
- 1苹果6s强制删除id锁_#Vlog# 苹果7绕过id激活锁
- 2AI人工智能 Agent:高级概念剖析_ai agent tag
- 3git分支与gitee_怎么gitee的dev分支保持和master一致,页面操作
- 4建议收藏!数据分析和机器学习必备SQL技能
- 5【蓝桥杯】最难算法没有之一· 动态规划真的这么好理解?(引入)_最难的算法
- 6Ubuntu SLAM 环境配置 for 视觉SLAM(包含 ROS CUDA OPENCV 等)_ubuntu 部署slam
- 7LangChain结合DSPy,高效实现提示工程自动优化_dspy 提示词优化
- 8FPGA和外围接口-第一章 爱上FPGA(1.1、1.2)_fpga的gtx接口 外围电路
- 9测试版ios15怎么信任软件,苹果ios15信任的描述文件在哪?苹果ios15授权信任怎么设置?...
- 10idea出现Java HotSpot(TM) 64-Bit Server VM warning: Options -Xverify解决_java hotspot(tm) 64-bit server vm warning: sharing
海量数据面试题----分而治之/hash映射 + hash统计 + 堆/快速/归并排序_hash分冶 统计词频 局部排序
赞
踩
1、从set/map谈到hashtable/hash_map/hash_set
稍后本文第二部分中将多次提到hash_map/hash_set,下面稍稍介绍下这些容器,以作为基础准备。一般来说,STL容器分两种:
序列式容器(vector/list/deque/stack/queue/heap),
关联式容器。关联式容器又分为set(集合)和map(映射表)两大类,以及这两大类的衍生体multiset(多键集合)和multimap(多键映射表),这些容器均以RB-tree完成。此外,还有第3类关联式容器,如hashtable(散列表),以及以hashtable为底层机制完成的hash_set(散列集合)/hash_map(散列映射表)/hash_multiset(散列多键集合)/hash_multimap(散列多键映射表)。也就是说,set/map/multiset/multimap都内含一个RB-tree,而hash_set/hash_map/hash_multiset/hash_multimap都内含一个hashtable。
所谓关联式容器,类似关联式数据库,每笔数据或每个元素都有一个键值(key)和一个实值(value),即所谓的Key-Value(键-值对)。当元素被插入到关联式容器中时,容器内部结构(RB-tree/hashtable)便依照其键值大小,以某种特定规则将这个元素放置于适当位置。
包括在非关联式数据库中,比如,在MongoDB内,文档(document)是最基本的数据组织形式,每个文档也是以Key-Value(键-值对)的方式组织起来。一个文档可以有多个Key-Value组合,每个Value可以是不同的类型,比如String、Integer、List等等。 { "name" : "July", "sex" : "male", "age" : 23 }
set/map/multiset/multimap:
set,同map一样,所有元素都会根据元素的键值自动被排序,因为set/map两者的所有各种操作,都只是转而调用RB-tree的操作行为,不过,值得注意的是,两者都不允许两个元素有相同的键值。
不同的是:set的元素不像map那样可以同时拥有实值(value)和键值(key),set元素的键值就是实值,实值就是键值,而map的所有元素都是pair,同时拥有实值(value)和键值(key),pair的第一个元素被视为键值,第二个元素被视为实值。
至于multiset/multimap,他们的特性及用法和set/map完全相同,唯一的差别就在于它们允许键值重复,即所有的插入操作基于RB-tree的insert_equal()而非insert_unique()。
hash_set/hash_map/hash_multiset/hash_multimap:
hash_set/hash_map,两者的一切操作都是基于hashtable之上。不同的是,hash_set同set一样,同时拥有实值和键值,且实质就是键值,键值就是实值,而hash_map同map一样,每一个元素同时拥有一个实值(value)和一个键值(key),所以其使用方式,和上面的map基本相同。但由于hash_set/hash_map都是基于hashtable之上,所以不具备自动排序功能。为什么?因为hashtable没有自动排序功能。
至于hash_multiset/hash_multimap的特性与上面的multiset/multimap完全相同,唯一的差别就是它们hash_multiset/hash_multimap的底层实现机制是hashtable(而multiset/multimap,上面说了,底层实现机制是RB-tree),所以它们的元素都不会被自动排序,不过也都允许键值重复。
所以,综上,说白了,什么样的结构决定其什么样的性质,因为set/map/multiset/multimap都是基于RB-tree之上,所以有自动排序功能,而hash_set/hash_map/hash_multiset/hash_multimap都是基于hashtable之上,所以不含有自动排序功能,至于加个前缀multi_无非就是允许键值重复而已。
2、寻找热门查询:搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。
假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
解决方案:虽然有一千万个Query,但是由于重复度比较高,因此事实上只有300万的Query,每个Query255Byte,(300w*255B<1G,可以把数据全部读入内存),因此我们可以考虑把他们都放进内存中去,而现在只是需要一个合适的数据结构,在这里,Hash Table绝对是我们优先的选择。所以我们放弃分而治之/hash映射的步骤,直接上hash统计,然后排序。So:
- hash统计:先对这批海量数据预处理(维护一个Key为Query字串,Value为该Query出现次数的HashTable,即hash_map(Query,Value),每次读取一个Query,如果该字串不在Table中,那么加入该字串,并且将Value值设为1;如果该字串在Table中,那么将该字串的计数加一即可。最终我们在O(N)的时间复杂度内用Hash表完成了统计;
- 堆排序:第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。即借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比所以,我们最终的时间复杂度是:O(N) + N'*O(logK),(N为1000万,N’为300万)。
