
- 1Transformer模型-decoder解码器,target mask目标掩码的简明介绍_为什么要在encoder前做掩码
- 2JsonConvert.DeserializeObject 转实体对象时当中的空值处理
- 3Django计算机毕业设计基于数据可视化技术电子书城管理系统(程序+lw)Python_基于django的软著
- 4基于springboot后台微信商城购物小程序系统设计与实现_spring boot购物小程序
- 5OpenCV固定矩阵类Matx、矩阵类Mat初始化方法汇总_opencv mat初始化
- 6PostgreSQL的逻辑架构
- 7Unity - 性能优化实战03 - Texture基础概念介绍_unity texture设置
- 82024年职业院校大数据实验室建设及大数据实训平台整体解决方案
- 9Git上fork后的代码仓库如何与原仓库进行同步_github 的项目 fork以后是不是就可以同步代码了
- 10langchain agent 使用外部工具示例_langchain agent自定义outputparser
大促高并发背后的数据库技术解读 | OceanBase特性解析_支持高并发的内存数据库
赞
踩
无论是在“双11”还是“618”这样的年度大促,还是在如今促销活动“常态化”的背景下,如何通过合理设计应用架构和数据库架构来应对流量骤增,确保用户在业务高峰时仍能享受到如丝般顺滑的购物体验,并合理控制成本,已成为各家企业面临的长期挑战。
OceanBase凭借其稳定支撑10余年“双11”的丰富经验,以及强大的在线扩缩容能力和高并发低延迟特性,能够迅速响应业务负载的变动,且对业务系统保持完全透明,从而在秒杀等极端场景下大幅提升系统的吞吐能力,并有效降低成本。其背后的关键技术点有哪些,可以通过本文进行了解一二。
点击查看 OceanBase大促弹性解决方案的详细介绍 >>
案例阅读
支付宝:稳定支撑每秒百万笔支付请求,支付宝数据库架构的过去、现在与未来
OceanBase 高并发关键技术介绍
数据库系统是属于既要又要的系统,既要保证数据库的正确性,又要高并发。在高并发的场景下保证数据库的正确性,关键在于保证事务的 ACID。以 ACID 的 I(Isolation) 为例,I 表示的是在并发事务的场景下,事务并发执行的效果与事务串行执行的效果完全相同,这种隔离级别就是所说的可串行化隔离级别,但是可串行化隔离级别的代价比较大,往往伴随着大量的冲突等待或者冲突失败。
为了提供更好的并发执行性能,数据库不得不放宽调度的验证,允许更多非可串行化的调度被执行,多个并发的事务执行结果可能会不再等价于任何一种串行执行的结果,为了规范用户使用,数据库需要给用户做出保证:什么样的错误会发生,而什么样的错误不会发生,这些不同的保证就是数据库的隔离级别。
SQL-92 标准中基于事务并发执行过程中可能出现的三种导致数据错误的现象定义了一套隔离级别,按照这三种现象的容忍程度不同定义出了4个不同的隔离级别。1995年发表的一篇论文《A critique of ANSI SQL Isolation Levels》,论文指出了 SQL-92 标准中关于隔离级别的定义存在的一些问题:
- SQL-92 里关于异常现象的定义过于狭隘,即使排除了3个异常现象也没有办法做到可串行化;
- 新增了几种新的异常现象,脏写、丢失更新、读倾斜、写倾斜;
分布式事务一致性
并发事务的场景下,分布式数据库还要面临比单机数据库更多的挑战。
首先是读写并发问题。
在分布式数据库系统里面,通常会采用两阶段提交协议或者事务回滚补偿机制来保证分布式事务提交的原子性,不管是采用哪种机制都会面临读写并发问题。以两阶段提交为例,两阶段提交分为 prepare 阶段和 commit 阶段,当所有的参与者都 prepare 成功之后,协调者会向所有的参与者发起 commit 请求,协议上没有办法保证所有的参与者都在同一时刻 commit 成功。
假设事务 T1 发起 A 向 B 转账50块钱,事务 T1 在提交过程中,A 已经提交成功,B 正在提交,并发事务 T2 读到的 A 和 B 分别是多少呢?

