
- 1word-embedding_def forward(self,inp): out = self.fc(inp) return o
- 2如何申请与使用携程API接口_携程api开放平台
- 3手写RPC-令牌桶限流算法实现,以及常见限流算法
- 4单例模式以及线程安全问题_单例模式线程不安全
- 5基于java和百度AI人脸动漫头像生成系统设计与实现_人物头像卡通系统设计与实现
- 6【数据库】 mysql数据库管理工具 Navicat平替工具 免费开源数据库管理工具_navacat平替
- 7营销广告电商行业如何实现降本提效?看这篇就够了!_降低电商营销成本
- 8我开源的H5商城2.0版本发布,强烈推荐_开源的h5移动端商场项目
- 9Langflow系列教程之 09 快速搭建AI 文档质量检查,从本地内存加载的文档构建问答聊天机器人(教程含源码)_langflow 本地运行源码
- 10基于java swing和mysql实现的学生选课成绩信息管理系统(源码+数据库+ER图文档+运行指导视频)_javaswing+数据库学生管理系统
数据分析-深度学习 NLP Day3句法分析_pcfg是cfg的扩展,可用于上下文无关文法的句法分析,在给定一个pcfg规则集后,以下哪
赞
踩
第六章句法分析
在本章中,你将学到与句法分析相关的一些算法和技术 。 很多技术手段可以用来实 现句法分析,包括基于规则的和基于统计的,在本章中读者将会了解其基本原理和使用方法 。
本章要点主要如下:
句法分析及其难点
句法分析相关数据和技术
基于 Stanford Parser 的句法分析实战
6.1 句法分析概述
在自然语言处理中,机器翻译是一个重要的课题,也是 NLP 应用的主要领域,而句 法分析是机器翻译的核心数据结构。 句法分析是自然语言处理的核心技术,是对语言进 行深层次理解的基石 。 句法分析的主要任务是识别出句子所包含的句法成分以及这些成 分之间的关系,一般以句法树来表示句法分析的结果。 从 20 世纪 50 年代初机器翻译课 题被提出时算起,自然语言处理研究已经有 60 余年的历史,句法分析一直是自然语言处 理前进的巨大障碍 。 句法分析主要有以下两个难点:
歧义 。 自然语言区别于人工语言的一个重要特点就是它存在大量的歧义现象。 人 类自身可以依靠大量的先验知识有效地消除各种歧义,而机器由于在知识表示和 获取方面存在严重不足,很难像人类那样进行句法消歧 。
搜索空间 。 句法分析是一个极为复杂的任务,候选树个数随句子增多呈指数级增 长,搜索空间巨大。 因此,必须设计出合适的解码器,以确保能够在可以容忍的 时间内搜索到模型定义最优解 。
句法分析( Parsing ) 是从单词串得到句法结构的过程,而实现该过程的工具或程序 被称为句法分析器( Parser ) 。 句法分析的种类很多,这里我们根据其侧重目标将其分为 完全句法分析和局部句法分析两种。 两者的差别在于,完全句法分析以获取整个句子的 句法结构为目的;而局部句法分析只关注于局部的一些成分,例如常用的依存句法分析 就是一种局部分析方法 。
句法分析中所用方法可以简单地分为基于规则的方法和基于统计 的方法两大类 。 基 于规则 的方法在处理大规模真实文本时,会存在语法规则 覆盖有 限、系统可迁移差等 缺陷 。 随着大规模标注树库的建立,基于统计学习模型的句法分析方法开始兴起,句 法分析器的性能不断提高,最典型的就是风靡于 20 世纪 70 年代的 PCFG ( Probabil istic Context Free Grammar ),它在句法分析领域得到了极大的应用,也是现在句法分析中常 用的方法 。 统计句法分析模型本质是一套面向候选树的评价方法,其会给正确的句法树 赋予一个较高的分值,而给不合理的句法树赋予一个较低的分值,这样就可以借用候选 句法树的分值进行消歧。 在本章中,我们将着重于基于统计的句法分析方法(简称统计 分析方法)的介绍 。
6.2 句法分析的数据集与评测方法
6.2.1 句法分析的数据集
统计学习方法多需要语料,数据的支撑,统计句法分析也不例外 。 相较于分词或词性 标注,句法分析的数据集要复杂很多,其是一种树形的标注结构,因此又称树库 。 图 6 - 1 所示是一个典型的句法树 。
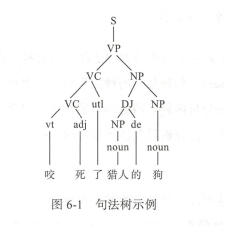
目前使用最多的树库来自美国宾夕法尼亚大学加工 的英文宾州树库( Penn TreeBank, PTB ) 。 PTB 的前身为 ATIS ( Air Travel Information System ) 和 WSJ ( Wall Street Journa ) 树库, 具有较高 的一致性和标注准确率。
中文树库建设较晚 ,比较著名 的有中文宾州树库 ( Chinese TreeBank, CTB ) 、清华 树库( Tsinghua Chinese TreeBank, TCT )、台湾中研院树库 。 其 中 CTB 是宾夕法尼亚大 学标注 的汉语句法树库, 也是 目前绝大多数 的中文句法分析研究的基准语料库 。 TCT 是 清华大学计算机系智能技术与系统国家重点实验室人员从汉语平衡语料库中提取出 100 万规模的汉字语料文本,经过自动句法分析和人工校对,形成的高质量的标注有完整句 法结构的中文句法树语料库 。 Sinica TreeBank 是 中国台 湾 中研院词库小组从中研院平衡 语料库中抽取句子,经过电脑自动分析成句法树,并加以人工修改 、 检验后所得的成果 。
不同的树库有着不同的标记体系 使用时切忌使用一种树库的句法分析器,然后用其他树库的标记体系来解释。 由于树库众多,这里不再讲述具体每一种树库的标记规范,图 6 -2 所示为清华树库的部分标记集 。

