
- 1Spring Boot 整合 Spring AI 实现项目接入ChatGPT(OpenAl的调用,开发属于你自己Al,体验Al的乐趣)本文仅讲解聊天方式的实现,关于gpt的其他东西,参考接下来的文章_springboot 扩展springai
- 2Apache Flink v1.8(首页)_flink 1.8 文档
- 3杭电和苏大计算机考研,江苏省各高校“排行榜”出炉,江苏大学10名开外,南大当属第一!...
- 4Java 实现并查集查询、合并_java两个查询并行查询后合并成结果
- 5Gitbook电子书同步至github_gitbook同步到git
- 6使用dblink同步本地数据库新增记录到远程服务器_有clob字段的表 远程视图
- 7Python基于大数据的微博的舆论情感分析,微博评论情感分析可视化系统,附源码_微博评论情感分析数据可视化
- 8首个开源中文金融大模型来了!解释授信额度、计算收益率、决策参考样样通,来自度小满|附下载...
- 9xilinx7系列FPGA上电flash模式选择,及CFGBVS管脚电平选择
- 102022年下半年软件设计师下午真题及答案解析_软件设计师中级真题
预训练语言模型--transformer_基于 transformer 的预训练语言模型
赞
踩
目录
一.背景
说到自然语言处理,语言模型,命名实体识别,机器翻译,可能很多人想到的LSTM等循环神经网络,但目前其实LSTM起码在自然语言处理领域已经过时了,在Stanford阅读理解数据集(SQuAD2.0)榜单里,机器的成绩已经超人类表现,这很大程度要归功于transformer的BERT预训练模型。
transformer是谷歌大脑在2017年底发表的论文中所提出的seq2seq模型(从序列到序列的模型).现在已经取得了大范围的应用和扩展,而BERT就是从transformer中衍生出来的预训练语言模型。
这里介绍一下在目前的自然语言处理领域,transformer模型已经得到广泛认可和应用,而应用的方式主要是先进行预训练语言模型(上游任务),然后把预训练的模型适配给下游任务(在自然语言处理中要完成的实际的任务,如情感分析,分类,机器翻译等),以完成各种不同的任务,如分类,生成,标记等等,预训练模型非常重要,预训练的模型的性能直接影响下游任务的性能。就好比要培养一个孩子成为作家,不可能上来就直接让他开始写作,在写作之前肯定会让他识字,看很多的大作家的作品汲取精华,最后才可以进行写作。
二.transformer编码器
- 1. t r a n s f o r m e r transformer transformer模型直觉,建立直观认识;
- 2. p o s i t i o n a l positional positional e n c o d i n g encoding encoding,即位置嵌入(或位置编码);
- 3. s e l f self self a t t e n t i o n attention attention m e c h a n i s m mechanism mechanism,即自注意力机制与注意力矩阵可视化;
- 4. L a y e r Layer Layer N o r m a l i z a t i o n Normalization Normalization和残差连接;
- 5. t r a n s f o r m e r transformer transformer e n c o d e r encoder encoder整体结构。
1. t r a n s f o r m e r transformer transformer模型直觉,建立直观认识;
首先来说一下transformer和LSTM/RNN的最大区别,就是LSTM/RNN的训练是迭代的,是一个接一个字的来,当前这个字过完LSTM单元/RNN层,才可以进下一个字,而transformer的训练是并行的,一般以字为单位训练的,transformer模型就是所有字是全部同时训练的,这样就大大加快了计算效率, transformer使用了位置嵌入(positional encoding)来理解语言的顺序(获取时间序列关系),使用自注意力机制和全连接层来进行计算。
transformer模型主要分为两大部分,分别是编码器和解码器,编码器负责把自然语言序列映射成为隐藏层(下图中第2步用九宫格比喻的部分),含有自然语言序列的数学表达.然后解码器把隐藏层再映射为自然语言序列,从而使我们可以解决各种问题,如情感分类,命名实体识别,语义关系抽取,摘要生成,机器翻译等等,下面我们简单说一下下图的每一步都做了什么:
1.1transformer的流程



- <1>
Inputs是经过padding的输入数据,大小(shape)是[batch_size, max_sequence](batch_size个max_sequence长度的句子,同时输入) - <2>初始化
embedding matrix,通过embedding lookup(到字向量表中去查找对应的字向量)将Inputs映射成token embedding,大小是[batch_size, max_sequence, embedding_size] - <3>通过
sin和cos函数创建positional encoding,表示一个token(这里的token就是目标词(字)的意思)的绝对位置信息,并且加入到token embedding中,然后dropout - <4>
multi-head attention(多头注意力机制) - <4.1>输入
token embedding,通过Dense生成Q,K,V,大小是[batch size, max seq length, embedding size],然后按第2维split成num heads份并按第0维concat,生成新的Q,K,V,大小是[num heads*batch size, max seq length, embedding size/num heads],完成multi-head的操作。 - <4.2>将K的第1维和第2维进行转置,然后Q和转置后的K的进行点积,结果的大小是
[num heads*batch size, max seq length, max seq length]。 - <4.3> 将<4.2>的结果除以
hidden size的开方(在transformer中,hidden size=embedding size),完成scale的操作。 - <4.4> 将<4.3>中padding的点积结果置成一个很小的数(-2^32+1),完成mask操作,后续
softmax对padding的结果就可以忽略不计了。 - <4.5> 将经过
mask的结果进行softmax操作。 - <4.6> 将
softmax的结果和V进行点积,得到attention的结果,大小是[num heads*batch size, max seq length, hidden size/num heads]。 - <4.7> 将
attention的结果按第0维split成num heads份并按第2维concat,生成multi-head attention的结果,大小是[batch size, max seq length, hidden size]。Figure 2上concat之后还有一个linear的操作,但是代码里并没有。 - <5> 将
token embedding和multi-head attention的结果相加,并进行Layer Normalization。 - <6> 将<5>的结果经过2层Dense,其中第1层的
activation=relu,第2层activation=None。 - <7> 功能和<5>一样。
- 未完待续
1.2transformer-encoder部分
这里主要分析编码器的结构,主要是Bert预训练语言模型只用到了编码器部分。
Transformer Block结构图:
注意,为了方便查看,下边的内容分别对应着图中第1,2,3,4个方框的序号
图表分析:
- 这里输入一个 X X X(多个句子)得到一个 X h i d d e n X_{hidden} Xhidden, X h i d d e n X_{hidden} Xhidden就是通过编码器输出得到的隐藏层。先看一下第一步
Input Embedding,先从字向量表里边查到对应的字向量,它的维度就变成了[batch_size , Sequence_length , embedding_dimmension],这里的input Embedding就是从这个表中找到每一个字的数学表达。
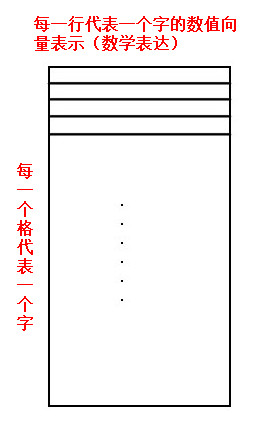
字向量表的结构:
这里是一个字的向量查询表(哪里来的?),本文第一幅图中的第二步中初始化embedding matrix,就是通过embedding lookup(到字向量表中去查找对应的字向量)将Inputs映射成token embedding,大小(shape)是[batch_size, max_sequence, embedding_size]

接下来引入position encoding的概念,即给每一个字设定一个位置
2.
p
o
s
i
t
i
o
n
a
l
e
n
c
o
d
i
n
g
positional \ encoding
positional encoding, 即位置嵌入(或位置编码)声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/701199
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

