
- 1vscode+docker搭建迷你开发环境。制作docker镜像,并通过vscode连接后进行开发_vscode docker
- 2Git使用入门_git lens push stash
- 3VMware Workstation 17 Pro下载与安装
- 4js判断两个input是否一致_required判断两个input框输入是否一致
- 5开源大模型之辩:真假开源_分辨大模型基于什么开源
- 6服务器启用tls协议,在服务器上启用 TLS 1.2 - Configuration Manager | Microsoft Docs
- 7python实现按键精灵之找图点击_python 找图
- 8ARIMA参数判定_如何通过acf和pacf判断arima的参数
- 9探索未来显示技术:Parsec VDD - 您的虚拟超级显示屏解决方案
- 10吴恩达:AI 智能体工作流_ai智能体工作流
sqoop数据迁移(基于Hadoop和关系数据库服务器之间传送数据)_2个关系型数据库可以用sqoop做数据传输吗
赞
踩
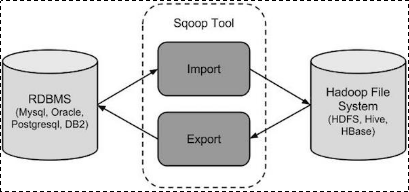
1:sqoop的概述:
(1):sqoop是apache旗下一款“Hadoop和关系数据库服务器之间传送数据”的工具。
(2):导入数据:MySQL,Oracle导入数据到Hadoop的HDFS、HIVE、HBASE等数据存储系统;
(3):导出数据:从Hadoop的文件系统中导出数据到关系数据库(4):工作机制:
将导入或导出命令翻译成mapreduce程序来实现;
在翻译出的mapreduce中主要是对inputformat和outputformat进行定制;(5):Sqoop的原理:
Sqoop的原理其实就是将导入导出命令转化为mapreduce程序来执行,sqoop在接收到命令后,都要生成mapreduce程序;
使用sqoop的代码生成工具可以方便查看到sqoop所生成的java代码,并可在此基础之上进行深入定制开发;
2:sqoop安装:
安装sqoop的前提是已经具备java和hadoop的环境;
第一步:下载并解压,下载以后,上传到自己的虚拟机上面,过程省略,然后解压缩操作:
最新版下载地址:http://ftp.wayne.edu/apache/sqoop/1.4.6/
Sqoop的官方网址:http://sqoop.apache.org/
[root@master package]# tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /home/hadoop/
第二步:修改配置文件:
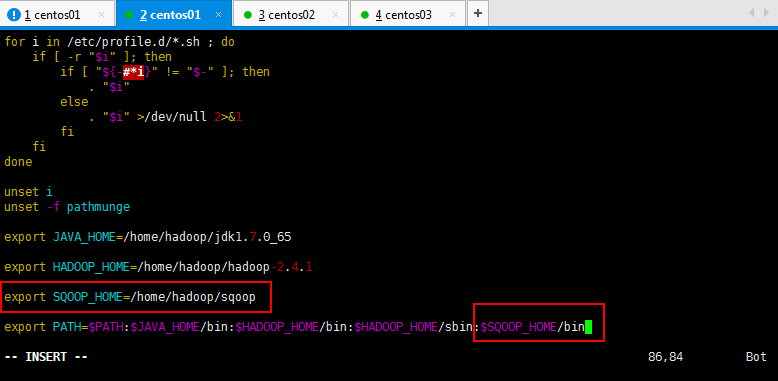
可以修改一下sqoop的名称,因为解压缩的太长了。然后你也可以配置sqoop的环境变量,这样可以方便访问;
[root@master hadoop]# mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha/ sqoop
配置Sqoop的环境变量操作,如下所示:
[root@master hadoop]# vim /etc/profile
[root@master hadoop]# source /etc/profile
修改sqoop的配置文件名称如下所示:
[root@master hadoop]# cd $SQOOP_HOME/conf
[root@master conf]# ls
oraoop-site-template.xml sqoop-env-template.sh sqoop-site.xml
sqoop-env-template.cmd sqoop-site-template.xml
[root@master conf]# mv sqoop-env-template.sh sqoop-env.sh
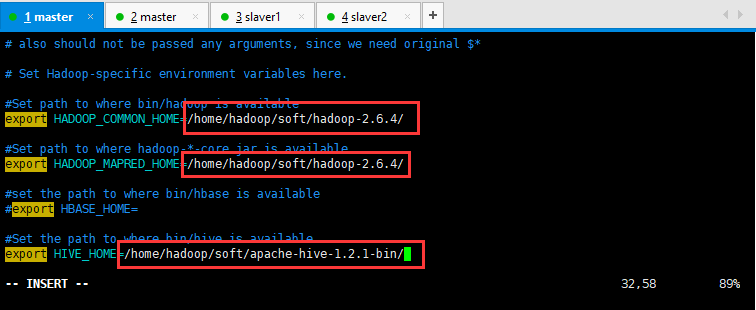
修改sqoop的配置文件如下所示,打开sqoop-env.sh并编辑下面几行(根据需求,可以修改hadoop,hive,hbase的配置文件):
第三步:加入mysql的jdbc驱动包(自己必须提前将mysql的jar包上传到虚拟机上面):
[root@master package]# cp mysql-connector-java-5.1.28.jar $SQOOP_HOME/lib/
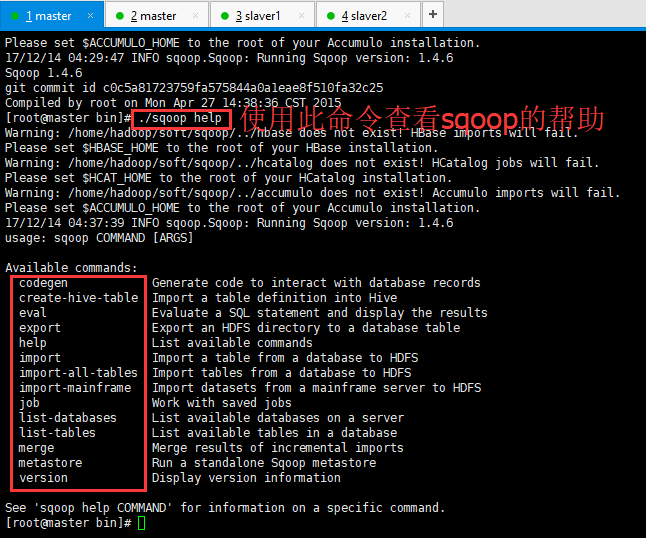
第四步:验证启动,如下所示(由于未配置$HBASE_HOME等等这些的配置,所以发出Warning,不是Error):
[root@master conf]# cd $SQOOP_HOME/bin
1 [root@master bin]# sqoop-version 2 Warning: /home/hadoop/soft/sqoop/../hbase does not exist! HBase imports will fail. 3 Please set $HBASE_HOME to the root of your HBase installation. 4 Warning: /home/hadoop/soft/sqoop/../hcatalog does not exist! HCatalog jobs will fail. 5 Please set $HCAT_HOME to the root of your HCatalog installation. 6 Warning: /home/hadoop/soft/sqoop/../accumulo does not exist! Accumulo imports will fail. 7 Please set $ACCUMULO_HOME to the root of your Accumulo installation. 8 17/12/14 04:29:47 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6 9 Sqoop 1.4.6 10 git commit id c0c5a81723759fa575844a0a1eae8f510fa32c25 11 Compiled by root on Mon Apr 27 14:38:36 CST 2015
到这里,整个Sqoop安装工作完成。下面可以尽情的和Sqoop玩耍了。
3:Sqoop的数据导入:
“导入工具”导入单个表从RDBMS到HDFS。表中的每一行被视为HDFS的记录。所有记录都存储为文本文件的文本数据(或者Avro、sequence文件等二进制数据)
下面的语法用于将数据导入HDFS。
1 $ sqoop import (generic-args) (import-args)
导入表表数据到HDFS
下面的命令用于从MySQL数据库服务器中的emp表导入HDFS。
1 $bin/sqoop import \ 2 --connect jdbc:mysql://localhost:3306/test \ #指定主机名称和数据库 3 --username root \ #mysql的账号 4 --password root \ #mysql的密码 5 --table emp \ #导入的数据表 6 --m 1 #多少个mapreduce跑,这里是一个mapreduce
或者使用下面的命令进行导入:
1 [root@master sqoop]# bin/sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table emp --m 1
开始将mysql的数据导入到sqoop的时候出现下面的错误,贴一下,希望可以帮到看到的人:
1 [root@master sqoop]# bin/sqoop import \ 2 > --connect jdbc:mysql://localhost:3306/test \ 3 > --username root \ 4 > --password 123456 \ 5 > --table emp \ 6 > --m 1 7 Warning: /home/hadoop/sqoop/../hbase does not exist! HBase imports will fail. 8 Please set $HBASE_HOME to the root of your HBase installation. 9 Warning: /home/hadoop/sqoop/../hcatalog does not exist! HCatalog jobs will fail. 10 Please set $HCAT_HOME to the root of your HCatalog installation. 11 Warning: /home/hadoop/sqoop/../accumulo does not exist! Accumulo imports will fail. 12 Please set $ACCUMULO_HOME to the root of your Accumulo installation. 13 Warning: /home/hadoop/sqoop/../zookeeper does not exist! Accumulo imports will fail. 14 Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 15 17/12/15 10:37:20 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6 16 17/12/15 10:37:20 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 17 17/12/15 10:37:21 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 18 17/12/15 10:37:21 INFO tool.CodeGenTool: Beginning code generation 19 17/12/15 10:37:24 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1 20 17/12/15 10:37:24 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1 21 17/12/15 10:37:24 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/hadoop/hadoop-2.4.1 22 Note: /tmp/sqoop-root/compile/2df9072831c26203712cd4da683c50d9/emp.java uses or overrides a deprecated API. 23 Note: Recompile with -Xlint:deprecation for details. 24 17/12/15 10:37:46 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/2df9072831c26203712cd4da683c50d9/emp.jar 25 17/12/15 10:37:46 WARN manager.MySQLManager: It looks like you are importing from mysql. 26 17/12/15 10:37:46 WARN manager.MySQLManager: This transfer can be faster! Use the --direct 27 17/12/15 10:37:46 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path. 28 17/12/15 10:37:46 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql) 29 17/12/15 10:37:46 INFO mapreduce.ImportJobBase: Beginning import of emp 30 17/12/15 10:37:48 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar 31 17/12/15 10:37:52 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps 32 17/12/15 10:37:54 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.3.129:8032 33 17/12/15 10:37:56 ERROR tool.ImportTool: Encountered IOException running import job: java.net.ConnectException: Call From master/192.168.3.129 to master:9000 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused 34 at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) 35 at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) 36 at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) 37 at java.lang.reflect.Constructor.newInstance(Constructor.java:526) 38 at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:783) 39 at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:730) 40 at org.apache.hadoop.ipc.Client.call(Client.java:1414) 41 at org.apache.hadoop.ipc.Client.call(Client.java:1363) 42 at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:206) 43 at com.sun.proxy.$Proxy14.getFileInfo(Unknown Source) 44 at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) 45 at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) 46 at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) 47 at java.lang.reflect.Method.invoke(Method.java:606) 48 at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:190) 49 at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:103) 50 at com.sun.proxy.