
- 1JimuReport 积木报表 v1.7.6 版本发布,免费的低代码报表_积木报表v1.7.6 源码
- 2【ATT&CK】守株待兔式的水坑攻击_常见水坑攻击识别
- 3C++——new关键字_c++ new
- 4python cv2包的读取和保存_cv2.save
- 5Windows server 16/19/22_windowsserver2016镜像下载
- 6句向量训练总结_句子向量
- 7信息化对决策的支撑_信息对决策的支持表现在哪些方面
- 8git add 多个文件和文件夹的方法_git add 文件夹
- 9微服务网关Spring Cloud Gateway深度解析!轻松学会各种高级配置,收藏了!_springcloud gateway
- 10前端开发质量保证指南_前端如何进行质量管理
【论文阅读】零样本目标检测:鲁棒的区域特征合成器用于目标检测
赞
踩
摘要
- 零样本目标检测(Zero-shot object detection)旨在结合类语义向量来实现在给定无约束测试图像的情况下检测(可见和)未见过的类。
- 这一研究领域的核心挑战:如何合成与真实样本一样具有类内多样性和类间可分性的鲁棒区域特征(对于未见对象),从而可以实现强大的未见目标检测器。
- 为了应对这些挑战,研究者构建了一个新颖的零样本目标检测框架,其中包含一个类内语义发散组件和一个类间结构保留组件。
1. 类内语义发散组件:前者用于实现一对多映射,从每个类语义向量中获取不同的视觉特征,防止将真实的看不见的物体误分类为图像背景。
2. 类间结构保留组件:而后者用于避免合成特征过于分散而混淆类间和前景-背景关系。- 为了证明所提出方法的有效性,对PASCAL VOC、COCO和DIOR数据集进行了综合实验。值得注意的是,新提出的方法在PASCAL VOC和COCO上实现了最先进的性能,并且是第一个在遥感图像中进行零样本目标检测的研究。
1. 介绍
随着CNN和Transformer等深度学习技术的快速发展,目标检测研究领域取得了讯飞的进步。尽管现有方法实现的检测性能看起来很有希望和令人鼓舞,但在实际场景中应用它们存在一个隐藏的缺点——主流检测方法对要检测的类别有严格的限制。
一旦模型被训练,它只能识别出现在训练数据中的物体,而其他出现在测试图像中但在训练过程中看不到的物体会极大地混淆模型,导致无法避免的检测结果错误。为了解决这个问题,近年来提出了零样本目标检测(ZSD)的任务。目标是使检测模型能够预测在训练期间没有任何可用样本的看不见的对象。
- 早期关于零镜头对象检测(ZSD)[4,32]的研究集中在基于映射函数的方法上,这些方法学习从视觉空间到语义空间的映射函数。利用学习到的映射函数,通过将不可见对象的视觉特征映射到语义空间,进而在语义空间中进行最近邻搜索,从而预测不可见对象的类别。但是,由于映射函数都是根据训练数据提供的可见类别来学习的,所以在测试[16]时,在处理视觉特征时,模型会明显偏向于可见类别。
