
- 1基于云开发快速搭建智能名片小程序_做一个名片小程序
- 2探寻计算世界的进化:硬件、软件与未来发展_随着信息技术的飞速发展,软件、硬件
- 3【课程项目】BIT人工智能大作业:五子棋游戏_人工智能实验五子棋
- 4GitHub 创建分支 (branch) 并提交分支_git 新建branch
- 5华为认证传送网工程师 HCIA-Transmission V2.5(中文版)正式发布_hcia transmission 2.5
- 6海外云服务对比: AWS、GCP、Azure 与 DigitalOcean_aws 多收费
- 7【教程】使用 UnityWebRequest 进行 Post Json内容_unitywebrequest.post
- 8mac系统u盘启动盘制作教程,更新至macOS Sonoma 14_苹果电脑启动盘
- 9【头歌-Python】Python第六章作业(初级)_初始化一个空列表,输入一个正整数 n。 接下来,你将被要求输入 n 个指令,每得到一
- 10AI安全领域的“雨山机车大赛”,改变了什么?
【Linux】gcc/g++、makefile、yum、git、gdb工具简单使用_gcc上传git
赞
踩
目录
前言:
hi~大家好呀!欢迎点进我的文章~希望我这一系列的Linux文章能够给你带来帮助,当然,这也是我学习过程中的学习笔记,希望能够共同学习,一起进步呀!(〃'▽'〃)
这篇文章要介绍的是在Linux环境下做c/c++开发的时候需要的gcc和g++工具,以及make命令和Makefile文件来处理项目的工具,以及yum进行软件下载和管理,和git如何托管到gitee线上仓库进行管理代码最后九十调试器gdb的使用啦~
一、gcc/g++
1.安装工作
在介绍gcc/g++之前,先看一下是否安装了吧~一般默认Linux应该安装了gcc(我使用的是云服务器centos7)
gcc -v or g++ -v
上述两个命令可以查看对应的版本信息。
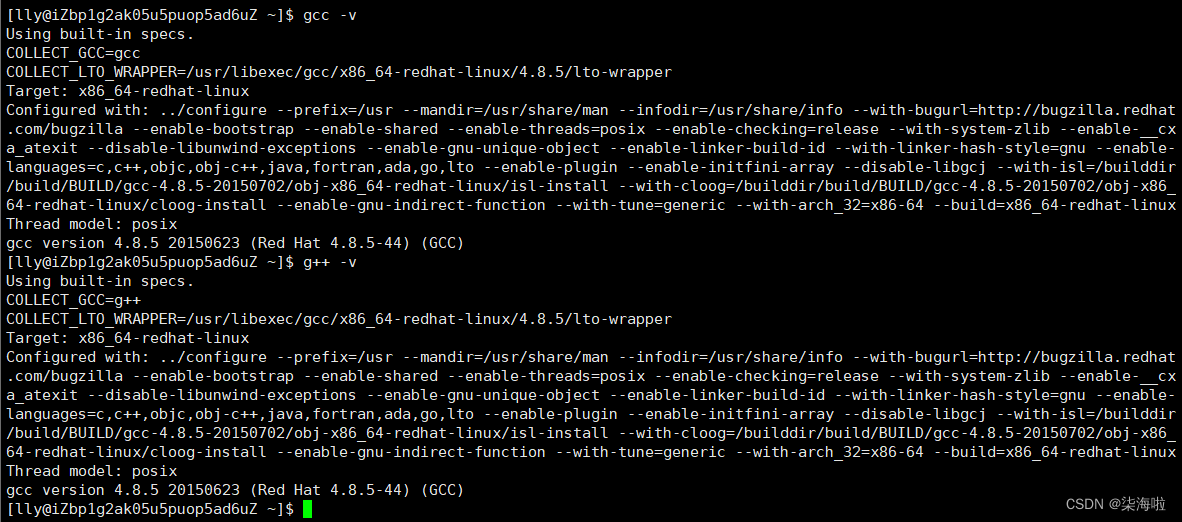
出现上面两种信息就表示了已经安装的有gcc和g++哦,这样我们就可以进行编译代码了。
如果没有出现,就说明没有安装,使用指令:yum install -y gcc-c++ 进行安装即可。
在使用工具进行编译代码之前,首先我们了解一下c/c++程序将代码编译成可执行程序的过程吧:
2.编译过程
流程一览:
1.预处理:头文件拷贝在源文件下、宏替换、注释和条件编译该去的去掉 || .i文件后缀
