
- 1【079期】面试官:设计一个安全的登录都要考虑哪些?我一脸懵逼。。_设计用户登录表的时候考虑哪些因素
- 2云安全架构的设计_纯云业务如何设计安全架构
- 3FileProvider 安装 apk_fileprovider apk miui
- 4XtraBackup
- 57-36 社交网络图中结点的“重要性”计算 (30 分)(思路加详解)兄弟们PTA乙级题目冲起来
- 6解决 linux 系统中Error: Unable to access jarfile XXX.jar问题_linux unable to access jarfile
- 7DevOps 内容分享(九):利用AI掌握DevOps,构建新的CI/CD流水线_ai devops
- 8数据结构绪论——什么是数据结构?_数据结构由数据的1 point(s)、1 point(s)和1 point(s)三部分组成。
- 9基础环境:wsl2安装Ubuntu22.04 + miniconda_wsl 2 上安装 ubuntu 22.04
- 105年测试被裁,恶补3个月上岸字节28K,面试差点被问哭了_程序员刷题上岸
【绝对有用】快速掌握GPT-4o:详细免费使用指南!_gpt-4o怎么用
赞
踩
GPT-4o 简介

北京时间5月14日,OpenAI举行了春季发布会,并发布了其新旗舰模型“GPT-4o”。据OpenAI首席技术官穆里·穆拉蒂(Muri Murati)介绍,GPT-4o在继承GPT-4强大智能的基础上,进一步提升了文本、图像及语音处理能力,为用户带来更加流畅、自然的交互体验。更多详情请访问官网。
GPT-4o的含义
GPT-4o中的“o”代表“omni”,源自拉丁语“omnis”,在英语中表示“全部”或“所有”。GPT-4o是一个多模态大模型,支持文本、音频和图像的任意组合输入,并能生成文本、音频和图像的任意组合输出。与现有模型相比,它在视觉和音频理解方面尤其出色。
GPT-4o的性能
GPT-4o可以在音频、视觉和文本中进行实时推理,接受文本、音频和图像的任意组合作为输入,并生成文本、音频和图像的任意组合进行输出。它可以在最短232毫秒内响应音频输入,平均响应时间为320毫秒,与人类对话中的响应时间相似。
文本能力
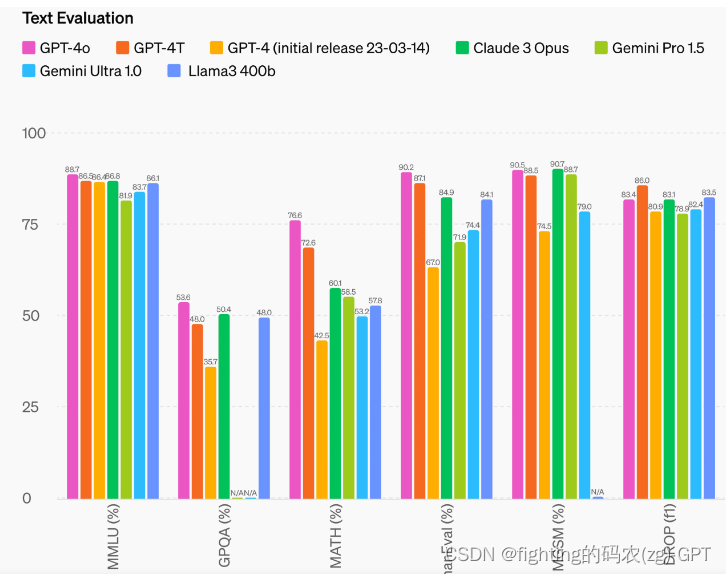
GPT-4o在0次COT MMLU(常识问题)上创下了88.7%的新高分。此外,在传统的5次无CoT MMLU上,GPT-4o创下了87.2%的新高分。
音频能力
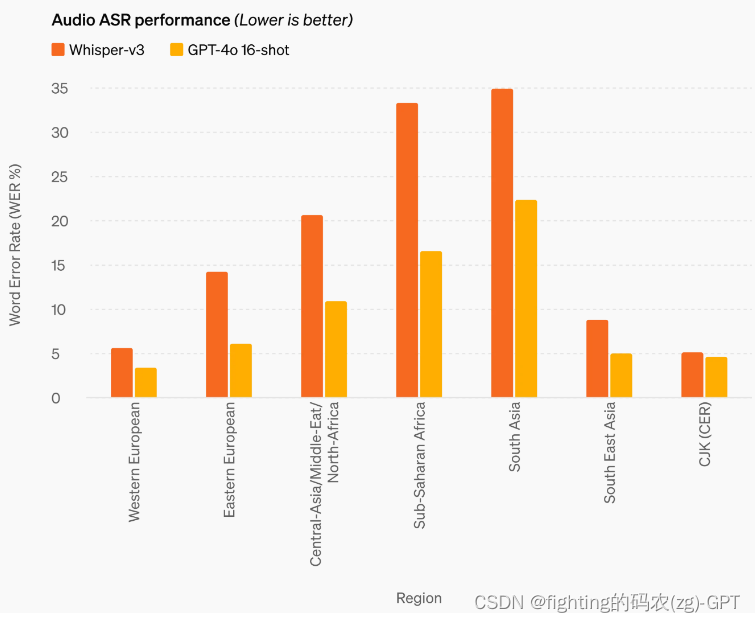
GPT-4o在语音翻译方面取得了新的领先地位,并在MLS基准测试中优于Whisper-v3。
各种语言的考试能力
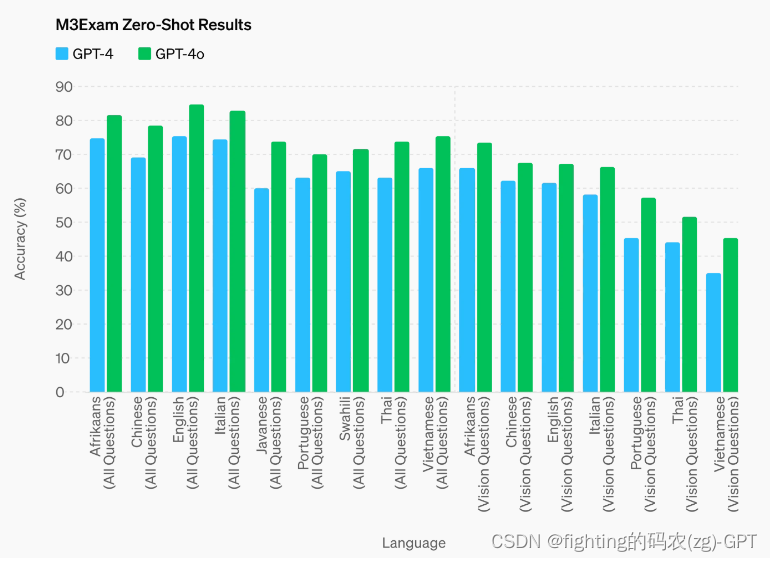
