
- 122、基于51单片机电压电流功率系统设计(程序+原理图+PCB图+Proteus仿真+答辩技巧+开题报告+参考论文+元器件清单等)_基于51单片机的电压电流的系统设计
- 2centos6 & kylin3.2 安装 Chrome浏览器_kylin chrome
- 3vue.js word文档解析_你知道吗?原来普通的Word文档里的表格也能用Power Query直接读??!!!...
- 4RabbitMQ学习笔记(六)——优化RabbitMQ集群_rabbitmq 集群状态api
- 5原创文章汇总(职场经验分享、自学教程、面试真题解析、技术专题深度解析)
- 6大模型应用之路:从提示词到通用人工智能(AGI)_如何写出有效的prompt提示词
- 7常见黑客渗透测试工具
- 8BGP —— 软收敛_bgp 收敛
- 9oracle集合类型详解_oracle 集合类型
- 10nginx安装及使用(学习笔记)_nginx安装成功
PG302 QDMA Subsystem for PCI Express v4.0 Ch.2 Overview
赞
踩
Ch.2 Overview
Queue-based Direct Memory Access (QDMA) 基于队列的直接存储器访问子系统是基于 DMA引擎的 PCI Express® (PCIe®) ,此DMA引擎专为满足高带宽和高包计数数据传输需求而优化。QDMA 由 UltraScale+™ Integrated Block for PCI Express 以及广泛的 DMA 和 Bridge 基础架构组成,可实现卓越的性能和灵活性。
QDMA Subsystem for PCIe 提供了广泛的设置和使用选项,大部分设置和选项均可按队列来选择,例如存储器映射DMA(memory-mapped DMA) 或串流 DMA(stream DMA)、中断模式和轮询。该子系统提供了诸多选项,用于通过用户逻辑来自定义描述符和 DMA,以提供复杂的流量(traffic)管理功能。
QDMA 引擎可凭借使用 QDMA 进行数据传输的主要机制来对主机操作系统所提供的指令(描述符)进行操作。QDMA 可使用描述符在主机到卡 (H2C) 方向或卡到主机 (C2H) 方向进行数据移动。您可基于逐个队列选择 DMA 流量是进入 AXI4 存储器映射 (MM) 接口还是进入 AXI4-Stream 接口。此外,QDMA 可以选择实现 AXI4 MM 主端口或实现AXI4 MM 从端口,从而允许 PCIe traffic 完全绕过 DMA 引擎。
QDMA 与其它 DMA 产品的主要区别在于队列的概念。队列的概念源自高性能计算 (HPC) 互连的远程直接存储器访问(RDMA) 的“队列集”概念。这些队列可以通过接口类型进行单独配置,并且能够在许多不同的模式下工作。基于单个队列加载 DMA 描述符的方式,每个队列均可提供极低开销的建立时间选项和连续更新功能。通过将队列作为资源分配给多个 PCIe 物理功能 (PF) 和虚拟功能 (VF),即可在各种多功能和虚拟化应用空间中使用同一个 QDMA 核与 PCIExpress 接口。
QDMA Subsystem for PCIe 搭配赛灵思提供的 QDMA 参考驱动程序一起使用和实践,随后构建并输出以满足各种应用空间的需求。
QDMA Architecture
下图显示了 QDMA Subsystem for PCIe 的模块框图。
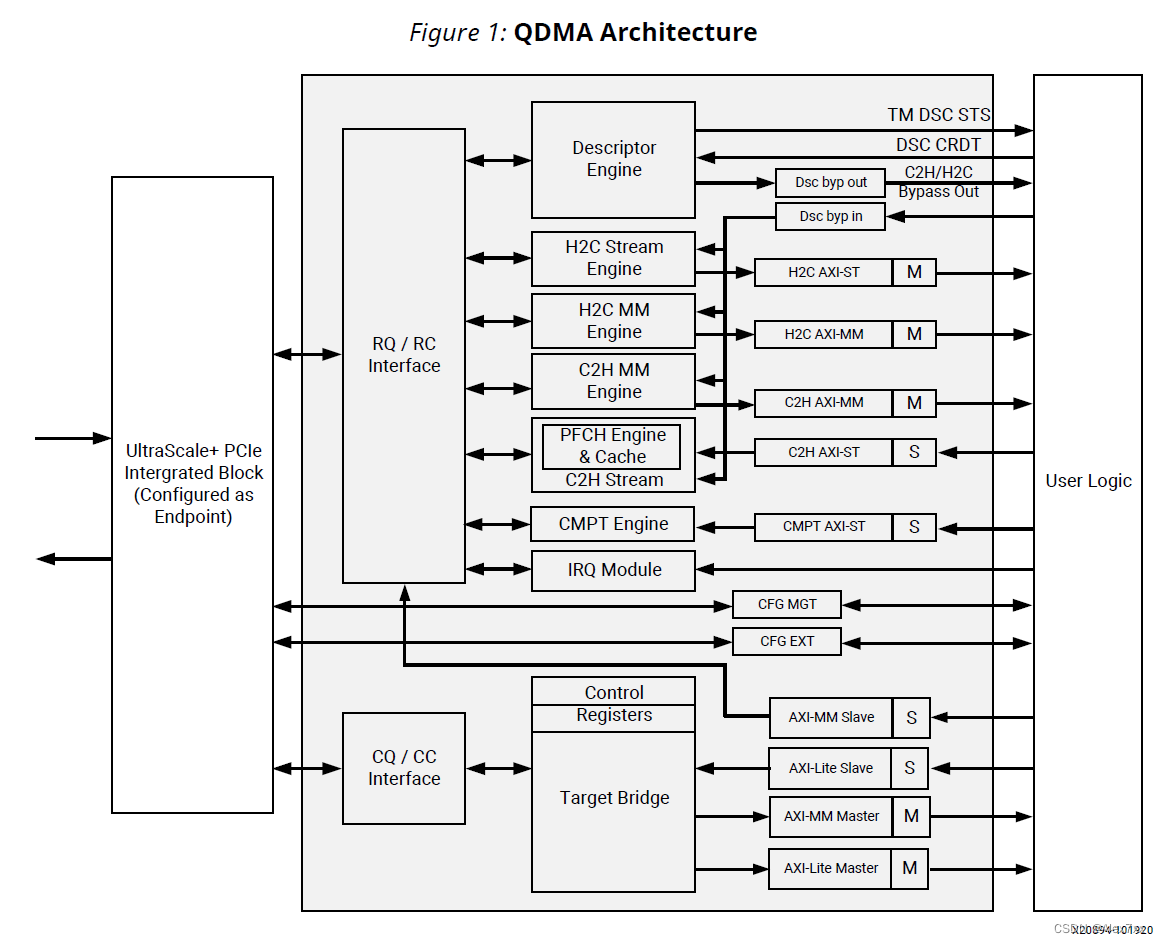
DMA Engines
Descriptor Engine
描述符引擎可选择下列两种模式之一来提取主机到卡 (H2C) 和卡到主机 (C2H) 描述符:内部模式和描述符旁路模式。描述符引擎可维护每个队列的上下文,包括跟踪每个队列的软件 (SW) 生产者索引指针 (producer index pointer, PIDX)、使用者索引指针(consumer index pointer, CIDX)、队列基址 (base address of the queue, BADDR) 和队列配置。描述符引擎使用循环算法来提取描述符。描述符引擎为 H2C 和 C2H 队列提供单独的缓冲区,并确保它永远不会获取比可用空间更多的描述符。任一时间每个队列内,描述符引擎有且仅有一个未完成的 DMA 读取操作,描述符引擎可读取的描述符数量仅受 MRRS 中可包含的描述符数量限制。描述符引擎负责对乱序完成进行重新排序,并确保队列的描述符始终有序。