$Proxy14.getFileInfo(Unknown Source) 51 at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getFileInfo(ClientNamenodeProtocolTranslatorPB.java:699) 52 at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:1762) 53 at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:1124) 54 at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:1120) 55 at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) 56 at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1120) 57 at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:1398) 58 at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:145) 59 at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:458) 60 at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:343) 61 at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1285) 62 at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1282) 63 at java.security.AccessController.doPrivileged(Native Method) 64 at javax.security.auth.Subject.doAs(Subject.java:415) 65 at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1556) 66 at org.apache.hadoop.mapreduce.Job.submit(Job.java:1282) 67 at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1303) 68 at org.apache.sqoop.mapreduce.ImportJobBase.doSubmitJob(ImportJobBase.java:196) 69 at org.apache.sqoop.mapreduce.ImportJobBase.runJob(ImportJobBase.java:169) 70 at org.apache.sqoop.mapreduce.ImportJobBase.runImport(ImportJobBase.java:266) 71 at org.apache.sqoop.manager.SqlManager.importTable(SqlManager.java:673) 72 at org.apache.sqoop.manager.MySQLManager.importTable(MySQLManager.java:118) 73 at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:497) 74 at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:605) 75 at org.apache.sqoop.Sqoop.run(Sqoop.java:143) 76 at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) 77 at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:179) 78 at org.apache.sqoop.Sqoop.runTool(Sqoop.java:218) 79 at org.apache.sqoop.Sqoop.runTool(Sqoop.java:227) 80 at org.apache.sqoop.Sqoop.main(Sqoop.java:236) 81 Caused by: java.net.ConnectException: Connection refused 82 at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method) 83 at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:739) 84 at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206) 85 at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:529) 86 at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:493) 87 at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:604) 88 at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:699) 89 at org.apache.hadoop.ipc.Client$Connection.access$2800(Client.java:367) 90 at org.apache.hadoop.ipc.Client.getConnection(Client.java:1462) 91 at org.apache.hadoop.ipc.Client.call(Client.java:1381) 92 ... 40 more 93 94 [root@master sqoop]# service iptables status 95 iptables: Firewall is not running. 96 [root@master sqoop]# cat /etc/hosts 97 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 98 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 99 100 192.168.3.129 master 101 192.168.3.130 slaver1 102 192.168.3.131 slaver2 103 192.168.3.132 slaver3 104 192.168.3.133 slaver4 105 192.168.3.134 slaver5 106 192.168.3.135 slaver6 107 192.168.3.136 slaver7 108 109 [root@master sqoop]# jps 110 2813 Jps 111 [root@master sqoop]# sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table emp --m 1 112 Warning: /home/hadoop/sqoop/../hbase does not exist! HBase imports will fail. 113 Please set $HBASE_HOME to the root of your HBase installation. 114 Warning: /home/hadoop/sqoop/../hcatalog does not exist! HCatalog jobs will fail. 115 Please set $HCAT_HOME to the root of your HCatalog installation. 116 Warning: /home/hadoop/sqoop/../accumulo does not exist! Accumulo imports will fail. 117 Please set $ACCUMULO_HOME to the root of your Accumulo installation. 