
- 1sql modify 会丢失数据么_面试数据分析会遇到的SQL题
- 2基于javaweb+mysql的springboot学生信息管理系统(java+springboot+maven+mybaits+html+easyui+mysql)_javaspringboot学生管理系统
- 3python-中文闲聊的GPT2模型首次使用笔记_gpt-2 下载模型数据后如何运行
- 4vue3+vite+ts 使用webrtc-streamer播放海康rtsp监控视频_vue3 webrtc 播放
- 5PyCharm没有找到Django怎么办_pycharm新建项目没有django
- 6Github不再支持密码验证的方式进行git操作_github代码推送不能使用密码验证了吗
- 7Xilinx 原语简介--(Xilinx FPGA开发实用教程)_bufg和bugio在xilinx的哪个文档
- 8韩国Meetup | Trias,区块链公链底层的一条“高速公路”
- 9原来阿里P8的工资这么低啊。。。
- 10作为重度使用者,简评一下国内外几大 AI 大模型_国外哪些ai大模型中国能使用?
腾讯开源数字人视频生成神器MuseV整合包获取和使用教程_musetalk整合包
赞
踩
MuseV 是基于扩散模型的虚拟人视频生成框架,具有以下特点:
- 支持使用新颖的视觉条件并行去噪方案进行无限长度生成,不会再有误差累计的问题,尤其适用于固定相机位的场景。
- 提供了基于人物类型数据集训练的虚拟人视频生成预训练模型。 支持图像到视频、文本到图像到视频、视频到视频的生成。
- 兼容StableDiffusion 文图生成生态系统,包括 base_model、lora、controlnet 等。
- 支持多参考图像技术,包括IPAdapter、ReferenceOnly、ReferenceNet、IPAdapterFaceID。
MuseV支持图生视频、视频生视频,可与腾讯开源的另一款AI工具MuseTalk 一起构建完整的虚拟人生成解决方案。
MuseV开源地址:https://github.com/TMElyralab/MuseV
MuseTalk开源地址:https://github.com/TMElyralab/MuseTalk
MuseV在线试用地址(需要魔法):https://huggingface.co/spaces/AnchorFake/MuseVDemo