描述符旁路可按队列启用,并且缓冲后提取的描述符将被发送到相应的旁路输出接口,而不是直接发送到 H2C 或 C2H引擎。在内部模式中,描述符将根据上下文设置来发送,并按 H2C 存储器映射 (MM)、C2H MM、H2C 串流或 C2H串流引擎分别执行删除。
描述符引擎还负责生成对应 DMA 操作完成的状态描述符。除了 C2H 串流模式外,所有模式都使用这种机制来传达每
个 DMA 操作的完成,以便软件回收描述符并清空任何关联的缓冲器。状态描述符的 CIDX 字段可指示此操作。
建议:如果队列与中断聚合相关联,赛灵思建议关闭状态描述符,改为从中断聚合环接收 DMA 状态。
- 1
要给提取的描述符数量施加限制(例如,限制存储描述符所需的缓冲量),可以逐队列开启信用值并进行微调。在此模式下,描述符引擎会提取描述符(上限不超过可用信用值),并且每个队列提取的描述符总数上限不超过提供的信用值。用户逻辑可以通过 dsc_crdt 接口返回信用值。信用值按描述符大小粒度来设置。
为了帮助用户开发的流量管理器排列工作负载优先顺序,PIDX 更新的待提取的可用描述符(增量 PIDX 值)将会被发送到 tm_dsc_sts 接口上的用户逻辑。通过使用此接口,即可实现相应设计来排列描述符存储的优先顺序并加以最优化。
H2C MM Engine
H2C MM 通过 H2C AXI-MM 接口将数据从主机存储器移至卡存储器。该引擎会在 PCIe 上生成读取,并基于 MRRS 以及 PCIe 读取不得超过 4 KB 边界的要求,将描述符拆分为多个读取请求。收到读取请求的完成数据后,就会在 H2CAXI-MM 接口上生成 AXI 写入。对于未对齐的源和目标地址,硬件将对数据进行移位,并在 AXI-MM 上拆分写入,以免跨 4 KB 边界。每个已完成的描述符都会被检查,判定是否需要写回和/或中断。
对于内部模式,描述符引擎会将存储器映射的描述符直接交付至 H2C MM 引擎。用户逻辑也可以将描述符注入 H2C描述符旁路接口,以将数据从主机移至卡存储器。这样即可执行一些有趣的操作,如在同一个队列中混用控制和 DMA命令。控制信息可发送至控制处理器,以指示 DMA 操作完成。
C2H MM Engine
C2H MM 引擎通过 C2H AXI-MM 接口将数据从卡存储器移入主机存储器。该引擎会在 C2H AXI-MM 总线上生成 AXI读取,基于 4 KB 边界将描述符拆分为多个请求。一旦在 AXI4 接口上接收到读取请求的完成数据,就会使用来自 AXI读取的数据作为写入内容来生成 PCIe 写入。对于未对齐的源和目标地址,硬件将对数据进行移位,并在 PCIe 上拆分写入,从而满足最大有效载荷大小 (MPS) 要求并避免跨 4 KB 边界。每个已完成的描述符都会被检查,判定是否需要写回和/或中断。
对于内部模式,描述符引擎会将存储器映射的描述符直接交付至 C2H MM 引擎。与 H2C MM 引擎一样,用户逻辑也可以将描述符注入 C2H 描述符旁路接口,以将数据从卡移至主机存储器。
对于多功能配置支持,在 AXI-MM 接口总线的 aruser 位中将提供 PCIe 功能编号信息,以便用户逻辑对卡存储器进行虚拟化。除了数据和用户总线外,还会提供奇偶校验总线用于端到端奇偶校验支持。
H2C Stream Engine
H2C 串流引擎用于将数据从主机移至 H2C 串流接口。对于内部模式,描述符直接交付至 H2C 串流引擎;对于旁路模式下的队列,描述符可重新格式化并馈送到旁路输入接口。引擎负责将 DMA 读取分解为 MRRS 大小,保证有足够空间可用于完成,并确保对 completions 进行重新排序以确保将 H2C 串流数据按顺序交付到用户逻辑。
引擎有足够缓冲可用于进行最多 256 次描述符读取和处理最多 32 KB 的数据。DMA 会提取数据并与 AXI4 接口侧要传输的第一个字节对齐。这样每个描述符就都有了随机偏移和随机长度。所有描述符的总长度必须小于 64 KB。
对于内部模式队列,每个描述符定义一个要传输到 H2C AXI-ST 接口的 AXI4-Stream 包。由于每个队列存储空间的缺乏,因此不允许跨接多个描述符的包。但是,跨接多个描述符的包可使用描述符旁路模式来实现。在此模式下,当用户逻辑有足够描述符可形成一个包时,即可启动 H2C DMA 引擎。DMA 引擎的启动方式是将跨接多个描述符的包随其它H2C ST 包描述符一起通过旁路接口来进行交付,这样可确保各描述符之间不发生交织。另外,通过旁路接口,用户逻辑可以控制状态描述符的生成。
