
- 1vscode根据prettier设置的格式 保存自动格式化_vue保存自动格式化
- 2【Linux】gcc/g++、makefile、yum、git、gdb工具简单使用_gcc上传git
- 3红队内网攻防渗透:内网渗透之Kerberos协议全讲解
- 4thinkphp5 实现微信支付的步骤方法和简单的实例_thinkphp微信小程序支付功能实现
- 5linux swap交换分区_linux mem和swap
- 6ssm基于微信小程序的付费自习室系统j58m4【独家源码】计算机毕业设计问题的解决方案与方法_基于ssm的微信小程序付费自习室系统
- 7【OCR】OCR前置工作——透视矫正,使用YOLOv8-pose分支在卡证文档图片上进行yolo关键点检测_透视变换应用到yolo检测中
- 8WhatsApp模板信息申请大全:更好地触达WhatsApp客户_消息触达模版
- 9win10下用docker安装onlyoffice服务_onlyoffice镜像下载
- 10网络安全最全自学CTF,这100道题必刷!(1),2024年最新阿里P8手把手教你
【Python架构】在 Python 中使用架构模式管理复杂性_python应用文件架构
赞
踩
你的源代码是不是感觉像一个大泥球?依赖项是否在您的代码库中交织在一起,以至于改变感觉很危险或不可能?
随着业务的增长和领域模型(您在应用程序中解决的业务问题)变得更加复杂,我们如何在不从头开始重新编写所有内容的情况下解开我们创建的混乱?更好的是,我们如何避免一开始就陷入混乱?
鸟瞰图
以下是 Python 架构模式中介绍的技术的简要总结:
分层架构
-
单一职责
-
视图 vs 服务 vs 存储库 vs ORM vs 域
-
依赖倒置
-
高级与低级模块
-
抽象
领域驱动设计
-
先说“业务上下文”
-
领域建模(事件风暴等)
-
实体 vs ValueObjects vs 域服务
-
数据类
测试驱动开发
-
什么是TDD
-
在服务层进行高速测试
-
在域中进行低速测试
设计模式
-
存储库模式
-
服务层模式
-
工作单元模式
-
聚合模式
事件驱动架构
-
活动
-
消息总线
-
事件处理程序作为服务层
-
时间解耦
-
队列和代理
-
幂等性、故障和监控
-
命令
-
CQRS
-
简单读取与复杂命令
-
非规范化、缓存和最终一致性
我将简要介绍这些主题中的每一个,但我不会在这篇博文中重新打印这本书。这些将是我自己的话和我的解释,所以如果你想要“真正的交易”,我建议你去源头找一本这本书:)
分层架构
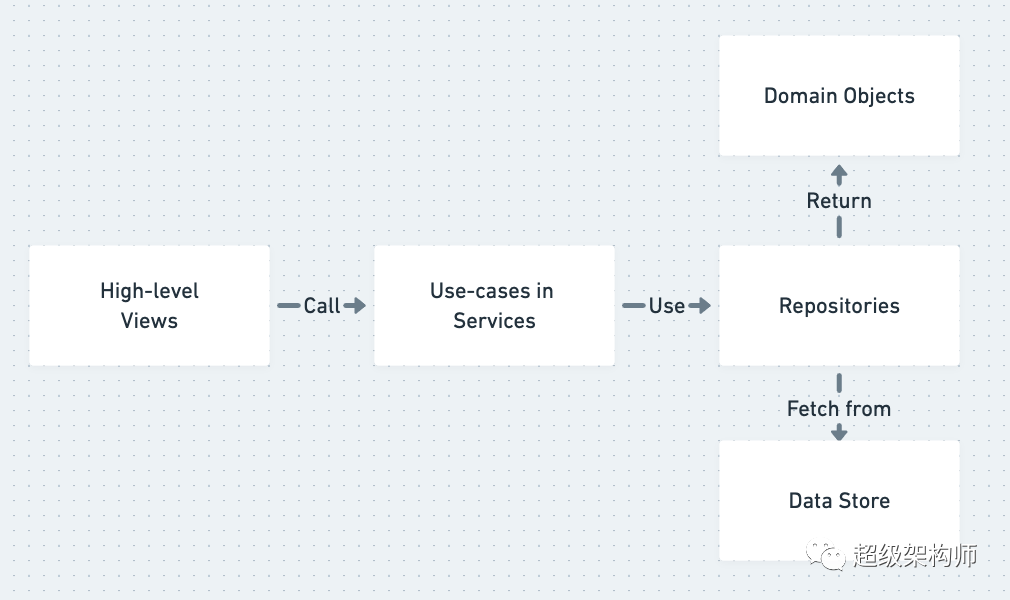
A simplified summary of Layered Architecture
-
SOLID 原则大量存在于良好的设计中。简而言之,如果您不知道,我将解释这些是什么。S,Single Responsibility,意味着代码应该有一个改变的理由,而且只有一个理由。O,对于 Open-Closed,意味着您的代码应该对扩展开放但对修改关闭。L,对于 Liskov Substitution,意味着子类的实例可以在不改变行为的情况下替换其父类的用法。我,对于接口隔离,意味着你的代码不应该被迫实现它不使用的行为。最后,D,表示依赖倒置,意味着一种松散耦合。