github上提供了源码搭建运行环境的中文和英文教程,因此本文只详细介绍整合包的获取和使用教程。
点击打开我的个人博客主页,扫码关注微信公众号回复关键词【muse】获取整合包
MuseV使用教程
获取安装包后解压,双击【01运行程序.bat】去运行
1. 提示词和图片生成视频(Text to Video)
运行成功后会在浏览器中打开如下界面,可以看到支持Text to Video和 Video to Video两种模式。Text to Video 各个参数含义如下图,其中输入的图像的越小生成视频的动作幅度越大,所以输入图像的宽高尽量不要设置太大,但是小的话也会导致视频分辨率降低,设置图像宽高的时候尽量去设置 img_edge_ratio,这个参数会等比例缩放图像,如果直接设置width和height比例不对的话会导致图像变形 ;另外视频的帧率也不要设置太大,因为生成的帧数最大为144,设置的越大会导致视频的时长越短,分辨率和帧率的问题可以另外通过补帧和视频高清化工具去处理。
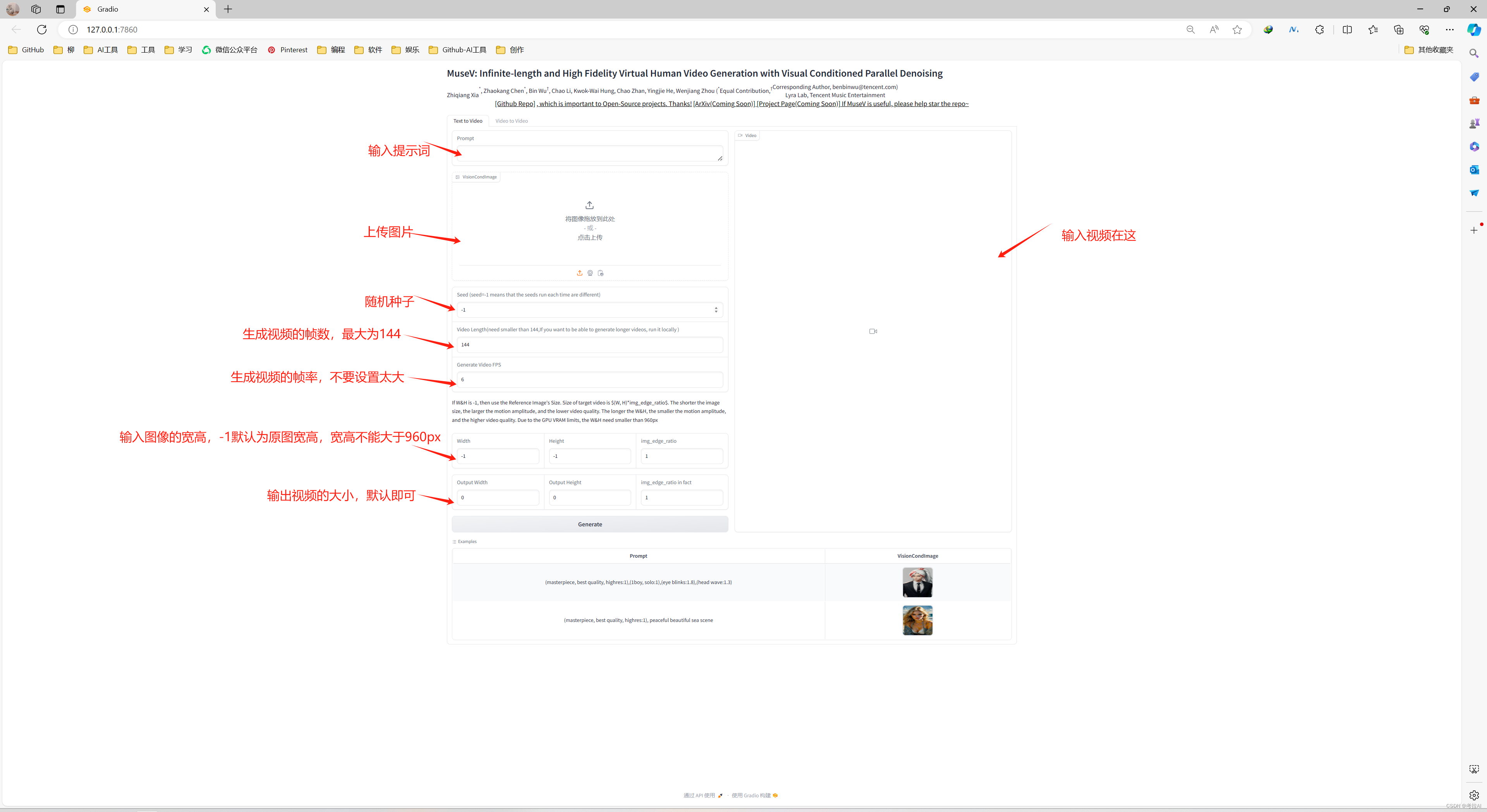
可以参照我下面的设置,设置完成后点击Generate按钮等待视频生成即可,生成完成后可以点击图中的下载箭头下载到本地,也可以在Video窗口点击鼠标右键将视频另存为本地

