
- 1代码随想录训练营day43
- 2探索富文本新高度:mp-html——小程序领域的强大组件
- 3【3.2】Eureka-搭建注册中心/服务注册/服务发现_eruke 如何自动注册
- 4音频分类-有监督-案例01:ESC-50 audio classification_audio classificiation
- 5Fastapi 中间件 middleware_fastapi middleware
- 6docker问题统计_docker daemon.json和daemon.conf
- 7Python酷库之旅-第三方库Pandas(074)
- 8html5 小游戏 404页面,分享一款超级简洁大方的网站404页面HTML模板
- 9FastText原理与代码实例讲解_fasttext代码
- 10推荐一个优秀人工智能学习网站_csdn 给大家推荐一个人工智能网站
阿里开源自家首个MoE技术大模型:Qwen1.5-MoE-A2.7B,性能约等于70亿参数规模的大模型Mistral-7B_阿里开源官网 大模型
赞
踩
阿里开源自家首个MoE技术大模型:Qwen1.5-MoE-A2.7B,性能约等于70亿参数规模的大模型Mistral-7B
原创 DataLearner DataLearner 2024-03-29 07:01 江苏
本文原文来自DataLearnerAI官方网站:
https://www.datalearner.com/blog/1051711644006739
阿里巴巴的通义千问一直是开源领域最强大的大模型之一。就在今天,阿里巴巴首次开源了他们家的MoE技术大模型Qwen1.5-MoE-A2.7B,这个模型是使用现有的Qwen-1.8B模型作为起点,通过类似merge技术进行合并得到的。
-
Qwen1.5-MoE-A2.7B简介
-
Qwen1.5-MoE-A2.7B的效果
-
Qwen1.5-MoE-A2.7B开源和使用
Qwen1.5-MoE-A2.7B简介
最近2天,业界有3个重磅的MoE技术大模型开源,包括前天的DBRX以及今天的Jamba和阿里的Qwen1.5-MoE-A2.7B。
Qwen1.5-MoE-A2.7B是基于阿里此前开源的Qwen1.5-1.8B模型继续迭代升级的混合专家技术大模型。Qwen1.5-MoE-A2.7B模型总的参数数量是143亿,但每次推理只使用27亿参数。
阿里官方称他们使用的是特别设计的MoE架构。通常,如Mixtral方法中所见,每个transformer块内的MoE层采用八个专家,并使用前两名门控策略用于路由。这种配置虽然简单有效,但有很大的提升空间。因此,通过一系列广泛的实验,阿里对这个架构进行了几项修改:
-
更加细粒度专家
-
非从头训练的“升级再利用”的初始化
-
带有共享和路由专家的路由机制
以前的研究项目,如DeepSeek-MoE和DBRX,已经证明了使用细粒度专家的有效性。阿里将单个FFN分割成几个部分,每个部分作为一个独立的专家。这是一种更为细致的构建专家的方法。
所以,虽然Qwen1.5-MoE-A2.7B模型参数量不大,但是总共有64个专家,比传统的8个专家的MoE设置增加了8倍,每次推理激活其中4个专家。同时利用现有的Qwen-1.8B,将其转变为Qwen1.5-MoE-A2.7B。
一个值得注意的发现是,在初始化过程中引入随机性显著加快了收敛速度,并在整个预训练过程中取得了更好的整体性能。
Qwen1.5-MoE-A2.7B的效果
根据阿里官方提供的数据,Qwen1.5-MoE-A2.7B参数总数143亿,每次推理激活27亿,其效果约等于70亿参数规模的大模型。
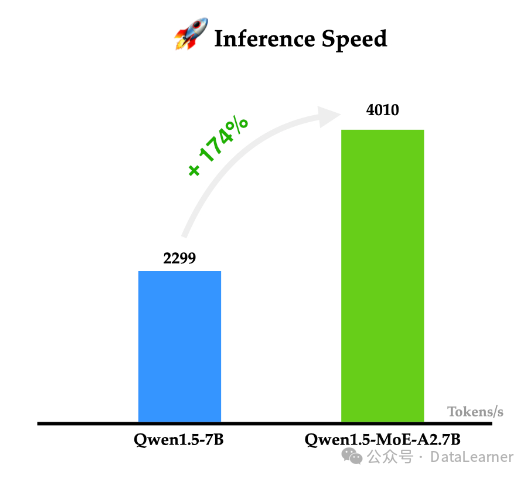
从这个角度看,Qwen1.5-MoE-A2.7B显存(半精度)最低需要28GB,但是推理的时候因为只使用了27亿参数,所以推理速度会更快。也就是意味着,Qwen1.5-MoE-A2.7B模型用2倍于70亿参数模型的显存,推理速度则提升到原来的1.74倍。
下图是模型与其它模型的评测对比:
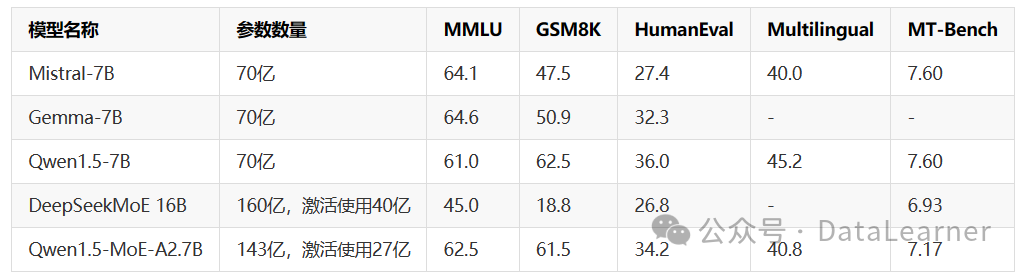
可以看到,Qwen1.5-MoE-A2.7B与70亿参数模型基本差不多。这种显存换速度的方法,看个人选择了。
另外一个值得注意的点是在Qwen1.5-MoE-A2.7B模型在NVIDIA A100-80G GPU可以达到每秒4000个tokens的生成速度!非常恐怖!(输入输出都是1K的tokens)
Qwen1.5-MoE-A2.7B开源和使用
Qwen1.5-MoE-A2.7B模型是允许免费商用的。不过由于最新的transformers代码没有合入这个模型,所以想要使用的话需要从GitHub下载源码进行编译安装后才能使用。
Qwen1.5-MoE-A2.7B模型开源地址参考:https://www.datalearner.com/ai-models/pretrained-models/Qwen1_5-MoE-A2_7B

