
热门标签
热门文章
- 1什么是AI绘画工具Stable Diffusion?如何安装使用?保姆级教程建议收藏!_秋叶整合包v4.7怎么安装controlnet
- 2AndroidStudio无法新建Java工程解决办法_android studio版本为什么新建不了java类,怎么解决
- 3【Git】概念_git概念
- 4文本识别之CRNN+CTC_crnn+ctc训练曲线
- 5逻辑树分析模型_逻辑树分析项目延期
- 6IDEA下载Maven依赖包报错:Could not transfer artifact org.springframework.boot:spring-boot-starter-parent:pom_idea could not transfer artifact org.springframewo
- 7js中防抖的实现_js防抖
- 8H5端实现扫一扫功能_h5 微信 扫一扫
- 9STM32单片机+机智云AIoT+智能服药箱_基于stm32智能药箱设计主要内容500字
- 10git命令下载远程分支代码_git远程创建分支,本地需要重新下载代码吗
当前位置: article > 正文
【Pytorch神经网络实战案例】30 jieba库分词+训练中文词向量_jieba如何训练语言词义
作者:IT小白 | 2024-05-07 04:03:24
赞
踩
jieba如何训练语言词义

1 安装jieba
1.1 安装
pip install jieba1.2 测试
- import jieba
- seg_list = jieba.cut("谭家和谭家和")
- for i in seg_list:
- printf(i);
1.3 词向量
在NLP中,一般都会将该任务中涉及的词训练成词向量,然后让每个词以词向量的形式型的输入,进行一些指定任务的训练。对于一个完整的训练任务,词向量的练大多发生在预训练环节。
除了从头训练词向量,还可以使用已经训练好的词向量。尤其在样本不充足的情况下,可以增加模型的泛化性。
通用的词嵌入模型常以key-vaue的格式保存,即把词对应的向量一一列出来。这种方式具有更好的通用性,它可以不依赖任何框架。
2 代码实现:训练中文词向量
2.1 样本预处理并生成字典---skip_gram.py(第一部分)
- # 1.1 样本预处理并生成字典
- # 使用get_ch lable函数将所有文字读入raining_data,然后在fenci函数里使用jeba库对ci放入buld_dataset里并生成指定长度(350)的字典。
-
- # 指定设备
- device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
- print(device)
- training_file = './data/一大段文本.txt'
-
- # 中文字
- def get_ch_lable(txt_file): # 获取文件内的文本信息
- labels= ""
- with open(txt_file, 'rb') as f:
- for label in f:
- labels =labels+label.decode('gb2312')
- return labels
-
- # 分词
- def fenci(training_data):
- seg_list = jieba.cut(training_data) # 默认是精确模式
- training_ci = " ".join(seg_list)
- training_ci = training_ci.split()
- # 以空格将字符串分开
- training_ci = np.array(training_ci)
- training_ci = np.reshape(training_ci, [-1, ])
- return training_ci
-
- # build dataset()函数实现了对样本文字的处理。
- # 在该函数中,对样本文字的词频进行统计,将照频次由高到低排序。同时,将排序后的列表中第0个索引设置成unknown(用“UNK”表示),
- # 这个unknown字符可用于对词频低的词语进行填充。如果设置字典为350,则频次排序在350的词都会被当作unknown字符进行处理。
- def build_dataset(words,n_words): #
- count = [['UNK', -1]]
- count.extend(collections.Counter(words).most_common(n_words - 1))
- dictionary = dict()
- for word, _ in count:
- dictionary[word] = len(dictionary)
- data = list()
- unk_count = 0
- for word in words:
- if word in dictionary:
- index = dictionary[word]
- else:
- index = 0 # dictionary['UNK']
- unk_count += 1
- data.append(index)
