
- 1YOLOv9独家原创改进|加入幽灵卷积Ghost Convolution模块,轻量化!_ghostconv
- 2Android Studio 配置flutter开发环境教程(超详细)_android studio flutter edit run configuration 如何填写
- 3汽车软件开发:ASPICE与ISO26262标准下的质量管理与控制实践
- 4程序员妻子的自述_程序员老婆是别人养的狗完整
- 510个团队建设技巧
- 6一级建造师-通信-知识点&口诀整理_换效抽骨抽,增效迅增维一建通信图
- 7C++物理设计——组件
- 8svn(代码管理)
- 9[ctf.show.reverse] 36D杯 神光_ctfshow神光
- 10华为OD 嵌入式开发工程师面经
终于有人把监督学习、强化学习和无监督学习讲明白了
赞
踩
导读:本文将讨论监督学习、无监督学习和强化学习这三种类型的机器学习。
作者:塞巴斯蒂安·拉施卡(Sebastian Raschka)、瓦希德·米尔贾利利(Vahid Mirjalili)
来源:大数据DT(ID:hzdashuju)
了解三者之间的根本差别,并通过概念性的示例,我们将形成可应用于实际问题领域的见解,如图1-1所示。

▲图 1-1
01 用监督学习预测未来
监督学习的主要目标是从有标签的训练数据中学习模型,以便对未知或未来的数据做出预测。在这里“监督”一词指的是已经知道训练样本(输入数据)中期待的输出信号(标签)。
图1-2总结了一个典型的监督学习流程,先为机器学习算法提供打过标签的训练数据以拟合预测模型,然后用该模型对未打过标签的新数据进行预测。

▲图 1-2
以垃圾邮件过滤为例,可以采用监督机器学习算法在打过标签的(正确标识垃圾与非垃圾)电子邮件的语料库上训练模型,然后用该模型来预测新邮件是否属于垃圾邮件。
带有离散分类标签的监督学习任务也被称为分类任务,例如上述的垃圾电子邮件过滤示例。监督学习的另一个子类被称为回归,其结果信号是连续的数值。
1. 用于预测类标签的分类
分类是监督学习的一个分支,其目的是根据过去的观测结果来预测新样本的分类标签。这些分类标签是离散的无序值,可以理解为样本的组成员关系。前面提到的邮件垃圾检测就是典型的二元分类任务,机器学习算法学习规则以区分垃圾和非垃圾邮件。
图1-3将通过30个训练样本阐述二元分类任务的概念,其中15个标签为负类(-),另外15个标签为正类(+)。该数据集为二维,这意味着每个样本都与x1和x2的值相关。现在,可以通过监督机器学习算法来学习一个规则——用一条虚线来表示决策边界——区分两类数据,并根据x1和x2的值为新数据分类。
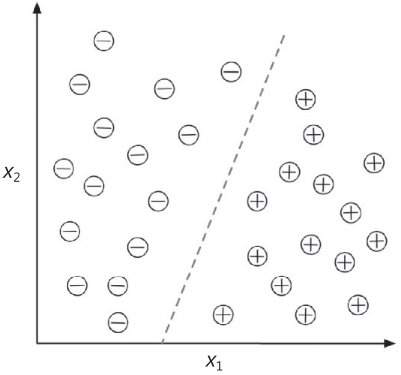
▲图 1-3
但是,类标签集并非都是二元的。经过监督

