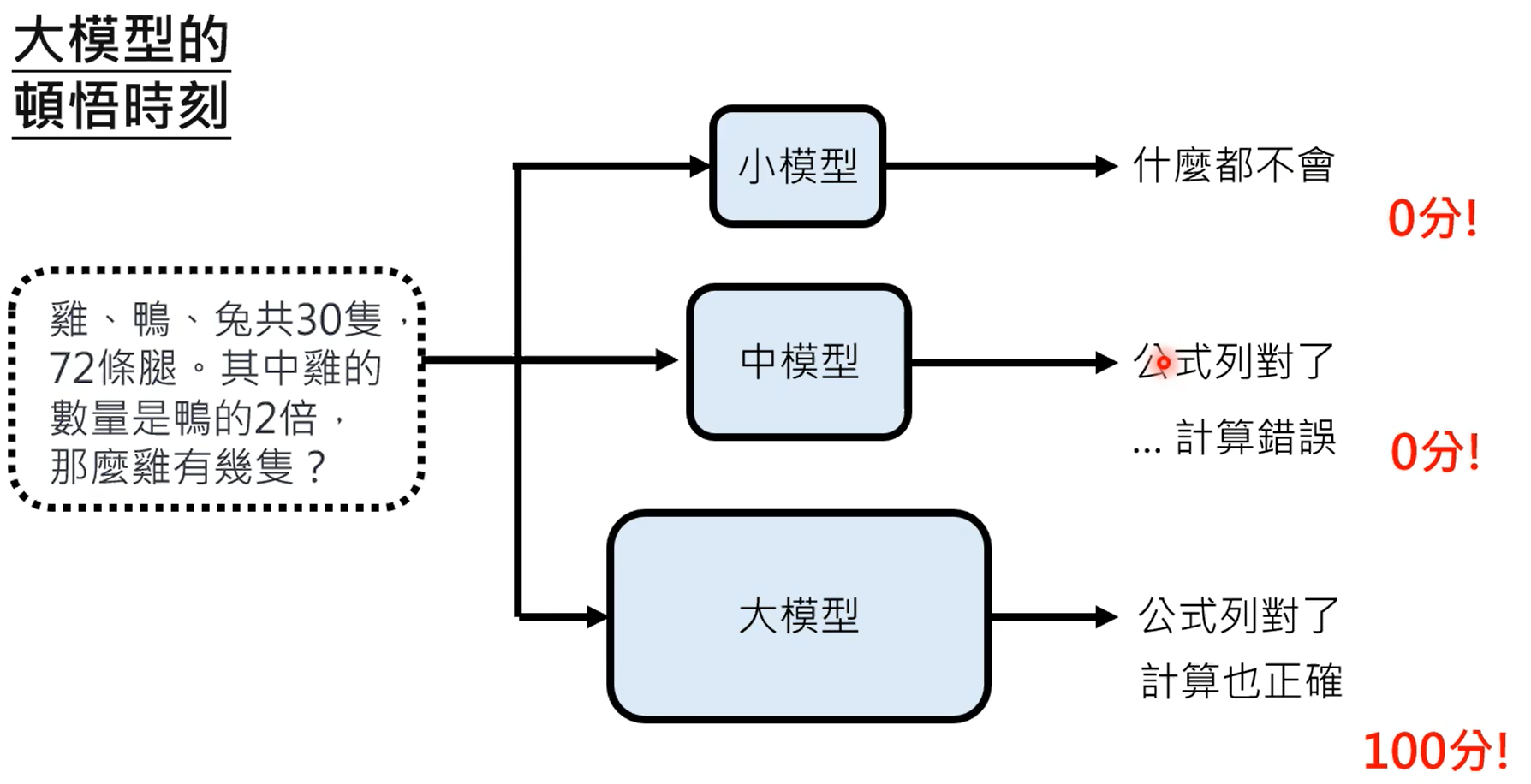

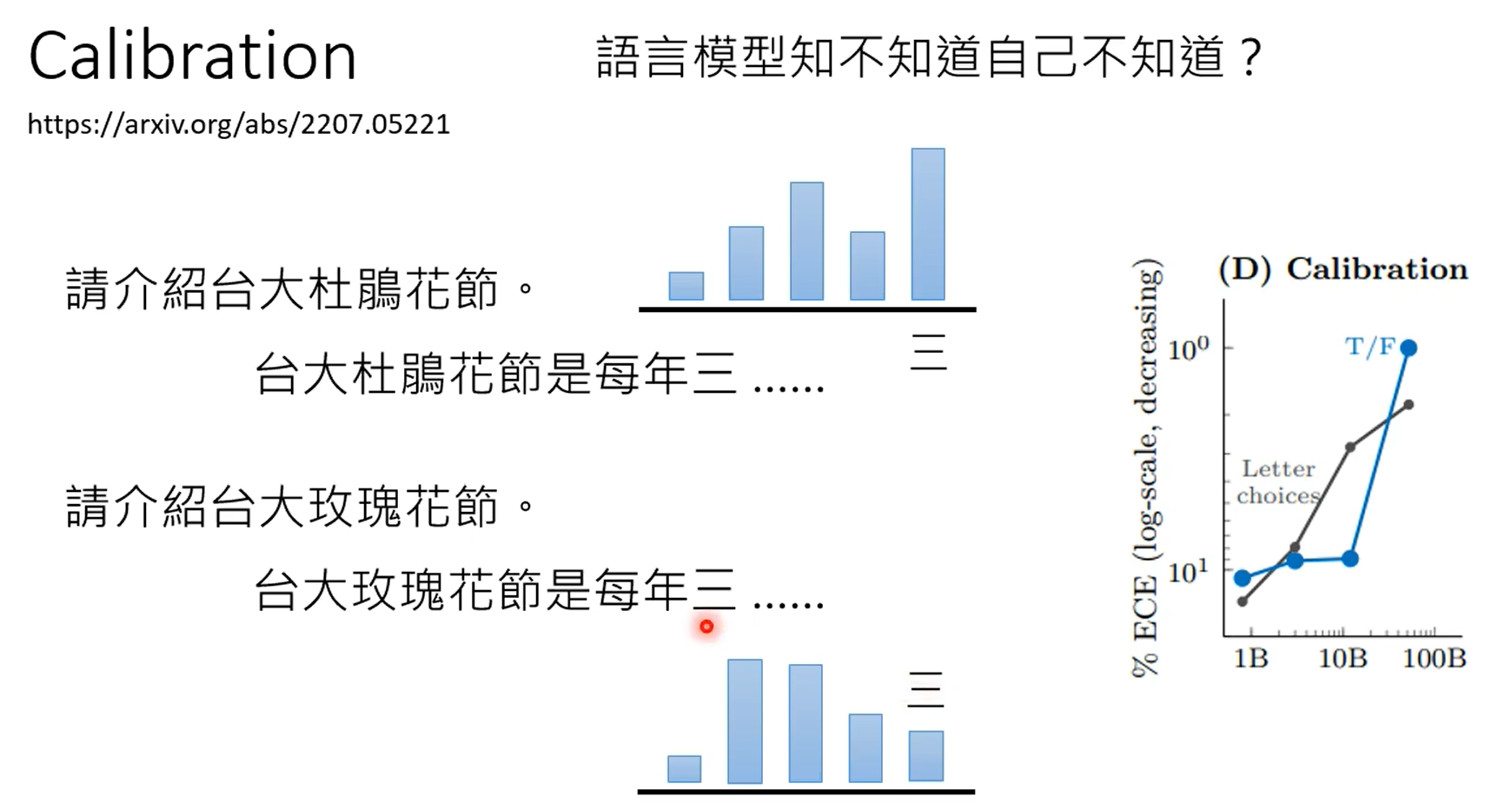

大模型在瞎说时,通过输出字的calibration是可以知道的。


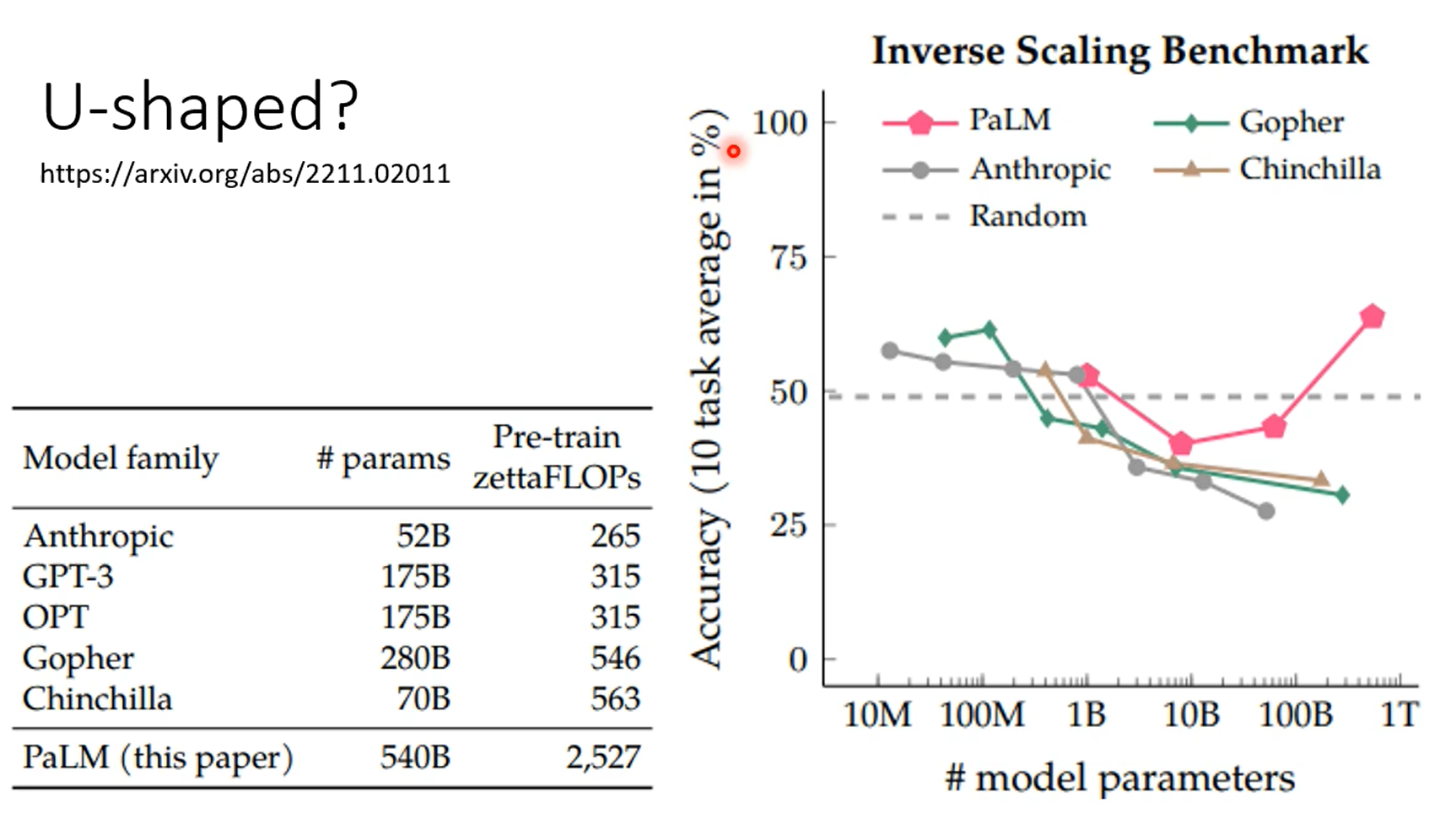


