
- 1拓数派与浙江平数举行「政务数据服务产品合作开发」签约仪式
- 2CSDN社区简介_scnd;论坛
- 3Java实现微信小程序登录授权_java微信小程序授权登录
- 4智能优化算法之蚁群算法_蚁群优化算法
- 5jenkins使用插件OWASP Dependency-Check Plugin对jar包漏洞扫描_jenkins 扫描 jar 插件
- 6使用AI开源引擎构建:智能文档处理系统提升企业生产效率_智能文档处理(idp)技术
- 7源码编译FFmpeg_centos ffmpeg 4.3 编译
- 8浙江大学数据结构MOOC-课后习题-第五讲-树8 File Transfer
- 9如何在python中安装Gurobi(详细教程)_gurobi python
- 10manjaro wechat
【PyTorch】(三)----搭建卷积神经网络
赞
踩
该系列笔记主要参考了小土堆的视频教程,传送门:P1. PyTorch环境的配置及安装(Configuration and Installation of PyTorch)【PyTorch教程】_哔哩哔哩_bilibili
涉及到的文件/数据集网盘:
链接:https://pan.baidu.com/s/1aZmXokdpbA97qQ2kHvx_JQ?pwd=1023 提取码:1023
在前面的两篇文章中,我们学会了对数据的处理、加载和数据集的使用,在本文以及后续的文章中我们将会会来学习如何使用pytorch搭建一个神经网络,让它能够使用到我们准备好的数据。
关于神经网络中激活函数、卷积层、池化层等底层原理,我不会在本文中详解,但是关于pytorch中如何使用对应的方法实现这些层的功能我会进行解释,如果你想要了解一些关于神经网络底层的只是,我十分推荐你去看一下吴恩达老师的深度学习课程,我后续也会推出他的课程视频。
Module
在pytorch中,想要自定义网络的话,需要使用pytorch.nn中的Module类。Module类是所有神经网络模块的基类,即自己编写的所有模块都需要继承Module类。
下面给出官方文档中的示例代码:
import torch.nn as nn
import torch.nn.functional as F #nn.functional中包含了神经网络所需要用到的大量函数,比如各种激活函数、损失函数等。
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
在继承nn.Module后,必须重写两个方法,_init_ 和forward ,在使用_init_ 时又必须先引用调用父类的初始化方法,即super().__init__(),然后在forward 前向传播中使用自定义的网络模块,上述示例中的conv2d方法将在后面介绍
【代码示例】 搭建一个自己的module子类,不需要实现神经网络的功能
import torch from torch import nn class Mymodule(nn.Module): def __init__(self): super().__init__() def forward(self, input): output = input + 1 return output mymodule = Mymodule() x = torch.tensor(1.0) output = mymodule(x) print(output)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
Conv2d卷积层
主要语法如下:
nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0)
# in_channels : 输入数据的通道数
# out_channels : 输出数据的通道数
# kernel_size : 卷积核的大小
# stride: 步长
# padding: 边缘填充·
- 1
- 2
- 3
- 4
- 5
- 6
【代码示例】对CIFAR10数据集使用3*3卷积,stride和padding为默认,CIFAR10中数据大小为3*32*32,卷积完成后,应该为3*30*30 ,通过图片检验你的代码结果是否正确
import torchvision from torch import nn from torch.nn import Conv2d from torch.utils.data import DataLoader dataset = torchvision.datasets.CIFAR10("dataset/CIFAR10", train=False, transform=torchvision.transforms.ToTensor(), download=True) dataloader = DataLoader(dataset, batch_size=64) class myModule(nn.Module): def __init__(self): super(myModule, self).__init__() # 在此处写自定义的神经网络层 self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0) def forward(self, input): # 在此处调用神经网络层 input = self.conv1(input) return input mymodule = myModule() step = 0 for data in dataloader: imgs, targets = data output = mymodule(imgs) print(imgs.shape) # torch.Size([64, 3, 32, 32]) 64为batch_size大小,即每轮读取64张图片 print(output.shape) # torch.Size([64, 6, 30, 30]) -> [xxx, 3, 30, 30] exit(0)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
