
- 1Python爬取全国各地区疫情风险等级_python爬取全国疫情
- 2报错记录01:AttributeError: module ‘numpy‘ has no attribute ‘dtype‘_import numpy as np 报错 module 'glob' has no attribu
- 3FastGPT编译前端界面,并将前端界面映射到Docker容器中_fastgpt界面定制
- 405_Scala运算符
- 5五分钟了解GPT 模型背后的原理是什么?为什么 GPT 模型能生成有意义的文本?为什么 GPT 模型不会做简单的数学题?为什么有人担心 GPT 模型可能会危害人类?
- 6sql语句查询,多字段like模糊查询优化_sql多个like模糊查询
- 7springboot的jar包太大不方便更新,使用生成的jar.originanl启动项目,不用修改生成其他不带依赖的jar包,分离lib_jar改名成jar.original
- 82020秋招——万字面经分享,这一篇超级走心
- 9NLP中常见的tokenize方式及token类型
- 10洗衣机模糊推理实验_洗衣机模糊推理系统
CVPR2023优秀论文 | AIGC伪造图像鉴别算法泛化性缺失问题分析_2023图像识别算法
赞
踩

作者 | 搜索内容技术部
导读
深度伪造检测算法无法检出未知伪造算法生成的攻击数据。以往算法采取手动建模伪造特征的方式提升模型泛化性,然而这种方式限制了算法可行域,影响了模型泛化性进一步提升,同时这类方法参数量巨大,无法满足工业实时检测要求。本文发现过往采取二分类训练检测算法的方式,使模型过多关注了样本中的用户身份信息,从而导致深伪检测模型无法检出未知伪造数据,我们称其为 “隐式的身份泄漏现象”。为解决此问题,本文提出了一种忽略样本身份特征的深度伪造检测算法。实验证明,当抑制了模型对图片身份信息的学习,模型可以自主学习不同 伪造特征之间所存在的 共性特征,即使基于最简单的二分类模型,检测精度也远超现有业界同期算法。
