
热门标签
热门文章
- 1集五福,我用 Python
- 2React-使用Sublime Text3开发的必备工具_sublime react
- 3自定义element-plus的弹框样式_elementplus dialog样式修改
- 4关系型数据库架构介绍及主流应用场景_无共享master和有共享master区别
- 5elementUi重置Select选择器样式、option、deep、vue3、plus_elementui选择器
- 6OpenCV进行图像分割:分水岭算法(相关函数介绍以及项目实现)_opencv分水岭算法
- 7docker(1)概念和三要素_使用容器的三个基本因素
- 8Semantic Seg 经典 Fully Convolutional Network 精读与进阶(Shift-and-stitch 到 backwards strided convolution)_long, j., shelhamer, e., darrell, t.: fully convol
- 9把 讯飞火星 接入到 微信_php讯飞火星
- 10CAN总线第2讲__数据链路层讲解_can数据链路层测量启动时间
当前位置: article > 正文
Vision Transformer模型简述(图像分类篇)_vision transformer分类项目
作者:IT小白 | 2024-02-16 12:04:21
赞
踩
vision transformer分类项目
主要素材来源链接 https://blog.csdn.net/qq_37541097?spm=1001.2014.3001.5509
模型的组成

简单而言,模型由三个模块组成:
- Linear Projection of Flattened Patches (嵌入层)
- Transformer Ecoder
- MLP Head(用于分类)
embeding层

一般的输入图像是[H,W,C]是三维的,这个格式是不符合Transformer Encoder的输入要求的。所以我们这一层的主要目的就是变换"三维矩阵变成二维矩阵"。
主要步骤:
1.将一张图片按给定的大小分成一堆patches。
2.通过线性映射将每个Patch映射到一维向量(token)中。
注意:在输入Transformer Encoder之前注意需要加上[class]token以及Position Embedding
Transformer Encoder模块
 Transformer Encoder其实就是重复堆叠Encoder Block L次。
Transformer Encoder其实就是重复堆叠Encoder Block L次。
- Layer Norm (是NLP领域的,这是相对于图像领域的BN)
- Multi-Head Attention
- Dropout/DropPath
- MLP Block,如下面所所示
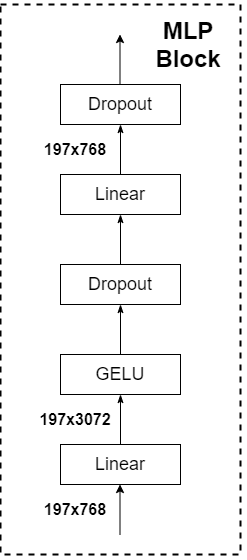
MLP Head

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/93014
推荐阅读
相关标签