输出结果:
torch.Size([64, 3, 32, 32])
torch.Size([64, 6, 30, 30])
- 1
- 2
池化层
池化层主要用于缩小输入的特征数量,池化有平均池化和最大值池化。现在最大值池化更加常用,其主要语法如下:
MaxPool2d(kernel_size=3, ceil_mode=False)
# kernel_size: 池化窗口的大小。它可以是一个整数(表示高和宽相等的正方形窗口)或者一个包含两个整数的元组(kernel_height, kernel_width),分别指定窗口的高度和宽度。
# stride: 窗口在输入数据上滑动的步长,默认等于kernel_size。它可以是一个整数(表示高度和宽度上的步长相同)或一个包含两个整数的元组(stride_height, stride_width)。
# padding: 在输入的每个边缘填充的大小。这可以是单个整数(表示所有边缘的相同填充)或一个包含两个整数的元组(pad_height, pad_width)。默认为0,意味着没有填充。
# return_indices: 如果设置为True,除了返回池化后的输出张量外,还会返回每个最大值在输入张量中的索引。这对于某些操作,如nn.MaxUnpool2d反池化操作,可能很有用。默认为False。
# ceil_mode: 当设为True,会计算输出尺寸时使用向上取整,而不是默认的向下取整。这会影响到输出的尺寸计算,特别是在使用非1的步长或填充时。默认为False。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
【代码示例】对CIFAR10数据集使用最大池化,并将最终结果进行可视化呈现
import torchvision from torch import nn from torch.nn import MaxPool2d from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter dataset = torchvision.datasets.CIFAR10("dataset/CIFAR10", train=False, download=True, transform=torchvision.transforms.ToTensor()) dataloader = DataLoader(dataset, batch_size=64) class myModule(nn.Module): def __init__(self): super().__init__() self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False) def forward(self, input): output = self.maxpool1(input) return output myModule = myModule() writer = SummaryWriter("logs_maxpool") step = 0 for data in dataloader: imgs, targets = data writer.add_images("input", imgs, step) output = myModule(imgs) writer.add_images("output", output, step) step = step + 1 writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
运行结果:最大池化相当于是邻近几个像素中只选取一个最大值作为特征,所以呈现结果就是图片减小,变成类似马赛克的效果
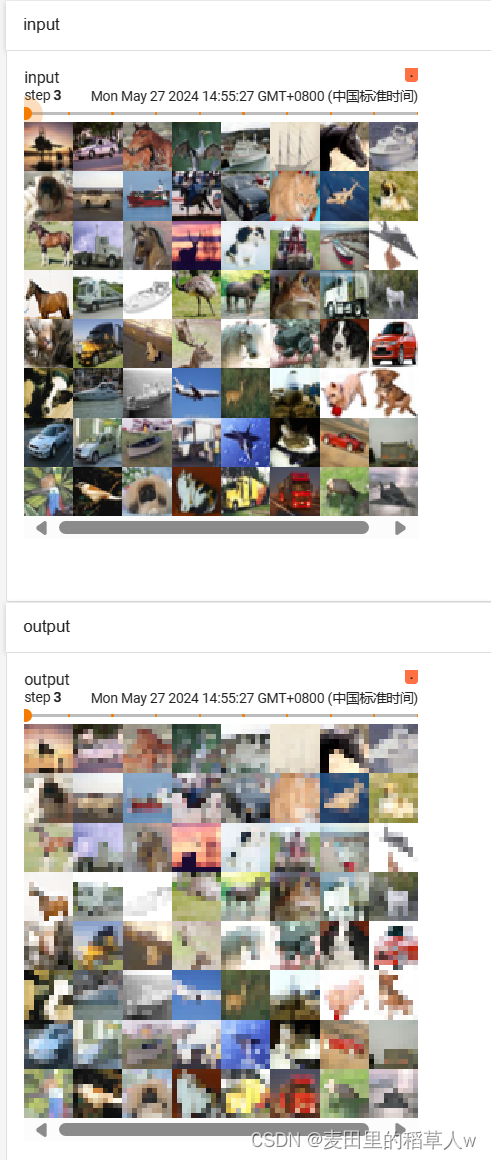
激活层
主要使用的是nn.relu 和 nn.sigmoid 两个方法,没有特殊的参数需求,直接调用即可
【代码示例】实现激活函数并进行可视化
import torch import torchvision from torch import nn from torch.nn import ReLU, Sigmoid from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter input = torch.tensor([[1, -0.5], [-1, 3]]) input = torch.reshape(input, (-1, 1, 2, 2)) print(input.shape) dataset = torchvision.datasets.CIFAR10("dataset/CIFAR10", train=False, download=True, transform=torchvision.transforms.ToTensor()) dataloader = DataLoader(dataset, batch_size=64) class myModule(nn.Module): def __init__(self): super().__init__() self.relu1 = ReLU() self.sigmoid1 = Sigmoid() def forward(self, input): output = self.sigmoid1(input) return output mymodule = myModule() writer = SummaryWriter("logs_relu") step = 0 for data in dataloader: imgs, targets = data writer.add_images("input", imgs, global_step=step) output = mymodule(imgs) writer.add_images("output", output, step) step += 1 writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