全文4358字,预计阅读时间11分钟。
01 导论
近来,伴随 AIGC 的快速发展,基于 AIGC 技术的人脸编辑算法开始在互联网兴起。其在增加用户使用趣味性同时,也降低了借助算法进行伪造攻击的技术门槛。攻击者借助面部编辑,利用伪造身份在互联网传播虚假新闻,制作恶作剧,造成恶劣影响。深伪检测算法旨在检出这类伪造数据,减少人脸伪造技术带来的负面效应。现有算法在已知的伪造数据中取得了极高的检测精度。然而,新的人脸伪造技术总是层出不穷,这部分检测模型在面对未知的伪造算法时,精度严重不足。
此前关于深伪检测模型泛化性的研究主要集中在两方面。一种是采用手动建模伪造特征的方式。它们假设不同伪造图片存在某种共有的伪造特征,并训练模型对其进行检测。然而,这一假设的特征往往反映的是人类对于伪造特征的主观理解,并不能体现数据中真实的多种不同伪造特征的共性特征,故并无法从根本上提升模型的泛化性。另一种方法则是通过简单的二分类模型进行检测。二分类模型可以自主从数据中学习伪造特征分布,但很容易出现过拟合的问题,一定程度上限制其泛化能力。为了解决这一问题,本文深入分析现有二分类模型,并期望提出构建一个简洁、鲁棒的深伪检测器。
本文发现现有二分类模型泛化性较差的主要原因在于图片身份信息的干扰。如图1 (a) 所示,伪造图像(Fake Image)是通过将原始图像(Source Image)的身份更换为目标图像(Target Image)所得来。伪造目标图像(New Target Image)则是基于 伪造图像和目标图像编辑得来。可以看出,伪造目标图像在图像伪造过程中丢失了部分身份信息,其身份特征同原始目标图像并不相同。如图1(b)所示,伪造过程中身份信息的丢失就导致了:深度伪造检测模型训练数据集中,真假数据集合间存在一个基于身份特征的分界面(Identity Boundary)。基于此训练的二分类模型会关注图像中的身份特征,当模型无法检出图像中的伪造特征时,会被图像身份信息误导,做出错误判定。我们称这种现象为“隐式的身份泄漏现象”。