- count[0][1] = unk_count
- reversed_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
-
- return data, count, dictionary, reversed_dictionary
-
- training_data = get_ch_lable(training_file)
- print("总字数",len(training_data)) # 1567
- training_ci =fenci(training_data)
- print("总词数",len(training_ci)) #
- training_label, count, dictionary, words = build_dataset(training_ci, 350)
-
- #计算词频
- word_count = np.array([freq for _,freq in count], dtype=np.float32)
- word_freq = word_count / np.sum(word_count)#计算每个词的词频
- word_freq = word_freq ** (3. / 4.)#词频变换
- words_size = len(dictionary)
- print("字典词数",words_size) # 350
- print('Sample data', training_label[:10], [words[i] for i in training_label[:10]]) # # 显示的是样本文字里前10个词的词频。
2.2 代码实现:按照skip-Gram模型的规则制作数据集---skip_gram.py(第二部分)
- # 1.2 按照skip-Gram模型的规则制作数据集
- # 使用Dataset与Dataloader接口制作数据集。
- # 在自定义Dataset类中,按照Skip-Gram模型的规则对样本及其对应的标签进行组合。
- # 每批次取12个,每个词向量的维度为128,中心词前后的取词个数为3,负采样的个数为64。具体代码如下。
-
- C = 3 # 定义中心词前后的取词个数
- num_sampled = 64 # 负采样个数
- BATCH_SIZE = 12
- EMBEDDING_SIZE = 128
-
- class SkipGramDataset(Dataset): # 自定义数据集
- # 样本中的每个词都被当作一个中心词,对于任意一个样本中心词,都会生成两组标签:正向标签与负向标签。
- # 正向标签来自中心词的前后位置,负向标签主要来自词频的多项式来样。
- def __init__(self,training_label,word_to_idx,idx_to_word,word_freqs):
- super(SkipGramDataset, self).__init__()
- self.text_encode = torch.Tensor(training_label).long()
- self.word_to_idx = word_to_idx
- self.idx_to_word = idx_to_word
- self.word_freqs = torch.Tensor(word_freqs)
-
- def __len__(self):
- return len(self.text_encode)
-
- def __getitem__(self, idx):
- idx = min(max(idx,C),len(self.text_encode)-2-C) # 防止越界:对组合标签过程中的越界问题做了处理,使提取样本的索引为3~(总长度-5)。
- center_word = self.text_encode[idx]
- pos_indices = list(range(idx-C,idx)) + list(range(idx+1,idx+1+C))
- pos_words = self.text_encode[pos_indices]
- # ---start---对负向标签进行采样。在使用多项式分布采样之后,还要从中去掉与正向标签相同的索引。其中np.setdiff1d()函数用于对两个数组做差集。
- # 多项式分布采样,取出指定个数的高频词
- neg_words = torch.multinomial(self.word_freqs, num_sampled + 2 * C, False) # True)
- # 去掉正向标签
- neg_words = torch.Tensor(np.setdiff1d(neg_words.numpy(), pos_words.numpy())[:num_sampled]).long()
- # ---end---对负向标签进行采样。在使用多项式分布采样之后,还要从中去掉与正向标签相同的索引。其中np.setdiff1d()函数用于对两个数组做差集。
- return center_word, pos_words,neg_words
-
- print("制作数据集...")