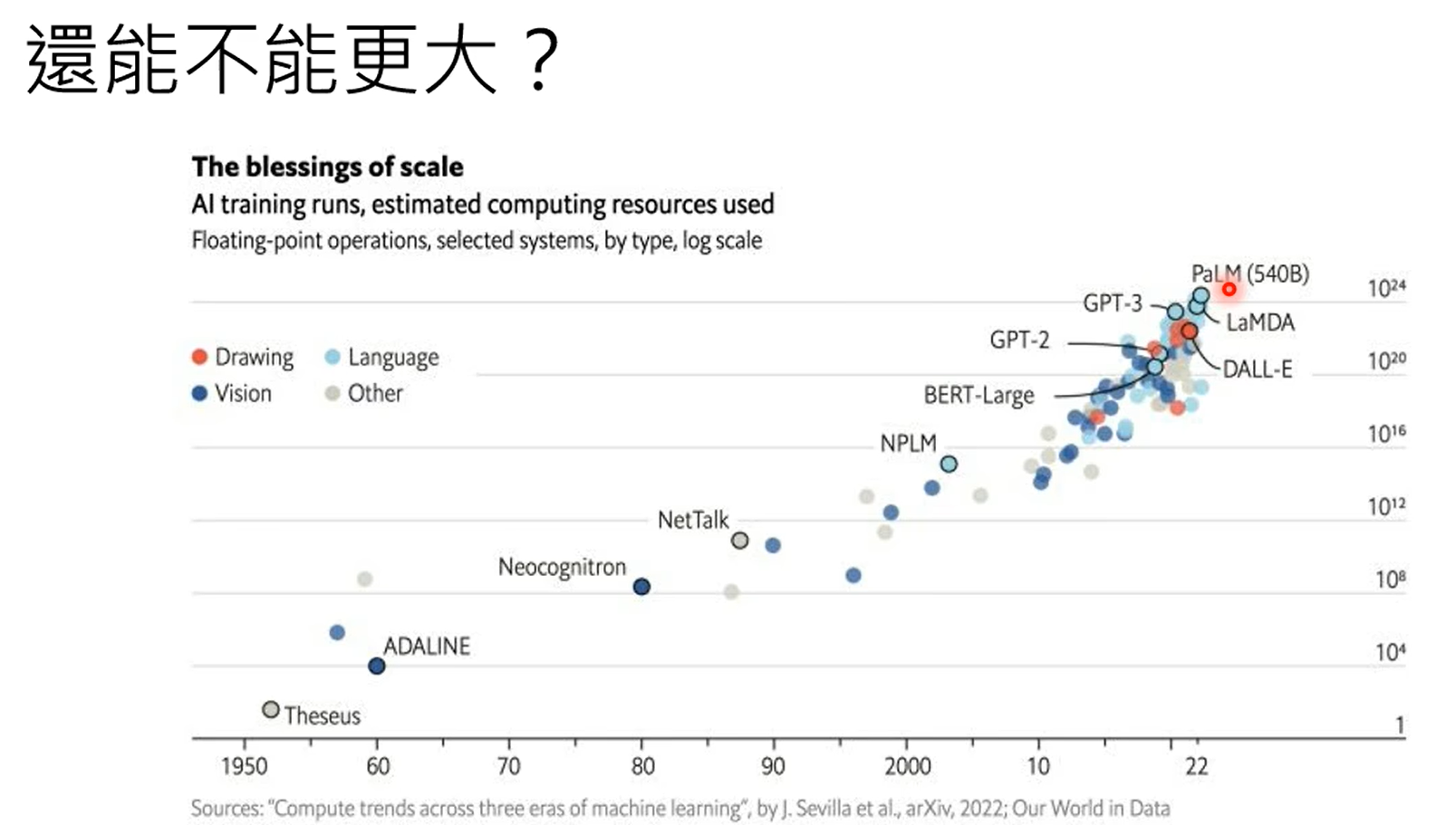




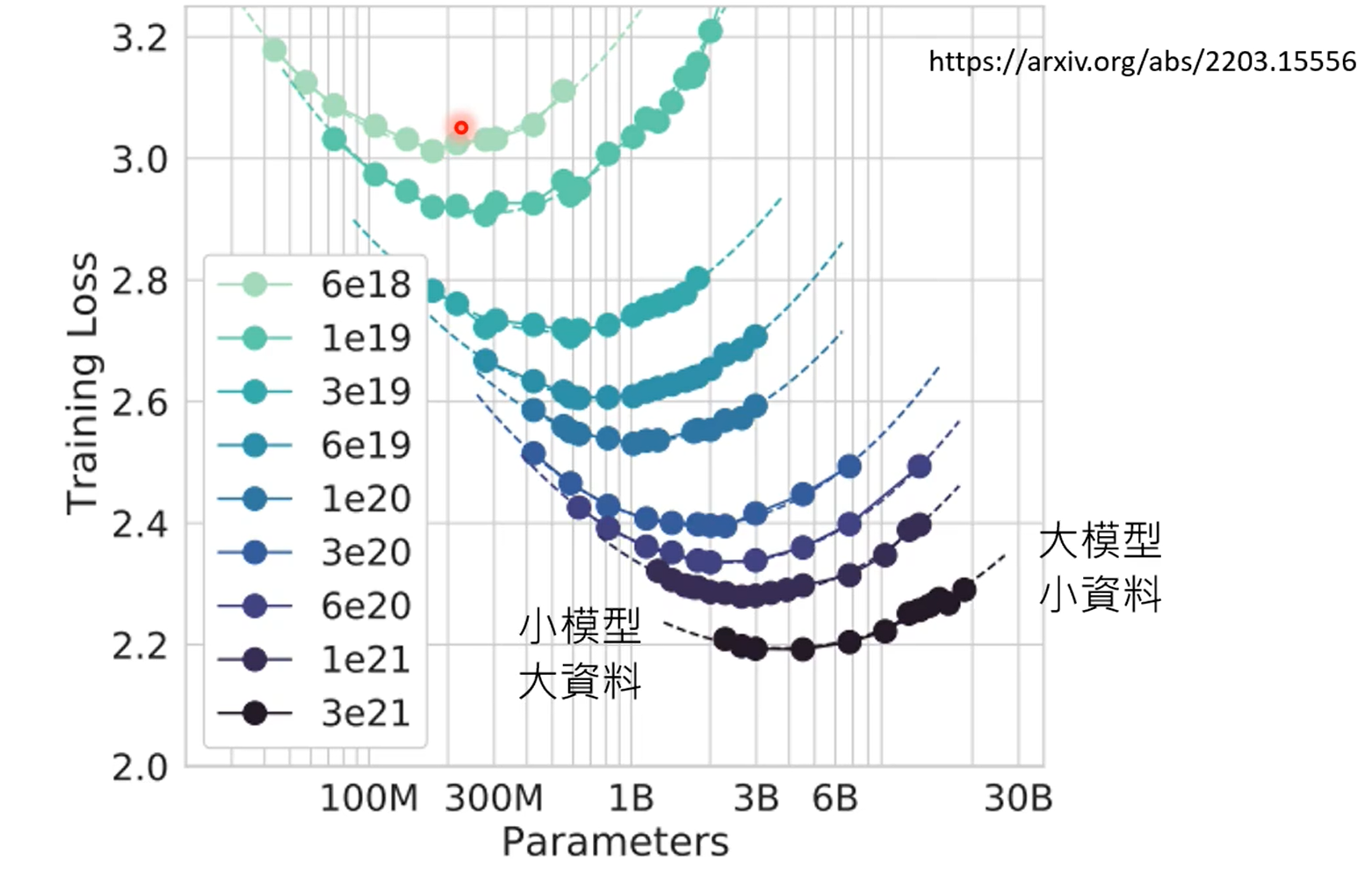
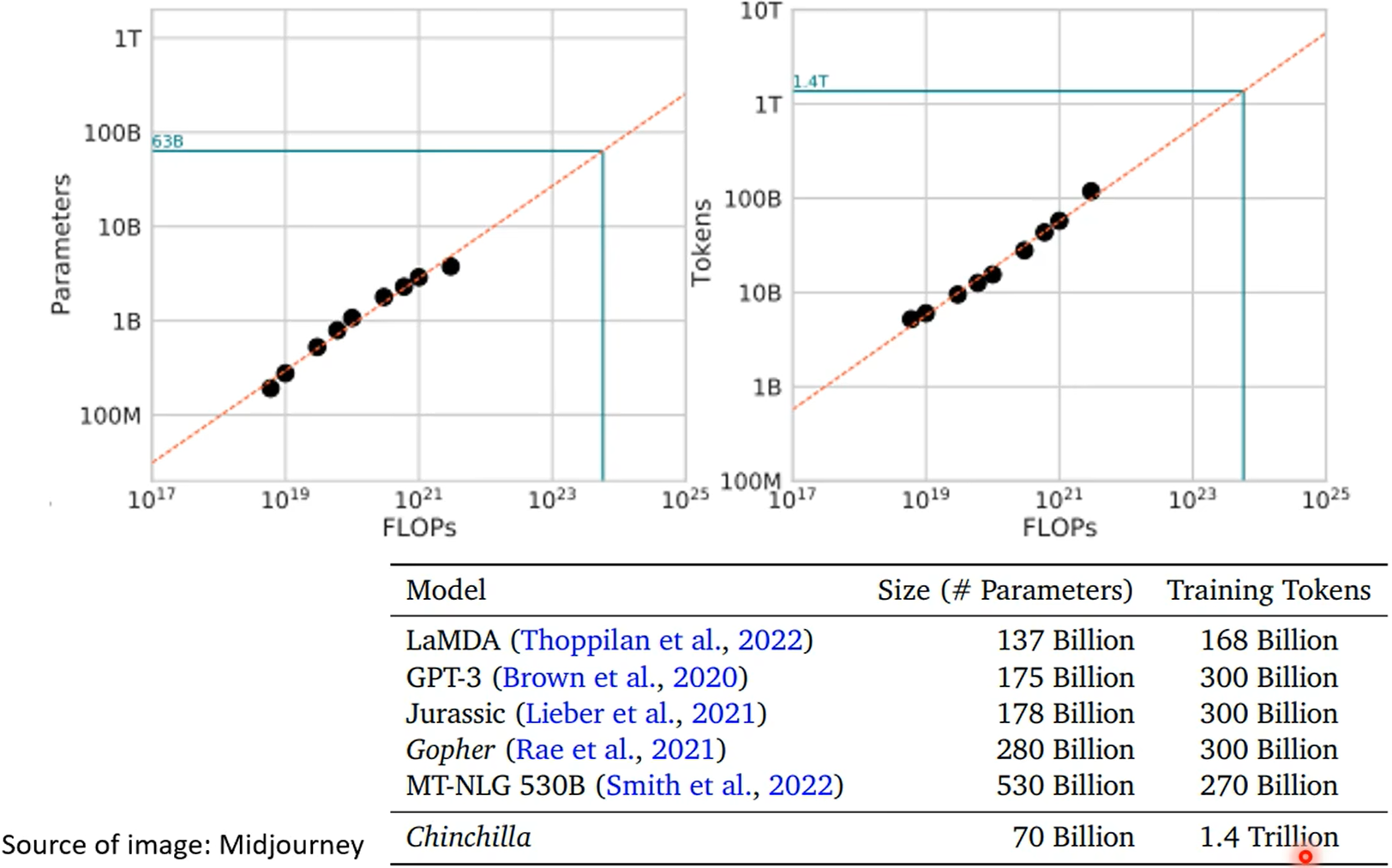
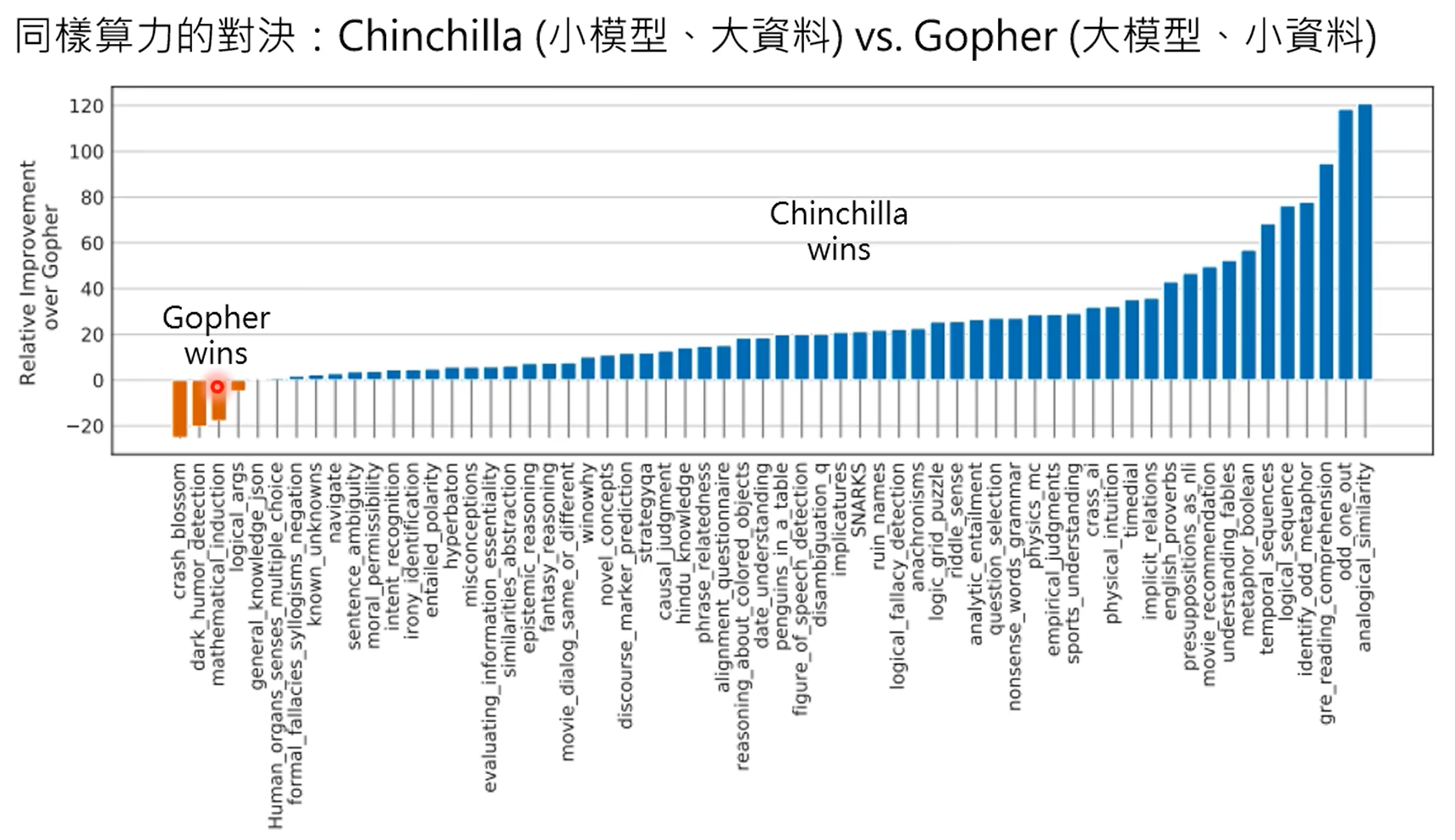
