
- 1C语言中使用scanf函数时应注意的问题_scanf如何防止输入小数
- 2RUST博客帖子编辑示例
- 3如何在vscode调试c++_vscode怎么debugc++代码
- 4Codeforces Round #700 (Div. 2)-B. The Great Hero-题解-一行实现向上取整_codeforces 700
- 5树莓派ros小车笔记_clbrobot
- 6使用Gitee Pages发布网站_gittee发布网页
- 7如何将我的服务开放给用户:构建API接口和用户认证的实践指南_开放给用户的api
- 8bat命令后台运行_bat run
- 9C语言结构体变量定义、引用、初始化_c语言结构体变量的初始化和引用
- 10c#与java的区别_c#与java区别
AI大模型全栈工程师课程笔记 - LangChain_selfaskwithsearch智能体
赞
踩
课程学习自 知乎知学堂 https://www.zhihu.com/education/learning
如果侵权,请联系删除,感谢!
LangChain 也是面向LLM的开发框架SDK,有 python 和 js 版的
https://python.langchain.com/docs/get_started
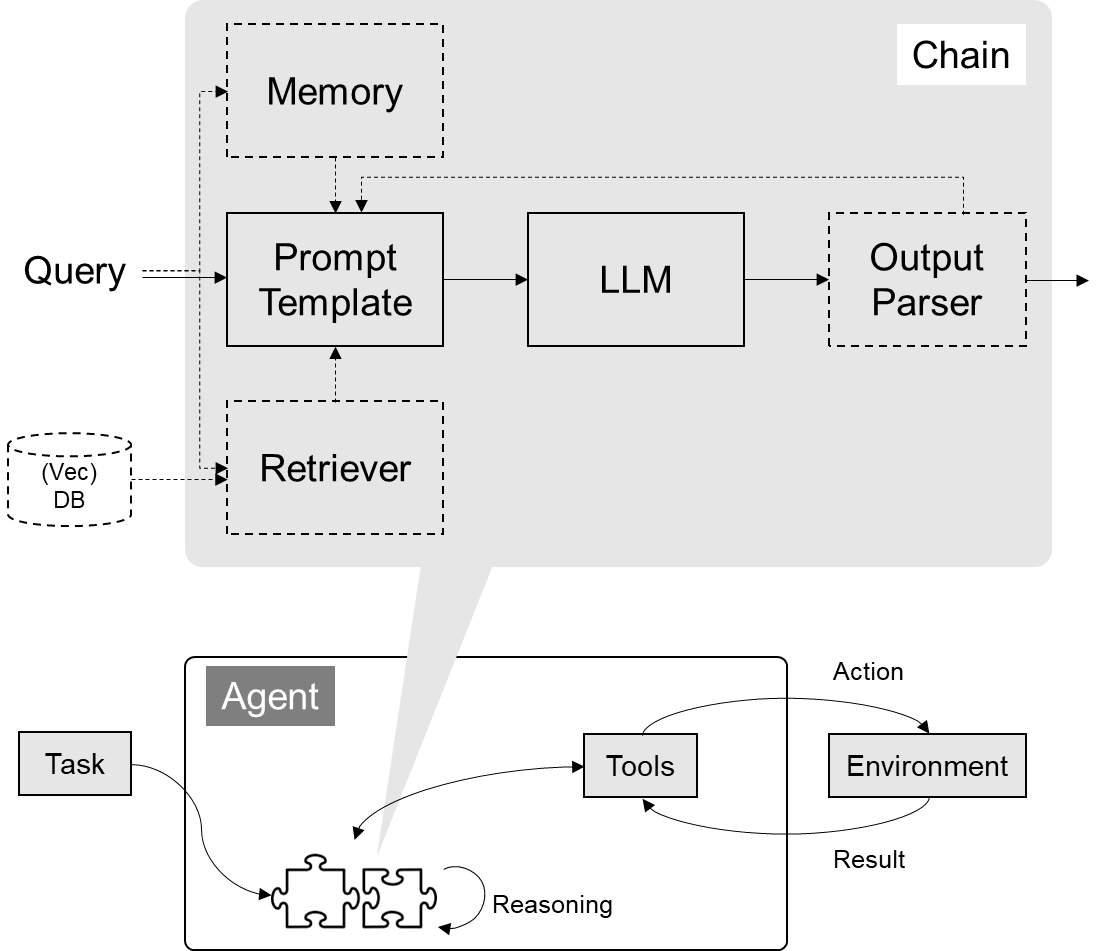
1. 模型 IO 封装
pip install langchain # 0.0.350
- 1
- 模型封装
from langchain.llms import OpenAI
# 设置环境变量
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv('../utils/.env'))
from langchain.chat_models import ChatOpenAI
llm = OpenAI() # 默认是text-davinci-003模型
llm.predict("你好,欢迎")