- train_dataset = SkipGramDataset(training_label,dictionary,words,word_freq)
- dataloader = torch.utils.data.DataLoader(train_dataset,batch_size=BATCH_SIZE,drop_last=True,shuffle=True)
- sample = iter(dataloader) #将数据集转化成迭代器
- center_word, pos_words, neg_words = sample.next() #从迭代器中取出一批次样本
- print(center_word[0],words[np.long(center_word[0])],[words[i] for i in pos_words[0].numpy()])
2.3 搭建模型并进行训练
2.3.1 余弦定理

2.3.2 代码片段

2.3.3 词嵌入夹角余弦结构

2.3.4 代码实现:搭建模型并进行训练---skip_gram.py(第三部分)
- # 1.3 搭建模型并进行训练
- # 首先定义一个词嵌入层用手训练,将输入的样本和标签分别用词嵌入层进行转化。
- # 在训练过程中,将输入与标签的词嵌入当作两个向量,将二者的矩阵相乘当作两个向量间的夹角余弦值,并用该夹角余弦值作为被优化的损失函数。
- # 在训练模型时,定义了验证模型的相关参数,其中valid_size表示在0~words_size/2中随机取不能重复的16个字来验证模型。
- class Model(nn.Module):
- def __init__(self,vocab_size,embed_size):
- super(Model, self).__init__()
- self.vocab_size = vocab_size
- self.embed_size = embed_size
- initrange = 0.5 / self.embed_size
- self.in_embed = nn.Embedding(self.vocab_size, self.embed_size, sparse=False)
- self.in_embed.weight.data.uniform_(-initrange, initrange)
-
- def forward(self,input_lables,pos_labels,neg_labels):
- # LogSigmoid激活函数,该激活函数的值域是(-inf,0](inf是无穷值的意思),即当输入值越大,输出值越接近于0。
- # 如果将输入样本的词嵌入和目标标签的词嵌入分别当作两个向量,则可以用这两个向量间的夹角余弦值来当作二者的相似度。
- # 为了规范计算,先通过LogSigmoid激活函数中的Sigmoid函数将参与运算的向量控制为0~1,再从正 / 负标签两个方向进行相似度计算:
- # ① 对于正向标签,可以直接进行计算:
- # ② 对于负向标签,可以先用1减去输入样本的词嵌入,得到输入样本对应的负向量,再将该结果与负向标签的词向量一起计算相似度。
- # 根据Sigmoid函数的对称特性1 - Sigmoid(x) = Sigmoid(-x),可以直接对输入样本词向量的符号取负来实现向量的转化。
- input_embedding = self.in_embed(input_lables)
- pos_embedding = self.in_embed(pos_labels)
- neg_embedding = self.in_embed(neg_labels)
-
- # 计算输入与正向标签间的夹角余弦值:用bmm函数完成两个带批次数据的矩阵相乘【bmm函数处理的必须是批次数据,即形状为{b,m,n]与[b,n,m]矩阵相乘;】
- log_pos = torch.bmm(pos_embedding, input_embedding.unsqueeze(2)).squeeze()
- # 计算输入与负向标签间的夹角余弦值:用bmm函数完成两个带批次数据的矩阵相乘【bmm函数处理的必须是批次数据,即形状为{b,m,n]与[b,n,m]矩阵相乘;】
- log_neg = torch.bmm(neg_embedding, -input_embedding.unsqueeze(2)).squeeze() # 在计算输入与负向标签间的夹角余弦值时,使用样本词嵌入的赋值。这样做与使用LogSigmoid激活函数有关。
- # 使用LogSigmoid激活函数
- log_pos = F.logsigmoid(log_pos).sum(1)
- log_neg = F.logsigmoid(log_neg).sum(1)
- loss = log_pos + log_neg
- return -loss # 对最终的损失值取负,将损失函数的值域由(-inf,0]变为(0,inf]。这种变换有利于使用优化器在迭代训练中进行优化(因为优化器只能使损失值沿着最小化的方向优化)。
- # 实例化模型
- model = Model(words_size,EMBEDDING_SIZE).to(device)
