
- 1AI技术内参031-经典搜索核心算法:TF-IDF及其变种_tf idf搜索
- 2Android Git之旅
- 35 款设计师必备的 SD模型,3D、电商、B端都能用(附模型下载)_sd工业设计模型
- 4Dubbo基础_zzo0
- 5[职场] 视频面试需要做好哪些准备 #微信#其他#知识分享
- 6AI 挑战周杰伦?Suno 全新功能面世,即兴哼几句就能创作成歌,还能模仿声音!..._suno sound-to-song
- 703、机器学习 (贝叶斯分类算法与应用)_以购买电脑案例为样本输入,调用自编的贝叶斯分类方法,预测 待分类数据x= {a
- 8Spark 分区(Partition)的认识、理解和应用法_spark分区的概念
- 9docker编译一个支持flv的nginx镜像
- 10uboot里读sd卡内容
tcl学习之路(四)(vivado设计分析)_vivado tcl 教学
赞
踩
1.FPGA芯片架构中的对象
在打开elaborated/synthesied/implemented的情况下,可使用如下命令获取期望的SLICE。SLICE分为SLICEL和SLICEM,由LUT、FF、MUX、CARRY组成。
set all_slice [get_sites SLICE*]
set col_slice [get_sites SLICEX0Y*]
set all_sliceL [get_sites -filter "SITE_TYPE == SLICEL"]
set all_sliceM [get_sites -filter "SITE_TYPE == SLICEM"]
#资源的个数可用llength来查看
llength $all_slice
- 1
- 2
- 3
- 4
- 5
- 6
BEL(Basic Element 基本要素 )是FPGA内部的基本单元,属于器件对象,也就是器件结构的一部分。换言之,即便是一个空设计,只要打开Device视图,也能看到BEL。具体地,BEL包括触发器、查找表、进位链、F7MUX、F8MUX和F9MUX(这里以UltraScale系列芯片为例,不难看出,这些基本单元都在SLICE内)。BEL还包括DSP内部的基本单元。使用get_bels可以获取bel资源。
get_bels -of [get_sites SLICE_X0Y0]
#这里=~表示匹配
get_bels -of [get_sites SLICE_X0Y0] -filter "TYPE =~ *6LUT || TYPE =~ *FF"
- 1
- 2
- 3
每一个SLICE都是一个基本的site,除了SLICE还有DSP48、BLOCK RAM等site,一个或多个同类型的site可以组成一个tile。
get_tiles
- 1
不同的tile按列排列构成了clock region。
get_clock_regions
- 1
SLR(super logic region)由多个clock region构成。单die(芯片未封装前的晶粒)芯片只包含一个SLR,而多die芯片,也就是SSI器件,包含两个以上的SLR。
get_slrs
- 1
对于获取的对象,可以通过highlight_objects使其高亮,也可以通过show_objects使其在单独的窗口中呈现,还可以通过mark_objects对其进行标记。在这些命令前面加get_,可以获取对象名称,加un可以取消命令结果。
2.网表中的对象
在进行设计分析、设计调试或描述约束时,都要寻找RTL代码所描述的对象,比如寄存器、存储单元、计算单元,或某个时钟、某个引脚。某根网线、某个端口等。
网表中最关键的五个要素为单元cell、时钟clock、引脚pin、网线net、端口part。可以使用如下命令获取
get_cells
get_clocks
get_pins
get_nets
get_ports
#current_instance可以设置顶层,如果后面不跟任何参数,那么就将设计顶层模块视为顶层
current_instance
- 1
- 2
- 3
- 4
- 5
- 6
- 7
使用-hier可以逐层查找目标对象。
set dut [get_cells -hier ip_*]
#可以新打开一个窗口看到你查找的返回结果
show_objects $dut -name dut
#还可以通过对象特定属性进行查找,比如NAME
set ip [get_cells -hier -filter "NAME =~ ip*" U0]
- 1
- 2
- 3
- 4
- 5
对于特定属性,还有一个比较重要的是REF_NAME(引用名),下面介绍一下7系列FPGA的引用名
同步时钟使能异步复位D触发器 FDCE
同步时钟使能异步置位D触发器 FDPE
同步时钟使能同步复位D触发器 FDRE
同步时钟使能同步置位D触发器 FDSE
异步复位锁存器 LDCE
异步置位锁存器 LDPE
使用DSP48构成的计算单元 DSP48E1
使用Block RAM构成的36KbFIFO FIFO36E1
使用Block RAM构成的36Kb存储单元 RAMB36E1
使用Block RAM构成的18KbFIFO FIFO18E1