另外一个是分布式数据库系统经常会面临的外部一致性问题。
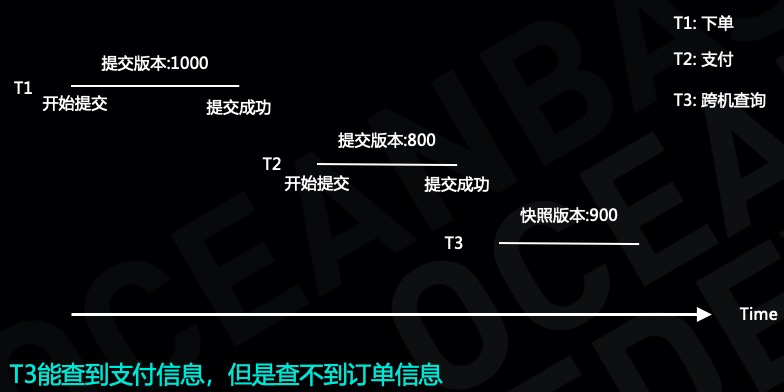
假设用户在淘宝上下了一个订单,并且支付成功了。
假设订单事务为 T1,支付事务为 T2,T1 和 T2 位于不同的服务器上,事务 T1 和事务 T2 分别各自提交,事务 T1 的提交版本号是 1000,事务 T2 的提交版本号是 800,假设有一个读事务 T3,他的快照版本号是 900,T3 能够读到支付成功的信息,但是读不到订单信息,显然这个违背了业务的语义。
并发事务调度算法
以上我们介绍了并发事务面临的挑战,并发事务的行为取决于并发事务的调度,常见的并发事务调度方法有以下几种:
- 首先是两阶段锁:两阶段锁是一种悲观并发控制的方法,保证了并行事务的可串行化调度,通过调整读锁和加锁的策略可以实现不同的隔离级别;
- 其次是乐观的并发控制,主要有时间序和 OCC;
- 最后是目前主流数据库库经常会用到的多版本并发控制;
这里我们主要介绍两阶段锁和多版本并发控制。
两阶段锁
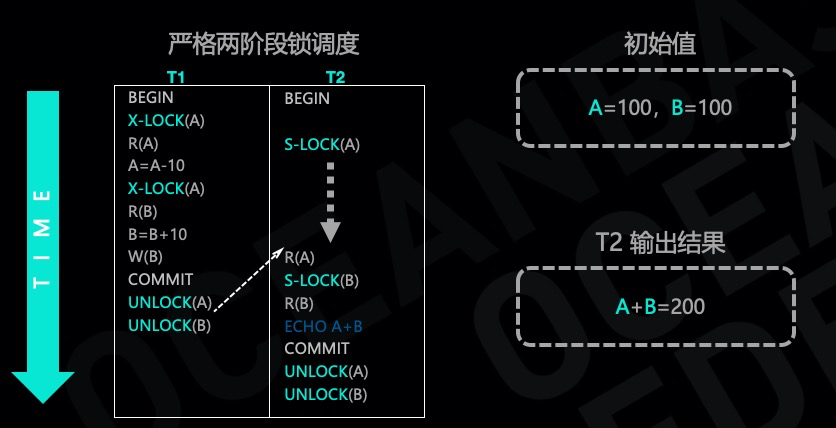
所谓的两阶段锁协议,顾名思义就是协议分为两个阶段,加锁阶段和解锁阶段,在加锁阶段不允许解锁,在加锁阶段向锁管理器申请加锁请求,锁可以是读锁也可以是写锁,当加锁不成功的时候需要等待,一旦进入解锁阶段就不允许再加锁,数据库实践中通常采用严格的两阶段锁,在事务 commit 成功之后再解锁。
看一个严格两阶段锁调度的例子,假设事务 T1,A 向 B 转账10块钱,转账过程中分别在 A 和 B 上加互斥锁,事务 T2 读取 A 和 B 的账户余额,需要加读锁,由于事务 T1 持有互斥锁,因此事务 T2 的读请求需要等待,等到事务 T1 提交成功并解锁,最后事务 T2 读到 A=90、B=110,满足两个账户加起来的和等于 200 这个约束。
两阶段锁的协议实现起来比较简单,但是当事务发现锁冲突的时候事务需要等待,可能会降低数据库的并发能力,其次多个并发事务由于彼此抢锁,有可能出现死锁的可能性。
多版本并发控制