- 最近,基于生成模型的方法[16,43]被提出作为一种替代解决方案。通常,这些方法利用生成模型,从提供的对应于每个对象类别的语义嵌入[2,29]中综合视觉特征。合成的视觉特征可以用来训练一个不可见类的标准检测器。与基于映射函数的方法相比,基于生成模型的方法在解决偏倚问题上表现出更强的性能,因为尽管未知对象对应的样本仍然不存在,但针对未知对象使用合成的视觉特征训练检测器。
- 然而,目前基于生成模型的方法主要遵循了零-short分类框架的思想,如[30,37],其中合成的视觉特征在不太复杂的分类场景中可能表现良好,但在复杂的检测场景中不够健壮,无法获得令人满意的结果。据我们所知,为检测场景合成视觉特征有两方面的挑战:
1. 类内多样性:真实世界检测场景中的对象在姿态、形状、纹理等方面呈现高度变化,一个对象实例可能被几个大小和位置不同的包围框所覆盖。这导致了它们特征表示的高度多样性。
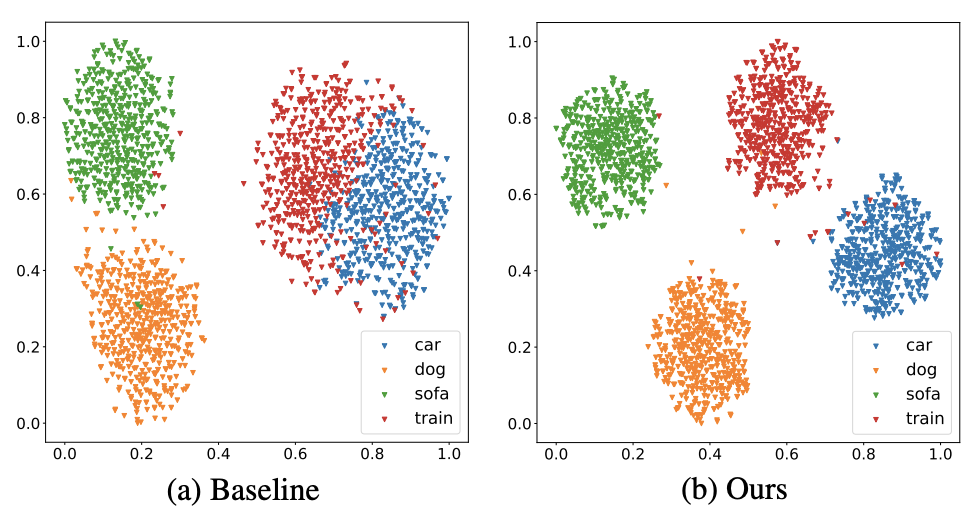
2. 类间可分性:虽然有这些变化,但每个物体类别仍然具有易于识别的特征,这些特征与其他物体类别和图像背景不同,使得不同类别(包括背景类)的特征表示具有高度可分性。虽然已有的一些方法已经认识到类内多样性的重要性[16,41],但在没有共同考虑类间可分性的情况下,这些方法要么会使合成的视觉特征的多样性不足,导致将真正看不见的物体误分类为图像背景(见图1(b)),或者过分地将不同类语义合成的视觉特征混合在一起,使得学习后的检测模型得到的前景区域的目标类别不准确或对图像背景处理错误(见图1(c))。
图1所示。本工作中所研究问题的例证。在实际情况下,样本构建的特征空间表现出较高的类内多样性,但仍具有类间可分性,如(a),而现有方法学习的合成视觉特征空间则表现出类内多样性不足,如(b),或者阶级内部差异过大,使得阶级之间不可分割,如(c)所示。
为了克服面向真实世界检测场景的特征综合问题,我们构建了如图2所示的新型零镜头目标检测框架。具体来说,我们设计了两个学习鲁棒区域特征的组件。
- 为了使模型能够合成不同的视觉特征,我们提出了一个类内语义发散(IntraSD)组件,它可以将单个类的语义向量分解成一组视觉特征。
- 为了防止合成特征的类内多样性过度混淆类间关系,我们进一步提出了一个类间结构保持(inter-class Structure Preserving, InterSP)组件,该组件利用来自不同对象类别的真实视觉样本来约束合成的视觉特征的可分性。
另外值得一提的是,在InterSP的设计中,我们充分利用了从真实图像场景中采样的区域特征进行检测,而不是在合成的视觉特征上实现。这使得我们的模型能够合成与真实情况一样可分离的视觉特征,并获得比前面提到的同类更好的性能(见第4.2节的实验)。
综上所述,本文主要有以下三方面的贡献:
- 我们揭示了在真实物体检测场景中特征合成的关键挑战,即类内多样性和类间可分离性。
- 为了为ZSD合成健壮的区域特征,我们构建了一个包含类内语义发散组件和类内结构保持组件的新框架。