# '你来到这里!\n\n很高兴认识你!'
chat_model = ChatOpenAI() # 默认是gpt-3.5-turbo
chat_model.predict("你好,欢迎")
# '你好!欢迎来到这里!有什么我可以帮助你的吗?'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
无缝替换 百度模型 ErnieBotChat
from langchain.chat_models import ErnieBotChat
from langchain.schema import HumanMessage
chat_model = ErnieBotChat()
messages = [
HumanMessage(content="你是谁")
]
chat_model(messages)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 多轮对话封装
from langchain.schema import (
AIMessage, #等价于OpenAI接口中的assistant role
HumanMessage, #等价于OpenAI接口中的user role
SystemMessage #等价于OpenAI接口中的system role
)
messages = [
SystemMessage(content="你是谷歌的大模型Gemini,你需要友好的回答用户的问题。"),
HumanMessage(content="我想python入门,请你给出学习计划")
]
chat_model(messages)
# AIMessage(content='当然!学习Python是一个很好的开始。以下是一个基本的学习计划,帮助你入门Python:\n\n1. 了解基础知识:首先,你可以通过阅读一些关于Python的基础知识的教程或书籍来了解Python的语法、数据类型、条件语句和循环等基本概念。\n\n2. 实践编程:通过编写一些简单的程序来巩固所学的知识。你可以尝试解决一些简单的编程问题,例如计算器程序、猜数字游戏等。\n\n3. 学习面向对象编程:Python是一种面向对象的编程语言,学习面向对象编程是非常重要的。你可以学习类、对象、继承、多态等概念,并在自己的代码中应用它们。\n\n4. 掌握常用模块和库:Python有很多强大的模块和库,可以帮助你更高效地开发应用程序。一些常用的模块包括NumPy、Pandas、Matplotlib等,你可以学习它们的用法并在实际项目中使用它们。\n\n5. 解决实际问题:找一些实际的问题,尝试用Python解决它们。这样可以帮助你将所学的知识应用到实际情境中,并提高你的编程能力。\n\n6. 参与项目或开源社区:参与开源项目或社区可以帮助你与其他开发者交流,并提升你的编程技能。你可以寻找一些适合你水平的项目,与其他开发者合作,共同完成项目。\n\n7. 持续学习和实践:编程是一个不断学习和实践的过程,持续学习和实践可以让你不断提高。保持对新技术和最佳实践的关注,并尝试将它们应用到你的项目中。\n\n记住,学习编程是一个长期的过程,需要坚持和耐心。祝你在学习Python的过程中取得成功!如果你有任何问题,随时向我提问。')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2. 输入输出封装
- 提示词模板
from langchain.prompts import PromptTemplate
template = PromptTemplate.from_template("给我讲个关于{subject}{things}的笑话")
print(template.input_variables) # ['subject', 'things']
print(template.format(subject='小明',things='小王'))
# 给我讲个关于小明小王的笑话
- 1
- 2
- 3
- 4
- 5
- 6
- 对话模板
from langchain.prompts import ChatPromptTemplate
from langchain.prompts.chat import SystemMessagePromptTemplate, HumanMessagePromptTemplate
from langchain.chat_models import ChatOpenAI
template = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate.from_template("你是{product}的客服助手。你的名字叫{name}"),
HumanMessagePromptTemplate.from_template("{query}"),
]
)
llm = ChatOpenAI()
prompt = template.format_messages(
product="AIGC课程",
name="小爱",
query="你好,我想学习AIGC课程"
)
llm(prompt)
# AIMessage(content='你好!非常欢迎你对AIGC课程感兴趣。AIGC课程是一门人工智能基础课程,旨在帮助学员掌握人工智能的基本概念、技术和应用。\n\n如果你想学习AIGC课程,我可以为你提供以下信息:\n1. 课程内容:AIGC课程包括人工智能基础知识、机器学习、深度学习、自然语言处理、计算机视觉等方面的内容。\n2. 学习方式:AIGC课程提供在线学习,你可以根据自己的时间和进度来学习课程内容。\n3. 学习资源:AIGC课程提供视频教程、学习笔记、练习题等学习资源,帮助学员更好地理解和掌握课程内容。\n4. 学习支持:我们提供学习支持,包括学习群组、论坛和定期答疑活动,帮助学员解决学习中的问题。\n\n如果你有更具体的问题或需要更多信息,可以告诉我,我会尽力帮助你。')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 从文件加载
prompt模板
yaml 格式
_type: prompt
input_variables:
["adjective", "content"]
template:
Tell me a {adjective} joke about {content}.