2.编译:将c语言转为汇编语言 || .s文件后缀
3.汇编:进行反汇编,将汇编语言转为二进制文件(即电脑能看懂)|| .o文件后缀
4.链接:将二进制文件内资源链接,变成可执行程序 || 无后缀
有了上面的介绍,那么我们的编译过程实际上使用gcc或者g++过程就是跟着上面的步骤一步一步的来的。
现在,在当前目录下创建了一个test.c文件,里面写上输出hello world的c语言代码,现在进行编译:
gcc -E test.c -o test.i
这里的test.c就是c源文件名,-E选项表示此次编译进行到预处理结束就停止,-o表示保存在名为test.i的文件中。
如果不加o就表示输出到屏幕上。
此时可以打开来看可以发现已经预处理过了。
然后进行编译:
gcc -S test.i -o test.s
这里的test.i就是之前只运行到预处理的文件,也可以换成源文件,只不过要重复进行预处理的操作。-S表示只是到编译完成就停止,不进行后面的汇编和链接步骤。-o和上面同理,存入test.s的文件中,否则就输出到屏幕上。
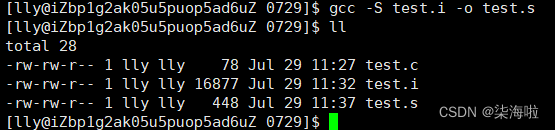
此时打开这个文件就可以发现转化成汇编语言啦:
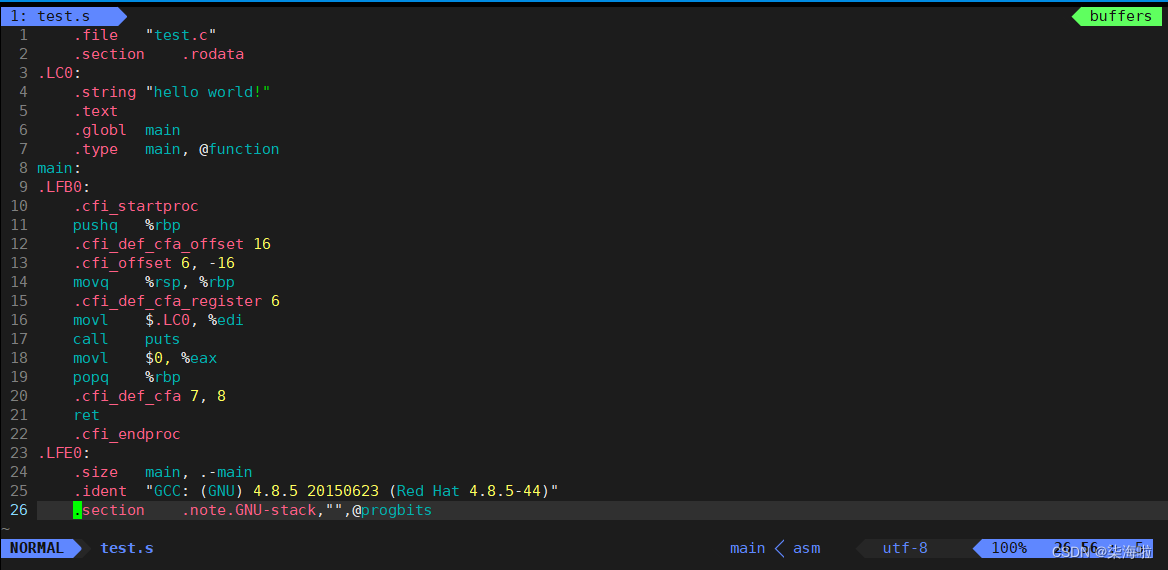
然后进行汇编操作:
gcc -c test.s -o test.o
test.s是上次编译得到的文件,即只进行到编译阶段的文件(里面是汇编代码),也可以是源文件(test.c)只不过需要重复上面的两次步骤。-c(小写)表示编译过程只进行到汇编操作完就结束(即把汇编语言转化为计算机看的懂的二进制文件)。-o同理,将其内容保存在tes.o文件内,不加o输出到屏幕上。
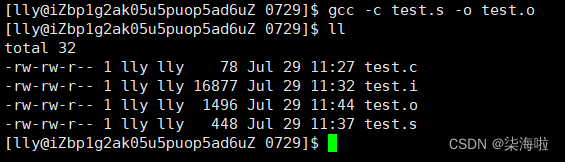
此时打开此文件可以发现已经反汇编成二进制文件啦,由于是10所以会显示乱码的哦~
最后一步,链接:
gcc test.o -o test ./test
没有选项就是默认执行到链接完就结束,即变成可执行程序。此可执行程序是默认动态链接的并且是release版本的(后面会进行介绍)。-o同理,保存到test文件内。此时此文件的权限就有x权限(执行) ./ 后面跟可执行文件名,就可执行程序。
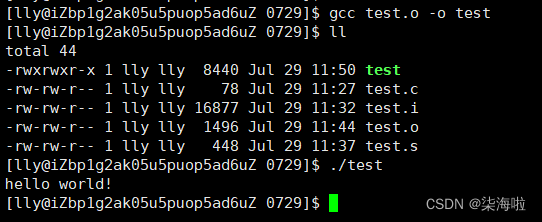
就这样,一个c源文件的编译和运行过程我们就通过gcc这个工具进行了实现。
3.动静态库的理解
首先,我们在编写c或者c++代码的时候,难道没有对所包的头文件存在疑惑吗?