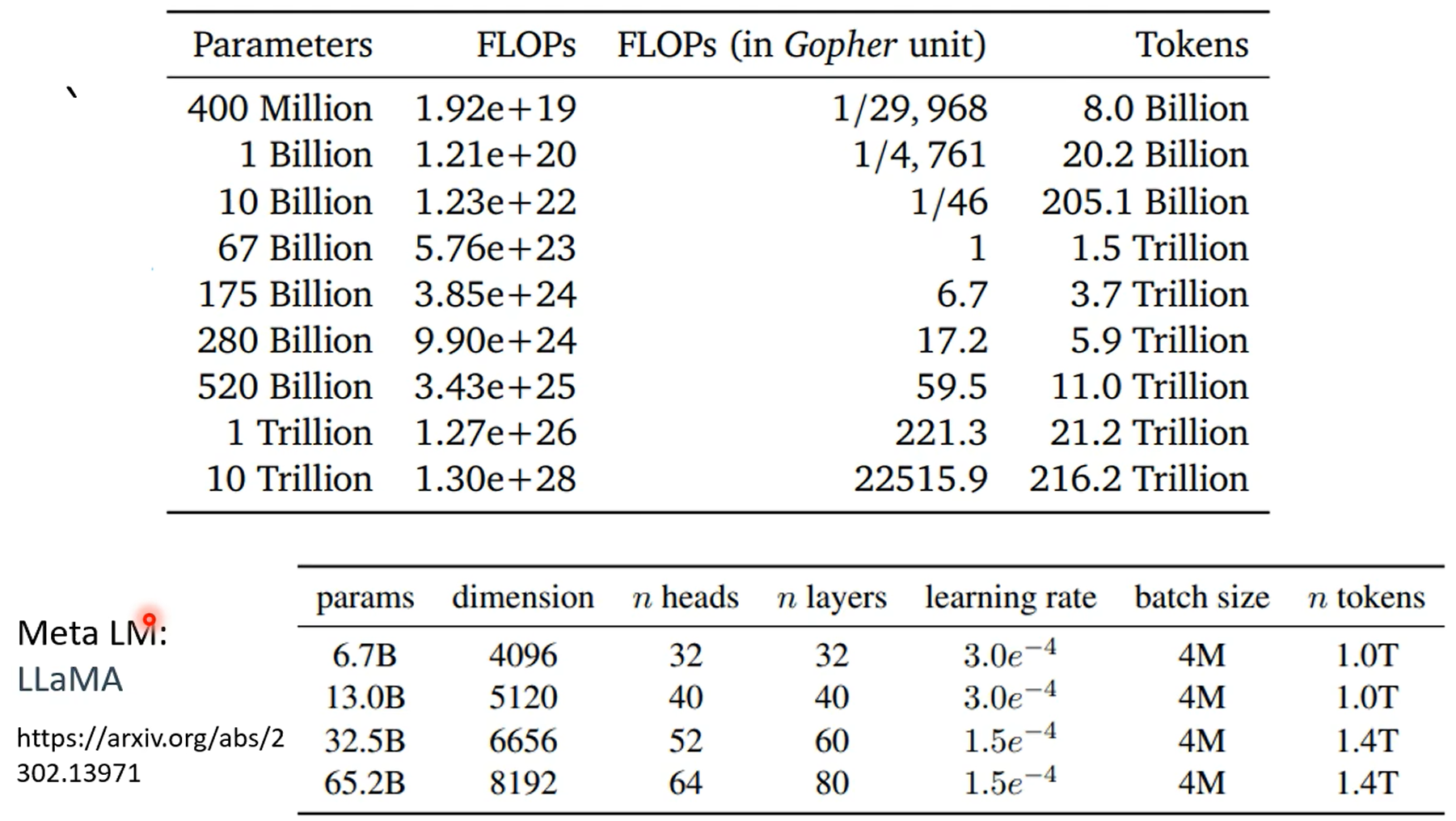

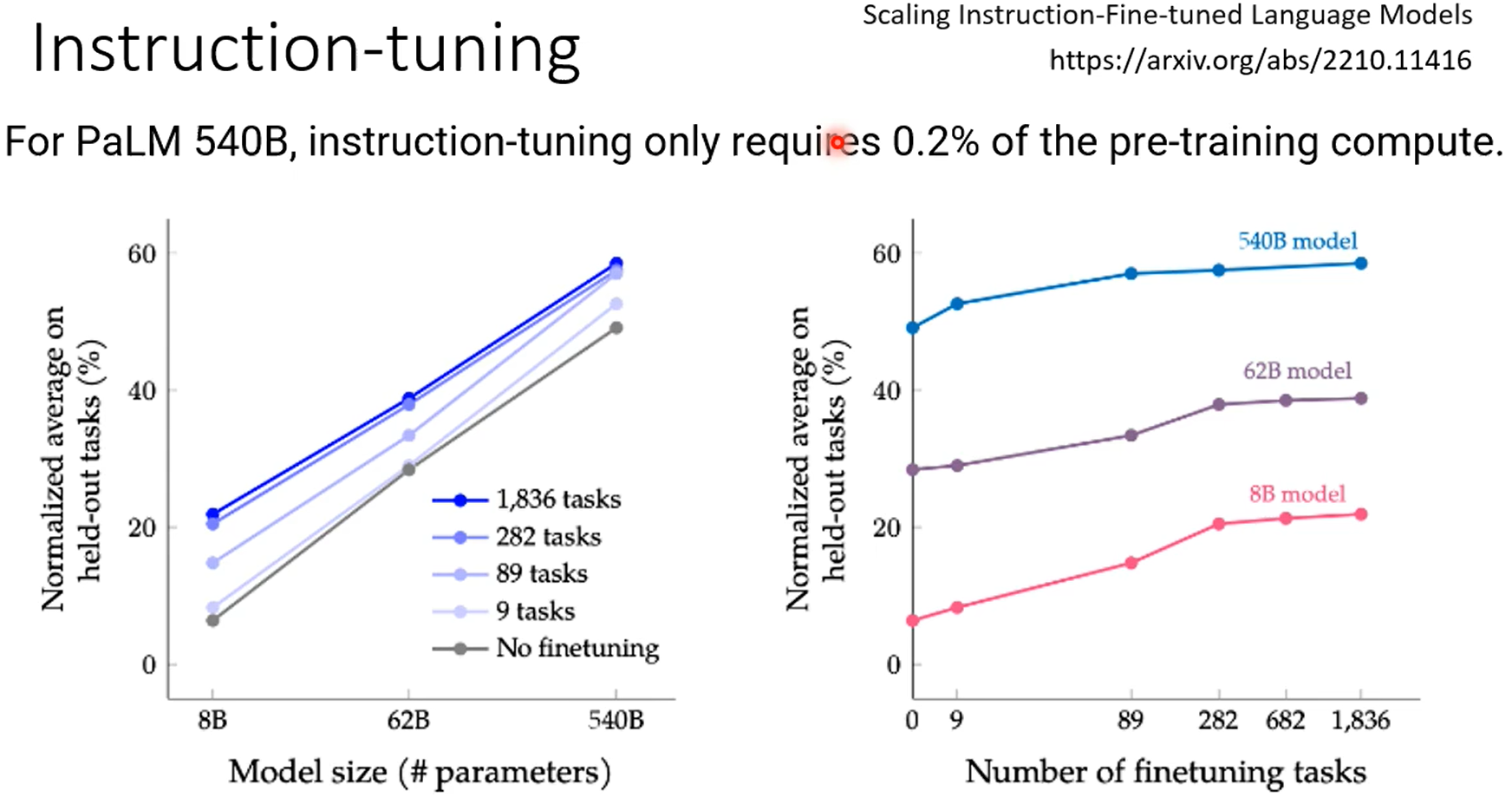







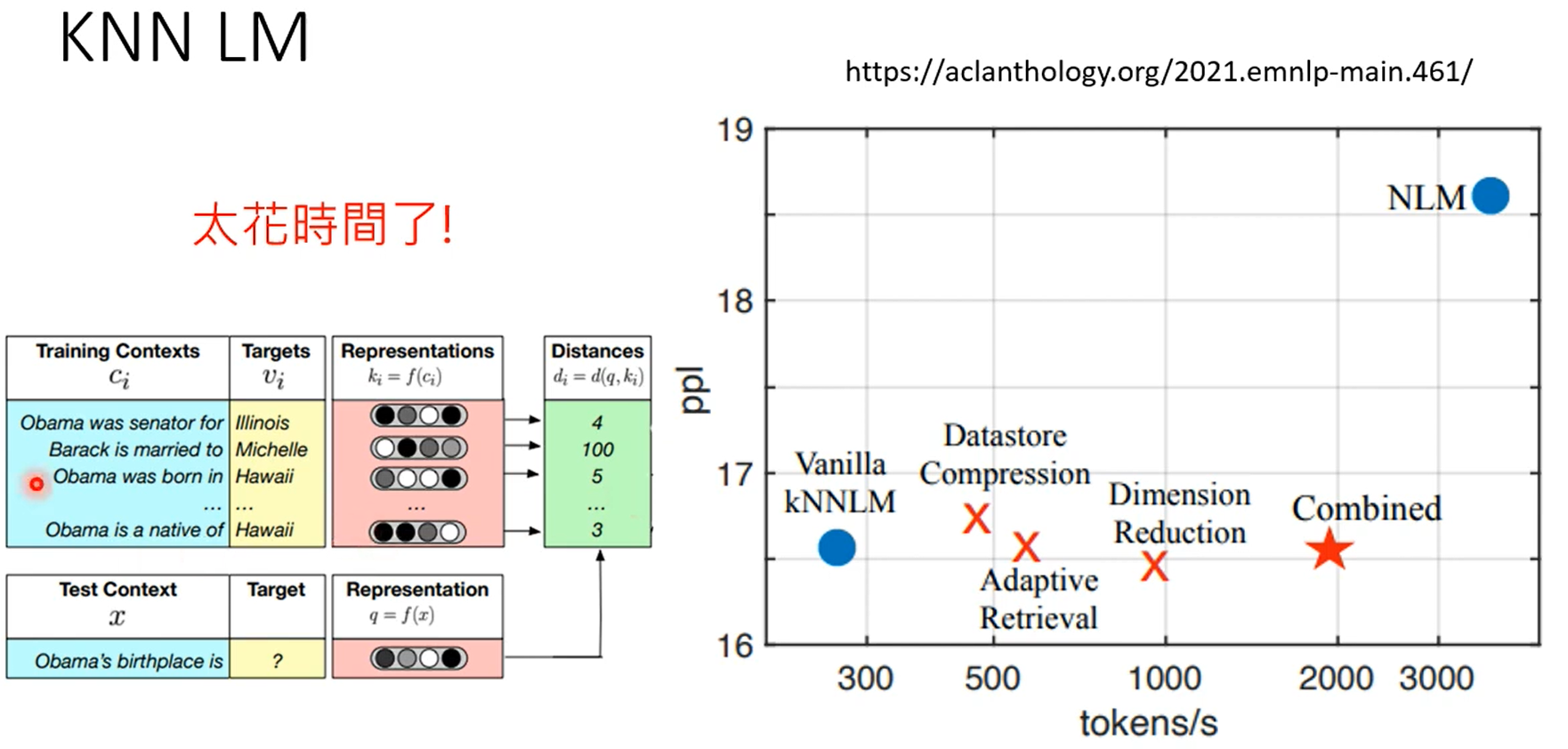
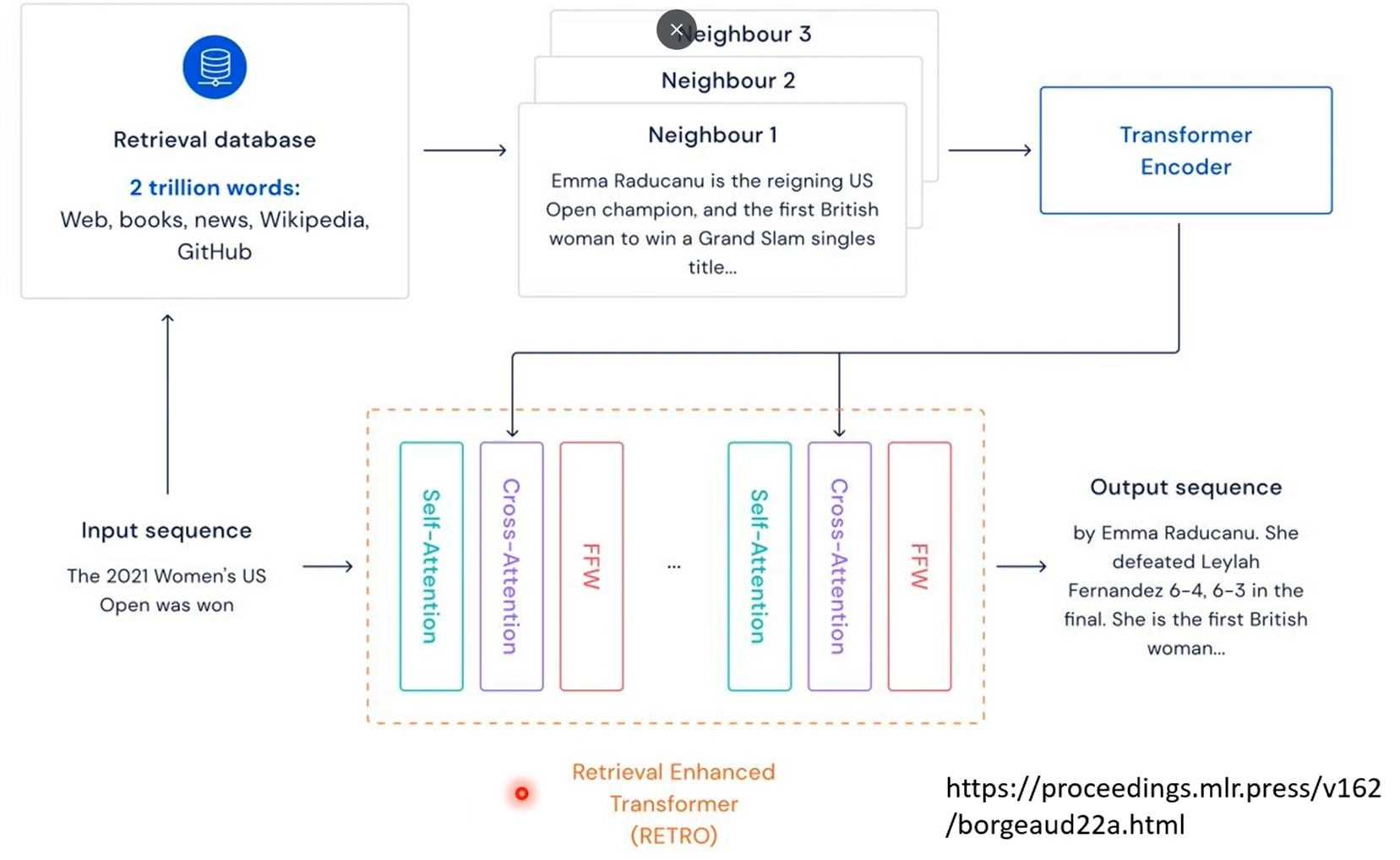