118 Warning: /home/hadoop/sqoop/../zookeeper does not exist! Accumulo imports will fail. 119 Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 120 17/12/15 10:42:13 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6 121 17/12/15 10:42:13 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 122 17/12/15 10:42:13 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 123 17/12/15 10:42:13 INFO tool.CodeGenTool: Beginning code generation 124 17/12/15 10:42:14 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1 125 17/12/15 10:42:14 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1 126 17/12/15 10:42:14 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/hadoop/hadoop-2.4.1 127 Note: /tmp/sqoop-root/compile/3748127f0b101bfa0fd892963bea25dd/emp.java uses or overrides a deprecated API. 128 Note: Recompile with -Xlint:deprecation for details. 129 17/12/15 10:42:15 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/3748127f0b101bfa0fd892963bea25dd/emp.jar 130 17/12/15 10:42:15 WARN manager.MySQLManager: It looks like you are importing from mysql. 131 17/12/15 10:42:15 WARN manager.MySQLManager: This transfer can be faster! Use the --direct 132 17/12/15 10:42:15 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path. 133 17/12/15 10:42:15 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql) 134 17/12/15 10:42:15 INFO mapreduce.ImportJobBase: Beginning import of emp 135 17/12/15 10:42:15 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar 136 17/12/15 10:42:15 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps 137 17/12/15 10:42:15 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.3.129:8032 138 17/12/15 10:42:15 ERROR tool.ImportTool: Encountered IOException running import job: java.net.ConnectException: Call From master/192.168.3.129 to master:9000 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused 139 at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) 140 at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) 141 at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) 142 at java.lang.reflect.Constructor.newInstance(Constructor.java:526) 143 at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:783) 144 at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:730) 145 at org.apache.hadoop.ipc.Client.call(Client.java:1414) 146 at org.apache.hadoop.ipc.Client.call(Client.java:1363) 147 at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:206) 148 at com.sun.proxy.$Proxy14.getFileInfo(Unknown Source) 149 at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) 150 at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) 151 at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) 152 at java.lang.reflect.Method.invoke(Method.java:606) 153 at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:190) 154 at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:103) 155 at com.sun.proxy.$Proxy14.getFileInfo(Unknown Source) 156 at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getFileInfo(ClientNamenodeProtocolTranslatorPB.java:699) 157 at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:1762) 158 at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:1124) 159 at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:1120) 160 at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) 161 at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1120) 162 at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:1398) 163 at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:145) 164 at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:458) 165 at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:343) 166 at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1285) 167 