-
单一职责是分层架构背后的动机。也就是说,您的 Django 视图负责处理 HTTP 事务——获取输入、发送输出和状态码。这些视图应该委托给编排业务逻辑的服务。服务实现用例并且应该依赖于围绕低级细节的抽象,这些抽象可以包括存储库(用于存储抽象)和工作单元(用于事务或原子操作管理)。
-
这些层(视图、服务、存储库/UoW)从您的业务与特定用例/端点/网页相关的高层开始。然后他们使用抽象层直到我们写入数据库(在存储库中)或与其他系统通信等的低级操作。这就是依赖倒置的原理。
-
依赖倒置原则有两个部分。首先,高级模块不应该依赖于低级模块,两者都应该依赖于抽象。其次,抽象不应该依赖于细节,而细节应该依赖于抽象。因为这是一个如此复杂的话题,我不会详述它,如果你有兴趣,我建议你在这里、这里、甚至在本书中找到更好的阅读材料!
领域驱动设计

也称为 DDD。成为您领域的主人!什么是域?好吧,实际上,这取决于您要解决的业务问题!不,我不是在开玩笑。这实际上取决于 - 域的定义是您要解决的业务问题!
也就是说,如果您在一家航运公司工作,那么当您为您的域建模时,您会发现您可能有“ShippingContainers”和“Ships”或“Trucks”等。您可能有“SalesReports”和“PackingManifests” ”。但是,如果你要为一家软件公司工作,那么这些域对象就没有多大意义,你将拥有一个完全不同的域模型。
找出你的领域模型的过程被称为……“领域建模”。您可以为此使用几种不同的技术,我最喜欢的技术之一是“事件风暴”(https://eventstorming.com/)。不过,基本上,TLDR 是您需要与利益相关者(需要解决问题的人)坐下来弄清楚他们使用的语言。写下名词和动词,将它们连接在一起,并弄清楚你的领域是如何工作的。做对了,它会使剩下的过程变得更容易。
然后,您需要将此域模型转换为实际代码。出于我们的目的,我们专注于“实体”和“值对象”——区别在于实体具有永久身份(例如 ID 字段),而值对象根据其……嗯……值……来改变身份。例如,“用户”将有一个 ID 字段,您可以在不更改实际用户的情况下更改用户的电子邮件。然而,ValueObject 类似于地址。如果你改变地址的值,你就有了一个新的地址!看看它是如何工作的?
你可以很简单地使用“@dataclass”在 python 中表示你的域模型,它为你设置了你的构造函数和其他一些简洁的东西。这可以为您提供一个非常简单的对象,该对象仅用于存储特定属性(例如,城市、州、zip 或名字、姓氏等)。然后您可以从您的存储库中返回这些对象,并且您将有一个一致的结构来传递您的应用程序。让您的领域模型通过 ID 相互引用并根据需要进行水合,可选择存储在缓存中,然后您就可以参加比赛了。
测试驱动开发
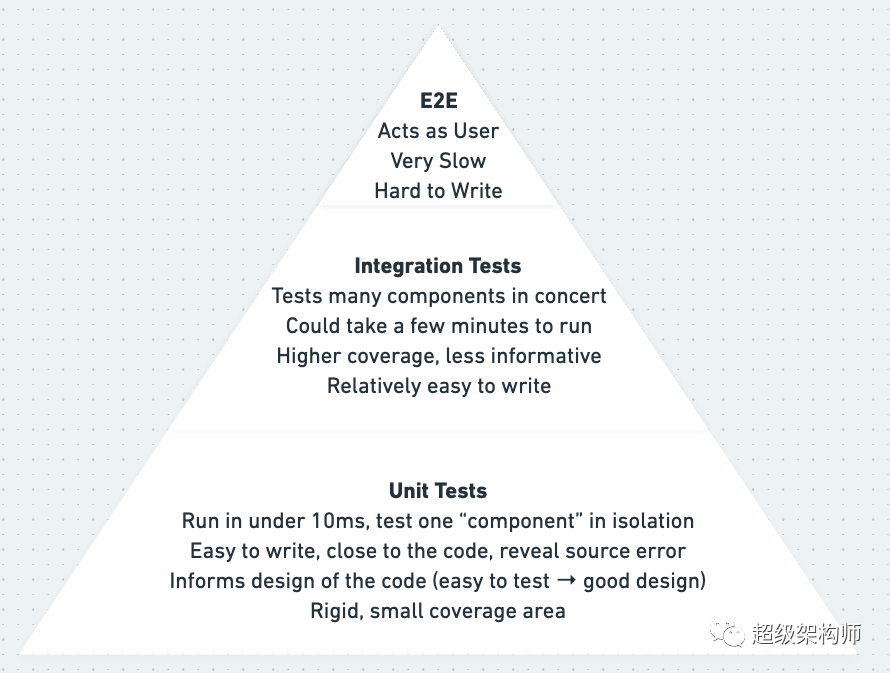
The “Testing Pyramid” with explanations
对于某些人来说,TDD 是一个有争议的话题。如果你不熟悉,TDD 的基本前提是只有三个规则:
-
除非您的测试失败,否则您不得编写任何代码。