C2H Stream Engine
C2H 串流引擎负责接收来自用户逻辑的数据,并将其写入由 C2H 描述符提供的主机存储器地址,对于一个给定的队列。
C2H 引擎有两个主要模块用于完成 C2H 串流 DMA:描述符预取高速缓存 (PFCH) 和 C2H-ST DMA 写入引擎。PFCH具有逐队列上下文,旨在增强其功能的性能以及增强用于对其进行编程的软件的性能。
PFCH 高速缓存基于每个队列具有三种主要模式:称为 Simple Bypass Mode(简单旁路模式)、Internal Cache Mode(内部高速缓存模式)和 Cached Bypass Mode(高速缓存旁路模式)。
- 在简单旁路模式下,引擎不会对队列进行任何跟踪,用户逻辑可自行定义描述符的接收方法。随后,用户逻辑负责通过简单旁路接口来交付包和关联的描述符。在旁路模式下,所有队列在旁路接口和 C2H 串流接口中提取描述符的顺序都必须保持不变。
- 在内部高速缓存模式和高速缓存旁路模式下,PFCH 模块可以为最多 512 个描述符提供存储空间,这些描述符可供最多 64 个不同队列使用。在此模式下,为了控制要提取的描述符,引擎采用的方法是根据流水线中收到的包,按需对 C2H 描述符队列信用值加以控制。预取模式(Pre-fetch mode)可按队列启用,启用此模式会导致适时地预取描述符,使描述符在数据包可用之前可用。其状态可在预取上下文中找到。这种近乎即时方式将包数据传输至 PCIe 集成块,而不必等待相关描述符完成获取,因而显著缩短时延。对于队列(PFCH 上下文)来说,数据缓冲器的大小是固定的,引擎可将数据包分散在多达 7 个描述符上。在高速缓存旁路模式下,描述符通过旁路连接到用户逻辑以进行进一步处理(如地址转换),并通过接口中的旁路发回。这种模式不假设任何排序描述符和 C2H 串流包接口,并且预取引擎可以匹配数据包和描述符。启用预取模式时,请勿向 IP 提供信用值。预取引擎负责信用值管理。
Completion Engine
完成 (CMPT) 引擎被用于写入到完成队列。尽管完成引擎可搭配 AXI-MM 接口和串流 DMA 引擎一起使用,但 C2H 串流DMA 引擎旨在与完成引擎紧密合作。完成引擎也可用于将即时数据传递给完成环。完成引擎可用于在完成环中写入最多 64B 的完成。当完成与 DMA 引擎搭配一起使用时,驱动程序会使用完成来判定随每个包传输的数据字节数。这样驱动程序即可回收描述符。
完成引擎会维护完成上下文。此上下文由驱动程序进行编程,并按队列进行维护。完成上下文可存储各种信息,如,完成环的基址、 PIDX、CIDX 和完成引擎的多方面信息,这些信息可通过设置完成上下文的各字段来加以控制。
引擎还可以根据软件需要,按每个队列进行配置,以生成中断和/或完成状态更新。如果多个队列的中断聚合到中断聚合环中,那么在中断聚合环中还会提供状态描述符信息。
CMPT 引擎具有多达 64 个条目的高速缓存,用于将多个较小的 CMPT 写入合并为 64B 写入,以提升 PCIe 效率。无论何时,完成均可同时合并,上限不超过 64 个队列。除此之外,只要有任何额外队列需要写入 CMPT 条目,就会导致从高速缓存中逐出最近使用最少的队列。为此,所用高速缓存的深度可配置为下列值:8、16、32 和 64。
Bridge Interfaces
AXI Memory Mapped Bridge Master Interface
AXI MM Bridge 主接口用于从主机对 AXI 存储器映射空间进行高带宽访问。此接口支持最多 32 个未完成的 AXI 读取和写入。可将任意物理功能 (PF) 或虚拟功能 (VF) 的一个或多个 PCIe BAR 映射到 AXI-MM Bridge 主接口。此选择必须在设计编译之前完成。在 AXI-MM 接口的 aruser 和 awuser 中都将提供功能 ID、BAR ID、VF 组和 VF 组偏移,以便允许用户逻辑识别每次存储器访问的来源。在 AXI Bridge 主端口中罗列了 m_axib_awuser/m_axib_aruser[54:0] 用户位映射。