为了解决读写冲突的问题,很多数据库实现的时候采用了多版本并发控制的机制,该机制最大的好处是读不阻塞写,写不会阻塞读,大大提高了系统的并发能力。
以 MySQL innodb 多版本并发控制的实现为例。Innodb 数据块记录的是最新版本的数据,通过 undo log 记录了多个旧版本的数据,innodb 每一行上保存了两个隐藏的字段,事务 ID 字段和回滚指针,分别用于记录修改当前行的事务 ID 以及指向旧版本数据的指针,沿着回滚可以找到多个旧版本的数据。事务在对 innodb 修改之前首先会用互斥锁锁定该行,避免其他事务并发修改,然后写 undo log 和 redo log,最后修改当前行的数据并且将行上隐藏的事务 ID 修改为本事务 ID,将回滚指针指向 undo log,以上是事务修改的简要过程。
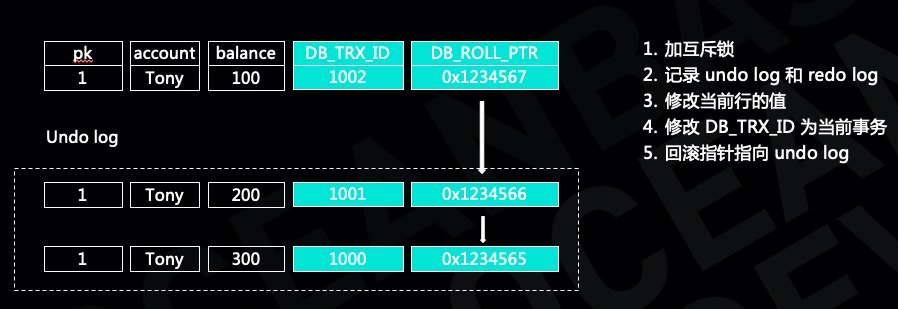
下面我们看一下事务的读取过程,事务在读取数据之前首先生成一个 Read view,代表当前事务的可见范围。Read view 包含几个信息,首先是本事务的事务 ID,其次是当前活跃事务列表以及当前活跃事务的上限和下限。确定了 Read view 之后就相当于确定了事务的快照,然后读取行记录,根据 Read view 对行记录进行检查,如果当前行不可见,则通过回滚指针继续查找旧版本的数据。首先检查行上的事务 ID,如果行上的事务 ID 在当前的活跃事务列表里或者行上的事务 ID 大于 Read view 的最大事务 ID,则行上的数据不可见,需要找旧版本的数据,否则数据可见。

多版本管理
OceanBase 采用基于互斥锁的多版本并发控制,其中 OceanBase 存储引擎采用的是 LSM tree 架构,将数据拆分成静态数据和动态数据,动态数据保存在 Memtable 中并定期 dump 到磁盘中,Memtable 采用 B+tree 以及Hash 双索引结构对数据进行存储,其中 B+tree 用于范围查询,Hash 用于单行查询。
B+tree 的叶子节点保存了行数据的元信息,元信息里面有很多字段,这里只介绍3个字段,主键信息、锁信息以及链表指针:
- 锁信息表示是否有事务持有行锁,事务在修改数据之前需要先加行锁;