at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1282) 168 at java.security.AccessController.doPrivileged(Native Method) 169 at javax.security.auth.Subject.doAs(Subject.java:415) 170 at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1556) 171 at org.apache.hadoop.mapreduce.Job.submit(Job.java:1282) 172 at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1303) 173 at org.apache.sqoop.mapreduce.ImportJobBase.doSubmitJob(ImportJobBase.java:196) 174 at org.apache.sqoop.mapreduce.ImportJobBase.runJob(ImportJobBase.java:169) 175 at org.apache.sqoop.mapreduce.ImportJobBase.runImport(ImportJobBase.java:266) 176 at org.apache.sqoop.manager.SqlManager.importTable(SqlManager.java:673) 177 at org.apache.sqoop.manager.MySQLManager.importTable(MySQLManager.java:118) 178 at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:497) 179 at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:605) 180 at org.apache.sqoop.Sqoop.run(Sqoop.java:143) 181 at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) 182 at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:179) 183 at org.apache.sqoop.Sqoop.runTool(Sqoop.java:218) 184 at org.apache.sqoop.Sqoop.runTool(Sqoop.java:227) 185 at org.apache.sqoop.Sqoop.main(Sqoop.java:236) 186 Caused by: java.net.ConnectException: Connection refused 187 at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method) 188 at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:739) 189 at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206) 190 at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:529) 191 at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:493) 192 at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:604) 193 at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:699) 194 at org.apache.hadoop.ipc.Client$Connection.access$2800(Client.java:367) 195 at org.apache.hadoop.ipc.Client.getConnection(Client.java:1462) 196 at org.apache.hadoop.ipc.Client.call(Client.java:1381) 197 ... 40 more 198 199 [root@master sqoop]#
出现上面错误的原因是因为你的集群没有开,start-dfs.sh和start-yarn.sh开启你的集群即可:
正常运行如下所示:
1 [root@master sqoop]# bin/sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table emp --m 1 2 Warning: /home/hadoop/sqoop/../hbase does not exist! HBase imports will fail. 3 Please set $HBASE_HOME to the root of your HBase installation. 4 Warning: /home/hadoop/sqoop/../hcatalog does not exist! HCatalog jobs will fail. 5 Please set $HCAT_HOME to the root of your HCatalog installation. 6 Warning: /home/hadoop/sqoop/../accumulo does not exist! Accumulo imports will fail. 7 Please set $ACCUMULO_HOME to the root of your Accumulo installation. 8 Warning: /home/hadoop/sqoop/../zookeeper does not exist! Accumulo imports will fail. 9 Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 10 17/12/15 10:49:33 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6 11 17/12/15 10:49:33 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 12 17/12/15 10:49:34 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 13 17/12/15 10:49:34 INFO tool.CodeGenTool: Beginning code generation 14 17/12/15 10:49:35 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1 15 17/12/15 10:49:35 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `emp` AS t LIMIT 1 16 17/12/15 10:49:35 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/hadoop/hadoop-2.4.1 17 Note: /tmp/sqoop-root/compile/60ee51250c5c6b5f5598392e068ce2d0/emp.java uses or overrides a deprecated API. 18 Note: Recompile with -Xlint:deprecation for details. 19 17/12/15 10:49:41 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/60ee51250c5c6b5f5598392e068ce2d0/emp.jar 20 17/12/15 10:49:41 WARN manager.MySQLManager: It looks like you are importing from mysql. 