
热门标签
热门文章
- 1蓝桥杯物联网开发 入门篇③ 利用CubeMX配置一个MDK工程_物联网 cube
- 2前端面试常见问题小总结(更新中)_前端开发面试时项目中遇到的问题
- 3AI时代,GPGPU和NPU哪个才是王者?_海光dcu华为npu
- 4mysql数据迁移_mysql数据库迁移
- 5【Holocubic简化修改版——基于STM32F405+ESP8266-12F:使用FreeRTOS和标准库】
- 6强化学习——学习笔记3
- 7[蓝桥杯物联网从0开始]第15届蓝桥杯物联网省赛CubeMx、Keil5软件的学习与使用_stm32cubemx用那种系列符合蓝桥杯
- 8Rust 的网络编程实践与技巧
- 9完全关闭Windows 安全中心防火墙
- 107个月我 自学Java 找到啦一份9k的工作,分享经历_go,上船! 推荐-java从零到就业 整个课程讲历时7个月左右,对标薪资:15000。 对标薪
当前位置: article > 正文
PubMedBERT:生物医学自然语言处理领域的特定预训练模型_微软的pubmedbert
作者:IT小白 | 2024-06-03 10:11:57
赞
踩
微软的pubmedbert
今年大语言模型的快速发展导致像BERT这样的模型都可以称作“小”模型了。Kaggle LLM比赛LLM Science Exam 的第四名就只用了deberta,这可以说是一个非常好的成绩了。所以说在特定的领域或者需求中,大语言模型并不一定就是最优的解决方案,“小”模型也有一定的用武之地,所以今天我们来介绍PubMedBERT,它使用特定领域语料库从头开始预训练BERT,这是微软研究院2022年发布在ACM的论文。
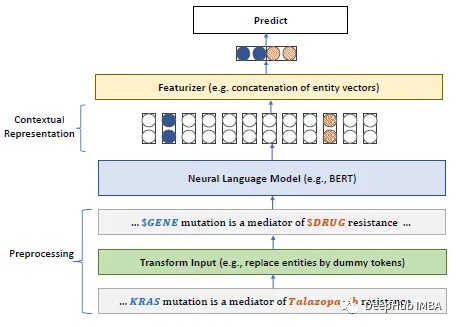
论文的主要要点如下:
对于具有大量未标记文本的特定领域,如生物医学,从头开始预训练语言模型比持续预训练通用领域语言模型效果显著。提出了生物医学语言理解与推理基准(BLURB)用于特定领域的预训练。
PubMedBERT
1、特定领域Pretraining
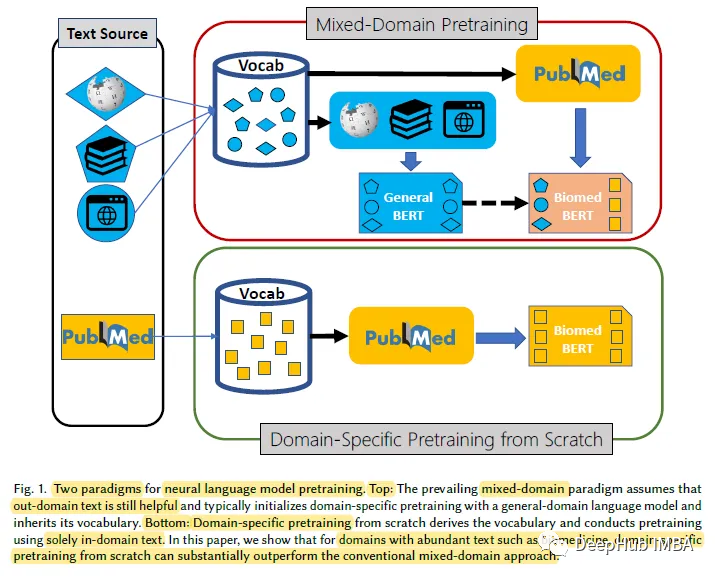
研究表明,从头开始的特定领域预训练大大优于通用语言模型的持续预训练,从而表明支持混合领域预训练的主流假设并不总是适用。
2、模型
使用BERT。对于掩码语言模型(MLM),全词屏蔽(WWM)强制要求整个词必须被屏蔽。
3、BLURB数据集

据作者介绍,BLUE[45]是在生物医学领域创建NLP基准的第一次尝试。但BLUE的覆盖范围有限。针对基于pubmed的生物医学应用,作者提出了生物医学语言理解与推理基准(BLURB)。
PubMedBERT使用更大的特定领域语料库(21GB)。
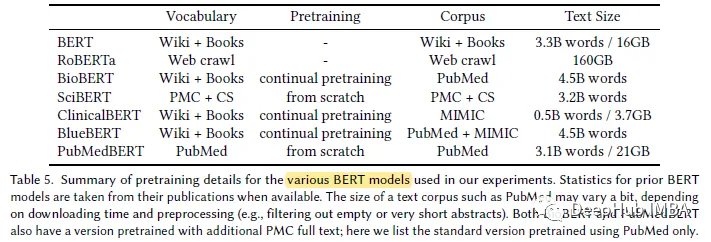
结果展示
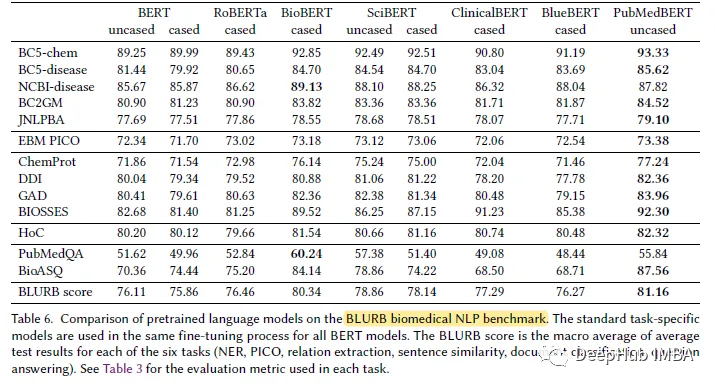
在大多数生物医学NLP任务中,PubMedBERT始终优于所有其他BERT模型,并且通常具有显著的优势。
论文地址:
https://avoid.overfit.cn/post/02c09a271dd246f4b04421794d87c679
作者:Sik-Ho Tsang
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/666761
推荐阅读
相关标签

