
- 1面试馆:你们项目中的难点是什么,你是如何解决的?_项目中遇到的困难怎么解决的面试
- 2android 上层设置 自动调节亮度_android systemui中增加自动亮度调节按钮
- 3编译原理——递归下降分析法_本关任务:根据某一文法编制调试递归下降分析程序,以便对任意输入的符号串进行分析
- 4Hadoop数据目录迁移
- 5【智能算法】灰狼算法(GWO)原理及实现_gwo算法
- 6neo4j卸载社区版
- 7在 CentOS 6 和 Nginx 中部署 Let's Encrypt 的 SSL 证书
- 8linux下离线安装redis详细操作_linuxredis离线安装
- 9基于Matlab的各种图像滤波Filter算法(代码开源)_matlab图像滤波
- 10自然语言处理困难点_中午自然语言处理的困难
python语言程序设计 答案,python程序设计教程题库_python语言程序设计基础教程答案
赞
踩
本篇文章给大家谈谈python语言程序设计编程题答案,以及python程序设计编程题答案,希望对各位有所帮助,不要忘了收藏本站喔。

下面是eval()函数作用的是:
A去掉参数中元素两侧所有引号,含单引号或双引号,当作Python语句执行
B直接将参数中元素当作Python语句执行
C去掉参数中做外侧一对引号,含单引号或双引号,当作Python语句执行
D在参数两侧增加一对单引号,当作Python语句执行
正确答案 C :eval(x)函数用于去掉参数x最外侧一对引号。
下面属于import保留字作用的是:
A改变当前程序的命名空间
B每个程序都必须有这个保留字
C引入程序之外的功能库
D当调用函数时需要使用该保留字
正确答案 C :import保留字仅用于引用外部库
下列选项中不符合Python语言变量命名规则的是
A I
B TempStr
C 3_1
D _AI
正确答案 C
给出如下代码
TempStr =“Hello World” 可以输出“World”子串的是
A print(TempStr[–5:])
B print(TempStr[–5: –1])
C print(TempStr[–4: –1])
D . print(TempStr[–5:0])
正确答案 A
5关于Python程序中与“缩进”有关的说法中,以下选项中正确的是
A缩进在程序中长度统一且强制使用
B缩进是非强制性的,仅为了提高代码可读性
C缩进统一为4个空格
D缩进可以用在任何语句之后,表示语句间的包含关系
正确答案 A
Python 语言中,以下表达式输出结果为11的选项是
A print(eval(“1” + “1”))
B print(eval(“1+1”))
C print(1+1)
D print(eval(“1” + 1))
正确答案 A
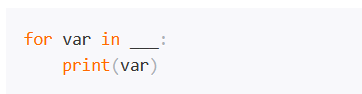
哪个选项不符合上述程序空白处的语法要求?
A {1;2;3;4;5}
B (1,2,3)
C range(0,10)
D “Hello”
正确答案 A :for … in … 中 in 的后面需要是一个迭代类型(组合类型),{1;2;3;4;5}不是Python的有效数据类型Python流星雨特效代码:简单实现梦幻星空。

哪个选项给出了上述程序的输出次数?
A 14
B 15
C 13
D 1000
正确答案 A :请跟随程序计算或在IDLE中运行程序获得结果。
哪个选项关于循环结构的描述是错误的?
A循环是程序根据条件判断结果向后反复执行的一种运行方式
B死循环无法退出,没有任何作用
C条件循环和遍历循环结构都是基本的循环结构
D循环是一种程序的基本控制结构
正确答案 B :死循环能够用于测试性能,形式上的死循环可以用break来退出,例如:
x = 10while True:
x = x - 1
if x == 1:
break
死循环是有其作用的。
哪个选项是random库中用于生成随机小数的函数?
A randrange()
B random()
C getrandbits()
D randint()
正确答案 B :randint()、getrandbits()、randrange()都产生随机整数,random()产生0到1之间的随机小数。
以下是二分支结构紧凑模式的是:
A <表达式1> if <条件> else: <表达式2>
B <条件> if <表达式1> else <表达式2>
C <条件> if else <表达式1> <表达式2>
D <表达式1> if <条件> else <表达式2>
正确答案 D :<表达式1> if <条件> else <表达式2>注意:前后都是<表达式>不是<语句或语句块>
关于try-except,哪个选项的描述是错误的?