- model.eval()
- # 定义测试样本
- valid_size = 16
- valid_window = words_size/2 # 取样数据的分布范围
- valid_examples = np.random.choice(int(valid_window),valid_size,replace=True) #0- words_size/2,中的数取16个。不能重复。
-
- optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
-
- NUM_EPOCHS = 200
-
- for e in range(NUM_EPOCHS): # 训练模型
- for ei, (input_labels, pos_labels, neg_labels) in enumerate(dataloader):
- input_labels = input_labels.to(device)
- pos_labels = pos_labels.to(device)
- neg_labels = neg_labels.to(device)
-
- optimizer.zero_grad()
- loss = model(input_labels, pos_labels, neg_labels).mean()
- loss.backward()
- optimizer.step()
-
- if ei % 20 == 0: # 显示训练结果
- print("epoch: {}, iter: {}, loss: {}".format(e, ei, loss.item()))
- if e % 40 == 0: # 测试模型
- # ---start---实现对现有模型的能力测试。该代码会从验证样本中取出指定的个数的词,通过词嵌入的转化,在已有的训练样本中找到与其语义相近的词,并显示出来。
- # 计算测试样本词嵌入和所有样本词嵌入间的余弦相似度
- norm = torch.sum(model.in_embed.weight.data.pow(2), -1).sqrt().unsqueeze(1) # norm代表每一个词对应向量的长度矩阵,见式(3-5)。
- normalized_embeddings = model.in_embed.weight.data / norm # normalized_embeddings表示向量除以自己的模,即单位向量。它可以确定向量的方向。
- valid_embeddings = normalized_embeddings[valid_examples]
- # 计算余弦相似度:用mm函数完成矩阵相乘【mm函数处理的是普通矩阵数据,即形状为[m,n]与[n,m]矩阵相乘】
- similarity = torch.mm(valid_embeddings, normalized_embeddings.T) # similanity就是valid_dataset中对应的单位向量vald_embeddings与整个词嵌入字典中单位向量的夹角余弦。
- for i in range(valid_size):
- valid_word = words[valid_examples[i]]
- top_k = 8 # 取最近的排名前8的词
- # similarity就是当前词与整个词典中每个词的夹角余弦,夹角余弦值越大,就代表相似度越高。
- nearest = (-similarity[i, :]).argsort()[1:top_k + 1] # argsort()用于将数组中的值按从小到大的顺序排列后,返回每个值对应的索引。在使用argsort函数之前,将similarity取负,得到的就是从小到大的排列。
- log_str = 'Nearest to %s:' % valid_word # 格式化输出日志
- for k in range(top_k):
- close_word = words[nearest[k].cpu().item()]
- log_str = '%s,%s' % (log_str, close_word)
- print(log_str)
- # ---end---实现对现有模型的能力测试。该代码会从验证样本中取出指定的个数的词,通过词嵌入的转化,在已有的训练样本中找到与其语义相近的词,并显示出来。
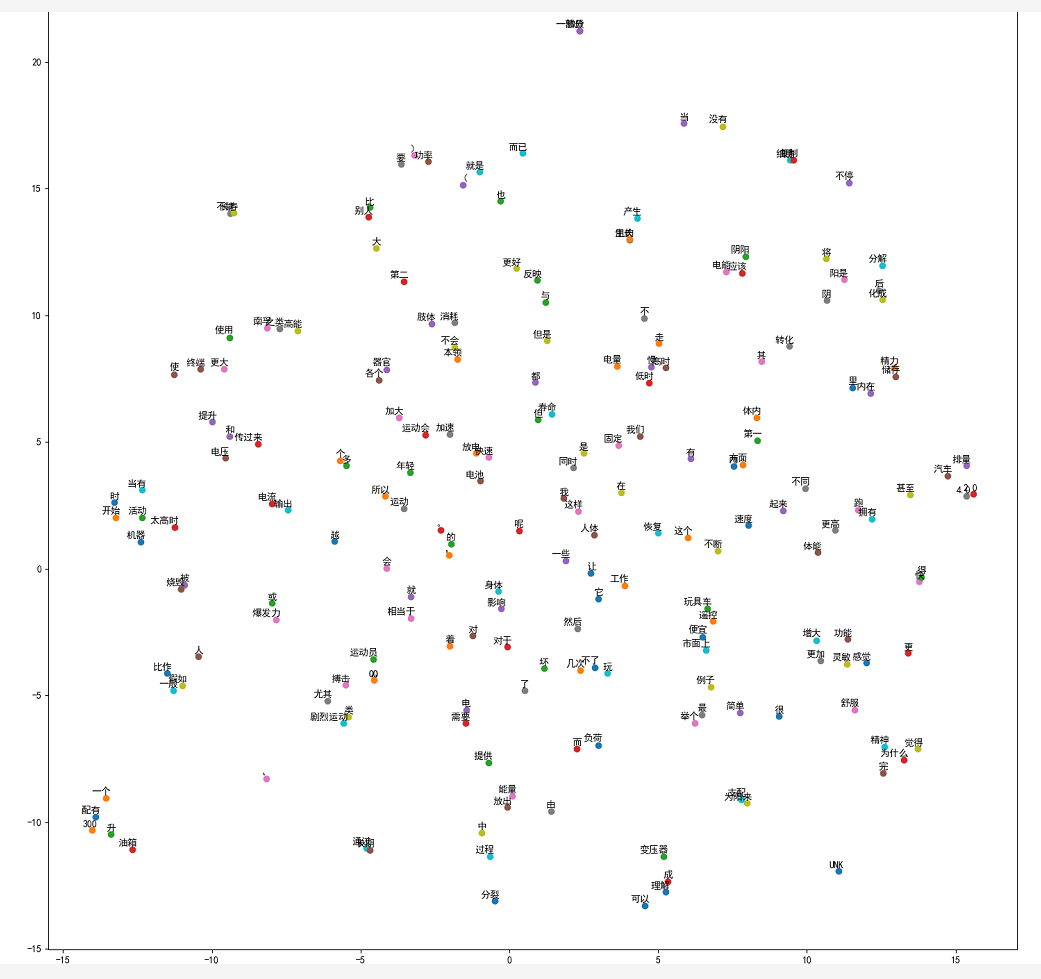
2.4 代码实现:实现词向量可视化---skip_gram.py(第四部分)
- # 1.4 实现词向量可视化
- # 对与可视化相关的引入库做了初始化,具体说明如下:
- # ①通过设置mpl的值让p|ot能够显示中文信息。
- # ②Scikit-learn(也称为sklearn)库的t-SNE算法模块,作用是非对称降维。
- # t-SNE算法结合t分布,将高维空间的数据点映射到低维空间的距离,主要用于可视化和理解高维数据。
- #
- # 将词典中的词嵌入向量转成单位向量(只有方向),然后将它们通过t-SNE算法降维映射到二维平面中进行显示。
- def plot_with_labels(low_dim_embs, labels, filename='./data/tsne.png'):
