
- 1不知道怎样计算权重?告诉你8种确定权重方法_根据排名如何计算权重
- 2很文雅,很不错的句子分享 _文雅总结句子
- 3流式数据湖存储技术,Apache Paimon是什么?
- 4四、Flink使用广播状态和定时器实现word_join_count有效时间1分钟_flink 定时器
- 5【论文阅读笔记】BTS-ST: Swin transformer network for segmentation and classification of multimodality breast
- 6龙格库塔求解车辆振动模型_多自由度振动系统的龙格库塔法
- 7概念解析 | 威胁建模与DREAD评估:构建安全的系统防线_基于dread模型的风险分析:
- 8Java开发-防止重复提交解决办法_java添加车辆数据防止重复提交
- 9Linux软件安装
- 10JVM CMS垃圾收集器简聊
Linux命令大全 以及搭建hadoop
赞
踩

Liunx系统目录
- ├── bin -> usr/bin # 用于存放二进制命令
- ├── boot # 内核及引导系统程序所在的目录
- ├── dev # 所有设备文件的目录(如磁盘、光驱等)
- ├── etc # 配置文件默认路径、服务启动命令存放目录
- ├── home # 用户家目录,root用户为/root
- ├── lib -> usr/lib # 32位库文件存放目录
- ├── lib64 -> usr/lib64 # 64位库文件存放目录
- ├── media # 媒体文件存放目录
- ├── mnt # 临时挂载设备目录
- ├── opt # 自定义软件安装存放目录
- ├── proc # 进程及内核信息存放目录
- ├── root # Root用户家目录
- ├── run # 系统运行时产生临时文件,存放目录
- ├── sbin -> usr/sbin # 系统管理命令存放目录
- ├── srv # 服务启动之后需要访问的数据目录
- ├── sys # 系统使用目录
- ├── tmp # 临时文件目录
- ├── usr # 系统命令和帮助文件目录
- └── var # 存放内容易变的文件的目录

Linux常用基本命令
文件相关的命令
ls
ls:查看指定的文件夹下面所有的文件以及目录
语法:ls [-l|-a] [目录名称]
-l:显式文件的详细信息,包括文件的权限,大小,时间,用户等等
-a:显式文件夹下面的所有的隐藏文件以及普通文件
注意:如果省略目录名称,则默认查询是当前的目录。
ll:相当于ls -l的简写
| ls | 显示文件或目录 |
| ls -l | list--列出文件详细信息 |
| ls -a | all--列出当前目录下所有文件及目录,包括隐藏的。相当于ll |
| ls -h | human-readable--以人类可读的方式显示(K、M) |
| ll -ah | 列出当前文件或目录下的所有文件的详细信息。 |
pwd:查看当前用户所在的目录
| 参数 | 功能 |
|---|---|
| -P | 显示物理路径 |
| -L | 显示逻辑路径 |
-
-P参数会忽视''/'',显示实际的物理路径。 -
-L参数(这也是默认选项)会把符号链接作为实际的路径来显示。
1.3 创建文件:touch、echo、cat
echo
一般是把内容写入文件,创建新的文件或旧文件
| 字符 | 含义 |
|---|---|
| -n | 不自动换行 |
| -e | 解释转义字符 |
1、覆盖文件
echo “内容”> 文件名:将想要的内容(支持文章所述的所有echo输出格式)覆盖到对应的文件当中去,文件中之前的内容将不复存在。实际上是修改原文件的内容, 且文件在系统中不存在时,此命令会先创建新文件再覆盖。
2、文件尾追加
echo “内容”>> 文件名:将输入的内容(支持文章所述的所有echo输出格式)在文件最后一行后插入,对文件之前的内容不修改,只进行增添,也叫追加重定向
touch :
- 将已存在的文件的时间标签改修改为系统当前的时间(默认),也可以通过参数指定时间,但是数据原封不动。
- 用来创建新的空文件,这个应该是最常用的一种方法。
- -a:或--time=atime或--time=access或--time=use 只更改存取时间;
- -c: 或--no-create 不建立新文件
- -f:此参数将忽略不予处理,仅负责解决BSD版本touch指令的兼容性问题;
- -m:或--time=mtime或--time=modify 只更该变动时间;
- -r:<参考文件或目录> 把指定文件或目录的日期时间,统统设成和参考文件或目录的日期时间相同;
- -t:<日期时间> 使用指定的日期时间,而非现在的时间;
- --help:在线帮助;
- --version:显示版本信息。
- access:最后一次访问文件的时间
- modify:最后一次对文件内容进行修改的时间
- change:最后一次对文件属性或状态进行修改的时间
cat:
cat 命令允许我们创建单个或多个文件、查看文件内容、连接文件和重定向终端或文件中的输出。
-n:显示行号,可与其他参数连用;-b:显示非空行号,忽略空白行;-s:压缩空白行,将连续多行空白行压缩成一行;-E:在每一行的末尾显示$符号;-T:将制表符(tab)显示为^I;-A:相当于-vET的合集。
cat 文件名 >> 新文件名 创建新文件添加内容 用法同echo一致
cat 文件1 文件2 查看多个文件
创建文件:vim的使用
vim是vi的升级版本,有三种模式:命令模式、插入模式、编辑模式。使用ESC(末行模式)或i(插入)或:来切换模式。
| :q | 退出 |
| :q! | 强制退出 |
| :wq | 保存并退出 |
| :set number/nu | 显示行号 |
| :set nonumber | 隐藏行号 |
| :set paste | 保证复制粘贴的内容格式不会乱 |
| yy | 复制光标所在行 ,2yy是复制两行 |
| p | 粘贴 |
| dd | 删除光标所在行,2dd是删除两行 |
| /apache | 在文档中查找apache,按n跳到下一个,shift+n上一个 |
| h(左移一个字符←)j(下一行↓) | k(上一行↑)、l(右移一个字符→) |
复制文件、文件夹:cp
-i:交互模式,在覆盖已存在的文件前提示用户确认。
-r 或 -R:递归复制目录及其包含的所有子目录和文件。
-p:保留原文件的属性(权限、修改时间等)。
-v:显示详细的复制进度信息。
-u:仅当源文件比目标文件新时才进行复制。
-f 或 --force:强制复制,即使目标文件已存在也不提示,直接覆盖。
交互式复制并保留属性:
cp -ip source.txt destination.txt
强制覆盖已有文件:
cp -f source.txt existing_file.txt
同时复制多个文件到一个目录:
cp file1.txt file2.txt /path/to/directory/
使用通配符批量复制文件:
cp *.txt target_directory/
在一些情况下,你可能希望在复制过程中忽略某些错误,可以使用`-n`选项(no-clobber)来避免覆盖已存在的文件: cp -n source.txt existing_file.txt
使用`--sparse=always`选项复制稀疏文件(sparse file):
cp --sparse=always sparse_file destination_file
删除文件:rm
- DESCRIPTION
- -f, --force ignore nonexistent files and arguments, never prompt
- #强制删除文件或目录,即使文件属性设为只读也直接删除,不产生提示确认。
- -i prompt before every removal
- # 删除之前逐一询问确认。
- -I prompt once before removing more than three files, or
- when removing recursively; less intrusive than -i,
- while still giving protection against most mistakes
- #如果文件数量超过3个,或者当递归删除时,提示用户。
- --interactive[=WHEN] prompt according to WHEN: never, once (-I), or
- always (-i); without WHEN, prompt always
- #根据WHEN进行提示:never,once(等同于-I),或者always(-i);WHEN不填时,一直提示(always)
- --one-file-system when removing a hierarchy recursively, skip any
- directory that is on a file system different from
- that of the corresponding command line argument
- --no-preserve-root do not treat '/' specially
- #不对根目录/特别对待
- --preserve-root do not remove '/' (default)
- #不删除根目录(默认情况)
-
- -r, -R, --recursive remove directories and their contents recursively
- #递归地删除目录及其内容
- -d, --dir remove empty directories