生成视频效果如下:
musev-text-video
2. 提示词和图片和参考视频生成视频(Video to Video)
Video to Video 各个参数含义如下图,其中没写的与Text to Video相同,不再赘述。其中图片和参考视频要保持一致性,可以通过sd或者mj拿参考视频的第一帧通过图生图生成图片,控制条件的意思是生成的视频按照参考视频的什么条件去生成,webui中只支持dwpose_body_hand,即模仿参考视频中人物的身体和手的姿势去生成,通过命令行运行的方式可以支持多种,如何命令行运行可以去github中查看。
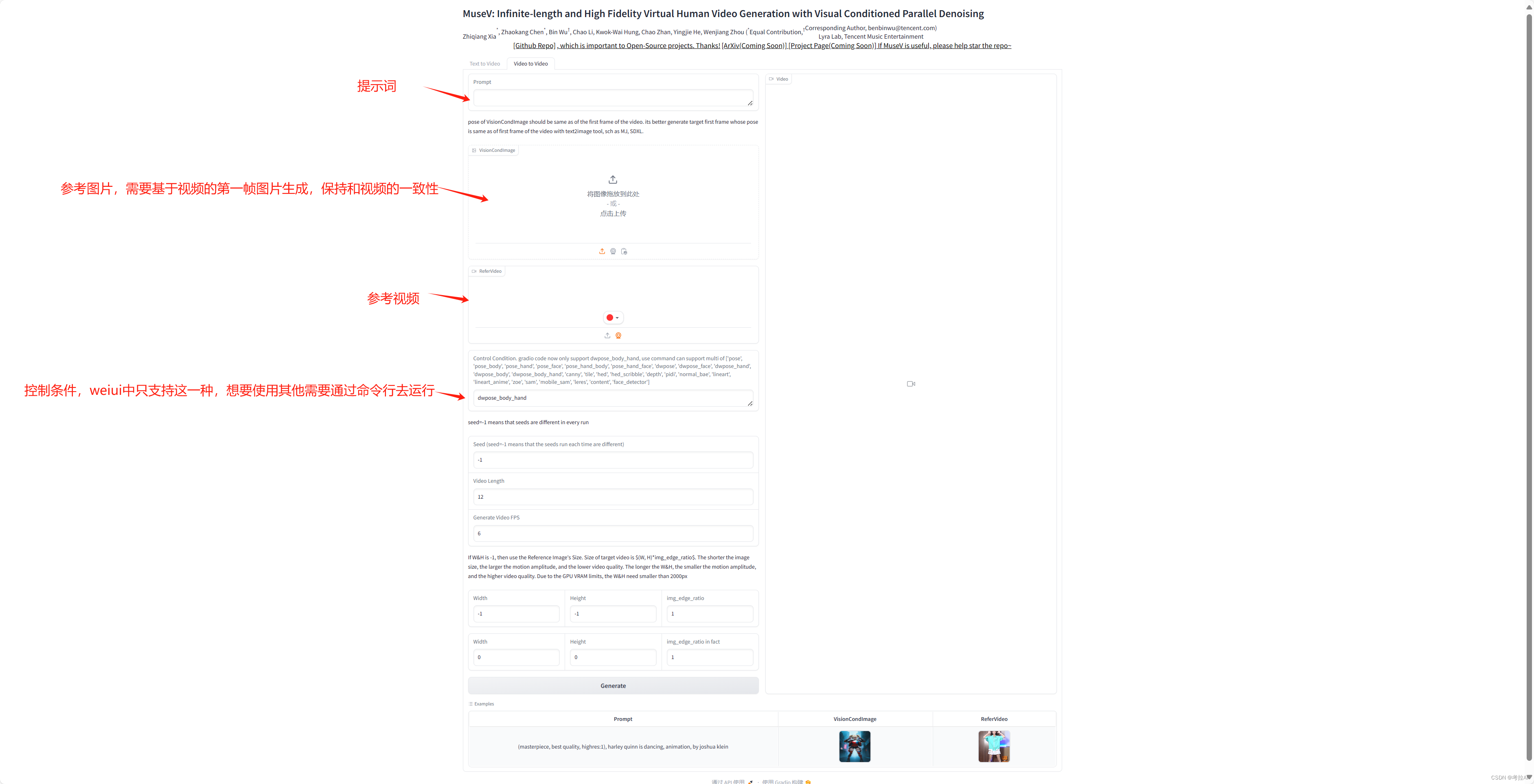
可以参照我下面的设置,设置完成后点击Generate按钮等待视频生成即可,生成完成后可以点击下载箭头下载到本地,也可以在Video窗口点击鼠标右键将视频另存为本地
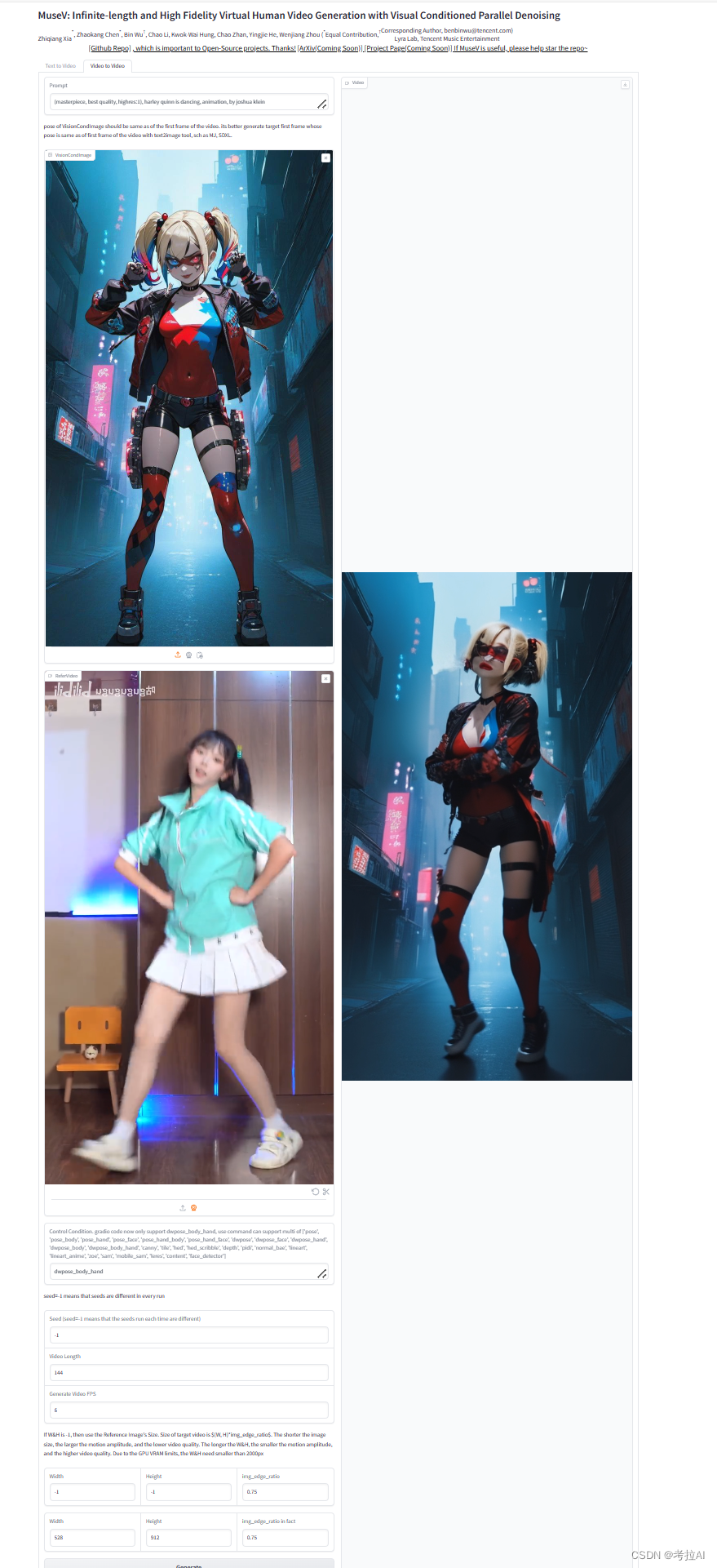
最终生成的效果如下:
musev-video-video
点击打开我的个人博客主页,扫码关注微信公众号回复关键词【muse】获取整合包