Linear线性层
线性变换主要有两个函数:
nn.flatten 用来将图片展开为一维信息
nn.Linear 用来进行全连接的线性变换
【代码示例】实现nn.flatten 展开和nn.Linear 线性变换
import torch import torchvision from torch import nn from torch.nn import Linear from torch.utils.data import DataLoader dataset = torchvision.datasets.CIFAR10("dataset/CIFAR10", train=False, transform=torchvision.transforms.ToTensor(), download=True) dataloader = DataLoader(dataset, batch_size=64, drop_last=True) class myModule(nn.Module): def __init__(self): super().__init__() # in_feature 为输入特征数量 # out_feature 为输出特征数量 self.linear1 = Linear(196608, 10) def forward(self, input): output = self.linear1(input) return output mymodule = myModule() for data in dataloader: imgs, targets = data print(imgs.shape) output = torch.flatten(imgs) # flatten将图片变为一维信息 print(output.shape) output = mymodule(output) print(output.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
卷积神经网络的简单搭建
相信你还记得我们在上一章中使用到的CIFAR10数据集,官方为我们提供了一个卷积神经网络的架构实现对其进行分类,其架构图如下所示:
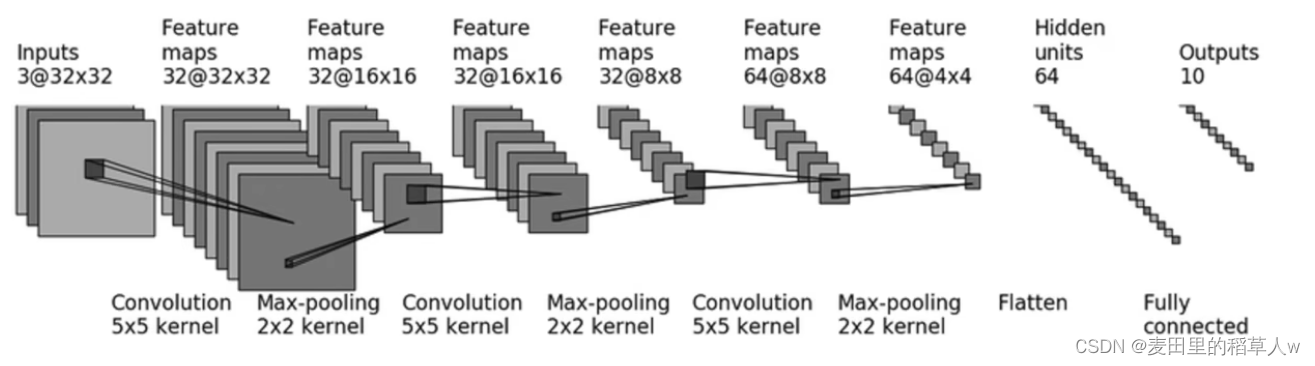
图例说明:a@b*c 中,a为通道数,b和c为图像的宽高
【代码示例】自己动手实现上面的卷积神经网络并测试其输出内容和大小
import torch from torch import nn # 搭建CIFAR10神经网络 class myModule(nn.Module): def __init__(self): super().__init__() self.my_conv1 = nn.Conv2d(3, 32, 5, 1, 2) self.my_pool1 = nn.MaxPool2d(2) self.my_conv2 = nn.Conv2d(32, 32, 5, 1, 2) self.my_pool2 = nn.MaxPool2d(2) self.my_conv3 = nn.Conv2d(32, 64, 5, 1, 2) self.my_pool3 = nn.MaxPool2d(2) self.my_flat = nn.Flatten() self.my_line1 = nn.Linear(64*4*4, 64) self.my_line2 = nn.Linear(64, 10) def forward(self, input): output = self.my_conv1(input) output = self.my_pool1(output) output = self.my_conv2(output) output = self.my_pool2(output) output = self.my_conv3(output) output = self.my_pool3(output) output = self.my_flat(output) output = self.my_line1(output) output = self.my_line2(output) return output if __name__ == '__main__': mymodule = myModule() print(mymodule) # 查看自己创建的结构 # 验证最后的输出大小是否为自己想要的 input = torch.ones((64, 3, 32, 32)) output = mymodule(input) print(output.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
运行结果:
myModule(
(my_conv1): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(my_pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(my_conv2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(my_pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(my_conv3): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(my_pool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(my_flat): Flatten(start_dim=1, end_dim=-1)
(my_line1): Linear(in_features=1024, out_features=64, bias=True)
(my_line2): Linear(in_features=64, out_features=10, bias=True)