- 链表信息指向多个版本的数据,每个版本只保存增量信息,比如某一次修改只修改一个字段,增量信息只会记录该字段的变化情况;
从下图可以看出,主键等于1这一行记录发生过3次变更,第1次变更是一个插入操作,事务版本号是1000,第2次变更修改了b字段,事务版本号是1005,第3次变更修改了b字段,事务版本号是无穷大,表示当前事务还没有提交。
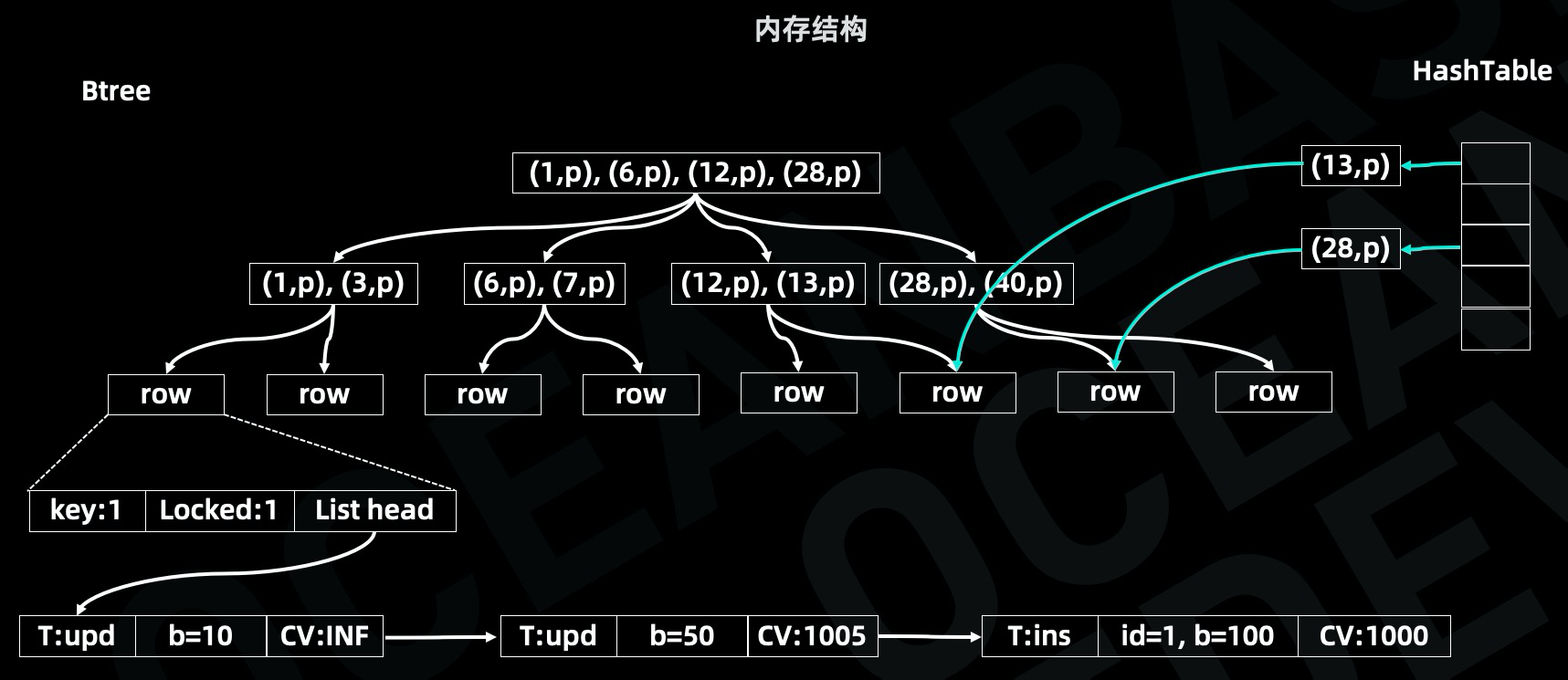
多版本并发控制
OceanBase 分布式数据库系统对事务进行调度,确保并发事务不会出现一致性问题。假设有3个并发事务,分别为读写事务 T1, 只读事务 T2,读写事务 T3,其中事务 T1 还没有提交,持有行的行锁。
事务 T3 在对行1进行修改之前需要先持有行1的行锁,由于行1的行锁被事务 T1 持有,因此 T3 需要等待,直到事务T1提交成功并且将行锁解开。事务 T2 是一个只读事务,事务的快照版本号是1008,在读取之前首先通过索引结构找到行的元数据,然后根据快照版本号找到比快照版本号小的最大提交版本号的数据。从下图可以看出事务 T2 能够读到提交版本号是1005的数据。以上就是 OceanBase 内部的读写并发控制机制,通过行上的互斥锁来解决写写冲突的问题,通过多版本机制保证写不阻塞读,读不阻塞写。
OceanBase 的多版本并发控制实现非常的简单,快照版本就是一个时间戳,通过比较时间戳的大小就可以确定事务的可见性,不需要维护活跃事务。在有些分布式数据库系统里,维护了全局事务管理器,这个全局事务管理器本质上就是用来确定事务的快照的,当并发的事务比较多的时候,全局事务管理器容易成为集群的瓶颈,OceanBase 不需要维护全局事务管理器。还有一点就是 OceanBase 行的元数据上保存了锁信息,不需要额外的锁管理器。

回到开头讲到的读写并发问题,事务 T1 在提交过程中,A 已经提交成功,B 正在提交,为了解决读写并发问题有些分布式系统采用两阶段锁方案,在读的时候需要加读锁确保在事务 T1 提交成功之后事务 T2 可以读到。
