
- 1【100个 Unity实用技能】☀️ | Unity读取本地文件(Json,txt等)的三种方法示例
- 2使用mpvue框架开发小程序入门系列_mpvue小程序可以用idea打开吗
- 3【鸿蒙开发】第九章 ArkTS语言UI范式-状态管理(一)_鸿蒙artts对象数组中数据怎么更新
- 4Juno markets:特斯拉FSD登陆中国市场,自动驾驶能否颠覆传统出行?
- 5ONLYOFFICE 桌面编辑器 8.1使用体验分享
- 6基于Flask的Web应用框架_flask 前端框架
- 75大技巧教你快速找到最感兴趣的文章
- 8ssh: command not found的解决办法_ssh报错command 'roslaunch' not found, but can be ins
- 9Elasticsearch 之 commit point | Segment | refresh | flush 索引分片内部原理_在 elasticsearch 中,commit 操作做了什么
- 10matlab读取cvs文件的几种方法_matla中怎么完整读入csv文件
Mysql数据库
赞
踩
Day01
一、数据库介绍Mysql5.7
1、什么是数据库
- 数据库就是一个存放计算机数据的仓库,这个仓库是按照一定的数据结构(数据结构是指数据的组织形式或数据之间的联系)来对数据进行组织和存储的,可以通过数据库提供的多种方法来管理其中的数据。
- 由来: 过去:账本
现在:excel
当前:mysql - Mysql:开源:免费、源代码开放
2、数据库的种类
- 最常用的数据库模式主要有两种,即关系型数据库和非关系型数据库。
3、生产环境常用数据库
- 生产环境主流的关系型数据库有 Oracle、Microsoft SQL Server、MySQL/MariaDB等。
- 生产环境主流的非关系型数据库有 MongoDB Memcached Redis
- 1
- 2
4、关系型数据库
1、关系型数据库介绍
- 关系型数据库模型是把复杂的数据结构归结为简单的二元关系(即二维表格形式)。在关系型数据库中,对数据的操作几乎全部建立在一个或多个关系表格上,通过这些关联的表格分类、合并、连接或选取等运算来实现数据的管理。
- 关系型数据可以很好地存储一些关系模型的数据,比如一个老师对应多个学生的数据(“一对多”),一本书对应多个作者(“一对多”),一本书对应一个出版日期(“一对一”)
- 关系型数据库诞生距今已有 40 多年了,从理论产生到发展到实现产品,例如:常见的 MySQL 和 Oracle 数据库,Oracle 在数据库领域里上升到了霸主地位,形成每年高达数百亿美元的庞大产业市场,而 MySQL 也是不容忽视的数据库,以至于被 Oracle 重金收购了。
- 数据的存储形式:

2、关系型数据库小结
- 关系型数据库在存储数据时实际就是采用的一张二维表(和 Word 和 Excell 里表格几乎一样)。
- 市场占有量较大的是 MySQL 和 Oracle 数据库,而互联网场景最常用的是 MySQL 数据库。
- 通过 SQL 结构化查询语言来存取、管理关系型数据库的数据。
- 关系型数据库在保持数据安全和数据一致性方面很强,遵循 ACID 理论 ACID指的的事务的4大特性
- 1
- 2
- 3
- 4
5、非关系型数据库
1、非关系数据库诞生的背景
- 非关系型数据库也被称为 NoSQL 数据库,NoSQL 的本意是 “Not Only SQL”,指的是非关系型数据库,而不是“NO SQL”的意思,NoSQL 的产生并不是要彻底否定关系型数据库,而是作为传统数据库的一个有效补充。NoSQL 数据库在特定的场景下可以发挥难以想象的高效率和高性能。特别是对于规模日益扩大的海量数据,超大规模和高并发的微博、微信、SNS 类型的纯动态网站已经显得力不从心,暴露了很多难以克服的问题,例如:传统的关系型数据库IO瓶颈、性能瓶颈都难以有效突破,于是开始出现了大批针对特定场景,以高性能和使用便利为目的功能特异化的数据库产品。NoSQL(非关系型)类的数据库就是这样的情景中诞生并得到了非常迅速的发展。
- NoSQL 是非关系型数据库的广义定义。它打破了长久以来关系型数据库与ACID理论大一统的局面。NoSQL数据存储不需要固定的表结构,通常也不存在连续操作。
非关系型数据库小结
- NoSQL 数据库不是否定关系型数据库,而是作为关系数据库的一个重要补充。 (no only sql)
- NoSQL 数据库为了灵活及高性能、高并发而生;
- 在NoSQL 数据库领域,当今的最典型产品为 Redis(持久化缓存)、MongoDB、Memcached(纯内存)等。
- NoSQL 数据库没有标准的查询语言(SQL),通常使用数据接口或者查询API。
- 1
- 2
- 3
- 4
3、非关系型数据库种类
1.键值(Key-Value)存储数据库
- 键值数据库就类似传统语言中使用的哈希表。可以通过key来添加、查询或者删除数据,因为使用key主键访问,所以会获得很高的性能及扩展性。这个表中有一个特定的键和一个指针指向特定的数据。Key-Value模型对于IT系统来说的优势在于简单、易部署、高并发。
- 典型产品:Memcached、Redis、MemcachedB
2、列存储(Column-Oriented)数据库
- 列存储数据库将数据存储存在列族(Column Family)中,一个列族存储经常被一起查询的相关数据。举个例子,如果有一个 Person 类,通常会一起查询他们的姓名和年龄而不是薪资。这种情况下,姓名和年龄就会被放入一个列族中,而薪资则在另一个列族中。这部分数据库通常用来应对分布式存储的海量数据。键仍然存在,但是他们的特点是指向了多个列。这些列是由列家族来安排的。
- 典型产品:Cassandra,HBase
3、面向文档(Document-Oriented)的数据库
- 面向文档数据库会将数据以文档的形式存储,数据存储的最小单位是文档,同一个表中存储的文档属性可以是不同的,数据可以使用XML、JSON等多种形式存储。
- 典型产品:MongDB、CouchDB
4、图形(Graph)数据库
- 图形数据库允许我们将数据以图的方式存储。图形结构的数据库同其他行列以及刚性结构的 SQL 数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。
- 典型产品:Neo4J、InfoGr id
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
问题回顾:1.什么是数据库 存放数据的仓库,以表的形式进行存储
2.数据库的种类有哪些 关系型数据库与非关系型数据库
3.我们要学的是什么 mysql redis
6、常用关系型数据库管理系统
1、Oracle 数据库

- Oracle 前身叫 SDL,由 Larry Ellison 和另两个编程人员在1977创办,他们开发了自己的拳头产品,在市场上大量销售,1979年,Oracle 公司引入了第一个商用 SQL关系数据库管理系统。Oracle公司是最早开发关系数据库的厂商之一,其产品支持最广泛的操作系统平台。目前 Oracle 关系数据库产品的市场占有率数一数二。
- Oracle 公司是目前全球最大的数据库软件公司,也是近年业务增长极为迅速的软件提供与服务商。
- 主要应用范围:传统大企业,大公司,政府,金融,证券等等。
- 版本升级:Oracle8i,Oracle9i,Oracle10g,Oracle11g,Oracle12c。
2、MySQL 数据库

- MySQL 数据库是一个中小型关系型数据库管理系统,软件开发者为瑞典 MySQL AB 公司。在2008年1月16号被 Sun 公司收购,后 Sun 公司又被 Oracle 公司收购。目前MySQL 被广泛地应用在 Internet 上的大中小型网站中。由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,许多大中小型网站为了降低网站总体拥有成本而选择了 MySQL 作为网站数据库,甚至国内知名的淘宝网也选择弃用 Oracle 而更换为更开放的 MySQL。
- MySQL 数据库主要应用范围:互联网领域,大中小型网站,游戏公司,电商平台等等。
3、MariaDB 数据库

- MariaDB 数据库管理系统是 MySQL 数据库的一个分支,主要由开源社区维护。开发这个 MariaDB 数据库分支的可能原因之一是:甲骨文公司收购了MySQL 后,有将 MySQL 闭源的潜在风险,因此 MySQL 开源社区采用分支的方式来避开这个风险。
- 开发 MariaDB 数据库的目的是完全兼容 MySQL 数据库,包括 API 和命令行,使之能轻松的成为 MySQL 的代替品。在存储引擎方面,使用 XtraDB (英语:XtraDB)来代替MySQL 的 InnoDB MariaDB 由 MySQL 的创始人 Michael Widenius(英语:Michael Widenius)主导开发,他早前曾以 10 亿美元的价格,将自己创建的公司MySQL AB卖给了 SUN,此后,随着 SUN 被甲骨文收购,MySQL 的所有权也落入Oracle 的手中,MariaDB 数据库的名称来自 MySQL 的创始人Michael Widenius 的女儿 Maria 的名字。
4、SQL Server 数据库
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M7skp9H2-1692006783544)(https://yangge666.oss-cn-nanjing.aliyuncs.com/img/image-20230807231748595.png)]
- Microsoft SQL Server是微软公司开发的大型关系型数据库系统。1987年,微软和IBM合作开发完成 OS/2,IBM 在其销售的 OS/2 ExtendedEdition 系统中绑定了 OS/2 DatabaseManager,而微软产品线中尚缺少数据库产品。为此,微软将目光投向 Sybase,同 Sybase 签订了合作协议,使用 Sybase 的技术开发基于 OS/2 平台的关系型数据库。1989年,微软发布了 SQLServer1.0 版。
- SQL Server 的功能比较全面,效率高,可以作为中型企业或单位的数据库平台。
- SQL Server 可以与 Windows 操作系统紧密集成,不论是应用程序开发速度还是系统事务处理运行速度,都能得到较大的 提升。SQL Server 的缺点是只能在 Windows 系统下运行。
- 主要应用范围:部分企业电商(央视购物),使用windows服务器平台的企业。
7、常用非关系型数据库管理系统
1、Memcached(Key-Value)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h0EUjJ04-1692006783544)(https://yangge666.oss-cn-nanjing.aliyuncs.com/img/image-20230807231903982.png)]
- Memcached 是一个开源的、高性能的、具有分布式内存对象的缓存系统。通过它可以减轻数据库负载,加速动态的 Web 应用,最初版本由 LiveJoumal 的 Brad Fitzpatrick在2003年开发完成。目前全球有非常多的用户都在使用它来构建自己的大负载网站或提高自己的高访问网站的响应速度。注意:Memcache 是这个项目的名称,而Memcached 是服务器端的主程序文件名。
- 缓存一般用来保存一些经常被存取的对象或数据(例如,浏览器会把经常访问的网页缓存起来一样),通过缓存来存取对象或数据要比在磁盘上存取快很多,前者是内存,后 者是磁盘。Memcached 是一种纯内存缓存系统,把经常存取的对象或数据缓存在 Memcached 的内存中,这些被缓存的数据被程序通过API的方式被存取,Memcached里面的数据就像一张巨大的 HASH 表,数据以 Key-Value 对的方式存在。Memcached 通过缓存经常被存取的对象或数据,从而减轻频繁读取数据库的压力,提高网站的响应速度.官方:http://Memcached.org/
- 由于Memcached 为纯内存缓存软件,一旦重启所有数据都会丢失,因此,新浪网基于 Memcached 开发了一个开源项目 MemcacheDB。通过为 Memcached 增加 Berkeley DB 的持久化存储机制和异步主辅复制机制,使 Memcached 具备了事务恢复能力、持久化数据存储能力和分布式复制能力,但是最近几年逐渐被其他的持久化产品替代例如Redis。
Memcached缺点:
1、存储的数据类型比较单一 只能存储字符串
2、无法持久化(没办法把数据存放到磁盘中)
2、Redis(Key-Value)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yHYglsfn-1692006783544)(https://yangge666.oss-cn-nanjing.aliyuncs.com/img/image-20230807231917179.png)]