)
torch.Size([64, 10])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Sequential
在PyTorch中,nn.Sequential是一个容器模块,用于将多个模块按照顺序串联起来形成一个有序的神经网络结构。这意味着数据会按照添加到nn.Sequential中的顺序依次通过每个模块(层)。在上一个例子中,我们要手写forward中所有的调用,使用nn.Sequential时,你不需要显式地定义前向传播(forward)方法,因为这个容器会自动将输入传递给序列中的第一个模块,然后将前一个模块的输出自动作为下一个模块的输入,依此类推,直到序列结束。这样不仅是不需要手写forward,同时也不需要在Sequential中定义每一层的名字了。这对于定义那些没有分支或者跳连的简单前馈网络特别方便。
【代码示例】使用Sequential改写上面的例子
import torch from torch import nn # 搭建神经网络 class myModule(nn.Module): def __init__(self): super().__init__() self.model = nn.Sequential( nn.Conv2d(3, 32, 5, 1, 2), nn.MaxPool2d(2), nn.Conv2d(32, 32, 5, 1, 2), nn.MaxPool2d(2), nn.Conv2d(32, 64, 5, 1, 2), nn.MaxPool2d(2), nn.Flatten(), nn.Linear(64*4*4, 64), nn.Linear(64, 10) ) def forward(self, x): x = self.model(x) return x if __name__ == '__main__': mymodule = myModule() input = torch.ones((64, 3, 32, 32)) output = mymodule(input) print(output.shape) # 运行结果不变,代码更加简洁
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
损失函数
主要用到的三种损失函数如下:
- CrossEntropyLoss:交叉熵损失,常用于多分类问题,特别是类别相互排斥的情况(每个样本只属于一个类别)。它结合了softmax函数和负对数似然损失,直接从raw logits预测中计算损失。
- MSELoss:均方误差损失,广泛应用于回归问题,计算预测值和真实值之间的均方差。
- L1Loss:L1范数损失,也称为绝对误差损失,适用于回归任务,鼓励生成稀疏解,因为它对误差的惩罚不如MSELoss敏感。
在PyTorch中的L1Loss以及其他许多损失函数中,reduction参数是用来指定如何将每个样本或批次中元素的损失进行汇总的方式。这个参数决定了最终返回的损失值是单个标量还是保持为向量/张量的形式。reduction参数可以取以下几个值:
- ‘none’:不进行约简,即返回的loss是一个与输入形状相同的张量,每个元素对应一个样本的损失。这对于需要对每个样本的损失进行单独分析或者后处理的情况很有用。
- ‘mean’(默认值):将所有样本的损失求平均值,得到一个标量。这是最常用的情况,特别是在训练神经网络时,因为这能给出批次内损失的总体表现。
- ‘sum’:将所有样本的损失相加,得到一个标量。这种情况下,损失值会随着批次大小的增加而增加,因此在比较不同大小批次的损失时需要注意归一化。
【代码示例】 在上面创建的CIFAR10卷积神经网络中使用交叉熵损失函数观察其预测结果和正确结果之间的差距
import torchvision from torch import nn from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear from torch.utils.data import DataLoader dataset = torchvision.datasets.CIFAR10("dataset/CIFAR10", train=False, transform=torchvision.transforms.ToTensor(), download=True) dataloader = DataLoader(dataset, batch_size=1) class myModule(nn.Module): def __init__(self): super().__init__() self.model1 = Sequential( Conv2d(3, 32, 5, padding=2), MaxPool2d(2), Conv2d(32, 32, 5, padding=2), MaxPool2d(2), Conv2d(32, 64, 5, padding=2), MaxPool2d(2), Flatten(), Linear(1024, 64), Linear(64, 10) ) def forward(self, x): x = self.model1(x) return x loss = nn.CrossEntropyLoss() mymodule = myModule() for data in dataloader: imgs, targets = data outputs = mymodule(imgs) result_loss = loss(outputs, targets) print(result_loss)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
运行结果:
tensor(2.3523, grad_fn=<NllLossBackward0>)
tensor(2.2240, grad_fn=<NllLossBackward0>)
...