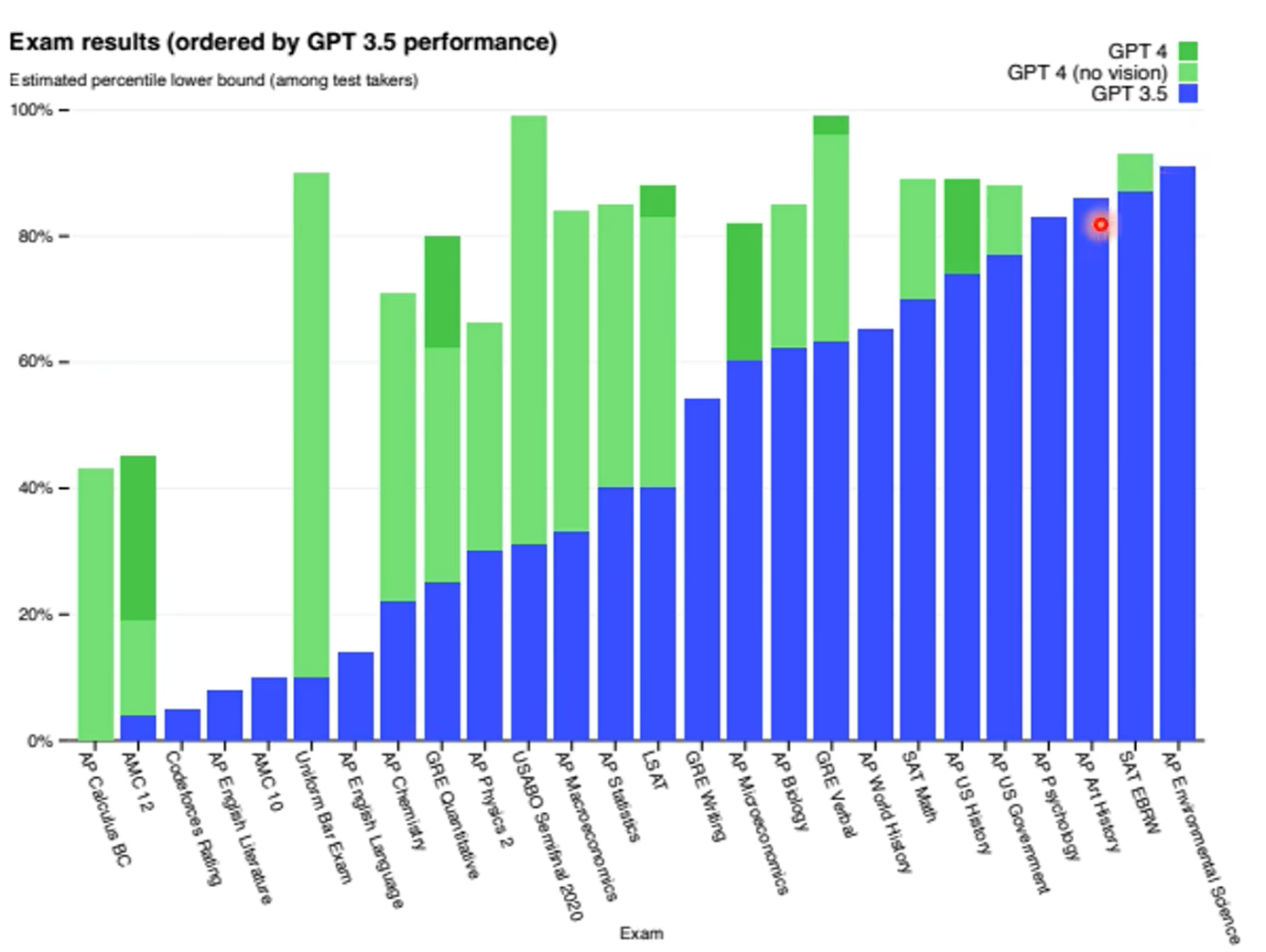
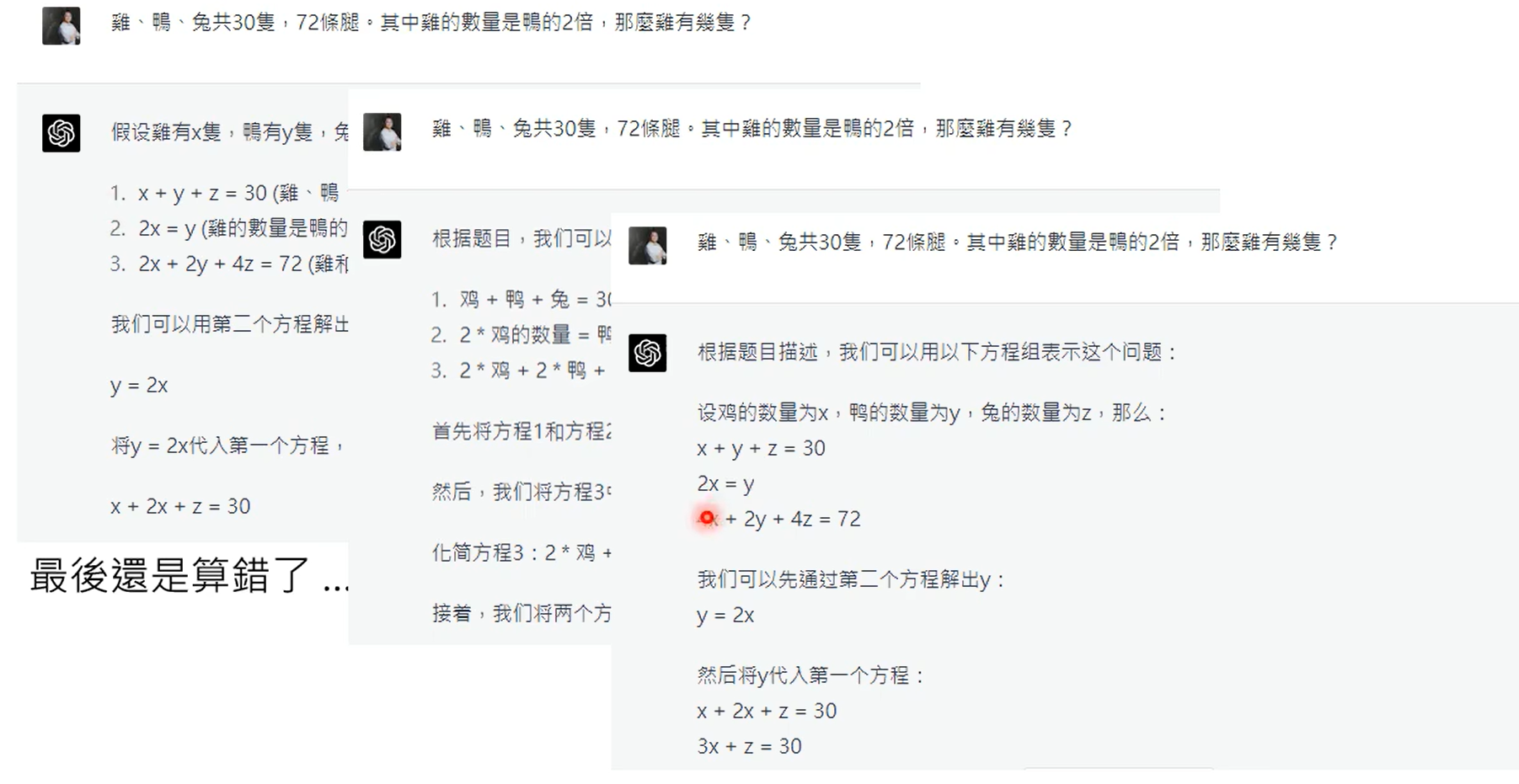
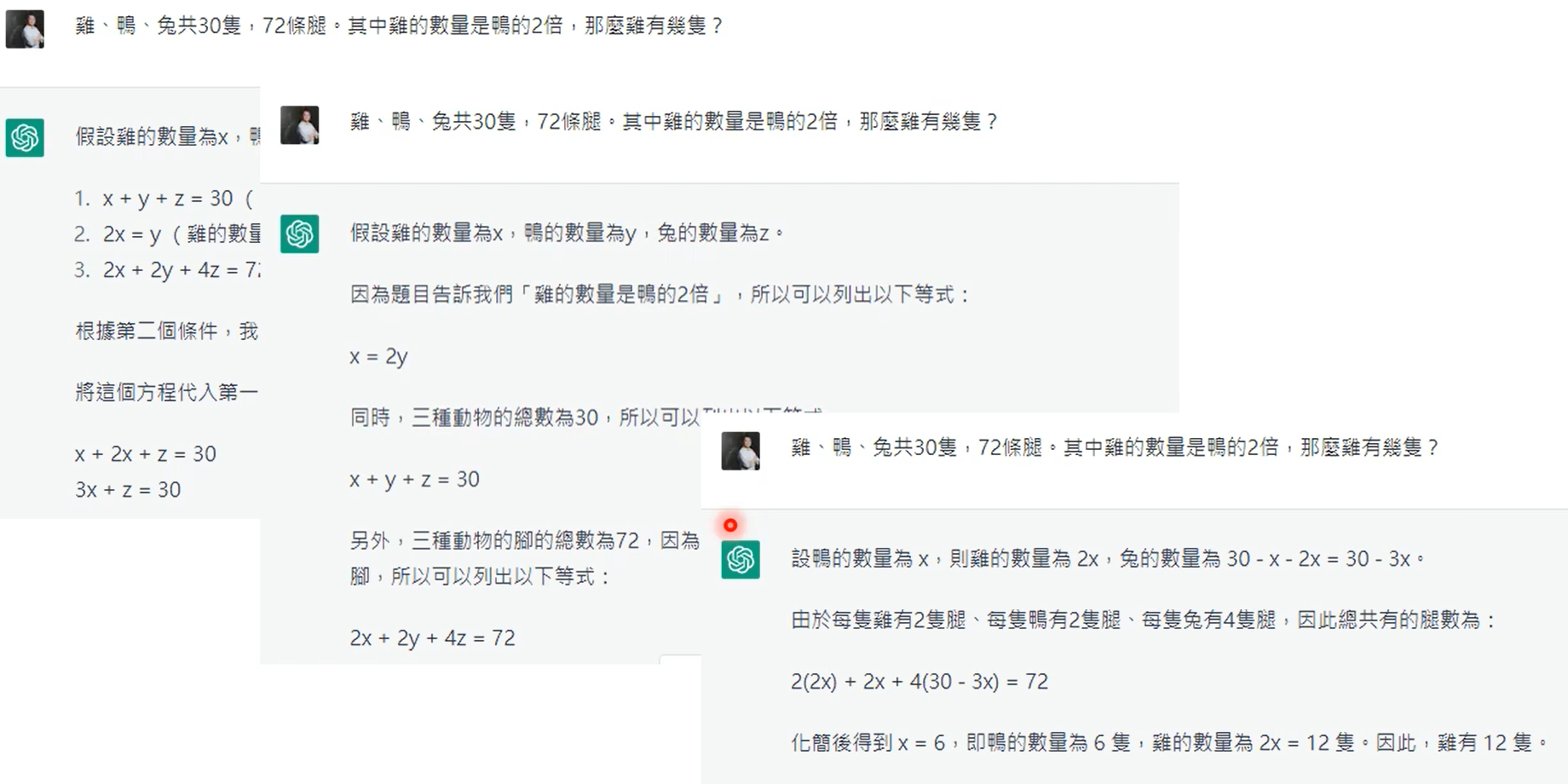
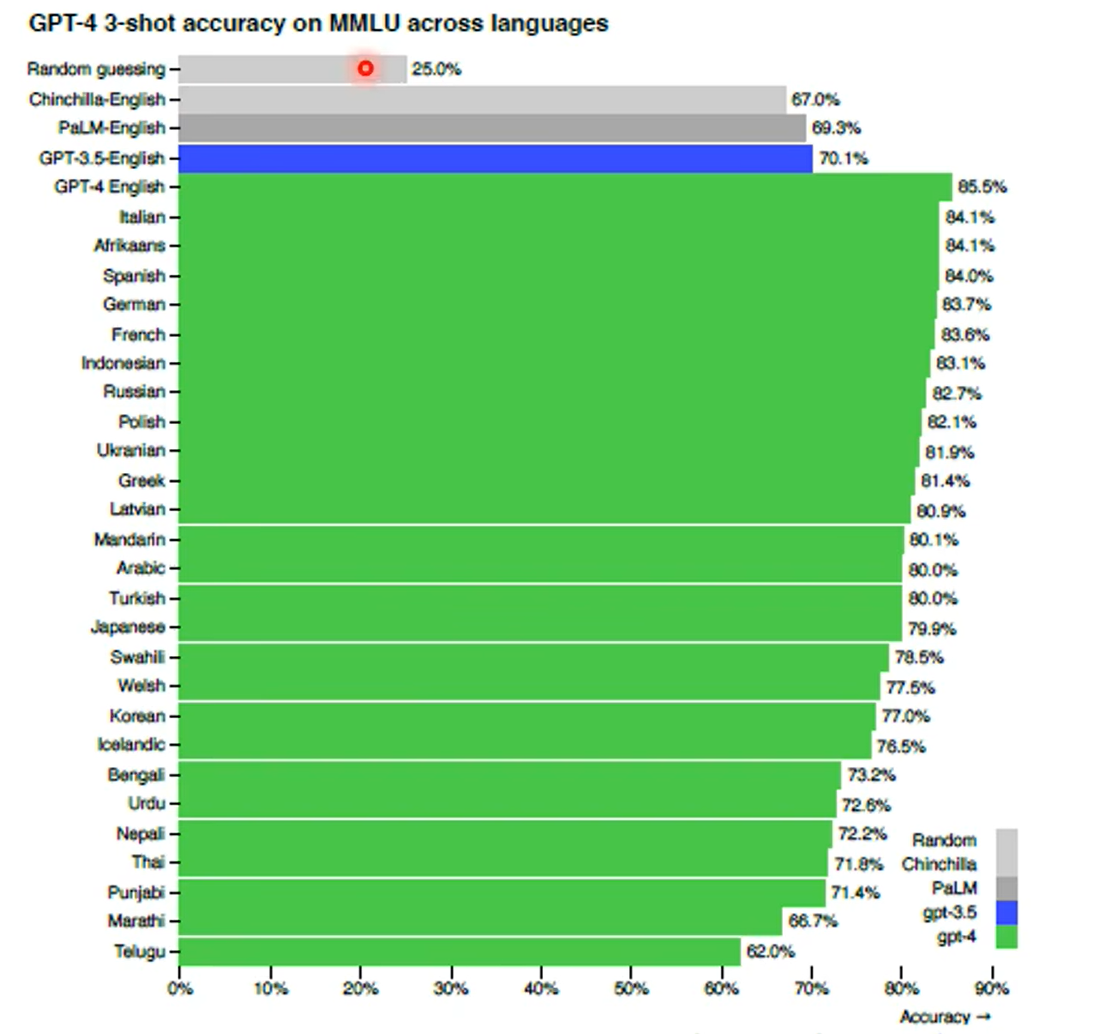