- Redis 是一个Key-Value型存储系统。但Redis支持的存储value 类型相对更多,包括 string(字符串)、list(列表)、set(集合)和 zset(有序集合)等。这些数据类型都支持 push/pop、add/remove 及取交集、并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,Redis 支持各种不同方式的排序。与 Memcached 一样,为了保证效率,Redis 的数据都是缓存在内存中。区别是 Redis 会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了 Master-Slave(主从)同步。
- Redis 是一个高性能的 Key-Value 数据库。Redis 的出现,很大程度补偿了 Memcached 这类 Key-Value 存储的不足,在部分场合可以对关系数据库有很好的补充作用。它提供了 Python,Ruby,Erlang,PHP 客户端,使用很方便。官方:http://www.Redis.io/documentation
- Redis 特点:
1. 支持内存缓存,这个功能相当于 Memcached。
2. 支持持久化存储,这个功能相当于 MemcacheDB。
3. 数据类型更丰富。比其他 Key-Value 库功能更强。
4. 支持主从集群,分布式。
- 1
- 2
- 3
- 4
- 应用:缓存从存取 Memcached 更改存取 Redis。
3、MongoDB (Document-Web)

- MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,类似 Json 的 Bjson 格式,因此可以存储比较复杂的数据类型。MongoDB 最大的特点是他支持查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。它的特点是高性能、易部署、易使用,存储数据非常方便。
- MongoDB 服务端可运行在 Linux、Windows 或 OS X 平台,支持32位和64位应用,默认端口为 27017。推荐运行在64位平台。
- MongoDB 把数据存储在文件中(默认路径为:/data/db)。
二、正篇

MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
MySQL所使用的 SQL 语言是用于访问数据库的最常用标准化语言。MySQL 软件采用了双授权政策,分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发都选择 MySQL 作为网站数据库。
RDBMS即关系数据库管理系统(Relational Database Management System)
MySQL 类型
1、MySQL Community Server
- MySQL Community Server是社区版本,开源免费,但不提供官方技术支持。MySQL Community Server也是我们通常用的MySQL的版本。根据不同的操作系统平台细分为多个版本。
2、MySQL Enterprise Edition
- MySQL Enterprise Edition企业版本,需付费,可以试用30天。
3、MySQL Cluster
- MySQL Cluster集群版,开源免费。可将几个MySQL Server封装成一个Server。MySQL Cluster CGE 高级集群版,需付费。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
MySQL 安装方式
1、yum 安装
优点:操作简单易用。不用单独下载,服务器可以联网且yum源没有问题即可(可以选择国内的163/阿里源)
- 1
2、编译安装
- 5.1.X 及之前的版本是通过下载tar包以后解压后进入软件包解压路径。然后./configure、make、make install
- 5.4.X 到 5.7.X 通过下载tar包以后解压后进入软件包解压路径。然后 cmake、make、make install(cmake需要提前安装)
优点:可以定制功能特性。
- 1
- 2
- 3
3、二进制安装
官方下载二进制包,解压初始化即可直接使用不用安装
- 1
4、rpm 安装
- 需要提前下载 rpm 软件包上传到服务器系统本地
- 使用 rpm 或者 yum 命令直接安装
- 1
- 2
MySQL 版本号
以 MySQL 5.7.27 这个版本的版本号为例说明每个数字含义。
- 第一个数字(5)主版本号:文件格式改动时,将作为新的版本发布;
- 第二个数字(7)发行版本号:新增特性或者改动不兼容时,发行版本号需要更改;
- 第三个数字(27)发行序列号:主要是小的改动,如bug的修复、函数添加或更改、配置参数的更改等。
- 1
- 2
- 3
- 4
- 5
关系型数据库与非关系型数据库的区别:
1.关系型数据库: 优点: 1、易于维护:都是使用表结构,格式一致; 2、使用方便:SQL语言通用,可用于复杂查询; 3、复杂操作:支持SQL,可用于一个表以及多个表之间非常复杂的查询。 缺点: 1、读写性能比较差,尤其是海量数据的高效率读写; 2、固定的表结构,灵活度稍欠; 3、高并发读写需求,传统关系型数据库来说,硬盘I/O是一个很大的瓶颈。 ============================================================================= 2.非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合,可以是文档或者键值对等。 优点: 1、格式灵活:存储数据的格式可以是key,value形式、文档形式、图片形式等等,使用灵活,应用场景广泛。 2、速度快:nosql可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘; 3、高扩展性; 4、成本低:nosql数据库部署简单,基本都是开源软件。 缺点: 1、不提供sql支持; 2、无事务处理; 3、数据结构相对复杂,复杂查询方面稍欠。

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
MySQL的官方网址: http://www.mysql.com/ ,MySQL的社区版本下载地址为: http://dev.mysql.com/downloads/mysql/ ,在写本文时,当前的MySQL最新版本是:8.0 。
什么是sql?
SQL代表结构化查询语言(Structured Query Language)。SQL是用于访问数据库的标准化语言。
SQL包含三个部分:
数据定义语言包含定义数据库及其对象的语句,例如表,视图,触发器,存储过程等。
数据操作语言包含允许您更新和查询数据的语句。
数据控制语言允许授予用户权限访问数据库中特定数据的权限。
- 1
- 2
- 3
mysql安装
关闭防火墙和selinux
1、编译安装mysql5.7
1、清理安装环境:
# yum erase mariadb mariadb-server mariadb-libs mariadb-devel -y
# userdel -r mysql
# rm -rf /etc/my*
# rm -rf /var/lib/mysql
- 1
- 2
- 3
- 4
2、创建mysql用户
[root@mysql-server ~]# useradd -r mysql -M -s /bin/false
- 1
3、从官网下载tar包
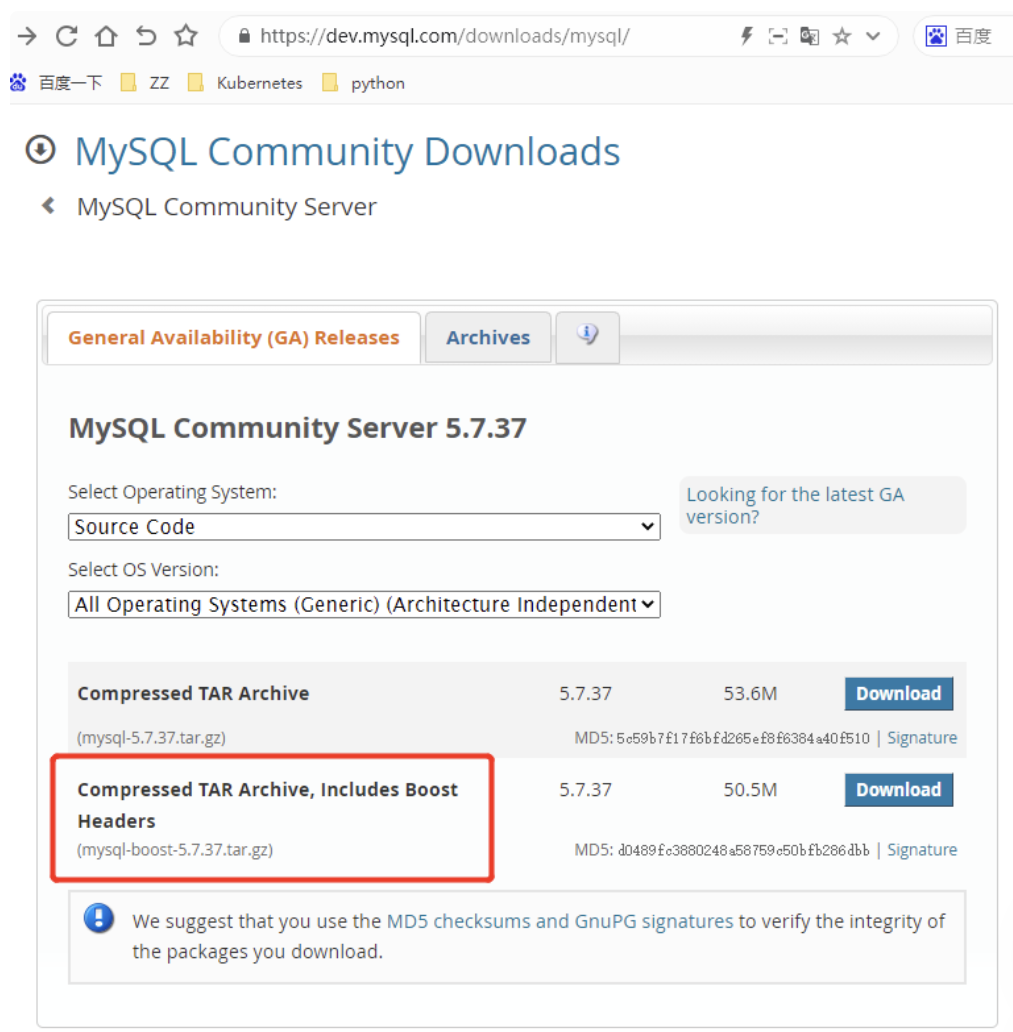
[root@mysql-server ~]# wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-boost-5.7.27.tar.gz
- 1
4、安装编译工具
# yum -y install ncurses ncurses-devel openssl-devel bison gcc gcc-c++ make cmake
- 1
5、创建mysql目录
[root@mysql-server ~]# mkdir -p /usr/local/{data,mysql,log}
- 1
6、解压
[root@mysql-server ~]# tar xzvf mysql-boost-5.7.27.tar.gz -C /usr/local/
注:如果安装的MySQL5.7及以上的版本,在编译安装之前需要安装boost,因为高版本mysql需要boots库的安装才可以正常运行。否则会报CMake Error at cmake/boost.cmake:81错误
安装包里面自带boost包
Boost库是为C++语言标准库提供扩展的一些C++程序库
- 1
- 2
- 3
- 4
7、编译安装
cd 解压的mysql目录 [root@mysql-server ~]# cd /usr/local/mysql-5.7.27/ [root@mysql-server mysql-5.7.27]# cmake . \ -DWITH_BOOST=boost/boost_1_59_0/ \ -DCMAKE_INSTALL_PREFIX=/usr/local/mysql \ -DSYSCONFDIR=/etc \ -DMYSQL_DATADIR=/usr/local/mysql/data \ -DINSTALL_MANDIR=/usr/share/man \ -DMYSQL_TCP_PORT=3306 \ -DMYSQL_UNIX_ADDR=/tmp/mysql.sock \ -DDEFAULT_CHARSET=utf8 \ -DEXTRA_CHARSETS=all \ -DDEFAULT_COLLATION=utf8_general_ci \ -DWITH_READLINE=1 \ -DWITH_SSL=system \ -DWITH_EMBEDDED_SERVER=1 \ -DENABLED_LOCAL_INFILE=1 \ -DWITH_INNOBASE_STORAGE_ENGINE=1 提示:boost也可以使用如下指令自动下载,如果不下载bost压缩包,把下面的这一条添加到配置中第二行 -DDOWNLOAD_BOOST=1/ 参数详解: -DCMAKE_INSTALL_PREFIX=/usr/local/mysql \ 安装目录 -DSYSCONFDIR=/etc \ 配置文件存放 (默认可以不安装配置文件) -DMYSQL_DATADIR=/usr/local/mysql/data \ 数据目录 错误日志文件也会在这个目录 -DINSTALL_MANDIR=/usr/share/man \ 帮助文档 -DMYSQL_TCP_PORT=3306 \ 默认端口 -DMYSQL_UNIX_ADDR=/tmp/mysql.sock \ sock文件位置,用来做网络通信的,客户端连接服务器的时候用 -DDEFAULT_CHARSET=utf8 \ 默认字符集。字符集的支持,可以调 -DEXTRA_CHARSETS=all \ 扩展的字符集支持所有的 -DDEFAULT_COLLATION=utf8_general_ci \ 支持的 -DWITH_READLINE=1 \ 上下翻历史命令 -DWITH_SSL=system \ 使用私钥和证书登陆(公钥) 可以加密。 适用与长连接。坏处:速度慢 -DWITH_EMBEDDED_SERVER=1 \ 嵌入式数据库 -DENABLED_LOCAL_INFILE=1 \ 从本地倒入数据,不是备份和恢复。 -DWITH_INNOBASE_STORAGE_ENGINE=1 默认的存储引擎,支持外键
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
[root@mysql-server mysql-5.7.27]# make && make install
如果安装出错,想重新安装:
不用重新解压,只需要删除安装目录中的缓存文件CMakeCache.txt
- 1
- 2
- 3
**需要很长时间!**大约半小时
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mpsiCNob-1692006783546)(https://yangge666.oss-cn-nanjing.aliyuncs.com/img/image-20230807232327541.png)]
8、初始化
[root@mysql-server mysql-5.7.27]# cd /usr/local/mysql
[root@mysql-server mysql]# chown -R mysql.mysql .