21 17/12/15 10:49:41 WARN manager.MySQLManager: This transfer can be faster! Use the --direct 22 17/12/15 10:49:41 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path. 23 17/12/15 10:49:41 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql) 24 17/12/15 10:49:41 INFO mapreduce.ImportJobBase: Beginning import of emp 25 17/12/15 10:49:42 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar 26 17/12/15 10:49:44 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps 27 17/12/15 10:49:44 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.3.129:8032 28 17/12/15 10:49:52 INFO db.DBInputFormat: Using read commited transaction isolation 29 17/12/15 10:49:53 INFO mapreduce.JobSubmitter: number of splits:1 30 17/12/15 10:49:53 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1513306156301_0001 31 17/12/15 10:49:55 INFO impl.YarnClientImpl: Submitted application application_1513306156301_0001 32 17/12/15 10:49:56 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1513306156301_0001/ 33 17/12/15 10:49:56 INFO mapreduce.Job: Running job: job_1513306156301_0001 34 17/12/15 10:50:42 INFO mapreduce.Job: Job job_1513306156301_0001 running in uber mode : false 35 17/12/15 10:50:42 INFO mapreduce.Job: map 0% reduce 0% 36 17/12/15 10:51:12 INFO mapreduce.Job: map 100% reduce 0% 37 17/12/15 10:51:13 INFO mapreduce.Job: Job job_1513306156301_0001 completed successfully 38 17/12/15 10:51:14 INFO mapreduce.Job: Counters: 30 39 File System Counters 40 FILE: Number of bytes read=0 41 FILE: Number of bytes written=110675 42 FILE: Number of read operations=0 43 FILE: Number of large read operations=0 44 FILE: Number of write operations=0 45 HDFS: Number of bytes read=87 46 HDFS: Number of bytes written=46 47 HDFS: Number of read operations=4 48 HDFS: Number of large read operations=0 49 HDFS: Number of write operations=2 50 Job Counters 51 Launched map tasks=1 52 Other local map tasks=1 53 Total time spent by all maps in occupied slots (ms)=25363 54 Total time spent by all reduces in occupied slots (ms)=0 55 Total time spent by all map tasks (ms)=25363 56 Total vcore-seconds taken by all map tasks=25363 57 Total megabyte-seconds taken by all map tasks=25971712 58 Map-Reduce Framework 59 Map input records=3 60 Map output records=3 61 Input split bytes=87 62 Spilled Records=0 63 Failed Shuffles=0 64 Merged Map outputs=0 65 GC time elapsed (ms)=151 66 CPU time spent (ms)=730 67 Physical memory (bytes) snapshot=49471488 68 Virtual memory (bytes) snapshot=365268992 69 Total committed heap usage (bytes)=11317248 70 File Input Format Counters 71 Bytes Read=0 72 File Output Format Counters 73 Bytes Written=46 74 17/12/15 10:51:14 INFO mapreduce.ImportJobBase: Transferred 46 bytes in 90.4093 seconds (0.5088 bytes/sec) 75 17/12/15 10:51:14 INFO mapreduce.ImportJobBase: Retrieved 3 records. 76 [root@master sqoop]#
为了验证在HDFS导入的数据,请使用以下命令查看导入的数据,如下所示:
总之,遇到很多问题,当我我没有指定导入到的目录的时候,我去hdfs查看的时候竟然没有我导入的mysql数据表。郁闷。先记录一下。如果查看成功的话,数据表的数据和字段之间用逗号(,)表示。
4:导入关系表到HIVE:
1 bin/sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table emp --hive-import --m 1
5:导入到HDFS指定目录:
在导入表数据到HDFS使用Sqoop导入工具,我们可以指定目标目录。
以下是指定目标目录选项的Sqoop导入命令的语法。
1 --target-dir <new or exist directory in HDFS>
1 下面的命令是用来导入emp表数据到'/sqoop'目录。 2 bin/sqoop import \ 3 --connect jdbc:mysql://localhost:3306/test \ 4 --username root \ 5 --password 123456 \ 6 --target-dir /sqoop \ 7 --table emp \ 8 --m 1 9 10 11 [root@master sqoop]# bin/sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --target-dir /sqoop --table emp --m 1