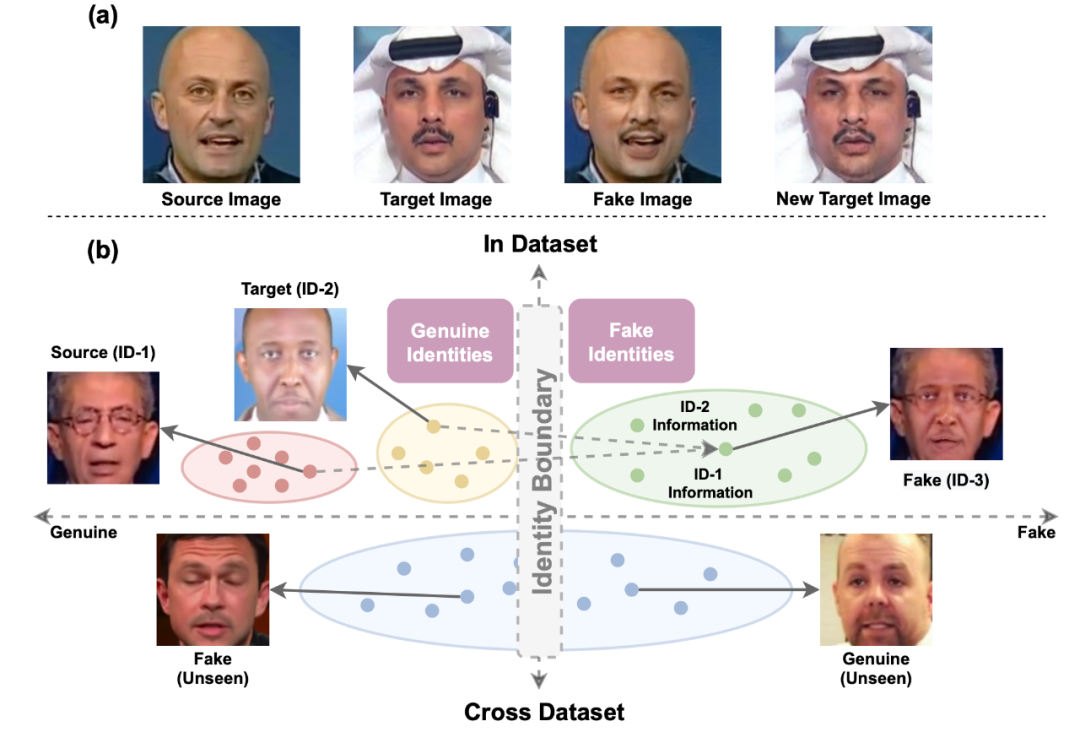
为削减“隐式的身份泄漏现象” 的负面影响,我们进一步提出了忽略身份特征的深度伪造检测器。简而言之,只要迫使伪造检测模型关注图像中的局部信息,那么算法就无法借助全局五官特征来捕获人脸的身份信息,进而就削减了身份特征对伪造检测任务的负面影响。模型共由 伪造区域检测器 和 多尺度面部伪造方法 两部分组成。其中伪造区域检测器采取局部检测方式避免了全局身份信息影响,同时迫使模型从不同局部伪造区域中学习共性特征。多尺度面部伪造方法 通过对面部进行局部伪造,为 伪造区域检测器提供了训练所需的标注信息。实验结果证明,避免图片身份信息的影响后,忽略身份特征的深度伪造检测器即便使用最简单的二分类模型,其精度也可远超业界同期算法。该模型为未来研究深伪检测模型泛化性问题提供了一个新的方向,同时也为模型真实场景的部署提供了一个更为简单有效的方案。
02 隐式的身份泄漏现象
隐式的身份泄漏现象特指深伪检测模型在训练过程中,捕捉到了训练数据集中存在的身份特征分界面。尽管这种特征会在同源数据测试阶段强化真伪数据间的特征差异,但在面对新的伪造数据时,模型无法捕捉伪造特征分布,就开始被曾学习到的身份特征所误导。为此我们构建了线性身份分类实验来验证基于二分类的深伪检测算法在训练阶段捕捉到了身份特征信息,同时提出了量化指标来精确度量这种现象在同源数据测试和交叉数据测试(未见过的伪造方法)过程中,对算法精度的影响。
假设一:深伪检测算法在训练过程中用到了身份特征完成真假判定
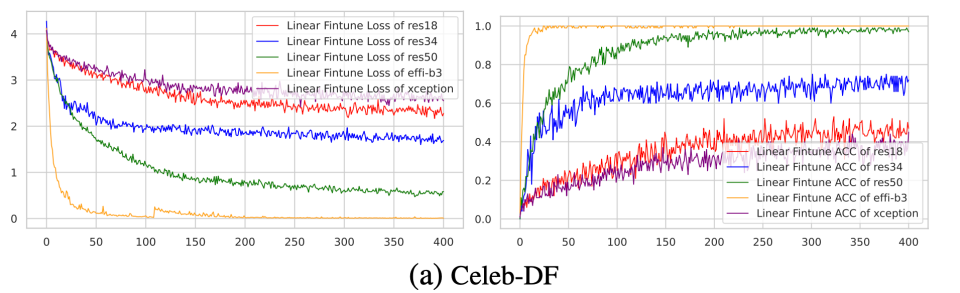
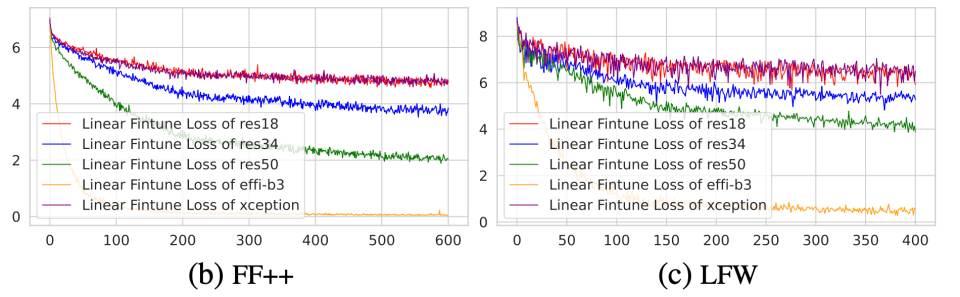
