
热门标签
热门文章
- 1RabbitMQ入门_rabbitmq 开启mqtt后没有15675端口
- 2uniapp保存修改个人信息后,使用uni.navigateBack(),返回上一页,没有消息提示,但是已经写过消息提示代码
- 3Stable Diffusion教程:4000字说清楚图生图_stable diffusion拉伸、裁剪、填充
- 4工控安全工具集
- 5java并发编程的艺术和并发编程这一篇就够了_java并发编程的艺术和java并发编程之美
- 6语义分割综述_语义分割多通道数据
- 7寒假集训一期总结
- 8MySQL的四个事务隔离级别有哪些?各自存在哪些问题?_mysql事物的隔离级别
- 9LangChain曝关键漏洞,数百万AI应用面临攻击风险_langchain 漏洞
- 10[转](21条消息) Pico Neo 3教程☀️ 三、SDK 的进阶功能_pico3怎么转换场景
当前位置: article > 正文
Hive表数据优化_hive表的优化
作者:IT小白 | 2024-08-14 00:07:05
赞
踩
hive表的优化
Hive表数据优化
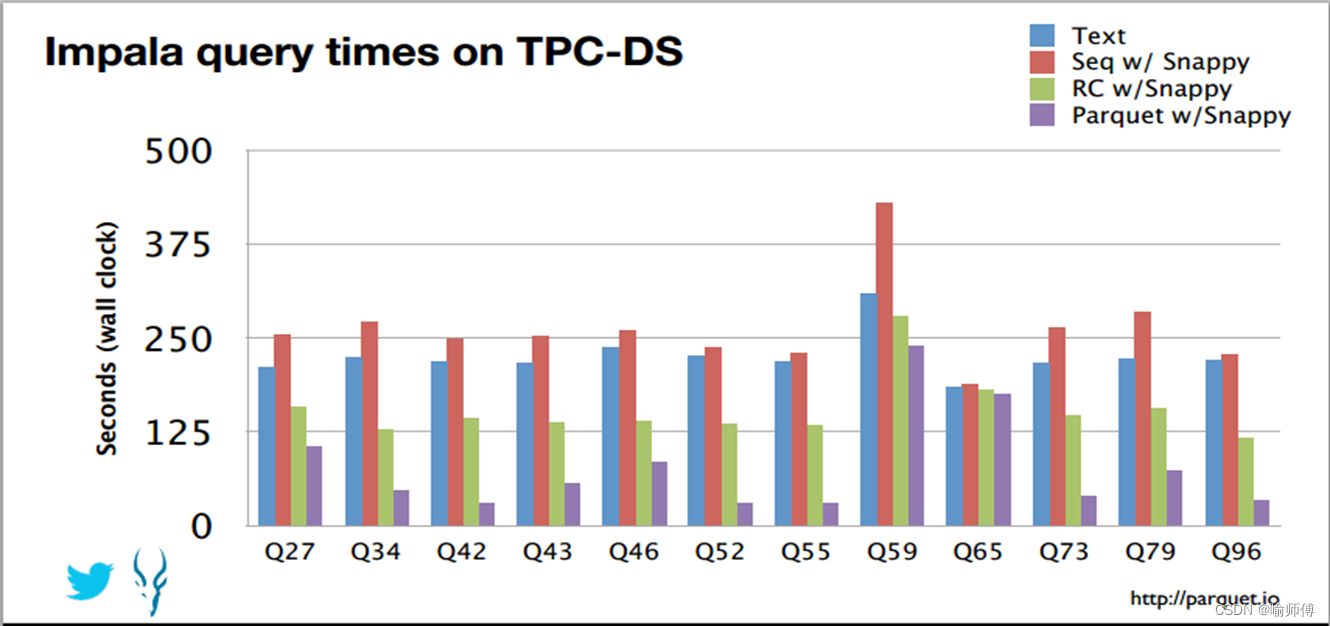
1.文件格式
为Hive表中的数据选择一个合适的文件格式,对提高查询性能的提高是十分有益的。

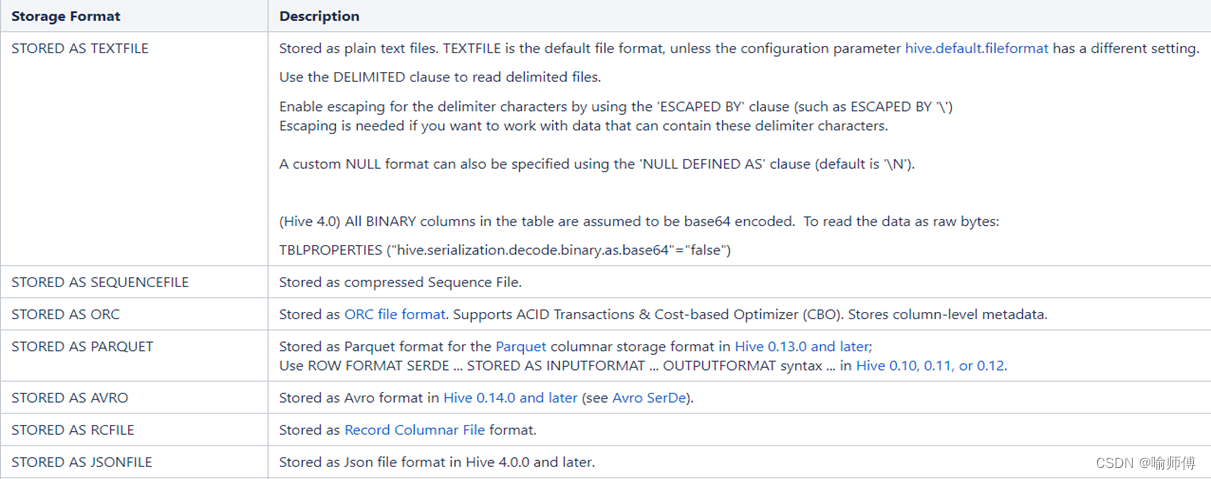
(1)Text File
文本文件是Hive默认使用的文件格式,文本文件中的一行内容,就对应Hive表中的一行记录。