在 OceanBase 分布式数据库系统里,读请求首先会根据快照版本号找到对应版本的数据,假设事务 T1 的提交版本号小于事务 T2 的快照版本号,那么事务 T2 可以读到 T1 的修改,事务 T2 在读 B 这一行数据的时候,如果发现 B 上处于 committing 状态,那么事务 T2 需要等待,直到 B 这一行数据提交成功。这样就可以保证事务 T2 既能够读到 A 上的数据还能读到 B 上的数据。在这种场景下事务 T2 需要等待的时间窗口,就是两阶段提交过程中从 prepare 阶段到 commit 阶段这个时间窗口,这个时间窗口要远远小于两阶段锁的等锁时间。
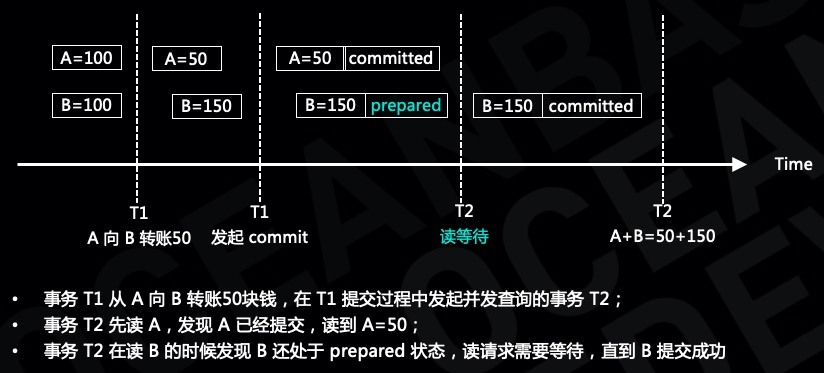
外部一致性是分布式数据库系统要解决的另外一个问题。
假设用户在淘宝上要买一个手机,首先用户先下单,下单成功之后发起订单支付。下单和支付是两个不同的事务,我们假设这两个事务分别是 T1 和 T2,由于这两个事务分别在两个不同的机器上执行,各自生成提交版本号,事务 T1 的提交版本号是1000,事务 T2 的提交版本号是800,假设事务 T3 的快照版本号是900,事务 T3 会出现能够读到订单的支付信息,但是读不到订单信息,显然不符合事务的先后顺序,这个就是外部一致性。
全局时间戳服务
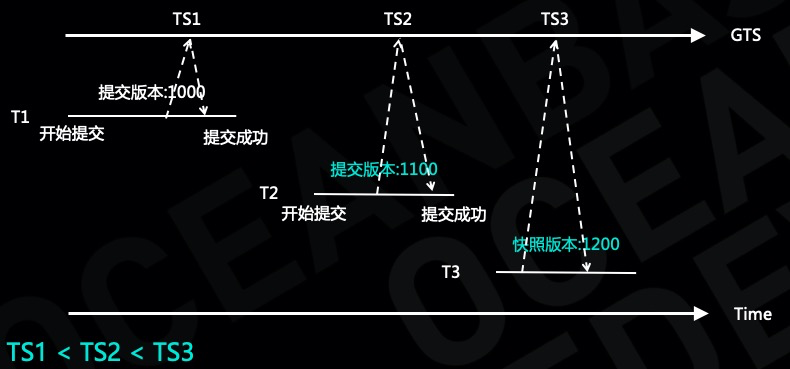
为了解决外部一致性的问题,OceanBase 引入了全局时间戳服务,通过全局时间戳为每个事务分配快照版本及提交版本号。
从图上我们可以看出事务 T1 和事务 T2 在提交过程中分别向全局时间戳服务申请一个时间作为事务的提交版本号,事务 T3 也从全局时间戳申请一个时间戳做为事务的快照,显然全局时间戳服务可以保证 TS1 < TS2 < TS3,假如事务 T3 能够读到 T2 修改的数据,那么 T3 肯定也能够读到 T1 修改的数据,解决了外部一致性的问题。
提前解行锁
在单机数据库里面会碰到热点行更新的问题,但是在分布式数据库系统里热点行更新的问题会更加的明显,热点行更新的性能取决于行锁持锁的时间,行锁持锁的时间越长热点行更新的性能会越差。
