
热门标签
热门文章
- 1github中git clone需要username和password问题_git username password
- 2二叉树的前序遍历,中序遍历,后序遍历(Java实现)_java后续遍历
- 3WMI系列--关于WMI_wmi协议
- 4flutter从0到1构建大前端应用 pdf_这些年的体验技术部(四)· 平台前端 - 有技术,有业务,有爱与远方...
- 5Oracle:左连接、右连接、全外连接、(+)号详解_左外连接和右外连接详解
- 6DS18B20工作原理_ds18b20工作原理及电路图
- 7程序员面试时这样介绍自己的项目经验,成功率能达到98,2024年最新分享一波阿里、字节、腾讯、美团等精选大厂面试题_程序员面试怎么介绍项目
- 8ESP32+VSCode+CMake_esp32 vscode编译带调试信息的elf
- 9el-table二次封装表格组件
- 10RabbitMQ和Kafka的区别_kafaka和rabitmq的区别
当前位置: article > 正文
机器学习笔记 - PyTorch 分布式训练概览
作者:IT小白 | 2024-06-02 19:37:48
赞
踩
机器学习笔记 - PyTorch 分布式训练概览
一、简述
对于大规模的数据集,只能进行分布式训练,分布式训练会尽可能的利用我们的算力,使模型训练更加高效。PyTorch提供了Data Parallel包,它可以实现单机、多GPU并行。
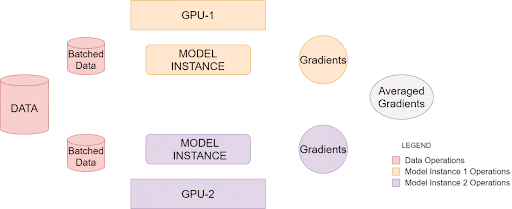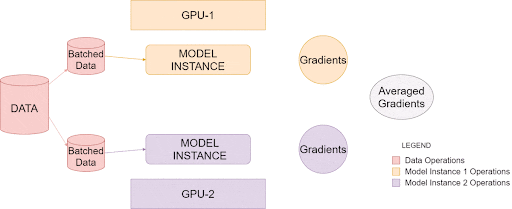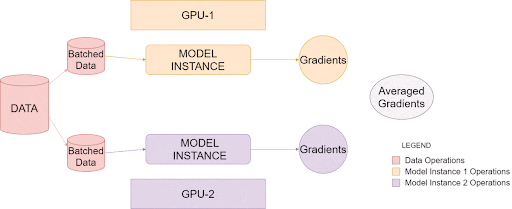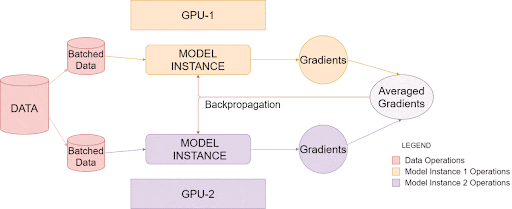
上面的图像说明了PyTorch 如何在单个系统中利用多个 GPU,这称为数据并行训练,您可以使用具有多个 GPU 的单个主机系统来提高处理大量数据的效率。
一旦被调用,就会在每个GPU上创建单独的模型实例。然后,数据被分成相等的部分,每个模型实例一个。最后,每个实例创建自己的梯度,然后在所有可用实例之间进行平均和反向传播。
这里首先看看单机多卡的训练,弄明白了以后多机多卡就差不多了。
下面就进入代码,看看如何进行分布式训练,这里写的基本都是从别人哪里借鉴来的,基本算是个记录,回头实操完事再来补充一些东西和遇到的问题。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/664091
推荐阅读
相关标签