堆排序思路:“维护k个元素的最小堆,即用容量为k的最小堆存储最先遍历到的k个数,并假设它们即是最大的k个数,建堆费时O(k),并调整堆(费时O(logk))后,有k1>k2>...kmin(kmin设为小顶堆中最小元素)。继续遍历数列,每次遍历一个元素x,与堆顶元素比较,若x>kmin,则更新堆(用时logk),否则不更新堆。这样下来,总费时O(k*logk+(n-k)*logk)=O(n*logk)。此方法得益于在堆中,查找等各项操作时间复杂度均为logk。
3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
解决方案:(1G=5000*200k,将文件分成5000个小文件,每个文件200k)
1)分而治之/hash映射:顺序读文件中,对于每个词x,取hash(x)%5000,然后按照该值存到5000个小文件(记为x0,x1,...x4999)中。这样每个文件大概是200k左右,并且每个文件存放的都是具有一样hash值的词。如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。
2)hash统计:对每个小文件,采用trie树/hash_map等统计每个文件中出现的词以及相应的频率。
3)堆/归并排序:取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100个词及相应的频率存入文件,这样又得到了5000个文件。最后就是把这5000个文件进行归并(类似于归并排序)的过程了。
1)堆排序:在每台电脑上求出TOP10,可以采用包含10个元素的堆完成(TOP10小,用最大堆,TOP10大,用最小堆)。比如求TOP10大,我们首先取前10个元素调整成最小堆,如果发现,然后扫描后面的数据,并与堆顶元素比较,如果比堆顶元素大,那么用该元素替换堆顶,然后再调整为最小堆。最后堆中的元素就是TOP10大。
2)求出每台电脑上的TOP10后,然后把这100台电脑上的TOP10组合起来,共1000个数据,再利用上面类似的方法求出TOP10就可以了。
上述第4题的此解法,经读者反应有问题,如举个例子如求2个文件中的top2,照上述算法,如果第一个文件里有:a 49次b 50次c 2次d 1次第二个文件里有:a 9次b 1次c 11次d 10次虽然第一个文件里出来top2是b(50次),a(49次),第二个文件里出来top2是c(11次),d(10次),然后2个top2:b(50次)a(49次)与c(11次)d(10次)归并,则算出所有的文件的top2是b(50 次),a(49 次),但实际上是a(58 次),b(51 次)。是否真是如此呢?若真如此,那作何解决呢?首先,先把所有的数据遍历一遍做一次hash(保证相同的数据条目划分到同一台电脑上进行运算),然后根据hash结果重新分布到100台电脑中,接下来的算法按照之前的即可。最后由于a可能出现在不同的电脑,各有一定的次数,再对每个相同条目进行求和(由于上一步骤中hash之后,也方便每台电脑只需要对自己分到的条目内进行求和,不涉及到别的电脑,规模缩小)。
1)hash映射:顺序读取10个文件,按照hash(query)%10的结果将query写入到另外10个文件(记为)中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。
2)hash统计:找一台内存在2G左右的机器,依次对用hash_map(query, query_count)来统计每个query出现的次数。注:hash_map(query,query_count)是用来统计每个query的出现次数,不是存储他们的值,出现一次,则count+1。
3)堆/快速/归并排序:利用快速/堆/归并排序按照出现次数进行排序,将排序好的query和对应的query_cout输出到文件中,这样得到了10个排好序的文件(记为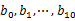 )。最后,对这10个文件进行归并排序(内排序与外排序相结合)。
)。最后,对这10个文件进行归并排序(内排序与外排序相结合)。
方案2:一般query的总量是有限的,只是重复的次数比较多而已,可能对于所有的query,一次性就可以加入到内存了。这样,我们就可以采用trie树/hash_map等直接来统计每个query出现的次数,然后按出现次数做快速/堆/归并排序就可以了。
方案3:与方案1类似,但在做完hash,分成多个文件后,可以交给多个文件来处理,采用分布式的架构来处理(比如MapReduce),最后再进行合并。
6、 给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
可以估计每个文件安的大小为5G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
1)分而治之/hash映射:遍历文件a,对每个url求取![]() ,然后根据所取得的值将url分别存储到1000个小文件(记为
,然后根据所取得的值将url分别存储到1000个小文件(记为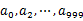 )中。这样每个小文件的大约为300M。遍历文件b,采取和a相同的方式将url分别存储到1000小文件中(记为
)中。这样每个小文件的大约为300M。遍历文件b,采取和a相同的方式将url分别存储到1000小文件中(记为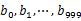 )。这样处理后,所有可能相同的url都在对应的小文件(
)。这样处理后,所有可能相同的url都在对应的小文件(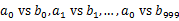 )中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
)中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
2)hash统计:求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
7、怎么在海量数据中找出重复次数最多的一个?
1)先做hash映射,求模将大文件中的内容映射到小文件中
2)然后hash统计,求出每个小文件中重复次数最多的一个,并记录重复次数。
3)最后快速排序/堆排序/归并排序,找出上一步求出的数据中重复次数最多的一个就是所求
8、上千万或上亿数据(有重复),统计其中出现次数最多的钱N个数据。
1)数据如果可以直接全部放进内存,就不用hash映射成多个小文件。
2)采用hash_map/搜索二叉树/红黑树等来进行统计次数。
3)然后就是取出前N个出现次数最多的数据了,可以用第2题提到的堆机制完成。

