
- 1peer not authenticated和Could not generate DH keypair解决方法
- 2单目相机位姿估计:PNP算法原理与实践_pnp 相机
- 3Linux怎么查看boot目录的挂载分区_linux查询boot
- 4C#程序变量统一管理例子 - 开源研究系列文章
- 5电赛神器:FPGA+STM32开发板PCB开源_示波器gerber 图
- 6vue与element小案例、小技巧_vue结合element实例
- 7性能测试看这一篇文章就够了!性能测试学习之测试工具Jmeter
- 8使用Token方式实现用户身份鉴权认证_token发起权限认证请求
- 9git原理及指令_commitid 父节点
- 10python:ipaddress --- IPv4/IPv6 操作库_python ipv6
《异常检测——从经典算法到深度学习》26 Time-LLM:基于大语言模型的时间序列预测_timellm代码运行
赞
踩
《异常检测——从经典算法到深度学习》
- 0 概论
- 1 基于隔离森林的异常检测算法
- 2 基于LOF的异常检测算法
- 3 基于One-Class SVM的异常检测算法
- 4 基于高斯概率密度异常检测算法
- 5 Opprentice——异常检测经典算法最终篇
- 6 基于重构概率的 VAE 异常检测
- 7 基于条件VAE异常检测
- 8 Donut: 基于 VAE 的 Web 应用周期性 KPI 无监督异常检测
- 9 异常检测资料汇总(持续更新&抛砖引玉)
- 10 Bagel: 基于条件 VAE 的鲁棒无监督KPI异常检测
- 11 ADS: 针对大量出现的KPI流快速部署异常检测模型
- 12 Buzz: 对复杂 KPI 基于VAE对抗训练的非监督异常检测
- 13 MAD: 基于GANs的时间序列数据多元异常检测
- 14 对于流数据基于 RRCF 的异常检测
- 15 通过无监督和主动学习进行实用的白盒异常检测
- 16 基于VAE和LOF的无监督KPI异常检测算法
- 17 基于 VAE-LSTM 混合模型的时间异常检测
- 18 USAD:多元时间序列的无监督异常检测
- 19 OmniAnomaly:基于随机循环网络的多元时间序列鲁棒异常检测
- 20 HotSpot:多维特征 Additive KPI 的异常定位
- 21 Anomaly Transformer: 基于关联差异的时间序列异常检测
- 22 Kontrast: 通过自监督对比学习识别软件变更中的错误
- 23 TimesNet: 用于常规时间序列分析的时间二维变化模型
- 24 TSB-UAD:用于单变量时间序列异常检测的端到端基准套件
- 25 DIF:基于深度隔离林的异常检测算法
- 26 Time-LLM:基于大语言模型的时间序列预测
- 27 Dejavu: Actionable and Interpretable Fault Localization for Recurring Failures in Online Service Systems
- 28 UNRAVEL ANOMALIES:基于周期与趋势分解的时间序列异常检测端到端方法
相关:
26. Time-LLM:基于大语言模型的时间序列预测
论文名称:Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
会议名称:ICLR 2024
下载地址:https://arxiv.org/abs/2310.01728
源码地址:https://github.com/KimMeen/Time-LLM
论文配套数据集:百度云盘提取码jxw5 | google云盘
论文相关推荐阅读链接:https://mp.weixin.qq.com/s/ZnR33epXCB7N5Y_kO0YJ_w https://mp.weixin.qq.com/s/FSxUdvPI713J2LiHnNaFCw