- 在PASCAL VOC、COCO和DIOR三个数据集上进行综合实验,验证了所提方法的有效性。值得注意的是,这也是在遥感图像中实现零拍目标检测的首次尝试。

2. 相关工作
Zero-shot Learning (ZSL).ZSL的目标是通过利用语义标签嵌入(例如字向量[29]或语义属性[2])作为辅助信息,使用已见过的例子来训练网络并推理未见类。早期的ZSL研究工作集中在基于函数的嵌入方法上,这种方法将视觉特征嵌入到语义描述符空间中,反之亦然[1,5,11,20]。因此,视觉特征和语义特征将位于同一个嵌入空间,通过在嵌入空间[15]中搜索最接近的语义描述符即可完成ZSL分类。基于函数的嵌入方法在传统的ZSL场景中工作得很好[1,5,12,38],但在更具挑战性的GZSL场景中往往会过度拟合常见的类[6,15,36,39]。为了解决这个过拟合问题,一些研究人员引入了基于生成的方法[6,15,19,34],它通过生成条件生成模型(如变异自动编码器(V AE)[19]和生成对抗网络(GAN)[40])来学习补充未知类的训练样本。通过合成的不可见类实例,可以将零镜头分类问题转化为一般的全监督分类问题,并缓解过拟合问题。在本文中,我们也使用生成模型合成看不见的视觉特征,将ZSL转换成完全监督的方式。然而,由于我们的目标是解决更具挑战性的ZSD问题,我们需要在模型设计中处理更重的类内多样性和类间可分离性。
Zero-shot object detection.ZSD近年来受到了广泛的研究兴趣[4,7,16,22,31,32,41 - 43]。一些研究集中在基于嵌入函数的方法上[4,7,22,31,32,42]。不幸的是,这些方法会遇到过拟合问题,就像在ZSL中一样,不可见的对象明显偏向于可见的类或后台[16]。基于生成模型的方法[16,41,43]在解决偏差问题方面表现出很强的性能。Zhuet et al.[43]从语义信息中综合了不可见物体的视觉特征,并增强了现有的训练算法,将不可见物体检测纳入其中。Zhaoet al.[41]提出了一种生成传输网络用于零拍目标检测。Hayatet et al.[16]提出了一种零拍目标检测的特征合成方法,并利用模式寻求正则化[27]增强合成特征的多样性。然而,这些方法对于像真实样本一样具有类内多样性和类间可分离性的区域特征的合成都缺乏足够的学习能力,这也是本文研究的核心问题。
3.方法
3.1. 问题定义和框架概述
- 在ZSD中,我们有两个不相交的类集:在ys中可见的类和在yu中不可见的类,其中ys∩yu=∅。训练集包含可见的对象,其中每个图像都提供了相应的类标签和边界框坐标。
- 相反,测试集可以只包含不可见的对象(即ZSD设置),或者同时包含可见的和不可见的对象(即GZSD设置)。
- 在学习和测试过程中,语义词
同时提供给可见类和不可见类。ZSD的任务是学习能够定位和识别与语义词向量对应的看不见的对象的检测器(参数化θ)。