- 1
- 2
- 3
- 4
- 5
{
"_type": "prompt",
"input_variables": ["adjective", "content"],
"template": "Tell me a {adjective} joke about {content}."
}
- 1
- 2
- 3
- 4
- 5
json里面的还可以换成文件路径:"template_path": "simple_template.txt"
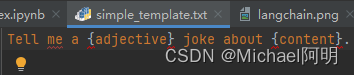
from langchain.prompts import load_prompt
prompt = load_prompt("simple_prompt.yaml")
# prompt = load_prompt("simple_prompt.json")
print(prompt.format(adjective="funny", content="fox"))
# Tell me a funny joke about fox.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 输出封装
Pydantic (JSON) Parser
自动根据Pydantic类的定义,生成输出的格式说明
# pydantic 2.5.2
from pydantic import BaseModel, Field, ValidationInfo, field_validator
from typing import List, Dict
# 定义你的输出对象
class Date(BaseModel):
year: int = Field(description="Year")
month: int = Field(description="Month")
day: int = Field(description="Day")
era: str = Field(description="BC or AD")
# ----- 可选机制 --------
# 你可以添加自定义的校验机制
@field_validator('month')
def valid_month(cls, field, info):
if field <= 0 or field > 12:
raise ValueError("月份必须在1-12之间")
return field
@field_validator('day')
def valid_day(cls, field, info):
if field <= 0 or field > 31:
raise ValueError("日期必须在1-31日之间")
return field
@field_validator('day', mode='before')
def valid_date(cls, day, values):
year = values.data['year']
month = values.data['month']
# 确保年份和月份都已经提供
if year is None or month is None:
return day # 无法验证日期,因为没有年份和月份
# 检查日期是否有效
if month == 2:
if cls.is_leap_year(year) and day > 29:
raise ValueError("闰年2月最多有29天")
elif not cls.is_leap_year(year) and day > 28:
raise ValueError("非闰年2月最多有28天")
elif month in [4, 6, 9, 11] and day > 30:
raise ValueError(f"{month}月最多有30天")
return day
@staticmethod
def is_leap_year(year):
if year % 400 == 0 or (year % 4 == 0 and year % 100 != 0):
return True
return False
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.output_parsers import PydanticOutputParser
model_name = 'gpt-4'
temperature = 0
model = ChatOpenAI(model_name=model_name, temperature=temperature)
# 根据Pydantic对象的定义,构造一个OutputParser
parser = PydanticOutputParser(pydantic_object=Date)
template = """提取用户输入中的日期。
{format_instructions}
用户输入:
{query}"""
prompt = PromptTemplate(
template=template,
input_variables=["query"],
# 直接从OutputParser中获取输出描述,并对模板的变量预先赋值
partial_variables={"format_instructions": parser.get_format_instructions()}
)
print("====Format Instruction=====")
print(parser.get_format_instructions())
query = "2023年四月6日天气晴..."
model_input = prompt.format_prompt(query=query)
print("====Prompt=====")
print(model_input.to_string())
output = model(model_input.to_messages())
print("====Output=====")
print(output)
print("====Parsed=====")
date = parser.parse(output.content)
print(date)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
输出:
====Format Instruction=====
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here is the output schema:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
{"properties": {"year": {"description": "Year", "title": "Year", "type": "integer"}, "month": {"description": "Month", "title": "Month", "type": "integer"}, "day": {"description": "Day", "title": "Day", "type": "integer"}, "era": {"description": "BC or AD", "title": "Era", "type": "string"}}, "required": ["year", "month", "day", "era"]}
- 1
====Prompt=====
提取用户输入中的日期。
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here is the output schema:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
{"properties": {"year": {"description": "Year", "title": "Year", "type": "integer"}, "month": {"description": "Month", "title": "Month", "type": "integer"}, "day": {"description": "Day", "title": "Day", "type": "integer"}, "era": {"description": "BC or AD", "title": "Era", "type": "string"}}, "required": ["year", "month", "day", "era"]}
- 1
用户输入:
2023年四月6日天气晴...
