
- 1云计算2232-centos单节点搭建openstack(先电)_openstack单节点安装(先电版)
- 2开通git账号流程
- 3第3章 系统分析_系统分析平台综述csdn
- 4生产者/消费者模式的理解及实现_生产者消费者
- 5git提交代码到仓库的完整命令_git 提交命令到仓库
- 6专业认知 | 用 Python 制作 13 个小游戏,边玩边学!(含源码)_python编程游戏
- 7Android Activity启动流程一:从Intent到Activity创建_android startactivity
- 8linux shell脚本退出,Bash退出命令和退出代码
- 9测试工程师学习笔记(黑盒测试)_在黑盒测试中如果程序不能按照预期接收输入并产生正确的输出说明什么
- 10Git:文件大小写不敏感_windowsgit下载linux文件,大小写不敏感
Spark编程基础:(实验四)Sark SQL**编程初级实践**_首先为employee.json创建dataframe,并写出python语句完成下列操作:
赞
踩
Sark SQL**编程初级实践**
一、实验环境
操作系统:Ubunt 16.04.
Spark 版本:2.4.0。
数据库:MySQL。
Python 版本:3.4.3.
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
import os
os.environ["JAVA_HOME"]="/home/spark021/servers/jdk"
os.environ["PYSPARK_PYTHON"]="/home/spark021/servers/anaconda3/envs/pyspark/bin/python3.6"
os.environ["PYSPARK_DRIVER_PYTHON"]="/home/spark021/servers/anaconda3/envs/pyspark/bin/python3.6"
spark= SparkSession.builder.appName("employee021").config(conf=SparkConf()).getOrCreate()
二、 实验内容与完成情况
1. Spark SQL基本操作
为 employee.json 创建 DataFrame,并编写 Python 语句完成下列操作:
(1)查询所有数据;
(2)查询所有数据,并去除重复的数据;
(3)查询所有数据,打印时去除id 字段;
(4)筛选出 age>30 的记录;
(5)将数据按 age 分组;
(6)将数据按name升序排列;
(7)取出前3行数据;
(8)查询所有记录的 name 列,并为其取别名为 userame;
(9)查询年龄 age的平均值;
(10)查询年龄 age 的最小值。
# (1) 加载 JSON 文件并查询所有数据
df = spark.read.json("file:///home/spark021/data/employee021.json")
df.show()

# (2) 去除重复的数据
unique_df = df.dropDuplicates()
unique_df.show()

# (3) 去除 id 字段
df_no_id = df.selectExpr(*[c for c in df.columns if c != 'id'])
df_no_id.show()
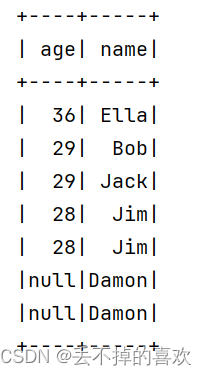
# (4) 筛选出 age > 30 的记录
older_than_30 = df.filter(df['age'] > 30)
older_than_30.show()

# (5) 按 age 分组
grouped_by_age = df.groupBy('age')
grouped_by_age.count().show()

# (6) 按 name 升序排列
sorted_by_name = df.orderBy('name')
sorted_by_name.show()
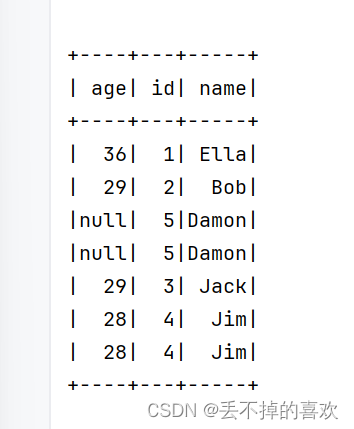
# (7) 取出前3行数据
first_three = df.limit(3)
first_three.show()

