
- 1QT 显示USB摄像头数据_qt usb 摄像头 获取画面
- 2nodejs sqlite模块
- 3FFmpeg安装与配置(windows与mac)_ffmpeg环境配置
- 4EM算法_斯坦福CS229_学习笔记_em算法会陷入局部极小值吗
- 5推荐一款M1电脑可用的虚拟机软件_m1 你能用的虚拟机器
- 6DeepMind CEO称AI智力不如猫!LeCun持相同看法!曝光谷歌新项目AI将突破聊天限制
- 7LightGBM算法——广告收益回归预测模型_lightgbm 回归模型
- 8苹果WWDC揭晓AI系统、电脑等设备系统全线更新,iPhone将接入ChatGPT_ios18 game mode
- 9Random rand = new Random(47);
- 10AI大语言模型的模型教育与培训_大语言模型培训
句向量训练总结_句子向量
赞
踩
https://zhuanlan.zhihu.com/p/151854074
句向量应用
语义搜索,通过句向量相似性,检索语料库中与query最匹配的文本
文本聚类,文本转为定长向量,通过聚类模型可无监督聚集相似文本
文本分类,表示成句向量,直接用简单分类器即训练文本分类器
句向量模型:
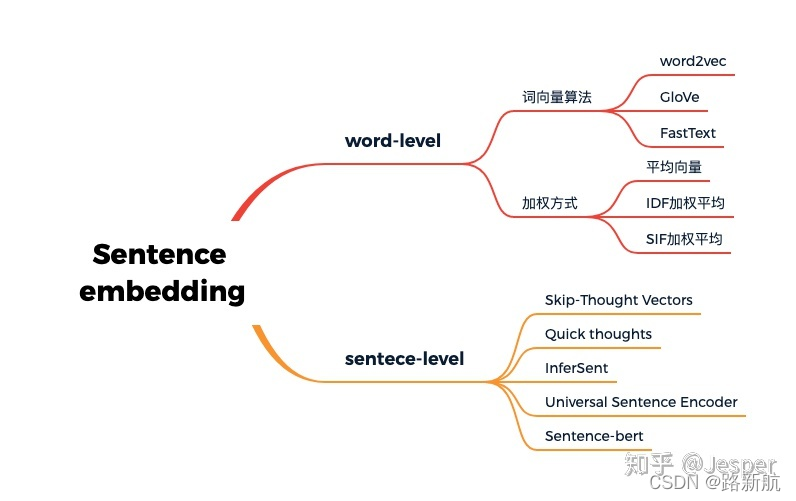
文档向量构建方法优缺点:
-
bag of words而言,有如下缺点:1.没有考虑到单词的顺序,2.忽略了单词的语义信息。因此这种方法对于短文本效果很差,对于长文本效果一般,通常在科研中用来做baseline。
-
average word vectors就是简单的对句子中的所有词向量取平均。是一种简单有效的方法,但缺点也是没有考虑到单词的顺序
-
tfidf-weighting word vectors是指对句子中的所有词向量根据tfidf权重加权求和,是常用的一种计算sentence embedding的方法,在某些问题上表现很好,相比于简单的对所有词向量求平均,考虑到了tfidf权重,因此句子中更重要的词占得比重就更大。但缺点也是没有考虑到单词的顺序
构造句向量方法:
基于Word2Vec的句向量

基于加权Word2Vec的句向量

tf idf
参考:Python sklearn 中的TfidfVectorizer参数解析
TF-IDF算法介绍和基于Python的实现
vectorizer = TfidfVectorizer(stop_words=drop_words_list) #max_df=0.3基于内部预料词频来自动检测和过滤停用词, TfidfVectorizer产生归一化向量
# 从训练集学习词汇表和idf
tfidf = vectorizer.fit(corpus)
#把这个计数矩阵转换成tf-idf表示,每个文本的各维度值是特征词的Tfidf值
tfidf_matrix_content = tfidf.transform(corpus)
weight = tfidf_matrix_content.toarray()
# get_most_similary_sentences_by_tfidf(clean_data, weight, seg_text, n)
key_word_list = vectorizer.get_feature_names() #获取词袋中所有文本关键词
pickle.dump(vectorizer, open(tfidf_model_path, "wb"))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
doc2vec VS word2vec
doc2vec 对于短文本效果并不好
doc2vec
官网:https://radimrehurek.com/gensim/models/doc2vec.html
doc2vec的使用场景
参考:https://blog.csdn.net/m0_37870649/article/details/80748539