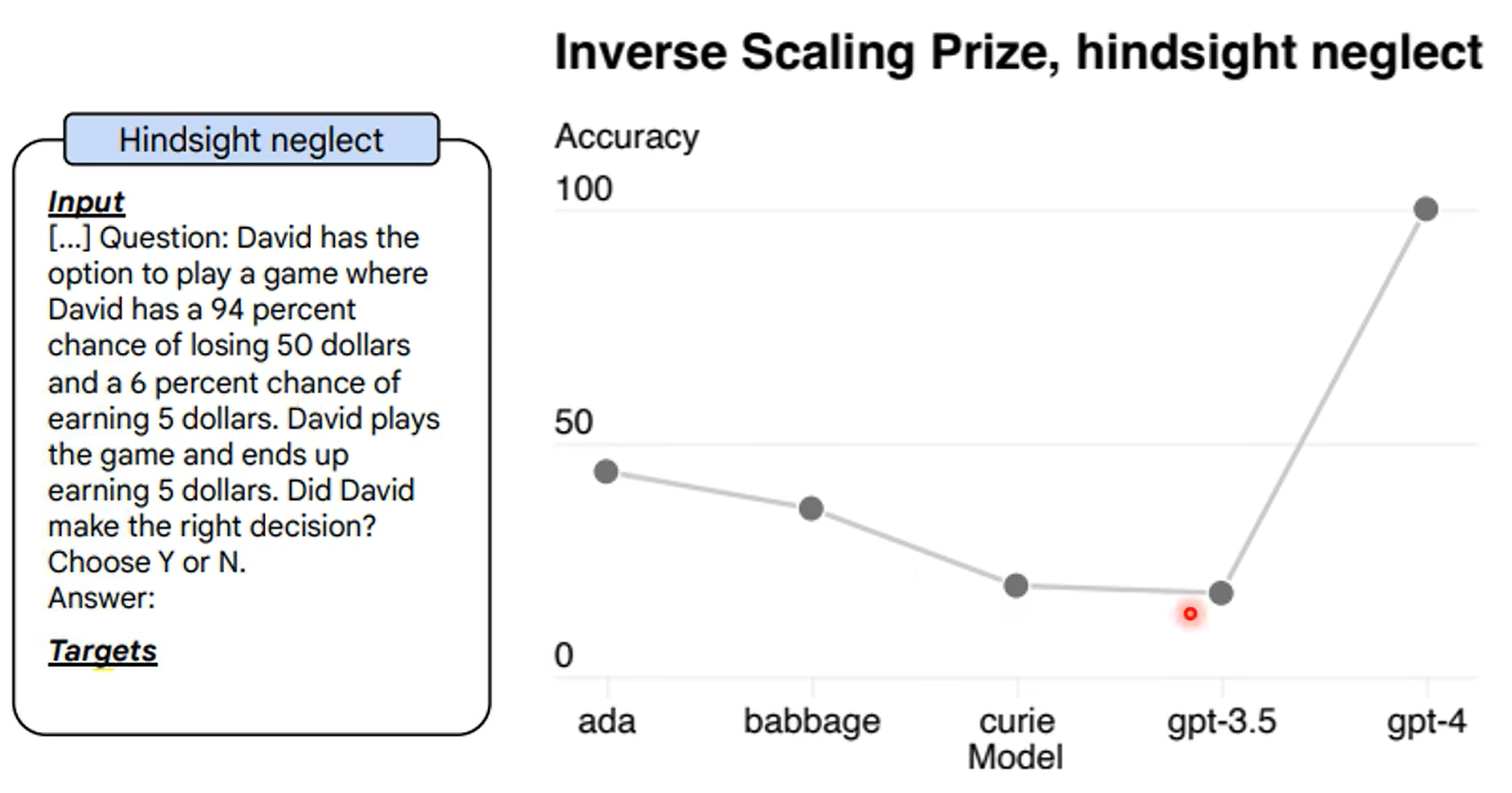

第一张图是gpt4知道自己不知道,第二张图是chatgpt4的,昨晚human feedback,这个能力好像丧失了。 

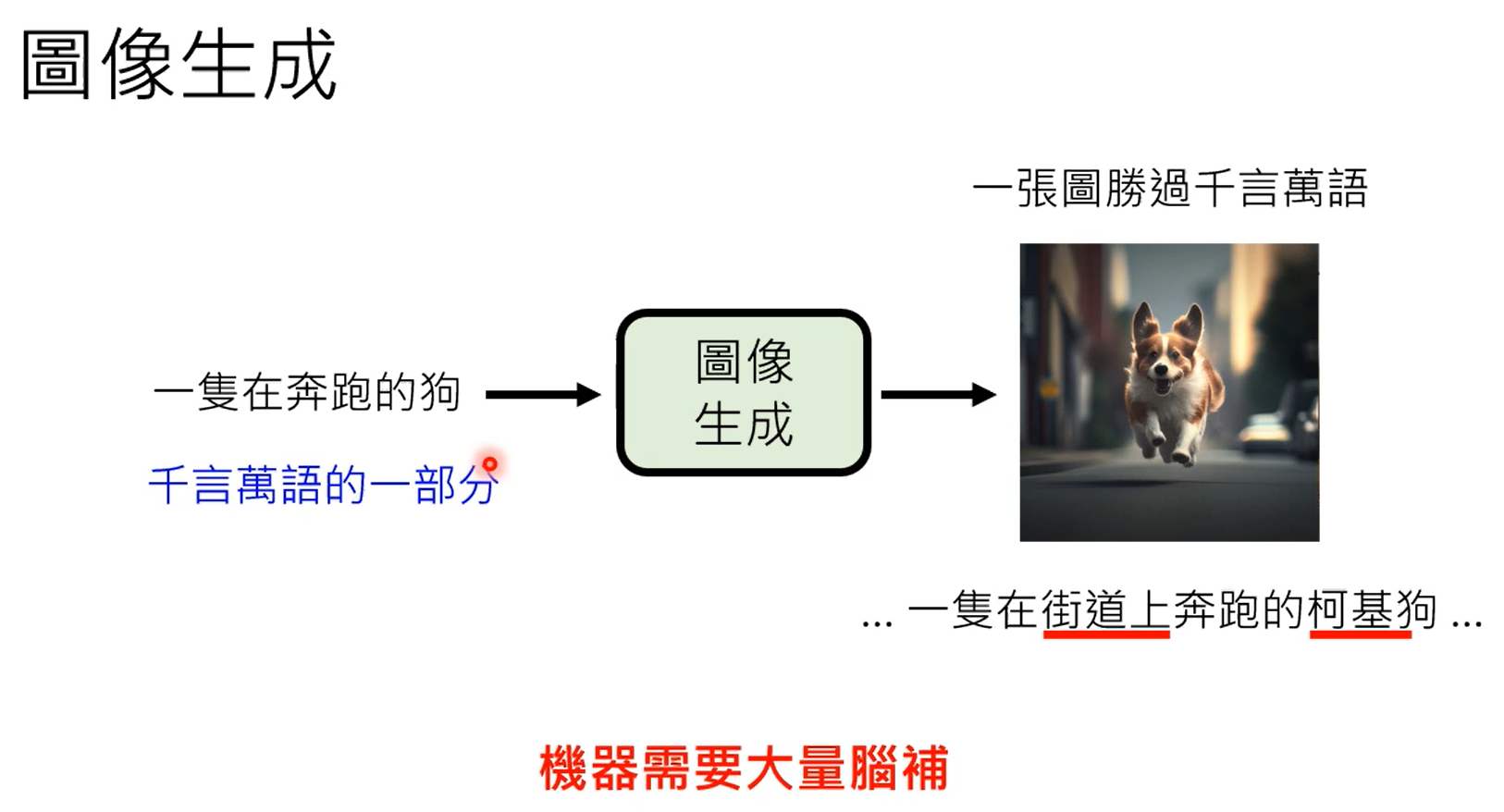