[root@mysql-server mysql]# ./bin/mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data ---初始化完成之后,一定要记住提示最后的密码用于登陆或者修改密码
centos7 64最小化密码:AVyXok_uo8By
centos7 64 -001密码:*lZm3PO6)tpZ
centos7 64 -002密码:rcc-)i%(z4E4
服务器密码:p/T:YosXS2wd
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KXYa4mLx-1692006783546)(https://yangge666.oss-cn-nanjing.aliyuncs.com/img/image-20230807232417029.png)]
初始化,只需要初始化一次
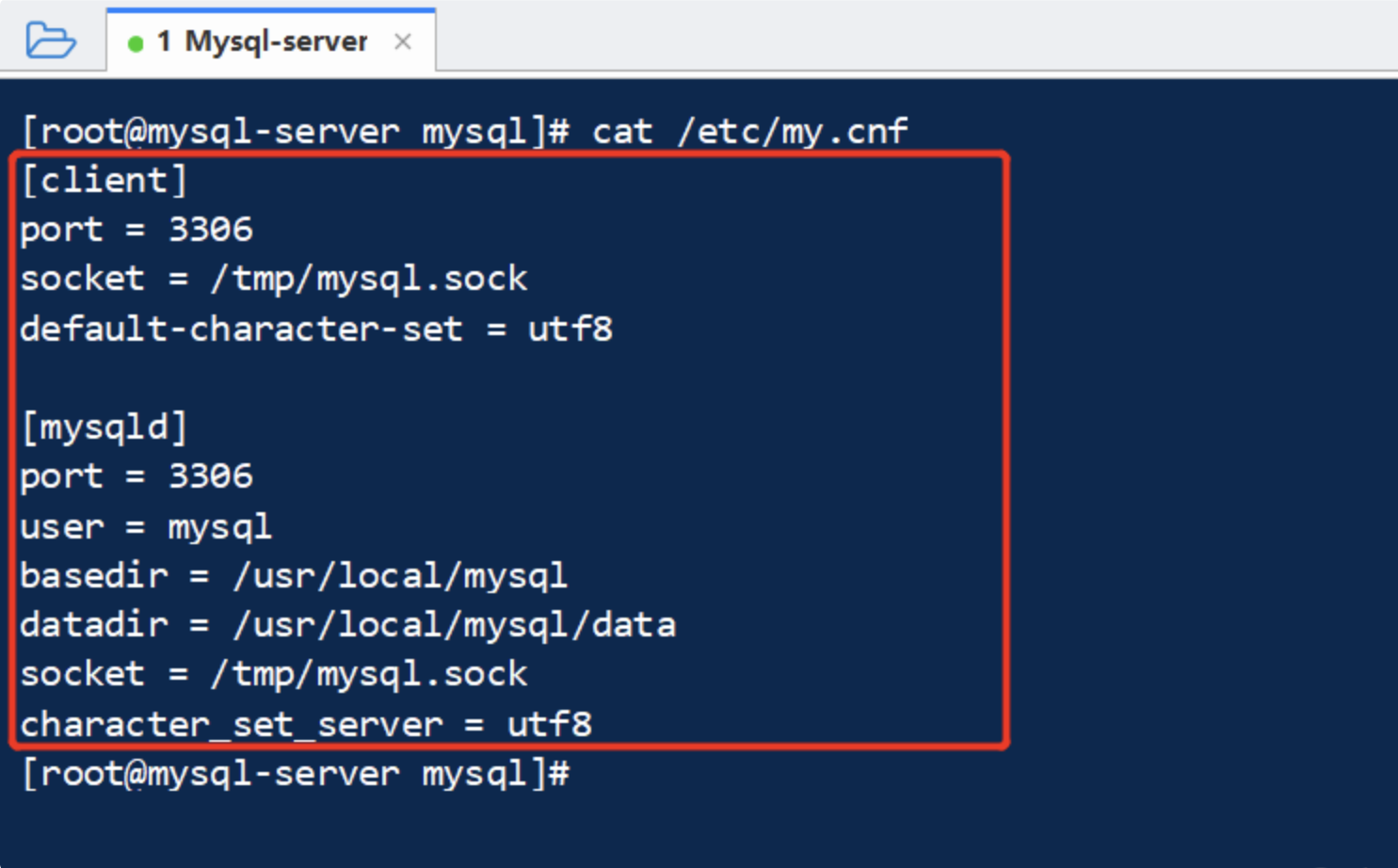
[root@mysql-server ~]# vim /etc/my.cnf ---将文件中所有内容注释掉在添加如下内容 [client] port = 3306 socket = /tmp/mysql.sock default-character-set = utf8 [mysqld] port = 3306 user = mysql basedir = /usr/local/mysql #指定安装目录 datadir = /usr/local/mysql/data #指定数据存放目录 socket = /tmp/mysql.sock character_set_server = utf8 参数详解: [client] # 默认连接端口 port = 3306 # 用于本地连接的socket套接字 socket = /tmp/mysql.sock # 编码 default-character-set = utf8 [mysqld] # 服务端口号,默认3306 port = 3306 # mysql启动用户 user = mysql # mysql安装根目录 basedir = /usr/local/mysql # mysql数据文件所在位置 datadir = /usr/local/mysql/data # 为MySQL客户端程序和服务器之间的本地通讯指定一个套接字文件 socket = /tmp/mysql.sock # 数据库默认字符集,主流字符集支持一些特殊表情符号(特殊表情符占用4个字节) character_set_server = utf8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
9、启动mysql
[root@mysql-server ~]# cd /usr/local/mysql
[root@mysql-server mysql]# ./bin/mysqld_safe --user=mysql &
- 1
- 2
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sKpvBjr4-1692006783547)(https://yangge666.oss-cn-nanjing.aliyuncs.com/img/image-20230807232509057.png)]
10、登录mysql
[root@mysql-server mysql]# /usr/local/mysql/bin/mysql -uroot -p'2720C+Xa:E+j' mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 2 Server version: 5.7.27 Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> exit centos7 64最小化密码:AVyXok_uo8By centos7 64 -001密码:*lZm3PO6)tpZ centos7 64 -002密码:rcc-)i%(z4E4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
11、修改密码
[root@mysql-server mysql]# /usr/local/mysql/bin/mysqladmin -u root -p'2720C+Xa:E+j' password 'QianFeng@123'
mysqladmin: [Warning] Using a password on the command line interface can be insecure.
Warning: Since password will be sent to server in plain text, use ssl connection to ensure password safety.
- 1
- 2
- 3
12、添加环境变量
[root@mysql-server mysql]# vim /etc/profile ---添加如下 PATH=$PATH:$HOME/bin:/usr/local/mysql/bin [root@mysql-server mysql]# source /etc/profile 之后就可以在任何地方使用mysql命令登陆Mysql服务器: [root@mysql-server mysql]# mysql --version mysql Ver 14.14 Distrib 5.7.27, for Linux (x86_64) using EditLine wrapper [root@mysql-server mysql]# mysql -uroot -p'QianFeng@123' mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 5 Server version: 5.7.27 Source distribution Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | +--------------------+ 4 rows in set (0.00 sec) mysql> exit
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
13、配置mysqld服务的管理工具:
Centos6的管理方式,Centos7暂时没有摒弃这种方式,也可以用
[root@mysql-server mysql]# cd /usr/local/mysql/support-files/
[root@mysql-server support-files]# cp mysql.server /etc/init.d/mysqld
[root@mysql-server support-files]# chkconfig --add mysqld
[root@mysql-server support-files]# chkconfig mysqld on
先将原来的进程杀掉
[root@mysql-server ~]# /etc/init.d/mysqld start
Starting MySQL. SUCCESS!
[root@mysql-server ~]# netstat -lntp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1087/sshd
tcp6 0 0 :::22 :::* LISTEN 1087/sshd
tcp6 0 0 :::3306 :::* LISTEN 31249/mysqld
[root@mysql-server ~]# /etc/init.d/mysqld stop
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
数据库编译安装完成.