A NameError是一种异常类型
B表达了一种分支结构的特点
C用于对程序的异常进行捕捉和处理
D使用了异常处理,程序将不会再出错
正确答案 D :使用了异常处理,程序可能运行不会出错,但逻辑上可能出错。程序错误是一个大概念,不仅指代码运行错误,更代表功能逻辑错误。
7 random库的random.randrange(start, stop[, step])函数的作用是
A生成一个[start, stop)之间的随机小数
B生成一个[start, stop)之间以step为步数的随机整数
C从序列类型(例如列表)中随机返回一个元素
D将序列类型中元素随机排列,返回打乱后的序列
正确答案 B
random.uniform(a, b)的作用是
A生成一个[a,b]之间的随机整数
B生成一个[a, b]之间的随机小数
C生成一个[0.0, 1.0)之间的随机小数
D生成一个[a, b)之间以1为步数的随机整数
正确答案 B
生成一个[10,99]之间的随机整数的函数是
A random.randint(10, 99)
B random.randrange(10, 99,2)
C random.random()
D random.uniform(10,99)
正确答案 A
关于try-except,哪个选项的描述是错误的?
A用于对程序的异常进行捕捉和处理
B NameError是一种异常类型
C表达了一种分支结构的特点
D使用了异常处理,程序将不会再出错
正确答案 D :使用了异常处理,程序可能运行不会出错,但逻辑上可能出错。程序错误是一个大概念,不仅指代码运行错误,更代表功能逻辑错误。
11 实现多路分支的最佳控制结构是
A if
B if-else
C if-elif-else
D try
正确答案 C
random库的seed(a)函数的作用是
A生成一个k比特长度的随机整数
B生成一个[0.0, 1.0)之间的随机小数
C生成一个随机整数
D设置初始化随机数种子a
正确答案 D
以下关于递归函数基例的说法错误的是:
A每个递归函数都只能有一个基例
B递归函数的基例不再进行递归
C递归函数的基例决定递归的深度
D递归函数必须有基例
正确答案 A :每个递归函数至少存在一个基例,但可能存在多个基例。
以下选项不是函数作用的是:
A降低编程复杂度
B复用代码
C增强代码可读性
D提高代码执行速度
正确答案 D :函数不能直接提高代码执行速度。
以下关于Python函数说法错误的是:
def func(a,b):
c=a**2+b
b=a
return c
a=10
b=100
c=func(a,b)+a
A执行该函数后,变量b的值为100
B执行该函数后,变量a的值为10
C该函数名称为func
D执行该函数后,变量c的值为200
正确答案 D :a, b为全局变量,请在IDLE中执行代码观察结果。
以下关于模块化设计描述错误的是:
A应尽可能合理划分功能块,功能块内部耦合度低
B高耦合度的特点是复用较为困难
C应尽可能合理划分功能块,功能块内部耦合度高
D模块间关系尽可能简单,模块之间耦合度低
正确答案 A :模块内高耦合、模块间低耦合。
以下对递归描述错误的是:
A一定要有基例
B递归程序都可以有非递归编写方法
C书写简单
D执行效率高
正确答案 D :递归不提高程序执行效率。任何递归程序都可以通过堆栈或队列变成非递归程序(这是程序的高级应用)。
以下关于函数说法错误的是:
A函数可以看做是一段具有名字的子程序
B函数是一段具有特定功能的、可重用的语句组
C对函数的使用必须了解其内部实现原理
D函数通过函数名来调用
正确答案 C :调用函数不需要知道函数内部实现原理,只需要知道调用方法(即接口)即可。
哪个选项对于函数的定义是错误的?
A def vfunc(a,b):
B def vfunc(a,b=2):
C def vfunc(a,*b):
D def vfunc(*a,b):
正确答案 D :def vfunc(*a, b) 是错误的定义:*a表示可变参数,可变参数只能放在函数参数的最后。
函数定义时,以下不需要使用global声明就可能操作全局变量的类型是:
A列表
B浮点数
C整数
D字符串
正确答案 A :全局列表类型变量可以直接在函数中使用。
关于lambda函数说法错误的是
A必须使用lambda保留字定义
B函数中可以使用赋值语句块
C仅适用于简单单行函数
D匿名函数,定义后的结果是函数名称
正确答案 B :lambda函数内部只能用表达式,不能用带赋值的语句块。
以下能够返回struct_time类型时间的函数是:
A time.asctime()
B time.mktime()
C time.gmtime()
D time.time()
正确答案 C :能够返回struct_time类型时间的函数是:time.gmtime()和time.localtime()
哪个选项是下面代码的执行结果?