我们基于不同网络结构,不同的实验配置进行了 线性身份分类实验。模型先在深伪检测训练数据集进行伪造检测任务训练,而后固定主干模型参数,追加线性分类器(Fully Connection Layer)进行身份分类。如图2 (a, b, c)所示,我们分别在深伪数据集 Celeb-DF 和 FF++ 以及人脸识别数据集 LFW 上进行实验。实验结果发现深伪检测算法在数据集上不同程度收敛,同时分类准确度皆高于 50%,证明了模型的特征空间具备身份信息,可用于身份识别任务。进而验证了深伪检测算法在训练过程中用到了身份特征完成真假判定这一假设。
假设二:身份特征在交叉数据测试阶段误导模型,限制了算法泛化性

我们认为通常身份特征对伪造检测任务的贡献,表现在局部特征联合的全局交互得分。具体而言,我们通常难以仅基于人的鼻子,眼睛和嘴这些局部五官特征判定人的身份。但是当我们基于人的全局五官进行身份判定,任务就变得简单许多。在这里,基于局部判定身份就可以看作是局部特征在伪造检测任务中的独立得分,全局五官身份判定可以理解为局部特征拼接在一起时所形成的全局交互得分。为验证当前假设,我们引入 Shapley Value 对局部特征独立伪造检测得分和全局交互伪造检测得分进行解耦,并分析全局交互得分(仅基于身份特征做伪造检测)在不同测试集上的精度(AUC)。实验结果如上,身份特征在同源数据(FF++)测试阶段都表现出了较高的精度(>=81.53%), 但用于交叉数据(Celeb-DF)测试时,对判别结果产生负面影响。证明了身份特征在交叉数据测试阶段误导模型,限制了算法泛化性这一假设。
03 忽略样本身份特征的深伪检测算法
本文提出了一种简洁、鲁棒的深伪检测器 —— 忽略样本身份特征的深伪检测算法。算法共由 局部伪造区域检测模块 和 多尺度面部伪造方法 组成。其中局部伪造区域检测模块通过检测样本局部区域中是否含有伪造特征过滤伪造样本,以此避免模型关注样本的全局身份信息。多尺度面部伪造方法用于生成带有伪造区域位置信息的伪造样本,以支持局部伪造区域检测模块训练。
3.1 局部伪造特征检测模块
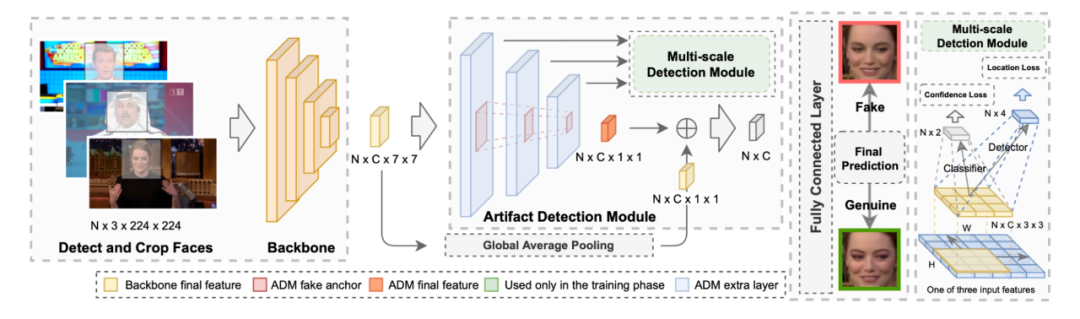
