
热门标签
当前位置: article > 正文
python实验 模块(运用jieba,词云wordcloud)_pip install jieba wordcloud -i
作者:IT小白 | 2024-06-02 11:45:47
赞
踩
pip install jieba wordcloud -i
笔记。
首先需要下载jieba和wordcloud:
win+r打开cmd或者Anaconda Prompt,输入以下代码:
-
- pip install jieba
pip install wordcloud下载stopwords和hlm文本文件的时候记得将编码设为:
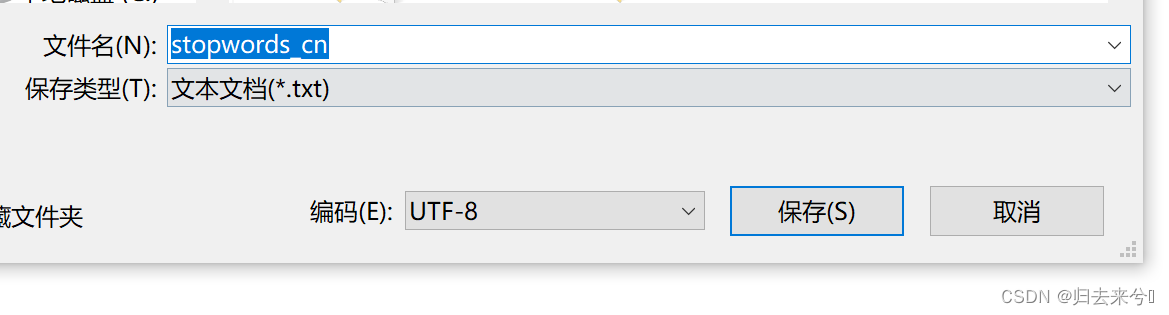
防止和代码冲突:

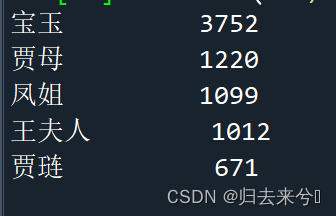
1.统计红楼梦人物的出现次数,输出出现次数最多的五个人;
-
- import jieba
-
- path = "C://Users//lzx//Desktop//hlm.txt" #绝对路径
-
- txt = open(path , 'r' , encoding = 'utf-8').read()#.read()实现全部读取,返回str类型
-
- # 精确分词
- txt1 = jieba.lcut(txt)#返回列表
- # txt1 = jieba.lcut(txt , cut_all = True) 返回所有可能 , 存在冗余
- book = {}
-
- #屏蔽掉无效词
- mapp1 = ["什么" , "一个" , "我们" , "那里" , "如今" , "你们" , "姑娘" , "起来" , "这里" , "老太太" , "说到" , "知道" ,"出来" ,"他们" , ""]
- mapp2 = ["说道" , "众人" , "奶奶" , "自己" , "一面" , "太太" , "只见" , "两个" , "怎么" , "没有" , "不是" , "不知" , "这个" , "听见"]
-
- for word in txt1:
- if((len(word) == 1) or (word in mapp1) or (word in mapp2)):
- continue;
- else:
- book[word] = book.get(word , 0) + 1;#字典类型中get函数贼好用
-
- #把字典中的元素以元组的形式放到列表中去
- l1 = list(book.items())
-
- # 排序
- l1.sort(key = lambda x : x[1] , reverse = True)#reverse为反转,默认升序
-
- #输出前五的人物
- for i in range(5):#range里面只能是数字(int)
- t = l1[i]
- print("{0:<10}{1:>5}".format(t[0],t[1]))
- #也可以print("{:<10}{:>5}".format(t[0],t[1]))
- #也可以:
- #x,y=l1[i].items() 这种写法可效仿
- #print("{0:<10}{1:>5}".format(x,y))
- # < > 是指左对齐 还是 右对齐 后面的数字是指占几位
- #可以在 "< >" 号前面写上占位符(如*),默认空格
- #至于本例中0,1是字典类型输出的一种格式,去掉0,1也可

2.制作红楼梦人物词云;
- import wordcloud as wd
- import jieba
-
- path = "C://Users//lzx//Desktop//hlm.txt"
- pathx = "C://Users//lzx//Desktop//stopwords_cn.txt"
-
- txt = open(path , 'r' ,encoding = 'utf-8').read()#string类型
- l1 = open(pathx , 'r',encoding = 'utf-8' ).read()#string类型
-
- #把 无用词文本 转换成列表
- ls = list(l1.split())
-
- txt = jieba.lcut(txt)#返回的是列表
-
- # 可实现删除功能,如:“刘备曰”变成“刘备”,也可以不用
- # =============================================================================
- # for i in range(len(txt)):#range里面只能是数字(int)
- # txt[i] = txt[i].replace('道' , '')
- # txt[i] = txt[i].replace('笑' , '')
- # txt[i] = txt[i].replace('听了' , '')
- # txt[i] = txt[i].replace('曰' , '')
- # =============================================================================
-
- w = wd.WordCloud(width = 1000 , height = 800, font_path='C://Windows//Fonts//simsun' ,stopwords = ls , background_color="white")
-
- # font_path 是文字样式,最后的simsun在右击属性中查看,如果出现方框而没有文字的情况,说明字体选的不合适
- # stopwords 是去除文字集 传入格式是列表
-
- w.generate(" ".join(txt))
- # 连结成一个字符串用空格分割
-
- w.to_file("C://Users//lzx//Desktop//worldcloud.png")
- # 生成图片到桌面

