
热门标签
热门文章
- 1CNN基础知识笔记_对于主干特征提取网络来说目标的局部细节是浅层还是深层,目标的边界信息是浅层还
- 2python版本升级后编译_python升级到3.*版本
- 3Hadoop-Hive 内部表/外部表 分区表/分桶表区别_hive分区表和非分区表的区别
- 4使用echartgl构建3D中国地图_echarts 3d中国地图
- 5python的赋值操作浅析_python赋值不赋地址
- 6SpringBoot中使用ElasticSearch聚合功能_sptingboot elasticsearch8 template聚合查询
- 7联想Y9000P安装ubuntu20.04问题记录_拯救者y9000p 4080装ubuntu20.04
- 8Spring Boot整合新版Spring Security:Lambda表达式配置优雅安全
- 9ArchLinux 更换系统语言安装搜狗输入法_archlinux安装搜狗输入法
- 10国内maven镜像_maven 国内镜像
当前位置: article > 正文
爬虫实战--人民网_://jhsjk.people.cn/testnew/result
作者:IT小白 | 2024-02-14 23:00:06
赞
踩
://jhsjk.people.cn/testnew/result
前言
为了巩固所学的知识,作者尝试着开始发布一些学习笔记类的博客,方便日后回顾。当然,如果能帮到一些萌新进行新技术的学习那也是极好的。作者菜菜一枚,文章中如果有记录错误,欢迎读者朋友们批评指正。
(博客的参考源码可以在我主页的资源里找到,如果在学习的过程中有什么疑问欢迎大家在评论区向我提出)
发现宝藏
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【宝藏入口】。
http://jhsjk.people.cn/testnew/result
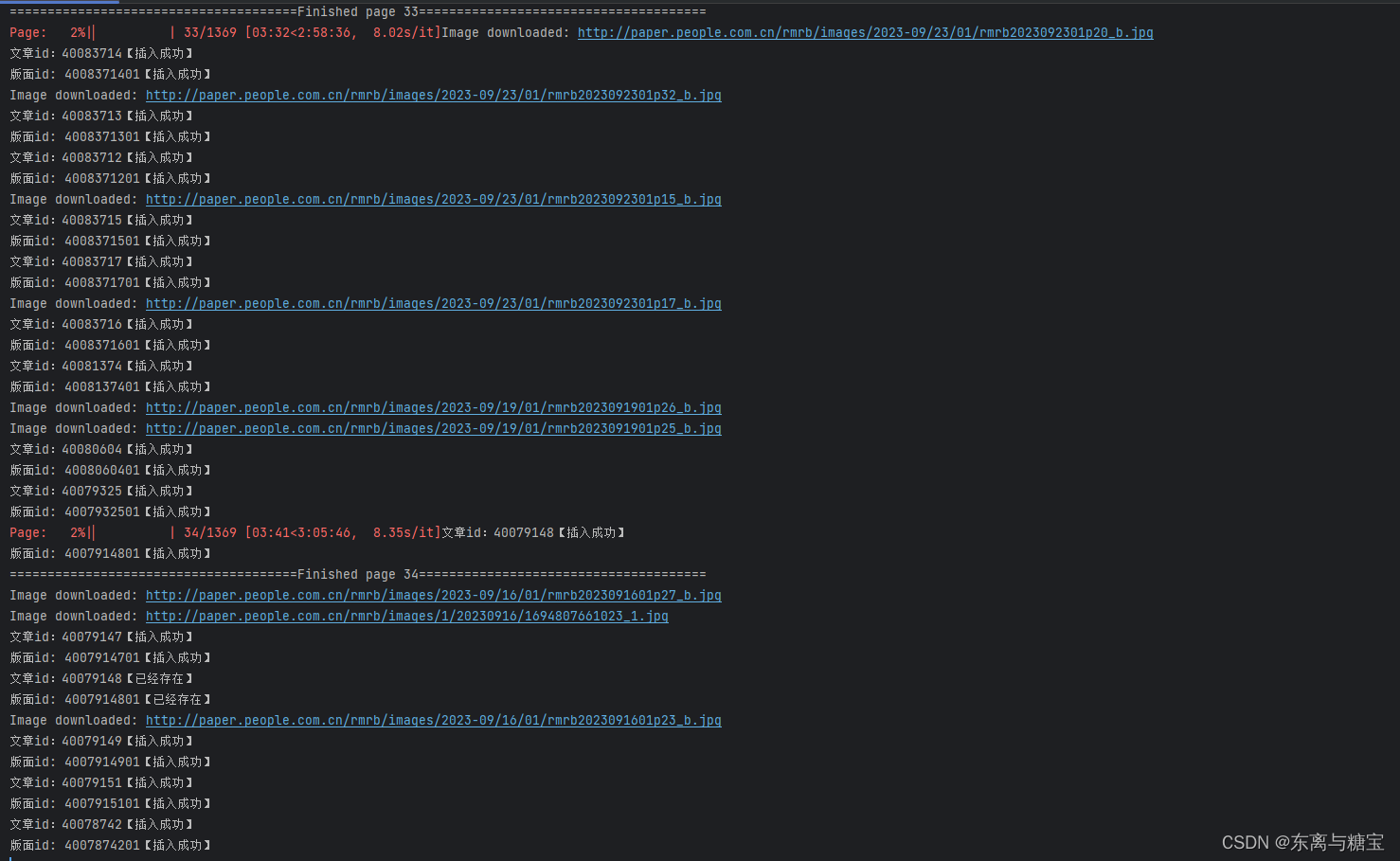
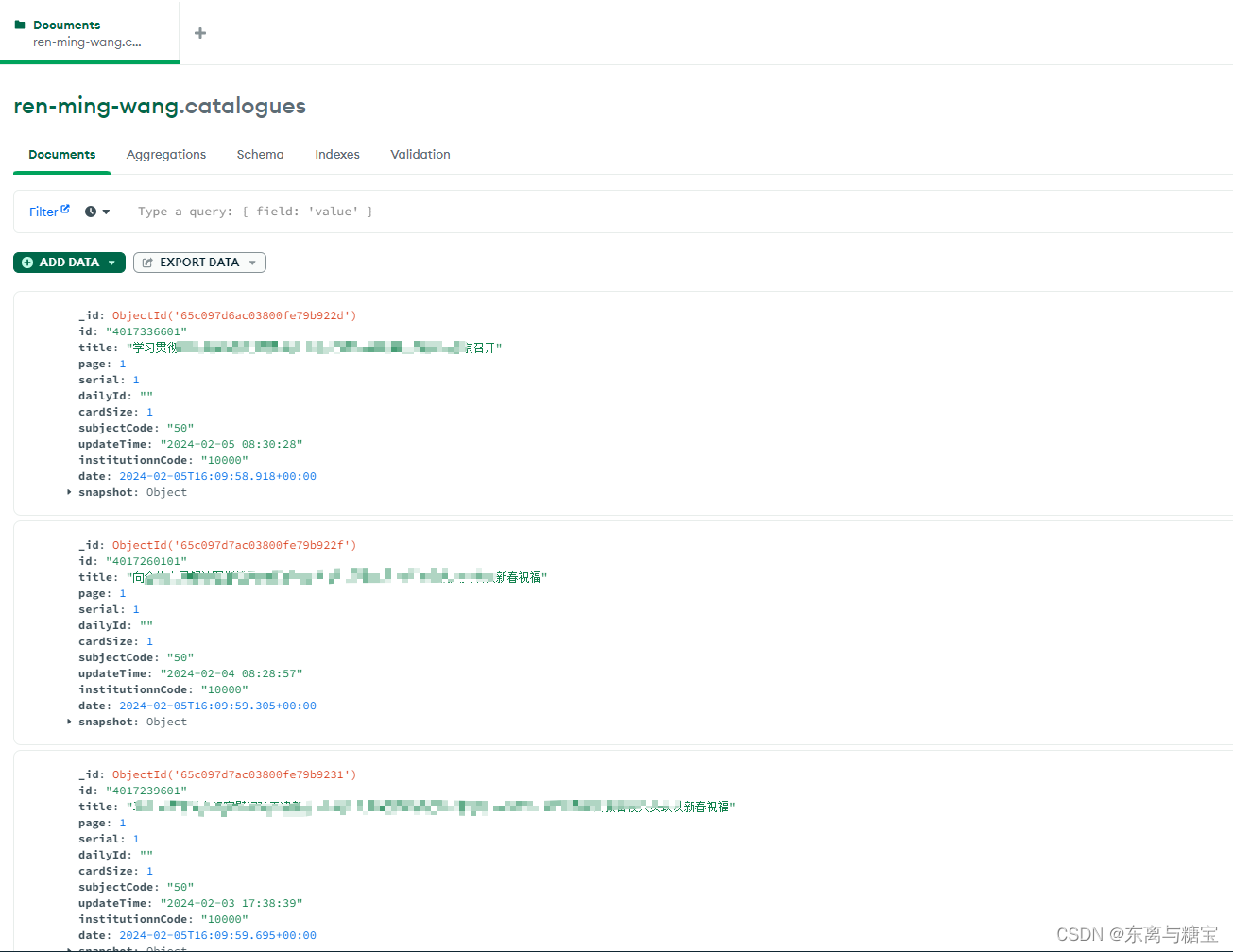
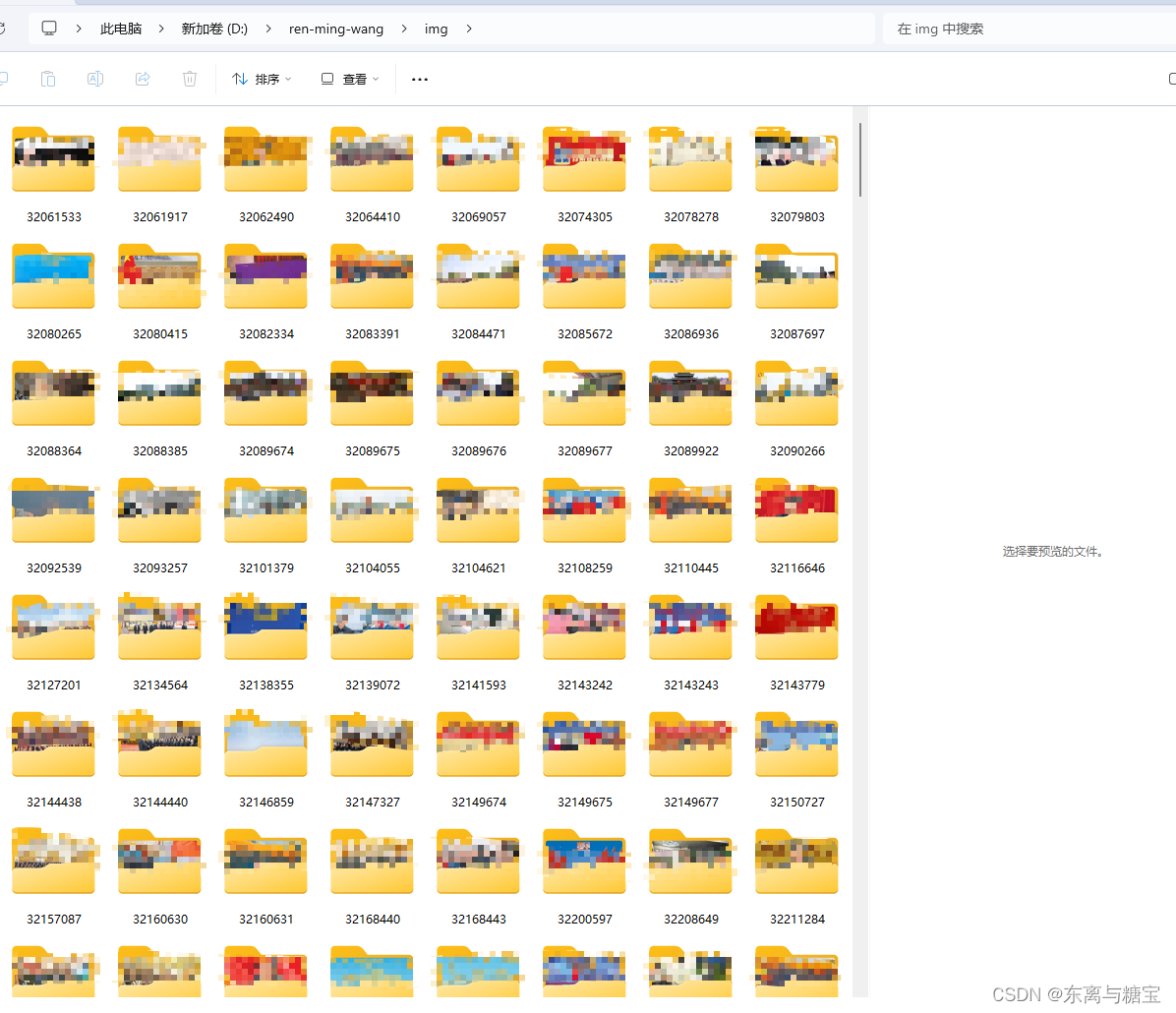
import os import re from datetime import datetime import requests import json from bs4 import BeautifulSoup from pymongo import MongoClient from tqdm import tqdm class ArticleCrawler: def __init__(self, catalogues_url, card_root_url, output_dir, db_name='ren-ming-wang'): self.catalogues_url = catalogues_url