- assert low_dim_embs.shape[0] >= len(labels), 'More labels than embeddings'
- plt.figure(figsize=(18, 18)) # in inches
- for i, label in enumerate(labels):
- x, y = low_dim_embs[i, :]
- plt.scatter(x, y)
- plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points',
- ha='right', va='bottom')
- plt.savefig(filename)
-
- final_embeddings = model.in_embed.weight.data.cpu().numpy()
- tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
- plot_only = 200 # 输出100个词
- low_dim_embs = tsne.fit_transform(final_embeddings[:plot_only, :])
- labels = [words[i] for i in range(plot_only)]
- plot_with_labels(low_dim_embs, labels)
3 skip_gram.py(代码总览)
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
- from torch.utils.data import DataLoader, Dataset
- import collections
- from collections import Counter
- import numpy as np
- import random
- import jieba
- from sklearn.manifold import TSNE
- import matplotlib as mpl
- import matplotlib.pyplot as plt
-
- plt.rcParams['font.sans-serif'] = [u'SimHei']
- plt.rcParams['axes.unicode_minus'] = False
-
- # 1.1 样本预处理并生成字典
- # 使用get_ch lable函数将所有文字读入raining_data,然后在fenci函数里使用jeba库对ci放入buld_dataset里并生成指定长度(350)的字典。
-
- # 指定设备
- device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
- print(device)
- training_file = './data/一大段文本.txt'
-
- # 中文字
- def get_ch_lable(txt_file): # 获取文件内的文本信息
- labels= ""
- with open(txt_file, 'rb') as f:
- for label in f:
- labels =labels+label.decode('gb2312')
- return labels
-
- # 分词
- def fenci(training_data):
- seg_list = jieba.cut(training_data) # 默认是精确模式
- training_ci = " ".join(seg_list)
- training_ci = training_ci.split()
- # 以空格将字符串分开
- training_ci = np.array(training_ci)
- training_ci = np.reshape(training_ci, [-1, ])
- return training_ci
-
- # build dataset()函数实现了对样本文字的处理。
- # 在该函数中,对样本文字的词频进行统计,将照频次由高到低排序。同时,将排序后的列表中第0个索引设置成unknown(用“UNK”表示),
- # 这个unknown字符可用于对词频低的词语进行填充。如果设置字典为350,则频次排序在350的词都会被当作unknown字符进行处理。
- def build_dataset(words,n_words): #
- count = [['UNK', -1]]
- count.extend(collections.Counter(words).most_common(n_words - 1))
- dictionary = dict()
- for word, _ in count:
- dictionary[word] = len(dictionary)
- data = list()
- unk_count = 0
- for word in words:
- if word in dictionary:
- index = dictionary[word]
- else:
- index = 0 # dictionary['UNK']
- unk_count += 1
- data.append(index)
- count[0][1] = unk_count
- reversed_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
-
- return data, count, dictionary, reversed_dictionary
-
- training_data = get_ch_lable(training_file)
- print("总字数",len(training_data)) # 1567
- training_ci =fenci(training_data)
- print("总词数",len(training_ci)) #
- training_label, count, dictionary, words = build_dataset(training_ci, 350)
-
- #计算词频
- word_count = np.array([freq for _,freq in count], dtype=np.float32)
- word_freq = word_count / np.sum(word_count)#计算每个词的词频
- word_freq = word_freq ** (3. / 4.)#词频变换
- words_size = len(dictionary)
- print("字典词数",words_size) # 350
- print('Sample data', training_label[:10], [words[i] for i in training_label[:10]]) # # 显示的是样本文字里前10个词的词频。
-
-
- # 1.2 按照skip-Gram模型的规则制作数据集
- # 使用Dataset与Dataloader接口制作数据集。
- # 在自定义Dataset类中,按照Skip-Gram模型的规则对样本及其对应的标签进行组合。
- # 每批次取12个,每个词向量的维度为128,中心词前后的取词个数为3,负采样的个数为64。具体代码如下。
-
- C = 3 # 定义中心词前后的取词个数
- num_sampled = 64 # 负采样个数
- BATCH_SIZE = 12
- EMBEDDING_SIZE = 128
-
- class SkipGramDataset(Dataset): # 自定义数据集
- # 样本中的每个词都被当作一个中心词,对于任意一个样本中心词,都会生成两组标签:正向标签与负向标签。
- # 正向标签来自中心词的前后位置,负向标签主要来自词频的多项式来样。
- def __init__(self,training_label,word_to_idx,idx_to_word,word_freqs):
- super(SkipGramDataset, self).__init__()
- self.text_encode = torch.Tensor(training_label).long()
- self.word_to_idx = word_to_idx
- self.idx_to_word = idx_to_word
- self.word_freqs = torch.Tensor(word_freqs)
-
- def __len__(self):
- return len(self.text_encode)
-
- def __getitem__(self, idx):
- idx = min(max(idx,C),len(self.text_encode)-2-C) # 防止越界:对组合标签过程中的越界问题做了处理,使提取样本的索引为3~(总长度-5)。
- center_word = self.text_encode[idx]
- pos_indices = list(range(idx-C,idx)) + list(range(idx+1,idx+1+C))
- pos_words = self.text_encode[pos_indices]
- # ---start---对负向标签进行采样。在使用多项式分布采样之后,还要从中去掉与正向标签相同的索引。其中np.setdiff1d()函数用于对两个数组做差集。
- # 多项式分布采样,取出指定个数的高频词
- neg_words = torch.multinomial(self.word_freqs, num_sampled + 2 * C, False) # True)
- # 去掉正向标签
- neg_words = torch.Tensor(np.setdiff1d(neg_words.numpy(), pos_words.numpy())[:num_sampled]).long()
- # ---end---对负向标签进行采样。在使用多项式分布采样之后,还要从中去掉与正向标签相同的索引。其中np.setdiff1d()函数用于对两个数组做差集。
- return center_word, pos_words,neg_words
-
- print("制作数据集...")
