
- 1怎么在navicat导入excel文件、csv文件、DBase文件...........?_navicat导入csv文件
- 2高可用的分布式Hadoop大数据平台搭建,超详细,附代码。_四、启动hadoop分布式环境. 写清楚步骤及截图。
- 3【华为OD机试真题 JS语言】432、 密码解密 | 机试真题+思路参考+代码解析(最新C卷抽中)(双代码)_华为c卷密码解密
- 4Linux权限管理_$uid -gt 199
- 5一款挺好看的南瓜影视APP下载页面_dl.keke1.app
- 6Elasticsearch 嵌套类型的深度剖析与实例_elastic search嵌套文档查询
- 7MySQL的触发器、索引和存储引擎
- 8【算法】【二叉树,DFS,哈希集合,分类讨论】力扣1110. 删点成林
- 9python PyQt5窗口运行vue项目记录_pyqt vue
- 10Qt实现简单的显示网页(QtWebkit、QtWebEngine、QAxWidget)_qt 显示网页
赛博炼丹指南——如何训练深度学习模型_赛博炼丹模型融合‘
赞
踩
关于如何更好地训练深度学习模型,主要可以从优化器、学习率、初始化策略、权重衰减、优化器超参数、LN层超参数、DropPath、Gradient Clipping等方面考虑
1. 优化器
主要有这几个:SGD、SGD(momentum)、Adagrad、RMSProp、Adam、AdamW
SGD就是普通的梯度下降法用在mini-batch上
SGDmomentum在SGD基础上优化方向朝着动量方向而不是梯度方向
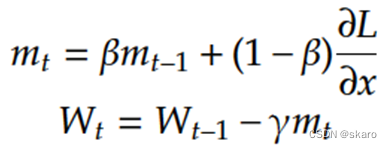
Adagrad优化过程为在更新的时候让梯度除以累积梯度平方,但这样会使得分母项越来越大,训练速度越来越慢,可能使得训练提前终止
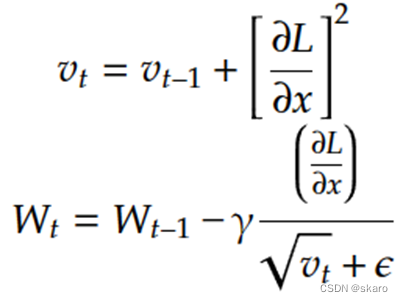
RMSProp在Adagrad基础上在计算二阶梯度的时候前面再加一个加权系数
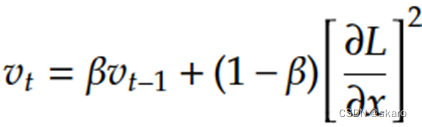
Adam可以认为是SGDmomentum和RMSProp的结合体,它两种策略都要

AdamW是在Adam的基础上做了权重衰减的修正,将权重衰减从添加进损失函数的L2范数改为直接在权重更新时减去衰减系数乘以当前权重

AMSgrad是为了应对自适应优化器难以收敛到最优解而出现的,它的二阶动量取当前二阶动量与上一次二阶动量中的较大值
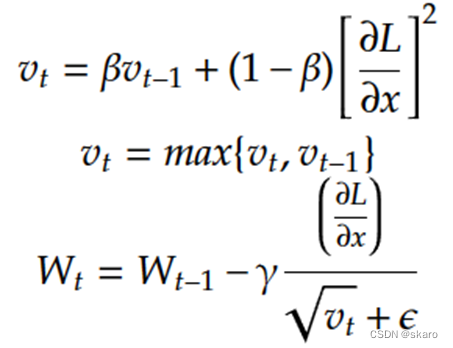
主流的观点认为在训练transformer架构等复杂结构网络时最好采用Adam、AdamW等自适应的优化器,难以收敛的问题最好采用AMSgrad优化器,而在各个论文中优化器的选择似乎并不一定,主要还是依据实验效果确定,当然,大伙一般是不会专门做优化器的对比实验的
2. 学习率
主要有多步间隔MultiStepLR、线性学习率LinearLR、指数衰减ExponentialLR、余弦退火CosineAnnealingLR、CyclicLR
多步间隔MultiStepLR是最简单的自己设置迭代到多少个epoch学习率调整至多少
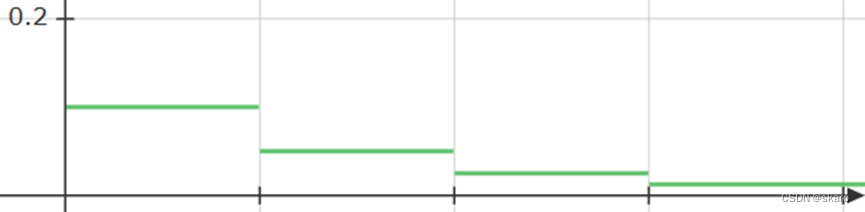
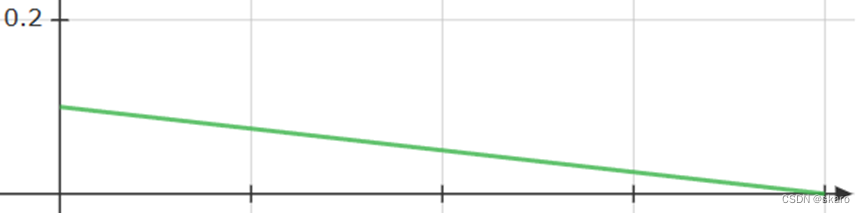
线性学习率LinearLR指学习率线性下降
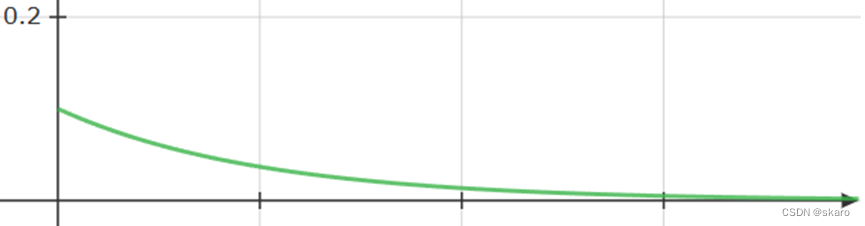
指数衰减ExponentialLR
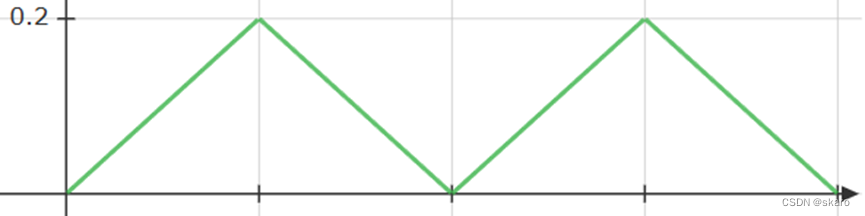
余弦退火CosineAnnealingLR指用余弦函数来调整学习率