2、yum安装方式
关闭防火墙和selinux
mysql的官方网站:www.mysql.com
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MWEP8ILe-1692006783547)(https://yangge666.oss-cn-nanjing.aliyuncs.com/img/image-20230807232538530.png)]
拉到底
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UsZTXicR-1692006783547)(https://yangge666.oss-cn-nanjing.aliyuncs.com/img/image-20230807232555795.png)]

下载
[root@mysql-server ~]# wget https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm
或者下载到本地上传到服务器
- 1
- 2
- 3
2.安装mysql的yum仓库
[root@mysql-server ~]# rpm -ivh mysql80-community-release-el7-3.noarch.rpm
[root@mysql-server ~]# yum -y install yum-utils #安装yum工具包
- 1
- 2
3、配置yum源
[root@mysql-server ~]# vim /etc/yum.repos.d/mysql-community.repo #修改如下
- 1
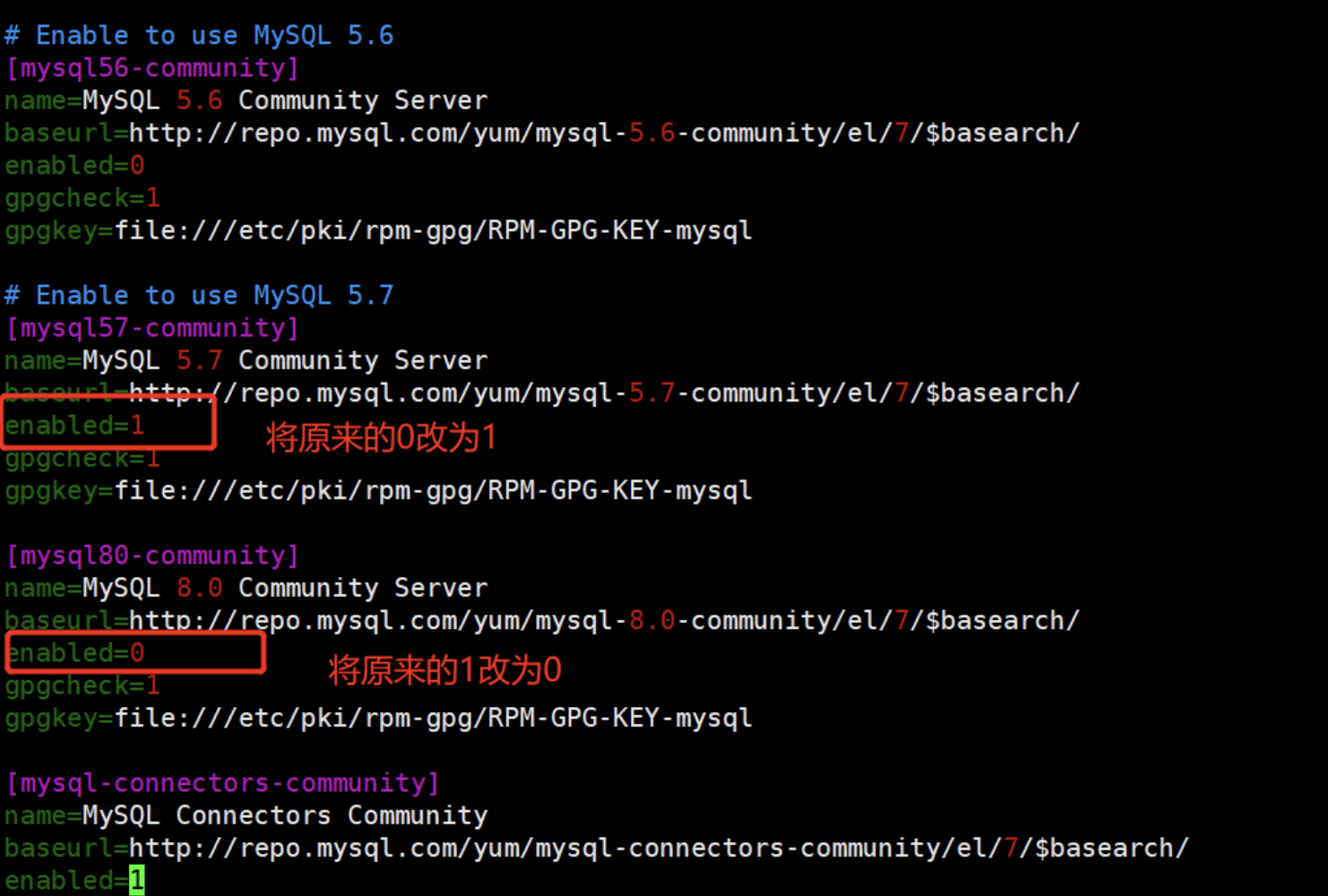
1表示开启,0表示关闭
或者
# yum-config-manager --enable mysql57-community 将禁用的yum源库启用
# yum-config-manager --disable mysql80-community 将启用的yum源库禁用
- 1
- 2
4、安装数据库
[root@mysql-server ~]# yum install -y mysql-community-server
启动服务
[root@mysql-server ~]# systemctl start mysqld
设置开机启动
[root@mysql-server ~]# systemctl enable mysqld
- 1
- 2
- 3
- 4
- 5
5、查找密码
密码保存在日志文件中
[root@mysql-server ~]# grep password /var/log/mysqld.log
2019-08-18T14:03:51.991454Z 1 [Note] A temporary password is generated for root@localhost: woHtkMgau9,w
错误案例1:
如果首次启动,在日志文件中,没有产生密码,进行以下操作:
# systemctl stop mysqld
# rm -rf /var/lib/mysql/*
# systemctl start mysqld
密码就会重新生成;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
6、修改密码
两种方式: 第一种: [root@mysql-server ~]# mysql -uroot -p'woHtkMgau9,w' #登录 mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 2 Server version: 5.7.27 .... mysql> alter user 'root'@'localhost' identified by 'QianFeng@123'; Query OK, 0 rows affected (0.01 sec) mysql> flush privileges; //刷新权限表 Query OK, 0 rows affected (0.00 sec) mysql> exit Bye [root@mysql-server ~]# mysql -uroot -p'QianFeng@123' mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 3 Server version: 5.7.27 MySQL Community Server (GPL) ... mysql> exit Bye 第二种: # mysqladmin -u root -p'旧密码' password '新密码' 注:修改密码必须大小写、数字和特殊符号都有。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
扩展
通过配置文件设置密码强度
[root@mysql-server ~]# vim /etc/my.cnf #在最后添加如下内容 validate_password=off [root@mysql-server ~]# systemctl restart mysqld #重启mysql生效 可以用第二种方式修改为简单的密码: [root@mysql-server ~]# mysqladmin -uroot -p'QianFeng@123' password 'qf123' mysqladmin: [Warning] Using a password on the command line interface can be insecure. Warning: Since password will be sent to server in plain text, use ssl connection to ensure password safety. [root@mysql-server ~]# mysql -uroot -pqf123 mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 3 Server version: 5.7.27 MySQL Community Server (GPL) Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> exit Bye
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
编译安装: # ls COPYING README bin include mysql-test support-files COPYING-test README-test docs lib share 1、bin目录 用于放置一些可执行文件,如mysql、mysqld、mysqlbinlog、mysqladmin等。 2、include目录 用于放置一些头文件,如:mysql.h、mysql_ername.h等。 3、lib目录 用于放置一系列库文件。 4、share目录 用于存放字符集、语言等信息。 yum安装: /var/lib/mysql #存放数据文件 /usr/share/mysql #用于存放字符集、语言等信息。 /usr/bin/mysql #二进制命令文件 /var/log/mysqld.log #日志路径 /etc/my.cnf #主配置文件
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
三、数据库基本操作
一、数据库存储引擎(扩展)
数据库存储引擎是数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行创建、查询、更新和删除数据。不同的存储引擎提供不同的存储机制、索引、锁表等功能,使用不同的存储引擎,还可以 获得特定的功能。现在许多不同的数据库管理系统都支持多种不同的数据引擎。MySQL的核心就是存储引擎。
MySQL引擎功能: 除了可以提供基本的读写功能,还有更多功能事务功能、锁定、备份和恢复、优化以及特殊功能。
- 1
1、InnoDB存储引擎:默认引擎,最常用的。 InnoDB是事务型数据库的首选引擎,支持事务安全表(ACID),支持行锁定;InnoDB是默认的MySQL引擎 InnoDB特点: 支持事务处理,支持崩溃修复和并发控制。如果需要对事务的完整性要求比较高(比如银行),要求实现并发控制(比如售票),那选择InnoDB有很大的优势。如果需要频繁的更新、删除操作的数据库,也可以选择InnoDB,因为支持事务的提交(commit)和回滚(rollback)。 2、MyISAM存储引擎:(了解) MyISAM基于ISAM存储引擎,并对其进行扩展。它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一。MyISAM拥有较高的插入、查询速度,但不支持事务。 MyISAM特点: 插入数据快,空间和内存使用比较低。如果表主要是用于插入新记录和读出记录,那么选择MyISAM能实现处理高效率。如果应用的完整性、并发性要求比较低,也可以使用。 12306查询 只生成一条数据这种适合。 3、MEMORY内存型引擎(了解) MEMORY存储引擎将表中的数据存储到内存中,为查询和引用其他表数据提供快速访问 MEMORY特点: 所有的数据都在内存中,数据的处理速度快,但是安全性不高。如果需要很快的读写速度,对数据的安全性要求较低,可以选择MEMOEY。它对表的大小有要求,不能建立太大的表。所以,这类数据库只使用在相对较小的数据库表。 4、Archive(归档引擎)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
**如何选择引擎:**如果要提供提交、回滚、并要求实现并发控制,InnoDB是一个好的选择;如果数据表主要用来插入和查询记录,则MyISAM引擎能提供较高的处理效率;如果只是临时存放数据,数据量不大,并且不需要较高的数据安全性,可以选择将数据保存在内存中的Memory引擎;MySQL中使用该引擎作为临时表,存放查询的中间结果;
使用哪一种引擎需要灵活选择,一个数据库中多个表可以使用不同引擎以满足各种性能和实际需求,使用合适的存储引擎,将会提高整个数据库的性能。
存储引擎查看:
mysql> show engines;
- 1
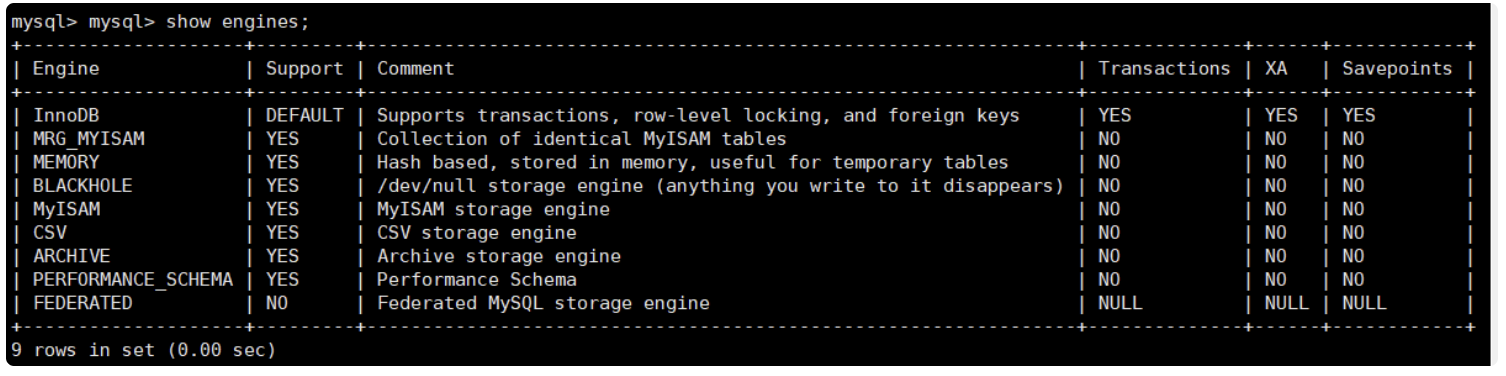
修改搜索引擎
ALTER TABLE 表名 ENGINE=引擎;
- 1
看你的mysql当前默认的存储引擎:
mysql> show variables like '%storage_engine%';
- 1
如何查看Mysql服务器上的版本
mysql> select version();
- 1
创建时候指定引擎
mysql> create table t1(id int,manager char(10)) engine =innodb;
- 1
了解:
1.什么是外键:外键的主要作用是保持数据的一致性、完整性。
2.什么是索引:索引相当于书中的目录,可以提高数据检索的效率,降低数据库的IO的压力。MySQL在300万条记录左右性能开始逐渐下降,虽然官方文档说500~800w记录,所以大数据量建立索引是非常有必要的
3.什么是行锁定与锁表:可以将一张表锁定和可以单独锁一行的记录。为了防止你在操作的同时也有别人在操作。
4.什么是事务:事务是由一步或几步数据库的操作。这系列操作要么全部执行,要么全部放弃执行。
- 1
- 2
- 3
- 4
事务控制语言(TCL)
事务控制语言 (Transaction Control Language) 有时可能需要使用 DML 进行批量数据的删除,修改,增加。比如,在一个员工系统中,想删除一个人的信息。除了删除这个人的基本信息外,还应该删除与此人有关的其他信息,如邮箱,地址等等。那么从开始执行到结束,就会构成一个事务。对于事务,要保证事务的完整性。要么成功,要么撤回。
- 1
事务要符合四个条件(ACID):
事务具有四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持续性(Durability)。这四个特性也简称ACID性。
(1)原子性:事务是应用中最小的执行单位,就如原子是自然界最小颗粒,事务要么成功,要么撤回.具有不可再分的特征一样。事务是应用中不可再分的最小执行体。(最小了,不可再分了)
(2)一致性:事务执行的结果,必须使数据库从一个一致性状态,变到另一个一致性状态比如:当数据库中只包含事务成功提交的结果时,数据库处于一致性状态。一致性是通过原子性来保证的。
(3)隔离性:当涉及到多用户操作同一张表时,数据库会为每一个用户开启一个事务。各个事务的执行互不干扰,任意一个事务的内部操作对其他并发的事务都是隔离的。也就是说:并发执行的事务之间不能看到对方的中间状态,并发执行的事务之间不相互影响。(说白了,就是你做你的,我做我的!)