如果你指定的目录存在的话,将会报如下的错误:
1 17/12/15 11:13:52 ERROR tool.ImportTool: Encountered IOException running import job: org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://master:9000/wordcount already exists 2 at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:146) 3 at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:458) 4 at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:343) 5 at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1285) 6 at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1282) 7 at java.security.AccessController.doPrivileged(Native Method) 8 at javax.security.auth.Subject.doAs(Subject.java:415) 9 at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1556) 10 at org.apache.hadoop.mapreduce.Job.submit(Job.java:1282) 11 at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1303) 12 at org.apache.sqoop.mapreduce.ImportJobBase.doSubmitJob(ImportJobBase.java:196) 13 at org.apache.sqoop.mapreduce.ImportJobBase.runJob(ImportJobBase.java:169) 14 at org.apache.sqoop.mapreduce.ImportJobBase.runImport(ImportJobBase.java:266) 15 at org.apache.sqoop.manager.SqlManager.importTable(SqlManager.java:673) 16 at org.apache.sqoop.manager.MySQLManager.importTable(MySQLManager.java:118) 17 at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:497) 18 at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:605) 19 at org.apache.sqoop.Sqoop.run(Sqoop.java:143) 20 at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) 21 at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:179) 22 at org.apache.sqoop.Sqoop.runTool(Sqoop.java:218) 23 at org.apache.sqoop.Sqoop.runTool(Sqoop.java:227) 24 at org.apache.sqoop.Sqoop.main(Sqoop.java:236)
导入到指定的目录,如果成功的话,会显示出你的mysql数据表的数据,字段之间以逗号分隔。
使用如下的命令是用来验证 /sqoop 目录中 emp数据表导入的数据形式。它会用逗号,分隔emp数据表的数据和字段。
1 [root@master sqoop]# hadoop fs -cat /sqoop/part-m-00000 2 1,zhangsan,22,yi 3 2,lisi,23,er 4 3,wangwu,24,san 5 [root@master sqoop]#
6:导入表数据子集:
我们可以导入表的使用Sqoop导入工具,"where"子句的一个子集。它执行在各自的数据库服务器相应的SQL查询,并将结果存储在HDFS的目标目录。
where子句的语法如下。
1 --where <condition>
1 #下面的命令用来导入emp表数据的子集。子集查询检索员工ID和地址,居住城市为:city; 2 #方式一 3 bin/sqoop import \ 4 --connect jdbc:mysql://localhost:3306/test \ 5 --username root \ 6 --password 123456 \ 7 --where "city ='zhengzhou'" \ 8 --target-dir /sqoop02 \ 9 --table emp \ 10 --m 1 11 12 #方式二 13 [root@master sqoop]# bin/sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --where "city ='zhengzhou'" --target-dir /sqoop02 --table emp --m 1
7:sqoop的按需导入:
可以如上面演示使用命令用来验证数据从emp数据表导入/sqoop03 目录
它用逗号'\t'分隔 emp数据表数据和字段。
1 #sqoop按需导入 2 #方式一 3 bin/sqoop import \ 4 --connect jdbc:mysql://localhost:3306/test \ 5 --username root \ #mysql的账号 6 --password 123456 \ #mysql的密码 7 --target-dir /sqoop03 \ #指定存放的目录 8 --query 'select id,name,age,dept from emp WHERE id>0 and $CONDITIONS' \ #灵活的mysql语句,且必须加and $CONDITIONS' 9 --split-by id \ #按照那个字段做切片,id做切片 10 --fields-terminated-by '\t' \ #导入到我的文件系统中为'\t',默认为逗号。 11 --m 1 12 13 #方式二 14 [root@master sqoop]# bin/sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --target-dir /sqoop03 --query 'select id,name,age,dept from emp WHERE id>0 and $CONDITIONS' --split-by id --fields-terminated-by '\t' --m 1
7:sqoop的增量导入,增量导入是仅导入新添加的表中的行的技术:
它需要添加‘incremental’, ‘check-column’, 和 ‘last-value’选项来执行增量导入。
下面的语法用于Sqoop导入命令增量选项。
1 --incremental <mode> 2 --check-column <column name> 3 --last value <last check column value>