# (8) 重命名 name 列为 username
renamed_df = df.withColumnRenamed('name', 'username')
renamed_df.show()

# (9)使用聚合函数avg()计算年龄的平均值
average_age = df.agg({"age": "avg"}).collect()0
print("年龄平均值:", average_age)
# (10)使用聚合函数min()计算年龄的最小值
min_age = df.agg({"age": "min"}).collect()0
print("年龄最小值:", min_age)
# 关闭 SparkSession
spark.stop()

2.编程实现将RDD转换为DataFrame
from pyspark import SparkConf
from pyspark.sql import SparkSession,Row
from pyspark.sql.types import *
import os
os.environ["JAVA_HOME"]="/home/spark021/servers/jdk"
os.environ["PYSPARK_PYTHON"]="/home/spark021/servers/anaconda3/envs/pyspark/bin/python3.6"
os.environ["PYSPARK_DRIVER_PYTHON"]="/home/spark021/servers/anaconda3/envs/pyspark/bin/python3.6"
spark = SparkSession.builder.appName("RDD转换成DataFrame").config(conf=SparkConf()).getOrCreate()
*#**配置Spark应用程序
* employee021 = spark.sparkContext.\
textFile("file:///home/spark021/data/employee021.txt").\
map(lambda line: line.split(",")).\
map(lambda x: Row(id=x[0],name=x[1],age=x[1]))
employee021.foreach(print)
*#创建DataFrame(具有模式)
* schemaPeople = spark.createDataFrame(employee021)
*#注册为临时表,才可以通过sql查询
* schemaPeople.createOrReplaceTempView("people")
peopleDF = spark.sql("select * from people ")
peopleDF.show()
peopleRDD = peopleDF.rdd.map(lambda p: "id"+":"+p.id+","+"name"+":"+p.name+","+"age"+":"+p.age)
peopleRDD.foreach(print)
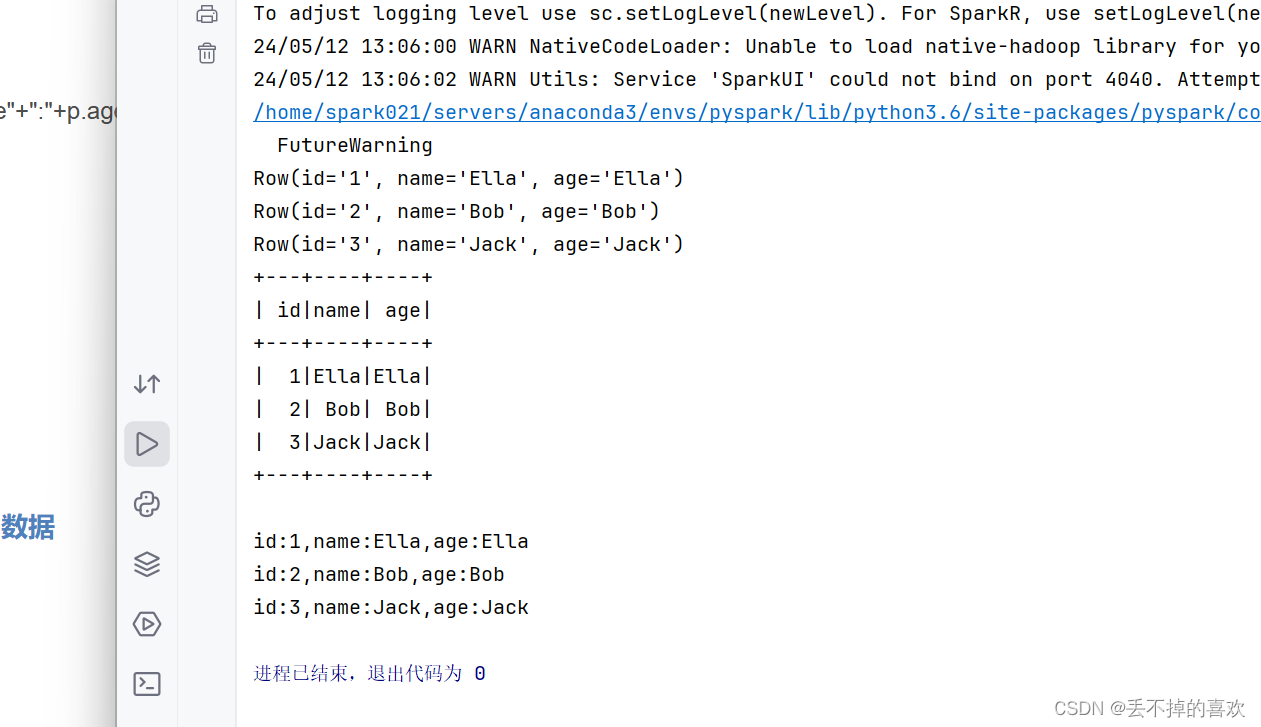
3.编码实现利用DataFrame读写Mysql的数据
(1)创建数据库
创建表
create table employee021 (id int(4), name char(20), gender char(4), age int(4));
插入数据
insert into employee021 values(1,'Alice','F',22);
insert into employee021 values(2,'John','M',25);
查看表
select * from employee021;
(2)进入saprk,配置 Spark通过 JDBC 连按数据库 MySQL,编程实现利用 DataFrame 插入数据到 MySQL 中,最后打印出 age 的最大值和 age 的总和。
from pyspark.sql import Row
from pyspark.sql.types import *
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
import os
