
- 1推荐开源项目:PyCryptodome——Python加密库的卓越替代品
- 2NameError: name xxxxxx is not defined
- 3大神之路-起始篇 | 第2章.计算机科学导论之【数字系统】学习笔记_计算机导论中数码的数量怎么理解
- 42023年中国研究生数学建模等待成绩的心路历程(二十届华为杯)_2023华为杯数学建模竞赛成绩
- 5杠上Google I/O?OpenAI抢先一天直播,ChatGPT或将具备通话功能
- 6Java开发9年经验,三轮技术面+HR面试成功砍下阿里巴巴Offer!_java 9年面试
- 7neo4j3.0 java使用,neo4j 3.0中的存储过程
- 8盘点分布式文件存储系统____分布式文件存储系统简介
- 9网络安全专业名词解释_计算机靶机是什么意思
- 10SQL Server使用教程_初学者必备
FPN (特征金字塔) 的原理和代码_fpn代码实现
赞
踩
1. 为什么会使用金字塔式的representation以及它存在的问题。
论文中提到一些传统的使用深度学习来做物体检测的结构会倾向于避开使用金字塔性质的representation, 因为使用这样的representation会对算力和内存带来很大的压力。但是金字塔形式的representation对物体检测有着非常大的作用。因为它可以将一张图像在多个不同的尺寸上进行处理,会提高对图像中尺寸相对较小的物体检测的准确度。因为传统的物体检测的方法都是基于一张特征图,但是一张特征图能提供的信息非常的有限,若是物体在图像中所占的像素非常的少,是很有可能检测不到的。但是传统的特征金字塔也存在着诸多的问题。
传统的特征金字塔存在这些问题:
- 为了得到图像在不同尺寸下的金字塔式的表示,使用图像金字塔去生成对应的特征金字塔在理论上虽然是可行,但是特征金子塔的推理时间相当的长,在追求高效和实时的需求下的劣势非常明显。除此之外,如果想要配合深度学习进行端对端的训练,是不现实的,因为计算量过于巨大。
- 除了使用图像金字塔以外的方法,还可以使用卷积神经网络本身自带的金字塔属性(每一个卷积层输出的特征图的大小会逐渐变小,最后得到一些高语义的特征。)来构建一个 in-network feature hierarchy来产出不同大小的feature map.但是这样的作法也存在着问题,不同的深度会导致较大的semantic gap 从而影响到网络进行物体检测的表现。
在本文中,作者利用CNN模型固有的金字塔形式的属性,提出一个有着 bottom-up, top-down, lateral connection 3个模块的特征金字塔。它的目的之一是为了让特征图进行融合,是特征图拥有更丰富的语义信息。接下来就着重记录,这三个板块的结构和特点,以及实现和训练中要注意的问题。
下图是论文中 特征金字塔的示意图。
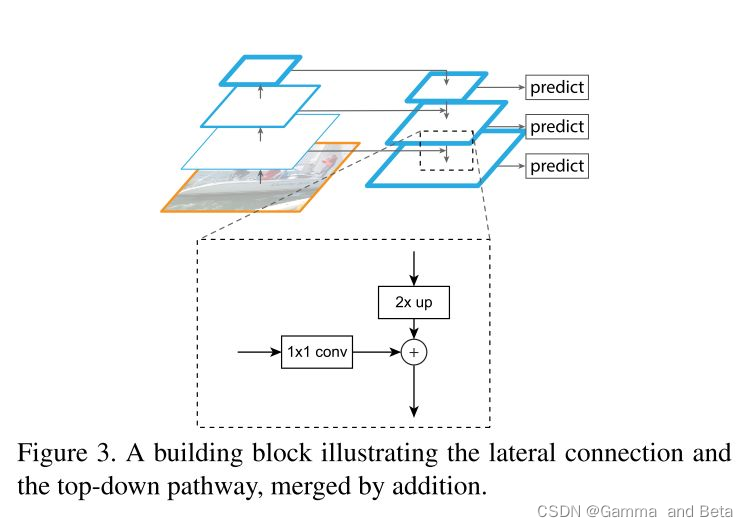
2. 原理和特点。
从Bottom-up pathway 开始,这一个小模块其实可以简答的理解成是 CNN的前向传播过程,每一个卷积层都会输出一个特征图。输出相同的大小的特征图的卷积层作者称之为是一个阶段。使用每个阶段中的最后一个输出作为当前阶段的输出。和传统的网络的不同之处在于,每一个阶段的所输出的特征图会被保存下来在后续的操作当中进行使用。Bottom-up 最后一层的输出是有着高语义的特征图。这里需要注意的一点是bottom-up pathway当中,每一个特征图是按照步长为2进行下采样的。这意味着,从第二个阶段开始的步长是 4, 第三个阶段是8,第4个阶段是16,然后第5个阶段是32。这是因为在这里的上采样过程使用的是 邻近值法。
随着bottom-up过程的结束,top-down也随之开始。Top-down过程可以先简单的理解成是一个上采样的过程。说的具体一些,Top-down过程的首先将 bottom-up最后一个阶段得到的特征图上采样到和bottom-up的第四阶段输出的特征图一样大的尺寸,然后在将通过横向连接(lateral connection)将他们进行 element-wise addition。换句话说就是,横相连接将bottom-up 和 top-down 尺寸相同的特征图进行融合。然后这个过程一直重复,直到整个过程结束。这里也有一些关于top-down和lateral connection的小细节需要注意。每一次 lateral connection都会有一个1 * 1 的卷积,这样做的目的是在调整特征图通道的数量。除此之外,每一个经过横向连接产生的特征图还会被一个3*3的卷积核进行卷积。论文中提到的原因是使用这样的技术去处理在上采样操作中出现的混叠效应。那所谓的混叠效应是什么呢? 这里的混叠效应指的是一种失真的现象,在这里可以简单的理解成两个特征图叠加,造成的特征失真或者混乱的现象。
从上面的记录中可以可以看出,对于这样一个网络,他的输入是一张任意大小的图像,然后输出多个,尺寸不一但是通道数一致的特征图。
3. 如何基于resnet实现(思路)。
那么应该如何将上述的FPN网络实现呢。这里使用resnet来举个例子。首先记录bottom-u的过程,这个过程就是Resnet的前向传播过程。ResNet的bottleNeck 可以用以下代码来实现。