当我们不包含比如常见的stdio.h或者iostream文件的时候就会发现所谓的输入输出语句就没有办法调用。原因就是这些语句并不是我们实现的,而是官方库里面实现的,而我们要去使用就自然而然要包含头文件来调用其函数。
那么,一般链接的方式有两种,1.动态链接-动态库,2.静态链接-需要静态库。
在Linux下:动态库.so 静态库.a
在Windows下:动态库.dll 静态库.lib
下面两种指令可以方便我们查看可执行程序的位数和依赖的动态库:
file 可执行程序名
ldd 可执行程序名
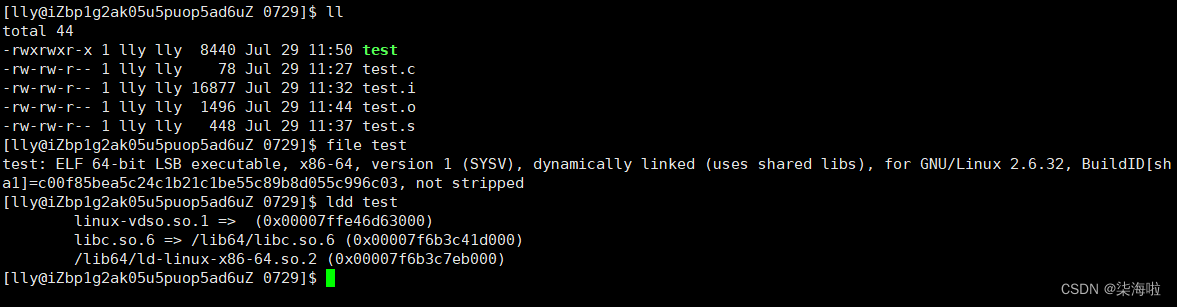
那么,动态链接和静态链接的区别何在?
动态链接(.so) 库的方法地址填入可执行程序中,建立关联,链接就要去库里找。优点:节约资源 缺点:需要依赖库
静态链接(.a) 库的方法的实现直接拷贝到可执行程序中。优点:不依赖库 缺点:浪费资源需要注意的是:gcc、g++默认形成的可执行文件使用动态链接.so 使用lld和file (基本是所有编译器默认的)
那么既然默认动态链接,那么如何静态链接呢?
