
- 1【包邮送书】你好!Python
- 2关于java运行环境的配置
- 3MATLAB实现遗传算法_如何用matlab实现遗传算法解决多规格一维下料问题
- 4人工智能发展史_早期人工智能应用
- 5使用obsidian数据同步至Git,从而解决obsidian多端同步收费的问题-windows_obsidian远程仓库
- 6详细图解如何注册 Navicat for Mysql 11.0.17 企业版(Win7 64bit)_navicat premium11.0.17注册码
- 7【PostgreSQL的四种进程间锁】_谓词锁
- 8常用模拟低通滤波器的设计~经典 IIR 滤波器之椭圆滤波器
- 9头歌python答案 实验6:Python函数_头歌python函数实训答案
- 10PMP项目管理的前路_现在随着经济的发展,时代的进步,国内很多企业对持有pmp证书的项目管理人才的需求
SQL底层执行过程
赞
踩
MySQL 的查询流程
- 客户端请求
- 连接器
负责与客户端的通信,是半双工模式(半双工(Half Duplex)数据传输指数据可以在一个信号载体的两个方向上传输,但是不能同时传输。),验证请求用户的账户和密码是否正确,③如果用户的账户和密码验证通过,会在MySQL自带的权限表中查询当前用户的权限:
验证用户身份,给予权限
- 查询缓存
MySQL的缓存主要的作用是为了提升查询的效率,缓存以key和value的哈希表形式存储,key是具体的sql语句,value是结果的集合。如果无法命中缓存,就继续走到分析器的的一步,如果命中缓存就直接返回给客户端 。(存在缓存则直接返回,不存在则执行后续操作)
- 分析器
分析器的主要作用是将客户端发过来的sql语句进行分析,这将包括预处理与解析过程,在这个阶段会解析sql语句的语义,并进行关键词和非关键词进行提取、解析,并组成一个解析树。具体的关键词包括不限定于以下:select/update/delete/or/in/where/group by/having/count/limit等.如果分析到语法错误,会直接给客户端抛出异常:ERROR:You have an error in your SQL syntax.(对SQL进行词法分析和语法分析操作)
- 优化器
主要对执行的sql优化选择,最优的执行方案方法(判断走哪个索引)
- 执行器
执行时会先看用户是否有执行权限,有才去使用这个引擎提供的接口
- 去引擎层获取数据返回
如果开启查询缓存则会缓存查询结果
在mysql8.0后,放弃缓存机制。原因在于:如果对表数据进行表更新操作某一条数据,无法查找那条已缓存的数据进行并进行更改,而是对更新操作对那张表所有缓存数据进行清空
SQL在引擎层执行过程(INNODB引擎)
在掌握SQL在引擎层的执行过程,首先需要掌握以下几个知识点
缓存池(Buffer Pool)
数据库的CURD操作都是直接操作Buffer Pool,默认大小128M,一般设置为机器内存的60%~70%。
缓存池数据结构= 描述信息(数据页的元数据信息,包括数据页所属表空间、数据页编号)+缓存页
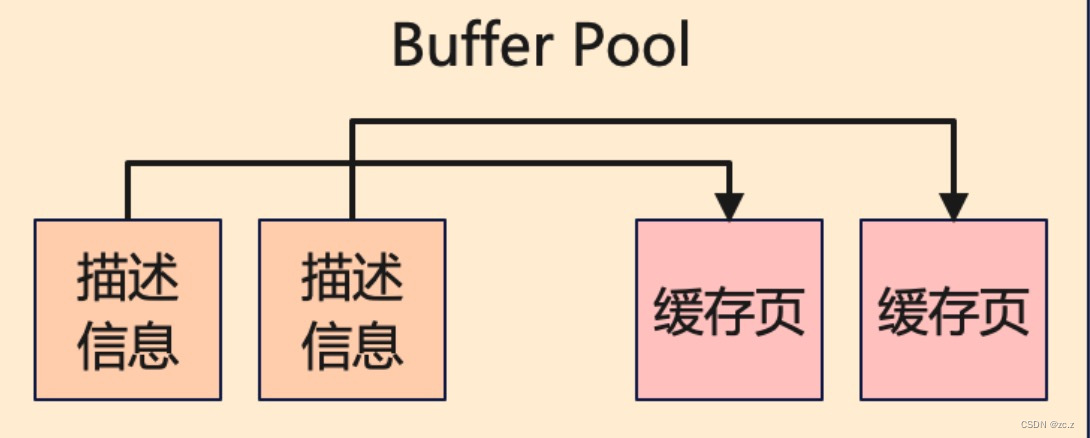
InnoDB的缓冲池设计的思路
- 磁盘访问按页读取能够提高性能,所以缓冲池一般也是按页缓存数据;
- 预读机制启示了我们,能把一些“可能要访问”的页提前加入缓冲池,避免未来的磁盘IO操作;
Buffer Pool中哪些是空闲的缓存页
MYSQL引入了一个链表来帮助我们找到空闲的缓存页,叫free链表,是一个双向链表,链表节点是空闲的缓存页对应的描述信息块(空的缓存页)。
free加载的时机:数据库启动时,如果缓存页不够用了
如何数据是否在Buffer Pool中(查询)
MYSQL中还有一个哈希表数据结构,用表空间号+数据页号作为key,缓存页的地址作为value。当需要操作数据页时,首先从哈希表中根据"表空间号+数据页号"作为key进行查询,如果查询不为空的话证明数据页已经被缓存了;如果查询为空,则从磁盘进行加载,并将数据写入该哈希表,下次再使用这个数据页,就可直接从哈希表中读取。
更新Buffer Pool中的数据
当我们对数据进行更新操作时,由于是直接操作Buffer Pool缓存中的数据,势必会导致和磁盘文件中的数据页不一致,这些不一致的数据页就叫脏页。
脏页是需要刷盘的,那刷盘的时候怎么知道哪些数据页需要刷,哪些不需要刷呢?因为不可能每个数据页都刷一遍,这样效率太低了。