(4)持续性:持续性也称为持久性指事务一旦提交对数据所做的任何改变,都要记录到永久存储器中,通常是保存进物理数据库。即使数据库崩溃了,我们也要保证事务的完整性。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uzYtATTv-1692006783549)(https://yangge666.oss-cn-nanjing.aliyuncs.com/img/image-20230807232906836.png)]
二、sql语句
增删改查
SQL(Structured Query Language 即结构化查询语言)
SQL语言主要用于存取数据、查询数据、更新数据和管理关系数据库系统,SQL语言由IBM开发。
DDL语句Database Define Language 数据库定义语言:数据库、表、视图、索引、存储过程,例如CREATE DROP ALTER
DML语句Database Manage Language 数据库操纵语言(对记录的操作): 插入数据INSERT、删除数据DELETE、更新数据UPDATE
DCL语句Database Control Language 数据库控制语言(和权限有关): 例如控制用户的访问权限GRANT、REVOKE
DQL语句Database Query Language 数据库查询语言:查询数据SELECT
- 1
- 2
- 3
- 4
- 5
- 6
程序连接数据库的文件:
A. ODBC --------- PHP<.php>
B. JDBC --------- JAVA <.jsp>
- 1
- 2
==========================================================================
库----相当于一个目录,存放数据的
库里面存放的表, 相当于是文件。
每一行叫做记录,除第一行。
每一列叫一个字段。列上面的第一个叫字段名称。
创建一个库:---->查看库--->进入这个库----->创建表----->查看表:查看表名,表的字段(表结构),表里面的内容(表记录),查看表的状态----->修改表:添加字段,删除字段,修改字段----->修改记录(更新记录),添加记录,删除记录。各种查询,删除表,删除库。
- 1
- 2
- 3
- 4
1.创建库
mysql> create database 库名;
2.查看数据库
mysql> show databases;
3.进入数据库
mysql> use 库名;
4.查看当前所在的库
mysql> select database();
5.查看当前库下所有的表格
mysql> show tables;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
创建表
语法: create table 表名( 字段名1 类型[(宽度) 约束条件], 字段名2 类型[(宽度) 约束条件], 字段名3 类型[(宽度) 约束条件] )[存储引擎 字符集]; ==在同一张表中,字段名是不能相同 ==宽度和约束条件可选 ==字段名和类型是必须的 ========================================================= 1.创建表: 创建表 create table t1(id int,name varchar(20),age int); 字段 类型 字段 类型(长度),字段 类型 mysql> create table t1(id int,name varchar(50),sex enum('m','f'),age int); 2.查看有哪些表 mysql> show tables; 3.查看表结构: mysql> desc t1; 4.查看表里面的所有记录: 语法: select 内容 from 表名; mysql> select * from t1; *:代表所有内容 5.查看表里面的指定字段: 语法:select 字段,字段 from 表名; mysql> select name,sex from t1; 6.查看表的状态 mysql> show table status like '表名'\G ---每条SQL语句会以分号结尾,想看的清楚一些以\G结尾,一条记录一条记录显示。(把表90度向左反转,第一列显示字段,第二列显示记录)使用的\G就不用添加分号了 7.修改表名称 方式一、语法:rename table 旧表名 to 新表名; mysql> rename table t1 to t2; Query OK, 0 rows affected (0.00 sec) 方式二、语法:alter table 旧表名 rename 新表名; mysql> alter table t2 rename t3; 8.使用edit(\e)编辑------了解 mysql> \e #可以写新的语句,调用的vim编辑器,在里面结尾的时候不加分号,保存退出之后在加“;” -> ; 9.删除表 mysql> drop table 表名; 10.删除库 mysql> drop database 库名;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
Day02
四、数据类型
1、数据类型
在MySQL数据库管理系统中,可以通过存储引擎来决定表的类型。同时,MySQL数据库管理系统也
提供了数据类型决定表存储数据的类型。
1.整型 作用:用于存储用户的年龄、游戏的等级、经验值等。 分类:tinyint smallint mediumint int bigint 常用的是int(6) 显示宽度:类型后面小括号内的数字是显示的最小宽度,并不能限制插入数值的长度 比如:bigint(2) 2是显示宽度 取值范围: | MySQL数据类型 | 最小值 | 最大值 | | ------------- | -------------------------- | -------------------- | | tinyint(n) | -128 | 127 | | smallint(n) | -32,768 | 32,767 | | mediumint(n) | -8388608 | 8388607 | | int(n) | -2,147,483,648 | 2,147,483,647 | | bigint(n) | -9,223,372,036,854,775,808| 9,223,372,036,854,775,807 | --------------------------------------------------------------------- 结论: - 当整数值超过 int 数据类型支持的范围时,就可以采用 bigint。 - 在 MySQL 中,int 数据类型是主要的整数数据类型。 - int(n)里的n是表示SELECT查询结果集中的显示宽度,并不影响实际的取值范围,没有影响到显示的宽度 #整型的宽度仅为显示宽度,不是限制。因此建议整型无须指定宽度。 示例: mysql> create table qf.test1(age int(10)); //在qf库下创建test1表格,设置数据类型 mysql> insert into test1(age) values(1000); Query OK, 1 row affected (0.00 sec) mysql> insert into test1(age) values(2147483647); Query OK, 1 row affected (0.00 sec) mysql> insert into test1(age) values(2147483648); //超出范围,报错 ERROR 1264 (22003): Out of range value for column 'age' at row 1 mysql> select * from test1; //查询 +------------+ | age | +------------+ | 100 | | 1000 | | 2147483647 | +------------+ 3 rows in set (0.00 sec) ===================================================== 2.浮点数类型 FLOAT DOUBLE 作用:用于存储用户的身高、体重、薪水等 float(5,2) #一共5位,整数占3位.做了限制 mysql> create table test4(float_test float(5,2)); #案例 宽度不算小数点 mysql> desc test4; +------------+------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------+------------+------+-----+---------+-------+ | float_test | float(5,2) | YES | | NULL | | +------------+------------+------+-----+---------+-------+ 1 row in set (0.00 sec) mysql> insert into test4(float_test) values(123.345534354); Query OK, 1 row affected (0.01 sec) mysql> insert into test4(float_test) values(34.39567); Query OK, 1 row affected (0.00 sec) mysql> insert into test4(float_test) values(678.99993); Query OK, 1 row affected (0.00 sec) mysql> insert into test4(float_test) values(6784.9); ERROR 1264 (22003): Out of range value for column 'float_test' at row 1 mysql> select * from test4; +------------+ | float_test | +------------+ | 123.35 | | 34.40 | | 679.00 | +------------+ 4 rows in set (0.00 sec) ==================================================================================== 定点数类型 DEC 定点数在MySQL内部以字符串形式存储,比浮点数更精确,适合用来表示货币等精度高的数据。 3.字符串类型 作用:用于存储用户的姓名、爱好、电话,邮箱地址,发布的文章等 字符类型 char varchar --存字符串 - char表示定长字符串,长度是固定的;如果插入数据的长度小于char的固定长度时,则用空格填充;因为长度固定,所以存取速度要比varchar快很多,甚至能快50%,但正因为其长度固定,所以会占据多余的空间。 - varchar表示可变长字符串,长度是可变的;插入的数据是多长,就按照多长来存储;varchar在存取方面与char相反,它存取慢,因为长度不固定,但正因如此,不占据多余的空间。 - 结合性能角度(char更快),节省磁盘空间角度(varchar更小),具体情况还需具体来设计数据库才是妥当的做法。 char(10) 根据10,占10个. 列的长度固定为创建表时声明的长度: 0 ~ 255 varchar(10) 根据实际字符串长度占空间,最多10个 列中的值为可变长字符串,长度: 0 ~ 65535 案例: mysql> create table t8(c char(5),v varchar(12)); Query OK, 0 rows affected (0.42 sec) mysql> insert into t8 values('abcde','abcdef'); Query OK, 1 row affected (0.38 sec) mysql> insert into t8 values('abc','abcdef'); #char可以少于规定长度。 Query OK, 1 row affected (0.05 sec) mysql> insert into t8 values('abc777','abcdef7'); #char不能大于规定的长度。 ERROR 1406 (22001): Data too long for column 'c' at row 1 ===================================================================== 总结: 1.经常变化的字段用varchar 2.知道固定长度的用char 3.超过255字符的只能用varchar或者text 4.能用varchar的地方不用text text:文本格式 ----------------------------------------------------------------- 4.枚举类型 enum mysql> create table t10(sex enum('m','w')); 只能从m,w两个里面2选其1 (enumeration) 有限制的时候用枚举 案例: mysql> insert into t10(sex) values('m'); Query OK, 1 row affected (0.00 sec) mysql> insert into t10 values('w'); Query OK, 1 row affected (0.00 sec) mysql> insert into t10 values('n'); ERROR 1265 (01000): Data truncated for column 'sex' at row 1 ================================================================== 5.日期类型 ===时间和日期类型测试:year、date、time、datetime、timestamp 作用:用于存储用户的注册时间,文章的发布时间,文章的更新时间,员工的入职时间等 注意事项: ==插入年份时,尽量使用4位值 ==插入两位年份时,<=69,以20开头,比如65, 结果2065 >=70,以19开头,比如82,结果1982 案例: mysql> create table test_time(d date,t time,dt datetime); Query OK, 0 rows affected (0.03 sec)+ mysql> desc test_time; +-------+----------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+----------+------+-----+---------+-------+ | d | date | YES | | NULL | | | t | time | YES | | NULL | | | dt | datetime | YES | | NULL | | +-------+----------+------+-----+---------+-------+ 3 rows in set (0.01 sec) mysql> insert into test_time values(now(),now(),now()); Query OK, 1 row affected, 1 warning (0.02 sec) mysql> select * from test_time; +------------+----------+---------------------+ | d | t | dt | +------------+----------+---------------------+ | 2022-01-04 | 17:21:16 | 2022-01-04 17:21:16 | +------------+----------+---------------------+ 1 row in set (0.00 sec) 测试年: mysql> create table t3(born_year year); Query OK, 0 rows affected (0.40 sec) mysql> desc t3; +-----------+---------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-----------+---------+------+-----+---------+-------+ | born_year | year(4) | YES | | NULL | | +-----------+---------+------+-----+---------+-------+ 1 row in set (0.00 sec) mysql> insert into t3 values (12),(80); Query OK, 2 rows affected (0.06 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> select * from t3; +-----------+ | born_year | +-----------+ | 2012 | | 1980 | +-----------+ 2 rows in set (0.00 sec) mysql> insert into t3 values (2019),(81); Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> select * from t3; +-----------+ | born_year | +-----------+ | 2012 | | 1980 | | 2019 | | 1981 | +-----------+ 4 rows in set (0.00 sec) mysql>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