- #删除空目录
- -v, --verbose explain what is being done
- #输出执行过程
查找文件 :find、Locate、which、whereis
find命令:
-a:and 必须满足两个条件才显示
-o:or 只要满足一个条件就显示
-name:按照文件名查找文件
-iname:按照文件名查找文件(忽略大小写)
-type:根据文件类型进行搜索
-perm:按照文件权限来查找文件
-user 按照文件属主来查找文件。
-group 按照文件所属的组来查找文件。
-fprint 文件名:将匹配的文件输出到文件。
-newer file1 ! newer file2 查找更改时间比文件file1新但比文件file2旧的文件
-print 默认动作,将匹配的文件输出到标准输出
-exec 对匹配的文件执行该参数所给出的命令。相应命令的形式为 'command' { } \;,注意{ }和\;之间的空格。
-ok 和-exec的作用相同,只不过以一种更为安全的模式来执行该参数所给出的命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行。
-delete 将匹配到的文件删除
|xargs 将匹配到的文件删除 |xargs rm -rf
在/home目录下查找以.txt结尾的文件名
find /home/ -name "*.txt"
在/home目录下查找以.txt结尾的文件名,但忽略大小写
find /home -iname "*.txt"
查找 /home/ 下所有以.txt或.pdf结尾的文件
find /home/ -name "*.txt" -o -name "*.pdf"
查找 /home/ 下所有以a开头和以.txt结尾的文件
find /home/ -name "*.txt" -a -name "a*"
搜索/home目录下txt结尾的文件,并将输出到指定文件中(re.txt)
find /home/ -type f -name "*.txt" -fprint /tmp/re.txt
基于目录深度搜索
- [root@host-136 ~]# find /usr/local/ -maxdepth 3 -type d
- /usr/local/
- /usr/local/bin
- /usr/local/etc
- /usr/local/games
- /usr/local/include
- /usr/local/lib
- /usr/local/lib64
- /usr/local/libexec
- /usr/local/sbin
- /usr/local/share
- /usr/local/share/applications
- /usr/local/share/info
- /usr/local/share/man
- /usr/local/share/man/man1
- /usr/local/share/man/man1x
根据文件时间戳进行搜索
访问时间(-atime/天,-amin/分钟):用户最近一次访问时间。
修改时间(-mtime/天,-mmin/分钟):文件最后一次修改时间
变化时间(-ctime/天,-cmin/分钟):文件数据元(例如权限等)最后一次修改时间。
- [root@host-136 ~]# find /etc/ -type f -atime -7
- /etc/fstab
- /etc/crypttab
- /etc/resolv.conf
- /etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
- /etc/pki/ca-trust/ca-legacy.conf
- /etc/pki/ca-trust/extracted/java/cacerts
- /etc/pki/ca-trust/extracted/openssl/ca-bundle.trust.crt
- /etc/pki/ca-trust/extracted/pem/tls-ca-bundle.pem
- /etc/pki/ca-trust/extracted/pem/email-ca-bundle.pem
- /etc/pki/ca-trust/extracted/pem/objsign-ca-bundle.pem
- [root@host-136 ~]# find /etc -type f -atime +7
- /etc/sasl2/smtpd.conf
- /etc/ethertypes
- /etc/makedumpfile.conf.sample
- /etc/postfix/access
- /etc/postfix/canonical
- /etc/postfix/generic
- /etc/postfix/header_checks
- /etc/postfix/relocated
- /etc/postfix/transport
- /etc/postfix/virtual
- [root@host-136 ~]# find /etc/ -type f -size +10k
- /etc/ssh/moduli
- /etc/postfix/access
- /etc/postfix/canonical
- /etc/postfix/header_checks
- /etc/postfix/main.cf
- /etc/postfix/transport
- /etc/postfix/virtual
- [root@host-136 ~]# find / -type f -name "*.txt" ! -perm 644
- /usr/lib/firmware/ivtv-firmware-license-end-user.txt
- /usr/lib/firmware/ivtv-firmware-license-oemihvisv.txt
- /usr/share/licenses/shadow-utils-4.6/gpl-2.0.txt
- /usr/share/licenses/shadow-utils-4.6/shadow-bsd.txt
-
locate,
定位的意思,作用是让使用者可以快速的搜寻系统中是否有指定的文件。
1) "locate"的速度比"find"快,因为它并不是真的查找文件,而是查数据库。
2) 新建的文件,我们立即用"locate"命令去查找,一般是找不到的,
因为数据库的更新不是实时的,数据库的更新时间由系统维护。
3) "locate"命令所搜索的后台数据库在"/var/lib/mlocate"这个目录下,
可能有些Linux系统位置不同,具体我们可以用"locate locate"查询。
4) 我们可以用"updatedb"命令来更新数据库,这样就能查询到刚才新建的文件了。
5) 并不是所有的目录下的文件都会用"locate"命令搜索到,
"/etc/updatedb.conf"这个配置文件中,配置了一些"locate"命令的一些规则。
- /etc/updatedb.conf配置文件解析:
- 1) PRUNE_BIND_MOUNTS = "yes"
- 值为"yes"时开启搜索限制,此时,下边的配置生效;为"no"时关闭搜索限制。
- 2) PRUNEFS =
- 后边跟搜索时,不搜索的文件系统。
- 3) PRUNENAMES =
- 后边跟搜索时,不搜索的文件类型。
- 4) PRUNEPATHS =
- 后边跟搜索时,不搜索的文件所在的路径。
"locate -c" 查询指定文件的数目。(c为count的意思)
"locate -e" 只显示当前存在的文件条目。(e为existing的意思)
"locate -h" 显示"locate"命令的帮助信息。(h为help的意思)
"locate -i" 查找时忽略大小写区别。(i为ignore的意思)
"locate -n" 最大显示条数" 至多显示"最大显示条数"条查询到的内容。
"locate -r" 使用正则运算式做寻找的条件。(r为regexp的意思)
1) 查找etc目录下所有以sh开头的文件

2) 查找etc目录下所有以sh开头的文件的数目

3) 查找etc目录下所有以sh开头的文件,并最多显示2条

4) 新建的文件,更新数据库后就能查询到了

5) 查找文件时,不区分大小写

6) 使用正则表达式,查找以akefile结尾的文件,并最多显示5条
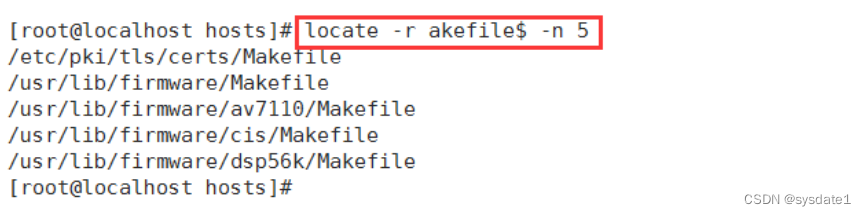
7) 只显示当前存在的文件条目

which
which指令会在PATH变量指定的路径中,搜索某个系统命令的位置,并且返回第一个搜索结果
-a:显示所有匹配的命令,而不仅仅是第一个匹配项。--skip-alias:忽略别名,仅搜索实际的命令。--skip-dot:忽略以.开头的命令。--tty-only:仅在终端中搜索命令。
查找命令的绝对路径:which ls
显示所有匹配的命令:which -a python
忽略别名,仅搜索实际的命令:which --skip-alias ll
忽略以 .开头的命令:which --skip-dot .bashrc
仅在终端中搜索命令: which --tty-only ls
whereis

查找所有与 `ls` 相关的文件:whereis ls
只查找 `ls` 的二进制文件:whereis -b ls
`whereis` 命令搜索以下三个标准位置:
(1). 二进制文件(通常位于 `/usr/bin`、`/usr/sbin`、`/bin` 或 `/sbin`)。
(2). 源代码文件(通常位于 `/usr/src` 或 `/usr/local/src`)。
(3). 手册页(通常位于 `/usr/share/man`)。
查看文件内容 head ,tail,less,more,wc
