
热门标签
热门文章
- 1基于SpringBoot+Vue的在线公务员考试练习系统_公考在线题库网站 csdn
- 2解决gif图在小程序的webview长按转发不是动图的问题(安卓手机)_微信小程序中web-view的图片长按分享
- 3前端怎么实现聊天输入框?怎么实现类似b站评论的输入并发送自定义表情包?输入回显、发送时表情包转义为[emoji]字符串、页面展示回显_vue自定义表情如何显示到输入框
- 4探索Web3D世界:Three.js城市模型项目详解
- 5海量数据面试题----分而治之/hash映射 + hash统计 + 堆/快速/归并排序_hash分冶 统计词频 局部排序
- 6快速构建本地RAG聊天机器人:使用LangFlow和Ollama实现无代码开发_ragflow ollama
- 7【翻译】GPT-3架构,简述于“餐巾纸”上_gpt3 前馈网络 隐藏层维度
- 8【数据结构】C语言实现单链表万字详解(附完整运行代码)_c语言可运行代码
- 9通用大模型VS垂直大模型,两者的详细分析对比_通用大模型和垂直大模型
- 10数据结构——二叉树的非递归遍历_二叉树遍历的非递归实现
当前位置: article > 正文
本地离线模型搭建指南-RAG架构实现_rag 搭建
作者:IT小白 | 2024-07-26 13:17:50
赞
踩
rag 搭建
搭建一个本地中文大语言模型(LLM)涉及多个关键步骤,从选择模型底座,到运行机器和框架,再到具体的架构实现和训练方式。以下是一个详细的指南,帮助你从零开始构建和运行一个中文大语言模型。
本地离线模型搭建指南将按照以下四个部分展开
3 RAG架构实现
3.1 什么是RAG
检索增强生成(Retrieval Augmented Generation, RAG) 是当前最热门的大语言模型(LLM)应用方案之一。RAG结合了信息检索和生成模型的优势,旨在增强生成式模型的知识覆盖和输出准确性。
3.2 为什么使用RAG
使用RAG的主要原因有以下几点:
- 知识的局限性:
- 现有的大模型(如ChatGPT、文心一言、通义千问等)的知识来源于它们的训练数据,这些数据主要是公开的网络数据。
- 对于一些实时性、非公开或离线的数据,大模型无法直接获取和使用。
- 幻觉问题:
- 大模型的输出基于数学概率,有时会出现“幻觉”——即生成看似合理但实际上错误的回答。
- 这种问题难以区分,尤其是在用户不具备相关领域知识的情况下。
- 数据安全性:
- 企业非常注重数据安全,不愿意将私有数据上传到第三方平台进行训练。
- 使用通用大模型可能会在数据安全和效果之间产生取舍。
RAG通过结合检索和生成的方式,能够有效解决上述问题。
3.3 RAG架构
RAG架构主要包括以下几个部分:
- 向量化:
- 将文本数据转化为向量矩阵,这个过程会直接影响后续检索的效果。
- 常见的embedding模型包括BERT、RoBERTa等,可以满足大部分需求。
- 对于特殊场景,可以选择微调现有的开源embedding模型,或直接训练适合自己场景的模型。
- 数据入库:
- 数据向量化后构建索引,并写入数据库。
- 适用于RAG场景的数据库包括FAISS、ChromaDB、Elasticsearch(ES)、Milvus等。
- 选择合适的数据库时,需要综合考虑业务场景、硬件和性能需求等因素。
- 检索模块:
- 在用户提出问题时,首先检索相关的文档或信息片段。
- 这些检索到的信息将作为生成模型的辅助输入。
- 生成模块:
- 利用检索到的信息和用户输入的问题,生成更加准确和相关的回答。
- 生成模型可以是预训练的大语言模型,如GPT-3等。
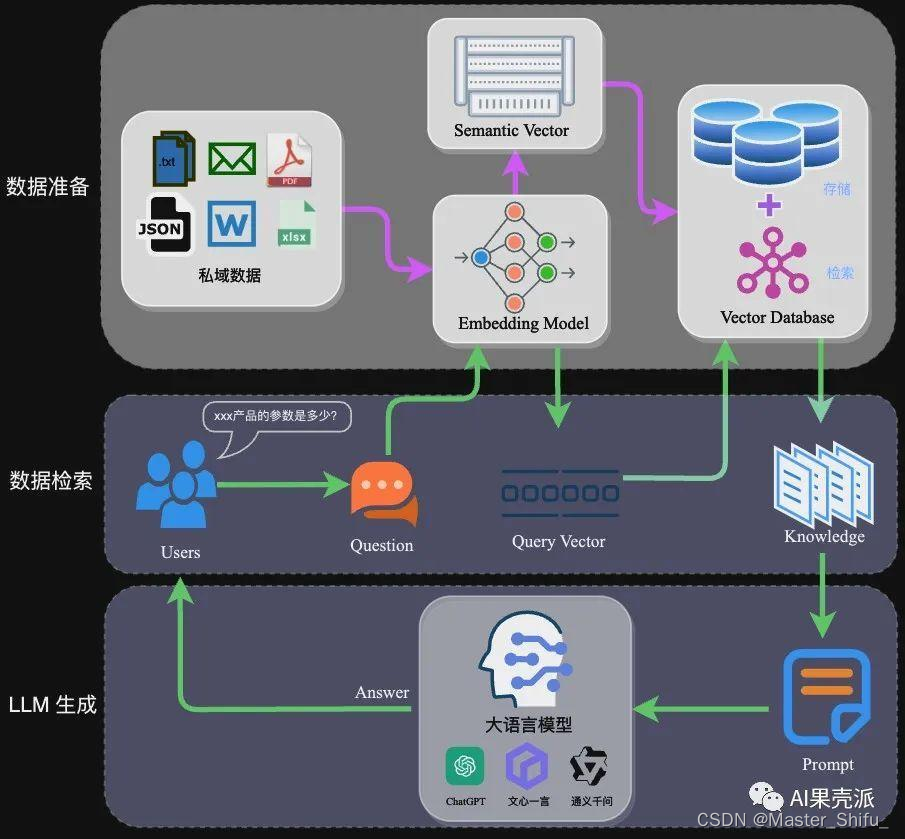
3.4 RAG的工作流程
- 用户输入问题。
- 检索模块从数据库中检索相关信息。
- 生成模块结合用户输入和检索到的信息生成答案。
- 返回生成的答案给用户。
通过这种方式,RAG不仅能利用大模型的强大生成能力,还能结合实时、私有的数据源,提供更加精准和安全的解决方案。
3.5 embedding模型链接
| 模型名称 | 描述 | 获取地址 |
|---|---|---|
| ChatGPT-Embedding | ChatGPT-Embedding由OpenAI公司提供,以接口形式调用。 | https://platform.openai.com/docs/guides/embeddings/what-are-embeddings |
| ERNIE-Embedding V1 | ERNIE-Embedding V1由百度公司提供,依赖于文心大模型能力,以接口形式调用。 | https://cloud.baidu.com/doc/WENXINWORKSHOP/s/alj562vvu |
| M3E | M3E是一款功能强大的开源Embedding模型,包含m3e-small、m3e-base、m3e-large等多个版本,支持微调和本地部署。 | https://huggingface.co/moka-ai/m3e-base |
| BGE | BGE由北京智源人工智能研究院发布,同样是一款功能强大的开源Embedding模型,包含了支持中文和英文的多个版本,同样支持微调和本地部署。 | https://huggingface.co/BAAI/bge-base-en-v1.5 |
更多详细信息和具体模型的链接,请访问
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/885509
推荐阅读
相关标签