五、表完整性约束
作用:用于保证数据的完整性和一致性
约束条件 说明
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录,不可以为空 UNIQUE + NOT NULL
FOREIGN KEY (FK) 标识该字段为该表的外键,实现表与表之间的关联
NULL 标识是否允许为空,默认为NULL。
NOT NULL 标识该字段不能为空,可以修改。
UNIQUE KEY (UK) 标识该字段的值是唯一的,可以为空,一个表中可以有多个UNIQUE KEY
AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键)
DEFAULT 为该字段设置默认值
UNSIGNED 无符号,正数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
1.主键
每张表里只能有一个主键,不能为空,而且唯一,主键保证记录的唯一性,主键自动为NOT NULL。
一个 UNIQUE KEY 又是一个NOT NULL的时候,那么它被当做PRIMARY KEY主键。
定义两种方式:
#表存在,添加约束
mysql> alter table t7 add primary key (hostname);
创建表并指定约束
mysql> create table t9(hostname char(20),ip char(150),primary key(hostname));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
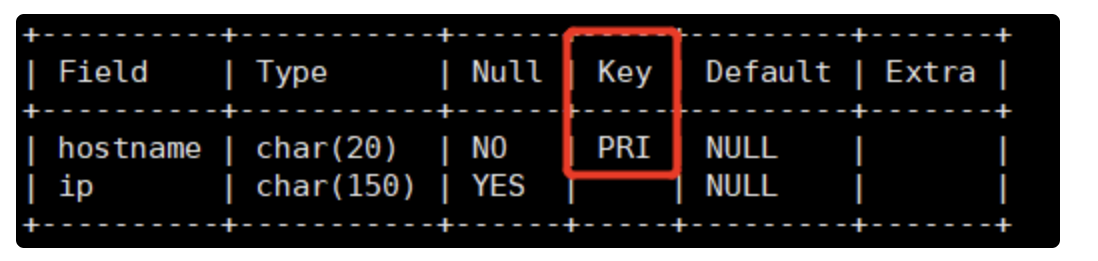
mysql> insert into t9(hostname,ip) values('qfedu.com', '10.10.10.11'); Query OK, 1 row affected (0.00 sec) mysql> insert into t9(hostname,ip) values('qfedu.com', '10.10.10.12'); ERROR 1062 (23000): Duplicate entry 'qfedu.com' for key 'PRIMARY' mysql> insert into t9(hostname,ip) values('qfedu', '10.10.10.11'); Query OK, 1 row affected (0.01 sec) mysql> select * from t9; +-----------+-------------+ | hostname | ip | +-----------+-------------+ | qfedu | 10.10.10.11 | | qfedu.com | 10.10.10.11 | +-----------+-------------+ 2 rows in set (0.00 sec) mysql> insert into t9(hostname,ip) values('qfjy', '10.10.10.12'); Query OK, 1 row affected (0.00 sec) mysql> select * from t9; +-----------+-------------+ | hostname | ip | +-----------+-------------+ | qfedu | 10.10.10.11 | | qfedu.com | 10.10.10.11 | | qfjy | 10.10.10.12 | +-----------+-------------+ 3 rows in set (0.00 sec) mysql> insert into t9(ip) values('10.10.10.13'); ERROR 1364 (HY000): Field 'hostname' doesn't have a default value 删除主键 mysql> alter table tab_name drop primary key; 主键被删除之后,这个字段仍然不允许为空值;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
2.auto_increment自增
--------自动编号,且必须与主键组合使用默认情况下,起始值为1,每次的增量为1。当插入记录时,如果为AUTO_INCREMENT数据列明确指定了一个数值,则会出现两种情况:
- 如果插入的值与已有的编号重复,则会出现出错信息,因为AUTO_INCREMENT数据列的值必须是唯一的;
- 如果插入的值大于已编号的值,则会把该插入到数据列中,并使在下一个编号将从这个新值开始递增。也就是说,可以跳过一些编号。如果自增序列的最大值被删除了,则在插入新记录时,该值不会被重用。
(每张表只能有一个字段为自增) (成了key才可以自动增长)
mysql> CREATE TABLE department3 (
dept_id INT PRIMARY KEY AUTO_INCREMENT,
dept_name VARCHAR(30),
comment VARCHAR(50)
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vVdvwdRx-1692006783550)(https://yangge666.oss-cn-nanjing.aliyuncs.com/img/image-20230807233018353.png)]
mysql> select * from department3; Empty set (0.00 sec) 插入值 mysql> insert into department3(dept_name, comment) values('tom','test'), ('jack', 'test2'); Query OK, 2 rows affected (0.00 sec) mysql> select * from department3; +---------+-----------+---------+ | dept_id | dept_name | comment | +---------+-----------+---------+ | 1 | tom | test | | 2 | jack | test2 | +---------+-----------+---------+ 2 rows in set (0.00 sec) 删除自动增长 mysql> ALTER TABLE department3 CHANGE dept_id dept_id INT NOT NULL; Query OK, 2 rows affected (0.01 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> desc department3; +-----------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-----------+-------------+------+-----+---------+-------+ | dept_id | int(11) | NO | PRI | NULL | | | dept_name | varchar(30) | YES | | NULL | | | comment | varchar(50) | YES | | NULL | | +-----------+-------------+------+-----+---------+-------+ 3 rows in set (0.00 sec) 再次插入数据,报错 mysql> insert into department3(dept_name,comment) values('tom','test1'),('jack','test2'); ERROR 1364 (HY000): Field 'dept_id' doesn't have a default value
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
3.UNIQUE KEY
字段添加唯一约束之后,该字段的值不能重复,也就是说在一列当中不能出现一样的值。
表已创建:
mysql> alter table department2 add unique key (dept_id);
表未创建:
mysql> CREATE TABLE department2 (
dept_id INT,
dept_name VARCHAR(30) UNIQUE,
comment VARCHAR(50)
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T9sTCa5Y-1692006783551)(https://yangge666.oss-cn-nanjing.aliyuncs.com/img/image-20230807233039623.png)]
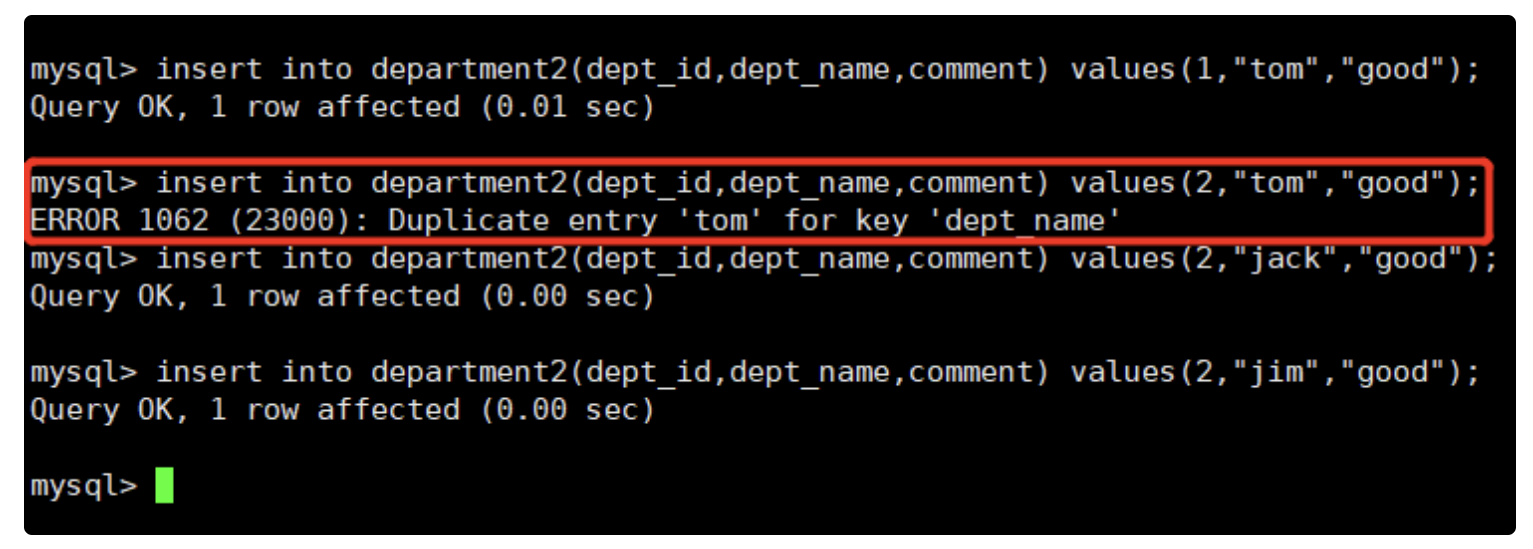

插入数据的时候id和comment字段相同可以插入数据,如果有相同的名字不唯一。所以插入数据失败。
删除unique
mysql> alter table department2 drop index dept_name;
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> desc department2;
+-----------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+-------------+------+-----+---------+-------+
| dept_id | int(11) | YES | UNI | NULL | |
| dept_name | varchar(30) | YES | | NULL | |
| comment | varchar(50) | YES | | NULL | |
+-----------+-------------+------+-----+---------+-------+
3 rows in set (0.00 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
4.null与not null
1. 是否允许为空,默认NULL,可设置NOT NULL,字段不允许为空,必须赋值
2. 字段是否有默认值,缺省的默认值是NULL,如果插入记录时不给字段赋值,此字段使用默认值
sex enum('male','female') not null default 'male' #只能选择male和female,不允许为空,默认是male
- 1
- 2
- 3
mysql> create table t4(id int(5),name varchar(10),sex enum('male','female') not null default 'male');
Query OK, 0 rows affected (0.00 sec)
mysql> insert into t4(id,name) values(1,'tom');
mysql> select * from t4;
+------+------+------+
| id | name | sex |
+------+------+------+
| 1 | tom | male |
+------+------+------+
1 row in set (0.00 sec)
删除不允许为空,和默认值
mysql> alter table t4 change sex sex enum('male','female');
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
允许为null 如果已经设置null为no:alter table user change id id int; mysql> create table t1(id int(5),name varchar(10),age int(5)); Query OK, 0 rows affected (0.00 sec) mysql> desc t1; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | int(5) | YES | | NULL | | | name | varchar(10) | YES | | NULL | | | age | int(5) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ 3 rows in set (0.01 sec) mysql> insert into t1(id,name) values(1,'tom'); Query OK, 1 row affected (0.00 sec) mysql> select * from t1; +------+------+------+ | id | name | age | +------+------+------+ | 1 | tom | NULL | +------+------+------+ 1 row in set (0.00 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
5.unsigned属性:
整数类型有可选的UNSIGNED属性,表示不允许负值,这大致上可以使正数的上限提高一倍 可以使用这几种整数类型:TINYINT,SMALLINT,MEDIUMINT,INT,BIGINT。分别使用8,16,24,32,64位存储空间 它们可以存储的值的范围从-2(n-1)到2(n-1)-1,其中n是存储空间的位数。 mysql> create table t1(id int(1) default null,qq int(5) unsigned default null); id为未指定unsigned,而qq为指定unsigned 先对id列插入数据 根据计算得2(n-1)-1为2147483647 mysql> insert into t1(id) values(2147483647); Query OK, 1 row affected (0.00 sec) 插入2147483648则提示超出范围 mysql> insert into t1(id) values(2147483648); ERROR 1264 (22003): Out of range value for column 'id' at row 1 下面对unsigned列进行插入,范围应该为 2(n-1)+2(n-1)-1为4294967295 mysql> insert into t1(qq) values(-2147483648); ERROR 1264 (22003): Out of range value for column 'qq' at row 1 mysql> insert into t1(qq) values(4294967296); ERROR 1264 (22003): Out of range value for column 'qq' at row 1 mysql> insert into t1(qq) values(4294967295); Query OK, 1 row affected (0.01 sec) MySQL可以为整数指定宽度,例如int(11),对大多数应用这是没有意义的:它不会限制值的合法范围,只是规定了MySQL的一些交互工具(例如MySQL命令行客户端)用来显示字符的个数。对于存储和计算来说,int(1)和int(20)是相同的。 create table t1(id tinyint(3) default null,qq tinyint(3) unsigned default null); id -128-->127 qq 0-->255
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
6.字符集问题:
参考链接:https://blog.csdn.net/qq_42068856/article/details/83792174 不宜深看