gcc test.c -o test-static -static
当然,如果本地没有安装c或者c++的静态库的话会导致静态链接失败,所以没有安装的话就需要: sudo yum install -y glibc-static c静态库和sudo yum install -y libstdc++-static c++静态库
安装哦~

此时就可以发现静态链接和动态链接的两者可执行文件的大小差异了,很大。
二、make&Makefile
首先需要明确的是make是命令,Makefile是文件哦~
我们知道,真正实际开发的时候可不是只写一个源文件那么简单。而是很多文件组合在一起,每一个完成自己对应的功能,这样才能像一个项目。
但是,这样多个文件的话,以目前的掌握的Linux开发知识,难不成要一个一个文件进行编译?那样的话不就效率太低了嘛。
所以,在Linux下就有Makefile这个工具,来支持我们在Linux指令环境下进行项目的编译。
make指令需要在makefile文件下进行编写,这个文件名的首字母大写和小写均可。
Makefile文件的编写指令格式:
满足:依赖关系和依赖方法
命令名:文件名 -- 依赖关系
[tab]Linux命令 -- 依赖方法
可以理解为通过关系找到对应文件,依照方法进行命令操作。
还有一种特殊情况:
.PHONY:clean(位目标) //伪目标,直接执行方法的
clean: --关系
[tab] rm -f .. --方法上述伪目标一般用于清理文件上。即不需要依赖关系只执行命令。
需要注意的是:1.make 后面跟上Makefile中的命令名即可执行。2.如果后面没有跟上名字,默认执行第一个命令。
如上介绍完后,我们通过Makefile工具以上面的test.c文件编译一个可执行程序test1,并且clean命令对其删除。
首先创建Makefile(首字母大写小写均可)(vim可以直接进行创建)
![]()
写入依赖关系和方法:

保存退出后使用默认make看是否编译成功
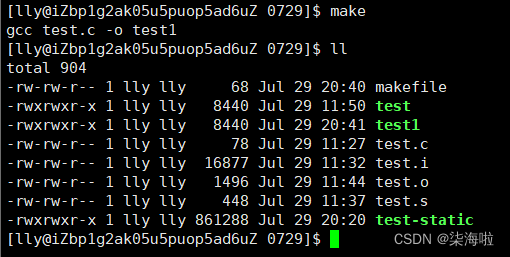
![]()
编译不存在问题,查看是否可以删除
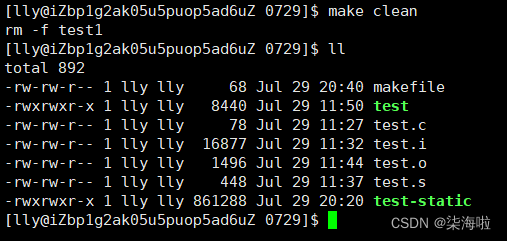
那么一般在进行项目编写的时候需要如何做呢?
在编译阶段执行两次,一次进行到.o文件,即进行到汇编阶段,最后一起进行链接。
演示Makefile:
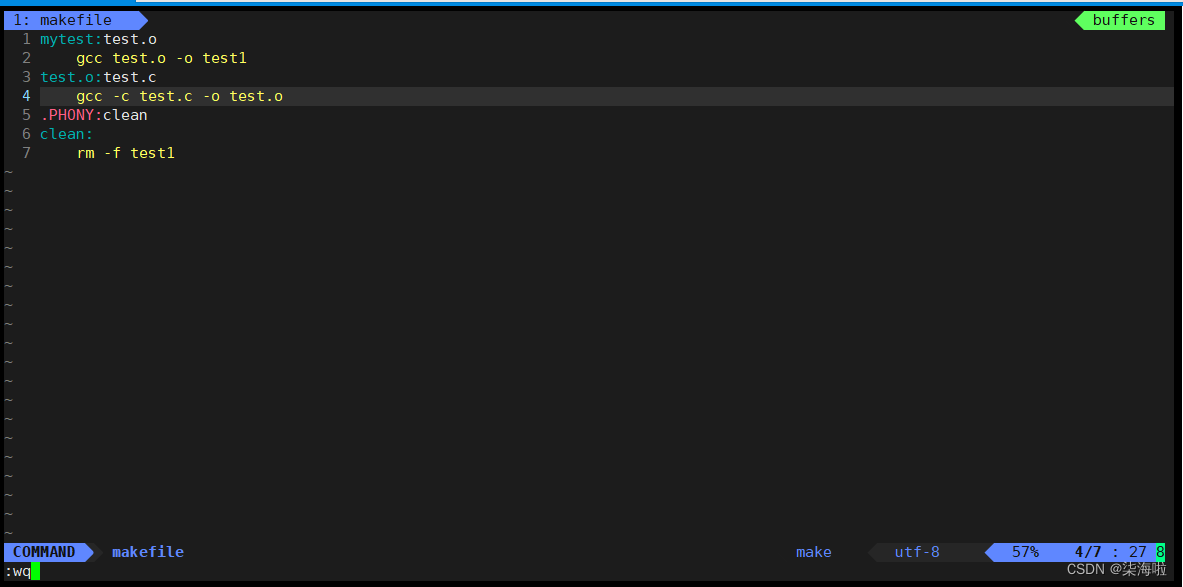
即命令递归下去。即可。
扩展:进度条代码编写
我们知道,程序代码均是从上往下执行的,比如下面的一段代码:
- #include<stdio.h>
- #include<unistd.h>
-
- int main()
- {
- printf("hello world\n");
- sleep(1);
- return 0;
- }
那么,此行代码的逻辑就是先打印出hello world,然后换行,暂停1秒后结束main函数。
那么将上述代码的\n去掉会发生什么事情呢?