====Output=====
content='{"year": 2023, "month": 4, "day": 6, "era": "AD"}'
====Parsed=====
year=2023 month=4 day=6 era='AD'
- 1
- 2
- 3
- 4
- 5
- 6
Auto-Fixing Parser
使用LLM修复不符合格式的输出
from langchain.output_parsers import OutputFixingParser
new_parser = OutputFixingParser.from_llm(parser=parser, llm=ChatOpenAI(model="gpt-4"))
#我们把之前output的格式改错
output = output.content.replace("4","四")
print("===格式错误的Output===")
print(output)
try:
date = parser.parse(output)
except Exception as e:
print("===出现异常===")
print(e)
#用OutputFixingParser自动修复并解析
date = new_parser.parse(output)
print("===重新解析结果===")
print(date)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
输出:
===格式错误的Output===
{"year": 2023, "month": 四, "day": 6, "era": "AD"}
===出现异常===
Failed to parse Date from completion {"year": 2023, "month": 四, "day": 6, "era": "AD"}. Got: Expecting value: line 1 column 25 (char 24)
===重新解析结果===
year=2023 month=4 day=6 era='AD'
- 1
- 2
- 3
- 4
- 5
- 6
3. 数据连接封装
主要是封装了一些,文档加载、向量化、检索等
- 目前版本的实现,比较粗糙,老师建议自己实现
文档加载
# pip install pypdf
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("llama2.pdf")
pages = loader.load_and_split()
print(pages[0].page_content)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
文档切分
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200,
chunk_overlap=50, # 思考:为什么要做overlap
length_function=len,
add_start_index=True,
)
paragraphs = text_splitter.create_documents([pages[0].page_content])
for para in paragraphs:
print(para.page_content)
print('-------')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
内置 RAG
# pip install chromadb
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
from langchain.document_loaders import PyPDFLoader
# 加载文档
loader = PyPDFLoader("llama2.pdf")
pages = loader.load_and_split()
# 文档切分
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=100,
length_function=len,
add_start_index=True,
)
texts = text_splitter.create_documents([pages[2].page_content,pages[3].page_content])
# 灌库
embeddings = OpenAIEmbeddings()
db = Chroma.from_documents(texts, embeddings)
# LangChain内置的 RAG 实现
qa_chain = RetrievalQA.from_chain_type(
llm=OpenAI(temperature=0),
retriever=db.as_retriever()
)
query = "llama 2有多少参数?"