CyclicLR作者认为后期的学习率调整不能一味的减小学习率,使用周期性的学习率增大减小可以避免模型进入局部最优的状态,也能让模型用更少的迭代达到最佳精度
3. 参数初始化
初始化方法主要有零初始化、高斯初始化、均匀分布初始化、Xavier初始化、Kaiming初始化、预训练初始化
零初始化会使得梯度消失,同时,每个神经元权重都相同的时候还会面对对称失效的问题,所以一般没人用这个
高斯初始化,一般采用均值为0,方差为1来采样初始化权重
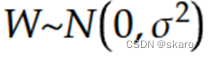
均匀分布初始化
![]()
Xavier初始化,其实也是一种高斯初始化,论文证明这种初始化手段在采用sigmoid激活函数的时候可以保证每层神经元输入输出数据分布方差一致,也可以使得单层网络的lipschitz常数小于2,大于1小于2是一个合适的范围,不会发生梯度消失也不容易产生梯度爆炸,这里n是输入层和输出层神经元个数
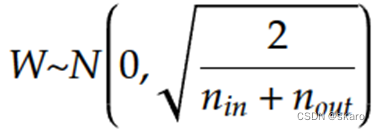
Kaiming初始化,但现在的深度网络普遍采用ReLU激活函数,这时候用Xavier初始化会使得多层网络的梯度越来越小,越深的网络越容易梯度消失,因此提出Kaiming初始化,其中n是输入层神经元个数

预训练初始化,指直接用在其他任务上训练过的网络参数迁移过来作为初始化参数
4. 其他
权重衰减,权重衰减调大一些可以让训练更稳定,网络越大,应该选更大的系数
Adam优化器中的β2如果太接近于1会使得训练不稳定,特别是当数据中有少部分异常样本会贡献较大的梯度的时候,这会减少网络的泛化能力,pytorch官方给Adam的默认参数中β2是0.999,如果数据不够干净,这个值可以减小到0.95到0.99之间
LayerNorm层的计算公式是
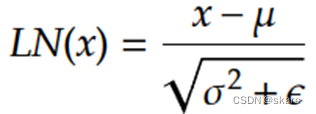
而深层的transformer很容易出现方差趋近于0的情况,如果epsilon取值太小,容易使得局部网络梯度过大,出现梯度爆炸,如果训练不稳定,可以将pytorch默认的epsilon=1e-5增大到1e-2(再大就不合适了)
DropPath,对于多路的网络来说,可以设置droppath率,让网络在训练的过程中随机关闭一些通路,这也是一种正则的手段,跟dropout很像
Gradient Clipping也是一种防止梯度爆炸的手段,具体来说就是对于某个节点的梯度如果计算得到gx,计算如下公式,对梯度绝对值超过阈值的部分做梯度裁剪
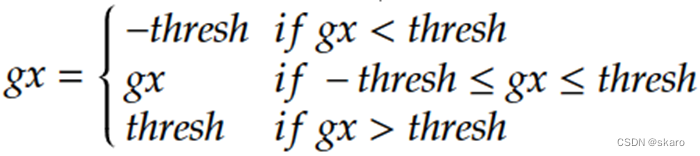
参考:
深度学习各类优化器详解(动量、NAG、adam、Adagrad、adadelta、RMSprop、adaMax、Nadam、AMSGrad)_动量优化器-CSDN博客
史上最全学习率调整策略lr_scheduler - 知乎 (zhihu.com)
尝试 Cyclical Learning Rates - 知乎 (zhihu.com)
pytorch之warm-up预热学习策略_pytorch warmup-CSDN博客