可通过以下建表语句指定文件格式为文本文件:
create table textfile_table
(column_specs)
stored as textfile;
- 1
- 2
- 3
(2)ORC
ORC(Optimized Row Columnar)file format是Hive 0.11版里引入的一种列式存储的文件格式。ORC文件能够提高Hive读写数据和处理数据的性能。

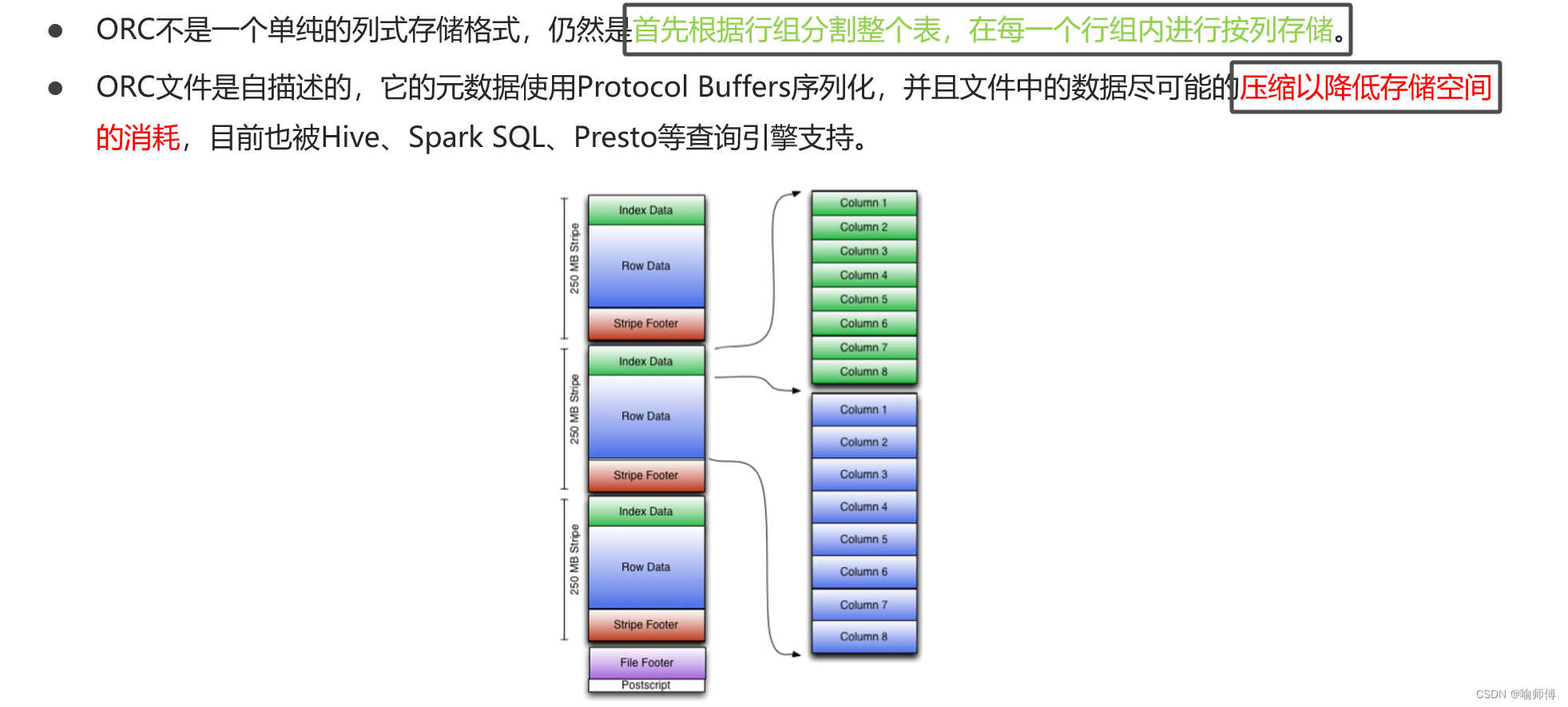
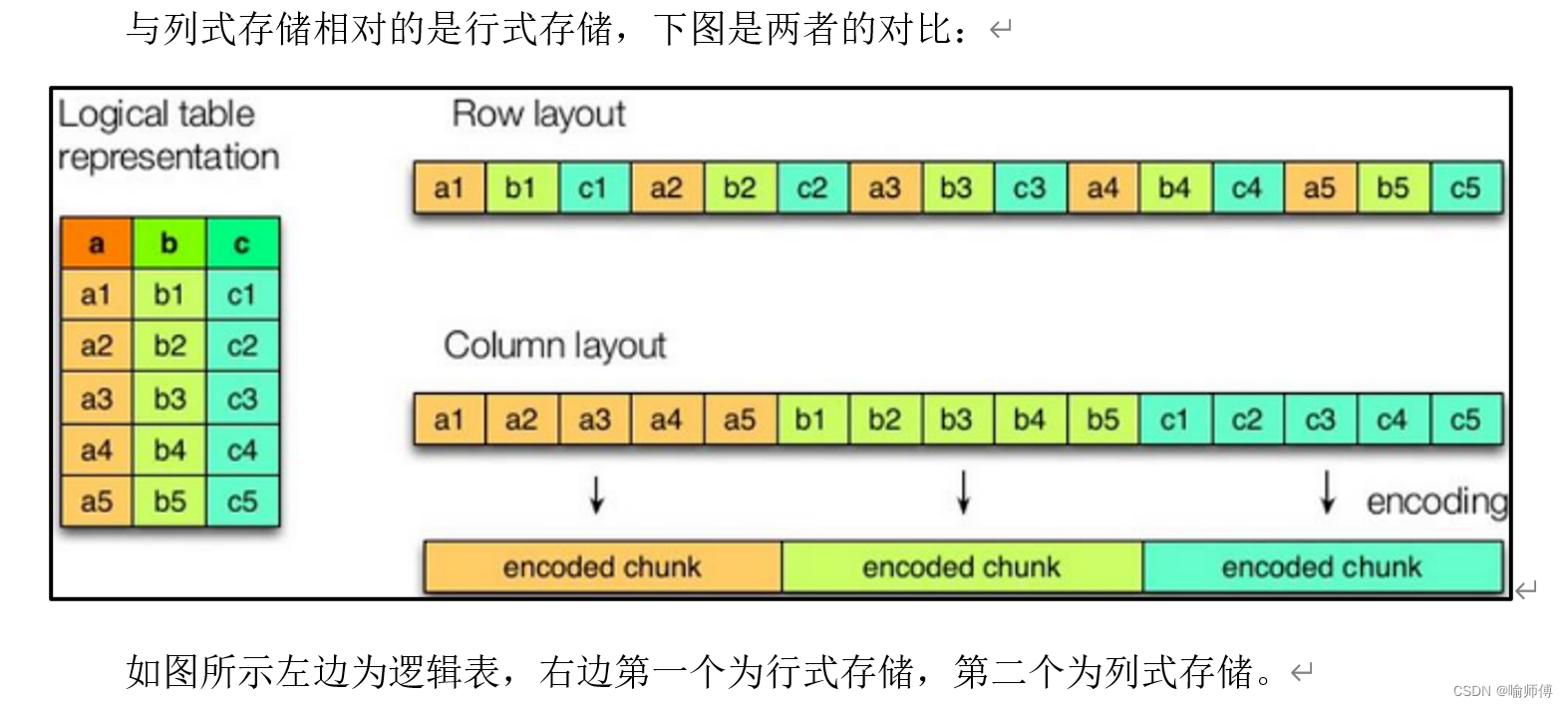
- 行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。 - 列存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