3.三国的和红楼梦的要求差不多,但没有给stopwords文档
- import wordcloud as wd
- import jieba
-
- path = "C://Users//lzx//Desktop//三国演义.txt"
- #pathx = "C://Users//lzx//Desktop//stopwords_cn.txt"
-
- txt = open(path , 'r' ,encoding = 'utf-8').read()#string类型
-
- txt = jieba.lcut(txt)#返回的是列表
- mp=['商议','何不','却说','不可','今日','不能','原来','于是','次日','大喜','大怒','大败','二人','左右','汉中''一人','此人','何故']
- txt1=[]
- for i in txt:
- if len(i)!=1:
- txt1.append(i)
- for i in range(len(txt1)):
- txt1[i] = txt1[i].replace('之' , '')
- txt1[i] = txt1[i].replace('曰' , '')
-
- w = wd.WordCloud(width = 1000 , height = 800, font_path='C://Windows//Fonts//simsun' ,stopwords=mp, background_color="white")
-
- # font_path 是文字样式,最后的simsun在属性中查看,如果出现方框而没有文字的情况,说明字体选的不合适
-
- w.generate(" ".join(txt1))
- # 连结成一个字符串用空格分割
-
- w.to_file("C://Users//lzx//Desktop//三国演义.png")
- # 生成图片到桌面

至于去除文字集,你可以多删一些词来完善,我懒得弄了。
另外,记录一个小知识:

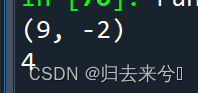
输出:(9,-2)



改正:

不知道为啥,这样都不行。
正确改正:

最后:
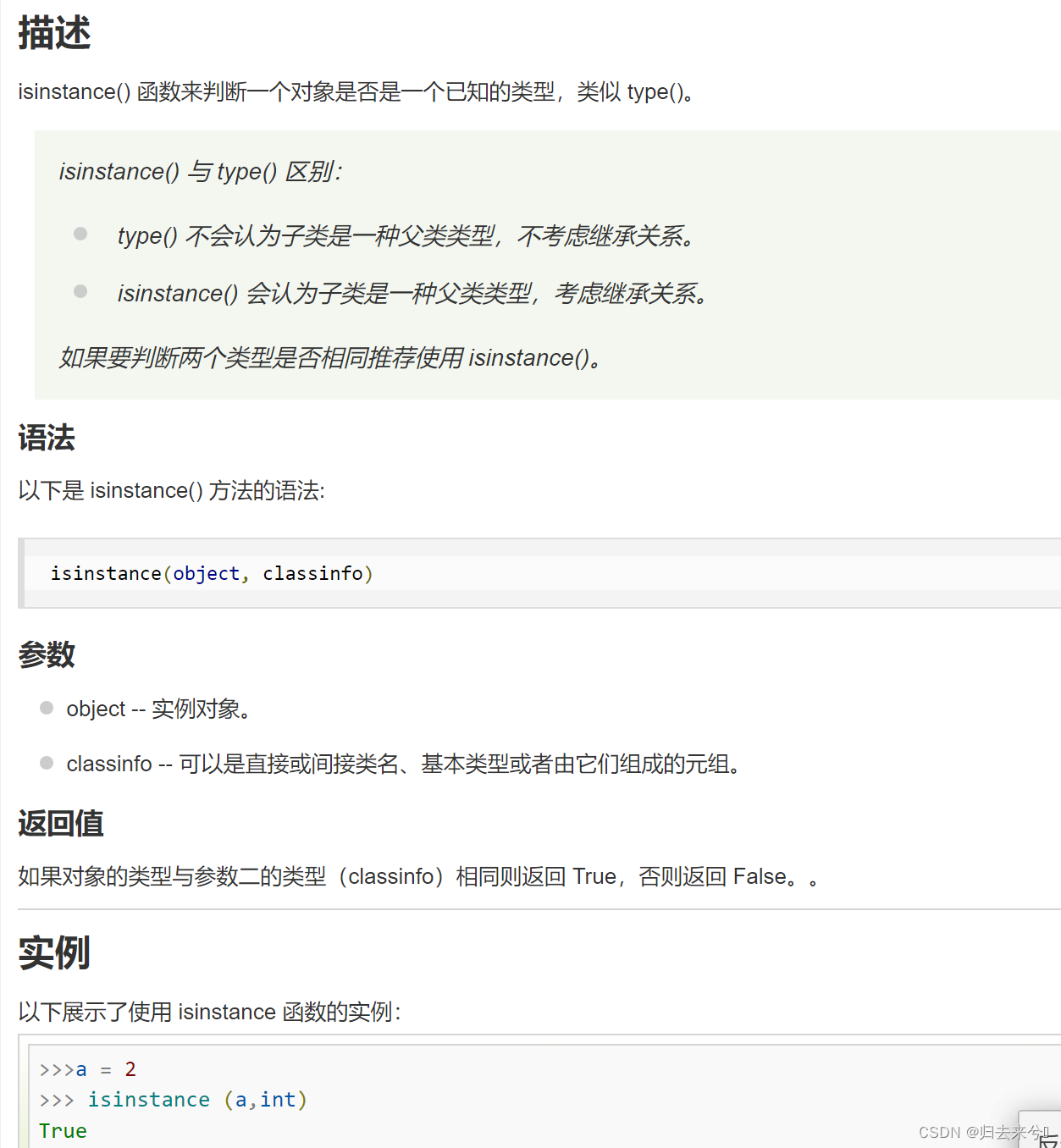
- def countV(a):
- if isinstance(a,int):
- return a
- else:
- return max(a),min(a)#python函数可以返回多个,且被打包成元组。
- l=[1,4,7,-2,9]
- print(countV(l))
-
- print(countV(4))
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/662574
推荐阅读
相关标签