解决脏页的方案:MYSQL引入了另一个链表来记录更新过的脏页数据,叫flush链表。通过这个flush链表,就能记录目前哪些缓存页是脏页,刷盘的时候后台线程只需要处理这个链表上面记录的数据页即可,刷盘结束后,将节点从链表上抹去。
Buffer Pool内存空间不足
基于LRU算法淘汰Buffer Pool内部缓存页,缓存命中率低的缓存页会被淘汰。引入一个新的LRU链表来记录,缓存页的命中情况(最新访问的缓存页一定在LRU头部,链表尾巴的肯定是命中率比较低的,需要被淘汰)
- 普通LRU有什么问题
容易出现预读失效 预读:由于预读(Read-Ahead),提前把页放入了缓冲池,但最终MySQL并没有从页中读取数据,称为预读失效。
容易出现缓冲池污染 缓冲池污染:当某一个SQL语句,要批量扫描大量数据时,可能导致把缓冲池的所有页都替换出去,导致大量热数据被换出,MySQL性能急剧下降,这种情况叫缓冲池污染。 eg: select * from user where name like "%shenjian%"; 虽然结果集可能只有少量数据,但这类like不能命中索引,必须全表扫描,就需要访问大量的页。
- MYSQL对LRU算法进行的优化
- 冷热数据分离,可以将LRU链表分为两个,一个存放冷数据,一个存放热数据
回滚日志(undo日志)
回滚日志,保存了事务发生之前的数据的一个版本,用于事务的回滚操作。
- 事务发生错误时回滚rollback,数据更新之前,会把原始数据保存在回滚日志中,保证事务出错回滚或者我们手动回滚的时候,能够在回滚日志中找到最初的数据。
- 提供了MVCC的非锁定读(快照读),依赖undo log实现。
重做日志(redo 日志)
redo 日志是为了在系统因奔溃而重启时恢复奔溃前的状态而提出的。lnnoDB 存储引擎是以页为单位来管理存储空间的,我们进行的增删改查操作从本质上来说都是在访问页面(包括读页面、写页面、创建),其实都在缓存池中操作。如果系统崩溃,可以通过该日志将数据加载到磁盘中,确保缓存池的数据和磁盘数据保持一致(redo 日志是用来保证 MySQL 持久化功能的)。
二进制日志(binlog日志 )
Bin Log是一个二进制格式的文件,是MySQL最重要的日志,它记录了所有的DDL及DML语句(除了数据查询select、show等),以事件形式记录,还包含语句所执行的消耗时间,MySQL的二进制日志是事务安全型的。binlog 的主要目的是复制和恢复(mysqlbinlog来恢复)。
错误日志(error日志)
记录中MySQL启动和关闭服务的时候详细的日志信息,包括在MySQL实例在运行过程中遇到的错误、警告等信息也会记录在error log中。
SQL在引擎层执行步骤
以update 语句为例:update table set name="123" where id = 666
- 第一步
首先先判断数据是否在Buffer Pool的页中,如果不在,加载id为666的数据所在的缓存页加载到Buffer pool中。
- 第二步
写入更新数据前的旧数据到undo日志中
- 第三步
在Buffer Pool中对数据进行更新操作
- 第四步
写redo日志(在哪页做了修改),redo日志顺序写入磁盘,准备提交事务(prepare阶段)
- 第五步
准备提交事务,binlog日志写入磁盘中
- 第六步
写commit标记事务到redo日志中,保证redo日志和binlog日志保持一致
- 第七步
在系统空闲,将数据写入磁盘中,以页的形式
Redolog和binlog区别
redolog是循环写的,空间固定会用完;binlog是可以追加写的
redolog是InnoDB存储引擎特有的日志,用于记录事务的操作,包括对数据的修改、插入和删除等。redolog是在内存中缓存的,当事务提交时,会将redolog写入磁盘中的redo log文件中,以保证数据的持久性。
binlog是MySQL服务器的日志,用于记录所有的数据库操作,包括对数据的修改、插入和删除等。binlog是在磁盘上的文件,可以用于数据备份、恢复和复制等操作。
、
mysql redo log为什么有两阶段提交/为什么有prepare和commit两个状态
为了解决redo log和binlog不一致的问题。
我们直接提交事务,直接写入redo不可以吗,为什么要设置两阶段提交的机制呢?
