
- 1Unity打包窗口化放大、缩小、拖拽功能、无边框设置 C#_unity 无边框窗口化
- 2图的遍历bfs dfs模板及其解决二叉树层次遍历_dfs算法适合求解二叉树层序遍历,图遍历,最短路径,组合问题
- 3昇思25天学习打卡营第二天|张量 Tensor
- 4八大排序----快速排序_以数组[5,2,9,4,7,8,6,3,0,1]为例讲解下快速排序每一步是如何进行排序的以及如何
- 5免费GPU汇总及选购
- 6【最新鸿蒙应用开发】——ArkWeb1——arkts加载h5页面_arkweb onjspromat
- 7Java微服务面试题整理_初级开发会问微服务哪些问题
- 8Ubuntu环境的Git安装与使用_ubuntu安装git
- 9Libevent库笔记(一)下载和编译,测试demo_libevent-2.1.11-stable.tar.gz
- 10python令牌桶_python 令牌桶
Python基础知识点拾遗---文件IO(os、filecmp、shutil库)、sys库、序列化(pickle)、类
赞
踩
文件IO
open(params) —— 用于打开文件及类文件数据或设备
params:
- file —— 被读取的文件
- buffering —— 要读取的
- encoding ——
- errors ——
- newline ——
- closefd ——
- opener ——
windows —— 默认编码类型 cp936(GBK)
linux —— 默认编码类型 UTF-8
换行符:
windows —— CR LF (ASCII —> 13 10)

linux/unix —— LF(ASCII —>10)

在将一个文本从windows传输到linux(反之亦然)时,要注意先转换编码方式,再转换换行的方式
文本
1)、基本函数 open(name[.mode[.buffering]])
buffering — 控制文件缓冲,即是否将数据临时保存到内存中。
buffering=0 — 文件无缓冲(不在内存中操作),直接将数据存放到硬盘中
buffering=1 — 将文本中所有数据缓冲到内存中,并等待调用 .close() 或者 .flush()方法时才将数据写入硬盘。(若不调用此方法,数据将不保存至硬盘中)
buffer=-1 — 会将数据缓冲到内存中,但仅使用默认的缓冲区大小
buffer=20 — 值大于1时,此值即代表缓冲大小,单位字节
2)、主要方法
① .read([size]) — 读取size个字节的容读,返回类型为string。若size为空则读取所有文本内容
② .readline() — 读取一行数据,使用此方法注意文本游标所在位置,返回类型为string
③ .readlines() — 读取所有数据,返回数据类型为list,每行内容为一个元素(string),所有行组成返回的list
④ .flush() — 将内存中的数据立即写入到硬盘中,此时即使后面发生异常或者未调用 .close()方法,调用.flush()以上的方法均可以正常保存
目录
1)、基本模块:
os
os.getcwd() — 获取当前python脚本的工作目录,返回 string
os.chdir(路径) — 更改当前脚本的所在环境为参数“路径”
os.listdir([路径]) — 列出参数“路径”下的所有文件及目录,若"路径"为空则列出当前脚本所在路径下的所有文件及目录,返回 list
os.name()
os.rename(old, new) — 重命名文件或者目录
os.remove([文件]) — 删除文件,不可删除目录(抛出异常win error5 权限异常)
os.removedirs([目录路径]) — 删除目录,不可删除非空目录(包括目录中包含空的子目录的情况),即不会递归删除空目录。遇到非空目录或不存在目录则抛出异常
os.path.isfile(文件路径) — 判断给出的“文件路径”是否为文件
os.path.isdir(目录路径) — 判断给出的“目录路径”是否为目录
os.path.isabs(路径) — 判断给出的“路径”是否为绝对路径
os.path.exists(路径) — 判断给出的“路径”是否存在
os.path.split(路径) — 将路径分割为最后一级和前面所有级两个部分的 二元素元组
os.path.splitext(路径) — 将路径按最后一级文件(目录也不报错)的扩展名分为 二元素元组
