- 1go 针对 time类型字段,前端查询,后端返回数据格式为UTC时间
- 2git clone没有权限的解决方法_git没有权限clone代码
- 3Kafka-消费者(订阅主题消费数据及常用调优参数解析)
- 4Raid介绍_服务器raid
- 5mysql 数据导入sqlserver_如何从mysql中将数据导入到sqlserver
- 6【Python数据挖掘课程】四.决策树DTC数据分析及鸢尾数据集分析_decision tree test data
- 7Mysql查看连接并批量kill线程_show processlist kill 批量
- 8vue3.0使用axios 解决跨域问题_vue3 axios跨域
- 9Python 数据挖掘 | 第3章 使用 Pandas 数据分析_pandas 并计算潜力低、中等、优秀三个等级的数量
- 10如何读源码-方法论总结_常用方法论总结
LLM大语言模型(十六):最新开源 GLM4-9B 本地部署,带不动,根本带不动
赞
踩
目录

前言
GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。
在语义、数学、推理、代码和知识等多方面的数据集测评中, GLM-4-9B 及其人类偏好对齐的版本 GLM-4-9B-Chat 均表现出超越 Llama-3-8B 的卓越性能。
除了能进行多轮对话,GLM-4-9B-Chat 还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大 128K 上下文)等高级功能。
本代模型增加了多语言支持,支持包括日语,韩语,德语在内的 26 种语言。
我们还推出了支持 1M 上下文长度(约 200 万中文字符)的 GLM-4-9B-Chat-1M 模型和基于 GLM-4-9B 的多模态模型 GLM-4V-9B。GLM-4V-9B 具备 1120 * 1120 高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中,GLM-4V-9B 表现出超越 GPT-4-turbo-2024-04-09、Gemini 1.0 Pro、Qwen-VL-Max 和 Claude 3 Opus 的卓越性能。
本机环境
OS:Windows
CPU:AMD Ryzen 5 3600X 6-Core Processor
Mem:32GB
GPU:RTX 4060Ti 16G
GLM4代码库下载
参考:LLM大语言模型(一):ChatGLM3-6B本地部署_llm3 部署-CSDN博客
- # 下载代码库
- https://github.com/THUDM/GLM-4.git
-
模型文件下载:文件很大
建议从modelscope下载模型,这样就不用担心网络问题了。
模型链接如下:
- git lfs install # 以安装则忽略
- git clone https://www.modelscope.cn/ZhipuAI/glm-4-9b-chat.git
做好心理准备:接近20G(我的带宽只有300Mbps~~)
修改为从本地模型文件启动
修改此文件basic_demo/trans_cli_demo.py
修改这一行:
MODEL_PATH = os.environ.get('MODEL_PATH', 'D:\github\glm-4-9b-chat') 该为你下载的模型文件夹
- """
- This script creates a CLI demo with transformers backend for the glm-4-9b model,
- allowing users to interact with the model through a command-line interface.
- Usage:
- - Run the script to start the CLI demo.
- - Interact with the model by typing questions and receiving responses.
- Note: The script includes a modification to handle markdown to plain text conversion,
- ensuring that the CLI interface displays formatted text correctly.
- """
-
- import os
- import torch
- from threading import Thread
- from typing import Union
- from pathlib import Path
- from peft import AutoPeftModelForCausalLM, PeftModelForCausalLM
- from transformers import (
- AutoModelForCausalLM,
- AutoTokenizer,
- PreTrainedModel,
- PreTrainedTokenizer,
- PreTrainedTokenizerFast,
- StoppingCriteria,
- StoppingCriteriaList,
- TextIteratorStreamer
- )
-
- ModelType = Union[PreTrainedModel, PeftModelForCausalLM]
- TokenizerType = Union[PreTrainedTokenizer, PreTrainedTokenizerFast]
-
- # 改为你下载的模型文件夹
- MODEL_PATH = os.environ.get('MODEL_PATH', 'D:\github\glm-4-9b-chat')
-
-
- def load_model_and_tokenizer(
- model_dir: Union[str, Path], trust_remote_code: bool = True
- ) -> tuple[ModelType, TokenizerType]:
- model_dir = Path(model_dir).expanduser().resolve()
- if (model_dir / 'adapter_config.json').exists():
- model = AutoPeftModelForCausalLM.from_pretrained(
- model_dir, trust_remote_code=trust_remote_code, device_map='auto')
- tokenizer_dir = model.peft_config['default'].base_model_name_or_path
- else:
- model = AutoModelForCausalLM.from_pretrained(model_dir, trust_remote_code=trust_remote_code, device_map='auto')
- tokenizer_dir = model_dir
-
- tokenizer = AutoTokenizer.from_pretrained(
- tokenizer_dir, trust_remote_code=trust_remote_code, encode_special_tokens=True, use_fast=False
- )
- return model, tokenizer
-
-
- model, tokenizer = load_model_and_tokenizer(MODEL_PATH, trust_remote_code=True)
-
-
- class StopOnTokens(StoppingCriteria):
- def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
- stop_ids = model.config.eos_token_id
- for stop_id in stop_ids:
- if input_ids[0][-1] == stop_id:
- return True
- return False
-
-
- if __name__ == "__main__":
- history = []
- max_length = 8192
- top_p = 0.8
- temperature = 0.6
- stop = StopOnTokens()
-
- print("Welcome to the GLM-4-9B CLI chat. Type your messages below.")
- while True:
- user_input = input("\nYou: ")
- if user_input.lower() in ["exit", "quit"]:
- break
- history.append([user_input, ""])
-
- messages = []
- for idx, (user_msg, model_msg) in enumerate(history):
- if idx == len(history) - 1 and not model_msg:
- messages.append({"role": "user", "content": user_msg})
- break
- if user_msg:
- messages.append({"role": "user", "content": user_msg})
- if model_msg:
- messages.append({"role": "assistant", "content": model_msg})
- model_inputs = tokenizer.apply_chat_template(
- messages,
- add_generation_prompt=True,
- tokenize=True,
- return_tensors="pt"
- ).to(model.device)
- streamer = TextIteratorStreamer(
- tokenizer=tokenizer,
- timeout=60,
- skip_prompt=True,
- skip_special_tokens=True
- )
- generate_kwargs = {
- "input_ids": model_inputs,
- "streamer": streamer,
- "max_new_tokens": max_length,
- "do_sample": True,
- "top_p": top_p,
- "temperature": temperature,
- "stopping_criteria": StoppingCriteriaList([stop]),
- "repetition_penalty": 1.2,
- "eos_token_id": model.config.eos_token_id,
- }
- t = Thread(target=model.generate, kwargs=generate_kwargs)
- t.start()
- print("GLM-4:", end="", flush=True)
- for new_token in streamer:
- if new_token:
- print(new_token, end="", flush=True)
- history[-1][1] += new_token
-
- history[-1][1] = history[-1][1].strip()

