
- 1mtd-utils工具的使用_mtd-utils对nor测试
- 2【IT人沟通技巧】如何学会结构化倾听_结构化倾听的案例
- 3数据安全与隐私保护:人工智能与大数据的发展与应用
- 4ChatGPT:人工智能语言模型的革命性进步_gpt系列模型在语言生成与理解中的创新与改进
- 5如何运用 AI 提升产品经理工作效率?_ai工具如何帮助互联网产品经理高效完成实际工作开展
- 6【前端开发】Vue + Fabric.js + Element-plus 实现简易的H5可视化图片编辑器_vue fabric
- 7桥接模式C++实现
- 8python实现改进版冒泡排序_改进的冒泡排序pathony
- 9MySQL面试题大全,MySQL必刷的那些面试题(2024版)
- 10【大语言模型】5分钟快速认识ChatGPT、Whisper、Transformer、GAN_chatgpt whisper
李沐学AI--DALL·E 2 + Diffusion Model_跟着李沐学ai diffusion
赞
踩
DALL·E 2

CLIP的一半的反过程
clip是 text–> text feature
image --> image fueture
对比找相似的,就能进行分类任务,将给定的图像与给定的text对应起来。
dall e2是
text – > text feature --> image feature -->(扩散模型)–> image
就能进行图像生成了,就是从text到图像。其中image feature是使用CLIP监督的。
DALL·E2原文讨论了五六个它自己的局限性/可能的发展方向,但这不影响它很强
有意思的局限:
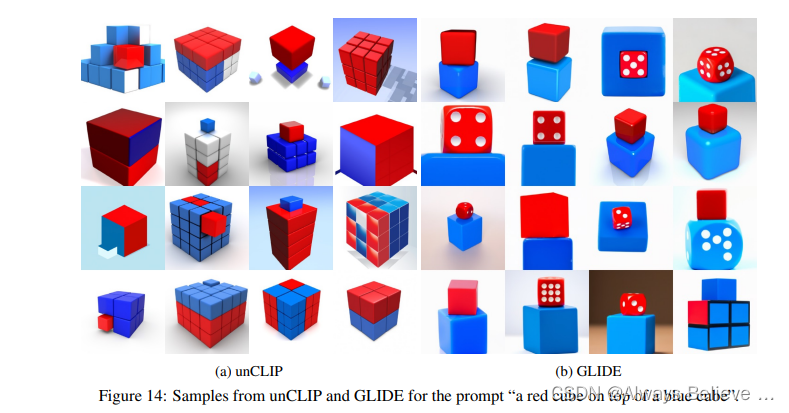
无法理解 逻辑关系,可能是因为CLIP就是找图片-文本对,找文字描述的具有某些物体所对应的图像,而不能理解上下左右等关系?

图片中的文字没有逻辑。生成的图中的文字是逻辑混乱的。
扩散模型讲解
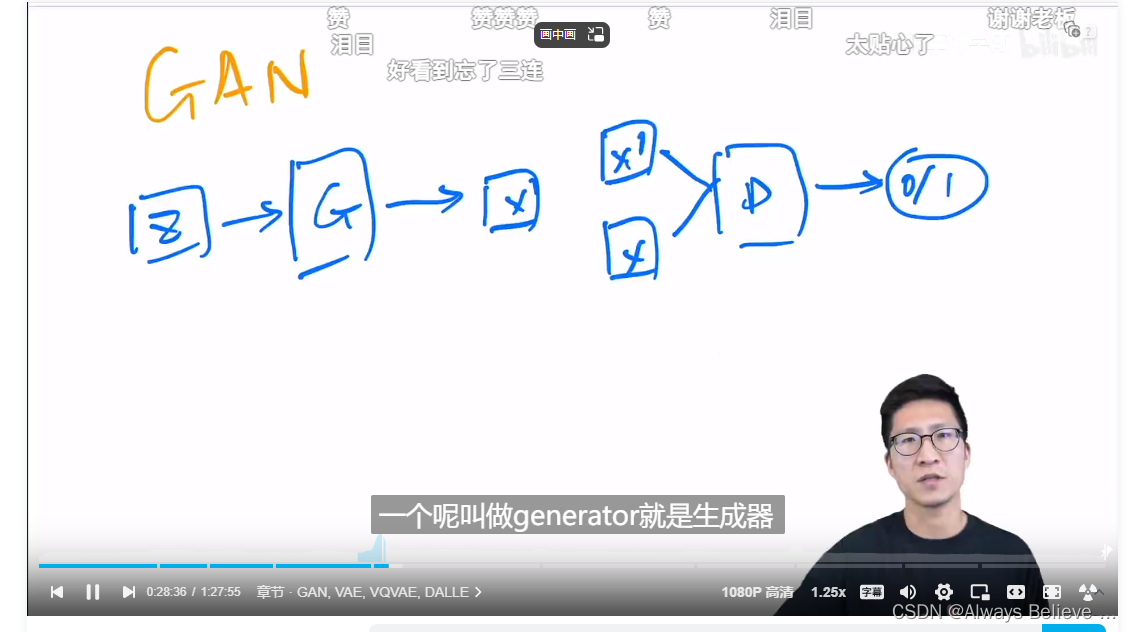
GAN:
训练不够稳定
尽可能的真实,但是多样性不高,主要是来自于噪声
不是一个概率模型(?),生成都是隐式的,不知道数据的内在分布
GAN不是概率模型的解释:
无明确的概率解释:GAN的生成器并不直接建模数据的概率分布,而是通过一个随机噪声向量生成数据,这个过程没有明确的概率解释。
无法进行精确的推断:在概率模型中,你可以根据已知的数据推断出未知的参数。但在GAN中,由于没有明确的概率模型,你无法进行这样的推断。
训练过程与概率无关:GAN的训练过程是一个最小化生成器和判别器之间的“对抗”损失函数的过程,而这个过程与概率无关。
AE: Auto-Encoder
DAE: Denoising Auto-encoder
类似的还有MAE:masked auto-encoder
主要就是去学习bottleneck那个特征,拿特征图/向量去做检测分割等任务
但是这个不是随机噪声,是用来重建的一个特征,没办法做生成任务,为什么?
VAE: Variational Auto-encoder
待仔细研读,怎么将其转化为概率模型的?
VQVAE: Vector Quantised Variational Auto-encoder
Diffusion Model
再从噪声恢复回去,就是图像生成。
DDPM 思想类似resnet,预测噪声而不是每一步中的图像
扩散模型的分数是
inception score:
IS score:
FID score:
improved DDPM
Diffusion Model Beats GAN


