
- 1scrapy框架-反爬虫与绕过方法+setting动态配置
- 2浅谈单元测试和JUnit4使用_还有人在用 junit4吗
- 3开源新纪元:ChatTTS——引领对话式文本转语音的新潮流_chattts特点
- 4pnpm安装成功但不能用_pnpm 安装没效果
- 5【Mysql】utf8与utf8mb4区别,utf8mb4_bin、utf8mb4_general_ci、utf8mb4_unicode_ci区别
- 6python2.7是什么_python2.7是什么
- 7PG302 QDMA Subsystem for PCI Express v4.0 Ch.2 Overview
- 8AIGC总体相似度是什么意思_aigc相似度
- 9记录docker-compose遇到的坑_dockercompose keyerror: 'containerconfig
- 10unity入门教程(非常详细)从零基础入门到精通,看完这一篇就够了_unity完全自学教程
reshape功能介绍_scikit-learn的5大新功能
赞
踩

CDA数据分析师 出品
Python的主要功能机器学习库的最新版本包括许多新功能和错误修复。你可以从Scikit-learn官方0.22 发行要点中找到有关这些更改的完整说明。
通过pip完成安装更新:
pip install --upgrade scikit-learn
或conda:
conda install scikit-learn
最新的Scikit-learn中有5个新功能值得你注意。
1.新的绘图API
新的绘图API可用,无需重新计算即可正常工作。支持的图包括一些相关图,混淆矩阵和ROC曲线。下面是Scikit-learn用户指南中的示例,对API进行了演示:
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import plot_roc_curve
from sklearn.datasets import load_wine
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
svc = SVC(random_state=42)
svc.fit(X_train, y_train)
svc_disp = plot_roc_curve(svc, X_test, y_test)
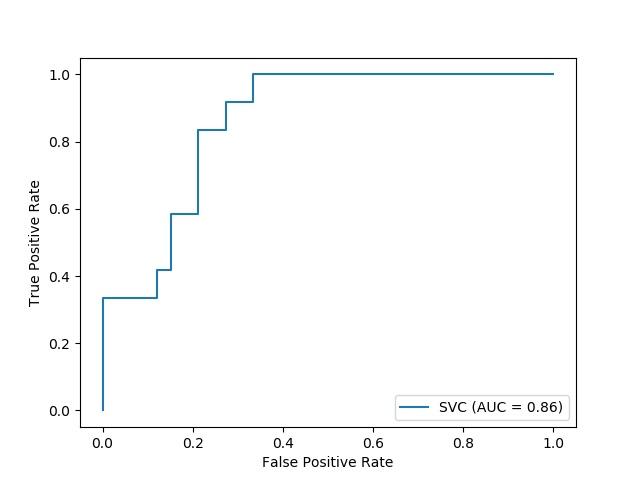
请注意,绘制是通过最后一行代码完成的。
2.堆叠概括
Scikit-learn已经集成了用于减少估计量偏差的整体学习技术。StackingClassifier和StackingRegressor是启用估算器堆叠的模块,并使用final_estimator这些堆叠的估算器预测作为其输入。请参阅用户指南中的示例,使用以下定义为的回归估计量estimators和梯度增强回归最终估计量:
from sklearn.linear_model import RidgeCV, LassoCV
from sklearn.svm import SVR
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.ensemble import StackingRegressor
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
estimators = [('ridge', RidgeCV()),
('lasso', LassoCV(random_state=42)),
('svr', SVR(C=1, gamma=1e-6))]
reg = StackingRegressor(
estimators=estimators,
final_estimator=GradientBoostingRegressor(random_state=42))
X, y = load_boston(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
reg.fit(X_train, y_train)
StackingRegressor(...)

3.任何估计器特征的重要性
现在,任何适合的Scikit-learn估计器都可以使用基于置换的重要性特征。从用户指南中描述如何计算功能的排列重要性:
特征排列重要性计算方式如下:首先,在X定义的数据集上评估通过评分定义的基线度量。接着,对验证集中的要素列进行置换,并再次评估度量。排列重要性定义为基线度量和来自特征列度量之间的差异。
发行说明中的完整示例:
from sklearn.ensemble import RandomForestClassifier
from sklearn.inspection import permutation_importance
X, y = make_classification(random_state=0, n_features=5, n_informative=3)
rf = RandomForestClassifier(random_state=0).fit(X, y)
result = permutation_importance(rf, X, y, n_repeats=10, random_state=0, n_jobs=-1)
fig, ax = plt.subplots()
sorted_idx = result.importances_mean.argsort()
ax.boxplot(result.importances[sorted_idx].T, vert=False, labels=range(X.shape[1]))
ax.set_title("Permutation Importance of each feature")
ax.set_ylabel("Features")
fig.tight_layout()
plt.show()
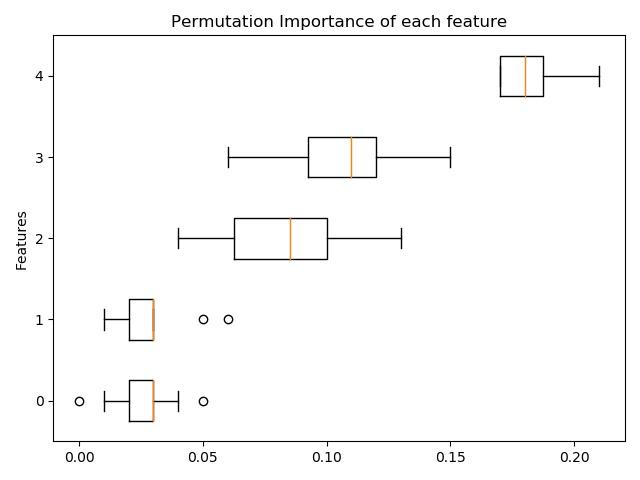
4.梯度提升缺失价值支持
梯度提升分类器和回归器现在都已经具备了处理缺失值的能力,从而消除了手动插补的需要。以下是遗漏的方式:
在训练过程中,树木种植者会根据潜在的收益,在每个分割点上了解缺失值的样本应归子级左还是右子级。进行预测时,因此将具有缺失值的样本分配给左或右的子级。如果在训练过程中没有遇到给定特征的缺失值,则将具有缺失值的样本映射到样本最多的那一方。
以下示例演示:
from sklearn.experimental import enable_hist_gradient_boosting
# noqa
from sklearn.ensemble import HistGradientBoostingClassifier
import numpy as np
X = np.array([0, 1, 2, np.nan]).reshape(-1, 1)
y = [0, 0, 1, 1]
gbdt = HistGradientBoostingClassifier(min_samples_leaf=1).fit(X, y)
print(gbdt.predict(X))
[0 0 1 1]
5.基于KNN的缺失值估算
现在,梯度增强本身就支持缺失值插补,但可以使用K近邻插值器在任何数据集上执行显式插补。只要在训练集中,n个最近邻居的平均值就推算出每个缺失值,只要两个样本都不缺失的特征就近了。欧式距离是使用的默认距离度量。
一个例子:
import numpy as np
from sklearn.impute import KNNImputer
X = [[1, 2, np.nan], [3, 4, 3], [np.nan, 6, 5], [8, 8, 7]]
imputer = KNNImputer(n_neighbors=2)
print(imputer.fit_transform(X))
[[1,2,4]
[3,4,3]
[5.5 ,6,5]
[8,8,7]]
最新版本的Scikit-learn中有更多功能,这里就不做过多介绍了。你可以去官网获取更多的信息!