26.1 论文概述
这篇论文提出了TIME-LLM框架,用于重新编程大型语言模型以实现通用时间序列预测。尽管预训练的大型语言模型(如GPT-3和GPT-4)在自然语言处理和计算机视觉领域展现出对多种任务的强大泛化能力,但在时间序列预测方面由于数据稀疏性问题发展受限。TIME-LLM旨在不改变预训练模型结构的前提下,利用大型语言模型识别复杂序列模式和推理的能力来进行时间序列预测。
通过将输入的时间序列转换为文本原型表示,并添加Prompt-as-Prefix(PaP)策略来丰富上下文和提供自然语言形式的任务指导,TIME-LLM有效地实现了连续时间序列数据与语言模型操作的离散符号之间的模态对齐。经过转换的时间序列片段从冻结的语言模型中输出后,被投影得到预测结果。
通过实验证明,TIME-LLM在主流预测任务中表现卓越,特别是在少量样本(few-shot)和零样本(zero-shot)场景下超越了现有的专用预测模型,同时保持了高效且无需从头训练的模型再编程特性。这种方法展示了如何将现成的大型语言模型应用于时间序列预测任务,揭示出它们在这方面的未充分利用潜力,并推动构建能够同时精通语言和顺序数据任务的多模态基础模型。相比传统针对特定领域的专门模型设计,TIME-LLM在提升时间序列预测的通用性、效率和知识融合能力方面迈出了坚实一步。
26.2 论文结构
-
引言:介绍时间序列预测在现实世界动态系统中的重要性,对比强调当前专门模型与通用大模型在处理不同任务上的差异,提出利用大型语言模型(LLMs)改进时间序列预测技术的潜在优势。
-
相关工作:回顾时间序列预测领域中任务特定学习方法的局限性,以及CV和NLP领域预训练模型的成功应用及启发,探讨时间序列预训练模型的发展现状及其局限性。
-
方法:提出TIME-LLM框架,通过重新编程LLMs并保持主干模型不变,将时间序列转化为文本原型输入,并结合Prompt-as-Prefix策略增强模型对时间序列概念的理解和推理能力,从而生成准确预测。
-
实验配置:详述TIME-LLM在多个时间序列数据集上的实验设置,包括模型超参数、训练过程、损失函数和评价指标等。
-
结果与分析:展示TIME-LLM在主流预测任务中优于现有最佳模型,尤其在少样本和零样本学习场景表现出色,且模型再编程效率高,有效释放了LLMs在时间序列预测中的潜能。
-
结论:总结本研究的主要贡献,即成功开发出一种新颖的LLMs再编程方法,使之适用于时间序列预测,开启跨模态基础模型在时序数据分析中的新范式。
26.3 相关工作
26.3.1 论文内容
论文的第2部分主要讨论了时间序列预测领域中传统任务特定学习方法与预训练模型应用的发展背景和局限性。
首先,该部分指出大多数专门设计的时间序列预测模型(如ARIMA、LSTM、TCN以及Transformer等)针对的是具体任务和特定领域(如交通流量预测),它们在小规模数据集上进行端到端训练,尽管在狭义任务上表现出色,但受限于缺乏通用性和对多种时间序列数据的泛化能力。
其次,随着CV和NLP领域中预训练模型的成功案例(例如BERT、GPT-3等),研究者受到启发并开始关注时间序列预训练模型(TSPTMs)的研发。这些模型采用监督学习或自监督学习策略进行预训练,以便学习如何表示各种输入时间序列,并通过微调使得预训练模型适应相似领域的特定任务,从而提高效率和性能。
然而,由于时间序列数据的稀疏性问题,TSPTMs的应用仍然局限于较小规模的数据集。此外,本论文还提到近期有研究进一步探索跨模态适应技术,即从NLP和CV的强大预训练基础模型转移知识到时间序列建模中,包括多模态微调和模型重新编程等方法,但关于时间序列的相关研究尚不多见。这一部分内容为论文提出TIME-LLM框架提供了研究背景,并突出了现有方法在处理时间序列数据时面临的问题和挑战,进而引出本文所提出的解决思路和方法。