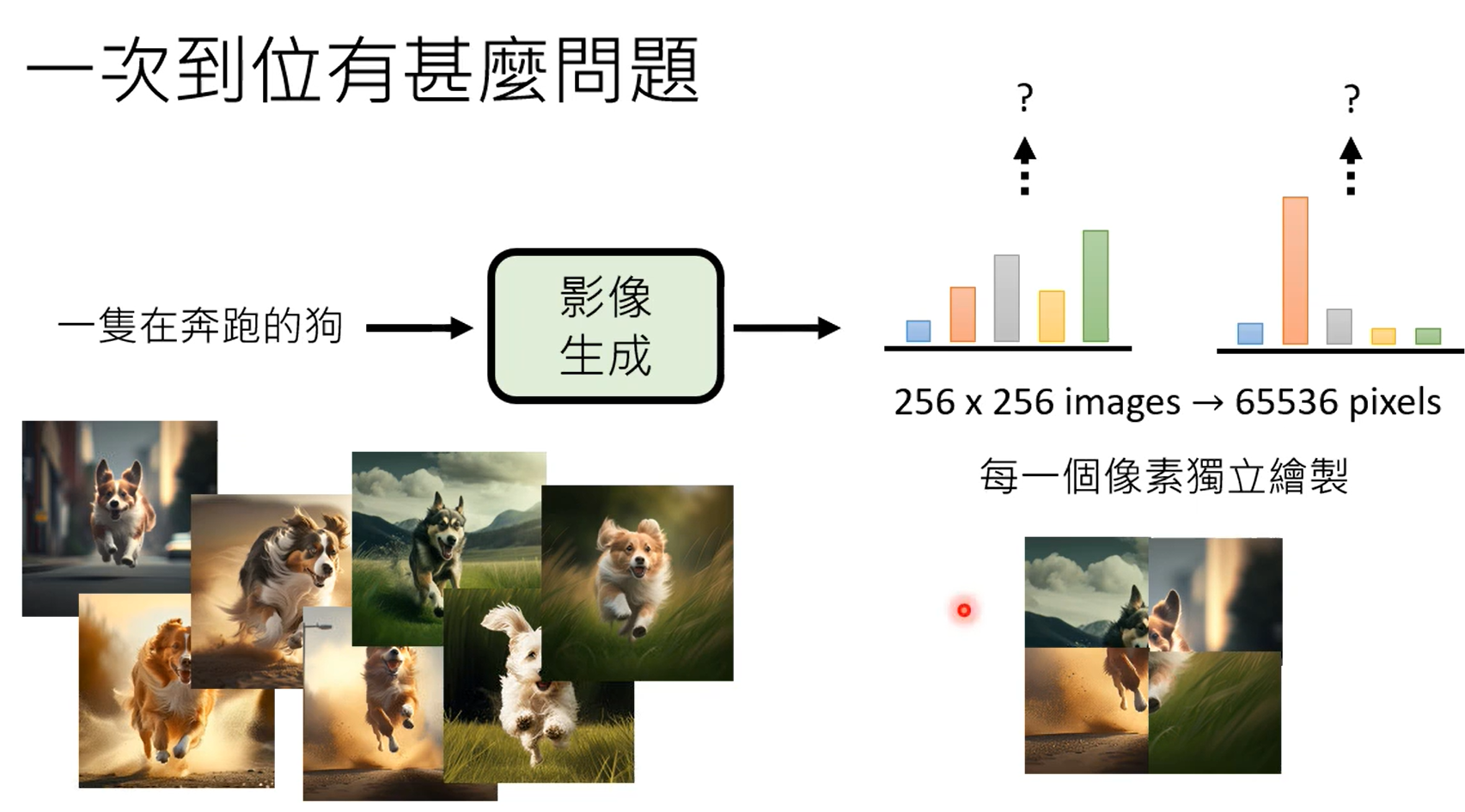
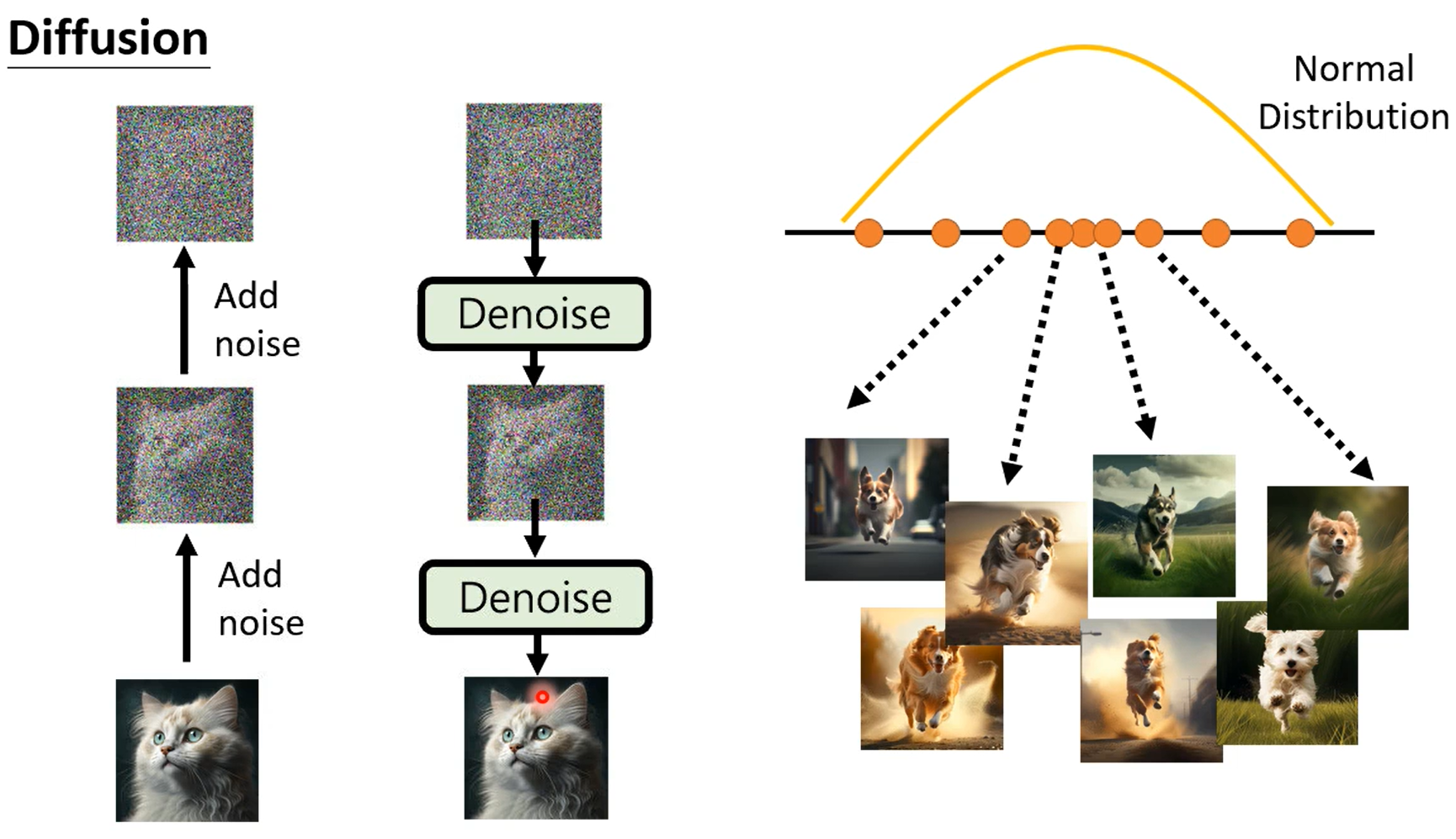
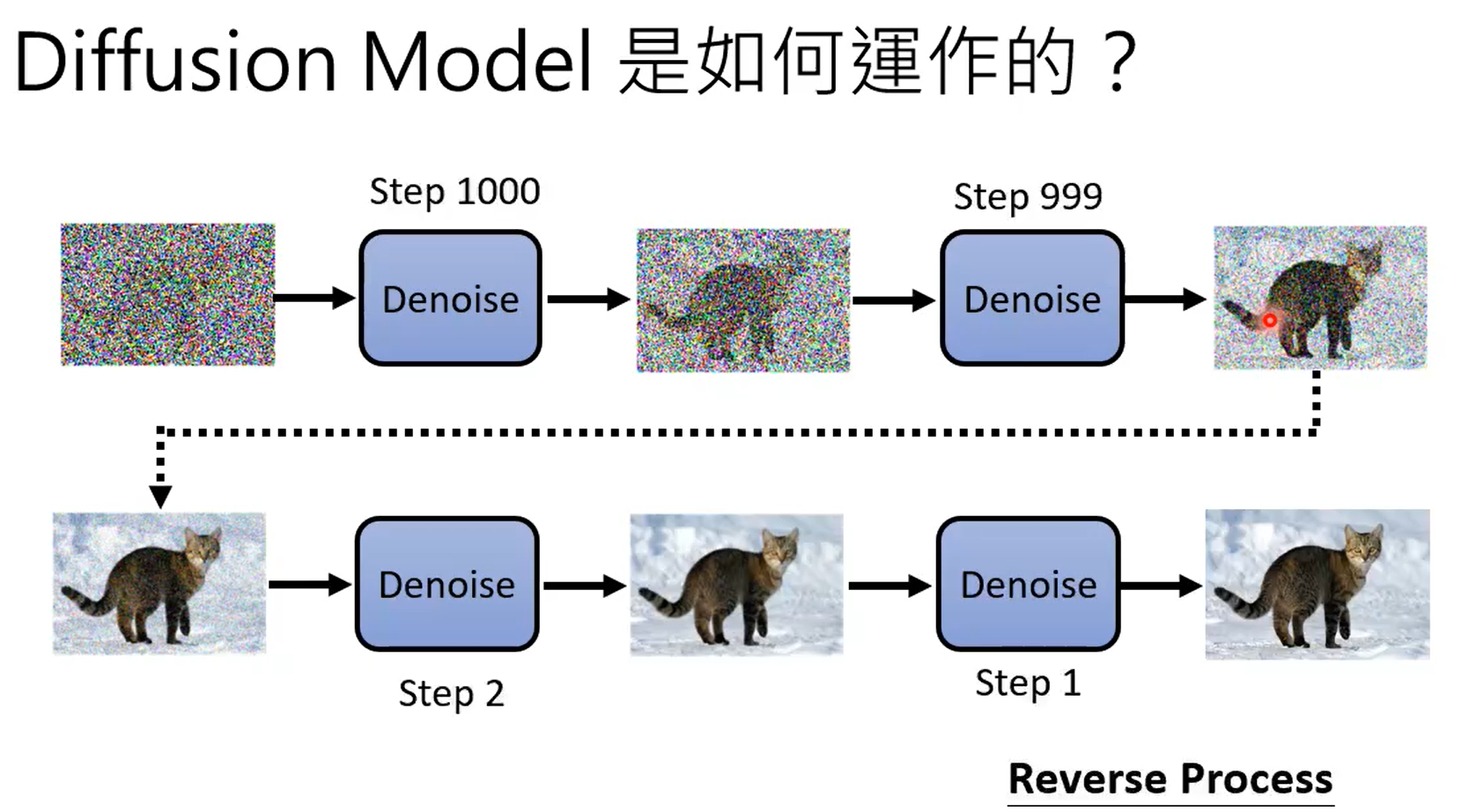
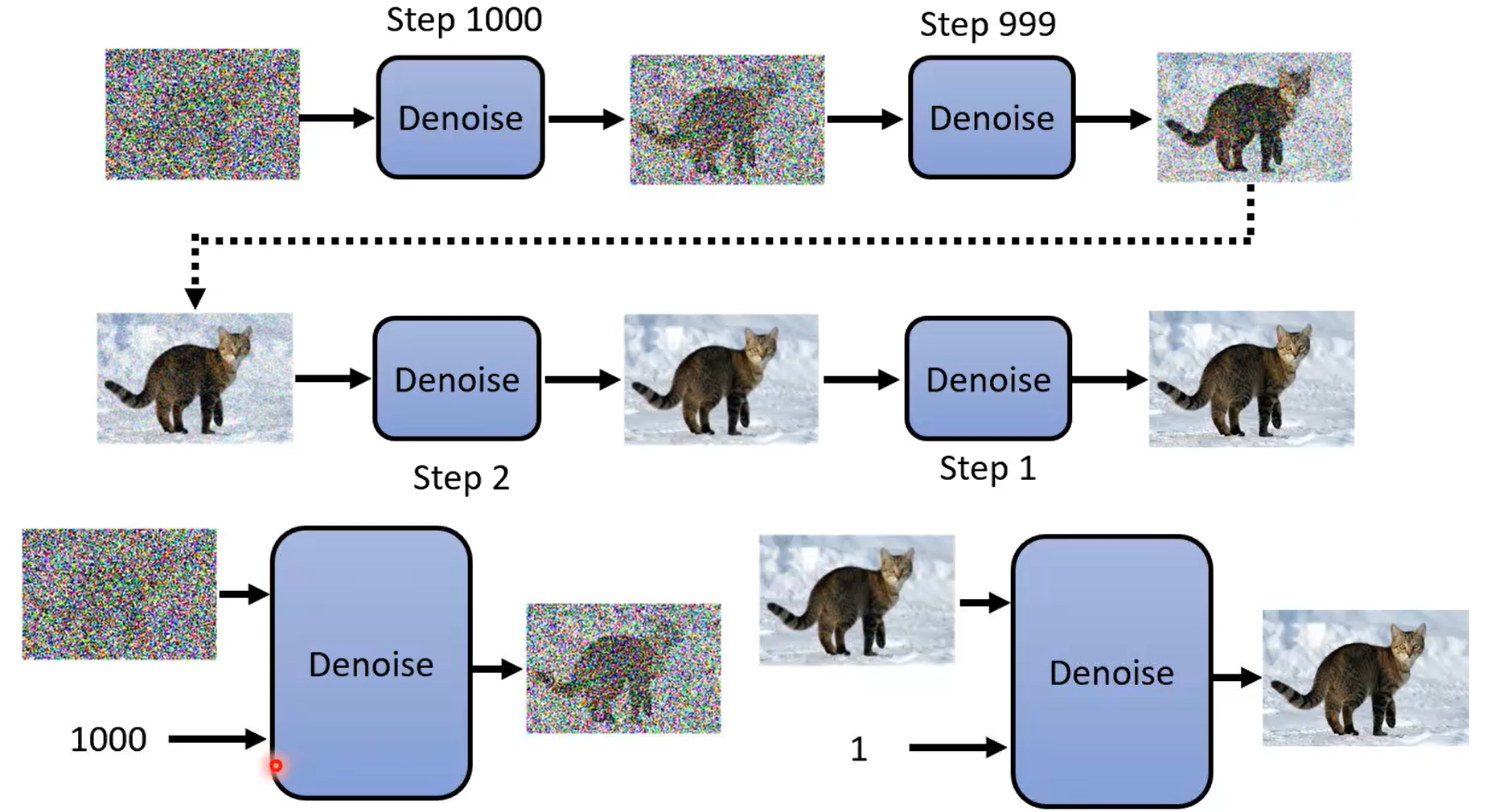