我们期望模型可以根据图片中的Artifact区域进行深伪检测,而非利用其它无关的身份信息。为此,我们设计了 局部伪造区域检测模块 用于定位和判别图片中存在伪造特征的局部区域,以此避免全局I身份信息干扰。如图所示,局部伪造区域检测模块的输入为传统二分类模型提取的图片特征,输出为图片中伪造特征存在的区域。同检测模型相似,局部伪造区域检测模块在主干网络后追加了四层卷积层,并将图片划分为多尺寸 锚点。局部伪造区域检测模块通过对这些锚点进行分类,可以有效学习到图片中真实区域与伪造区域之间的差别。此外,我们将主干网络输出结果经全局池化后追加在局部伪造区域检测模块输出结果中,从而进一步丰富提取特征的信息。
综上,通过定位图片中伪造特征存在的区域,模型可以较为精准地学习到多种伪造特征的共性特征,同时避免受到图片全局身份信息的影响,有效提升模型的泛化能力。
3.2 多尺度面部伪造方法
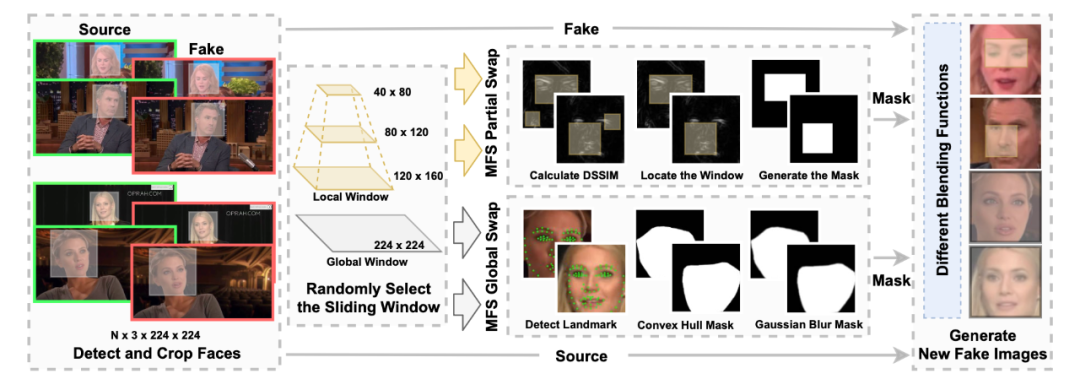
过往数据集中不包含图片中伪造区域的标注,我们提出多尺度面部伪造方法,其利用多尺度的滑动窗口和不同的融合方式,生成带有伪造特征区域标注的伪造图片,同时进一步丰富训练集中伪造特征的信息。多尺度面部伪造方法的流程如图所示。针对一对源图片和伪造图片,多尺度面部伪造方法使用不同尺度的滑动窗口定位伪造的区域,并生成指示局部换脸区域的0-1 Mask。输入的源图片和伪造图片会结合0-1 Mask,并采用不同的融合方式生成新的伪造图片。其共包括两种不同的处理方式:全局交换和局部交换。全局交换生成的Mask包含整个脸部区域,而局部交换的Mask只覆盖伪造特征最显著的区域。我们计算源图片和对应伪造图片的 DSSIM,并借助滑动窗口定位伪造图片与原图之间差异性最大的局部区域,并定义这一区域为伪造特征最显著的区域。该区域DSSIM最大,被改动的信息最多,也就最可能含有伪造特征。
综上,通过多尺度的滑动窗口和不同的融合方式,多尺度面部伪造方法 可以生成带有伪造区域标注的伪造图片,进一步丰富训练集中伪造特征的信息,最终帮助模型学习共性伪造特征。
04 实验部分