26.3.2 相关背景 — 特定任务学习、迁徙学习、基础模型、重编译模型
图片来自 “智能运维前沿” 微信公众号
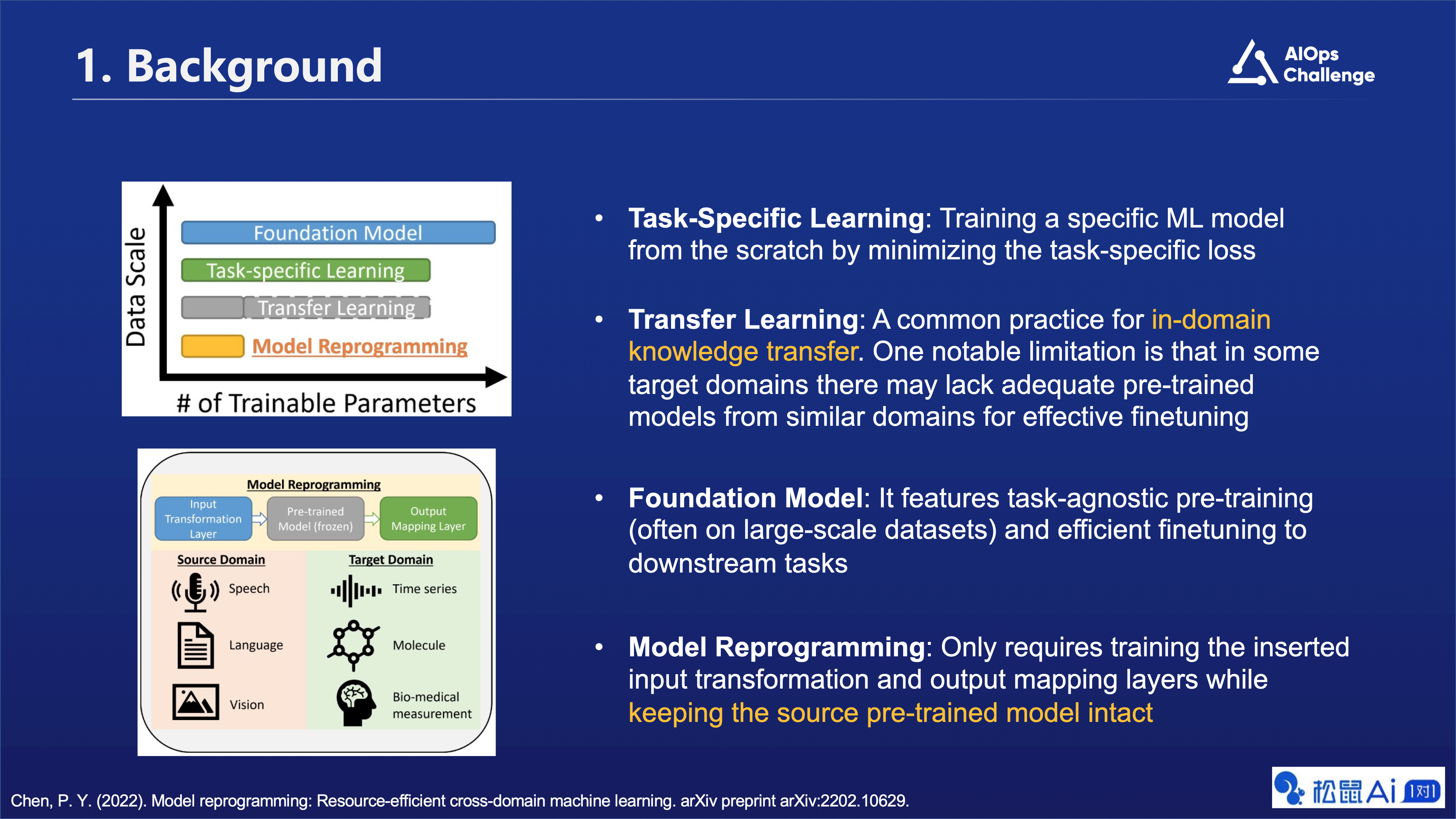
- 任务特定学习(Task-Specific Learning):通过从头开始训练一个特定的机器学习模型来实现,方法是通过最小化任务特定损失函数。
- 迁移学习(Transfer Learning):是一种常见的实践,用于在领域内转移知识。然而,在某些目标领域中可能缺乏足够的来自相似领域的预训练模型来进行有效的微调。
- 基础模型(Foundation Model):它具有任务无关的预训练(通常在大规模数据集上进行)以及对下游任务的有效微调。
- 模型重编程(Model Reprogramming):只需要训练插入的输入转换层和输出映射层,同时保持源预训练模型的完整。
此外,还展示了模型重编程的概念,包括输入转换层、预训练模型(冻结)和输出映射层。这个流程图还显示了模型重编程如何应用于不同的领域,如语音、语言、视觉、生物医学测量等。
26.3.3 算法动机
动机 1: Reprogramming makes LLMs instantly ready for time series tasks
动机 2:Reprogramming makes LLMs more powerful for time series tasks
如下图左边所示,输入时间序列到LLM中,通过 reprogrammer 对参数进行调整,进而完成对应的分析任务。
接着看右边,论文保持预训练的大语言模型完整,并仅通过微调重编程器来实现某些对齐。其中的 重编程 ≈ 适应+对齐。
最后可以理解为论文的核心方法:
- 适应使大语言模型理解如何处理输入的时序数据→打破领域隔离,实现知识共享;
- 对齐进一步消除领域边界,便于获取知识。

26.4 核心内容
前面内容介绍了 Motivation,接下来要解决的问题就比较明了:论文是怎么做到的。
26.4.1 从图2说起
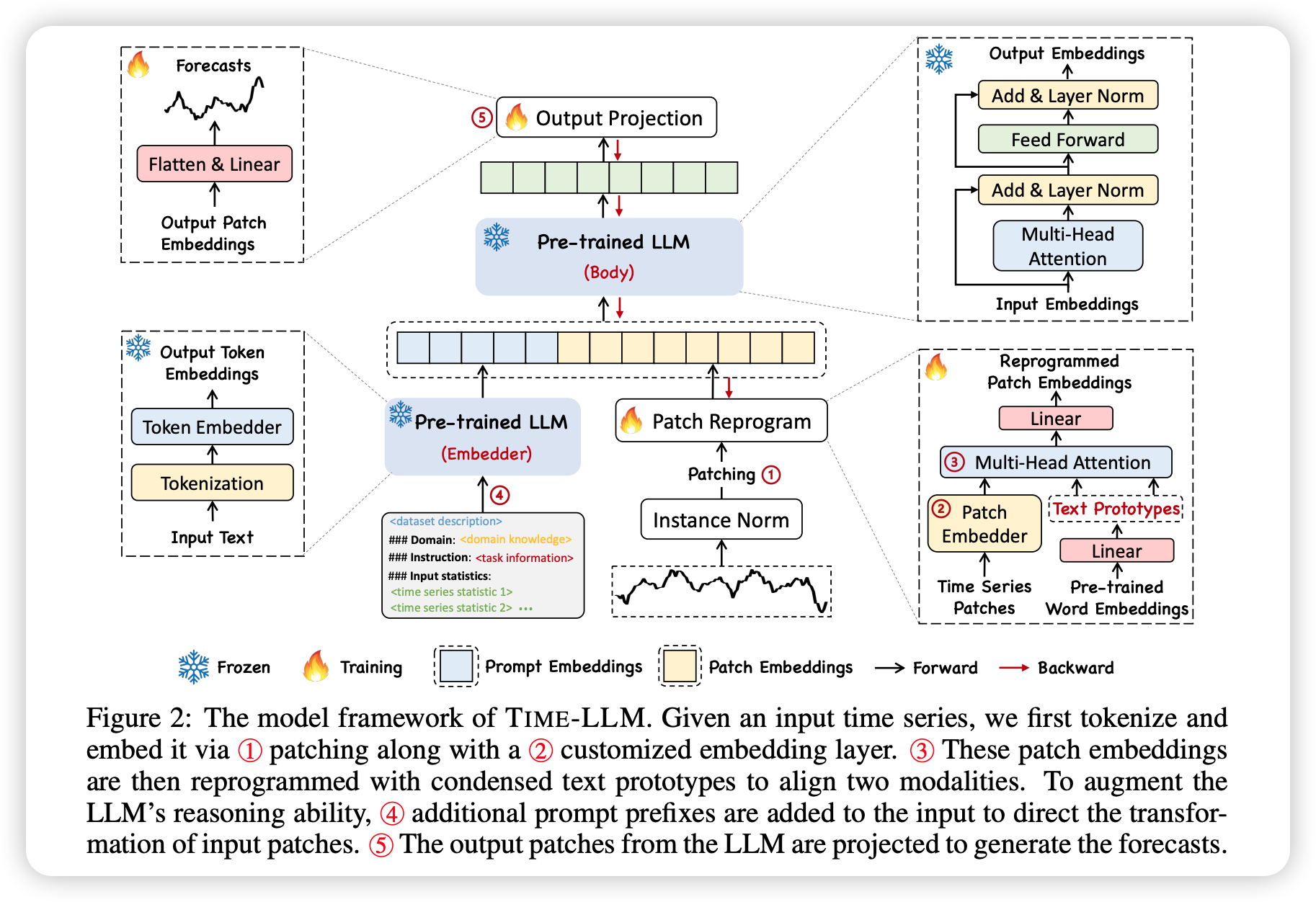
Time-LLM 主要分为两个部分:跨模态适应(Cross-modal Adaptation)和跨模态对齐(Cross-modal Alignment)。这种方法利用了预训练的大语言模型(Pre-trained LLM),并结合了领域知识和任务指令来生成更好的预测结果。
在跨模态适应阶段,通过添加和层归一化(Add & Layer Norm)、多头注意力(Multi-Head Attention)等操作,将输入的时间序列数据与自然语言进行融合。这有助于激活大语言模型的时序理解与推理能力。
在跨模态对齐阶段,通过重新编程时间序列的片段嵌入(Patch Reprogramming),将时间序列数据转换到源数据表示空间中,以使时间序列和自然语言的模态对齐。这样可以更好地利用大语言模型的预训练能力,从而提高预测准确性。
图片中的 “Frozen(雪花图案)” 是指在模型训练过程中,某些层或参数被冻结,即它们的权重不会在训练过程中更新。这种做法通常用于保留预训练模型的特征提取能力,同时只微调模型的其他部分以适应特定任务。
在这个上下文中,“Frozen” 可能指的是预训练的大语言模型(Pre-trained LLM)的某些部分,这些部分在训练过程中保持不变,而其他部分如 Patch Reprogramming 和 Instance Norm 等则可能被调整以适应新的时间序列数据。这样做的目的是利用预训练模型的通用性,同时针对特定任务进行优化,以获得更好的预测性能。
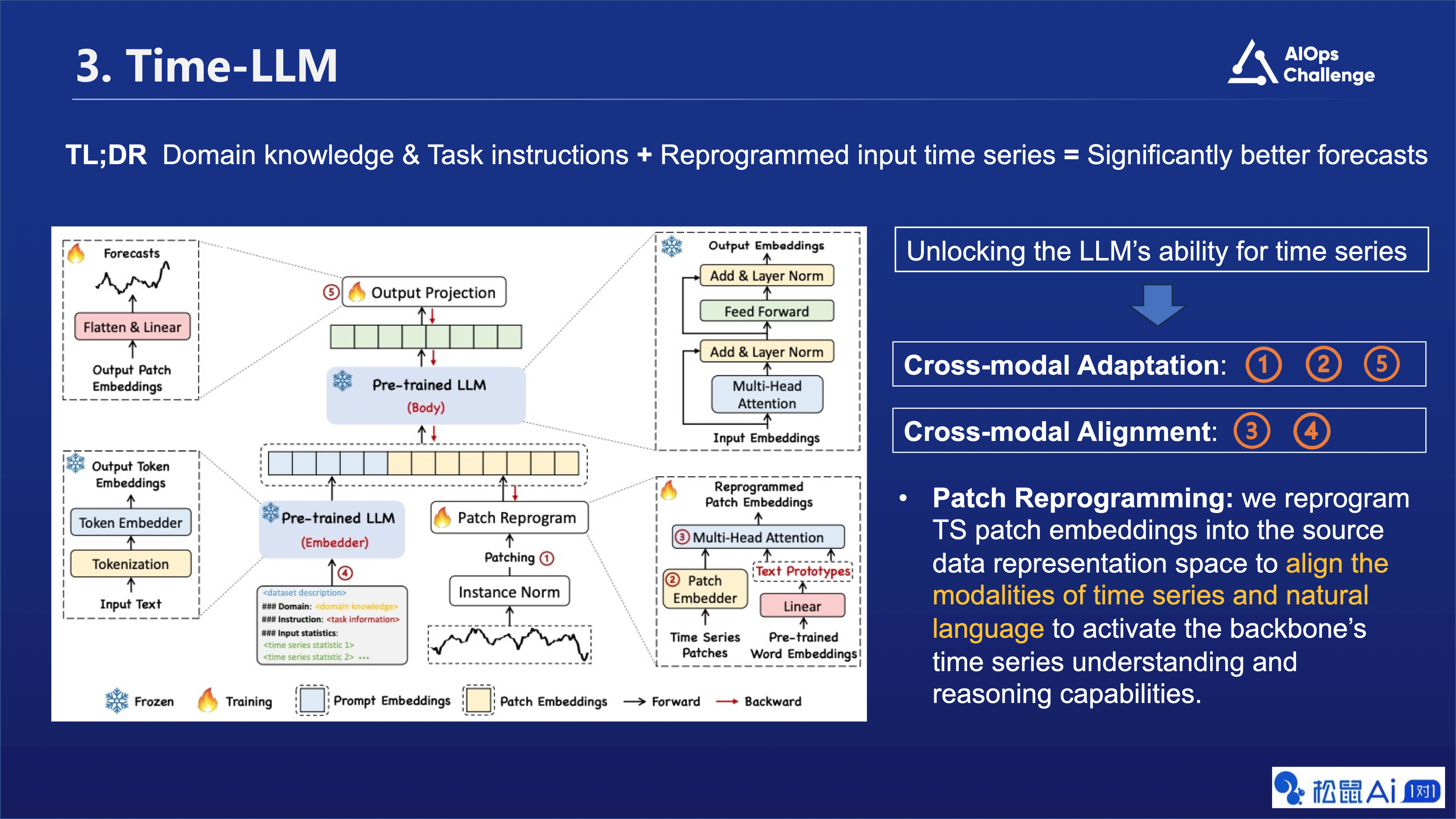
各个步骤这里我们不做详细介绍,总的来说,这个方法旨在通过将时间序列数据与自然语言处理技术相结合,利用大语言模型的先验知识和推理能力,实现更准确的时间序列预测。
26.4.2 明细拆解 —— 论文图 3