在这项工作中研究问题的插图。在实际情况下,样本构建的特征空间显示出较高的类内多样性,但仍具有类间可分离性,如a所示,而现有方法学习的合成视觉特征空间要么类内多样性不足(如b所示),或具有过多的类内多样性,使类间不可分割(如c所示)。
上图显示了提出的ZSD总体框架。可以看出,它包含一个目标检测模块和一个域变换模块。目标检测模块是一个Faster-RCNN模型,以ResNet-101作为主干。
- 我们用看到的图像及其相应的groundtruth注释来训练Faster-RCNN模型。
- 获得模型后,可以用它来使用RPN为所见类提取区域特征。
- 其次,我们训练区域特征合成器来学习语义词向量和视觉特征之间的映射。
- 然后,使用学习到的特征合成器为看不见的类生成区域特征。通过这些合成的未见区域特征及其相应的类别标签,我们可以为未见类别训练未见分类器。
- 最后,我们更新Faster-RCNN模型中的分类器,以实现ZSD任务的新检测器。
整个训练过程也在Algorithm 1中进行了详细说明。请注意,新提出的方法核心是如何学习统一的生成模型来学习视觉域和语义域之间的关系。具体来说,研究者设计了一个统一的区域特征合成器,用于在现实世界检测场景中进行特征合成,其中包含一个类内语义发散组件和一个类间结构保持组件。
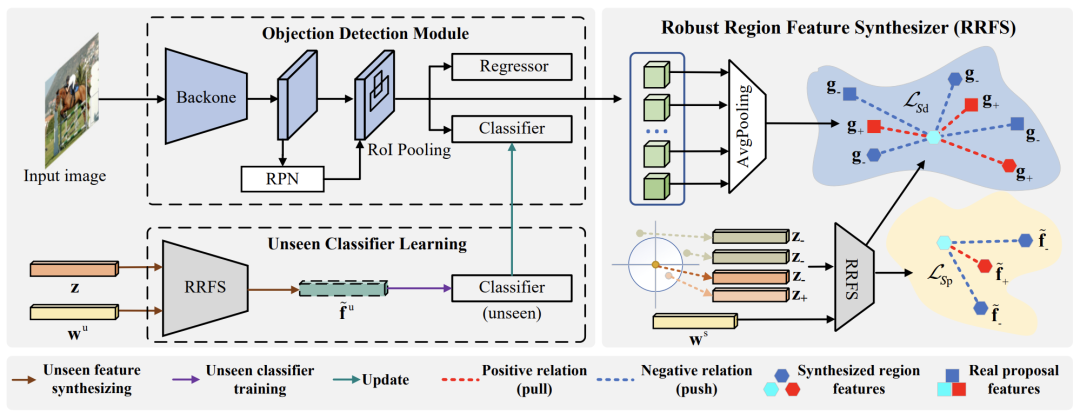
3.2.鲁棒区域特征合成器

四、实验及可视化
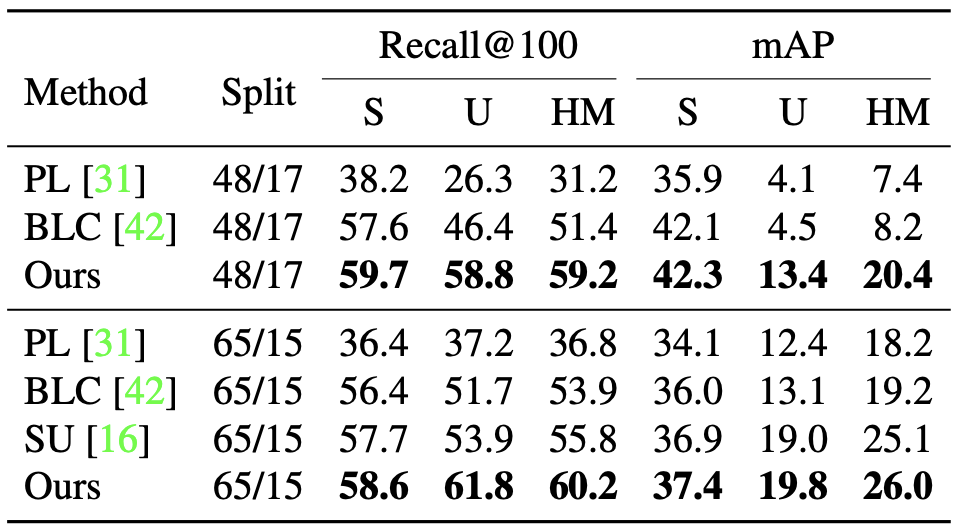
Comparison of mAP at IoU=0.5, under ZSD and GZSD settings on PASCAL VOC dataset
Comparison of Recall@100 and mAP at IoU=0.5 over two seen/unseen splits, under GZSD setting on MS COCO dataset
PASCAL VOC、MS COCO(48/17和65/15)和DIOR数据集的定性结果。
对于每个数据集,第一列和第二列分别是ZSD和GZSD的结果。看到的类用绿色表示,看不见的用红色表示。

5. 结论和局限性
在本工作中,我们将重点放在ZSD任务中,解决了合成不可见物体的鲁棒区域特征的挑战。具体来说,我们提出了一个新的ZSD框架,通过构建一个鲁棒的区域特征合成器,其中包括IntraSD和InterSP组件。
- IntraSD实现了一对多的映射,从每个类语义向量中获取不同的视觉特征,避免了将真正看不见的对象误分类为图像背景。
- InterSP分量充分利用了来自不同物体类别的合成区域特征和真实区域特征,提高了合成视觉特征的识别能力。
大量的实验结果表明,我们的方法优于目前最先进的ZSD方法。
限制。本研究的一个主要局限性是,所提出的方法是基于两级目标检测器,如fast - rcnn[33],其检测速度相对较慢。我们希望将我们的方法集成到一些单级目标检测器中,如YOLOv5[18],以进一步提高未来的检测速度。