- train_dataset = SkipGramDataset(training_label,dictionary,words,word_freq)
- dataloader = torch.utils.data.DataLoader(train_dataset,batch_size=BATCH_SIZE,drop_last=True,shuffle=True)
- sample = iter(dataloader) #将数据集转化成迭代器
- center_word, pos_words, neg_words = sample.next() #从迭代器中取出一批次样本
- print(center_word[0],words[np.long(center_word[0])],[words[i] for i in pos_words[0].numpy()])
-
- # 1.3 搭建模型并进行训练
- # 首先定义一个词嵌入层用手训练,将输入的样本和标签分别用词嵌入层进行转化。
- # 在训练过程中,将输入与标签的词嵌入当作两个向量,将二者的矩阵相乘当作两个向量间的夹角余弦值,并用该夹角余弦值作为被优化的损失函数。
- # 在训练模型时,定义了验证模型的相关参数,其中valid_size表示在0~words_size/2中随机取不能重复的16个字来验证模型。
- class Model(nn.Module):
- def __init__(self,vocab_size,embed_size):
- super(Model, self).__init__()
- self.vocab_size = vocab_size
- self.embed_size = embed_size
- initrange = 0.5 / self.embed_size
- self.in_embed = nn.Embedding(self.vocab_size, self.embed_size, sparse=False)
- self.in_embed.weight.data.uniform_(-initrange, initrange)
-
- def forward(self,input_lables,pos_labels,neg_labels):
- # LogSigmoid激活函数,该激活函数的值域是(-inf,0](inf是无穷值的意思),即当输入值越大,输出值越接近于0。
- # 如果将输入样本的词嵌入和目标标签的词嵌入分别当作两个向量,则可以用这两个向量间的夹角余弦值来当作二者的相似度。
- # 为了规范计算,先通过LogSigmoid激活函数中的Sigmoid函数将参与运算的向量控制为0~1,再从正 / 负标签两个方向进行相似度计算:
- # ① 对于正向标签,可以直接进行计算:
- # ② 对于负向标签,可以先用1减去输入样本的词嵌入,得到输入样本对应的负向量,再将该结果与负向标签的词向量一起计算相似度。
- # 根据Sigmoid函数的对称特性1 - Sigmoid(x) = Sigmoid(-x),可以直接对输入样本词向量的符号取负来实现向量的转化。
- input_embedding = self.in_embed(input_lables)
- pos_embedding = self.in_embed(pos_labels)
- neg_embedding = self.in_embed(neg_labels)
-
- # 计算输入与正向标签间的夹角余弦值:用bmm函数完成两个带批次数据的矩阵相乘【bmm函数处理的必须是批次数据,即形状为{b,m,n]与[b,n,m]矩阵相乘;】
- log_pos = torch.bmm(pos_embedding, input_embedding.unsqueeze(2)).squeeze()
- # 计算输入与负向标签间的夹角余弦值:用bmm函数完成两个带批次数据的矩阵相乘【bmm函数处理的必须是批次数据,即形状为{b,m,n]与[b,n,m]矩阵相乘;】
- log_neg = torch.bmm(neg_embedding, -input_embedding.unsqueeze(2)).squeeze() # 在计算输入与负向标签间的夹角余弦值时,使用样本词嵌入的赋值。这样做与使用LogSigmoid激活函数有关。
- # 使用LogSigmoid激活函数
- log_pos = F.logsigmoid(log_pos).sum(1)
- log_neg = F.logsigmoid(log_neg).sum(1)
- loss = log_pos + log_neg
- return -loss # 对最终的损失值取负,将损失函数的值域由(-inf,0]变为(0,inf]。这种变换有利于使用优化器在迭代训练中进行优化(因为优化器只能使损失值沿着最小化的方向优化)。
- # 实例化模型
- model = Model(words_size,EMBEDDING_SIZE).to(device)
- model.eval()
- # 定义测试样本
- valid_size = 16
- valid_window = words_size/2 # 取样数据的分布范围
- valid_examples = np.random.choice(int(valid_window),valid_size,replace=True) #0- words_size/2,中的数取16个。不能重复。
-
- optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
-
- NUM_EPOCHS = 200
-
- for e in range(NUM_EPOCHS): # 训练模型