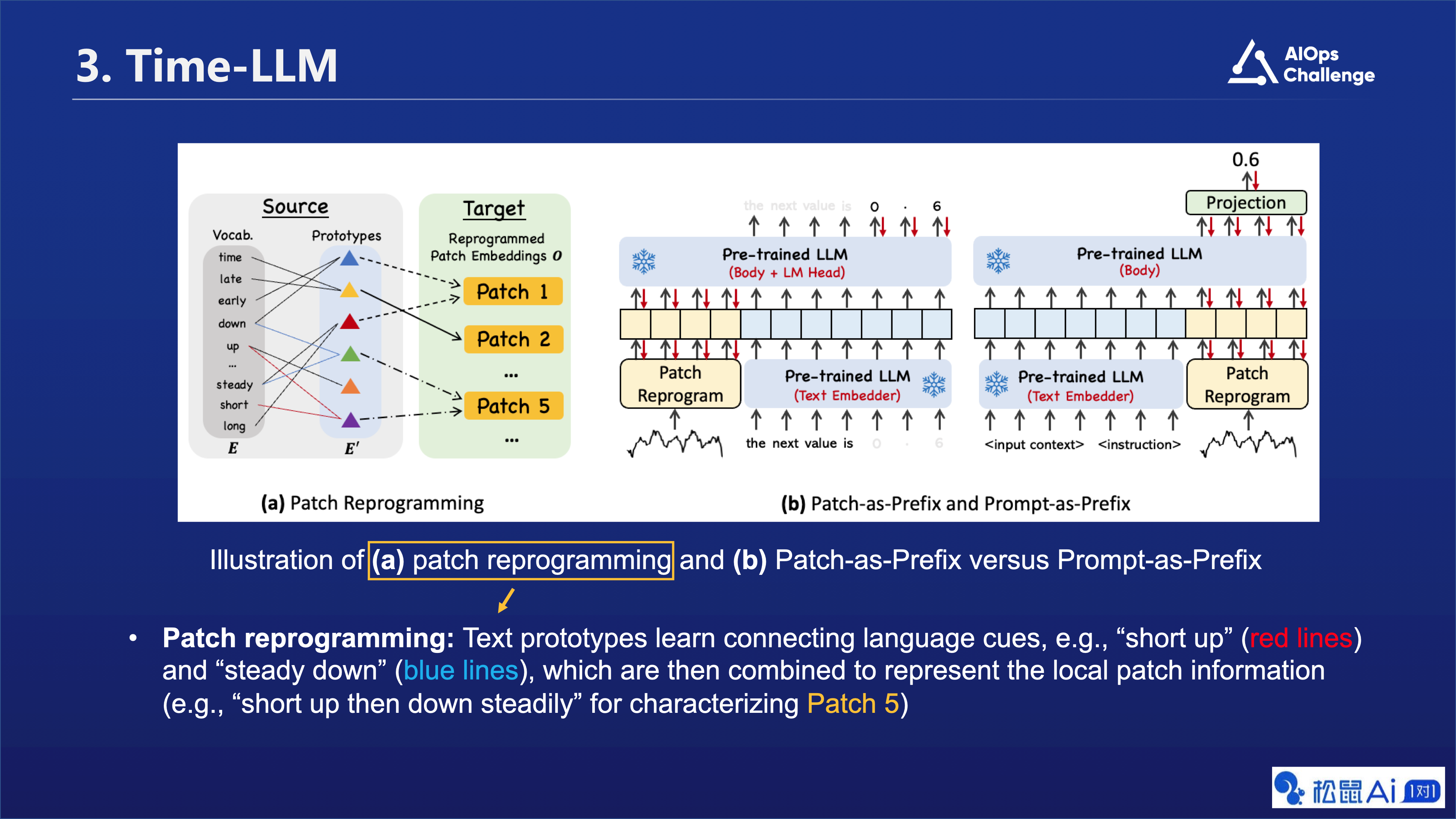
图片中的a部分,我们进一步描述了Patch reprogramming的核心思想。在这个例子中,我们展示了如何使用自然语言刻画时间序列片段 (Patch),比如Patch 5 的语义信息其实可以描述成两个具体过程:先短暂上升再平稳下降。因此我们可以用绿色和紫色两个不同的Text prototypes来表示它,进而打通如图所示的两个不同的数据模态/信息域。
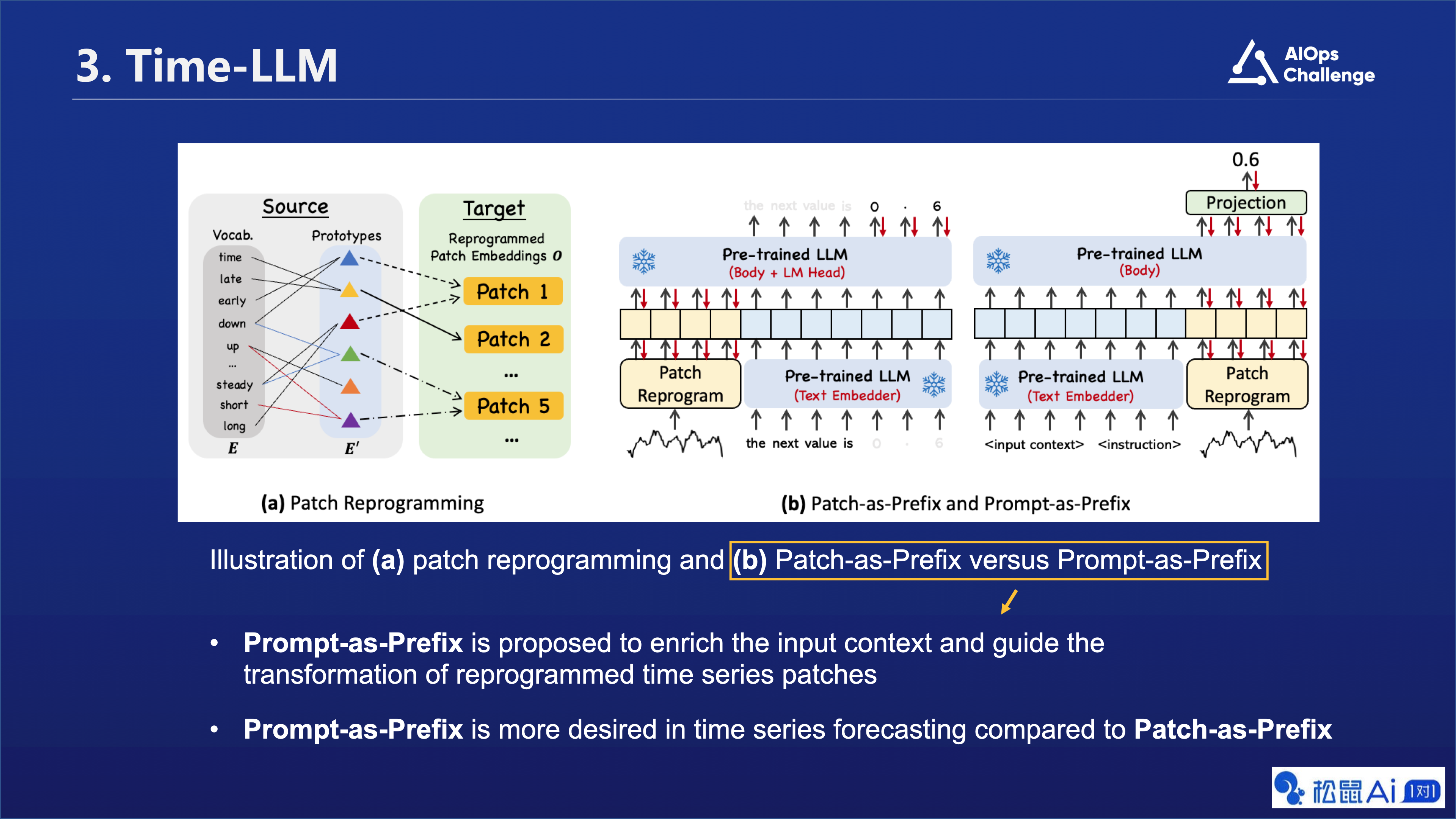
在图片中的 b 部分,我们对比了两种结合文本Prompt的范式,其中我们提出来的Prompt-as-Prefix(PaP)方法具有两个比较直接的优势:一是无需构建特定的多模态指令训练集,二是规避了大语言模型本身在生成输出时间序列方面存在的一些挑战,例如有限的上下文窗口,较低的高精度数字敏感度,和不同分词策略对结果产生的未知影响。
论文图 3 展示了两种不同的方法来利用预训练的大语言模型(Pre-trained LLM)进行时间序列预测,分别是“Patch Reprogramming”和“Patch-as-Prefix versus Prompt-as-Prefix”。
在“Patch Reprogramming”部分,展示了如何将时间序列数据的局部信息(例如,Patch 1、Patch 2等)与文本原型(Text Prototypes)相结合,形成新的片段嵌入(Reprogrammed Patch Embeddings)。这些新的片段嵌入包含了时间序列数据的局部信息,并且可以通过预训练的大语言模型进行进一步的处理和预测。
在“Patch-as-Prefix versus Prompt-as-Prefix”部分,展示了如何将片段嵌入(Patch Embeddings)和提示信息(Prompt)作为预训练的大语言模型的输入。其中,“Patch-as-Prefix”是指将片段嵌入作为模型输入的前缀,“Prompt-as-Prefix”是指将提示信息作为模型输入的前缀。这两种方法都可以帮助模型更好地理解和处理时间序列数据。
总的来说,这张图片展示了如何利用预训练的大语言模型进行时间序列预测,并提供了两种不同的方法:“Patch Reprogramming”和“Patch-as-Prefix versus Prompt-as-Prefix”。
26.5 相关公式
26.5.1 算法目标

数学表示如下:
这段文字描述了一个模型架构,用于将一个嵌入可见的语言基础模型(如Llama和GPT-2)重新编程为通用时间序列预测模型,而无需对主干模型进行任何微调。具体来说,它考虑了以下问题:给定一系列历史观测值 X ∈ R N × T \mathbf{X} \in \mathbb{R}^{N \times T} X∈RN×T,其中包含 N N N个不同的1维变量,跨越 T T T个时间步长,目标是重新编程一个大型语言模型 f ( ⋅ ) f(\cdot) f(⋅),使其能够理解输入的时间序列,并准确地预测在 H H H个未来时间步长上的读数,表示为 Y ^ ∈ R N × H \hat{\mathbf{Y}} \in \mathbb{R}^{N \times H} Y^∈RN×H。最终的目标是最小化真实值 Y \mathbf{Y} Y和预测值之间的均方误差,即 1 H ∑ h = 1 H ∥ Y ^ h − Y h ∥ F 2 \frac{1}{H}\sum_{h=1}^H\|\hat{\mathbf{Y}}_h - \mathbf{Y}_h\|_F^2 H1∑h=1H∥Y^h−Yh∥F2。
26.5.2 输入嵌入 Input Embedding