A绘制一个半径为90像素的弧形,圆心在小海龟当前行进的左侧
B绘制一个半径为90像素的弧形,圆心在小海龟当前行进的右侧
C绘制一个半径为90像素的整圆形
D绘制一个半径为90像素的弧形,圆心在画布正中心
正确答案 B :circle(x, y) 表示 以x长度为半径,y为角度,当前方向左侧x出为圆心,画圆。其中x和y都可以是负数,相应取反。
哪个选项不能改变turtle画笔的运行方向?
A bk()
B left()
C right()
D seth()
正确答案 A :bk()只能后退,但不改变方向,“后退"不是"转向”。
下面代码的输出结果是
A 10 10
B 20 10
C 10 20
D 20 20
正确答案 B
下列程序的输出结果为:
A 11 10
B 10 10
C 10 11
D 11 11
正确答案 C :这里没有全局变量,都是函数局部变量的运算。
以下关于函数调用描述正确的是:
A自定义函数调用前必须定义
B函数和调用只能发生在同一个文件中
C Python内置函数调用前需要引用相应的库
D函数在调用前不需要定义,拿来即用就好
正确答案 A :函数调用前必须已经存在函数定义,否则无法执行。Python内置函数直接使用,不需要引用任何模块。
下面是jieba库中用于精确分词的函数是:
A jieba.add_word()
B jieba.lcut_for_search()
C jieba.lcut(, cut_all=True)
D jieba.lcut()
#100355
正确答案 D :jieba.lcut(txt)对txt进行精确分词处理。
下面关于字典的描述错误的是:
A字典中键值对存在顺序
B键与值之间采用冒号分隔,键值对之间采用逗号分隔
C字典是键值对的集合
D字典表达了一种映射关系
正确答案 A :字典中各键值对之间没有顺序关系。
以下不能够与while循环搭配使用的保留字是:
A do
B continue
C break
D else
正确答案 A :Python没有do保留字
以下与Python异常处理无关的保留字是:
A in
B try
C else
D finally
正确答案 A :try-except-else-finally是与异常处理相关的保留字。
以下函数定义的说法错误的是:
A函数定义时,参数需要声明数据类型
B函数定义时,可以有return语句,也可以没有
C函数定义时,可以返回0个或多个结果,多个结果将作为元组类型返回
D函数定义时,参数个数可以是0个或多个,类型可以不同
正确答案 A :函数定义时的参数不需要声明类型。
关于Python组合数据类型,以下描述错误的是:
A组合数据类型可以分为3类:序列类型、集合类型和映射类型
B序列类型是二维元素向量,元素之间存在先后关系,通过序号访问
C Python的字符串、元组和列表类型都属于序列类型
D组合数据类型能够将多个相同类型或不同类型的数据组织起来,通过单一的表示使数据操作更有序、更容易
正确答案 B :序列类型总体上可以看成一维向量,如果其元素都是序列,则可被当作二维向量。
关于Python的元组类型,以下选项错误的是:
A元组中元素必须是相同类型
B元组采用逗号和圆括号(可选)来表示
C一个元组可以作为另一个元组的元素,可以采用多级索引获取信息
D元组一旦创建就不能被修改
正确答案 A :序列类型(元组、列表)中元素都可以是不同类型。
哪个选项是下面代码的输出结果?
A 2
B {‘b’:2}
C 3
D 1
正确答案 C :创建字典时,如果相同键对应不同值,字典采用最后(最新)一个"键值对"。
关于大括号{},以下描述正确的是:
A直接使用{}将生成一个列表类型
B直接使用{}将生成一个元组类型
C直接使用{}将生成一个集合类型
D直接使用{}将生成一个字典类型
正确答案 D :集合类型和字典类型最外侧都用{}表示,不同在于,集合类型元素是普通元素,字典类型元素是键值对。字典在程序设计中非常常用,因此,直接采用{}默认生成一个空字典。
S和T是两个集合,哪个选项对S^T的描述是正确的?
A S和T的差运算,包括在集合S但不在T中的元素
B S和T的交运算,包括同时在集合S和T中的元素
C S和T的补运算,包括集合S和T中的非相同元素
D S和T的并运算,包括在集合S和T中的所有元素
正确答案 C :集合"交并差补"四种运算分别对应的运算符是:& | - ^
以下不是Python序列类型的是:
A元组类型
B数组类型
C列表类型
D字符串类型
正确答案 B :Python内置数据类型中没有数组类型。
序列s,哪个选项对s.index(x)的描述是正确的?