修改字符集 :在创建表的最后面指定一下: default charset=utf8 #可以指定中文 启动MySQL,新建查询,执行如下语句: mysql> show variables like '%char%'; 有些可能是latin1、gbk或者其他的字符集,执行如下语句将其设置为utf8 * 未指定之前,插入 mysql> insert into t1(id,name) values(1,'chenge','帅气'); ERROR 1366 (HY000): Incorrect string value: '\xE7\x9F\xB3\xE5\xAE\x87...' for column 'name' at row 1 执行如下语句将字符集设置为utf8 mysql> set global 要修改的字段=utf8 * 创建表格式指定字符集为utf-8 mysql> create table t6(id int(2),name char(5),age int(4)) default charset=utf8; mysql> desc t6; +-------+---------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+-------+ | id | int(2) | YES | | NULL | | | name | char(5) | YES | | NULL | | | age | int(4) | YES | | NULL | | +-------+---------+------+-----+---------+-------+ 3 rows in set (0.00 sec) mysql> insert into t6(id,name) values(1,'臣哥'); 修改表的字符集 mysql> alter table 表名 default character set utf8; 配置文件设置默认字符集 来到MySQL的安装目录下找到my.cnf文件 在[mysql]下方添加一句: default-character-set=utf8 在[mysqld]下方添加两句: collation-server=utf8_general_ci character-set-server=utf8 停止mysql,重新启动mysql,再次执行语句 mysql> show variables like '%char%'; 注意: 这种方式并不能修改已经创建的数据库或表的字符集,修改的是之后创建的数据库或表的默认字符集
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
7.默认约束
添加/删除默认约束 1.创建一个表 mysql> create table user(id int not null, name varchar(20), number int, primary key(id)); Query OK, 0 rows affected (0.01 sec) mysql> desc user; +--------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | varchar(20) | YES | | NULL | | | number | int(11) | YES | | NULL | | +--------+-------------+------+-----+---------+-------+ 3 rows in set (0.00 sec) 2、设置默认值 mysql> ALTER TABLE user ALTER number SET DEFAULT 0; Query OK, 0 rows affected (0.00 sec) Records: 0 Duplicates: 0 Warnings: 0 也可以这样修改: mysql> alter table user change number num int(6) not null default 3; mysql> DESCRIBE user; +--------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------+-------------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | varchar(20) | YES | | NULL | | | number | int(11) | YES | | 0 | | +--------+-------------+------+-----+---------+-------+ 3 rows in set (0.00 sec) 3、插入值 mysql> ALTER TABLE user CHANGE id id INT NOT NULL AUTO_INCREMENT; Query OK, 2 rows affected (0.01 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> INSERT INTO user(name) VALUES('rock'); Query OK, 1 row affected (0.00 sec) mysql> INSERT INTO user(name) VALUES('rock'); Query OK, 1 row affected (0.00 sec) mysql> select * from user; +----+------+--------+ | id | name | number | +----+------+--------+ | 1 | rock | 0 | | 2 | rock | 0 | +----+------+--------+ 2 rows in set (0.00 sec) 删除默认值 mysql> ALTER TABLE user ALTER number drop DEFAULT;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
作业
1.查一下oracle和mysql的区别写出几点即可。---面试
-Oracle是大型数据库,而MySQL是中小型数据库。但是MySQL是开源的,但是Oracle是收费的,而且比较贵。
-Oracle的内存占有量非常大,而mysql非常小
-MySQL支持主键自增长,指定主键为auto increment,插入时会自动增长。Oracle主键一般使用序列。
-MySQL字符串可以使用双引号包起来,而Oracle只可以单引号
-MySQL分页用limit关键字,而Oracle使用rownum字段表明位置,而且只能使用小于,不能使用大于。
-MySQL中0、1判断真假,Oracle中true false
-MySQL中命令默认commit,但是Oracle需要手动提交
-MySQL在windows环境下大小写不敏感 在unix,linux环境下区分大小写,Oracle不区分
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
8.拓展
MySQL外键约束
外键约束(FOREIGN KEY,缩写FK)是用来实现数据库表的参照完整性约束的;
外键约束可以是两张表紧密的结合起来,特别是针对修改或者删除的级联操作时,会保证数据的完整性;
(注:级联(cascade)在计算机科学里指多个对象之间的映射关系,建立数据之间的级联关系提高管理效率)
外键是指表中某个字段的值依赖于另一张表中的某个字段的值,而被依赖的字段必须
具有主键约束或者唯一约束。被依赖的表我们通常称之为父表或者主表,设置外键约束的表
称之为子表或者从表。
案例:
1、创建一个班级表, 插入数据
create table class ( cno int(4) auto_increment, cname varchar(12) not null, room varchar(4), primary key(cno) ) default charset=utf8; insert into class values (null,'java001',101); insert into class values (null,'java002',102); insert into class values (null,'java001',101); select * from class; +-----+---------+------+ | cno | cname | room | +-----+---------+------+ | 1 | java001 | 101 | | 2 | java002 | 102 | | 3 | java001 | 101 | +-----+---------+------+ 3 rows in set (0.00 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2、创建一个学生表
create table student( sno int(6) primary key auto_increment, name varchar(12), sex char(1), age int(2), classno int(4), constraint fk_stu_classno foreign key (classno) references class(cno) ) default charset=utf8; insert into student values(null,'张三','男',23,1); insert into student values(null,'李四','男',24,1); insert into student values(null,'王五','男',16,2); mysql> select * from student; +-----+--------+------+------+---------+ | sno | name | sex | age | classno | +-----+--------+------+------+---------+ | 1 | 张三 | 男 | 23 | 1 | | 2 | 李四 | 男 | 24 | 1 | | 3 | 王五 | 男 | 16 | 2 | +-----+--------+------+------+---------+ 3 rows in set (0.00 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
3、尝试class表操作,删除、更改1班。都会失败
mysql> delete from class where cno=2;
ERROR 1451 (23000): Cannot delete or update a parent row: a foreign key constraint fails (`qf1`.`student`, CONSTRAINT `fk_stu_classno` FOREIGN KEY (`classno`) REFERENCES `class` (`cno`))
mysql> update class set cno=5 where cno=2;
ERROR 1451 (23000): Cannot delete or update a parent row: a foreign key constraint fails (`qf1`.`student`, CONSTRAINT `fk_stu_classno` FOREIGN KEY (`classno`) REFERENCES `class` (`cno`))
- 1
- 2
- 3
- 4
- 5
因为存在外键,class表中cno=1中有学生存在,所以删除不了。
如果想删除1班,请手动先对1班学生进行处理(删除或者清空外键)
mysql> update student set classno=null where classno=1;
Query OK, 2 rows affected (0.00 sec)
Rows matched: 2 Changed: 2 Warnings: 0
- 1
- 2
- 3
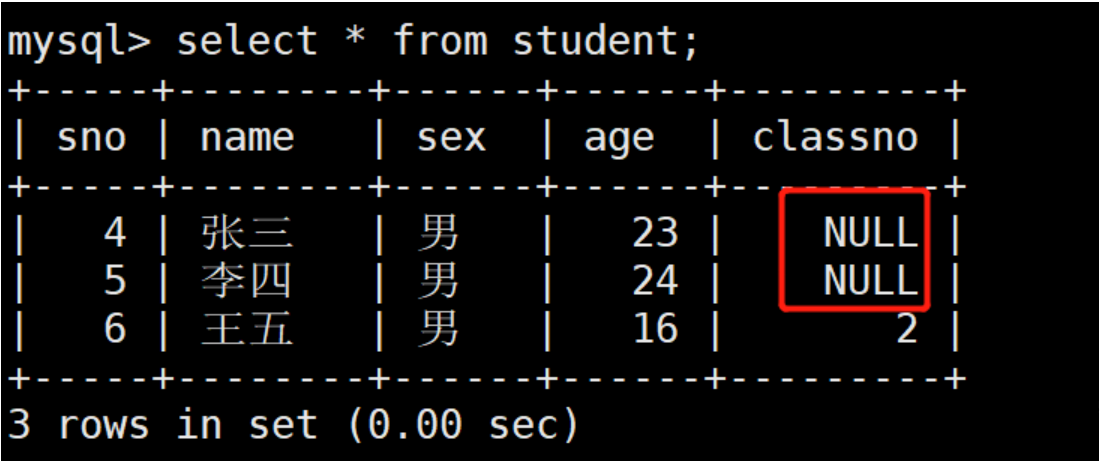
再次删除cno=1的班级
mysql> delete from class where cno=1;
Query OK, 1 row affected (0.00 sec)
- 1
- 2
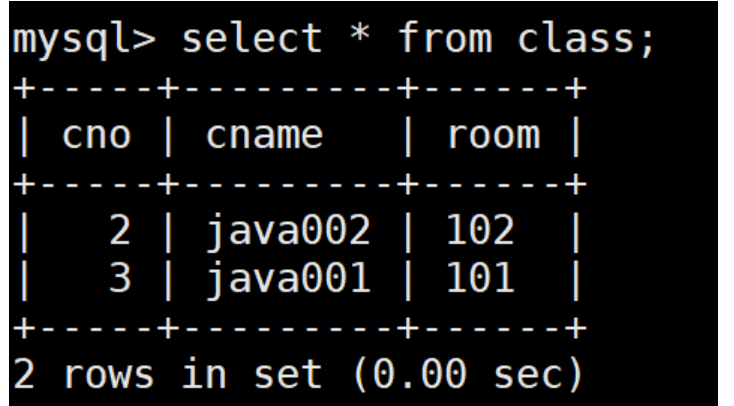 修改外键设置:外键要修改只能先删除再添加 如果希望在更新班级号的时候,可以直接更新学生的班级编号;希望在删除某个班级的时候,清空学生的班级编号
修改外键设置:外键要修改只能先删除再添加 如果希望在更新班级号的时候,可以直接更新学生的班级编号;希望在删除某个班级的时候,清空学生的班级编号
删除外键和添加外键
mysql> alter table student drop foreign key fk_stu_classno;
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
- 1
- 2
- 3
修改外键设置
mysql> alter table student add constraint fk_stu_classno foreign key(classno) references class(cno) on delete set null on update cascade;
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0
- 1
- 2
- 3
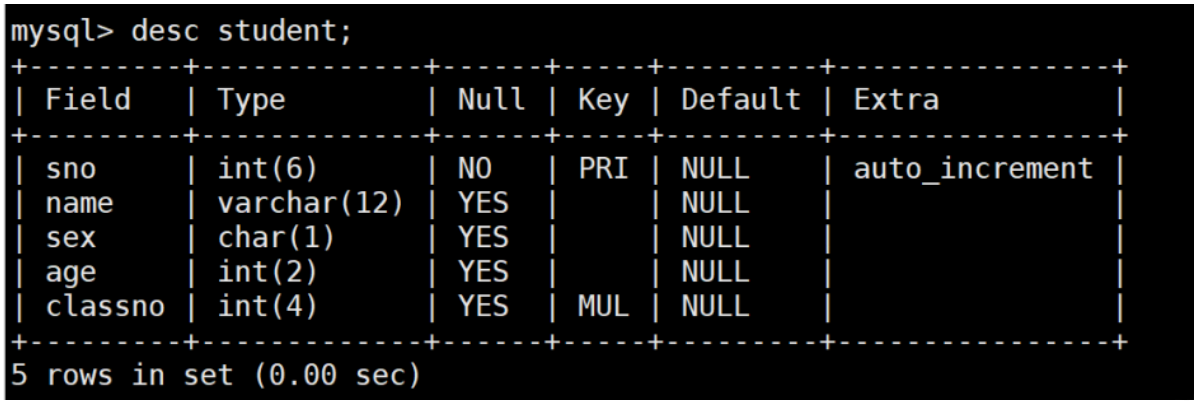
六、表操作
1.添加字段
1.添加新字段 alter table 表名 add 字段 类型; mysql> alter table t3 add math int(10);-------添加的字段 mysql> alter table t3 add (chinese int(10),english int(10));------添加多个字段,中间用逗号隔开。 ===================================================================== alter table 表名 add 添加的字段(和类型) after name; -------把添加的字段放到name后面 mysql> alter table t9 add id char(10) after home; Query OK, 0 rows affected (0.04 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc t9; +----------+---------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +----------+---------------+------+-----+---------+-------+ | name | char(10) | YES | | NULL | | | hostname | char(10) | NO | | NULL | | | ip | char(20) | YES | | NULL | | | math | int(3) | YES | | NULL | | | chinese | int(10) | YES | | NULL | | | english | int(10) | YES | | NULL | | | home | char(10) | YES | | NULL | | | id | char(10) | YES | | NULL | | | sex | enum('w','m') | YES | | NULL | | +----------+---------------+------+-----+---------+-------+ 9 rows in set (0.00 sec) ======================================================= alter table 表名 add 添加的字段(和类型) first; ----------把添加的字段放在第一个 mysql> alter table t9 add name char(10) first; Query OK, 0 rows affected (0.04 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc t9; +----------+---------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +----------+---------------+------+-----+---------+-------+ | name | char(10) | YES | | NULL | | | hostname | char(10) | NO | | NULL | | | ip | char(20) | YES | | NULL | | | math | int(3) | YES | | NULL | |
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
2.修改字段和类型
1.修改名称、数据类型、类型
alter table 表名 change 旧字段 新字段 类型; #change修改字段名称,类型,约束,顺序
mysql> alter table t3 change max maxs int(15) after id; #修改字段名称与修饰并更换了位置
2.修改字段类型,约束,顺序
alter table 表名 modify 字段 类型; #modify 不能修改字段名称
mysql> alter table t3 modify maxs int(20) after math; #修改类型并更换位置
3.删除字段
mysql> alter table t3 drop maxs; #drop 丢弃的字段。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.插入数据(添加记录)