text file和sequence file都是基于行存储的,orc和parquet是基于列式存储的。
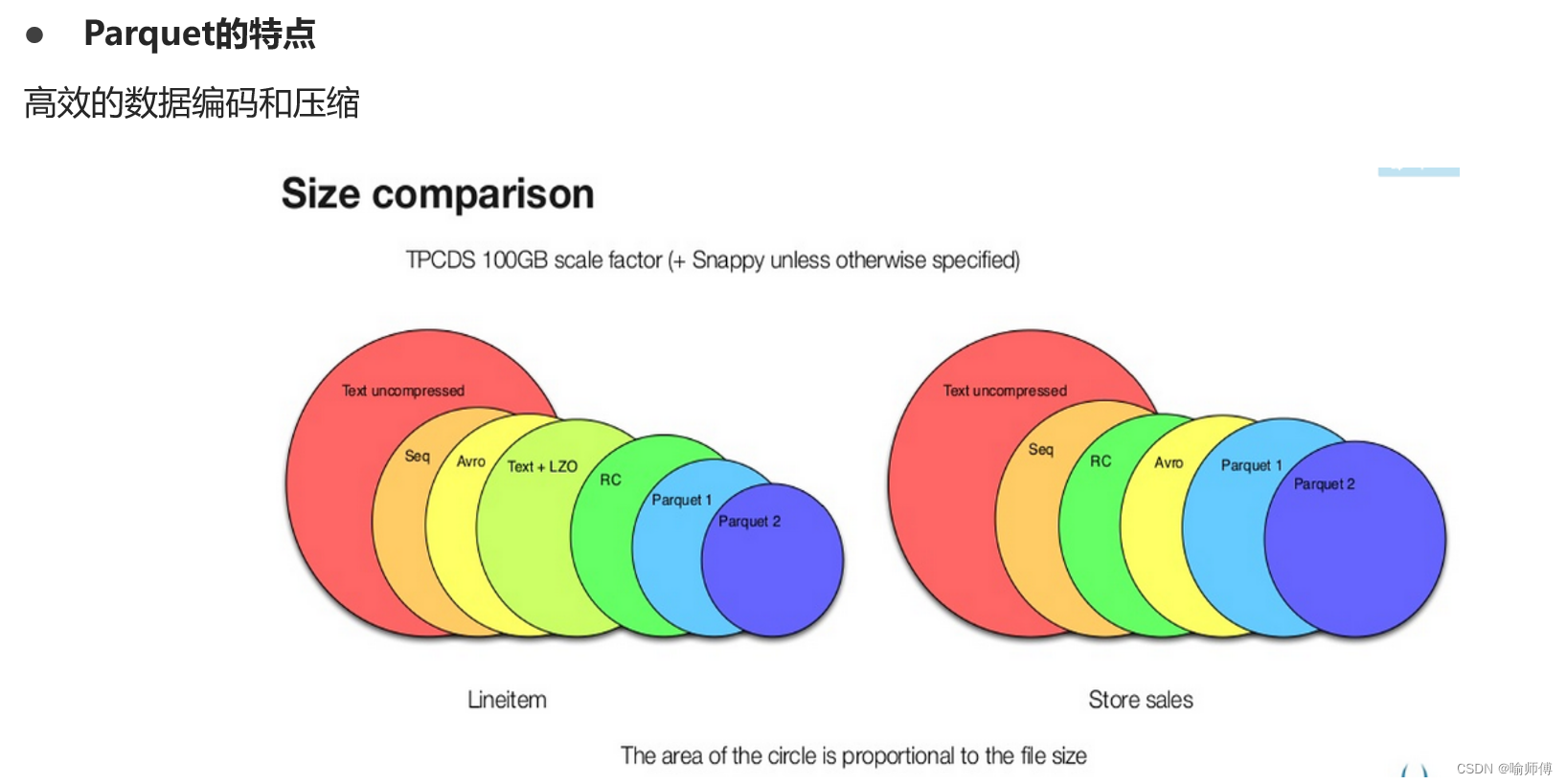
(3)Parquet
Parquet文件是Hadoop生态中的一个通用的文件格式,它也是一个列式存储的文件格式。

2.数据压缩
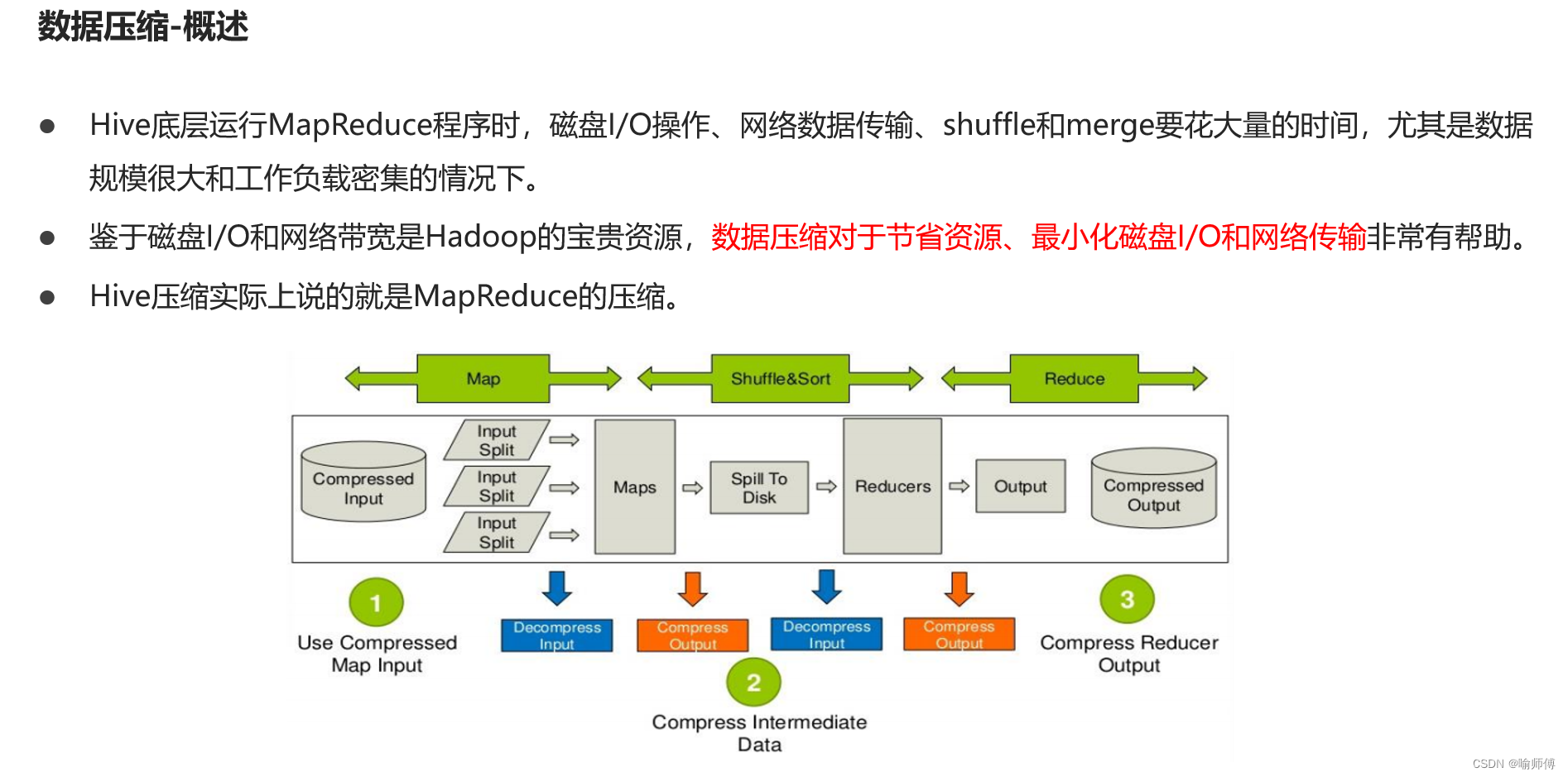
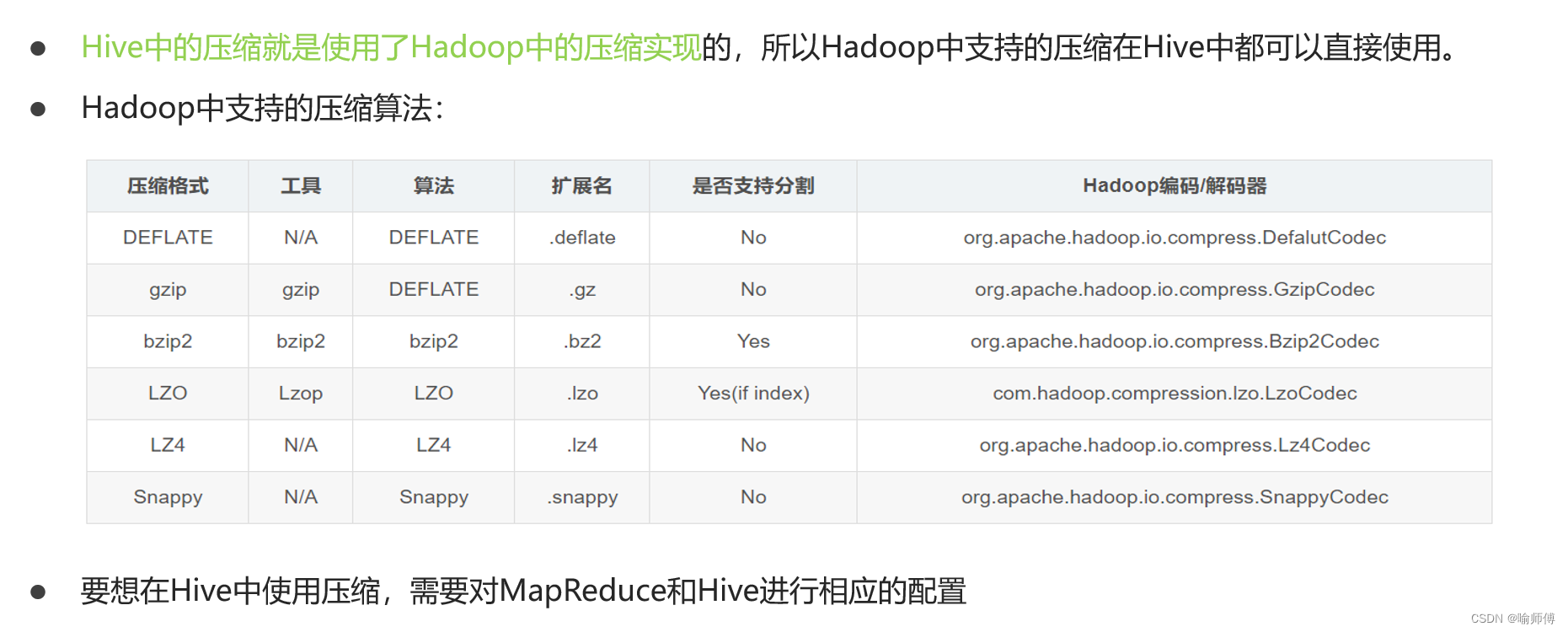

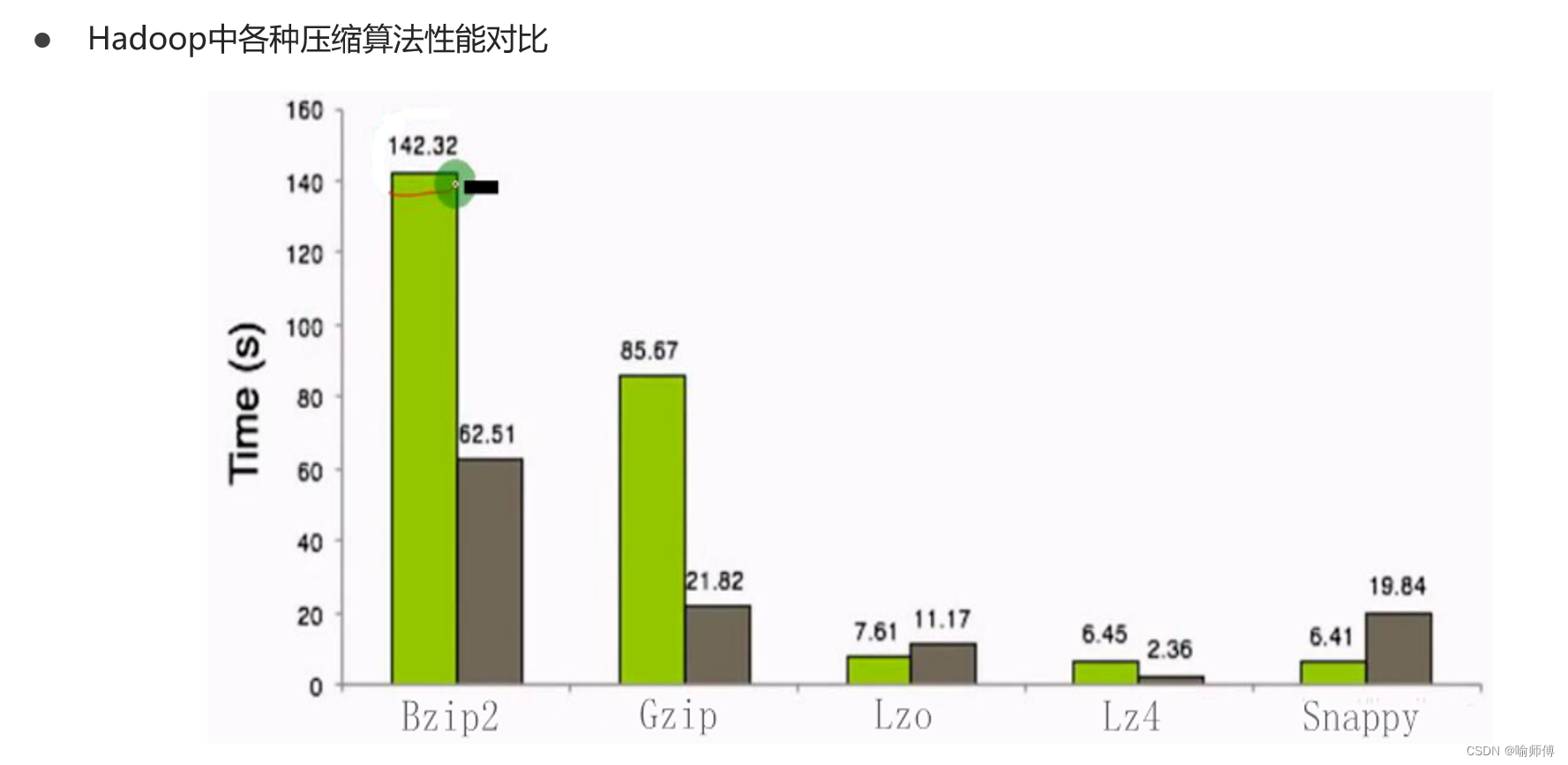
(1)Hive表数据进行压缩
