
- 12024.6.2力扣刷题记录
- 2基于51单片机音乐盒设计( proteus仿真+程序+原理图+PCB+报告+讲解视频)_单片机电子音乐盒的设计
- 3新思科技:部署数据安全战略,更好地实现合规性_安全策略与合规性
- 4基于neo4j的机械设备知识图谱问答展示系统_给电机及拖动基础知识问答网页系统(用python、neo4j做的)画一个主程序流程图和子
- 5网络安全笔记-TCP/IP_安全服务越上层可以部署的安全服务越多
- 6SpringBootWeb 篇-深入了解会话技术与会话跟踪三种技术(Cookie 会话跟踪、Session 会话跟踪与 JWT 令牌会话跟踪)_spring 禁用会话跟踪cookie
- 7C语言实现堆排序
- 8【2024最新版】neo4j安装配置_neo4j最新安装
- 9RDD—Transformation算子_rdd中transform 算子有什么
- 10OpenCV 单目测距实现
[Bart]论文实现:Denoising Sequence-to-Sequence Pre-training for Natural Language Generation..._lewis m , liu y , goyal n ,et al.bart: denoising s
赞
踩
论文:BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
作者:Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer
时间:2019
一、完整代码
这里我们使用python代码进行实现
# 完整代码在这里
# 这里感觉在输出端实现就好了,下次有时间在弄;
- 1
- 2
二、论文解读
BART论文名字为Denoising Sequence-to-Sequence Pre-training for Natural Language...,在这里有两个名词要考虑,一个是Sequence-to-Sequence,一个是Pre-training;前者的架构较为出名的有RNN和Transformer,后者的架构较为出名的有Bert,GPT;但是这里要注意的是BART是一个Transformer架构;
其于Transformer不同的地方只有一个,就是input;毫无疑问,这就是一篇水文;
2.1 模型架构
模型架构就是Transformer;

论文在水的时候,在画图故意不用Transformer来进行对比,而是用Bert和GPT来对比,很贼;

2.2 输入端
BART在输入端中采取的措施:
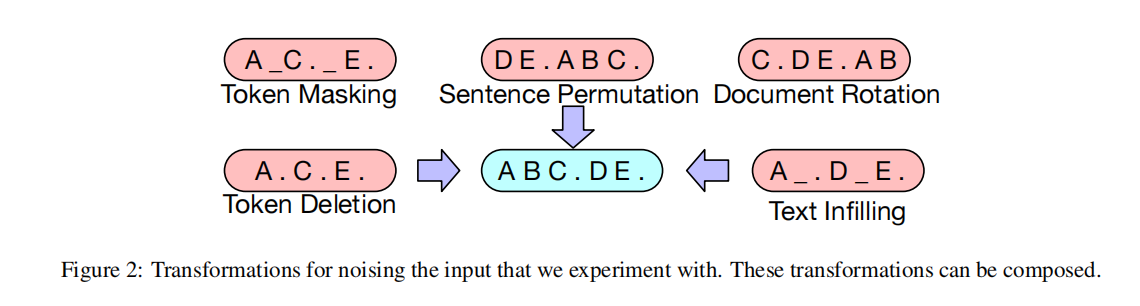
下面我们对其依次介绍:
Token Masking
这里采取的方式和BERT一样,使用随机的mask来regularization;
Token Deletion
这里采取的方式是随机删除一些token,注意是删除而不是使用掩码,是从源头删除,掩码的长度会改变;
Text Infilling
这里采取的方式是填充,有删除就有填充,这很好理解;
Sentence Permutation
这里是通过标点符号来切割sentences,然后对sentences进行排序,再来训练;
Document Rotation
这里就相当于说是随机打乱,没有一点规律;
2.3 微调
微调不同任务采取不同的措施,论文中的图片还挺形象的,如下所示:

Sequence Classification Tasks
这里使用transformer的decoder中隐藏层的最后一层进行文本分类,就相当于BERT中的[cls]的效果,至于为什么是最后一个,因为解码器是单向的,而最后一个是最后的输出,其是自回归模型与前面的信息进行了充分的交互;
Token Classification Tasks
看起来高大上,其本质就是在后面弄一层dense层,然后继续词的预测;这里写成classification真有意思…
Sequence Generation Tasks
和GPT一样,无需解释;
Machine Translation
这个就更不用说了,这就是transformer本来的任务;
2.4 结果
使用了消融实验,结果如下所示:

不同模型之间的不同如下所示:
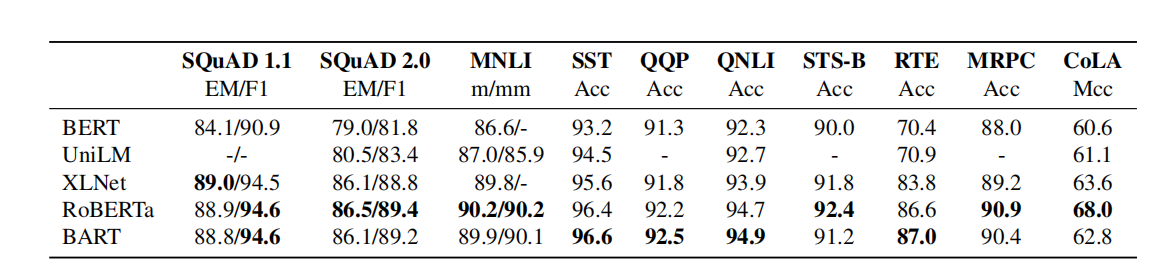
其中我们可以看到,BART的效果和RoBERTa和XLNet的效果差不多;
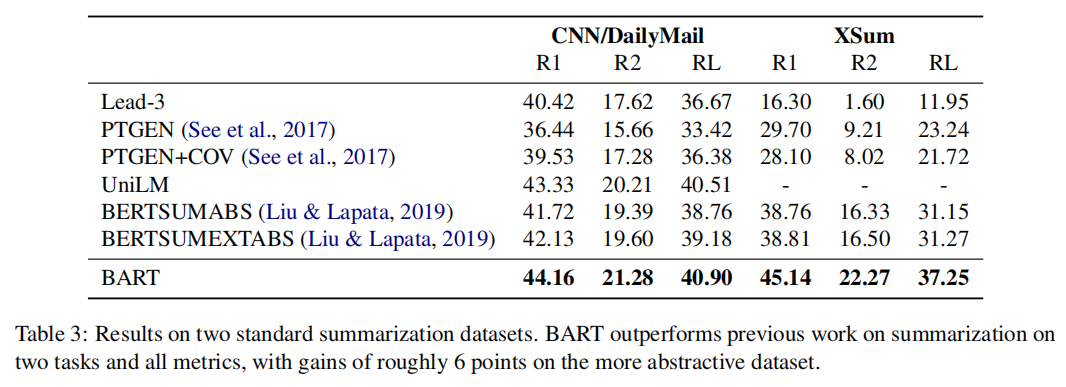
其中我们可以看到,在文本总结上效果挺好的;
三、过程实现
这里感觉在输出端实现就好了,下次有时间在弄;
四、整体总结
论文好水,就是几个regularization结合在一起;