head 命令基本语法:
-n 或 --lines:指定要显示的行数。
-c 或 --bytes:指定要显示的字节数。
-q 或 --quiet:不显示文件名的标题信息。
-v 或 --verbose:显示文件名的标题信息。
-z 或 --zero-terminated:使用 NULL 字符分隔输出行。
-h 或 --help:显示帮助信息
显示文件的前 10 行:head file.txt
显示文件的前 5 行:head -n 5 file.txt
显示文件的前 100 个字节:head -c 100 file.txt
-
UTF-8 编码:一个中文字符通常占据 3 个字节。
-
GB2312 编码:一个中文字符占据 2 个字节。
-
GBK/GB18030 编码:一个中文字符通常占据 2 个字节
tail 命令:
-n 或 --lines:指定要显示的行数。
-c 或 --bytes:指定要显示的字节数。
-f 或 --follow:实时监视文件的变化。
-q 或 --quiet:不显示文件名的标题信息。
-v 或 --verbose:显示文件名的标题信息。
-z 或 --zero-terminated:使用 NULL 字符分隔输出行。
-h 或 --help:显示帮助信息。
显示文件的后 10 行:tail file.txt
显示文件的后 5 行:tail -n 5 file.txt
显示文件的后 100 个字节:tail -c 100 file.txt
实时监视文件的变化:tail -f file.txt
如果同时指定 -n 和 -c 选项,则以行数为准。
如果行数超过了文件的总行数,则显示整个文件的内容。
对于二进制文件,使用 -n 选项可能会导致输出的行数不准确。
对于大文件,使用 -n 选项会比使用 -c 选项更快。
在一些 Unix 系统中,head 命令也可以通过相应的命令别名 top 或 tac 来调用。tail 命令则通过相应的命令别名 rlog 或 rtail 来调用。
动态显示access.log文件的变化情况。
tail -f access.log/ tailf access.log
less命令:
使用 less 非常简单,只需要输入 less 命令,后接要查看的文件名即可,在 less 环境下,可以使用方向键或 Page Up/Page Down 键来滚动浏览文件。按 q 键可以退出 less。
less 命令支持许多命令行选项以改变其行为。以下是一些常用的选项:
-N:显示行号-m:显示更详细的提示信息-E:在文件结束后自动退出-S:禁用自动换行-
搜索内容在
less中,可以使用/字符后接搜索模式来向前搜索内容,或者使用?后接搜索模式来向后搜索内容。例如,要在文件中搜索 “example”,可以输入/example并按回车键。
less 可以同时打开多个文件。只需要在命令行中列出所有的文件名即可
more命令
- +n 从笫n行开始显示。
- -n 定义屏幕大小为n行。
- +/pattern 在每个档案显示前搜寻该字串(pattern),然后从该字串前两行之后开始显示。
- -c 从顶部清屏,然后显示。
- -d 提示“Press space to continue,’q’ to quit(按空格键继续,按q键退出)”,禁用响铃功能。
- -l 忽略Ctrl+l(换页)字符。
- -p 通过清除窗口而不是滚屏来对文件进行换页,与-c选项相似。
- -s 把连续的多个空行显示为一行。
- -u 把文件内容中的下画线去掉。
显示文件中从第3行起的内容
- [root@localhost test]# cat log1.txt
- Thu Feb 25 09:46:34 2021
- Create Relation ADR_CONTROL
- Create Relation ADR_INVALIDATION
- Create Relation INC_METER_IMPT_DEF
- Create Relation INC_METER_PK_IMPTS
- [root@localhost test]# more +3 log1.txt
- Create Relation ADR_INVALIDATION
- Create Relation INC_METER_IMPT_DEF
- Create Relation INC_METER_PK_IMPTS
从文件中查找第一个出现"INC_METER_PK_IMPTS"字符串的行,并从该处前两行开始显示输出
- [root@localhost test]# cat log1.txt
- Thu Feb 25 09:46:34 2021
- Create Relation ADR_CONTROL
- Create Relation ADR_INVALIDATION
- Create Relation INC_METER_IMPT_DEF
- Create Relation INC_METER_PK_IMPTS
- [root@localhost test]# more +/INC_METER_PK_IMPTS log1.txt
-
- ...跳过
- Create Relation ADR_INVALIDATION
- Create Relation INC_METER_IMPT_DEF
- Create Relation INC_METER_PK_IMPTS
设定每屏显示行数
- [root@localhost test]# cat log1.txt
- Thu Feb 25 09:46:34 2021
- Create Relation ADR_CONTROL
- Create Relation ADR_INVALIDATION
- Create Relation INC_METER_IMPT_DEF
- Create Relation INC_METER_PK_IMPTS
- [root@localhost test]# more -3 log1.txt
- Thu Feb 25 09:46:34 2021
- Create Relation ADR_CONTROL
- Create Relation ADR_INVALIDATION
- --更多--(55%)
列一个目录下的文件用分页显示
- [root@localhost usr]# ll
- 总用量 244
- dr-xr-xr-x. 2 root root 45056 5月 12 14:20 bin
- drwxr-xr-x. 3 root root 18 5月 14 16:01 games
- drwxr-xr-x. 4 root root 43 5月 12 14:19 include
- dr-xr-xr-x. 37 root root 4096 5月 12 14:19 lib
- dr-xr-xr-x. 126 root root 81920 5月 12 14:23 lib64
- drwxr-xr-x. 49 root root 12288 5月 12 14:20 libexec
- drwxr-xr-x. 12 root root 131 5月 12 14:16 local
- dr-xr-xr-x. 2 root root 20480 5月 12 14:20 sbin
- drwxr-xr-x. 223 root root 8192 5月 12 14:19 share
- drwxr-xr-x. 4 root root 34 5月 12 14:16 src
- lrwxrwxrwx. 1 root root 10 11月 3 2020 tmp -> ../var/tmp
- [root@localhost usr]# ll |more -5
- 总用量 244
- dr-xr-xr-x. 2 root root 45056 5月 12 14:20 bin
- drwxr-xr-x. 3 root root 18 5月 14 16:01 games
- drwxr-xr-x. 4 root root 43 5月 12 14:19 include
- dr-xr-xr-x. 37 root root 4096 5月 12 14:19 lib
- --更多--
wc
| wc | 统计文本中行数、字数、字符数 |
| wc -l | 将每个文件的行数及文件名输出到屏幕上 |
| wc -c | 统计字节 |
过滤、查找:grep
-i:忽略大小写,不区分大小写地匹配模式。-r:递归地搜索目录及其子目录下的文件。-l:只打印包含匹配模式的文件名,而不打印匹配的行。-n:打印匹配行的行号。-v:反转匹配,只打印不匹配模式的行。-w:仅匹配整个单词,而不是部分匹配。-c:打印匹配模式的行数统计
- Hello, this is an example file.
- It contains some lines of text.
- Let's use grep to search for specific patterns.
- 在文件中搜索匹配模式的行
- 在文件中搜索包含单词 “example” 的行
- grep "example" demo.txt
- Hello, this is an example file.
- 忽略大小写地搜索匹配模式的行
- 在文件中搜索不区分大小写的单词 "hello"的行
- grep -i "hello" demo.txt
- Hello, this is an example file.
- 反转匹配,只打印不匹配模式的行在文件中搜索不包含"text"的行
- grep -v "text" demo.txt
- 显示匹配行的行号 在文件中搜索包含单词 “example” 的行,并显示行号
- grep -n "example" demo.txt
- 1 Hello, this is an example file.