os.path.dirname(路径) — 直接返回路径除最后一级(文件/目录皆可)外的路径
os.path.basename(路径) — 直接返回路径最后一级(文件/目录皆可)的名称,有扩展名则包含扩展名
os.mkdir(路径) — 创建目录,若父级目录不存在或要创建的目录已存在则抛出异常
os.makedirs(路径) — 递归创建多级目录,若目标目录已存在则抛出异常
os.stat(路径) — 查看目标路径(文件或目录)的属性,包括size、uid、gid、atime、btime、ctime等信息
os.chmod(path, mode) — 更改文件/目录的权限
os.walk(top[, topdown=True[, οnerrοr=None[, followlinks=False]]]) — 对某文件夹及其子目录进行递归访问,类似于ArcGIS模型构建器的遍历目录(勾选递归的情况)。此功能仅为遍历目录,要配合其他功能性模块一起使用,如搜索某个文件或者文件夹、将其中的某类文件批量复制、移动、删除、重命名等操作。
- top — 要递归遍历的最顶级目录
- topdown — True/False 优先遍历top目录/优先遍历top目录下每个目录的子目录
- onerror — 当程序抛出异常时要执行的区域,callable对象
- followlinks — 通过链接文件访问到链接文件所指向目标目录
os.system(command) — 控制启动系统的某些应用程序
获取文件的创建、修改及最近访问时间
文件创建时间:os.path.getctime(path)
文件最近一次修改时间:os.path.getmtime(path)
文件最近访问时间:os.path.getatime(path)
获取当前文件的大小
os.path.getsize()
获取当前的登录用户名称
os.getlogin()
获取当前的cpu核数
os.cpu_count()
调用操作系统底层的random生成器
os.urandom(n) —— n为n个字节长度
更不容易被破解
shutil
shutil.copytree(“olddir”, “newdir”) — 将"olddir"中的所有文件及目录复制到“newdir”中,"olddir"与"newdir"都只能是目录
shutil.copyfile(“oldfile”, “newfile”) — 将"oldfile"复制为 “newfile”,且"oldfile", "newfile"都只能是文件
shutil.copy(“oldfile”, “newfile or dir”) — 将"oldfile"复制为"newfile"或者复制到"dir"目录下,且"oldfile"只能是文件, "newfile or dir"即可以是文件也可以是目录
shutil.move(“oldposition”, “newposition”) —
将"oldposition"移动到 “newposition”,且"oldposition"既可以是文件也可以是目录 "newposition"只能是目录
删除目录
os.rmdir(“dir”) — 只能删除空目录
shutil.rmtree(“dir”) — 可以删除空及非空目录
序列化及反序列化
序列化:将内存中的内容存储到硬盘中或者通过网络传输到别的机器上
反序列化:将硬盘或其他形式存储的数据读入到内存中
注:python运行过程中的所有变量均存储在内存中,若有长时间运行的脚本 需要在固定时间或某些事情触发的时候将内存中的内容固定下来,此过程即序列化
应用场景:如 长时间爬虫、系统监控
序列化
python2中的序列化模块主要有俩:cPickle、pickle,前者由C编写 效率远高于后者,但后者是python标准库的成员之一
python3中的序列化模块即cPickle重命名为pickle
类似于xrange()和range()
pickle作用:将python变量转换为二进制字节流的形式,再人为进行存储
pickle的使用
- pickle.dumps(变量) — 将python内容序列化
- pickle.dump(变量,要存储的目标文件) — 将python的内容序列化的同时写入文件(扩展名自定义)
- pickle.loads(将二进制文件读为str) — 将二进制文件读取为str后再反序列化
- pickle.load(二进制文件) — 将二进制文件反序列化
pickle序列化之后的值如下:

import pickle
# 序列化
dict1 = {"a":1, "b":2, "c":3}
list1 = [1,2,34,5,6]
str1 = "test"
def test():
print("this is a test function")
print(pickle.dumps(dict1))
print(pickle.dumps(list1))
print(pickle.dumps(str1))
print(pickle.dumps(test))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
序列化的完整过程
import pickle # 序列化 import pickle # 序列化 dict1 = {"a":1, "b":2, "c":3} list1 = [1,2,34,5,6] str1 = "test" def test(): print("this is a test function") class Person: def __init__(self, name, age, grade): self.name = name self.age = age self.grade = grade def getName(self): print(self.name) return self.name def getAge(self): print(self.age) return self.age def getGrade(self): print(self.grade) return self.grade person1 = Person("小明", 18, "一年级") picklist = [dict1, list1, str1, test, test(), Person, person1, person1.getAge()] pkl = pickle.dumps(picklist) with open("E:/1/pickle.pkl", "wb") as f: f.write(pkl)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
反序列化
使用pickle.load()将二进制字节流反序列化为python内容
import pickle
# 反序列化
with open("E:/1/pickle.pkl", "rb") as f:
unpkl = pickle.load(f)
print(unpkl)
- 1
- 2
- 3
- 4
- 5

小结
pickle可以将包括 数值、字符串、布尔值、列表、元组、字典、函数、类等内容转化为二进制字节流的形式存储到目标存储器中
注意:
- 存储文件的扩展名可以自定义
- 无论是写入或读取存储文件均需要以二进制的形式进行操作
- pickle.dumps()和dump() 的区别
- pickle.loads()和pickle.load()的区别,load操作文件,loads操作str
with open("E:/1/pickle.pkl", "wb") as f:
pkl = pickle.dump(picklist, f)
- 1
- 2
pkl = pickle.dumps(picklist)
with open("E:/1/pickle.pkl", "wb") as f:
f.write(pkl)
- 1
- 2
- 3
文件比较库 —— filecmp
单文件比较 —— 函数式
filecmp.cmp(f1, f2, shallow=True) —— 比较f1和f2两个文件
若shallow为True则比较os.stat(),否则比较文件的内容
os.stat是操作系统记录的文件信息,通过比较这两个信息来判断文件是否相同。若仅比较文件内容,则使用shallow=False
多文件比较 —— 函数式
filecmp.cmpfiles(dir1, dir2, common, shallow=True) —— 比较dir1和dir2下的多个文件,common为列表类型
目录比较 —— 对象式
dcmp = filecmp.dircmp(dir1, dir2)
dcmp的属性
| 属性 | 说明 |
|---|---|
| left | 目录dir1 |
| right | 目录dir2 |
| left_list | 目录dir1和其子目录列表 |
| right_list | 目录dir2和其子目录列表 |
sys库
当前解释器所在的绝对路径
sys.executable() —— 返回当前python解释器所在的绝对路径
当前脚本搜索库的环境列表
sys.path()
控制是否生成.pyc的字节码
sys.dont_write_bytecode —— 为True则不生成
获取并设置系统递归最大深度
获取:sys.getrecursionlimit()
设置:sys.setrecursionlimit(n)
获取当前默认的字符串编码类型
sys.getdefaultencoding()
获取任意类型对象的字节长度(python一切皆对象)
sys.getsizeof(object)
类
类的构成:
1、实例化(_ _ init _ _,构造实例):实例对象(Instance Object)、实例属性(Instance Attribute)
2、引用(_ _ del _ _,删除引用):类对象引用(Object Reference)
3、类自身:类对象(Class Object)、类属性(Class Attritute)
4、方法:类方法(Class Method, @classmethod)、实例方法(Instance Method, def - selft)、自由方法(Namespace method, def)、静态方法(Static Method, @staticmethod)、保留方法(Reserved Method, _ _ XX _ _)
类的五种方法

1、实例方法
特征:定义时,第一个参数传入"self"(是__init__传入的第一个参数,也可以叫别的名字。不过最好叫self)
该方法是该类的所有实例都具有的方法
调用:实例对象调用
可修改:实例属性和方法、类属性和方法
2、类方法
特征:定义时,要在方法前加一个装饰器"@classmethod",第一个参数传入"cls"(也可以叫别的名字,不过最好叫cls)
该方法是该类的所有实例都具有的方法,类对象也有
调用:实例对象调用、类对象调用
可修改:类属性、其他类方法
注意:一定要加装饰器,并且传入的第一个参数是cls
3、自由方法
特征:定义在类命名空间中的一个普通函数,第一个参数即不传self,也不传cls。仅仅是定义在类中的一个函数,类的实例对象无法使用类中的自由方法。
调用:自由方法仅可通过 “类名.方法名” 的形式调用
可修改:类属性、其他类方法
4、静态方法
特征:在自由方法上添加了一个装饰器 “@staticmethod” ,从而使该方法可以同时被类和实例使用
调用:实例对象调用、类对象调用
可修改:类属性、其他类方法
5、保留方法
特征:双下划线开头及结尾的方法,一般是python内部保留,与某些方法有对应的联系,如 _ _ len _ 对应len(),即在class内部定义 _ len _ _ 则可在类外使用 len() 的形式调用。 在类内部编写 _ _ len _ _的过程即重载,对python内部已经定义好的方法,进行重定义以在对该类实例使用时,其进行的操作与默认定义好的有所不同
类的公开、私有方法和属性
私有类属性
特点:私有类属性是类属性名以双下划线开头的属性,此类属性仅可在类的内部使用,类外或者子类都不可访问此属性
用处:对某些属性进行保护,仅可通过某个方法去修改其值
如:
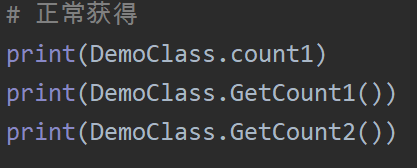
class DemoClass: count1 = 0 __count2 = 0 def __init__(self, name, age): self.name = name self.age = age DemoClass.count1 += 1 DemoClass.__count2 += 1 @classmethod def GetCount1(cls): return DemoClass.count1 @classmethod def GetCount2(cls): return DemoClass.__count2 dc1 = DemoClass("小王", 18) dc2 = DemoClass("小李", 20) # 正常获得 print(DemoClass.count1) # 抛出异常 print(DemoClass.__count2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24