首先,每个输入通道 X ( i ) \mathbf{X}^{(i)} X(i)通过可逆实例归一化(RevIN)进行标准化,以零均值和单位标准差来缓解时间序列分布偏移的问题。然后,将 X ( i ) \mathbf{X}^{(i)} X(i)划分为几个连续的重叠或非重叠的片段(patches),长度为 L p L_p Lp;因此,输入片段的总数为 P = ⌊ ( I − L p ) S ⌋ + 2 P = \lfloor \frac{(I-L_p)}{S} \rfloor + 2 P=⌊S(I−Lp)⌋+2,其中 S S S表示水平滑动步长。这样做的动机有两个:(1)通过将局部信息聚合到每个片段中,更好地保留局部语义信息;(2)作为分词化过程,形成紧凑的输入令牌序列,从而减少计算负担。给定这些片段 X P ( i ) ∈ R P × L p \mathbf{X}_P^{(i)} \in \mathbb{R}^{P \times L_p} XP(i)∈RP×Lp,我们将其嵌入为 X ^ P ( i ) ∈ R P × d m \hat{\mathbf{X}}_P^{(i)} \in \mathbb{R}^{P \times d_m} X^P(i)∈RP×dm,采用简单的线性层作为片段嵌入器来创建维度 d m d_m dm。
26.5.3 片段重编译 Patch Reprogramming
首先,作者指出,他们通过将片段嵌入到源数据表示空间中,来重新编程片段嵌入,以使时间序列数据和自然语言的模态性对齐,从而激活模型的时序理解与推理能力。常见的做法是学习一种形式的“噪声”,当应用于目标输入样本时,允许预训练的源模型在不需要参数更新的情况下产生期望的目标输出。从技术上讲,这是在跨模态数据之间建立桥梁的可行方法,这些模态数据要么相同,要么相似。例如,可以将视觉模型重新用于处理跨域图像或者将声学模型重新用于处理时间序列数据。在这两种情况下,都存在明确的、可学习的数据源和目标数据之间的转换,允许直接编辑输入样本。然而,时间序列既不能被直接编辑,也不能无损地用自然语言描述,这给直接利用LLM来理解时间序列带来了重大挑战,而无需资源密集型的微调。
这部分内容介绍了如何使用预训练的词嵌入来重新编程时间序列数据的片段嵌入。首先,作者提出了一种简单的方法,即通过线性探查预训练的词嵌入E来维护一个小规模的文本原型集合,记作 E ′ E' E′,其中 V ′ V' V′ 远小于 V V V 。原型学习连接语言线索,例如“短上”(红色线条)和“稳步下降”(蓝色线条),然后组合起来表示局部片段信息(例如,“短上然后稳步下降”来描述第五个片段)而不离开语言模型的预训练空间。这种方法高效且允许自适应选择相关源信息。为了实现这一点,作者使用多头交叉注意力层。对于每个前 k = 1 , . . . , K k={1, ..., K} k=1,...,K,作者定义查询矩阵 Q k ( i ) = X ^ P ( i ) W Q Q Q_k^{(i)}=\hat{X}_P^{(i)}W_Q^{Q} Qk(i)=X^P(i)WQQ,键矩阵 K k ( i ) = E W K K K_k^{(i)}=EW_K^{K} Kk(i)=EWKK,值矩阵 V k ( i ) = E W V V V_k^{(i)}=EW_V^{V} Vk(i)=EWVV,其中 W Q Q , W K K , W V V ∈ R d m × d W_Q^{Q}, W_K^{K}, W_V^{V} \in \mathbb{R}^{d_m \times d} WQQ,WKK,WVV∈Rdm×d, D D D是模型的隐藏维度, d = ⌊ D K ⌋ d=\left\lfloor \frac{D}{K} \right\rfloor d=⌊KD⌋。然后,作者定义了在每个注意力头中的时间序列片段的重新编程操作为:
Z
k
(
i
)
=
ATTENTION
(
Q
k
(
i
)
,
K
k
(
i
)
,
V
k
(
i
)
)
=
SOFTMAX
(
Q
k
(
i
)
K
k
(
i
)
⊤
d
k
)
V
k
(
i
)
.