这里我们逆向推导,现有这样一个更新操作,要将某表中的一个字段state从1改为0
1、如果是先写入redo,再写入binlog:
如果刚写完redo,服务崩溃了,再次重启时需要做数据恢复
因为这里redo已经写入完成了,事务已经生效,所以我们数据恢复就要恢复成事务完成后的状态,即将state恢复为0;重启服务后,因为有redo记录,数据会更新成0,但是如果这时执行了binlog的数据恢复,因为binlog是没有这条操作记录的,针对state的上一次记录是1,则会恢复为1,与我们想要恢复的值不符,也就产生了问题
2、如果是先写入binlog,再写入redo:
如果刚写完binlog,服务崩溃了,同样重启后需要做数据恢复
因为redo中没有这条操作的记录,事务没有生效,所以数据恢复是要恢复成事务开始之前的状态,即将state恢复成1;重启服务后,因为没有redo记录,系统不做事务操作,但是有binlog中‘1变成0’的记录,这时进行数据恢复,会将数据更新为0(产生了一个新的事务),与我们想要恢复的值也不同
可以使用binlog替代redolog进行数据恢复吗?
不可以
innodb利用wal技术进行数据恢复,write ahead logging技术依赖于物理日志进行数据恢复,binlog不是物理日志是逻辑日志,因此无法使用;
那么,为什么write ahead logging技术不可以使用逻辑日志进行数据恢复呢?这个问题可以考虑一下自增锁的场景,当自增锁的模式设置为innodb_autoinc_lock_mode = 2时,mysql会锁住分配自增值的代码逻辑,不去进行自增值的预分配,由此带来的问题就是,高并发场景下多个事务中的insert(单条insert语句包含多个待插入值)逻辑会造成自增ID不固定的问题,由此带来的结果就是,利用binlog中的逻辑日志进行主从复制时,从库中的ID和主库中的ID不一致。因此,在特定场景下,逻辑日志相对于物理日志,显得不是那么可靠。
可以只使用redolog而不使用binlog吗?
不可以
redolog是循环写,写到末尾要回到开头继续写,这样的日志无法保留历史记录,无法进行数据复制。
个人理解redolog其实是物理数据的一个缓存,理论上可以不需要redolog,插入的数据落盘后再返回插入成功,但是数据落盘的过程比较耗时,需要更新各种索引(B+树),因此现在数据落入redolog即返回成功,加快了返回速度。
为什么执行顺序是: redolog(prepare 准备状态)--->binlog--->redo log(commit 提交状态)?
假设执行顺序是 redolog(提交)- binlog
发生异常重启的状况,导致数据日志丢失
binlog日志丢失:对于一个数据库来说,当数据写入了(redolog记录到),但是没有写入记录(binlog没记录到)。相当于一个数据库只有数据,没有该数据的记录,一致性出错!
redolog日志丢失:对于一个数据库来说,当数据没有写入(redolog没记录到),但是却有记录(binlog记录到)。相当于对一个数据库来说,该数据有记录,但是查不到。
因此这也是为什么增删改语句的时候,执行顺序是:
redo log(prepare 状态)--->binlog--->redo log(commit状态)
这个时候发生了异常重启会怎么样呢? 这个就要依赖于 MySQL 的处理机制了,MySQL 的处理过程如下:
判断 redo log的状态,如果判断是是commit状态,就立即提交。
如果 redo log 只是预提交但不是 commit 状态,这个时候就会去判断 binlog 是否完整,如果完整就提交 redo log, 不完整就回滚事务。
结论:执行顺序很重要,这样执行的最终目的就是保持一致性!
有了redo log,为啥还需要binlog呢?
1、redo log 文件是固定大小的,是循环写的,写满了会从头继续写,而 binlog 是追加写的,写满了再新建文件接着写。
2、redo log是innodb引擎层实现的,并不是所有引擎都有。