response = qa_chain.run(query)
print(response)
# Llama 2 has 7B, 13B, and 70B parameters.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
4. 记忆封装
ConversationBufferMemory 长度无限制
from langchain.memory import ConversationBufferMemory, ConversationBufferWindowMemory
history = ConversationBufferMemory()
history.save_context({"input": "你好啊"}, {"output": "你也好啊"})
print(history.load_memory_variables({}))
history.save_context({"input": "你再好啊"}, {"output": "你又好啊"})
print(history.load_memory_variables({}))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出:
{'history': 'Human: 你好啊\nAI: 你也好啊'}
{'history': 'Human: 你好啊\nAI: 你也好啊\nHuman: 你再好啊\nAI: 你又好啊'}
- 1
- 2
ConversationBufferWindowMemory
只保留最近 k 轮对话
from langchain.memory import ConversationBufferWindowMemory
window = ConversationBufferWindowMemory(k=1)
window.save_context({"input": "第一轮问"}, {"output": "第一轮答"})
window.save_context({"input": "第二轮问"}, {"output": "第二轮答"})
window.save_context({"input": "第三轮问"}, {"output": "第三轮答"})
print(window.load_memory_variables({}))
# {'history': 'Human: 第三轮问\nAI: 第三轮答'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
ConversationSummaryMemory
自动将对话历史,进行摘要
from langchain.memory import ConversationSummaryMemory
from langchain.llms import OpenAI
memory = ConversationSummaryMemory(
llm=OpenAI(temperature=0),
buffer="The conversation is between a customer and a sales. 以中文进行摘要"
)
memory.save_context(
{"input": "你好"}, {"output": "你好,我是你的AI助手。我能为你回答有关AGIClass的各种问题。"})
print(memory.load_memory_variables({}))
# {'history': '\n这段对话是客户和销售之间的对话,AI助手可以回答有关AGIClass的各种问题。'}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
ConversationTokenBufferMemory
根据 Token 数限定 Memory 大小
VectorStoreRetrieverMemory
将 Memory 存储在向量数据库中,根据用户输入检索回最相关的部分
5. LangChain Expression Language
LCEL的一些亮点包括:
-
流支持
-
异步支持
-
优化的并行执行: 链条中可以并行的部分,自动并行执行(例如加载多个文档)
-
重试和回退:为 LCEL 链的任何部分配置重试和回退。更可靠。
-
访问中间结果:可以获取链条的中间结果,你可以流式传输中间结果,并且在每个LangServe服务器上都可用。
-
输入和输出模式:输入和输出模式为每个 LCEL 链提供了从链的结构推断出的 Pydantic 和 JSONSchema 模式。这可以用于输入和输出的验证,是 LangServe 的一个组成部分。
-
无缝LangSmith跟踪集成:随着链条变得越来越复杂,理解每一步发生了什么变得越来越重要。通过 LCEL,所有步骤都自动记录到 LangSmith,以实现最大的可观察性和可调试性。
-
无缝LangServe部署集成:任何使用 LCEL 创建的链都可以轻松地使用 LangServe 进行部署。
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
from pydantic import BaseModel, Field
from typing import List, Dict, Optional
from enum import Enum
# 输出结构
class SortEnum(str, Enum):
data = 'data'
price = 'price'
class OrderingEnum(str, Enum):
ascend = 'ascend'
descend = 'descend'
class Semantics(BaseModel):
name: Optional[str] = Field(description="流量包名称",default=None)
price_lower: Optional[int] = Field(description="价格下限",default=None)
price_upper: Optional[int] = Field(description="价格上限",default=None)
data_lower: Optional[int] = Field(description="流量下限",default=None)
data_upper: Optional[int] = Field(description="流量上限",default=None)
sort_by: Optional[SortEnum] = Field(description="按价格或流量排序",default=None)
ordering: Optional[OrderingEnum] = Field(description="升序或降序排列",default=None)
# OutputParser
parser = PydanticOutputParser(pydantic_object=Semantics)
# Prompt 模板
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"将用户的输入解析成JSON表示。输出格式如下:\n{format_instructions}\n不要输出未提及的字段。",
),
("human", "{query}"),
]
).partial(format_instructions=parser.get_format_instructions())
# 模型
model = ChatOpenAI(temperature=0)
# LCEL 表达式
runnable = (
{"query": RunnablePassthrough()} | prompt | model | parser
)
# 运行
print(runnable.invoke("不超过100元的流量至少10GB的最大流量套餐有哪些"))
# name=None price_lower=None price_upper=100 data_lower=10 data_upper=None sort_by=None ordering=None
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
from langchain.vectorstores import Chroma
# 向量数据库
vectorstore = Chroma.from_texts(
[
"Sam Altman是OpenAI的CEO,openai 一点也不 open",
"Sam Altman被解雇了",
"Sam Altman被复职了"
], embedding=OpenAIEmbeddings()
)
# 检索接口
retriever = vectorstore.as_retriever()
# Prompt模板
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# Chain
retrieval_chain = (
{"question": RunnablePassthrough(),"context": retriever}