通过聚合每个 Z k ( i ) ∈ R P × d Z_k^{(i)} \in \mathbb{R}^{P \times d} Zk(i)∈RP×d,作者得到了 Z ( i ) ∈ R P × d m Z^{(i)} \in \mathbb{R}^{P \times d_m} Z(i)∈RP×dm。然后,作者通过线性投影将其对齐到与模型的隐藏维度相匹配,得到 O ( i ) ∈ R P × D O^{(i)} \in \mathbb{R}^{P \times D} O(i)∈RP×D。
26.5.4 Prompt-as-Prefix

“Prompt-as-Prefix”的概念是基于一个观察,即提示可以作为前缀无缝集成到其他数据模式中,如上图,从而促进基于这些输入的有效推理。受此发现的启发,并为了使我们的方法能够直接应用于真实世界的时间序列数据,我们提出了一个替代问题:“提示能否作为前缀来丰富输入上下文并指导重新编程的时间序列片段的变换?” 我们将这种概念称为 “Prompt-as-Prefix”(PaP),并观察到它显著提高了LLM对下游任务的适应性,并补充了片段的重新编程。
在实践中,我们确定了三个关键组件来构建有效的提示:(1)数据集上下文,(2)任务说明,以及(3)输入统计信息。图4中的提示示例提供了关于输入时间序列的基本背景信息,这些信息往往具有不同的特点,这在不同领域中经常出现。数据集上下文为LLM提供有关输入时间序列的基本背景信息,这些信息通常在不同领域中具有不同的特性。任务说明作为LLM在特定任务中对片段嵌入进行转换的重要指南。我们还通过额外的关键统计信息来丰富输入时间序列,如趋势和滞后,以促进模式识别和推理。
26.5.5 输出 Output Projection
输出投影。在将提示和片段嵌入通过冻结的LM进行打包和前向传播后,我们丢弃前缀部分并获得输出表示。随后,我们展平并线性投影它们以得出最终的预测。
26.6 源码阅读
26.6.1 流程梳理(根据代码的运行过程梳理)
run_main.py 作为入口,可以看到主要逻辑包括:
- 按照运行参数选择模型;
- 模型的训练与测试(多批次)
具体而言可以参考如下注释:
# 首先,解析命令行参数
args = parser.parse_args()
# 初始化分布式训练的相关参数
ddp_kwargs = DistributedDataParallelKwargs(find_unused_parameters=True)
# 初始化DeepSpeed插件,并加载配置文件(例如用于ZeRO优化)
deepspeed_plugin = DeepSpeedPlugin(hf_ds_config='./ds_config_zero2.json')
# 创建一个加速器实例,用于管理模型并行、数据并行和优化器等任务
accelerator = Accelerator(kwargs_handlers=[ddp_kwargs], deepspeed_plugin=deepspeed_plugin)
# 迭代次数循环
for ii in range(args.itr):
# 构建实验设置名称,包含多个超参数信息
# setting record of experiments
setting = '{}_{}_{}_{}_ft{}_sl{}_ll{}_pl{}_dm{}_nh{}_el{}_dl{}_df{}_fc{}_eb{}_{}_{}'.format(
args.task_name,
args.model_id,
args.model,
args.data,
args.features,
args.seq_len,
args.label_len,
args.pred_len,
args.d_model,
args.n_heads,
args.e_layers,
args.d_layers,
args.d_ff,
args.factor,
args.embed,
args.des, ii)
# 加载不同阶段的数据集并提供相应的数据加载器
train_data, train_loader = data_provider(args, 'train')
vali_data, vali_loader = data_provider(args, 'val')
test_data, test_loader = data_provider(args, 'test')
# 根据模型类型创建对应的模型实例
if args.model == 'Autoformer':
model = Autoformer.Model(args).float()
elif args.model == 'DLinear':
model = DLinear.Model(args).float()
else:
model = TimeLLM.Model(args).float()
# 定义唯一的模型检查点保存路径
path = os.path.join(args.checkpoints,
setting + '-' + args.model_comment) # unique checkpoint saving path
# 加载内容相关的辅助信息
args.content = load_content(args)
# 如果本地主进程且路径不存在,则创建目录
if not os.path.exists(path) and accelerator.is_local_main_process:
os.makedirs(path)
# 记录当前时间
time_now = time.time()
# 获取训练步骤总数
train_steps = len(train_loader)
# 初始化早停机制,用于在验证损失不再下降时提前停止训练
early_stopping = EarlyStopping(accelerator=accelerator, patience=args.patience)
# 筛选出需要训练的模型参数
trained_parameters = []
for p in model.parameters():
if p.requires_grad is True:
trained_parameters.append(p)
# 使用Adam优化器初始化模型参数
model_optim = optim.Adam(trained_parameters, lr=args.learning_rate)
# 根据学习率调整策略选择合适的调度器
if args.lradj == 'COS':
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(model_optim, T_max=20, eta_min=1e-8)
else:
scheduler = lr_scheduler.OneCycleLR(optimizer=model_optim,
steps_per_epoch=train_steps,
pct_start=args.pct_start,
epochs=args.train_epochs,
max_lr=args.learning_rate)
# 定义损失函数:均方误差(MSE)与平均绝对误差(MAE)
criterion = nn.MSELoss()
mae_metric = nn.L1Loss()
# 将所有训练组件准备好进行分布式训练
train_loader, vali_loader, test_loader, model, model_optim, scheduler = accelerator.prepare(
train_loader, vali_loader, test_loader, model, model_optim, scheduler)
# 如果使用自动混合精度训练(Automatic Mixed Precision, AMP)
if args.use_amp:
scaler = torch.cuda.amp.GradScaler()
# 开始训练循环
for epoch in range(args.train_epochs):
iter_count = 0
train_loss = []
# 设置模型进入训练模式
model.train()
epoch_time = time.time()
# 对训练数据进行迭代
for i, (batch_x, batch_y, batch_x_mark, batch_y_mark) in tqdm(enumerate(train_loader)):
iter_count += 1
# 清零优化器梯度
model_optim.zero_grad()
# 将批次数据转移到设备上
batch_x = batch_x.float().to(accelerator.device)
batch_y = batch_y.float().to(accelerator.device)
batch_x_mark = batch_x_mark.float().to(accelerator.device)
batch_y_mark = batch_y_mark.float().to(accelerator.device)
# 准备解码器输入
# decoder input
dec_inp = torch.zeros_like(batch_y[:, -args.pred_len:, :]).float().to(
accelerator.device)
dec_inp = torch.cat([batch_y[:, :args.label_len, :], dec_inp], dim=1).float().to(
accelerator.device)
# encoder - decoder
if args.use_amp:
# 执行编码器-解码器前向传播
with torch.cuda.amp.autocast():
# 如果需要输出注意力权重,则从模型输出中提取预测值
if args.output_attention:
outputs = model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]
else:
outputs = model(batch_x, batch_x_mark, dec_inp, batch_y_mark)
# 提取特定维度的特征以进行损失计算
f_dim = -1 if args.features == 'MS' else 0
outputs = outputs[:, -args.pred_len:, f_dim:]
batch_y = batch_y[:, -args.pred_len:, f_dim:].to(accelerator.device)
# 计算损失
loss = criterion(outputs, batch_y)
train_loss.append(loss.item())
else:
if args.output_attention:
outputs = model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]
else:
outputs = model(batch_x, batch_x_mark, dec_inp, batch_y_mark)
f_dim = -1 if args.features == 'MS' else 0
outputs = outputs[:, -args.pred_len:, f_dim:]
batch_y = batch_y[:, -args.pred_len:, f_dim:]
loss = criterion(outputs, batch_y)
train_loss.append(loss.item())
# 输出训练进度信息
if (i + 1) % 100 == 0:
accelerator.print(
"\titers: {0}, epoch: {1} | loss: {2:.7f}".format(i + 1, epoch + 1, loss.item()))
speed = (time.time() - time_now) / iter_count
left_time = speed * ((args.train_epochs - epoch) * train_steps - i)
accelerator.print('\tspeed: {:.4f}s/iter; left time: {:.4f}s'.format(speed, left_time))
iter_count = 0
time_now = time.time()
# 反向传播并更新梯度(根据是否使用AMP)
if args.use_amp:
scaler.scale(loss).backward()
scaler.step(model_optim)
scaler.update()
else:
accelerator.backward(loss)
model_optim.step()
# 调整学习率(基于TST策略直接在训练过程中调整)
if args.lradj == 'TST':
adjust_learning_rate(accelerator, model_optim, scheduler, epoch + 1, args, printout=False)
scheduler.step()