去掉之后就会发现,是先休息了一秒然后才打印出helloworld的。这是为何?
*显示器设备,一般的刷新策略是行刷新 碰到\n,就把\n之前的所有字符全部会给我显示出来
因为上述代码最后一个\n去掉了,所以先执行的printf就没有从缓冲区刷新出来,而是等sleep之后就刷新了。
但是我们是有解决这个问题的方案的 -- 就是不让它在缓冲区存着,直接flush掉就可以啦~
但是这个就需要指定刷新哪里的缓冲区了,c语言会默认打开三个接口:stdin,stdout,stderr -- 文件类型,那么我们只需要使用fflush(stdout);就好啦~
- #include<stdio.h>
- #include<unistd.h>
-
- int main()
- {
- printf("hello world");
- fflush(stdout);//刷新缓冲区
- sleep(1);
- return 0;
- }
这样就会先显示出hello world啦,然后等待1秒程序结束。只不过不会换行哦~
由此,从\n我们可以了解到回车和换行的意义所在:
换行:当前位置上下*平移。
回车:回到当前行最开始位置所以很多换行实际上就是 回车换行 所以键盘上的enter可以看的出来先下在最左
c语言中的回车换行就是 \n, 回车就是\r 没有换行这个哦~
了解了上面的这个(\r fflush)那么我们是否可以制作一个进度条呢?
我们知道进度条从起点开始,满满向右增长,那么就要从起点开始变化,想下面这个代码就是不行的:
- #include<stdio.h>
- #include<unistd.h>
-
- int main()
- {
- char arr[102] = {0};
- int i = 0;
- for (i = 0; i < 101; i++)
- {
- arr[i] = '=';
- printf("[%s]",arr);
- printf("\n");
- usleep(100000);
- }
- return 0;
- }
-

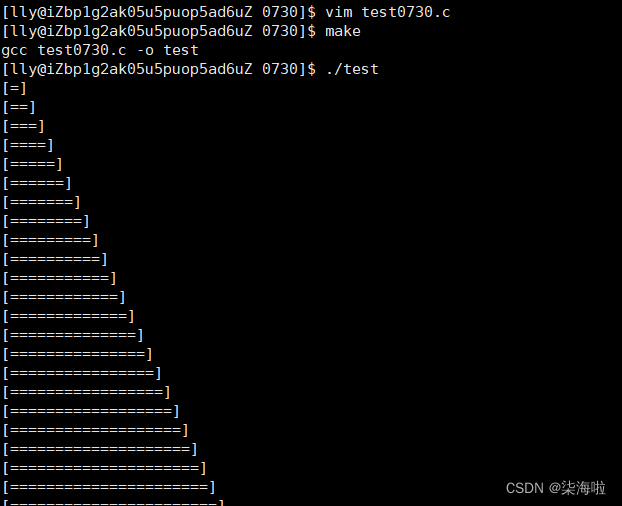
所以我们想一直从起点刷新就可以使用/r。但是在printf后面添加/r后就会出现如下情况:
![]()
前面一直卡着就不会出来,因为默认是回车,到开头,没有\n并且下一次就要开头显示所有就会出现上面的问题。很好解决,刷新缓冲区,并且格式化控制好位置,可以加上一些会动的字符表示加载。并且注意显示%需要%%进行表示:
- #include<stdio.h>
- #include<unistd.h>
-
- int main()
- {
- char arr[101] = {0};
- const char* ar = "//--||\\\\--";
- int i = 0;
- for (i = 0; i < 100; i++)
- {
- arr[i] = '=';
- printf("[%-100s][%d%%]%c\r",arr, i+1, ar[i%10]);
- fflush(stdout);
- usleep(100000);
- }
- printf("\n");
- return 0;
- }
![]()
三、yum
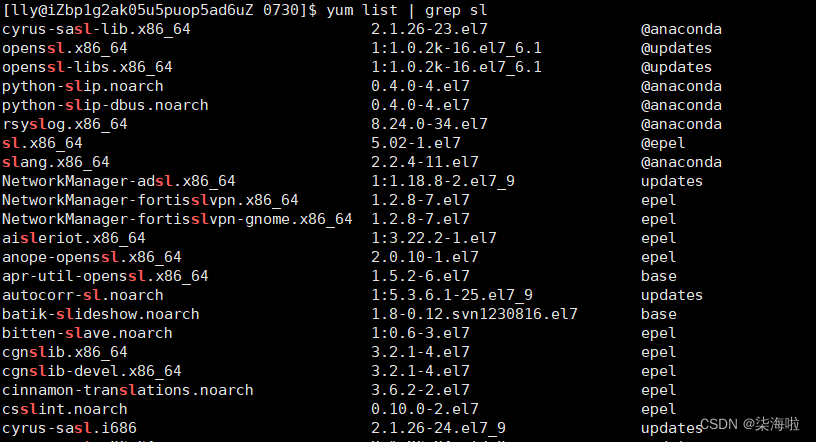
相信还没真正学过这个的已经多次使用了。yum可以类似于安装东西的软件,在Linux下。是用Python写的一个小工具。它是通过对应的yum源实现下载的。比如可以试着下载一个配置源:epel-release,可以下载到许多扩展的东西。
yum list
把Linux下能下载的软件显示出来:yum search sl -- 搜索命令显示 sl名字的软件(不推荐)
yum list | grep sl -- 和上面搜索命令类似,但是更加美观(推荐)
名字、位 版本 提供商yum install 软件 -- 安装软件(需要较高权限)
-y选项表示不需要问我是否要安装yum remove 你的软件移除
-y同理不需要提示
(娱乐一下)links 访问网址更新的时候,需要更新的就是动态库等...
四、git
git就是实现线上托管代码,并且实现版本控制器的功能。
检查git是否存在即查看其版本: git --version
![]()
git上传代码三板斧:
前提:需要将线上(gitee)仓库克隆到本地仓库
git clone 克隆仓库网址 (.git即就是用来同步)
1.添加到本地git:git add (指定文件 一般是.(全部))
2.提交上传日志:git commit -m "内容"
3.上传线上(同步代码):git push
其他情况:
1.登录邮箱Run
2.git pull 重新克隆代码(即同步代码 -- 本地代码和远端代码不同步会强制同步)
3.gitignore文件 #不想提交某个些文件到远端git仓库,就可以添加到这个文件内
首先将要传的文件传入本地仓库内:
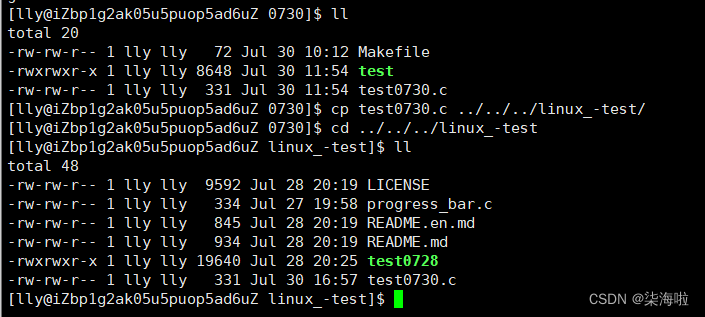
1.上传到.git中
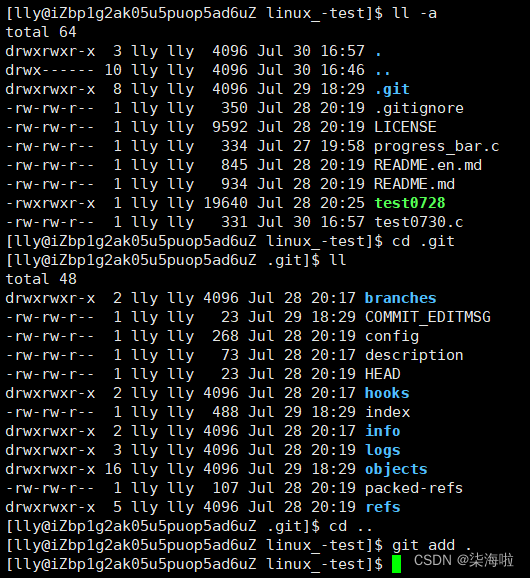
2.添加日志:

3.上传线上仓库:
输入自己对应的邮箱以及密码:
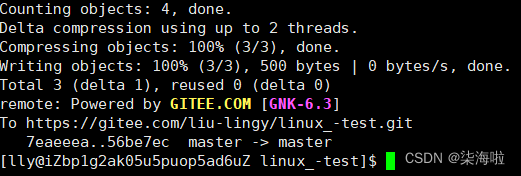
显示如上上传成功:

五、gdb
gdb是在Linux环境下的一个调试器。为了方便使用调试,自然也是通过指令的方式进行。只不过需要前提debug版本,即在链接过程使用 -g 进行debug版本,否则默认是release版本。
现在以如下代码进行演示:
- #include<stdio.h>
- int factorial(int n)
- {
- int sum = 1;
- int i = 1;
- for (i = 1; i <= n; i++)
- {
- sum *= i;
- }
- return sum;
- }
-
- int main()
- {
- int n = 0;
- printf("输入一个数,算其的阶乘:\n");
- scanf("%d", &n);
- printf("%d\n", factorial(n));
- return 0;
- }
首先要链接成debug版本:gcc 源文件名 -o 目标文件名 -g
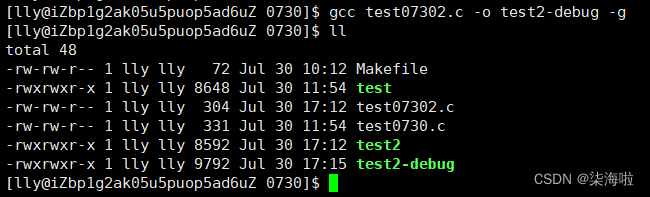
test2是默认的release版本的,可以发现两者的大小有区别。
现在进行gdb的介绍:
默认显示:list(l)
全部显示 l 0(l是简写的第一个字母,0是表示从头开始)
直接回车会执行上一条历史命令(如果命令没有变化可以直接回车)运行到第一个断点处run(r)开始调试 -- 类比于vs F5 没有断点就直接运行结束
打断点: b 18 (breakpoint)在第十八行处打断点
查看断点:info b
删除断点:d num 此num是打断点时的编号,可以通过查看断点进行查看
逐过程:next(n)执行一步 -- 类似于vs F10
打印变量值:p 变量
逐语句: step(s) 进入函数 -- 类似于vs F11
查看调用堆栈:bt
将函数跑完:finish
常显示变量的值:display 变量
取消常显示:undisplay num num同样是编号,display会显示编号
跳转指定行:until 行(只建议在函数内执行)