- 1
- 2
- 3
优化器
PyTorch提供了多种内置的优化器,用于在训练过程中更快地更新模型参数,主要作用在反向传播过程中以下是一些常用的优化器及其特点:
- SGD (Stochastic Gradient Descent):随机梯度下降,是最基础的优化算法,支持动量选项(momentum)。
- SGD with Nesterov Momentum:带Nesterov动量的SGD,动量更新时考虑的是未来位置,有时能提供更好的收敛性。
- ASGD (Averaged Stochastic Gradient Descent):平均随机梯度下降,会跟踪并最终使用参数的历史平均值进行更新。
- Adagrad:自动调整学习率的梯度下降,对每个参数维护一个不同的学习率,适合稀疏数据。
- Adadelta:不需要手动设置学习率,基于历史梯度平方的加权平均来调整学习率。
- RMSprop:Root Mean Square Propagation,也是基于梯度的平方,但使用指数移动平均来调整学习率。
- Adam (Adaptive Moment Estimation):非常流行的优化器,结合了动量和RMSprop的优点,自适应学习率,适用于多种任务。
- Adamax:Adam的一个变种,使用无穷范数代替二阶矩估计。
- AdamW:修正了Adam中权重衰减(L2惩罚)的实现,使权重衰减独立于学习率缩放。
- NAdam:带有Nesterov动量的Adam,结合了Nesterov动量和Adam的优点。
- SparseAdam:专门为稀疏梯度优化设计的Adam变体。
- L-BFGS:拟牛顿优化方法,适合解决小批量或批大小为1的情况,但内存消耗较大。
- RAdam (Rectified Adam):解决了Adam初期学习率过低的问题,通过修正初始阶段的偏差来提高训练稳定性。
- Radam:RAdam的另一种实现,同样旨在改进Adam的初期学习行为。
我会在后续专门的文章中给大家详细介绍关于优化器地底层原理以及它们的选择,敬请期待
【代码示例】使用随机梯度下降(SGD)实现模型的训练
import torch import torchvision from torch import nn from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear from torch.optim.lr_scheduler import StepLR from torch.utils.data import DataLoader dataset = torchvision.datasets.CIFAR10("dataset/CIFAR10", train=False, transform=torchvision.transforms.ToTensor(), download=True) dataloader = DataLoader(dataset, batch_size=1) class myModule(nn.Module): def __init__(self): super().__init__() self.model1 = Sequential( Conv2d(3, 32, 5, padding=2), MaxPool2d(2), Conv2d(32, 32, 5, padding=2), MaxPool2d(2), Conv2d(32, 64, 5, padding=2), MaxPool2d(2), Flatten(), Linear(1024, 64), Linear(64, 10) ) def forward(self, x): x = self.model1(x) return x loss = nn.CrossEntropyLoss() # 交叉熵损失函数 mymodule = myModule() optim = torch.optim.SGD(mymodule.parameters(), lr=0.01) # 随机梯度下降优化器 for epoch in range(20): running_loss = 0.0 for data in dataloader: imgs, targets = data outputs = mymodule(imgs) result_loss = loss(outputs, targets) optim.zero_grad() # 每次进行反向传播前,将优化器的梯度置零,避免梯度积累 result_loss.backward() # 根据计算出的损失函数进行反向传播,计算梯度 optim.step() # 更新参数 running_loss = running_loss + result_loss # 累加损失,方便对每一轮的损失进行监控 print(running_loss)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
运行结果:
tensor(18725.9844, grad_fn=<AddBackward0>)
tensor(16125.2676, grad_fn=<AddBackward0>)
tensor(15378.4766, grad_fn=<AddBackward0>)
tensor(16010.2520, grad_fn=<AddBackward0>)
tensor(17944.1855, grad_fn=<AddBackward0>)
tensor(20080.8281, grad_fn=<AddBackward0>)
tensor(21999.3105, grad_fn=<AddBackward0>)
tensor(23399.3027, grad_fn=<AddBackward0>)
tensor(23927.0293, grad_fn=<AddBackward0>)
tensor(24855.1445, grad_fn=<AddBackward0>)
tensor(25396.4512, grad_fn=<AddBackward0>)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
修改网络模型
现在我们已经会自己搭建一个模型并进行训练,但通常情况下我们都不需要自己从头搭建一个网络,而是在前人研究的基础上,进行改进,得到效果更好的/更适用于当前任务的网络模型,如何修改别人已经搭建好的模型就成为了一个问题。
就像之前用到的CIFAR10之类的数据集一样,pytorch官网也为我们提供了一些公开的网络模型,我们在这里使用vgg16进行演示。
# pretrained表示是否使用预训练好的参数,选择True就是使用作者已经为我们训练好的参数,False则是随机初始化参数,自己从头开始进行训练
vgg16_true = torchvision.models.vgg16(pretrained=True)