使用Block RAM构成的18Kb存储单元 RAMB18E1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
通常情况下,在找引脚或网线时,首先获取引脚或网线所隶属的单元,在通过-of来找到引脚或网线。
3.时钟分析
#生成时钟报告,可以看到时钟名称、时钟周期、占空比、时钟属性和时钟源
report_clocks
#生成时钟网络报告,可以查看哪个时钟遗漏了时钟周期约束,还可以检查到是否出现了BUFG级联的情形
report_clock_networks -name network_1
#生成时钟资源利用率报告
report_clock_utilization -name clkuti1
#精简版报告,关注点放在时钟树的源头上
report_clock_utilization -clock_roots_only -name clkuti1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在7系列FPGA中,时钟资源包括全局时钟缓冲器(BUFGCTRL),区域时钟缓冲器(BUFH/BUFR/BUFMR/BUFIO)和时钟生成模块(MMCM/PLL)等。如图
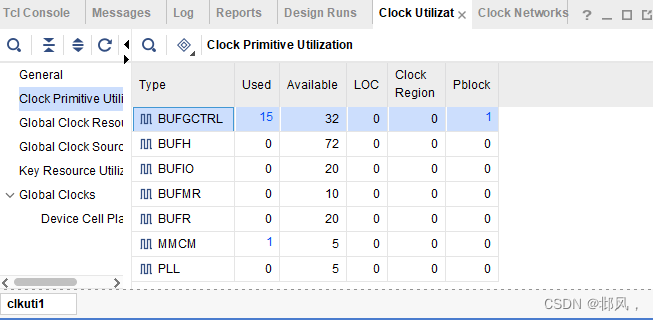
4.时序分析
生成时序报告的方式有两种:一种是通过命令report_timing或report_timing_summary生成时序报告;另一种是先用get_timing_paths获取特定时序路径,再用report_timing生成这些路径的时序报告。下面给出一些选项的含义
-from 时序路径的起点,可以是端口、引脚、单元或时钟
-to 时序路径的终点,可以是端口、引脚、单元或时钟
-through 时序路径穿过的节点,可以是引脚、单元或网线
-delay_type 时序分析的延迟类型,min代表分析保持时间,max代表分析建立时间,min_max代表两者都分析
-hold 等同min
-setup 等同max
-max_paths 待分析的时序路径的最大个数(最小值为1)
-nworst 以同一点作为终点的最糟糕的时序路径个数(默认值为1)
-slack_lesser_than 只分析时序裕量小于指定值的路径
-slack_greater_than 只分析时序裕量大于指定值的路径
-group 分析指定组的时序路径,可通过命令get_path_groups或group_path获取
-of_objects 指定时序路径对象,由get_timing_paths获取
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
5.质量分析
#在综合后或布局布线后使用
report_qor_assessment
- 1
- 2
使用后观察到QoR Assessment Score,该分数范围为1-5,分值越高表示时序越容易收敛。如果分数小于等于3,说明要改善时序了,就大概率不用进行后面的操作了。

第二部分要注意 Status,若是REVIEW,则说明会在很大程度上影响时序收敛,需要解决。

#生成改善设计质量的建议报告
report_qor_suggesrions
- 1
- 2
在布线后的.dcp中执行命令report_qor_suggestions可以得出基于机器学习的建议策略,同时要求原始的实现策略必须是Explore或Default。
6.资源利用率分析
#生成了资源利用分析
report_utilization -name util -file util.rpt
#可以保存到.xlsx文件中
report_utilization -name util -spreadsheet_file util_table.xlsx -spreadsheet_table "Hierarchy"
- 1
- 2
- 3
- 4
7.逻辑级数分析
逻辑级数是指时序路径起点单元和终点单元之间的组合逻辑门的个数。通常认为一个查找表加一根网线的延迟为0.5ns。使时序收敛的方法有流水线和重定时。
#用于分析逻辑级数
report_design_analysis -logic_level_distribution -logic_level_dist_paths 100 -min_level 10 -max_level 100 -name logiclecela
- 1
- 2
8.复杂度与拥塞分析
report_design_analysis -complexity -name cplx
- 1
可以得出如下界面:
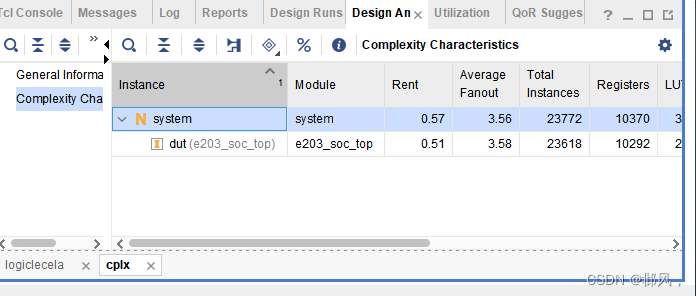
我们需要特别关注Rent、Average Fanout、Total Instance这三个参数。
Rent反应了模块的互连度,该指数越高,互连越重。较重的互连意味着设计会消耗大量的全局布线资源,从而导致布线拥堵。
Rent范围
0~0.65 正常
0.65~0.85 如果total instances超过了15000,则要格外注意
>0.85 如果total instances超过了15000,布局布线会失败
Average Fanout范围