虚拟功能组 (VFG) 表示 VF 组编号。它等同于对应 VF 关联的 PF 编号。VFG_OFFSET 表示与特定 PF 相关的 VF 编号。请注意,它并非每个 PF 的 FIRST_VF_OFFSET。
例如,如果 PF0 和 PF1 均有 8 个 VF,则 PF0 和 PF1 的 FIRST_VF_OFFSET 分别为 4 和 11。以下是 VFG 和VFG_OFFSET 的映射。
Table 1: AXI-MM Interface Virtual Function Group
- 1

每个主机发起的访问均可通过 PCIe 到 AXI BAR 转换单独映射到 64 位 AXI 地址空间。
由于所有功能都共享相同的 AXI 主接口地址空间,因此需要相应机制来将请求从不同功能映射到 AXI 主接口侧的不同地址空间。以下提供的示例演示了如何使用 PCIe 到 AXI 转换矢量。请注意,属于相同 PF 的所有 VF 都共享相同的PCIe 到 AXI 转换矢量。因此,每个 VF 的 AXI 地址空间都连接在一起。VFG_OFFSET 可用于计算特定 VF 的 AXI 实际起始地址。
总结,m_axib_awaddr 判定方式如下:
- 对于 PF,m_axib_awaddr = pcie2axi_vec + axib_offset。
- 对于 VF,m_axib_awaddr = pcie2axi_vec + (VFG_OFFSET + 1)*vf_bar_size + axib_offset。
其中,pcie2axi_vec 是 PCIe 到 AXI BAR 转换(从 Vivado IP 目录配置 IP 核时即可设置此转换)。
axib_offset 是请求的目标空间中的地址偏移。
AXI4-Lite Bridge Master Interface
可将任意物理功能 (PF) 或虚拟功能 (VF) 的一个或多个 PCIe BAR 映射到 AXI4-Lite 主接口。此操作必须在配置 IP 时完成。在 AXI4-Lite 接口的 aruser 和 awuser 中将提供功能 ID、BAR ID(BAR 命中)、VF 组和 VF 组偏移,帮助用户识别存储器访问的来源。
在 AXI4-Lite 主端口中会列出 m_axil_awuser/m_axil_aruser[54:0] 用户位的映射。
虚拟功能组 (VFG) 表示 VF 组编号。它等同于对应 VF 关联的 PF 编号。VFG_OFFSET 表示与特定 PF 相关的 VF 编号。请注意,它并非每个 PF 的 FIRST_VF_OFFSET。
例如,如果 PF0 和 PF1 均含 8 个 VF,PF0 和 PF1 的 FIRST_VF_OFFSET 分别为 4 和 11,以下是 VFG 和VFG_OFFSET 的映射。
Table 2: AXI4-Lite Interface VFG
- 1

每个主机发起的访问均可通过 PCIe 到 AXI BAR 转换单独映射到 64 位 AXI 地址空间。
由于所有功能都共享相同的 AXI4 主接口地址空间,因此需要相应机制来将请求从不同功能映射到 AXI 主接口侧的不同地址空间。以下显示了如何使用 PCIe 到 AXI 转换矢量。请注意,属于相同 PF 的所有 VF 都共享相同的 PCIe 到 AXI 转换矢量。因此,每个 VF 的 AXI 地址空间都连接在一起。VFG_OFFSET 可用于计算特定 VF 的 AXI 实际起始地址。
综上所述,m_axil_awaddr 的判定方式为:
- 对于 PF,m_axil_awaddr = pcie2axi_vec + axil_offset。
- 对于 VF,m_axil_awaddr = pcie2axi_vec + (VFG_OFFSET + 1)*vf_bar_size + axil_offset
其中,pcie2axi_vec 是 PCIe 到 AXI BAR 转换(可在 IP 配置期间设置)。
axib_offset 是请求的目标空间中的地址偏移。
每个主机发起的访问均可单独映射到 64 位 AXI 地址空间。在此接口上支持一个未完成的读取操作和一个未完成的写入操作。
在 IP 配置时,还可将扩展 ROM BAR 映射到 AXI4-Lite 接口。
PCIe to AXI BARs