- 统计匹配的行数
- grep -c "example" demo.txt
-
- 1
- 打印包含匹配模式的文件名
- grep -l "example" demo.txt
- demo.txt
- 仅匹配整个单词 在文件中搜索包含单词 “example” 的行,是整个单词,而不是一个单词的一部分
- grep -w "example" demo.txt
- 递归地搜索目录及其子目录下的文件 搜索/opt/目录下包含内容"Hello, this is an example file."的所有文件
- grep -r "Hello, this is an example file." /opt/
chmod
mode : 权限设定字串,格式如下 : [ugoa...][[+-=][rwxX]...][,...],其中
u 表示该档案的拥有者,g 表示与该档案的拥有者属于同一个群体(group)者,o 表示其他以外的人,a 表示这三者皆是。
+ 表示增加权限、- 表示取消权限、= 表示唯一设定权限。
r 表示可读取,w 表示可写入,x 表示可执行,X 表示只有当该档案是个子目录或者该档案已经被设定过为可执行。
-c : 若该档案权限确实已经更改,才显示其更改动作
-f : 若该档案权限无法被更改也不要显示错误讯息
-v : 显示权限变更的详细资料
-R : 对目前目录下的所有档案与子目录进行相同的权限变更(即以递回的方式逐个变更)
将档案 file1.txt 设为所有人皆可读取 :chmod ugo+r file1.txt /chmod a+r file1.txt
将档案 file1.txt 与 file2.txt 设为该档案拥有者,与其所属同一个群体者可写入,但其他以外的人则不可写入 :chmod ug+w,o-w file1.txt file2.txt
将 ex1.py 设定为只有该档案拥有者可以执行 chmod u+x ex1.py
将目前目录下的所有档案与子目录皆设为任何人可读取 :chmod -R a+r *
- r=4,w=2,x=1
- 若要rwx属性则4+2+1=7;
- 若要rw-属性则4+2=6;
- 若要r-x属性则4+1=5。
- -rw------- (600) -- 只有属主有读写权限。
- -rw-r--r-- (644) -- 只有属主有读写权限;而属组用户和其他用户只有读权限。
- -rwx------ (700) -- 只有属主有读、写、执行权限。
- -rwxr-xr-x (755) -- 属主有读、写、执行权限;而属组用户和其他用户只有读、执行权限。
- -rwx--x--x (711) -- 属主有读、写、执行权限;而属组用户和其他用户只有执行权限。
- -rw-rw-rw- (666) -- 所有用户都有文件读、写权限。这种做法不可取。
- -rwxrwxrwx (777) -- 所有用户都有读、写、执行权限。更不可取的做法。
打包压缩文件命令:tar、zip、gzip、unzip
zip:将文件打包成一个zip格式的文件
语法:zip -r 压缩之后的文件的名称 要压缩的文件的名称
unzip 要解压的文件名 [-d 解压后的文件位置]
tar:可以将文件压缩为tar格式的文件,也可以将tar格式的文件解压缩
压缩文件:
语法:tar [选项] 压缩后的文件的名称 要压缩的文件的名称
-z:代表压缩文件的格式
-c:代表当前的操作是压缩操作
-v:显示压缩过程信息
-f:设置压缩文件的名称
[root@master ~]# tar -zcvf demo.tar.gz demo
解压缩:
语法:tar [选项] 要解压缩文件的名称 [-C 解压缩的位置]
-z:代表压缩文件的格式
-x:代表当前的操作是解压操作
-v:显示压缩过程信息
-f:设置压缩文件的名称
[root@master ~]# tar -zxvf jdk-8u121-linux-x64.tar.gz -C demo
gzip:将文件打包成.gz格式的文件
语法:gzip 文件名
[root@master ~]# gzip 2024-4-10课件.txt
gunzip:解压.gz格式的文件
语法:gunzip 压缩文件
[root@master ~]# gunzip 2024-4-10课件.txt.gz
mv
移动文件
语法:mv 要移动的原文件 移动的位置[/名称]
[root@master ~]# mv 2024-4-10课件.txt test 仅移动
[root@master ~]# mv test/2024-4-10课件.txt /root/kejian.txt 移动并重命名
重命名
语法:mv 原文件名 新名称
[root@master ~]# mv kejian.txt 课件.txt
文件链接 ln
建立软链接: ln -s 软连接目标文件的文件名 软连接文件的文件名
建立硬链接:ln 硬连接目标文件的文件名 硬连接文件的文件名
一个硬链接:file-hard,这个硬连接的inode编号和目标文件相同,因此我们可以先断定该文件不是独立文件,和目标文件公用一个inode属性和内容,硬链接的本质是创建一个新的文件名映射一个已经存在的inode
主要区别:
-
系统视角:软链接是一个指向目标文件或目录的快捷方式,类似于Windows系统中的快捷方式或符号链接。硬链接是一个指向目标文件或目录的实际链接,可以看作是文件系统中的另一个入口点。
-
跨文件系统和目录边界:软链接可以在文件系统之间创建链接,并且可以链接到不存在的目标。而硬链接只能在同一个文件系统中创建,并且不能链接到目录或不存在的目标。
-
链接数量:软链接只是一个文件,而硬链接和目标文件共享相同的索引节点。删除软链接不会影响目标文件或目录,而只会减少目标文件或目录的链接计数。只有当链接计数为零时,目标文件或目录的存储空间才会被释放。
系统信息命令:
| stat 【文件名】 | 指定显示文件的详细信息,比ls更详细 |
| who | 显示在线登录用户 |
| whoami | 显示当前操作用户 |
| hostname | 显示主机名 |
| hostnamectl set-hostname【新主机名】 | 修改主机名 |
| uname | 显示系统信息 |
查看系统CPU使用情况
| top | 动态显示当前耗费资源最多进程信息(cpu系统的使用情况) |
| dstat | 综合内存cpu网络流量使用情况 |
| nethogs | 综合内存cpu网络流量使用情况 |
| yum install epel-release 先安装epel源 | yum install dstat/nethogs |
显示磁盘信息
df -h和df -Th的区别: -Th是1000 为单位而不是用 1024
| df(默认根目录下) | 查看 Linux 系统上的文件系统磁盘使用情况 |
| df -h | human--以人类可读的方式显示磁盘信息 |
| df -Th | 以人类可读的方式显示磁盘信息 |
显示内存信息
| free | 显示系统中可用和已用内存的量 |
| free -m | 显示系统中的内存量(以 MB 为单位) |
查看进程
| ps | 显示瞬间进程状态 |
| ps -aux | 显示所有包含其他使用者的进程 |
| ps -ef | 显示所有进程信息,连同命令行 |
| pstress -p | 查看当前进程数 |
kill :杀死进程,可以先用ps 或 top命令查看进程的id,然后再用kill命令杀死进程
| kill | 当前进程向另外一个进程发送信号 |
| kill -9 【程序】 | 杀死一个进程(发送kill信号) |
| kill -1 【程序】 | 重新加载进程(发送hup信号) |
| kill -15 【程序】 | 正常终止一个进程 |
| killall | 杀掉服务相关的所有进程 |
| lsof -i 【端口号】 | 查看指定端口进程 |
统计文件大小
| du | 查看文件、文件夹大小 |
| du -a | all--统计所有文件的大小(文件和目录) |
| du -h | human--以人类可读的方式显示文件大小(K/M) |
| du -sh | 统计文件、文件夹里所有文件的大小 |
显示网络连接信息
| ping | 测试网络连通性 |
| ping -c | 指定要ping几个包 |
| fping | 批量去ping,可以接网段也可以指定文件里的ip地址去ping |
| fping -g | 指定网段 |
| fping -f | 指定文件里的ip地址 |
| fping -agq | 指定网段中存活的ip地址 |
① fping -g:指定去ping192.168.119.0/24网段:fping -g 192.168.119.0/24。
②fping -agq:找到指定网段192.168.119.0/24中哪些ip是存活的:fping -agq 192.168.119.0/24
③fping -f:指定文件里面的ip地址:fping -f ip.txt
| netstat | 显示网络状态信息 |
| netstat -a | 显示详细的网络状况 |
| netstat -nu | 显示当前户UDP连接状况 |
| netstat -apu | 显示UDP端口号的使用情况 |
| netstat -i | 显示网卡列表 |
| ifconfig | 查看网络情况 |
| man | 是查询命令的使用手册、指南(说明书) |
| clear | 清屏 |
| alias | 对命令重命名(别名)如:alias c=clear(临时定义c是clear的别名) |
| unalias | 取消别名(unalias c) |
查看Linux系统ip
ip address、ip a、ip addr、ip ad、ifconfig(需要先安装net-tools)查看到的比ip a系列的要详细些,能够查看到接收的包和传输的包。
-
- 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
- link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
- inet 127.0.0.1/8 scope host lo
- valid_lft forever preferred_lft forever
- inet6 ::1/128 scope host
- valid_lft forever preferred_lft forever