class Bottleneck(nn.Module): expansion = 4 def __init__(self, in_planes, planes, stride=1): super(Bottleneck, self).__init__() self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False) self.bn1 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(planes) self.conv3 = nn.Conv2d(planes, self.expansion*planes, kernel_size=1, bias=False) self.bn3 = nn.BatchNorm2d(self.expansion*planes) self.shortcut = nn.Sequential() if stride != 1 or in_planes != self.expansion*planes: self.shortcut = nn.Sequential( nn.Conv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(self.expansion*planes) ) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = F.relu(self.bn2(self.conv2(out))) out = self.bn3(self.conv3(out)) out += self.shortcut(x) out = F.relu(out) return out

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
上述代码中的 self.expansion = 4 是什么意思? 因为resnet每一个residual module的输入通道数(in_channels)和输出通道数 (out_channels) 遵循 : out_channels = in_channels * 4 。有了上述的block 模块之后,就可以很容易的使用下面的代码完成resnet的前向传播:
class FPN(nn.Module):
def __init__(self, block, num_blocks):
super(FPN, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
# resnet forward propagation / Bottom-up pathway
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
上述的代码就是resnet 和 bottom-up pathway 需要经过的层。在bottom-up完成之后,我们需要使用一个layer,在top-down之前来调整layer4所输出的特征图的通道数量:
self.top_layer = nn.Conv2d(2048, 256, kernel_size=1, stride=1, padding=0)
- 1
之后就是进行特征图的上采样和相加,这个方法可以直接使用pytorch的functional中提供的upsample的方法去实现。到这里我们每一层还需要一个3 * 3的卷积核来去除混叠效应和一个1*1的通道数来调整每一个特征图通道的大小。
self.anti_alising_1 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.anti_alising_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.anti_alising_3 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
- 1
- 2
- 3
上面是每一层去除混叠效应的卷积核,因为文中提到了最后输出的每一张特征图的维度都是256,所以会看到上述定义的anti_alising_ 都有着相同的输入和输出的通道数。
self.lateral_layer1 = nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0)
self.lateral_layer2 = nn.Conv2d( 512, 256, kernel_size=1, stride=1, padding=0)
self.lateral_layer3 = nn.Conv2d( 256, 256, kernel_size=1, stride=1, padding=0)
- 1
- 2
- 3
上述代码是fpn的横向连接,仔细每一个观察横向连接中的输入channel 和 bottom-up中的正好相反。这个小的细节对我们在实现或者记忆FPN的结构上有一定的帮助。
到此,FPN的所有重要的板块都已经用代码实现,只需要重写nn.Module中的forward函数便可以完成FPN的前向传播。
我们假设输入一张尺寸为224 * 224的图像,那么基于Resnet101的FPN输出的特征图的形状应该如下所示:
torch.Size([1, 256, 56, 56])
torch.Size([1, 256, 28, 28])
torch.Size([1, 256, 14, 14])
torch.Size([1, 256, 7, 7])
- 1
- 2
- 3
- 4
4. 小总结
FPN利用了CNN自带的金子塔式的结构特点,使用了 bottom-up, top-down以及 lateral connection三个不同的路径,生成了具有高语义信息的特征图。这样技术可以被运用到了现在一些主流的物体检测和物体分割的网络中,比如mask rcnn。它有效的提高了网络的表现以及在一定的程度上解决了 pyramid representation的一些固有问题。