对于每个物理功能,PCIe 配置空间由一组 6 个 32 位存储器 BAR 和一个 32 位扩展 ROM BAR 组成。启用 SR-IOV后,将为每个虚拟功能启用额外的 6 个 32 位 BAR。这些 BAR 会为 AXI4 存储器映射空间功能、接口布线和 AXI4 请求属性配置提供地址转换。任意成对 BAR 均可配置为单个 64 位 BAR。 在《AXI Bridge for PCI Express Gen3 Subsystem产品指南》(PG194) 的“地址转换”部分中可找到编程示例(示例 3)。
Request Memory Type
可通过 attr_dma_pciebar2axibar__cache_pf 属性来为每个 PCIe BAR 设置存储器类型。
- AxCache[0] 设为 1 表示可修改,设为 0 则表示不可修改。
- AxCache[1] 设为 1 表示可缓存,设为 0 则表示不可缓存。
AXI Memory Mapped Bridge Slave Interface
AXI-MM Bridge 从接口用于用户逻辑与主机之间的高带宽存储器传输。支持通过 AXI 到 PCIe BAR 进行 AXI 到 PCIe 的转换。此接口将按需拆分请求,以遵循 PCIe MPS 和跨 4 KB 边界要求。最多支持 32 个未完成的读取和写入请求。
AXI4-Lite Bridge Slave CSR Interface
AXI4-Lite 从接口用于访问 AXI Bridge 和 QDMA 内部寄存器。地址位 [15] 指示访问的是 QDMA 寄存器还是 AXIBridge 寄存器。
- 当 s_axil_csr_awaddr[15] = 1’b1 时,写入访问对应的是 QDMA CSR 寄存器。
- 当 s_axil_csr_awaddr[15] = 1’b0 时,写入访问对应的是 Bridge 寄存器(访问 Bridge 寄存器时,从地址0x000 到 0xDFF 的访问将重定向至 PCIe 核配置空间访问,源自地址 0xE00 访问则将定向至 Bridge 寄存器)。
- 当 s_axil_csr_araddr[15] = 1’b1 时,读取访问对应的是 QDMA CSR 寄存器。
- 当 s_axil_csr_araddr[15] = 1’b0 时,读取访问对应的是 Bridge 寄存器。访问 Bridge 寄存器时,从地址0x000 到 0xDFF 的访问将重定向至 PCIe 核配置空间访问,源自地址 0xE00 的访问则将定向至 Bridge 寄存器。
QDMA 寄存器为 VF 和 PF 经过虚拟化。例如,VF 和 PF 可以访问地址空间的不同部分,并且各自均可访问自己的队列。为满足访问特定功能的需求,用户逻辑可以在写入访问 s_axil_awuser[7:0] 上和读取访问s_axil_aruser[7:0] 上提供功能 ID,从而为 QDMA 提供适当的内部寄存器访问。在 AXI4-Lite 从接口上支持单一未完成读取请求和单一未完成写入请求。
AXI4-Lite 从接口还可使用 Bridge 寄存器生成供应商定义报文 (VDM)。
相关信息 VDM
AXI to PCIe BARs
在 Bridge 从接口中,有 1 个 BAR 可配置为 32 位或 64 位。此 BAR 可提供从 AXI 地址空间到 PCIe 地址空间的地址转换。地址转换是通过 BDF 表编程来配置的。如需了解有关 BDF 编程的信息,请参阅“Slave Bridge”章节。
相关信息 Slave Bridge
Interrupt Module
IRQ 模块用于聚合各种来源的中断。中断来源为基于队列的中断、用户中断和错误中断。
在 PF 和 VF 上允许基于队列的中断和用户中断,但仅在 PF 上才允许错误中断。如果未启用 SR-IOV,则每个 PF 都可以选择 MSI-X 或 Legacy Interrupts(遗留中断)。启用 SR-IOV 后,所有功能都仅支持 MSI-X 中断。
MSI-X 中断默认启用。主机系统(根联合体)将启用硬件中支持的单一或全部中断类型。如果启用 MSI-X,则 MSI-X优先。
每个功能最多有 8 个中断可用。为了允许任一给定功能均可使用大量队列并且每个队列都有中断,QDMA Subsystemfor PCIe 提供了全新的方法,可用于将来自多个队列的中断聚合到单个中断矢量中。这样原则上全部 2048 个队列都可以映射到单个中断矢量。QDMA 可提供 256 个中断聚合环,可在 256 个可用功能之间灵活分配。