-
你一次只能写一个测试用例,它应该开始失败。
-
一旦你有一个失败的测试,你应该只写足够的代码来使测试通过。
而已。然后你重复。人们说这个完整的循环是一个 30 秒的过程——我怀疑他们练习它的时间比我多一点。这也被称为“进攻性”测试,而不是我们都习惯的“防御性”测试——也就是说,防御性测试是在事后编写测试以“保护”自己。防御性测试可以为您提供一些保护,但要获得高覆盖率要困难得多。进攻性测试为您提供 100% 的覆盖率,并*迫使*您使用抽象等编写可测试的代码。
也就是说,TDD 不是灵丹妙药。它不是一种宗教。有(很少)TDD 不起作用的情况。TDD 也不会阻止您编写错误或编写糟糕的代码(您仍然也可以编写糟糕的测试)。考虑到这一点,重要的是通过在可能时以“高速档”进行测试并在必要时以“低速档”进行测试,从而最大限度地提高测试的价值。
高速档与低速档测试是本书中讨论的一个概念。总而言之,“高级”是指您在服务层或使用其他高级模块编写测试(参见上面的“分层架构”)。它们往往涵盖更多代码,并且最适合添加新功能或修复简单错误。“低档”测试是在域级别和其他低级别模块。当面临特别困难的错误或进行非常大的重构时,低档是最好的。
设计模式
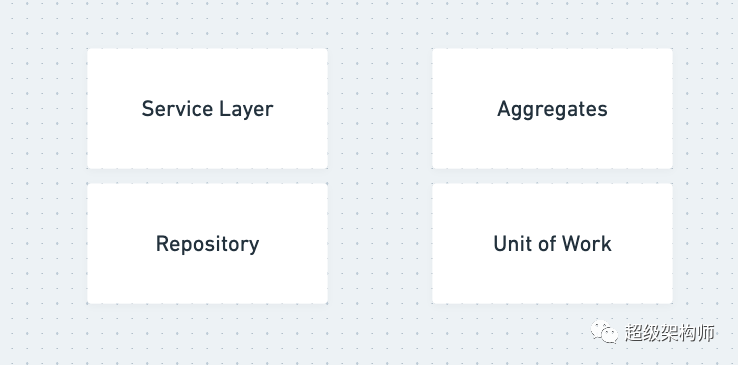
A simple layout of the design patterns we talk about
有很多设计模式值得了解。其他一些书籍,如“设计模式:可重用面向对象软件的元素”涵盖了其中的几本。Python 中的架构模式特别关注四种模式:存储库模式、服务层模式、工作单元模式和聚合模式。
存储库是围绕您的存储机制的抽象。您可以为 Redis、CSV 文件、数据库等创建一个存储库。它们都可以满足一个通用接口,如果您真的愿意,您可以将一个交换为另一个。目标是抽象出低级细节,以便您的高级模块不依赖于低级细节。这对于分层架构很重要,这也是本书广泛使用存储库模式的原因。
服务层只是您的业务逻辑的编排。当您第一次开始编写 API 端点时,倾向于将所有业务逻辑放在一个处理 API 请求的函数中。这违反了单一职责原则,因为 API 端点处理程序现在负责管理 HTTP 输入、响应以及业务逻辑的所有各个方面,如创建用户、验证输入、登录等。这些较低级别(尽管不是最低级别)任务可以委托给每个用例都有方法的服务。也就是说,该服务将具有注册用户、登录用户等的方法。这些方法将调用存储库并接收回域对象。
工作单元用于原子操作。想想“数据库事务”和“锁”,通常封装相关的操作。如果您需要“预订酒店房间”,那么您可以有一个包含此逻辑的“工作单元”。如果在查找可用房间并将房间分配给某人并处理此人的付款信息期间发生某种错误,那么工作单元将很好地为您回滚所有这些逻辑。您可以依赖低级别的数据库事务(并且您的工作单元可能在后台执行此操作),但是在您的服务函数中内联该逻辑开始混淆您的代码。使用工作单元来处理这些原子操作提供了一个干净的接口,可以利用 Python 强大的“with”语句并根据需要在您之后自动清理。
聚合是具有共同一致性边界的领域对象的集合。购物车之类的东西可以是一个聚合体——购物车内有几个领域对象,甚至购物车内可能还有其他聚合体。但是,在结账时,将购物车视为一个单元是很有用的。您可以将聚合视为对象树,并且可以通过根来引用聚合。