A返回序列s中元素x第一次出现的序号
B返回序列s中x的长度
C返回序列s中元素x所有出现位置的序号
D返回序列s中序号为x的元素
正确答案 A :注意:s.index(x)返回第一次出现x的序号,并不返回全部序号。
列表ls,哪个选项对ls.append(x)的描述是正确的?
A向ls中增加元素,如果x是一个列表,则可以同时增加多个元素
B向列表ls最前面增加一个元素x
C替换列表ls最后一个元素为x
D只能向列表ls最后增加一个元素x
正确答案 D :ls.append(x),如果x是一个列表,则该列表作为一个元素增加的ls中。
给定字典d,哪个选项对d.values()的描述是正确的?
A返回一种dict_values类型,包括字典d中所有值
B返回一个元组类型,包括字典d中所有值
C返回一个集合类型,包括字典d中所有值
D返回一个列表类型,包括字典d中所有值
正确答案 A :运行如下代码:(其中d是一个预定义的字典)d={“a”:1, “b”:2}type(d.values())输出结果是:<class ‘dict_values’> d.values()返回的是dict_values类型,这个类型通常与for…in组合使用。
给定字典d,哪个选项对x in d的描述是正确的?
A判断x是否是字典d中的键
B x是一个二元元组,判断x是否是字典d中的键值对
C判断x是否是在字典d中以键或值方式存在
D判断x是否是字典d中的值
正确答案 A :键是值的序号,也是字典中值的索引方式。因此,x in d 中的x被当作d中的序号进行判断。
关于数据组织的维度,哪个选项的描述是错误的?
A高维数据由键值对类型的数据构成,采用对象方式组织
B数据组织存在维度,字典类型用于表示一维和二维数据
C二维数据采用表格方式组织,对应于数学中的矩阵
D一维数据采用线性方式组织,对应于数学中的数组和集合等概念
正确答案 B :字典用于表示高维数据,一般不用来表示一二维数据。
给定列表ls = [1, 2, 3, “1”, “2”, “3”],其元素包含2种数据类型,哪个选项是列表ls的数据组织维度?
A一维数据
B二维数据
C多维数据
D高维数据
正确答案 A :列表元素如果都是列表,其可能表示二维数据,例如:[[1,2], [3,4], [5,6]]。如果列表元素不都是的将列表,则它表示一维数据。
二维列表ls=[[1,2,3], [4,5,6],[7,8,9]],哪个选项能获取其中元素5?
A ls[4]
B ls[-1][-1]
C ls[1][1]
D ls[-2][-1]
正确答案 C :这是二维切片的使用方式。
以下选项对文件描述错误的是:
A文件是数据的集合和抽象
B文件是程序的集合和抽象
C文件是存储在辅助存储器上的数据序列
D文件可以包含任何内容
正确答案 B :函数或类是程序的集合和抽象,文件不是。
关于CSV文件的描述,哪个选项的描述是错误的?
A CSV文件格式是一种通用的、相对简单的文件格式,应用于程序之间转移表格数据
B CSV文件通过多种编码表示字符
C CSV文件的每一行是一维数据,可以使用Python中的列表类型表示
D整个CSV文件是一个二维数据
正确答案 B :一般来说,CSV文件都是文本文件,由相同编码字符组成。
关于文件关闭的close()方法,哪个选项的描述是正确的?
A如果文件是只读方式打开,仅在这种情况下可以不用close()方法关闭文件
B文件处理结束之后,一定要用close()方法关闭文件
C文件处理后可以不用close()方法关闭文件,程序退出时会默认关闭
D文件处理遵循严格的“打开-操作-关闭”模式
正确答案 C :打开文件后采用close()关闭文件是一个好习惯。如果不调用close(),当前Python程序完全运行退出时,该文件引用被释放,即程序退出时,相当于调用了close()。
文件句柄f,以下是f.seek(0)作用的是:
A寻找文件中第一个值为0的位置
B保持文件指针不动
C将指针跳转到文件最后
D将指针返回文件开始
正确答案 D :f.seek(offset)能够改变当前文件操作指针的位置,offset含义如下:0 – 文件开头; 1 – 当前位置; 2 – 文件结尾
以下函数或方法一般不用于CSV格式文件与一二维数据转换的是:
A.strip()
B.replace()
C.split()
D.join()
正确答案 B :.split()方法用于分隔多元素;.strip()方法用来去掉收尾多余换行符或空格;.join()方法用于将多个元素组织在一行中。这三个方法是CSV文件与一二维数据转换中最常用的方法。
关于数据组织的维度,哪个选项的描述是错误的?