PCIe Block Interface
PCIe CQ/CC
PCIe 完成器请求 (CQ)/完成器完成 (CC) 模块用于从远程 PCIe 代理接收 TLP 请求并加以处理。此接口与 UltraScale+ Integrated Block for PCIe IP 对接,并在地址对齐模式下工作。此模块使用来自 Integrated Block for PCIe IP 的 BAR 信息以判定转发的请求应到哪里。这些请求的可能目的地包括:
- DMA 配置模块
- AXI4 MM Bridge 主接口
- AXI4-Lite Bridge 主接口
非转发请求应接收来自目标的完成,并将其转发至远程 PCIe 代理。如需了解更多详细信息,请参阅《UltraScale+ Integrated Block for PCI Express LogiCORE IP 产品指南》(PG213)。
PCIe RQ/RC
PCIe 请求器请求 (RQ)/请求器完成 (RC) 接口会在 RQ 总线上生成 PCIe TLP,并处理来自 RC 总线的 PCIe 完成 TLP。此 接口与 UltraScale+ Integrated Block for PCIe® 核对接,在 DWord 对齐模式下工作。对于 512 位接口,将启用跨接。支持跨接时,可能并不会实现 RQ 跨接传输事务的所有组合。如需了解更多详细信息,请参阅《UltraScale+ Integrated Block for PCI Express LogiCORE IP 产品指南》(PG213)。
PCIe Configuration
有多个因素会导致限制传出非转发传输事务。传出非转发传输事务是根据来自 PCIe® Integrated Block 的流量控制信息来加以限制的,以防止转发请求发送队头阻塞。DMA 将根据 PCIe 接收 FIFO 空间来测量非转发传输事务。
General Design of Queues
==QDMA Subsystem for PCIe 的多队列 DMA 引擎使用成对的 RDMA 模型队列来支持用户逻辑中的 RNIC 实现。==每个队列组均由主机到卡 (H2C)、卡到主机 (C2H) 和 C2H 串流完成 (CMPT) 组成。每个队列的元素均为描述符。
H2C 和 C2H 始终由驱动程序/软件写入;硬件始终从这些队列中读取。H2C 承载的描述符用于执行来自主机的 DMA读取操作。C2H 承载的描述符则用于对主机执行 DMA 写入操作。
在内部模式下,H2C 描述符承载地址和长度信息,被称为聚集描述符(gather descriptor)。这些描述符支持 32 位元数据,这些元数据可随每个描述符一起从软件传递到硬件。根据上下文设置,描述符可作为存储器映射(承载主机地址、卡地址和 DMA 传输长度)描述符,或者也可以作为串流(仅承载主机和 DMA 传输长度)描述符。通过描述符旁路可定义任意描述符格式,以便软件将即时数据和/或附加元数据随包一起传递。
C2H 队列存储器映射描述符包含卡地址、主机地址和长度。在串流内部缓存模式下,描述符仅承载主机地址。描述符的缓冲器大小由驱动程序编程,对于整个队列,其大小应固定不变。实际传输中,与每个描述符关联的数据并不一定必须是缓冲器大小的完整长度。
软件通过向硬件写入其生产者索引 (PIDX) 来为 H2C 和 C2H 队列播发有效描述符。状态描述符是描述符环(C2H 串流环除外)的最后一个条目。状态描述符承载硬件的使用者索引 (CIDX),以便驱动程序知晓何时回收描述符并在主机中取消分配缓冲器。
对于 C2H 串流模式,C2H 描述符将根据 CMPT 队列条目进行回收。通常情况下,每个 C2H 包承载一个条目,表示耗用一个或多个 C2H 描述符。CMPT 队列条目承载了足够的信息,可供软件申明所有已使用的描述符。通过外部逻辑可将其扩展到承载其它种类的完成或信息,以提供给主机。
驱动程序可使用描述符中的 color bit 或 CMPT 环末端的状态描述符来检测由硬件写入环中的 CMPT 条目。每个 CMPT 条目均可承载 C2H 串流包的元数据,也可以作为用户应用程序的自定义完成或即时通知。
所有环形缓冲器(H2C、C2H 和 CMPT)的基址都应对齐到 4 KB 地址。
Figure 2: Queue Ring Architecture
- 1