在Hive中,不同文件类型的表,声明数据压缩的方式是不同的。
- TextFile
若一张表的文件类型为TextFile,若需要对该表中的数据进行压缩,多数情况下,无需在建表语句做出声明。直接将压缩后的文件导入到该表即可,Hive在查询表中数据时,可自动识别其压缩格式,进行解压。
需要注意的是,在执行往表中导入数据的SQL语句时,用户需设置以下参数,来保证写入表中的数据是被压缩的。
--SQL语句的最终输出结果是否压缩
set hive.exec.compress.output=true;
--输出结果的压缩格式(以下示例为snappy)
set mapreduce.output.fileoutputformat.compress.codec =org.apache.hadoop.io.compress.SnappyCodec;
- 1
- 2
- 3
- 4
- ORC
若一张表的文件类型为ORC,若需要对该表数据进行压缩,需在建表语句中声明压缩格式如下:
create table orc_table
(column_specs)
stored as orc
tblproperties ("orc.compress"="snappy");
- 1
- 2
- 3
- 4
- Parquet
若一张表的文件类型为Parquet,若需要对该表数据进行压缩,需在建表语句中声明压缩格式如下:
create table orc_table
(column_specs)
stored as parquet
tblproperties ("parquet.compression"="snappy");
- 1
- 2
- 3
- 4
(2)计算过程中使用压缩
- 单个MR的中间结果进行压缩
单个MR的中间结果是指Mapper输出的数据,对其进行压缩可降低shuffle阶段的网络IO,可通过以下参数进行配置:
--开启MapReduce中间数据压缩功能
set mapreduce.map.output.compress=true;
--设置MapReduce中间数据数据的压缩方式(以下示例为snappy)
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
- 1
- 2
- 3
- 4
- 单条SQL语句的中间结果进行压缩
单条SQL语句的中间结果是指,**两个MR(一条SQL语句可能需要通过MR进行计算)之间的临时数据,**可通过以下参数进行配置:
--是否对两个MR之间的临时数据进行压缩
set hive.exec.compress.intermediate=true;
--压缩格式(以下示例为snappy)
set hive.intermediate.compression.codec= org.apache.hadoop.io.compress.SnappyCodec;
- 1
- 2
- 3
- 4
3.存储优化
(1)避免小文件生成


(2)合并小文件
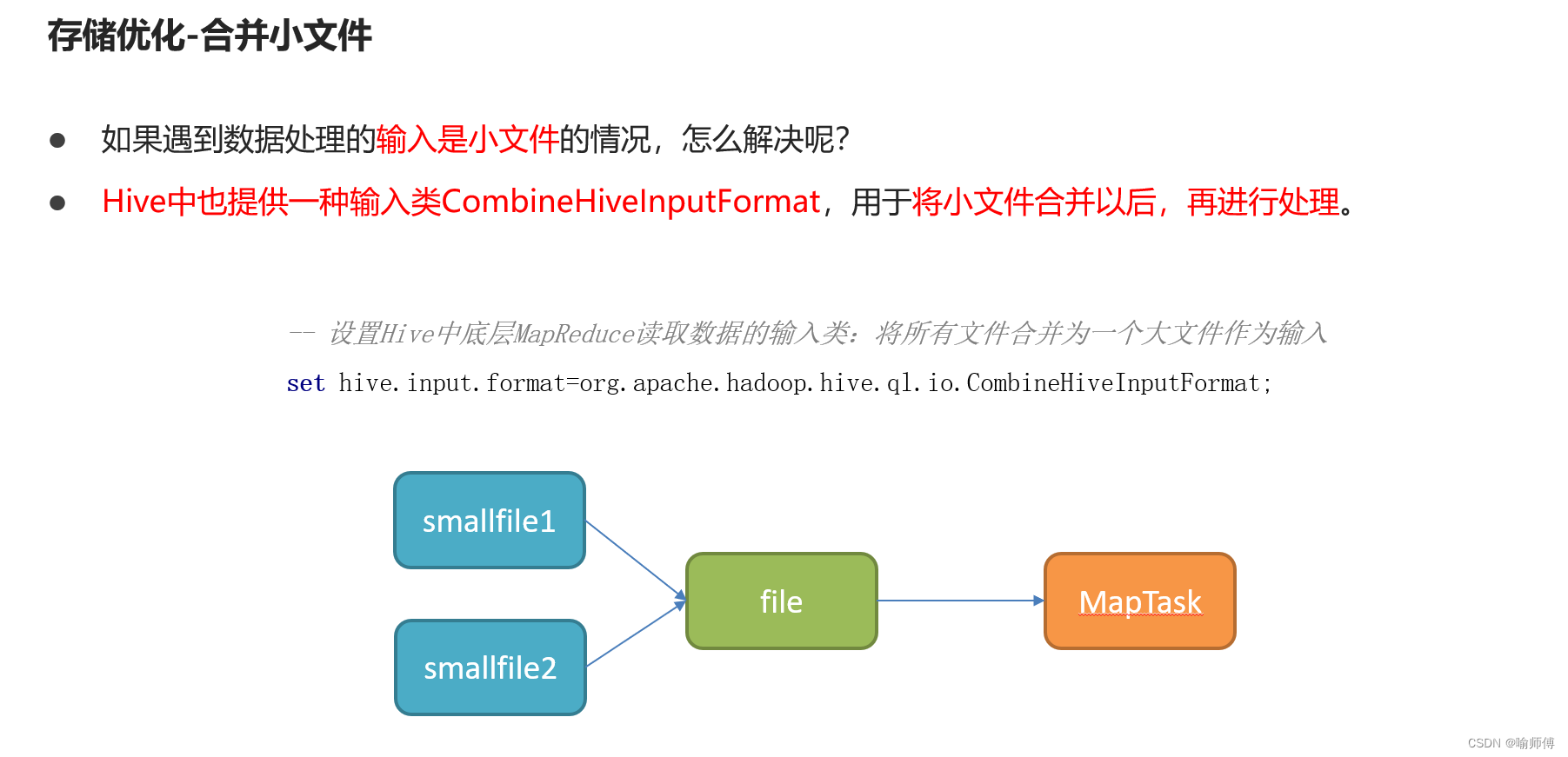
(3)ORC文件索引
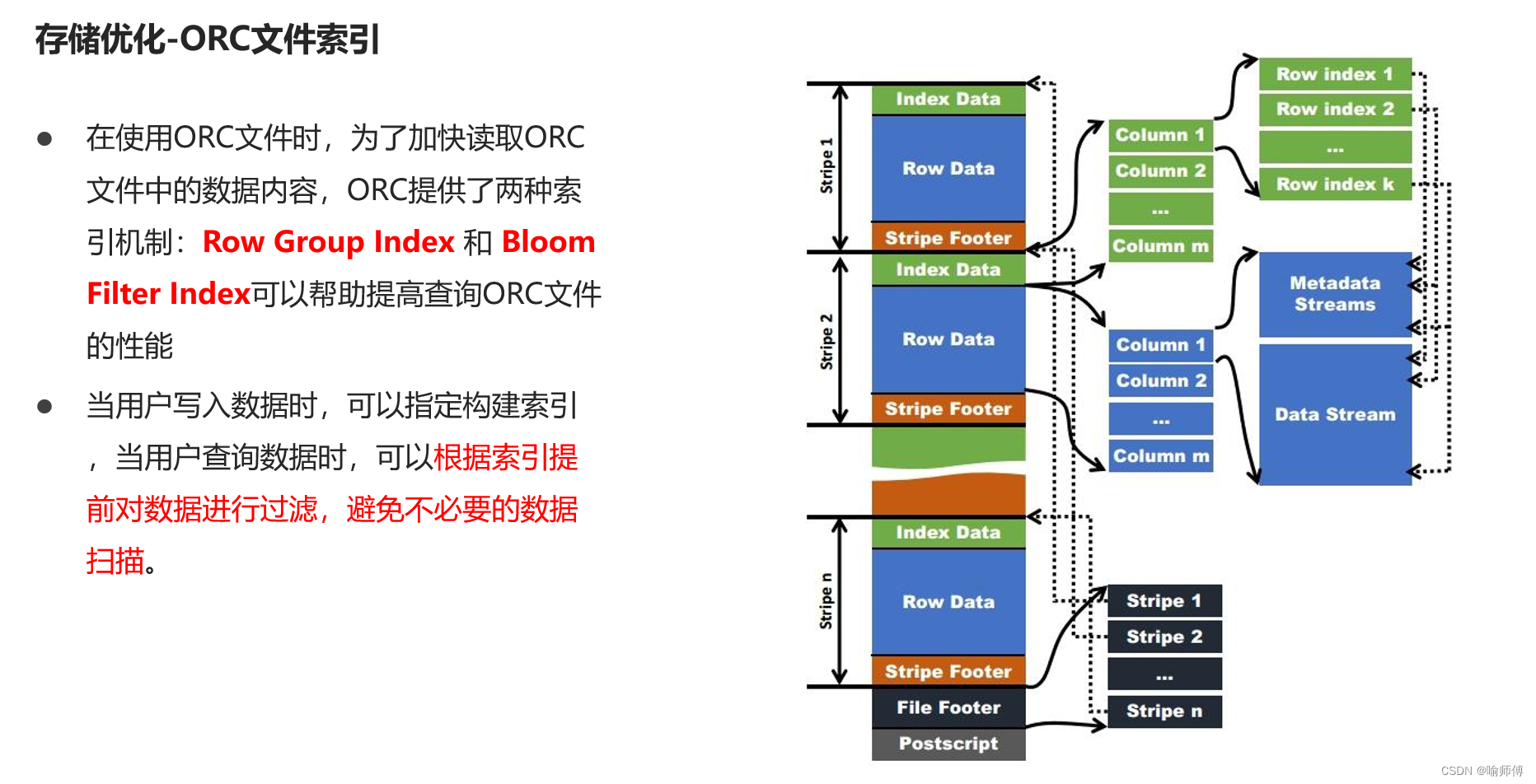



(4)ORC矢量化查询


推荐阅读
相关标签