在分布式系统里事务的延迟会比单机事务的延迟要大一些,事务持锁的时间会更长,另外在三地五中心的部署方式里,日志同步的延迟可能会超过几十ms,大大影响热点行更新的性能。为了缓解热点行更新的问题,OceanBase 采用提前解行锁的方案来缓解热点行更新的问题。
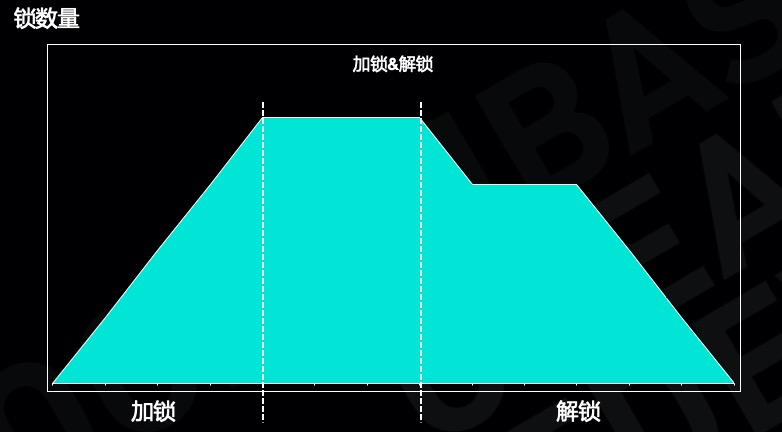
传统数据库在执行过程中加行锁,在最后事务提交的时候等待事务持久化成功之后再解锁,这个是普通事务的执行过程。在 OceanBase 热点行更新的方案里,事务在执行过程中也需要加行锁,但是在收到用户 commit 请求之后,在事务持久化成功之前就可以解锁。从下图可以看出在优化之前事务是串行执行的,采用提前解行锁方案之后,事务在日志持久化之前后续的事务就可以加锁成功,大大降低事务持锁的时间。

我们做了一些测试,测试了 oltp update 事务执行过程中各个阶段的时间消耗,其中生成执行计划大概需要 60us,dml 操作大概需要 50us,填充事务日志大概需要 33us,日志同步大概需要 170us,可以算出事务执行过程中持锁的总时间大概是 270us。提前解行锁优化之后,事务的持锁时间降低了 65%,相应的热点行更新的性能可以达到原来性能的3倍。

在上面介绍提前解行锁这个方案的时候,可能有同学已经想到,假如前面一个事务持久化失败,那后续的事务应该怎么处理呢?
如果一个事务失败了,那么后续的事务都需要回滚。这个就是通常所说的级联回滚,在数据库论文里经常会提到我们应该避免级联回滚,但是在实际的应用场景里,事务提交失败的比例是非常低的,因此出现级联回滚的可能性非常低,在实际的测试来看也能够证明这一点。
为了支持事务级联回滚,需要为每个热点行维护事务间的依赖关系,将修改同一行的多个事务串成一个链表,确保在某个事务失败的时候能够将后继的事务都回滚掉。比如事务 T1、T2、T3,对同一热点行数据做了修改,事务 T1 在持久化成功之前提前把行锁解开,事务 T2 就可以加锁成功,相应的 T2 提前解行锁,T3 也可以加锁成功。因此事务 T1、T2、T3 构成了一个依赖关系,事务 T3 依赖事务 T2,事务 T2 依赖事务 T1,这些依赖关系形成一个链表,当事务 T1 最终持久化失败的事务,事务 T2 和事务 T3 需要回滚,否则会出现正确性问题。