self.card_root_url = card_root_url self.output_dir = output_dir self.client = MongoClient('mongodb://localhost:27017/') self.db = self.client[db_name] self.catalogues = self.db['catalogues'] self.cards = self.db['cards'] self.headers = { 'Referer': 'https://jhsjk.people.cn/result?', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/119.0.0.0 Safari/537.36', 'Cookie': '替换成你自己的', } # 发送带参数的get请求并获取页面内容 def fetch_page(self, url, page): params = { 'keywords': '', 'isFuzzy': '0', 'searchArea': '0', 'year': '0', 'form': '', 'type': '0', 'page': page, 'origin': '全部', 'source': '2', } response = requests.get(url, params=params, headers=self.headers) soup = BeautifulSoup(response.text, 'html.parser') return soup # 解析请求版面 def parse_catalogues(self, json_catalogues): card_list = json_catalogues['list'] for list in card_list: a_tag = 'article/'+list['article_id'] card_url = self.card_root_url + a_tag card_title = list['title'] updateTime = list['input_date'] self.parse_cards(card_url, updateTime) date = datetime.now() catalogues_id = list['article_id']+'01' # 检查重复标题 existing_docs = self.catalogues.find_one({'id': catalogues_id}) if existing_docs is not None: print(f'版面id: {catalogues_id}【已经存在】') continue card_data = { 'id': catalogues_id, 'title': card_title, 