启动模型cli对话demo
运行该py文件即可,效果如下:
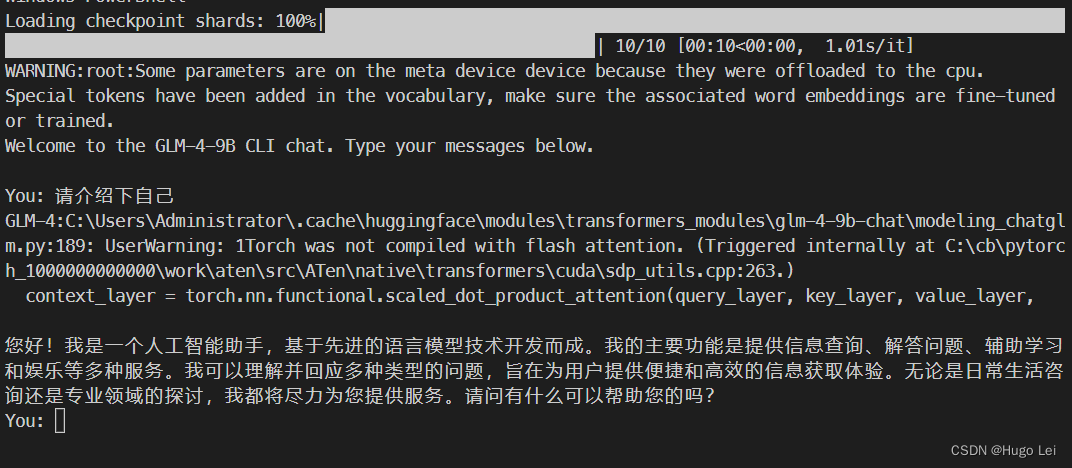
模型运行时会报个warning:
C:\Users\Administrator\.cache\huggingface\modules\transformers_modules\glm-4-9b-chat\modeling_chatglm.pm.py:189: UserWarning: 1Torch was not compiled with flash attention. (Triggered internally at C:\cb\pytorc000h_1000000000000\work\aten\src\ATen\native\transformers\cuda\sdp_utils.cpp:263.)
context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer, key_layer, value_layer,
不过也没影响运行。
慢,巨慢,一个字一个字的蹦
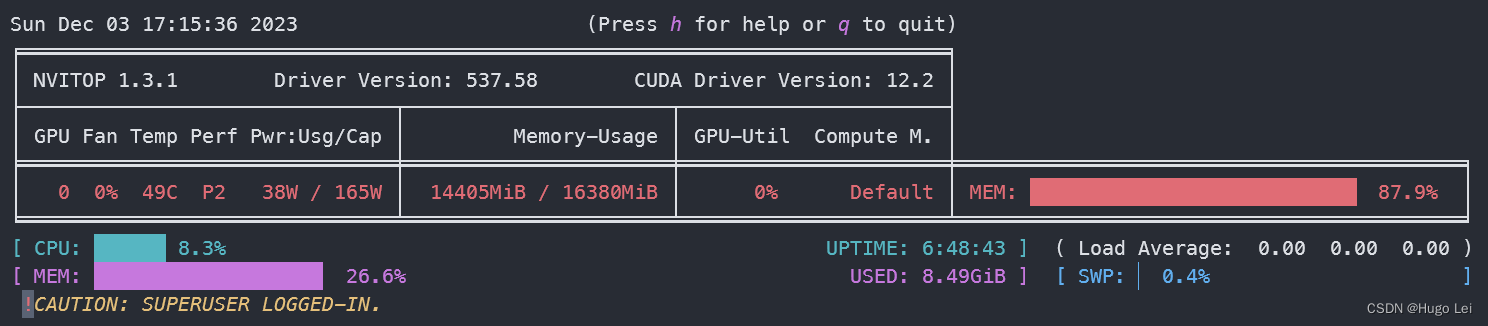
GPU资源使用情况
- 16G显存,使用率90%+
- 内存使用16G,50%

GLM3资源使用情况对比