该软件可按 16 种不同的环大小进行编程。可从上下文编程中选择每个队列的环大小。最后一个队列条目是描述符状态,允许的条目数为(队列大小 - 1)。
例如,如果队列大小为 8,其中包含条目索引 0 到 7,那么最后一个条目(索引 7)保留用于表示状态。无论如何,此索引(7)都不应该用于 PIDX 更新,PIDX 更新也不应该等于 CIDX。在此情况下,如果 CIDX 为 0,最大 PIDX 更新将为6。
在以上示例中,如果流量已启动,并且 CIDX 为 4,那么最大 PIDX 更新为 3。
H2C and C2H Queues
H2C/C2H 队列是位于主机存储器中的环。对于这两种类型的队列,生产者是软件,使用者则是描述符引擎。软件负责维护生产者索引 (PIDX) 和硬件使用者索引 (HW CIDX) 的副本,以避免覆盖未读取的描述符。描述符引擎还负责维护使用者索引 (CIDX) 和 SW PIDX 的副本,以确保引擎不会读取未写入的描述符。队列中的最后一个条目专用于状态描述符,引擎(Descriptor Engine)会在该状态描述符中写入 HW CIDX 和其它状态。
引擎(Descriptor Engine)在本地存储器中维护总计 2048 个 H2C 上下文和 2048 个 C2H 上下文。上下文负责存储队列的属性,例如,队列的基址 (BADDR)、SW PIDX、CIDX 和深度。
Figure 3: Simple H2C and C2H Queue
- 1

上图显示了 H2C 和 C2H 的提取操作。
- 对于 H2C,驱动程序会将有效载荷写入主机缓冲器,与有效载荷缓冲器信息一起构成 H2C 描述符,并将其放入PIDX 位置处的 H2C 队列中。对于 C2H,驱动程序以保留的可用缓冲器空间来构成描述符,以便接收来自 DMA的包写入。
- 驱动程序会将已发布的写入发送到描述符引擎中的 PIDX 寄存器中,用于关联的队列 ID (QID) 及其当前 PIDX 值。
- 在接收到 PIDX 更新后,引擎会根据地址偏移和功能 ID 来计算指针更新的绝对 QID。通过使用 QID,引擎将从与QDMA Subsystem for PCIe 关联的存储器提取绝对 QID 的上下文。
- 引擎会根据上下文判定允许提取的描述符数量。引擎会使用基址 (BADDR)、CIDX 和描述符大小来计算描述符地址,然后引擎会发出 DMA 读取请求。
- 描述符引擎从主机存储器接收到读取完成后,对于内部模式(internal mode),会将其交付至 H2C 引擎或 C2H 引擎。对于旁路(bypass mode),描述符将被传出至相关联的描述符旁路输出接口。
- 对于编程为内部模式的存储器映射或 H2C 串流队列,在完全处理完提取的描述符后,引擎会将 CIDX 值写入状态描述符。对于编程为旁路模式的队列,用户逻辑通过接口中的旁路来控制写回。状态描述符可根据上下文设置进行调节。C2H 串流队列始终使用 CMPT 环用于完成。
对于 C2H,通过 CMPT 环来隐式完成提取操作。
Completion Queues
完成 (CMPT) 队列是位于主机存储器中的环。使用者是软件,生产者则是 CMPT 引擎。软件负责维护使用者索引(CIDX) 和硬件生产者索引 (HW PIDX) 的副本,以避免读取未写入的完成。CMPT 引擎也负责维护 PIDX 和软件使用者索引 (SW CIDX) 副本,以确保引擎不会覆盖未读取的完成。队列中的最后一个条目专用于状态描述符,引擎会在该状态描述符中写入硬件生产者索引 (HW PIDX) 和其它状态。
该引擎在本地存储器中总计维护 2048 个 CMPT 上下文。上下文可存储队列的属性,如基址、SW CIDX、PIDX 和队列深度。
Figure 4: Simple Completion Queue Flow
- 1

C2H 串流应使用 CMPT 队列将完成传输至主机,但它也可以用于其它类型的完成操作或向驱动程序发送报文。通过 CMPT 的报文保证不会绕过对应的 C2H 串流包 DMA。
符合上述编号方式的 DMA CMPT 队列操作的简单流程如下所示:
- CMPT 引擎通过 CMPT 接口接收完成报文,但完成报文的 QID 来自 C2H 串流接口。该引擎会读取 CMPT 上下文RAM 的 QID 索引。
- DMA 则会将 CMPT 条目写入地址 BASE+PIDX。