Doc2Vec模型的介绍
参考:https://blog.csdn.net/liujh845633242/article/details/101595856
许多机器学习算法需要的输入是一个固定长度的向量,当涉及到短文时,最常用的固定长度的向量方法是词袋模型(bag-of-words)。但是词袋模型存在两个主要的缺点:一个是词袋模型忽略词序,如果两个不同的句子由相同的词但是顺序不同组成,词袋模型会将这两句话定义为同一个表达;另一个是词袋模型忽略了语义,这样训练出来的模型会造成类似’powerful’,'strong’和’Paris’的距离是相同的,而其实’powerful’应该相对于’Paris’距离’strong’更近。
Doc2vec又叫Paragraph Vector是Tomas Mikolov基于word2vec模型提出的,不仅考虑了词和词之间的语义,也考虑了词序。具有一些优点,比如不用固定句子长度,可以接受不同长度的句子做训练样本,Doc2vec是一个无监督学习算法,该算法用于向量来表示文档,该模型的结构潜在的克服了词袋模型的缺点。
Doc2Vec有两种模型,分别为:句向量的分布记忆模型(PV-DM: Distributed Memory Model of Paragraph Vectors,类似于word2vec中的CBOW模型,每次从一句话中滑动采样固定长度的词,取其中一个词作预测词,其他的作输入词)和句向量的分布词袋(PV-DBOW: Distributed Bag of Words version of Paragraph Vector,类似于word2vec中的skip-gram模型)。
Doc2vec是基于Word2vec基础上构建的,相比于Word2vec,Doc2vec不仅能训练处词向量还能训练处句子向量并预测新的句子向量。Doc2vec模型结构相对于Word2vec,不同点在于在输入层上多增加了一个Paragraph vector句子向量,该向量在同一句下的不同的训练中是权值共享的,这样训练出来的Paragraph vector就会逐渐在每句子中的几次训练中不断稳定下来,形成该句子的主旨。这样就训练出来了我们需要的句子向量。在预测新的句子向量时,是需要重新训练的,此时该模型的词向量和投影层到输出层的soft weights参数固定,只剩下Paragraph vector用梯度下降法求得,所以预测新句子时虽然也要放入模型中不断迭代求出,相比于训练时,速度会快得多。
gensim中Doc2Vec使用
TaggededDocument = gensim.models.doc2vec.TaggedDocument x_train = [] for index, col in data.iterrows(): ##如果是已经分好词的,不用再进行分词,直接按空格切分即可 word_list = str(col['Name']).split(' ') if user_drop_words: word_list = [x for x in word_list if x not in drop_words_list] document = TaggededDocument(word_list, tags=[col['tag']]) x_train.append(document) model = Doc2Vec(x_train, min_count=1, # window=1, # workers = 4, # sample=1e-5, # vector_size=500, # hs=0, #If set to 0, and `negative` is non-zero, negative sampling will be used. # negative=5, dm=0,#`distributed bag of words` (PV-DBOW) 在给定文档向量的情况下预测文档中一组随机抽样的单词的概率 dbow_words=1 #If set to 1 trains word-vectors (in skip-gram fashion) simultaneous with DBOW doc-vector training ) # model.dv[col['rName']]# 通过tags获取句子向量 model.build_vocab(x_train)#update If true, the new words in documents will be added to model’s vocab. model.train(x_train, total_examples=model.corpus_count, epochs=50) with open(file_name, 'wb') as f: pickle.dump(model, f) with open(filename, 'rb') as f: model = pickle.load(f) # 新句子的文本向量 #alpha(学习步长)设置小一些,迭代次数设置大一些 inferred_vector_dm = model .infer_vector(['','','',''], alpha=0.025, epochs=300) # 求相似的文本 sims_result = doc2vec_model.dv.most_similar([inferred_vector_dm], topn=3)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35