'page': 1, 'serial': 1, # 一个版面一个文章 'dailyId': '', 'cardSize': 1, 'subjectCode': '50', 'updateTime': updateTime, 'institutionnCode': '10000', 'date': date, 'snapshot': { } } self.catalogues.insert_one(card_data) print(f'版面id: {catalogues_id}【插入成功】') # 解析请求文章 def parse_cards(self, url, updateTime): response = requests.get(url, headers=self.headers) soup = BeautifulSoup(response.text, "html.parser") try: title = soup.find("div", "d2txt clearfix").find('h1').text except: try: title = soup.find('h1').text except: print(f'【无法解析该文章标题】{url}') html_content = soup.find('div', 'd2txt_con clearfix') text = html_content.get_text() imgs = [img.get('src') or img.get('data-src') for img in html_content.find_all('img')] cleaned_content = self.clean_content(text) # 假设我们有一个正则表达式匹配对象match match = re.search(r'\d+', url) # 获取匹配的字符串 card_id = match.group() date = datetime.now() if len(imgs) != 0: # 下载图片 self.download_images(imgs, card_id) # 创建文档 document = { 'id': card_id, 'serial': 1, 'page': 1, 'url' : url, 'type': 'ren-ming-wang', 'catalogueId': card_id + '01', 'subjectCode': '50', 'institutionCode': '10000', 'updateTime': updateTime, 'flag': 'true', 'date': date, 'title': title, 'illustrations': imgs, 'html_content': str(html_content), 'content': cleaned_content } # 检查重复标题 existing_docs = self.cards.find_one({'id': card_id}) if existing_docs is None: # 插入文档 self.cards.insert_one(document) print(f"文章id:{card_id}【插入成功】") else: print(f"文章id:{card_id}【已经存在】") # 文章数据清洗 def clean_content(self, content): if content is not None: content = re.sub(r'\r', r'\n', content) content = re.sub(r'\n{2,}', '', content) # content = re.sub(r'\n', '', content) content = re.sub(r' {6,}', '', content) content = re.sub(r' {3,}\n', '', content) content = content.replace('<P>', '').replace('<\P>', '').replace(' ', ' ') return content # 下载图片 def download_images(self, img_urls, card_id): # 根据card_id创建一个新的子目录 images_dir = os.path.join(self.output_dir, card_id) if not os.path.exists(images_dir): os.makedirs(images_dir) downloaded_images = [] for img_url in img_urls: try: response = requests.get(img_url, stream=True) if response.status_code == 200: # 从URL中提取图片文件名 image_name = os.path.join(images_dir, img_url.split('/')[-1]) # 确保文件名不重复 if os.path.exists(image_name): continue with open(image_name, 'wb') as f: f.write(response.content) downloaded_images.append(image_name) print(f"Image downloaded: {img_url}") except Exception as e: print(f"Failed to download image {img_url}. Error: {e}") return downloaded_images # 如果文件夹存在则跳过 else: print(f'文章id为{card_id}的图片文件夹已经存在') # 查找共有多少页 def find_page_all(self, soup): # 查找<em>标签 em_tag = soup.find('em', onclick=True) # 从onclick属性中提取页码 if em_tag and 'onclick' in em_tag.attrs: onclick_value = em_tag['onclick'] page_number = int(onclick_value.split('(')[1].split(')')[0]) return page_number else: print('找不到总共有多少页数据') # 关闭与MongoDB的连接 def close_connection(self): self.client.close() # 执行爬虫,循环获取多页版面及文章并存储 def run(self): soup_catalogue = self.fetch_page(self.catalogues_url, 1) page_all = self.find_page_all(soup_catalogue) if page_all: for index in tqdm(range(1, page_all), desc='Page'): # for index in tqdm(range(1, 50), desc='Page'): soup_catalogues = self.fetch_page(self.catalogues_url, index).text # 解析JSON数据 soup_catalogues_json = json.loads(soup_catalogues) self.parse_catalogues(soup_catalogues_json) print(f'======================================Finished page {index}======================================') self.close_connection() if __name__ == "__main__": crawler = ArticleCrawler( catalogues_url='http://jhsjk.people.cn/testnew/result', card_root_url='http://jhsjk.people.cn/', output_dir='D:\\ren-ming-wang\\img' ) crawler.run() # 运行爬虫,搜索所有内容 crawler.close_connection() # 关闭数据库连接

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/82429
推荐阅读
相关标签