- 如果所有条件都满足,则可选择将 PIDX 随颜色位一起写入 CMPT 队列的状态描述符中。
- 如果启用中断模式,CMPT 引擎会生成中断事件报文并发送给中断模块。
- 驱动程序可采用轮询模式或中断模式。无论采用何种方式,驱动程序都会识别新的 CMPT 条目,方法是匹配颜色位,或者将状态描述符中的 PIDX 值与其当前的软件 CIDX 值进行比较。
- 驱动程序会为该队列更新 CIDX。这样硬件即可复用描述符。软件完成对 CMPT 的处理后,即在停止轮询或离开中断处理程序之前,驱动程序会对关联队列的 CIDX 更新寄存器发出写入。
SR-IOV Support
QDMA Subsystem for PCIe 提供了可选功能特性,以支持单根 I/O 虚拟化 (Single Root I/O Virtualization, SR-IOV)。PCI-SIG® Single Root I/O Virtualization 与 Sharing (SR-IOV) 规范(详见《PCI-SIG 规范》(www.pcisig.com/specifications))旨在对数据路径传输事务内所涉及的 VMM 的旁路方法加以规范化,并允许单一端点显示为多个独立端点。SR-IOV 将各功能分类为:
- 物理功能 (Physical Functions,PF):全功能特性的 PCIe® 功能,包含 SR-IOV 等功能。
- 虚拟功能 (Viretual Functions,VF):PCIe 功能,特供含基址寄存器 (Base Address Registers,BAR) 的配置空间,但缺少完整配置资源,由 PF 配置进行控制。VF的主要作用是数据传输。
除了 PCIe 定义的配置空间,QDMA Subsystem for PCI Express 还会将数据路径操作(如队列的指针更新和中断)加以虚拟化。其余管理和配置功能都将推迟到物理功能驱动程序。没有足够特权的驱动程序必须通过邮箱接口与有特权的驱动程序进行通信,邮箱接口在 QDMA Subsystem for PCI Express 内提供。
安全性是虚拟化的一个重要方面。QDMA Subsystem for PCI Express 可提供以下安全性功能:
- QDMA 只允许有特权的 PF 对每个队列上下文和寄存器进行配置。VF 会将任何队列上下文编程告知对应的 PF。
- 驱动程序仅限于为分配到的队列执行指针更新。
- 通过开启系统 IOMMU 即可检查 PF 或 VF 当前请求的 DMA 访问。ARID 来自于有特权的功能所编程的队列上下文。
任何 PF 或 VF 均可通过邮箱与除本身以外的其它 PF 进行通信。每个功能均可实现一个 128B 收件箱和 128B 发件箱。这些邮箱对自身功能的 DMA BAR(通常是 BAR0)中的驱动程序均可见。无论何时,任一功能都能有一条传出邮箱报文和一条传入邮箱报文处于未完成状态。
下图显示了典型系统如何使用 QDMA 的不同功能和操作系统。不同的队列可分配到不同的功能,每个功能都可彼此独立传输 DMA 包。
Figure 5: QDMA in a System
- 1

Limitations
The limitations of the QDMA Subsystem for PCIe are as follows:
- The DMA supports a maximum of 256 Queues on any VF function.
- Slave Bridge AXI does not support Narrow Burst transfers.
RECOMMENDED: Use AXI SmartConnect to support Narrow Burst. - SRIOV is not supported in bridge mode.
Applications
QDMA Subsystem for PCIe 广泛应用于联网、计算和数据存储应用。==QDMA Subsystem for PCIe 的常用示例是用于实现数据中心和远程通信应用,例如,计算加速、Smart NIC、NVMe、启用 RDMA 的 NIC (RNIC)、服务器虚拟化和用户逻辑中的 NFV。==通过为每个应用分配不同的队列集和 PCIe 功能,即可实现多个共享 QDMA 的应用。随后,即可在用户逻辑中通过调整这些队列的规模来实现限速、流量优先级和定制工作队列条目 (WQE)。