关于聚合的另一个注意事项是每个存储库应该有一个聚合。换句话说,您不应该拥有不是聚合的域对象的存储库。这样,聚合就形成了领域模型的“公共”API。
事件驱动架构
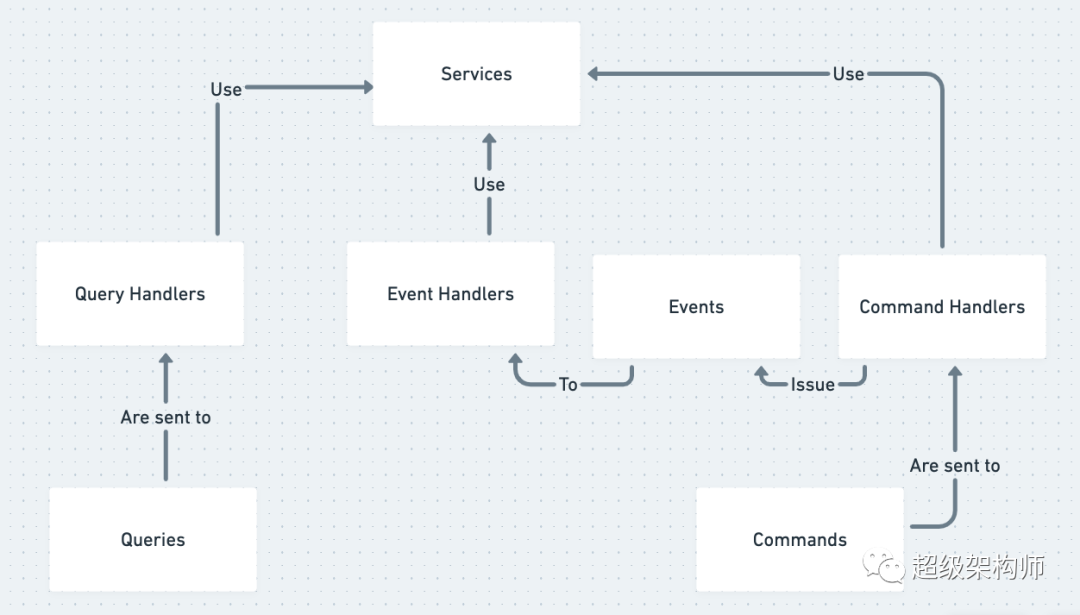
Simplified overview of Event Driven Architecture and CQRS
简而言之,EDA 就是您使用“事件”作为系统的输入。事件(或领域事件)是一个 ValueObject,您可以有内部和外部事件。内部事件永远不会离开您的系统,通常由消息总线(将事件映射到事件处理程序的简单路由器)之类的东西处理。外部事件被发送到其他系统并且非常适合“时间解耦”——您可以向消息代理发出事件,该消息代理异步管理一系列队列工作程序。
所有事件都可能失败,我们如何处理失败很重要。我们需要监控以了解事件何时失败以及哪些事件失败。我们还需要我们的事件处理程序是幂等的,所以当我们重试事件时,不会发生任何意外。常规事件可以在不影响整体操作的情况下安全地失败,这是事件和命令之间的重要区别。
命令是一种特殊类型的事件。一个常规事件可以有多个处理程序,而一个命令只有一个处理程序。一个命令,当它失败时,应该将异常重新抛出堆栈,而当一个事件失败时,应该有一些优雅的异常处理。命令通常会修改数据并触发副作用,将其与“返回数据”操作分开是 CQRS(Command/Query Responsibility Segregation)的目标。
CQRS 背后的主要动机是命令昂贵且复杂,通常需要一定程度的原子性以及即时一致性。另一方面,查询是简单的读取操作。查询通常不依赖于域(业务逻辑),而命令通常依赖于域。可以针对只读副本执行查询,其中命令通常最好针对主数据存储执行。查询还可以利用非规范化数据和最终一致性。这很好,因为查询通常比命令多几个数量级,这有助于系统更好地扩展。
应用所有这些
总而言之,重要的是逐个进行。您无需一次完成所有这些操作。如果您对尝试工作单元犹豫不决,或者您没有立即使用聚合,或者您甚至没有领域模型,那没关系!您可以从使用分层架构开始的最简单和最有效的事情之一 - 看看您是否可以使用服务将较低级别的模块与较高级别的模块解耦。看看您是否可以将您的存储逻辑隔离到您的服务使用的存储库中。如果您还可以绘制一些简单的数据类来表示您的域对象并让您的 ORM 依赖于这些,那就更好了。
如果您将依赖于自身的逻辑组合在一起,并使用抽象将模块分开,那么您将成为其中的一部分。查看接缝的位置并开始将代码拆分为可测试的块。有关这方面的一些优秀示例,请查看“有效地使用遗留代码”,这本书既是一本好书,又被“Python 中的架构模式”引用。
哦,如果您还没有阅读“Python 中的架构模式”,请特别注意结尾部分!这将为您提供更多关于我上面提到的所有内容的背景信息。我用大约 5 页总结了一本 300 多页的书,所以肯定有一些东西我遗漏了 :)
| 本文 :https://architect.pub/managing-complexity-architecture-patterns-python | ||