4.1 隐式身份泄漏现象验证实验
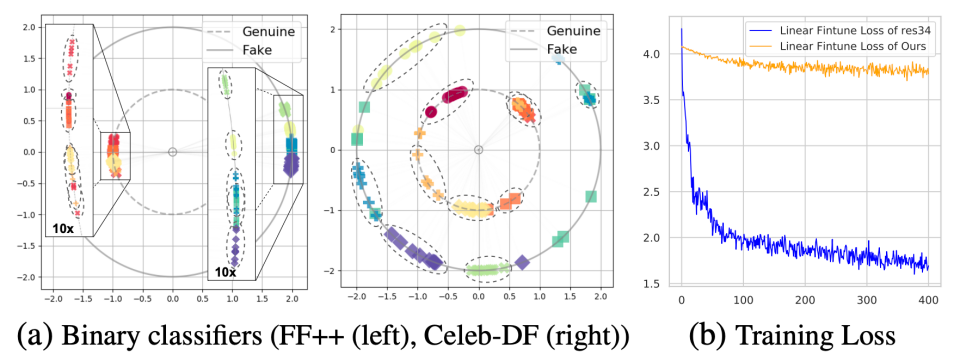
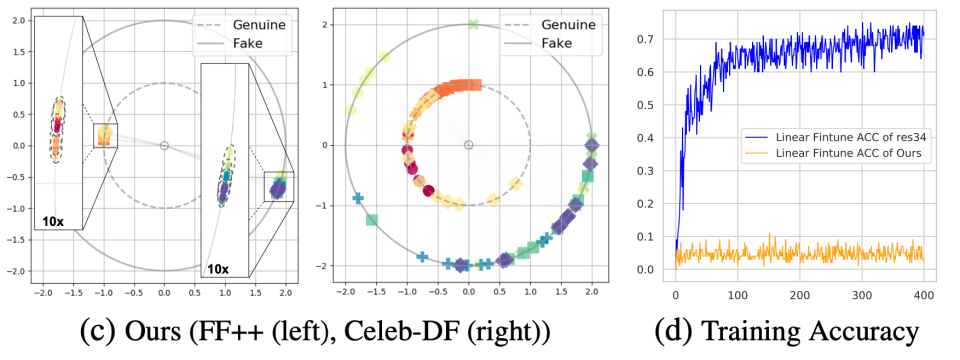
为验证隐式身份泄漏现象,我们从数据集中随机选取了来自10个不同ID的100张样本,借助在FF++数据集中训练的模型提取高维特征,并使用t-SNE将其投影到二维进行可视化(L2正则化后)。如图所示,每个点表示一张图片的特征,不同颜色的点表示不同身份图片的特征。如图b所示,二分类模型在同源数据测试中,在特征空间内,不同ID彼此可分,无明显重合。同时在交叉数据集测试过程中,二分类模型仍受到ID信息干扰,来自相同ID的不同样本被投影到邻近区域。相反,我们的方法在同源数据集和交叉数据集测试中,不同身份的图片特征之间不可分,且存在显著交集。这一结果说明所提出方法有效减少了模型对图片身份信息的提取。
4.2 不同主干网络精度对比实验
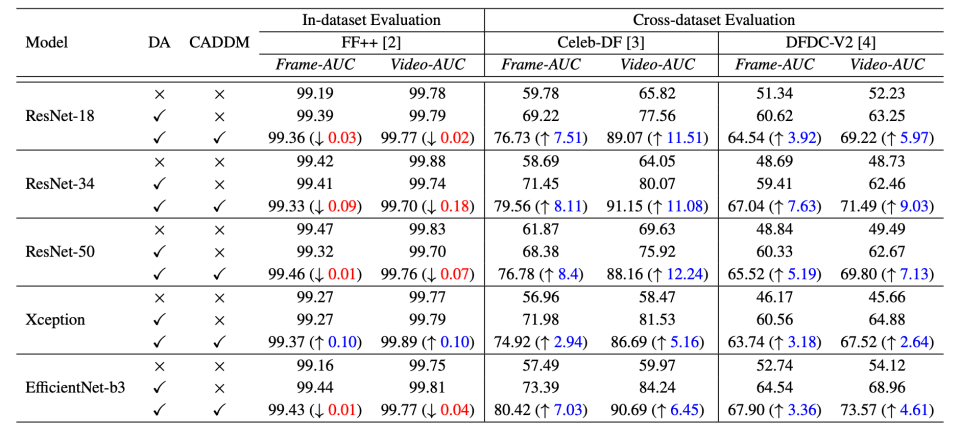
为了验证算法的广泛适用性,我们在不同的主干网络上进行了实验。实验表的结果表明,在交叉数据集测试中,我们的算法使用不同的主干网络都可以显著提升模型性能,而在同源数据集测试中,模型也可以保持模型精度。这一结果进一步说明了所提出方法的有效性,即便是简单的二分类模型,也可以取得不错的表现。同时根据可视化结果,我们提出的算法准确检测到局部伪造特征区域,具备更好的可解释性。

05 总结与展望
在本文中,我们发现以往利用二分类模型完成深伪检测的方式容易受到图片身份信息的影响,从而限制了模型泛化能力的提升。本文提出了忽略身份特征的深伪检测方法,迫使模型仅关注图片中包含伪造特征的局部区域,并从不同区域中学习共性伪造特征,以避免身份信息干扰。实验证明,随着训练集中伪造方法增加,提出的方法可以自主建模更鲁棒的共性伪造特征。综上,本文为深伪检测算法泛化性研究提供了新的思路,也为现实场景中的模型部署提供了一个更为简单有效的方案。
——END——
推荐阅读