A二维数据采用表格方式组织,对应于数学中的矩阵
B高维数据由键值对类型的数据构成,采用对象方式组织
C数据组织存在维度,字典类型用于表示一维和二维数据
D一维数据采用线性方式组织,对应于数学中的数组和集合等概念
正确答案 C :字典用于表示高维数据,一般不用来表示一二维数据。
给定列表ls = [1, 2, 3, “1”, “2”, “3”],其元素包含2种数据类型,哪个选项是列表ls的数据组织维度?
A高维数据
B多维数据
C二维数据
D一维数据
正确答案 D :列表元素如果都是列表,其可能表示二维数据,例如:[[1,2], [3,4], [5,6]]。如果列表元素不都是的将列表,则它表示一维数据。
关于Python对文件的处理,以下选项中描述错误的是
A Python通过解释器内置的open()函数打开一个文件
B文件使用结束后要用close()方法关闭,释放文件的使用授权
C Python能够以文本和二进制两种方式处理文件
D当文件以文本方式打开时,读写按照字节流方式
正确答案 D
以下选项中,不是Python对文件的读操作方法的是
A readline
B readlines
C readtext
D read
正确答案 C
给出如下代码
以下选项中描述错误的是
A通过fi.readlines()方法将文件的全部内容读入一个字典fi
B用户输入文件路径,以文本文件方式读入文件内容并逐行打印
C通过fi.readlines()方法将文件的全部内容读入一个列表fi
D上述代码中fi.readlines()可以优化为fi
正确答案 A
关于数据组织的维度,以下选项中描述错误的是
A数据组织存在维度,字典类型用于表示一维和二维数据
B二维数据采用表格方式组织,对应于数学中的矩阵
C一维数据采用线性方式组织,对应于数学中的数组和集合等概念
D高维数据由键值对类型的数据构成,采用对象方式组织
正确答案 A
关于Python文件打开模式的描述,以下选项中错误的是
A创建写模式n
B追加写模式a
C覆盖写模式w
D只读模式r
正确答案 A
执行如下代码:
以下选项中描述错误的是
A fo.seek(0)这行代码可以省略,不影响输出效果
B fo.writelines(ls)将元素全为字符串的ls列表写入文件
C执行代码时,从键盘输入“清明.txt”,则清明.txt被创建
D代码主要功能为向文件写入一个列表类型,并打印输出结果
正确答案 A
关于CSV文件的描述,以下选项中错误的是
A CSV文件格式是一种通用的、相对简单的文件格式,应用于程序之间转移表格数据
B CSV文件的每一行是一维数据,可以使用Python中的列表类型表示
C CSV文件通过多种编码表示字符
D整个CSV文件是一个二维数据
正确答案 C
关于Python文件的 ‘+’ 打开模式,以下选项中描述正确的是
A只读模式
B与r/w/a/x一同使用,在原功能基础上增加同时读写功能
C追加写模式
D覆盖写模式
正确答案 B
给定列表ls =[1, 2, 3, “1”, “2”, “3”],其元素包含两种数据类型,则ls的数据组织维度是
A一维数据
B多维数据
C高维数据
D二维数据
正确答案 A
给定字典d = {1:“1”, 2:“2”, 3: “3”},其元素包含两种数据类型,则字典d的数据组织维度是
A多维数据
B一维数据
C二维数据
D高维数据
正确答案 D
以下选项中,对CSV格式的描述正确的是
A CSV文件以英文逗号分隔元素
B CSV文件以英文分号分隔元素
C CSV文件以英文特殊符号分隔元素
D CSV文件以英文空格分隔元素
正确答案 A
表达式",".join(ls)中ls是列表类型,以下选项中对其功能的描述正确的是
A将列表所有元素连接成一个字符串,每个元素后增加一个逗号
B在列表ls每个元素后增加一个逗号
C将逗号字符串增加到列表ls中
D将列表所有元素连接成一个字符串,元素之间增加一个逗号
正确答案 D
二维列表ls=[[1,2,3], [4,5,6],[7,8,9]],以下选项中能获取其中元素5的是
A ls[–1][–1]
B ls[4]
C ls[1][1]
D ls[–2][–1]
正确答案 C