- 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
- link/ether 00:0c:29:bc:67:4d brd ff:ff:ff:ff:ff:ff
- inet 192.168.136.240/24 brd 192.168.136.255 scope global noprefixroute ens33
- valid_lft forever preferred_lft forever
- inet6 fe80::a61e:3db8:18c7:7a51/64 scope link noprefixroute
- valid_lft forever preferred_lft forever
① ip a系列:查看网卡:两块网卡: lo、 ens33(真实的网卡)都是网卡名。
lo --- loopback 本地回环接口,这个网卡是虚拟的,每一台服务器上都有一个这样的网卡。这个网卡就代表本机,自身。inet 127.0.0.1/8 这个网卡的ip地址基本上都是127.0.0.1,自己、本身的ip地址,是用来检测自身的。
两台主机之间的通信,就要借助ip地址,就像手机电话号码一样。
127.0.0.1就代表主机自己。访问别人的主机,千万不能使用127.0.0.1这个ip地址。
物理:windows 、127.0.0.1 (代表本机自己)、192.168.1.2
虚拟机:linux,运行了一个网站程序 127.0.0.1(代表本机自己 )、192.168.1.1
物理机访问虚拟机,访问127.0.0.1是访问自己的i地址。
② ens33 --- 真实的网卡 一个主机上可以有很多网卡。
inet 192.168.136.240/24 ip地址显示
link/ether 00:0c:29:ae:89:5d: mac地址,每一个主机都会有一个全球唯一的mac地址
运行了DNS才能修改ip地址。
域名服务(DNS domain name system):格式:域名:--ip地址的联系
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
mtu:最大传输单元,一般默认1500。
Uptime命令使用
uptime命令能够打印系统总共运行了多长时间和系统的平均负载。uptime命令可以显示依次为:现在时间、系统已经运行了多长时间、目前多少登录用户、系统在过去的1分钟、5分钟和14分钟内的平均负载。使用help参数查看帮助手册:
-p --pretty show uptime in pretty format 比较美观的打印出来
-h --help display this help and exit 查看参数帮助
-s, --since system up since 查看系统当前时间
-V, --version output version information and exit 查看版本
telnet命令使用
不管是在windows还是Linux系统要校验某台服务器是否可以ping通,都可以使用命令,如果要加上端口的,Linux可以使用telnet命令。语法格式:Telnet 127.0.0.1 8080
查看系统当前登录用户:w
- [root@hadoop120 ~]# w
- 12:14:11 up 20:59, 1 user, load average: 0.00, 0.01, 0.05
- USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
- root pts/0 192.168.136.1 12:10 3.00s 0.85s 0.48s w
关机/重启机器
| shutdown | 关机、重启程序 |
| shutdown -r | 关机后重新开机 |
| shutdown -h /【数字】 | 关机不重启 /指定几分钟后关机 |
| shutdown -r/h now | 立刻关机/重启 |
| init 0 | Linux中关机命令 |
| init 6 | 重启系统 |
| reboot | 重启系统 |
Linux管道
| | | 将前面一个命令的输出送给后面一个命令作为标准输入。 |
| xargs | 将管道符号送过来的内容,告诉后面的命令,送过来的内容做参数使用。 |
| -exec | 需要执行后面的命令 execute 执行 |
例:grep -r "sl" /home/* | more 在home目录下所有文件中查找,包括close的文件,并分页输出
软件包管理工具
rpm是linux系统里比较底层的软件管理的命令。
对redhat系统的安装:redhat 、oracle Linux
对Debian系列的安装:Debian、Ubuntu
缺点:不能自动解决软件包之间的依赖关系;不能自动化、智能化。
rpm -q 【软件名】 :quary--查询指定的软件包是否被安装
rpm -qa 【软件名】all--查询系统中安装的所有RPM软件包
rpm -ivh 【软件名】安装软件 -i:install
rpm -U 【软件名】升级软件(如果软件没有安装,会自动帮助安装)
文本处理三剑客
grep:文本过滤器,仅仅是过滤文本,没有编辑功能
sed:Stream EDitor,流编辑器,可以按照特定规则按行编辑数据(sed是不处理原数据的,编辑完的行默认是打印到屏幕,所以sed运行完原文件内容是不变的)
awk:报告生成器,可以根据特定字符分割行(如空格、冒号、顿号等),然后按照你设定的格式显示。(如果对处理的数据需要生成报告之类的信息,或者你处理的数据是按列进行处理的,最好使用 awk)
grep 更适合单纯的查找或匹配文本(尤其擅长过滤)
sed 更适合编辑匹配到的文本(尤其擅长替换)
awk 更适合格式化文本,对文本进行较复杂格式处理(擅长取列)
grep命令
-i : 忽略大小写。不会区分大小写字符。
-v : 不匹配。通常,grep 程序会打印包含匹配项的文本行。这个选项导致 grep 程序只会打印不包含匹配项的文本行。
-c : 打印匹配的数量(或者是不匹配的数目,若指定了-v 选项),而不是文本行本身。
-l : 打印包含匹配项的文件名,而不是文本行本身。
-L : 相似于-l 选项,但是只是打印不包含匹配项的文件名。
-n : 在每个匹配行之前打印出其位于文件中的相应行号。
-h : 应用于多文件搜索,不输出文件名。
- 正则:
- . 任意单个字符
-
- [] 指定范围的字符
-
- [^] 不在指定范围的字符
-
- 次数匹配:
-
- * :匹配前面字符任意次
-
- ? : 0 或1次
-
- + :1 次或多次
-
- {m} :匹配m次 次
-
- {m,n} :至少m ,至多n次
-
-
- * 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
-
- .* 任意前面长度的任意字符,不包括0次
-
- \? 匹配其前面的字符0 或 1次
-
- + 匹配其前面的字符至少1次
-
- {n} 匹配前面的字符n次
-
- {m,n} 匹配前面的字符至少m 次,至多n次
-
- {,n} 匹配前面的字符至多n次
-
- {n,} 匹配前面的字符至少n次
-
-
- ^ : 行首
-
- $ : 行尾
-
- <, \b : 语首
-
- >, \b : 语尾
-
- 分组:()
-
- 后向引用:\1, \2, ...
- --查询当前目录下面的所有以.txt结尾的文件的名称
- [root@master demo]# ls | grep '.txt$'
- 1. grep '^a' test.txt -i -n #查找以a开头的行,显示行号并且忽略大小写。
- 'a$' #查找以a结尾的行
- 'a*' #查找a出现一次或者多次行号
-
- 2. grep -v '^$' test.txt #反向输出所有非空格内容(过滤空行)
-
- 3. grep "\.$" test.txt -n #输出以.为结束的行,\为转义字符,.为特殊字符。
- '^.*c' #以任意内容开头, 直到c结束
- 4. grep "[abc]" test.txt -n -o #匹配abc字符中的任意一个,得到它的行数和行号,只显示被匹配的关键字。
- "[^a]" -c #匹配除a以外的字符,显示被匹配了多少行。
- "[a+]" -n #+号表示匹配前一个字符1一次或多次.
- "[go?d]" -n #匹配god或者good
- 5. grep -E "(ab)+c" test.txt -n #匹配ab出现一次或者多次以c结尾的行,并显示行号。
- "go(|o|od)d" #|或的意思,()将一个或多个字符捆绑一起, 当作一个整体进行处理。
- "(ab){1,3}" #匹配ab字符一到三次。
sed
-n :不输出模式空间内容到屏幕,即不自动打印,只打印匹配到的行
-e :多点编辑,对每行处理时,可以有多个Script
-f :把Script写到文件当中,在执行sed时-f 指定文件路径,如果是多个Script,换行写
-r :支持扩展的正则表达式
-i :直接将处理的结果写入文件
-i.bak :在将处理的结果写入文件之前备份一份
- d:删除模式空间匹配的行,并立即启用下一轮循环
-
- p:打印当前模式空间内容,追加到默认输出之后
-
- a:在指定行后面追加文本,支持使用\n实现多行追加
-
- i:在行前面插入文本,支持使用\n实现多行追加
-
- c:替换行为单行或多行文本,支持使用\n实现多行追加
-
- w:保存模式匹配的行至指定文件
-
- r:读取指定文件的文本至模式空间中匹配到的行后
-
- =:为模式空间中的行打印行号
-
- !:模式空间中匹配行取反处理
-
- 加g表示行内全局替换;
- 在替换时,可以加一下命令,实现大小写转换
- \l:把下个字符转换成小写。
- \L:把replacement字母转换成小写,直到\U或\E出现。
- \u:把下个字符转换成大写。
- \U:把replacement字母转换成大写,直到\L或\E出现。
- \E:停止以\L或\U开始的大小写转换
1. sed -n '5,19 p' demo #查看文件demo中5-19行中的内容。
2. sed -n '/^a/ p' demo #查看以a开头的demo文件的行。
3. sed '2,3 d' demo | head #将2-5行内容打印出来。
4. sed -e '4 a\abc' demo | head #在文件passwd上的第四行后面添加abc.