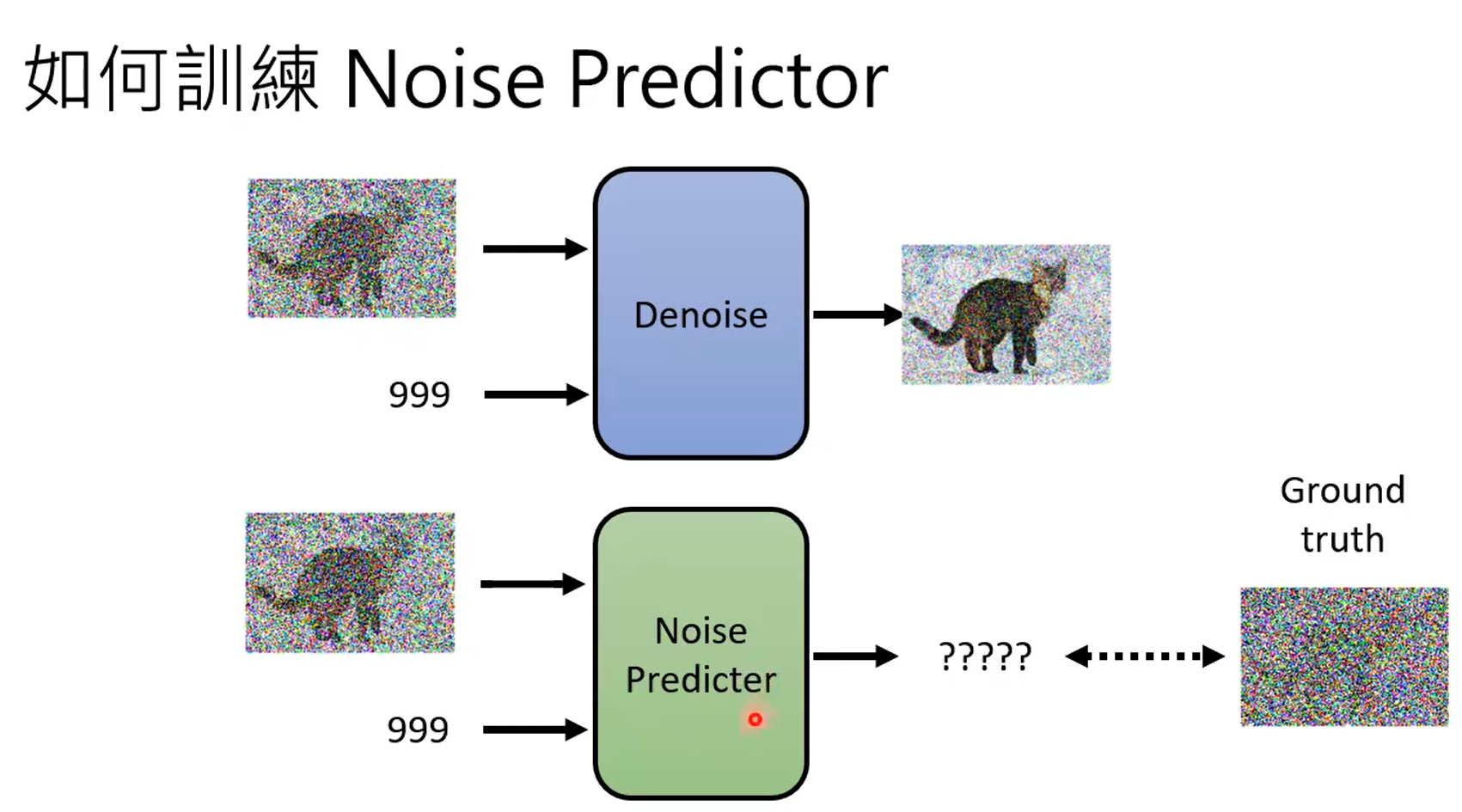
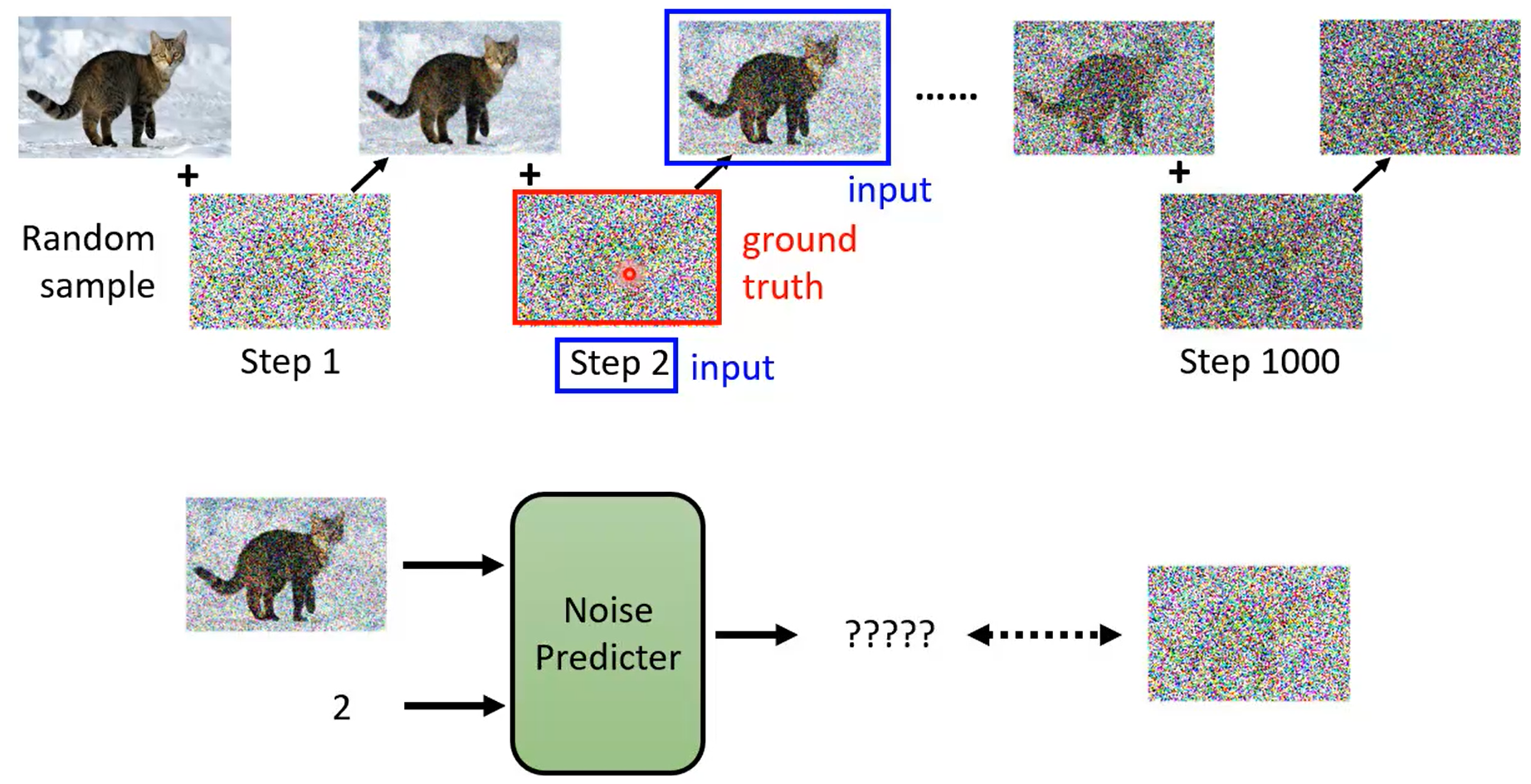
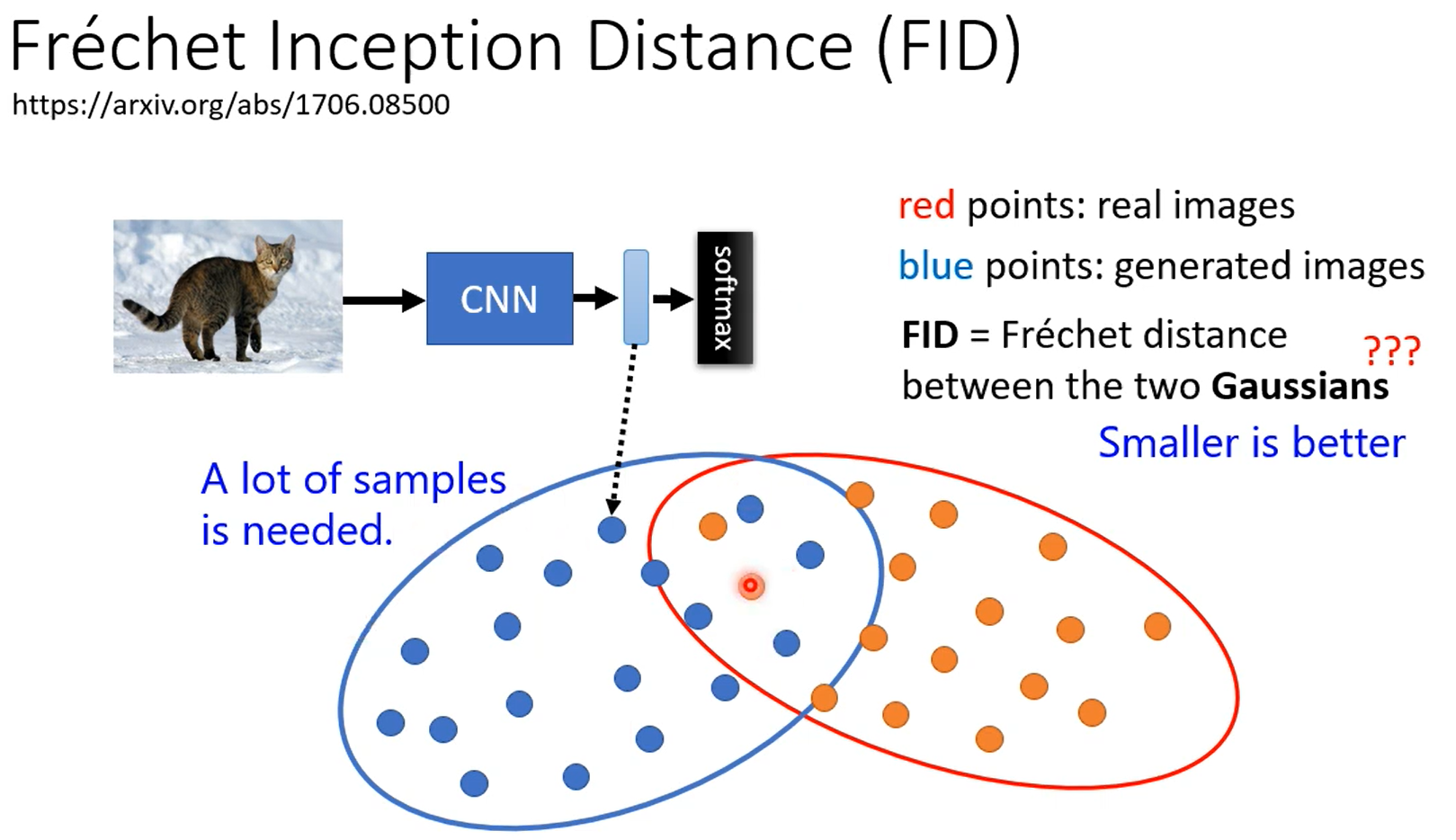
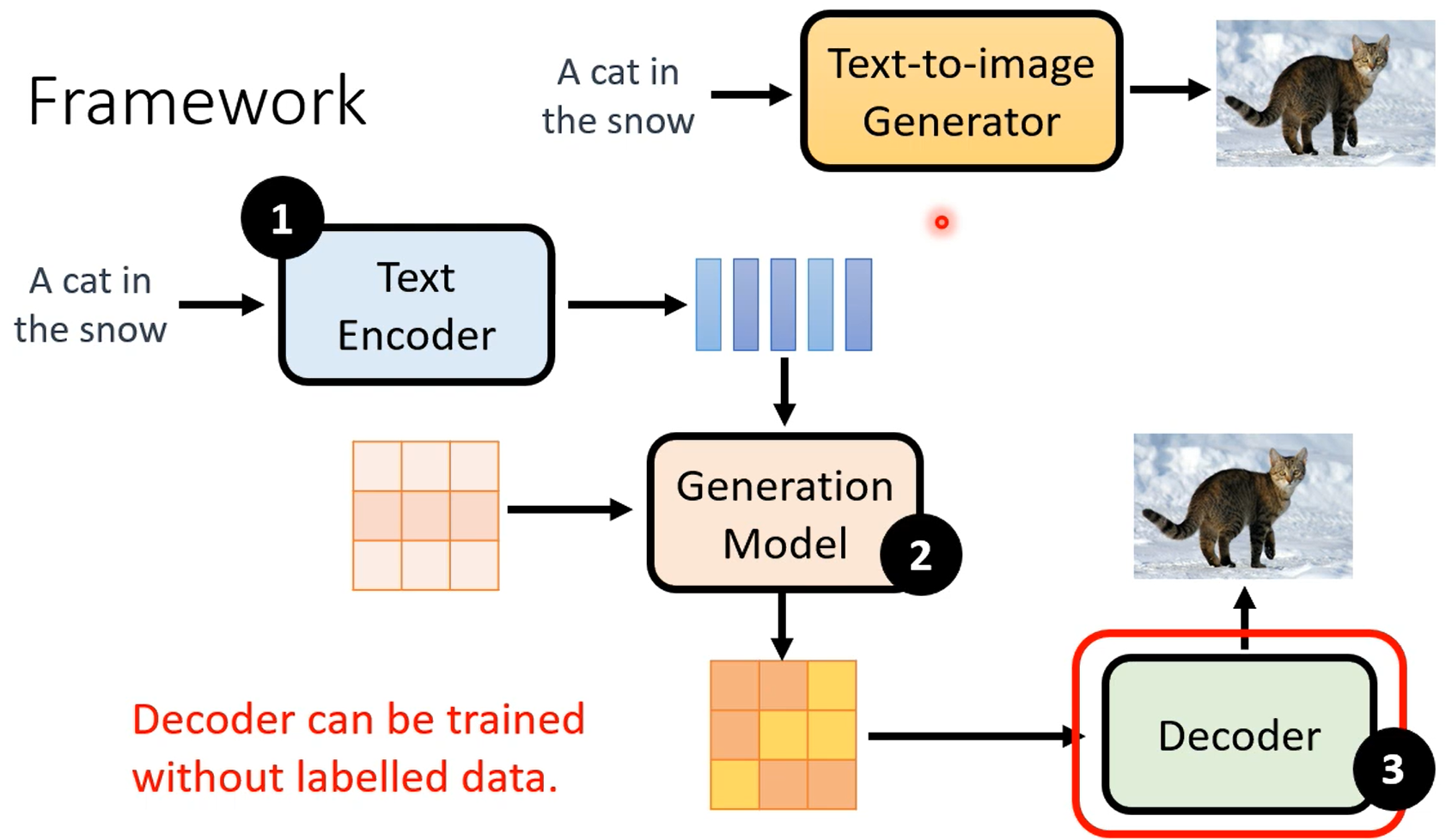