<4 正常
4~5 布局可能会出现拥塞。如果是SSI器件,并且Total instances超过了100000,则很难将实际放在1个SLR内或分布到两个SLR内
>5 布局布线可能会失败
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
导致Rent指数过高的原因:较高的LUT6利用率(同时会导致扇出过高),以及Block RAM和DSP利用率。当Rent或Fout较高时,可以对相关模块使用OOC综合方式,以避免工具执行边界优化,从而降低LUT6的使用率。还可以使用模块化综合技术,采用模块化综合属性LUT_COMBINING,阻止LUT整合,降低LUT6的使用率。
#分析拥塞程度
report_design_analysis -congestion -name cong
- 1
- 2
在报告中,需要格外关注Type和Level
type 产生原因
全局拥塞(Global) 较高的LUT6利用率,过多的控制集,不合理的位置约束
长线拥塞(Long) 较高的BRAM或DSP利用率,过多的跨die网线
短线拥塞(Short) 较高的MUXF或进位链利用率
level QoR影响
小于等于4 影响不大
5 在布局布线时会遇到一些困难
6 会遇到很多困难,编译时间显著增加
7 会失败
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
9.扇出分析
#-load_types可以显示负载类型
report_high_fanout_nets -load_types -name high
#-clock_regions可以显示负载在每个时钟区域的个数
report_high_fanout_nets -clock_regions -name high
#-fanout_greater_than和-fanout_lesser_than可以限定扇出值
report_high_fanout_nets -fanout_greater_than 1000 -fanout_lesser_than 2000 -name high
#可以使用-cells限定分析的单元,-max_nets可以限定分析网线的最大个数,-timing可以显示网线所在路径的时序信息
report_high_fanout_nets -cells cpuEngine -max_nets 4 -timing -name high
#假设网线reset_reg有18个引脚为数据信号,可以借助如下代码,找到这18个信号
set net [get_nets reset_reg]
set mypin [get_pins -of $net -filter "DIRECTION==IN" -leaf]
set target_pin [filter $mypin "REF_PIN_NAME != CLR && REF_PIN_NAME != R && REF_PIN_NAME != PRE && REF_PIN_NAME != S"]
show_objects $target_pin -name data_pin
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
10.UFDM分析
全称"UltraFast Design Methodology"翻译为超快速设计方法。是Xilinx针对Vivado提出的一个设计方法学,涵盖了板级规划、代码风格、时序约束、时序收敛等方面的内容。
report_methodology -name ufdm_1
- 1
11.跨时钟域分析
report_clock_interaction -delay_type min_max -name timing_1
#分析跨时钟域路径在HDL方面的问题以及在约束层面的问题Clock Domain Crossings
report_cdc -name cdc1
- 1
- 2
- 3
12.约束分析
report_exceptions -name exceptions_1
#-coverage可以显示时序例外约束的覆盖率
report_exceptions -coverage -name exceptions_2
#-write_valid_exceptions生成设计中有效的时序例外约束 -write_merged_exceptions生成被合并的时序例外约束;都要与-file同时使用
report_exceptions -write_valid_exceptions -file ./valid_exceptions.rpt
report_exceptions -write_merged_exceptions -file ./valid_exceptions.rpt
#将有效的时序约束输出到指定的文件中,-exclude_physical可以排除物理约束
write_xdc -constraints VALID -exclude_physical ./valid_timing_constraiints.xdc
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