M3Exam基准测试既是多语言评估,也是视觉评估,由来自其他国家标准化考试的多项选择题组成,有时包括数字和图表。GPT-4o在所有语言的基准测试中都比GPT-4表现更好。
视觉理解
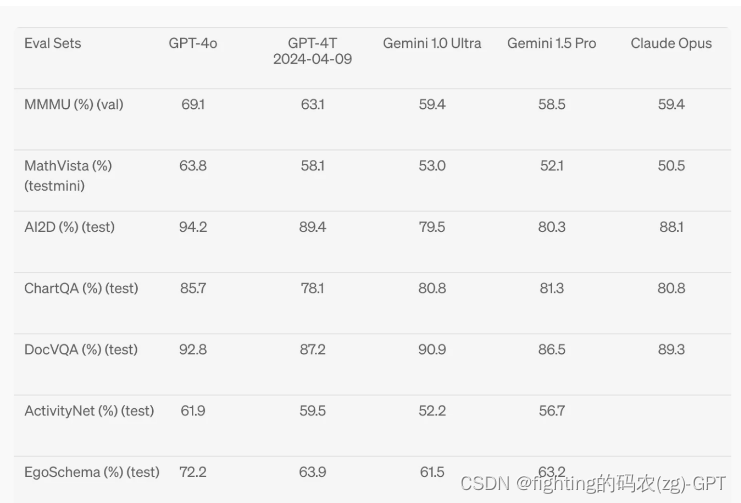
GPT-4o在视觉感知基准测试中实现了最先进的性能,全面超越之前的模型。所有视觉评估均为0次,其中MMMU、MathVista和ChartQA为0次CoT。
语音交互

GPT-4o在语音交互方面取得了重大进展。它采用了先进技术,显著提高了响应速度,使得对话更加流畅自然。在最近的发布会上,OpenAI展示了GPT-4o在语音对话中的表现,能够几乎实时地回答问题,并通过文本转语音技术进行朗读,提供了一种沉浸式的交流体验。GPT-4o还可以调整说话的语气,从夸张戏剧到冰冷机械,以适应不同的交流场景。此外,GPT-4o还具备唱歌的功能,增添了更多的趣味性和娱乐性。
GPT-4 Turbo与GPT-4o
GPT-4o不仅在传统的文本能力上与GPT-4 Turbo性能相当,还在API方面更快速,价格便宜50%。与GPT-4 Turbo相比,GPT-4o速度提高了2倍,价格减半,限制速率提高了5倍。截至2024年5月13日,Plus用户可以在GPT-4o上每3小时发送多达80条消息,在GPT-4上每3小时发送多达40条消息。在高峰时段可能会减少限制,以保持GPT-4和GPT-4o的可用性。
具体比较
- 定价:GPT-4o比GPT-4 Turbo便宜50%,输入费用为5美元/月,输出代币费用为15美元/M。
- 速率限制:GPT-4o的速率限制比GPT-4 Turbo高5倍,每分钟最多1000万个代币。
- 速度:GPT-4o的速度是GPT-4 Turbo的4倍。
- 视觉:GPT-4o在与视觉能力相关的评估中表现优于GPT-4 Turbo。
- 多语言:GPT-4o改进了对非英语语言的支持,超过了GPT-4 Turbo。
- 上下文窗口:GPT-4o的上下文窗口为128k,知识截止日期为2023年10月。
使用GPT-4o的方法
目前,GPT-4o的文本和图像功能已经开始在ChatGPT中逐步推出,用户可以在ChatGPT平台上免费体验GPT-4o的相关功能,但免费版有使用次数限制。Plus用户可以享受到5倍的调用额度(升级plus详细教程:升级PLUS)。OpenAI计划在接下来的几周内在ChatGPT Plus中推出带有GPT-4o的Voice Mode新版本,作为ChatGPT Plus的一个alpha版本。此外,GPT-4o也将通过API提供给开发者,作为文本和视觉模型。开发者可以利用API将GPT-4o集成到他们自己的应用程序中。
至于GPT-4o的音频和视频功能,OpenAI将在未来几周和几个月内继续开发技术基础设施,提升可用性并确保安全性,之后才会发布这些功能,并逐步向公众提供。
具体详情参考个人主页的链接。