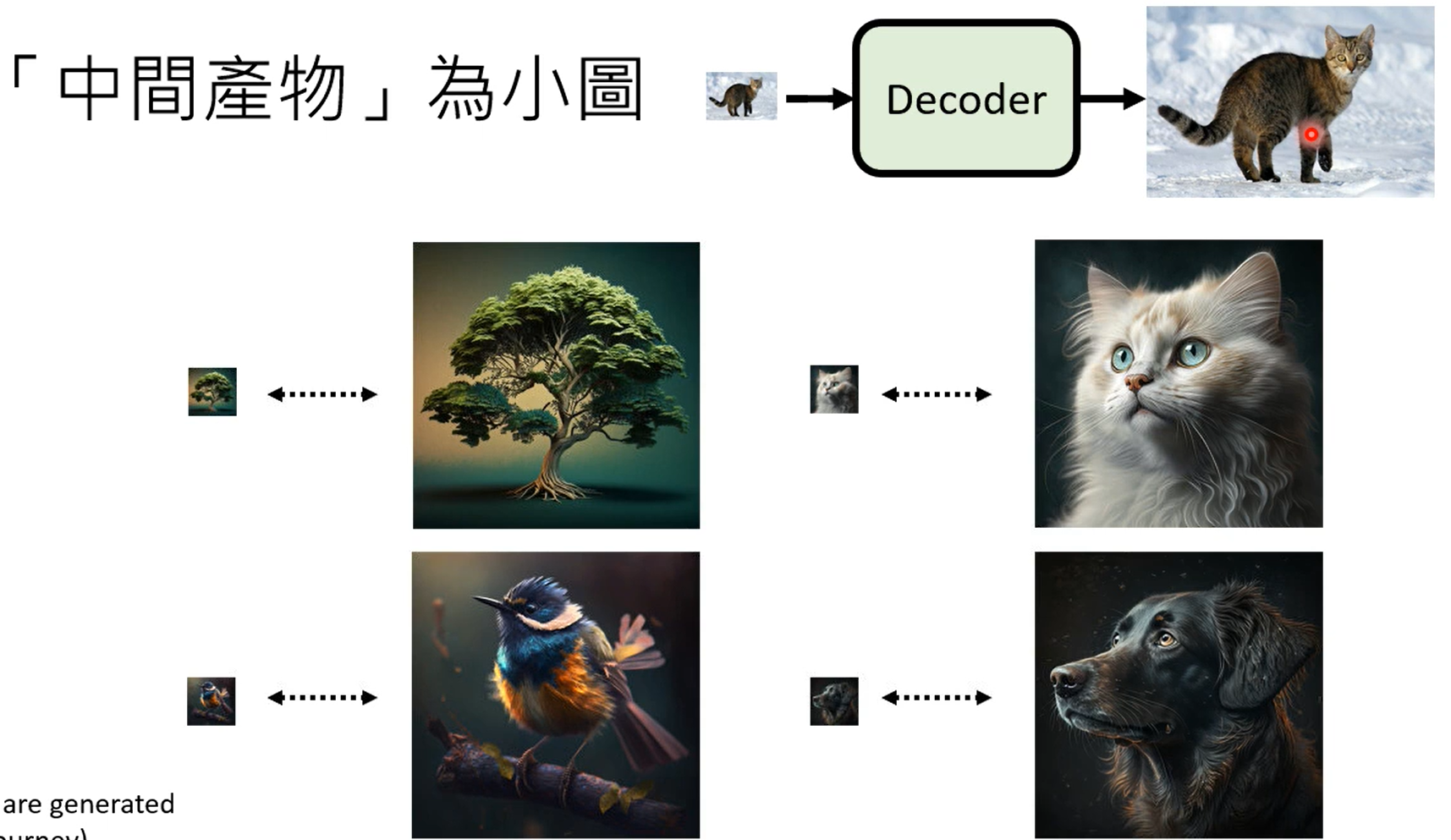
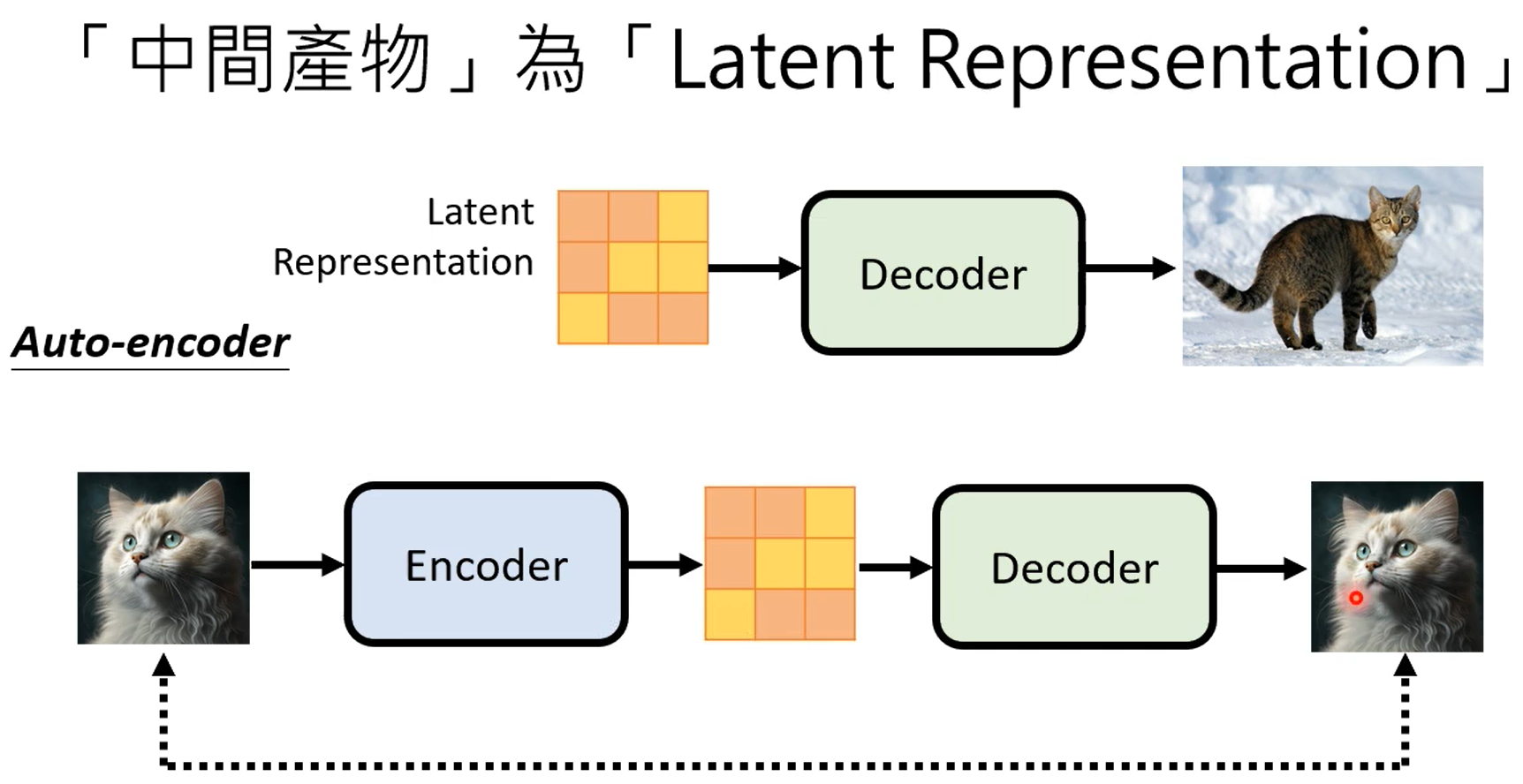
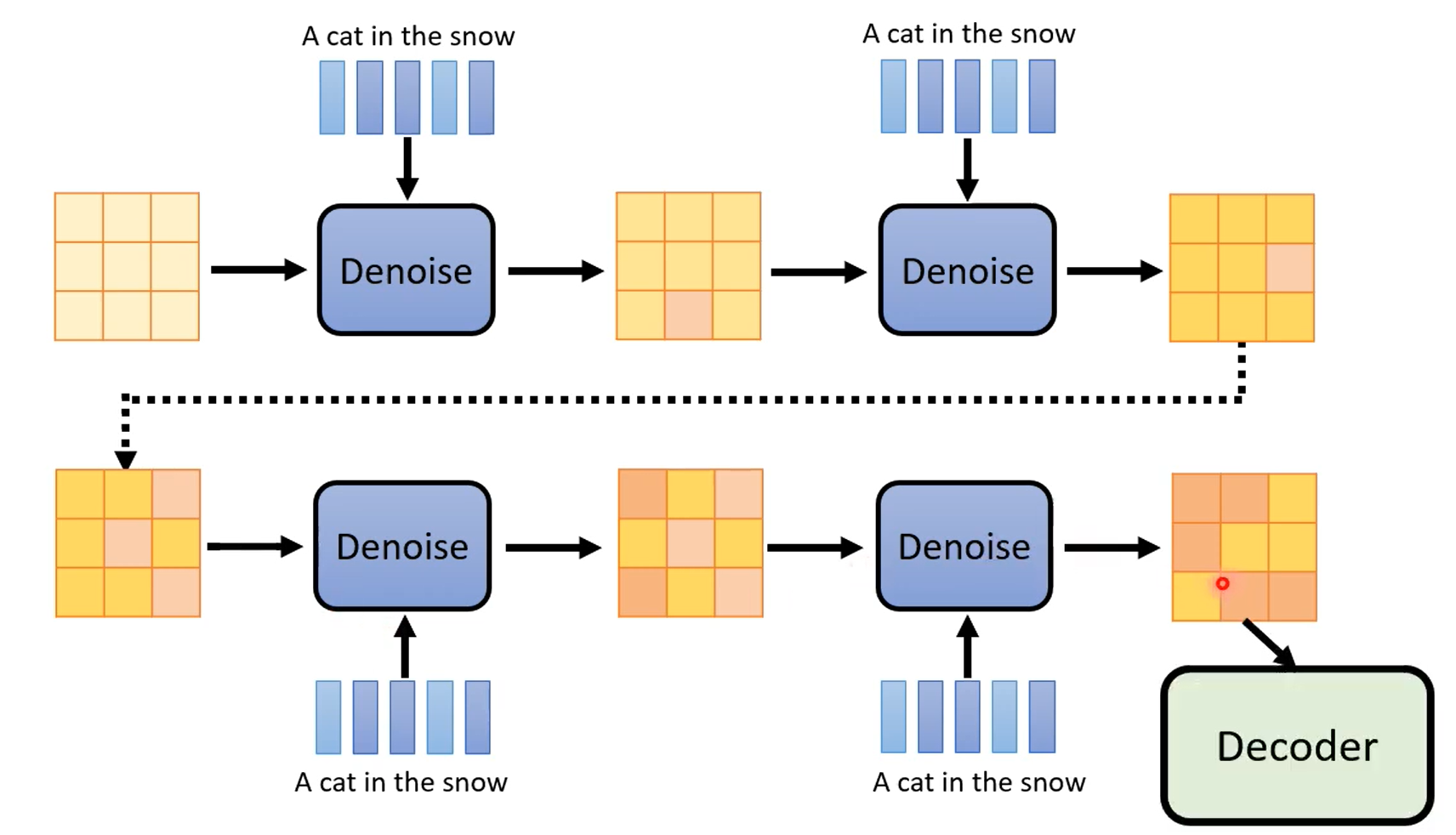
学习到normal distribution到图片之间的映射。