| 讨论:知识星球【首席架构师圈】或者加微信小号【ca_cto】或者加QQ群【792862318】 | ||
| 公众号 | 【jiagoushipro】 【超级架构师】 精彩图文详解架构方法论,架构实践,技术原理,技术趋势。 我们在等你,赶快扫描关注吧。 | |
| 微信小号 | 【ca_cea】 50000人社区,讨论:企业架构,云计算,大数据,数据科学,物联网,人工智能,安全,全栈开发,DevOps,数字化. | |
| QQ群 | 【285069459】深度交流企业架构,业务架构,应用架构,数据架构,技术架构,集成架构,安全架构。以及大数据,云计算,物联网,人工智能等各种新兴技术。 加QQ群,有珍贵的报告和干货资料分享。 | |
| 视频号 | 【超级架构师】 1分钟快速了解架构相关的基本概念,模型,方法,经验。 每天1分钟,架构心中熟。 | |
| 知识星球 | 【首席架构师圈】向大咖提问,近距离接触,或者获得私密资料分享。 | |
| 喜马拉雅 | 【超级架构师】路上或者车上了解最新黑科技资讯,架构心得。 | 【智能时刻,架构君和你聊黑科技】 |
| 知识星球 | 认识更多朋友,职场和技术闲聊。 | 知识星球【职场和技术】 |
| 领英 | Harry | https://www.linkedin.com/in/architect-harry/ |
| 领英群组 | 领英架构群组 | https://www.linkedin.com/groups/14209750/ |
| 微博 | 【超级架构师】 | 智能时刻 |
| 哔哩哔哩 | 【超级架构师】 | |
| 抖音 | 【cea_cio】超级架构师 | |
| 快手 | 【cea_cio_cto】超级架构师 | |
| 小红书 | 【cea_csa_cto】超级架构师 | |
| 网站 | CIO(首席信息官) | https://cio.ceo |
| 网站 | CIO,CTO和CDO | https://cioctocdo.com |
| 网站 | 架构师实战分享 | https://architect.pub |
| 网站 | 程序员云开发分享 | https://pgmr.cloud |
| 网站 | 首席架构师社区 | https://jiagoushi.pro |
| 网站 | 应用开发和开发平台 | https://apaas.dev |
| 网站 | 开发信息网 | https://xinxi.dev |
| 网站 | 超级架构师 | https://jiagou.dev |
| 网站 | 企业技术培训 | https://peixun.dev |
| 网站 | 程序员宝典 | https://pgmr.pub |
| 网站 | 开发者闲谈 | https://blog.developer.chat |
| 网站 | CPO宝典 | https://cpo.work |
| 网站 | 首席安全官 | https://cso.pub |
| 网站 | CIO酷 | https://cio.cool |
| 网站 | CDO信息 | https://cdo.fyi |
| 网站 | CXO信息 | https://cxo.pub |
谢谢大家关注,转发,点赞和点在看。