| prompt
| model
| StrOutputParser()
)
retrieval_chain.invoke("OpenAI的CEO是谁")
# 'Based on the given context, the CEO of OpenAI is Sam Altman.'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
参考:https://python.langchain.com/docs/expression_language/how_to/
- 配置运行时变量:configure
- 故障回退:fallbacks
- 并行调用:map
- 逻辑分支:routing
- 调用自定义流式函数:generators
- 链接外部Memory:message_history
更多例子:https://python.langchain.com/docs/expression_language/cookbook/
6. Agent 智能体
将LLM作为推理引擎。给定一个任务,智能体自动生成完成任务所需的步骤,执行相应动作(例如选择并调用工具),直到任务完成
- 定义一些工具,可以是一个函数、三方 API、 Chain 或者 Agent 的
run()作为一个 Tool
# 申请搜索的api https://serpapi.com/
# pip install google-search-results
- 1
- 2
搜索工具
from langchain import SerpAPIWrapper
from langchain.tools import Tool, tool
search = SerpAPIWrapper()
tools = [
Tool.from_function(
func=search.run,
name="Search",
description="useful for when you need to answer questions about current events"
),
]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
自定义工具
import calendar
import dateutil.parser as parser
from datetime import date
# 自定义工具
@tool("weekday")
def weekday(date_str: str) -> str:
"""Convert date to weekday name"""
d = parser.parse(date_str)
return calendar.day_name[d.weekday()]
tools += [weekday]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
6.1 智能体类型:ReAct
由于用到了 GG 搜索,需要 魔法连接
from langchain.chat_models import ChatOpenAI
from langchain.llms import OpenAI
from langchain.agents import AgentType
from langchain.agents import initialize_agent
llm = ChatOpenAI(model_name='gpt-4', temperature=0)
agent = initialize_agent(
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("张学友生日那天是星期几")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出:
> Entering new AgentExecutor chain...
我需要找出张学友的生日,然后使用weekday函数来确定那天是星期几。
Action: Search
Action Input: 张学友的生日
Observation: July 10, 1961
Thought:我现在知道张学友的生日是1961年7月10日。我可以使用weekday函数来确定这一天是星期几。
Action: weekday
Action Input: 1961-07-10
Observation: Monday
Thought:我现在知道张学友的生日那天是星期一。
Final Answer: 张学友的生日那天是星期一。
> Finished chain.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
上网确认了下,生日没错
6.2 智能体类型:SelfAskWithSearch
from langchain import OpenAI, SerpAPIWrapper
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
llm = OpenAI(temperature=0)
search = SerpAPIWrapper()
tools = [
Tool(
name="Intermediate Answer",
func=search.run,
description="useful for when you need to ask with search.",
)
]
self_ask_with_search = initialize_agent(
tools, llm, agent=AgentType.SELF_ASK_WITH_SEARCH,
verbose=True, handle_parsing_errors=True
)
self_ask_with_search.run(
"中国的K12逻辑思维教育公司有哪些比较有名的?请列举出前三个"
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
输出:
> Entering new AgentExecutor chain...
Could not parse output: Yes.
Follow up: 中国的K12逻辑思维教育公司有多少家?
Intermediate answer: Invalid or incomplete response
Could not parse output: .
Follow up: 中国有哪些著名的K12逻辑思维教育公司?
Intermediate answer: Invalid or incomplete response
Could not parse output:
Could not parse output: .
Follow up: 请列举出前三个著名的K12逻辑思维教育公司?
Intermediate answer: Invalid or incomplete response
Could not parse output:
Could not parse output:
Follow up: 中国有哪些著名的K12逻辑思维教育公司?
Intermediate answer: Invalid or incomplete response
Could not parse output:
Could not parse output:
Could not parse output:
Follow up: 请列举出前三个著名的K12逻辑思维教育公司?
Intermediate answer: Invalid or incomplete response
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
Follow up: 中国有哪些著名的K12逻辑思维教育公司?
Intermediate answer: Invalid or incomplete response
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
Follow up: 请列举出前三个著名的K12逻辑思维教育公司?
Intermediate answer: Invalid or incomplete response
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
Follow up: 前三个著名的K12逻辑思维教育公司是什么?
Intermediate answer: Invalid or incomplete response
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
So the final answer is:
The top three K12 logic thinking education companies in China are: 1. New Oriental Education & Technology Group; 2. TAL Education Group; 3. China Maple Leaf Educational Systems.