5. sed '2 i\abc' demo | head #在第二行前插入abc.
6. sed '3 c\abc' demo |head #将第三行替换为abc.
7. sed -n '5,10 s/bin/aaaa/ p' demo |head #将passwd的5到10的bin字符串查找出来替换为aaaa。
8. sed -i '1 d' demo #删除原文件的第一行。
9. sed -i.bak '1 d' demo #备份
- 1.过滤掉指定的行:
- 语法:sed 'n,md' 文件的名称
- [root@master demo]# sed '3,5d' d.txt 删除3-5行
- [root@master demo]# sed '3d' d.txt 只删除第三行
- [root@master demo]# sed '4,$d' d.txt 删除3行之后的所有数据
-
-
- 2.过滤出指定的行
- 语法:sed -n 'n,mp'文件名称
- [root@master demo]# sed -n '3,5p' d.txt 获取3-5行
- [root@master demo]# sed -n '5p' d.txt 获取第5行
- [root@master demo]# sed -n '5,$p' d.txt 获取从第5行开始的所有的行
-
- 3.替换文件中的关键字:
- 语法:sed 's/替换的内容/新的内容/g|n' 文件名称
- g:代表全局替换,就是替换文件中所有要替换的内容
- n:是一个数字,代表替换第几次出现的数据
- [root@master demo]# sed 's/s/o/g' d.txt 将所有的s替换为o
- [root@master demo]# sed 's/s/o/2' d.txt 将第二次出现的s替换为o
- [root@master demo]# sed 's/1[3-9][0-9]\{9\}/*****/g' a.txt 将文件中的所有的手机号替换为*****
awk
awk ‘BEGIN {commands} pattern {commands}END{commands}' file1
BEGIN:处理数据前执行的命令
END:处理数据后执行的命令
pattern:模式,每一行都执行的命令
BEGIN和END里的命令只是执行一次
pattern里的命令会匹配每一行去处理
- 1. awk -F ":" '{print $1,$2,$5}' /etc/passwd | head
-
-
- -F ":" : awk选项,指定输入分割符为:
-
- '{print}' : 固定语法
-
- $1,$2,$5 :输出第一个,第二个,第五个字段
-
- : 是输出分隔符,如果不加默认是没有分隔符的。
-
- 2. echo 'this is a test' | awk '{print $0}'
- this is a test
-
- 3. echo 'this is a test' | awk '{print $NF}'
- test #$NF表示最后一个字段,$(NF-1)表示倒数第二个字段。
-
- 4. cat awkdemo
- a:b
- c:d
-
- awk -v FS=':' '{print $1,$2}' demo #FS指定输入分隔符
- a b
- c d
-
-
- 5. awk -v FS=':' -v OFS='---' '{print $1,$2}' demo #OFS指定输出分隔符
- a---b
- c---d
-
- 6. awk -v RS=':' '{print $1,$2}' demo
- a
- b c
- d
-
- 7. awk -v FS=':' -v ORS='---' '{print $1,$2}' demo
- a b---c d
-
-
- 8. awk '{print FILENAME}' demo1
- demo1
-
- 9. awk 'BEGIN {print ARGC}' demo
- 2
- 10. awk 'BEGIN {print ARGV[0]}' demo1
- awk
- awk 'BEGIN {print ARGV[1]}' demo1
- demo1
-
内置函数对文本进行处理
-
tolower():字符转为小写。 -
length():返回字符串长度。 -
substr():返回子字符串。 -
sin():正弦。 -
cos():余弦。 -
sqrt():平方根。 -
rand():随机数。
- awk -F ':' '/usr/ {print $1}' demo.txt
- #print命令前面是一个正则表达式,只输出包含usr的行。
- awk -F ':' 'NR % 2 == 1 {print $1}' demo.txt
- #输出奇数行
- awk -F ':' 'NR >3 {print $1}' demo.txt
- #输出第三行后的行
- awk -F ':' '$1 == "root" {print $1}' demo.txt
-
- awk -F ':' '$1 == "root" || $1 == "bin" {print $1}' demo.txt
-
- #输出第一个字段等于指定值的行。
- awk -F ':' '{if ($1 > "m") print $1; else print "---"}' demo.txt
- #使用if语句
-
- 1. df -h |awk -F: '$0 ~ /^\/dev/' /dev/mapper/cl-root
- #查询以/dev开头的磁盘信息
- 模式匹配符:~ :左边是否和右边匹配包含
- !~ :是否不匹配
- 2. awk -F: '$3>=0 && $3<=10 {print $1,$3}' /aaa
-
- 3. awk -F: '$3==0 || $3>=10 {print $1}' /aaa
-
- 其他操作符
-
- 1.算术操作符:
-
- x+y, x-y, x*y, x/y, x^y, x%y
- -x: 转换为负数
- +x: 转换为数值
-
- 2.赋值操作符:
-
- =, +=, -=, *=, /=, %=, ^=, ++, --
-
- 3.比较操作符:
-
- ==, !=, >, >=, <, <=
-
cut
选项与参数:
-d:分隔符,按照指定分隔符分割列。与 -f 一起使用
-f:依据 -d 的分隔字符将一段信息分割成为数段,用 -f 取出第几段的意思(列号,提取第几列)
-c:以字符 (characters) 的单位取出固定字符区间
-b:以字节为单位进行分割
- [root@jiangnan data]$ touch cut.txt
- [root@jiangnan data]$ vim cut.txt
- dong shen
- guan zhen
- wo wo
- lai lai
- le le
- [root@jiangnan data]# cut -d ' ' -f 1 cut.txt
- dong
- guan
- wo
- lai
- le
- 切割cut.txt第二、三列
- [root@jiangnan data]# cut -d ' ' -f 2,3 cut.txt
- shen
- zhen
- wo
- lai
- le
- [root@jiangnan data]# cut -c 5-8 cut.txt
- she
- zhe
- wo
- lai
- le
- [root@jiangnan data]# cut -b 2,4,6 cut.txt
- ogs
- unz
- o o
- a l
- e e
-
-
-
-
网络命令
netstat
netstat 用来查看当前操作系统的网络连接状态、路由表、接口统计等信息,来自于 net-tools 工具包,ss 是 netstat 的升级版。
- [root@c7-1 ~]#netstat -anpt
- Active Internet connections (servers and established)
- Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
- tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 3631/master
- tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 3421/sshd
- tcp 0 0 20.0.0.19:22 20.0.0.1:64385 ESTABLISHED 20165/sshd: root@pt
- tcp 0 52 20.0.0.19:22 20.0.0.1:60938 ESTABLISHED 30806/sshd: root@pt
- tcp6 0 0 ::1:25 :::* LISTEN 3631/master
- tcp6 0 0 :::22 :::* LISTEN 3421/sshd
- [root@c7-1 ~]#netstat -anpt | grep sshd
- tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 3421/sshd
- tcp 0 0 20.0.0.19:22 20.0.0.1:64385 ESTABLISHED 20165/sshd: root@pt
- tcp 0 52 20.0.0.19:22 20.0.0.1:60938 ESTABLISHED 30806/sshd: root@pt
- tcp6 0 0 :::22 :::* LISTEN 3421/sshd
搭建hadoop平台 伪分布
1.先要设置静态网络ip和主机名
1.找到网络配置的文件所在的位置:
cd /etc/sysconfig/network-scripts
2.打开网络配置文件进行编辑:ifcfg-ens33
vi ifcfg-ens33
修改文件
按【i】进入编辑模式
BOOTPROTO=static
ONBOOT=yes
添加内容:
IPADDR=192.168.XXX.XXX
NETMASK=255.255.255.0
GATEWAY=192.168.XXX.2
DNS1=8.8.8.8
按【esc】退出编辑模式,然后再输入:wq保存退出


打开虚拟网络编辑器
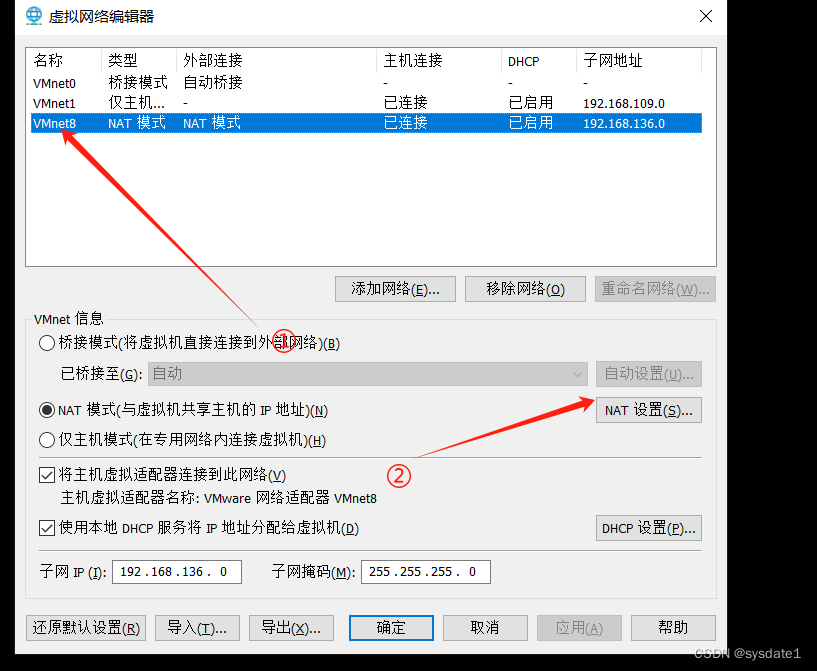
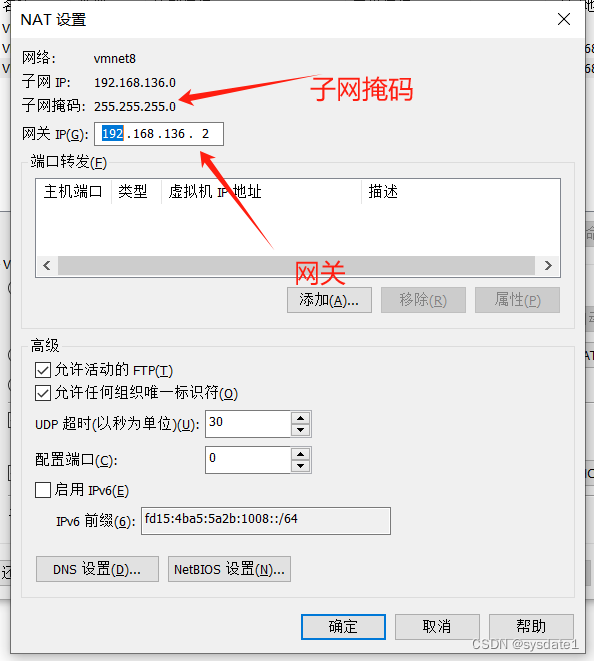


配置网关的ip 子网掩码 网关保持一致
vi /etc/sysconfig/network添加一下内容 NETWORKING=yes保存退出
重启网关service network restart 测试网络 ping baidu.com
修改主机名:
配置文件的地址:/etc 打开hostname文件,然后修改主机名
vi hostname 然后删除里面原来的内容,添加一个新的主机名即可
注意:主机名不允许有特殊符号出现,例如:- _ * . 等
将主机名和IP地址进行绑定映射
打开配置文件:/etc/hosts删除文件中原来的内容,输入一下内容
192.168.XXX.XXX 主机名保存退出
重启虚拟机reboot
2.搭建Hadoop平台:
安装包链接:https://pan.baidu.com/s/1awUyvoOZN1EKxSPhwmU3mA?pwd=7891
提取码:7891
hive是基于hadoop平台的数据仓库中的一个工具,主要就是对HDFS上保存的文件进行查询和操作。
hive:将编写的hivesql语句转换成mapreduce程序,然后mapreduce程序再进行操作hdfs上的数据。
物理机安装mysql数据库安装过程参考文档
使用mysql的客户端工具,在mysql中创建一个新的数据库,主要是用来保存hive中的元数据信息。
#创建一个数据库
CREATE DATABASE hive;
#给root用户授予允许远程访问mysql中的hive数据库的权限
GRANT ALL ON *.* TO root@'%' IDENTIFIED BY '123456';
#刷新权限
FLUSH PRIVILEGES;
免密设置:
查看当前服务器是否有免密登录: ssh 主机名 需要密码 就是没有设置
设置免密登录: ssh-keygen -t rsa 按 enter 键就行了直到结束
将公钥发送到目标主机 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
修改权限:chmod 0600 ~/.ssh/authorized_keys
测试;ssh 主机名
1.由于hadoop是java程序,所以再运行之前必须要先安装JDK环境
创建一个文件夹,来保存安装文件 mkdir bigdata
解压安装文件,解压到bigdata文件夹 tar -zxvf jdk-8u121-linux-x64.tar.gz -C bigdata/
进行环境变量的配置:vi /etc/profile
#配置JAVA_HOME路径
export JAVA_HOME=自己JDK安装的路径,
例如:export JAVA_HOME=/root/bigdata/jdk1.8.0_121
#将JAVA_HOME添加到系统的PAth路径中
export PATH=${PATH}:${JAVA_HOME}/bin
设置配置文件生效 source /etc/profile
验证是否安装成功 java -version
配置hadoop
上传安装包 进行解压:tar -zxvf hadoop-2.7.7.tar.gz -C bigdata/
配置hadoop的环境变量 vi /etc/profile
export HADOOP_PREFIX=自己Hadoop的安装路径
export PATH=${PATH}:${HADOOP_PREFIX}/bin
export PATH=${PATH}:${HADOOP_PREFIX}/sbin
设置配置文件生效 source /etc/profile
测试 hadoop version
配置hadoop 文件:
1.core-site.xml 文件 /root/bigdata/hadoop-2.7.7/etc/hadoop
vi core-site.xml
在configuration标签里面添加:
<!--配置hadoop集群服务器名称 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://主机名:8020</value>
</property>
2.hdfs-site.xml文件
在configuration标签里面添加:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/bigdata/hadoop-2.7.7/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/bigdata/hadoop-2.7.7/dfs/data</value>
</property>
3.mapred-site.xml
将mapred-site.xml.template文件复制一份重命名为:mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
在configuration标签里面添加:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
4.yarn-site.xml
vi yarn-site.xml
在configuration标签里面添加:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>主机名:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>主机名:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>主机名:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>主机名:8033</value>