1 下面的命令用于在EMP表执行增量导入。 2 3 #方式一 4 bin/sqoop import \ 5 --connect jdbc:mysql://localhost:3306/test \ 6 --username root \ 7 --password 123456 \ 8 --table emp \ 9 --m 1 \ 10 --incremental append \ #追加导入 11 --check-column id \ #根据id字段来判断从哪里开始导入 12 --last-value 6 #根据id字段,从7开始导入 13 14 15 #方式二 16 [root@master sqoop]# bin/sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --m 1 --incremental append --check-column id --last-value 6
8:Sqoop的数据导出:
将数据从HDFS导出到RDBMS数据库,导出前,目标表必须存在于目标数据库中。默认操作是从将文件中的数据使用INSERT语句插入到表中,更新模式下,是生成UPDATE语句更新表数据;
1 以下是export命令语法。 2 $ sqoop export (generic-args) (export-args)
具体操作如下所示:
首先,数据是在HDFS 中"/sqoop"目录的part-m-00000文件中。
第一步:首先需要手动创建mysql中的目标表:
1 [root@master hadoop]# mysql -uroot -p123456 2 3 mysql> show databases; 4 5 mysql> use test; 6 7 mysql> CREATE TABLE `emp` ( 8 -> `id` int(11) NOT NULL AUTO_INCREMENT, 9 -> `name` varchar(255) DEFAULT NULL, 10 -> `age` int(11) DEFAULT NULL, 11 -> `dept` varchar(255) DEFAULT NULL, 12 -> PRIMARY KEY (`id`) 13 -> ) ENGINE=MyISAM AUTO_INCREMENT=4 DEFAULT CHARSET=latin1;
如果不事先创建好数据表会报如下错误:
1 17/12/15 13:56:21 ERROR manager.SqlManager: Error executing statement: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Table 'test.emp' doesn't exist 2 com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Table 'test.emp' doesn't exist 3 at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) 4 at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) 5 at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) 6 at java.lang.reflect.Constructor.newInstance(Constructor.java:526) 7 at com.mysql.jdbc.Util.handleNewInstance(Util.java:411) 8 at com.mysql.jdbc.Util.getInstance(Util.java:386) 9 at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1054) 10 at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:4237) 11 at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:4169) 12 at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:2617) 13 at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2778) 14 at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2825) 15 at com.mysql.jdbc.PreparedStatement.executeInternal(PreparedStatement.java:2156) 16 at com.mysql.jdbc.PreparedStatement.executeQuery(PreparedStatement.java:2313) 17 at org.apache.sqoop.manager.SqlManager.execute(SqlManager.java:758) 18 at org.apache.sqoop.manager.SqlManager.execute(SqlManager.java:767) 19 at org.apache.sqoop.manager.SqlManager.getColumnInfoForRawQuery(SqlManager.java:270) 20 at org.apache.sqoop.manager.SqlManager.getColumnTypesForRawQuery(SqlManager.java:241) 21 at org.apache.sqoop.manager.SqlManager.getColumnTypes(SqlManager.java:227) 22 at org.apache.sqoop.manager.ConnManager.getColumnTypes(ConnManager.java:295) 23 at org.apache.sqoop.orm.ClassWriter.getColumnTypes(ClassWriter.java:1833) 24 at org.apache.sqoop.orm.ClassWriter.generate(ClassWriter.java:1645) 25 at org.apache.sqoop.tool.CodeGenTool.generateORM(CodeGenTool.java:107) 26 at org.apache.sqoop.tool.ExportTool.exportTable(ExportTool.java:64) 27 at org.apache.sqoop.tool.ExportTool.run(ExportTool.java:100) 28 at org.apache.sqoop.Sqoop.run(Sqoop.java:143) 29 at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) 30 at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:179) 31 at org.apache.sqoop.Sqoop.runTool(Sqoop.java:218) 32 at org.apache.sqoop.Sqoop.runTool(Sqoop.java:227) 33 at org.apache.sqoop.Sqoop.main(Sqoop.java:236)
第二步:然后执行导出命令(如果localhost不好使,可以换成ip试一下):
1 #方式一 2 bin/sqoop export \ 3 --connect jdbc:mysql://192.168.3.129:3306/test \ 4 --username root \ 5 --password 123456 \ 6 --table emp \ #导入的数据表 7 --export-dir /sqoop/ #导出的目录 8 9 #方式二 10 bin/sqoop export --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table emp --export-dir /sqoop
第三步:验证表mysql命令行(或者使用图形化工具查看是否有数据导入):
mysql>select * from emp;
如果给定的数据存储成功,那么可以找到符合的数据。
待续......