# 输出每个训练轮次的耗时信息
accelerator.print("Epoch: {} cost time: {}".format(epoch + 1, time.time() - epoch_time))
# 计算本轮训练的平均损失
train_loss = np.average(train_loss)
# 进行验证和测试,并获取损失和MAE
vali_loss, vali_mae_loss = vali(args, accelerator, model, vali_data, vali_loader, criterion, mae_metric)
test_loss, test_mae_loss = vali(args, accelerator, model, test_data, test_loader, criterion, mae_metric)
# 输出训练、验证、测试的损失及MAE
accelerator.print(
"Epoch: {0} | Train Loss: {1:.7f} Vali Loss: {2:.7f} Test Loss: {3:.7f} MAE Loss: {4:.7f}".format(
epoch + 1, train_loss, vali_loss, test_loss, test_mae_loss))
# 更新早停状态,若满足条件则提前终止训练
early_stopping(vali_loss, model, path)
if early_stopping.early_stop:
accelerator.print("Early stopping")
break
# 根据指定的学习率调整策略进行操作
if args.lradj != 'TST':
# 若采用CosineAnnealingLR调度器,执行步进并打印当前学习率
if args.lradj == 'COS':
scheduler.step()
accelerator.print("lr = {:.10f}".format(model_optim.param_groups[0]['lr']))
else:
# 其他情况下,在非首轮后可能需要调整学习率并打印
if epoch == 0:
args.learning_rate = model_optim.param_groups[0]['lr']
accelerator.print("lr = {:.10f}".format(model_optim.param_groups[0]['lr']))
adjust_learning_rate(accelerator, model_optim, scheduler, epoch + 1, args, printout=True)
else:
# 若采用OneCycleLR调度器,更新学习率并打印
accelerator.print('Updating learning rate to {}'.format(scheduler.get_last_lr()[0]))
# 等待所有进程完成
accelerator.wait_for_everyone()
# 如果是本地主进程,则清理checkpoint文件夹中的旧检查点文件
if accelerator.is_local_main_process:
path = './checkpoints' # unique checkpoint saving path
del_files(path) # delete checkpoint files
accelerator.print('success delete checkpoints')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
26.6.2 核心内容 TimeLLM.py
阅读 TimeLLM.py ,大致内容可以参考添加的注解:
# 定义FlattenHead类,用于展平并线性变换模型输出
class FlattenHead(nn.Module):
def __init__(self, n_vars, nf, target_window, head_dropout=0):
super().__init__()
self.n_vars = n_vars
# flatten 层,从倒数第二个维度开始展平
self.flatten = nn.Flatten(start_dim=-2)
# 线性变换层,将nf维特征映射到target_window维
self.linear = nn.Linear(nf, target_window)
# 输出Dropout层,防止过拟合
self.dropout = nn.Dropout(head_dropout)
def forward(self, x):
# 展平输入
x = self.flatten(x)
# 进行线性变换
x = self.linear(x)
# 应用Dropout
x = self.dropout(x)
return x
# 定义主模型类
class Model(nn.Module):
def __init__(self, configs, patch_len=16, stride=8):
super(Model, self).__init__()
# 初始化参数
self.task_name = configs.task_name
self.pred_len = configs.pred_len
self.seq_len = configs.seq_len
self.d_ff = configs.d_ff
self.top_k = 5
self.d_llm = 4096
self.patch_len = configs.patch_len
self.stride = configs.stride
# 加载LLaMA预训练模型配置
self.llama_config = LlamaConfig.from_pretrained('/mnt/alps/modelhub/pretrained_model/LLaMA/7B_hf/')
# self.llama_config = LlamaConfig.from_pretrained('huggyllama/llama-7b')
# 配置LLaMA模型层数、注意力输出和隐藏状态输出
self.llama_config.num_hidden_layers = configs.llm_layers
self.llama_config.output_attentions = True
self.llama_config.output_hidden_states = True
# 加载LLaMA预训练模型
self.llama = LlamaModel.from_pretrained(
"/mnt/alps/modelhub/pretrained_model/LLaMA/7B_hf/",
# 'huggyllama/llama-7b',
trust_remote_code=True,
local_files_only=True,
config=self.llama_config,
load_in_4bit=True
)
# 加载LLaMA模型对应的tokenizer
self.tokenizer = LlamaTokenizer.from_pretrained(
"/mnt/alps/modelhub/pretrained_model/LLaMA/7B_hf/tokenizer.model",
# 'huggyllama/llama-7b',
trust_remote_code=True,
local_files_only=True
)
# 设置padding_token
if self.tokenizer.eos_token:
self.tokenizer.pad_token = self.tokenizer.eos_token
else:
pad_token = '[PAD]'
self.tokenizer.add_special_tokens({'pad_token': pad_token})
self.tokenizer.pad_token = pad_token
# 将LLaMA模型参数设置为不需要梯度更新
for param in self.llama.parameters():
param.requires_grad = False
# 添加Dropout层
self.dropout = nn.Dropout(configs.dropout)
# 创建PatchEmbedding层
self.patch_embedding = PatchEmbedding(
configs.d_model, self.patch_len, self.stride, configs.dropout)
# 获取LLaMA模型的词嵌入权重,并获取词汇表大小
self.word_embeddings = self.llama.get_input_embeddings().weight
self.vocab_size = self.word_embeddings.shape[0]
self.num_tokens = 1000
# 添加一个映射层,将词汇表大小映射到num_tokens
self.mapping_layer = nn.Linear(self.vocab_size, self.num_tokens)
# 创建ReprogrammingLayer实例
self.reprogramming_layer = ReprogrammingLayer(configs.d_model, configs.n_heads, self.d_ff, self.d_llm)
# 计算patch数量和head_nf(特征维度)
self.patch_nums = int((configs.seq_len - self.patch_len) / self.stride + 2)
self.head_nf = self.d_ff * self.patch_nums
# 根据任务类型创建相应的输出投影层
if self.task_name == 'long_term_forecast' or self.task_name == 'short_term_forecast':
self.output_projection = FlattenHead(configs.enc_in, self.head_nf, self.pred_len,
head_dropout=configs.dropout)
else:
raise NotImplementedError
# 添加标准化层
self.normalize_layers = Normalize(configs.enc_in, affine=False)
# 前向传播方法
def forward(self, x_enc, x_mark_enc, x_dec, x_mark_dec, mask=None):
# 根据任务类型进行预测并返回相应结果
if self.task_name == 'long_term_forecast' or self.task_name == 'short_term_forecast':
dec_out = self.forecast(x_enc, x_mark_enc, x_dec, x_mark_dec)
return dec_out[:, -self.pred_len:, :]
return None
# 预测方法,针对长期或短期预测任务
def forecast(self, x_enc, x_mark_enc, x_dec, x_mark_dec):
# 对编码器输入进行归一化
x_enc = self.normalize_layers(x_enc, 'norm')
# 数据重塑和统计计算
B, T, N = x_enc.size()
x_enc = x_enc.permute(0, 2, 1).contiguous().reshape(B * N, T, 1)
min_values = torch.min(x_enc, dim=1)[0]
max_values = torch.max(x_enc, dim=1)[0]
medians = torch.median(x_enc, dim=1).values
lags = self.calcute_lags(x_enc)
trends = x_enc.diff(dim=1).sum(dim=1)
# 构造prompt
prompt = []
for b in range(x_enc.shape[0]):
min_values_str = str(min_values[b].tolist()[0])
max_values_str = str(max_values[b].tolist()[0])
median_values_str = str(medians[b].tolist()[0])
lags_values_str = str(lags[b].tolist())
prompt_ = (
f"<|start_prompt|>Dataset description: The Electricity Transformer Temperature (ETT) is a crucial indicator in the electric power long-term deployment."