通过方法去获得

注意:python并不明确支持私有属性,实例的私有属性可以通过 “实例. _ 类名 _ _私有属性名” 的形式去获取
私有类方法
特征:双下划线开头的方法名,常用于实现类内部的某些功能,并不对外提供接口
类的保留属性(语法糖)
常用:
| 方法 | 用途 |
|---|---|
| className._ _ qualname _ _ | 获取该类全命名空间类名,如:定义在某个函数(f)内部,则返回 f.className |
| className._ _ name _ _ | 返回该类的类名 |
| className._ _ bases _ _ | 返回该类的基类 |
| className._ _ dict _ _ | 返回类成员信息的字典,key是属性名和方法名,value是地址 |
| instanceName._ _ dict _ _ | 返回实例对象属性信息的字典,key为属性名称, value为值 |
| className._ _ class _ _ | 返回该类对应的类信息,即type信息 |
| className._ _ doc _ _ | 返回该类的类描述,不可继承 |
| className._ _ module _ _ | 类所在模块的名称 |
如:
def test(): class DemoClass: count1 = 0 __count2 = 0 def __init__(self, name, age): self.name = name self.age = age DemoClass.count1 += 1 DemoClass.__count2 += 1 @classmethod def GetCount1(cls): return DemoClass.count1 @classmethod def GetCount2(cls): return DemoClass.__count2 dc1 = DemoClass("小王", 18) dc2 = DemoClass("小李", 20) print("__name__: ", DemoClass.__name__) print("__qualname__: ", DemoClass.__qualname__) print("__bases__: ", DemoClass.__bases__) print("DemoClass __dict__: ", DemoClass.__dict__) print("dc1 __dict__: ", dc1.__dict__) print("__class__: ", DemoClass.__class__) print("__doc__: ", DemoClass.__doc__) print("__module__: ", DemoClass.__module__) test()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32

类方法重载
完全重载
使用相同的变量名,重新编写方法即可
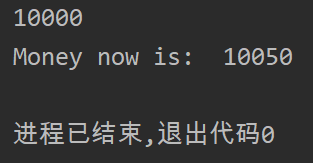
class GrandFather: "this is grand father" money = 10000 def __init__(self, name, age): self.name = name self.age = age @classmethod def showMoney(cls): print(GrandFather.money) return GrandFather.money @classmethod def makeMoney(cls): GrandFather.money += 100 print("Money now is: ", GrandFather.money) return GrandFather.money class Father(GrandFather): "this is father" money = GrandFather.money def __init__(self, name, age): self.name = name self.age = age @classmethod def makeMoney(cls): Father.money += 50 print("Money now is: ", Father.money) father = Father("小李", 30) print(father.money) father.makeMoney()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
增量重载
通过借助 “spuer().基类方法” 获取基类的返回值,再在此值上进行功能的添加
class GrandFather: "this is grand father" money = 10000 def __init__(self, name, age): self.name = name self.age = age @classmethod def showMoney(cls): print(GrandFather.money) return GrandFather.money @classmethod def makeMoney(cls): GrandFather.money += 100 print("Money now is: ", GrandFather.money) return GrandFather.money class Father(GrandFather): "this is father" money = GrandFather.money def __init__(self, name, age): self.name = name self.age = age @classmethod def makeMoney(cls): Father.money = super().makeMoney() + 1000 print("Money now is: ", Father.money) father = Father("小李", 30) print(father.money) father.makeMoney()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37

命名空间
命名空间可以简化理解为作用域,在python中有两个保留字 global 和 nonlocal 分别代表 “全局” 和 “上一级作用域” , 若在上一级作用域中未找到相关变量则继续往上一级寻找。
装饰器
装饰器的一般含义,在不改变原方法的前提下,为原方法扩充某些功能。如不扩充运行时间计数、赋值判断等。
赋值判断属性装饰器
class DemoClass: def __init__(self, name): self.name = name # 将age作为实例对象的属性 @property def age(self): return self._age # 设置age时,通过下面的方法对值进行加工 @age.setter def age(self, value): if value < 0 or value > 100: value = 30 self._age = value dc1 = DemoClass("老王") dc1.age = -100 print(dc1.age)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
属性装饰器一般用法:
1、对某个方法添加装饰器 —— @property
2、设立同名的属性赋值判断方法,并添加为属性装饰器的赋值入口 —— @属性装饰器名.setter
自定义异常类型
使某一个类继承自Exception类,即可以设置自定义的异常类
如:
class TooHandsome(Exception):
print("TooHandsome init")
while True:
score = int(input("请输入我的颜值有多少分(满分10分): "))
if score >= 50:
raise TooHandsome()
else:
print("答错了,请重新输入")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9