c:运行下一个断点处停下来
(在info b查看 有Enb选项 - 开关)
关闭断点:disable num
打开断点:enable num修改变量 :set var 变量 = ...
quit退出
首先显示代码:
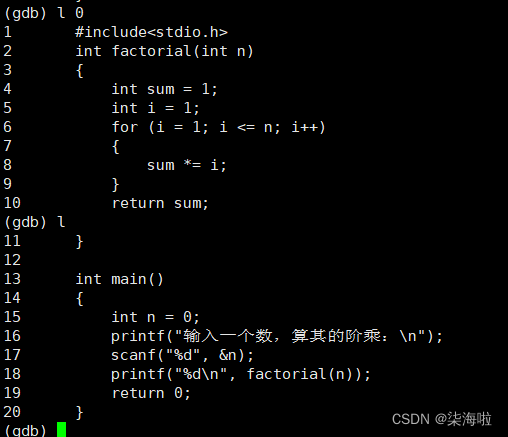
r开始调试:(可以与Windows下的vs2019的调试器F5类比)
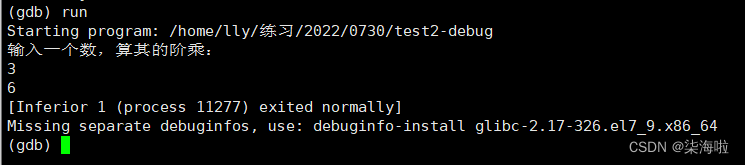
不存在断点会直接运行程序到结束。
b打断点:
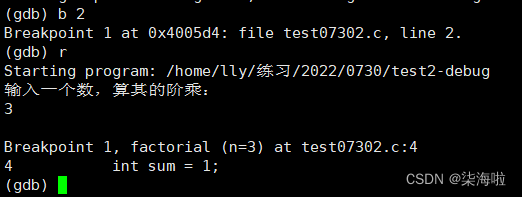
这样再次进行run就会运行到断点处。
info b查看断点:

End是开关 Num是编号,控制开关和删除断点均需要编号。
d num删除断点:
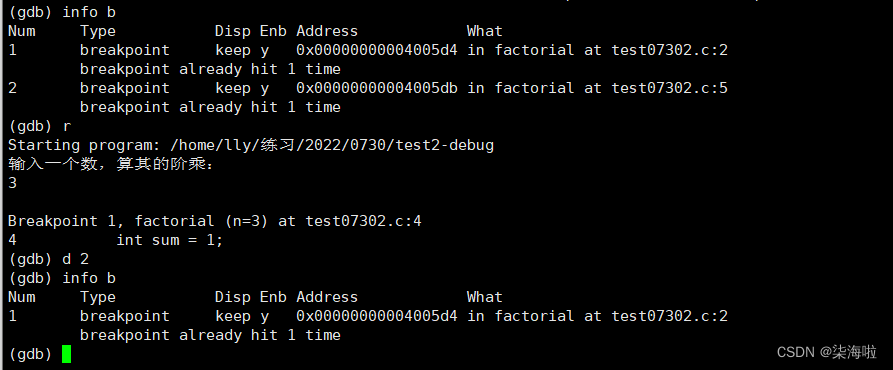
再次查看断点就可以发现已经删除了。
逐过程n:(类似于vs2019中的f10)
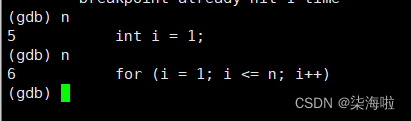
打印变量值p:
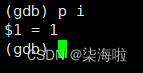
逐语句s:(类似于vs2019中的f11)
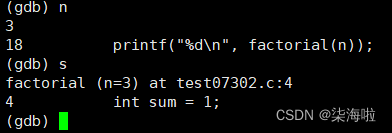
bt查看调用堆栈:

一个主函数一个是阶乘的函数。
将函数跑完finish:(即直接将此函数执行完)
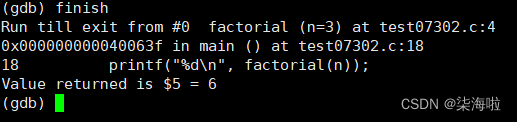
返回值6。
display常显示变量的值:(同时也会显示该变量的编号num)
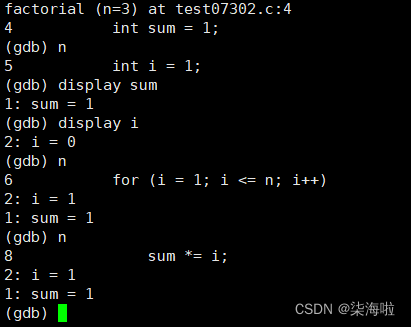
undisplay num 取消对应编号的常显示:

until 跳转到某行(建议在函数内部执行):
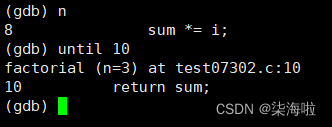
c运行到下个断点停止。
比如如下两个断点:


打开关闭断点enable disable num:
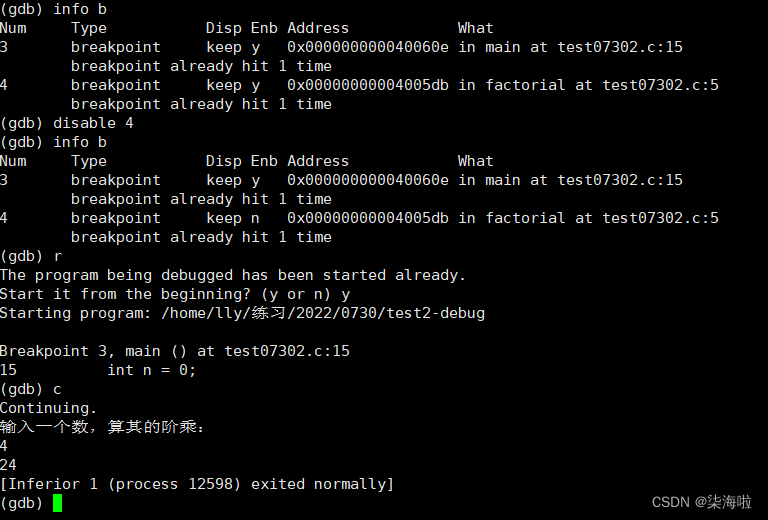
可以发现把函数内部的断点关闭后,c就不会调到下一个断点处,而是跳出程序了,Enb状态那一栏也会变成n。
 set var 修改变量值:
set var 修改变量值:

变量也可以直接在内部进行修改哦~
quit退出。