- for ei, (input_labels, pos_labels, neg_labels) in enumerate(dataloader):
- input_labels = input_labels.to(device)
- pos_labels = pos_labels.to(device)
- neg_labels = neg_labels.to(device)
-
- optimizer.zero_grad()
- loss = model(input_labels, pos_labels, neg_labels).mean()
- loss.backward()
- optimizer.step()
-
- if ei % 20 == 0: # 显示训练结果
- print("epoch: {}, iter: {}, loss: {}".format(e, ei, loss.item()))
- if e % 40 == 0: # 测试模型
- # ---start---实现对现有模型的能力测试。该代码会从验证样本中取出指定的个数的词,通过词嵌入的转化,在已有的训练样本中找到与其语义相近的词,并显示出来。
- # 计算测试样本词嵌入和所有样本词嵌入间的余弦相似度
- norm = torch.sum(model.in_embed.weight.data.pow(2), -1).sqrt().unsqueeze(1) # norm代表每一个词对应向量的长度矩阵,见式(3-5)。
- normalized_embeddings = model.in_embed.weight.data / norm # normalized_embeddings表示向量除以自己的模,即单位向量。它可以确定向量的方向。
- valid_embeddings = normalized_embeddings[valid_examples]
- # 计算余弦相似度:用mm函数完成矩阵相乘【mm函数处理的是普通矩阵数据,即形状为[m,n]与[n,m]矩阵相乘】
- similarity = torch.mm(valid_embeddings, normalized_embeddings.T) # similanity就是valid_dataset中对应的单位向量vald_embeddings与整个词嵌入字典中单位向量的夹角余弦。
- for i in range(valid_size):
- valid_word = words[valid_examples[i]]
- top_k = 8 # 取最近的排名前8的词
- # similarity就是当前词与整个词典中每个词的夹角余弦,夹角余弦值越大,就代表相似度越高。
- nearest = (-similarity[i, :]).argsort()[1:top_k + 1] # argsort()用于将数组中的值按从小到大的顺序排列后,返回每个值对应的索引。在使用argsort函数之前,将similarity取负,得到的就是从小到大的排列。
- log_str = 'Nearest to %s:' % valid_word # 格式化输出日志
- for k in range(top_k):
- close_word = words[nearest[k].cpu().item()]
- log_str = '%s,%s' % (log_str, close_word)
- print(log_str)
- # ---end---实现对现有模型的能力测试。该代码会从验证样本中取出指定的个数的词,通过词嵌入的转化,在已有的训练样本中找到与其语义相近的词,并显示出来。
-
- # 1.4 实现词向量可视化
- # 对与可视化相关的引入库做了初始化,具体说明如下:
- # ①通过设置mpl的值让p|ot能够显示中文信息。
- # ②Scikit-learn(也称为sklearn)库的t-SNE算法模块,作用是非对称降维。
- # t-SNE算法结合t分布,将高维空间的数据点映射到低维空间的距离,主要用于可视化和理解高维数据。
- #
- # 将词典中的词嵌入向量转成单位向量(只有方向),然后将它们通过t-SNE算法降维映射到二维平面中进行显示。
- def plot_with_labels(low_dim_embs, labels, filename='./data/tsne.png'):
- assert low_dim_embs.shape[0] >= len(labels), 'More labels than embeddings'
- plt.figure(figsize=(18, 18)) # in inches
- for i, label in enumerate(labels):
- x, y = low_dim_embs[i, :]
- plt.scatter(x, y)
- plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points',
- ha='right', va='bottom')
- plt.savefig(filename)
-
- final_embeddings = model.in_embed.weight.data.cpu().numpy()
- tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
- plot_only = 200 # 输出100个词
- low_dim_embs = tsne.fit_transform(final_embeddings[:plot_only, :])
- labels = [words[i] for i in range(plot_only)]
- plot_with_labels(low_dim_embs, labels)
推荐阅读
相关标签