Intermediate answer: Invalid or incomplete response
Could not parse output:
Intermediate answer: Invalid or incomplete response
Could not parse output:
Intermediate answer: Invalid or incomplete response
Could not parse output:
Could not parse output:
Intermediate answer: Invalid or incomplete response
Could not parse output:
Could not parse output:
Could not parse output:
Could not parse output:
So the final answer is: The top three K12 logic thinking education companies in China are: 1. New Oriental Education & Technology Group; 2. TAL Education Group; 3. China Maple Leaf Educational Systems.
> Finished chain.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
'The top three K12 logic thinking education companies in China are:
1. New Oriental Education & Technology Group;
2. TAL Education Group;
3. China Maple Leaf Educational Systems.'
- 1
- 2
- 3
- 4
回答的结果是:新东方、好未来、枫叶教育
再问一个:"中国出名的武侠小说作家?请列举出最有名的前三个"
> Entering new AgentExecutor chain...
Could not parse output: Yes.
Follow up: Who is the most famous Chinese wuxia novelist?
Intermediate answer: Invalid or incomplete response
Could not parse output: .
Follow up: Who are the top three most famous Chinese wuxia novelists?
Intermediate answer: Invalid or incomplete response
Could not parse output: The top three most famous Chinese wuxia novelists are Jin Yong, Gu Long, and Liang Yusheng.
So the final answer is: Jin Yong, Gu Long, and Liang Yusheng
> Finished chain.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
'Jin Yong, Gu Long, and Liang Yusheng'
(金庸、古龙、梁羽生)
- 1
- 2
6.3. OpenAI Assistants
from langchain.agents.openai_assistant import OpenAIAssistantRunnable
interpreter_assistant = OpenAIAssistantRunnable.create_assistant(
name="langchain assistant",
instructions="You are a personal math tutor. Write and run code to answer math questions.",
tools=[{"type": "code_interpreter"}],
model="gpt-4-1106-preview",
)
output = interpreter_assistant.invoke({"content": "10减4.5的差的2.8次方是多少"})
print(output[0].content[0].text.value)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这个case没有跑出结果,一直在运行状态
ReAct 是比较常用的 Planner
SelfAskWithSearch 更适合需要层层推理的场景(例如知识图谱)
OpenAI Assistants 不是万能的
7. LangServe
LangServe 用于将 Chain 或者 Runnable 部署成一个 REST API 服务。
# 安装 LangServe
# pip install "langserve[all]"
# 也可以只安装一端
# pip install "langserve[client]"
# pip install "langserve[server]"
- 1
- 2
- 3
- 4
- 5
- 6
服务端
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv('../utils/.env'))
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langserve import add_routes
import uvicorn
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple api server using Langchain's Runnable interfaces",
)
model = ChatOpenAI()
prompt = ChatPromptTemplate.from_template("讲一个关于{topic}的笑话")
add_routes(
app,
prompt | model,
path="/joke",
)
if __name__ == "__main__":
uvicorn.run(app, host="localhost", port=8080)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
客户端
from langserve import RemoteRunnable
joke_chain = RemoteRunnable("http://localhost:8080/joke/")
joke_chain.invoke({"topic": "小明"})
- 1
- 2
- 3
- 4
- 5
输出
AIMessage(content='小明上课老师问:小明,你的作业为什么没有写完?\n小明说:老师,我家的狗吃了我的作业。\n老师很生气地说:小明,这个借口已经听过很多次了!\n小明立刻回答:老师,真的是这样的!我的狗吃完了作业,我还特意把作业从狗的肚子里拿出来给你看呢!\n老师顿时无言以对,全班都笑翻了。')
- 1
LC 和 SK 对比
| 功能/工具 | LangChain | Semantic Kernel |
|---|---|---|
| 版本号 | 0.0.341 | python-0.3.15.dev |
| 适配的 LLM | 多 | 少 + 外部生态 |
| Prompt 工具 | 支持 | 支持 |
| Prompt 函数嵌套 | 需要通过 LCEL | 支持 |
| Prompt 模板嵌套 | 不支持 | 不支持 |
| 输出解析工具 | 支持 | 不支持 |
| 上下文管理工具 | 支持 | C#版支持,Python版尚未支持 |
| 内置工具 | 多,但良莠不齐 | 少 + 外部生态 |
| 三方向量数据库适配 | 多 | 少 + 外部生态 |
| 服务部署 | LangServe | 与 Azure 衔接更丝滑 |
| 管理工具 | LangSmith/LangFuse | Prompt Flow |