</property>
5.slaves
vi slaves
然后将里面的内容修改为当前的主机名
6.hadoop-env.sh
vi hadoop-env.sh
修改其中JAVA_HOME的路径
# The java implementation to use.
export JAVA_HOME=自己JDK安装的路径
7.在启动之前需要格式化一些主服务器 hadoop namenode -format
8.启动hadoop平台 start-all.sh
9.使用jps查看java进程jps 有以下这几个进程,说明配置没有问题
2096 ResourceManager
2211 NodeManager
1669 NameNode
2454 Jps
1754 DataNode
1951 SecondaryNameNode
10.如果在启动之后缺少进程或者是进程不全 前提:保证配置文件没有问题的前提下
1.关闭hadoop平台 stop-all.sh
2.删除hadoop安装目录下面的生成的dfs文件夹和logs文件夹
3.重新格式化主节点 hadoop namenode -format
4.重新启动hadoop平台 start-all.sh
在伪分布的基础上搭建完全分布
服务器规划:准备3台服务器:(使用虚拟机虚拟出来3台服务器)
按照 1 修改网络ip 和主机名 特别注意每台机器的mac地址要不一样
在hostname文件 写上三台机器的ip 以及 主机名 每一台机器slaves添加三台主机名


1.将原来伪分布的服务器关机,然后复制两份
2.使用虚拟机软件打开复制的虚拟机,然后修改对应的MAC地址,IP地址(ifcfg-ens33),主机名(hostname),主机映射(hosts),确保每一台服务器都能够正常上网。
3.将每一台服务器中的hadoop配置文件中的slaves文件添加所有的子服务器的主机名
4.验证服务器之间是否可以正常的免密登录
5.删除每个服务器中的hadoop安装目录下的dfs和logs文件夹
4.格式化主服务器(只在主服务器中格式化即可)hadoop namenode -format
6.启动服务(只启动主服务器即可)start-all.sh
7.验证是否启动成功
8.如果在重启网络的时候启动失败:
前提:已经修改了MAC地址
解决办法:1.查看网络配置文件是否有问题
2.禁用NetworkManager服务
systemctl stop NetworkManager
systemctl disable NetworkManager
#重启网络
service network restart
可以访问hadoop平台的web端系统:http://ip:50070
3.hive 安装 仅主服务器安装即可
将hive的安装文件解压到bigdata文件夹下面: tar -zxvf apache-hive-2.3.3-bin.tar.gz -C bigdata
重命名解压后的文件名称 mv bigdata/apache-hive-2.3.3-bin/ bigdata/hive2.3.3
配置环境变量:vi /etc/profile
#hive的环境变量
export HIVE_HOME=/root/bigdata/hive2.3.3
export HIVE_CONF_DIR=/root/bigdata/hive2.3.3/conf
export PATH=${PATH}:${HIVE_HOME}/bin
设置配置文件生效 source /etc/profile
测试 hive --version 出现版本号说明配置成功
修改hive的配置文件:主要配置元数据库的信息
在hive的配置文件的路径下面创建一个新的文件:hive-site.xml
vi /root/bigdata/hive2.3.3/conf/ hive-site.xml
添加以下内容
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License a
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.-->
<configuration>
<!-- WARNING!!! This file is auto generated for documentation purposes ONLY! -->
<!-- WARNING!!! Any changes you make to this file will be ignored by Hive. -->
<!-- WARNING!!! You must make your changes in hive-site.xml instead. -->
<!-- Hive Execution Parameters -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://物理机ip:3306/hive?useSSL=FALSE</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value> mysql密码
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.scratch.dir.permission</name>
<value>733</value>
</property>
</configuration>
将mysql的驱动包保存到hive安装目录下面的lib文件夹下面
初始化元数据库(只能成功初始化一次)schematool -dbType mysql -initSchema
查看mysql中的元数据库中的表是否生成,如果生成则代表格式化成功,否则代表格式化失败。
测试
可以使用hive命令来进入hive,进行数据操作
注意:在使用hive之前必须要将hadoop平台起来。输入hive即可
常见的hivesql操作:
1.查看hive中的所有的数据库s how databases;
2.切换数据库 use 数据库名;
3.创建一个新的数据库 create database 数据库名;
4.查看当前所在的数据库 select current_database();
5.查看数据库下面的所有的表show tables;
6.退出hive exit;
由于hadoop2.X本版中为了安全性考虑,在来连接hadoop平台的时候需要给用户进行设置授权。
在hadoop的核心配置文件中添加以下内容:core-site.xml,修改之前需要先关闭hadoop平台
<!--设置权限-->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
修改完配置文件之后需要重启hadoop平台,然后开启hive服务
将HDFS上根目录的权限修改为777,在修改的时候是要使用-R hdfs dfs -chmod -R 777 /
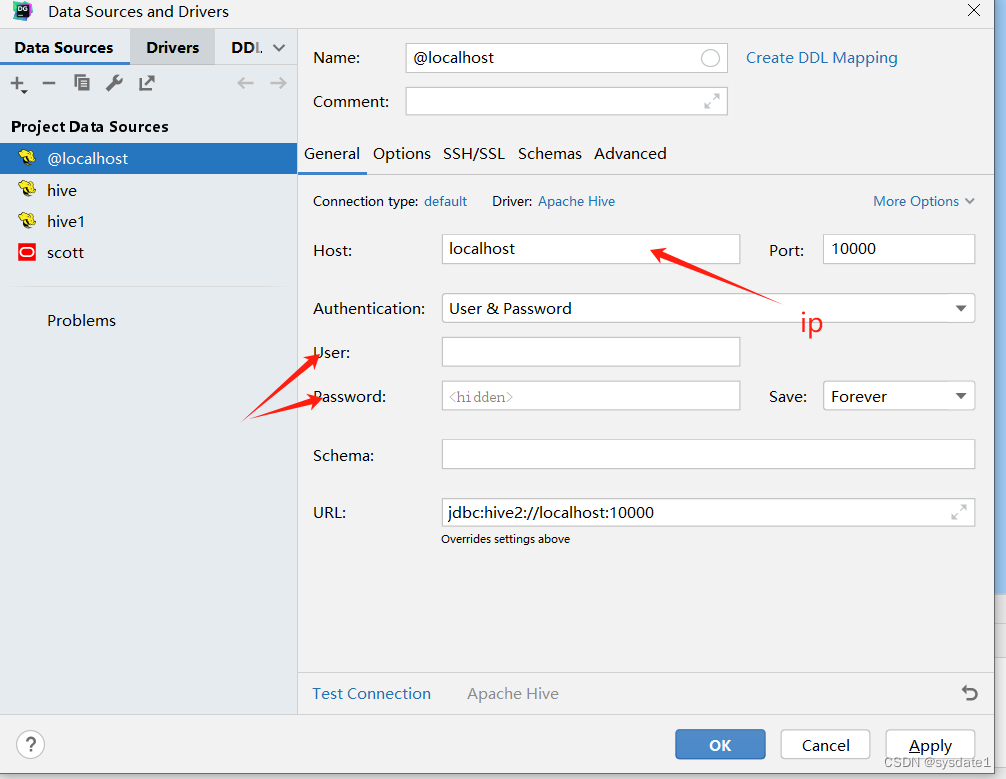
datagrip:可以连接
SQOOP 安装
将hadoop中的数据导出到关系型数据库中,或者可以将关系型数据库中的数据导入hadoop平台中。
由于sqoop依附于hadoop的一个组件,所以在使用之前必须要先将sqoop集成到hadoop中
集成sqoop
准备工作:
准备各种关系型数据库的驱动包
mysql驱动包:mysql-connector-java-5.1.49.jar
oracle驱动:ojdbc6.jar
将压缩文件解压到指定的路径tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C bigdata/
将解压文件进行重名了mv bigdata/sqoop-1.4.7.bin__hadoop-2.6.0/ bigdata/sqoop1.4
添加环境变量vi /etc/profile
添加一下环境变量
#添加sqoop的路径
export SQOOP_HOME=/root/bigdata/sqoop1.4
export PATH=${PATH}:${SQOOP_HOME}/bin
export CATALINA_BASE=${SQOOP_HOME}/server
export LOGDIR=${SQOOP_HOME}/logs
设置配置文件生效source /etc/profile
修改sqoop的配置文件
将sqoop安装目录下面的conf下面的配置文件sqoop-env-template.sh复制一份,
命名为sqoop-env.sh cp sqoop-env-template.sh sqoop-env.sh
打开复制之后的文件: vi sqoop-env.sh
将一下路径前面的#删除,并且添加对应的路径
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/root/bigdata/hadoop-2.7.7
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/root/bigdata/hadoop-2.7.7
#Set the path to where bin/hive is available
export HIVE_HOME=/root/bigdata/hive2.3.3
将数据库的驱动包放到sqoop安装路径下面的lib文件夹中
mysql驱动包:mysql-connector-java-5.1.49.jar
测试是否安装成功
sqoop version
测试是否能够连接数据库
sqoop list-databases \
--connect jdbc:mysql://ip:3306 \
--username root \
--password 123456