- 1
- 2
Downloading: "https://download.pytorch.org/models/vgg16-397923af.pth" to C:\Users\13563/.cache\torch\hub\checkpoints\vgg16-397923af.pth
100.0%
- 1
- 2
此时如果打印我们实例化的vgg16对象,就可以看到它的整个网络结构:
VGG( (features): Sequential( (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (1): ReLU(inplace=True) (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (3): ReLU(inplace=True) (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (6): ReLU(inplace=True) (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (8): ReLU(inplace=True) (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(inplace=True) (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (13): ReLU(inplace=True) (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (15): ReLU(inplace=True) (16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (18): ReLU(inplace=True) (19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (20): ReLU(inplace=True) (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (22): ReLU(inplace=True) (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (25): ReLU(inplace=True) (26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (27): ReLU(inplace=True) (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (29): ReLU(inplace=True) (30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
首先要知道,大部分复杂的神经网络都分为了很多部分,比如:
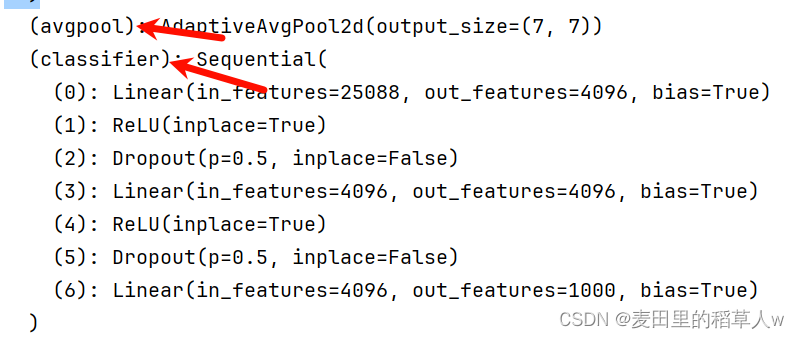
首先到达你需要修改网络的正确部分,添加层使用add_module,修改某个层使用它的下表定位后重新制定Module即可
【代码示例】修改下载的vgg16模型并观察其网络结构的变化
import torchvision from torch import nn vgg16_false = torchvision.models.vgg16(pretrained=False) vgg16_true = torchvision.models.vgg16(pretrained=True) print(vgg16_true) print("*"*30) vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10)) print(vgg16_true) print("*"*30) print(vgg16_false) print("*"*30) vgg16_false.classifier[6] = nn.Linear(4096, 10) print(vgg16_false)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
模型的保存与读取
当我们写好一个模型,训练好其参数后,谁也不想下次开机又要重新来一遍这个漫长的过程,这个时候就需要将训练好的模型进行保存,并在下一次需要使用它时候进行读取。
模型的保存和读取有两种方法:
-
保存模型结构+模型参数
# 保存 torch.save(vgg16, "vgg16_method1.pth") # 读取 model = torch.load("vgg16_method1.pth")- 1
- 2
- 3
- 4
- 5
用这个方法得到的模型对象直接答应就是其网络结构
-
保存模型参数
# 保存 torch.save(vgg16.state_dict(), "vgg16_method2.pth") # 读取 需要先创建好对象,然后给其传入参数 vgg16 = torchvision.models.vgg16(pretrained=False) vgg16.load_state_dict(torch.load("vgg16_method2.pth")) model = torch.load("vgg16_method2.pth") print(model) # 直接读取的话就是所有参数的字典 print(vgg16)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
推荐使用第二种方法,第一种方法的陷阱:
# 保存一个自定义网络 class myModule(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(3, 64, kernel_size=3) def forward(self, x): x = self.conv1(x) return x mymodule = myModule() torch.save(mymodule, "mymodule.pth") # 读取 model = torch.load('mymodule.pth') print(model)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
这种情况下在另一个文件中使用第一种方法进行读取就会报错,因为在新的文件中没有定义关于自定义模型的结构。这时候在新的文件中导入自定义模块的类,使用第二种方法创建对象,然后再传参就不会有问题了。