os.environ["JAVA_HOME"]="/home/spark021/servers/jdk"
os.environ["PYSPARK_PYTHON"]="/home/spark021/servers/anaconda3/envs/pyspark/bin/python3.6"
os.environ["PYSPARK_DRIVER_PYTHON"]="/home/spark021/servers/anaconda3/envs/pyspark/bin/python3.6"
spark=SparkSession.builder.config("spark.jars", "/home/spark021/servers/spark-local/jars/mysql-connector-java-5.1.40-bin.jar").getOrCreate()
#配置 Spark通过 JDBC 连按数据库 MySQL
employeeDF = spark.read \
.format("jdbc")\
.option("driver","com.mysql.jdbc.Driver")\
.option("url","jdbc:mysql://localhost:3306/sparktest")\
.option("dbtable","employee021")\
.option("user","spark021")\
.option("password","123456")\
.load()
employeeDF.show()
#编程实现利用 DataFrame 插入数据到 MySQL 中
#设置模式信息
schema =StructType([StructField("id", IntegerType(),True),\
StructField("name",StringType(),True),\
StructField("gender",StringType(),True),\
StructField("age",IntegerType(),True)])
#设置两条数据,表示两个员工的信息
employeeRDD =spark\
.sparkContext\
.parallelize(["3 Mary F 26","4 Tom M 23"])\
.map(lambda x:x.split(" "))
#创建 Row对象,每个Row 对象都是 rowRDD 中的一行
rowRDD = employeeRDD.map(lambda p:Row(int(p[0].strip()),p[1].strip(),p[2].strip(),int(p[3].strip())))
#建立 Row 对象和模式之间的对应关系,也就是把数据和模式对应起来
employeeDF = spark.createDataFrame(rowRDD,schema)
#写人数据库
prop ={}
prop['user']='spark021'
prop['password']='123456'
prop['driver']="com.mysql.jdbc.Driver"
employeeDF.write.jdbc("jdbc:mysql://localhost:3306/sparktest",'employee021','append', prop)
employeeDF.show()
#最后打印出 age 的最大值和 age 的总和。
jdbcDF=spark.read.format("jdbc")\
.option("driver","com.mysql.jdbc.Driver") .option("url","jdbc:mysql://localhost:3306/sparktest")\
.option("dbtable","employee021") .option("user","spark021")\
.option("password","123456")\
.load()
jdbcDF.createOrReplaceTempView("employee021")
spark.sql("select MAX(age) from employee021").show()
spark.sql("select Sum(age) from employee021").show()