f"Task description: forecast the next {str(self.pred_len)} steps given the previous {str(self.seq_len)} steps information; "
"Input statistics: "
f"min value {min_values_str}, "
f"max value {max_values_str}, "
f"median value {median_values_str}, "
f"the trend of input is {'upward' if trends[b] > 0 else 'downward'}, "
f"top 5 lags are : {lags_values_str}<|<end_prompt>|>"
)
prompt.append(prompt_)
# 数据恢复原形状
x_enc = x_enc.reshape(B, N, T).permute(0, 2, 1).contiguous()
# 使用tokenizer对prompt进行编码
prompt = self.tokenizer(prompt, return_tensors="pt", padding=True, truncation=True, max_length=2048).input_ids
# 提取prompt的嵌入表示
prompt_embeddings = self.llama.get_input_embeddings()(prompt.to(x_enc.device)) # (batch, prompt_token, dim)
# 将词嵌入映射到num_tokens大小
source_embeddings = self.mapping_layer(self.word_embeddings.permute(1, 0)).permute(1, 0)
# 对编码器输入进行patch embedding
x_enc = x_enc.permute(0, 2, 1).contiguous()
# 应用ReprogrammingLayer
enc_out, n_vars = self.patch_embedding(x_enc.to(torch.bfloat16))
enc_out = self.reprogramming_layer(enc_out, source_embeddings, source_embeddings)
# 将prompt嵌入与编码器输出拼接
llama_enc_out = torch.cat([prompt_embeddings, enc_out], dim=1)
# 通过LLaMA模型得到解码器输出
dec_out = self.llama(inputs_embeds=llama_enc_out).last_hidden_state
dec_out = dec_out[:, :, :self.d_ff]
# 解码器输出重塑及调整通道顺序
dec_out = torch.reshape(
dec_out, (-1, n_vars, dec_out.shape[-2], dec_out.shape[-1]))
dec_out = dec_out.permute(0, 1, 3, 2).contiguous()
# 应用输出投影层并进行反归一化
dec_out = self.output_projection(dec_out[:, :, :, -self.patch_nums:])
dec_out = dec_out.permute(0, 2, 1).contiguous()
dec_out = self.normalize_layers(dec_out, 'denorm')
# 返回预测结果
return dec_out
# 计算lags(滞后值)
def calcute_lags(self, x_enc):
q_fft = torch.fft.rfft(x_enc.permute(0, 2, 1).contiguous(), dim=-1)
k_fft = torch.fft.rfft(x_enc.permute(0, 2, 1).contiguous(), dim=-1)
res = q_fft * torch.conj(k_fft)
corr = torch.fft.irfft(res, dim=-1)
mean_value = torch.mean(corr, dim=1)
_, lags = torch.topk(mean_value, self.top_k, dim=-1)
return lags
# 定义ReprogrammingLayer类,这是一个自定义的多头注意力层,用于将目标嵌入与源嵌入进行交互以实现重编程功能
class ReprogrammingLayer(nn.Module):
def __init__(self, d_model, n_heads, d_keys=None, d_llm=None, attention_dropout=0.1):
# 继承nn.Module基类
super(ReprogrammingLayer, self).__init__()
# 如果d_keys未指定,则设置为模型维度除以头数的结果
d_keys = d_keys or (d_model // n_heads)
# 创建查询投影层,将目标嵌入映射到新的表示空间(每个头维度为d_keys)
self.query_projection = nn.Linear(d_model, d_keys * n_heads)
# 创建键投影层,将源嵌入映射到新的表示空间(每个头维度为d_keys)
self.key_projection = nn.Linear(d_llm, d_keys * n_heads)
# 创建值投影层,同样将源嵌入映射到新的表示空间(每个头维度为d_keys)
self.value_projection = nn.Linear(d_llm, d_keys * n_heads)
# 创建输出投影层,将注意力输出重新映射回原始模型维度
self.out_projection = nn.Linear(d_keys * n_heads, d_llm)
# 保存头数
self.n_heads = n_heads
# 创建Dropout层,用于在注意力计算中减少过拟合
self.dropout = nn.Dropout(attention_dropout)
def forward(self, target_embedding, source_embedding, value_embedding):
# 获取输入的形状参数
B, L, _ = target_embedding.shape
S, _ = source_embedding.shape
# 计算头数H
H = self.n_heads
# 对目标、源和值嵌入应用对应的线性投影,并调整形状以便进行多头注意力计算
target_embedding = self.query_projection(target_embedding).view(B, L, H, -1)
source_embedding = self.key_projection(source_embedding).view(S, H, -1)
value_embedding = self.value_projection(value_embedding).view(S, H, -1)
# 调用reprogramming方法执行多头注意力计算
out = self.reprogramming(target_embedding, source_embedding, value_embedding)
# 将注意力输出重塑为(batch_size, sequence_length, new_embedding_dim)
out = out.reshape(B, L, -1)
# 应用输出投影层得到最终输出
return self.out_projection(out)
def reprogramming(self, target_embedding, source_embedding, value_embedding):
# 获取形状参数
B, L, H, E = target_embedding.shape
# 计算缩放因子,用于softmax中的归一化
scale = 1. / sqrt(E)
# 计算注意力得分(点积注意力)
scores = torch.einsum("blhe,she->bhls", target_embedding, source_embedding)
# 应用Dropout并计算softmax得到注意力权重
A = self.dropout(torch.softmax(scale * scores, dim=-1))
# 根据注意力权重对值嵌入进行加权求和,得到重编程后的目标嵌入
reprogramming_embedding = torch.einsum("bhls,she->blhe", A, value_embedding)
# 返回经过注意力机制处理的目标嵌入
return reprogramming_embedding
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
实现的相关链接请自行查找资料,可能需要申请下载 llama2 的模型文件,请查询相关资料自行完成。
26.7 总结
TIME-LLM的核心思想是在不改变预训练模型结构的基础上,将输入的时间序列数据转化为文本形式,并通过Prompt-as-Prefix策略丰富上下文信息及提供自然语言形式的任务指导,从而让大型语言模型能够识别复杂的时间序列模式并进行推理以实现预测。这种方法实现了连续时间序列数据与语言模型操作的离散符号之间的有效对齐,从冻结的语言模型中输出转换后的时间序列片段,并将其投影得到最终预测结果。
由于个人能力有限、资源不足、空闲时间匮乏等方面原因,这里没法完成论文实现复现的相关工作,非常抱歉。
但关于LLAMA2 模型的加载与使用,可以根据官方文档,B站视频,相关博客等进行学习与实验,希望更多朋友能够在这方面取得更多成功 ~
Smileyan
2024.03.03 23:15