mysql> create table t3(id int, name varchar(20), sex enum('m','f'), age int); 字符串必须引号引起来 记录与表头相对应,表头与字段用逗号隔开。 1.添加一条记录 insert into 表名(字段1,字段2,字段3,字段4) values(1,"tom","m",90); mysql> insert into t3(id,name,sex,age) values(1,"tom","m",18); 注:添加的记录与表头要对应, 2.添加多条记录 mysql> insert into t3(id,name,sex,age) values(2,"jack","m",19),(3,"xiaoli","f",20); 3.用set添加记录 mysql> insert into t3 set id=4,name="zhangsan",sex="m",age=21; 4.更新记录 update 表名 set 修改的字段 where 给谁修改; mysql> update t3 set id=6 where name="xiaoli"; 5.删除记录 1.删除单条记录 mysql> delete from t3 where id=6; #删除那个记录,等于几会删除那个整条记录 2.删除所有记录 mysql> delete from t3;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
4.单表查询
测试表:company.employee5 mysql> create database company; #创建一个库; 创建一个测试表: mysql> CREATE TABLE company.employee5( id int primary key AUTO_INCREMENT not null, name varchar(30) not null, sex enum('male','female') default 'male' not null, hire_date date not null, post varchar(50) not null, job_description varchar(100), salary double(15,2) not null, office int, dep_id int ); 插入数据: mysql> insert into company.employee5(name,sex,hire_date,post,job_description,salary,office,dep_id) values ('jack','male','20180202','instructor','teach',5000,501,100), ('tom','male','20180203','instructor','teach',5500,501,100), ('robin','male','20180202','instructor','teach',8000,501,100), ('alice','female','20180202','instructor','teach',7200,501,100), ('tianyun','male','20180202','hr','hrcc',600,502,101), ('harry','male','20180202','hr',NULL,6000,502,101), ('emma','female','20180206','sale','salecc',20000,503,102), ('christine','female','20180205','sale','salecc',2200,503,102), ('zhuzhu','male','20180205','sale',NULL,2200,503,102), ('gougou','male','20180205','sale','',2200,503,102); mysql> use company 语法: select 字段名称,字段名称2 from 表名 条件 简单查询 mysql> select * from employee5; 多字段查询: mysql> select id,name,sex from employee5; 有条件查询:where mysql> select id,name from employee5 where id<=3; mysql> select id,name,salary from employee5 where salary>2000; 设置别名:as mysql> select id,name,salary as "salry_num" from employee5 where salary>5000; 给 salary 的值起个别名,显示值的表头会是设置的别名 mysql> select id as "员工编号",name as "姓名",salary as "薪资" from employee5 where salary>=5500; +--------------+--------+----------+ | 员工编号 | 姓名 | 薪资 | +--------------+--------+----------+ | 2 | tom | 5500.00 | | 3 | robin | 8000.00 | | 4 | alice | 7200.00 | | 6 | harry | 6000.00 | | 7 | emma | 20000.00 | +--------------+--------+----------+ 5 rows in set (0.00 sec) 统计记录数量:count() mysql> select count(*) from employee5; 统计字段得到数量: mysql> select count(id) from employee5; 案例:统计薪资大于5000的,有多少人? mysql> select count(name) from employee5 where salary>5000; 避免重复DISTINCT:表里面的数据有相同的 案例:统计公司部门名称? mysql> select distinct post from employee5; #字段 表名
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
表复制:key不会被复制: 主键、外键和索引 复制表 1.复制表结构+记录 (key不会复制: 主键、外键和索引) 语法:create table 新表 select * from 旧表; mysql> create table new_t1 select * from employee5; 2.复制单个字段和记录: mysql> create table new_t2(select id,name from employee5); 3.多条件查询: and ----和/与 语法: select 字段,字段2 from 表名 where 条件1 and 条件2; mysql> SELECT name,salary from employee5 where post='hr' AND salary>1000; mysql> SELECT name,salary from employee5 where post='instructor' AND salary>1000; 4.多条件查询: or ----或者/或 语法: select 字段,字段2 from 表名 where 条件 or 条件; mysql> select name from employee5 where salary>5000 and salary<10000 or dep_id=102; mysql> select name from employee5 where salary>2000 and salary<6000 or dep_id=100; 5.关键字 BETWEEN AND 什么和什么之间。 mysql> SELECT name,salary FROM employee5 WHERE salary BETWEEN 5000 AND 15000; mysql> SELECT name,salary FROM employee5 WHERE salary NOT BETWEEN 5000 AND 15000; mysql> select name,dep_id,salary from employee5 where not salary>5000; 注:not 给条件取反 6.关键字IS NULL 空的 mysql> SELECT name,job_description FROM employee5 WHERE job_description IS NULL; mysql> SELECT name,job_description FROM employee5 WHERE job_description IS NOT NULL; #-取反 不是null mysql> SELECT name,job_description FROM employee5 WHERE job_description=''; #什么都没有==空 NULL说明: 1、等价于没有任何值、是未知数。 2、NULL与0、空字符串、空格都不同,NULL没有分配存储空间。 3、对空值做加、减、乘、除等运算操作,结果仍为空。 4、比较时使用关键字用“is null”和“is not null”。 5、排序时比其他数据都小(索引默认是降序排列,小→大),所以NULL值总是排在最前。 7.关键字IN集合查询 一般查询: mysql> SELECT name,salary FROM employee5 WHERE salary=4000 OR salary=5000 OR salary=6000 OR salary=9000; IN集合查询 mysql> SELECT name, salary FROM employee5 WHERE salary IN (4000,5000,6000,9000); mysql> SELECT name, salary FROM employee5 WHERE salary NOT IN (4000,5000,6000,9000); #取反 8.排序查询 order by :指令,在mysql是排序的意思。 mysql> select name,salary from employee5 order by salary; #-默认从小到大排序。 mysql> select name,salary from employee5 order by salary desc; #降序,从大到小 9.limit 限制 mysql> select * from employee5 limit 5; #只显示前5行 mysql> select name,salary from employee5 order by salary desc limit 0,1; #从第几行开始,打印一行 查找什么内容从那张表里面降序排序只打印第二行。 注意: 0-------默认第一行 1------第二行 依次类推... mysql> SELECT * FROM employee5 ORDER BY salary DESC LIMIT 0,5; #降序,打印5行 mysql> SELECT * FROM employee5 ORDER BY salary DESC LIMIT 4,5; #从第5条开始,共显示5条 mysql> SELECT * FROM employee5 ORDER BY salary LIMIT 4,3; #默认从第5条开始显示3条。 10.分组查询:group by mysql> select count(name),post from employee5 group by post; +-------------+------------+ | count(name) | post | +-------------+------------+ | 2 | hr | | 4 | instructor | | 4 | sale | +-------------+------------+ count可以计算字段里面有多少条记录,如果分组会分组做计算 想一想: 如何查询同一薪资水准的,都有多少人? mysql> select count(name),salary from employee5 group by salary; +-------------+----------+ | count(name) | salary | +-------------+----------+ | 1 | 600.00 | | 3 | 2200.00 | | 1 | 5000.00 | | 1 | 5500.00 | | 1 | 6000.00 | | 1 | 7200.00 | | 1 | 8000.00 | | 1 | 20000.00 | +-------------+----------+ 查询男生,女生各有多少人? mysql> select count(name),sex from employee5 group by sex; +-------------+--------+ | count(name) | sex | +-------------+--------+ | 7 | male | | 3 | female | +-------------+--------+ 2 rows in set (0.00 sec) group by案例: mysql> CREATE TABLE `employee_tbl` ( `id` int(11) NOT NULL, `name` char(10) NOT NULL DEFAULT '', `date` datetime NOT NULL, `singin` tinyint(4) NOT NULL DEFAULT '0' COMMENT '登录次数', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; mysql> INSERT INTO `employee_tbl` VALUES ('1', '小明', '2016-04-22 15:25:33', '1'), ( '2', '小王', '2016-04-20 15:25:47', '3'), ('3', '小丽', '2016-04-19 15:26:02', '2'), ('4', '小王', '2016-04-07 15:26:14', '4'), ('5', '小明', '2016-04-11 15:26:40', '4'), ('6', '小明', '2016-04-04 15:26:54', '2'); mysql> SELECT * FROM employee_tbl; +----+--------+---------------------+--------+ | id | name | date | singin | +----+--------+---------------------+--------+ | 1 | 小明 | 2016-04-22 15:25:33 | 1 | | 2 | 小王 | 2016-04-20 15:25:47 | 3 | | 3 | 小丽 | 2016-04-19 15:26:02 | 2 | | 4 | 小王 | 2016-04-07 15:26:14 | 4 | | 5 | 小明 | 2016-04-11 15:26:40 | 4 | | 6 | 小明 | 2016-04-04 15:26:54 | 2 | +----+--------+---------------------+--------+ 6 rows in set (0.00 sec) 问题1:如何使用 GROUP BY 语句 将数据表按名字进行分组,并统计每个人有多少条记录: mysql> SELECT name, COUNT(*) FROM employee_tbl GROUP BY name; +--------+----------+ | name | COUNT(*) | +--------+----------+ | 小丽 | 1 | | 小明 | 3 | | 小王 | 2 | +--------+----------+ 3 rows in set (0.01 sec) 11、WITH ROLLUP(侧重点) WITH ROLLUP 可以实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)。 例如我们将以上的数据表按名字进行分组,再统计每个人登录的次数: mysql> SELECT name, SUM(singin) as singin_count FROM employee_tbl GROUP BY name WITH ROLLUP; +--------+--------------+ | name | singin_count | +--------+--------------+ | 小丽 | 2 | | 小明 | 7 | | 小王 | 7 | | NULL | 16 | +--------+--------------+ 4 rows in set (0.00 sec) 其中记录 NULL 表示所有人的登录次数。 我们可以使用 coalesce 来设置一个可以取代 NUll 的名称,coalesce 语法: select coalesce(a,b,c); 参数说明:如果a==null,则选择b;如果b==null,则选择c;如果a!=null,则选择a;如果a b c 都为null ,则返回为null(没意义)。 以下实例中如果名字为空我们使用总数代替: mysql> SELECT coalesce(name, '总数'), SUM(singin) as singin_count FROM employee_tbl GROUP BY name WITH ROLLUP; +--------------------------+--------------+ | coalesce(name, '总数') | singin_count | +--------------------------+--------------+ | 小丽 | 2 | | 小明 | 7 | | 小王 | 7 | | 总数 | 16 | +--------------------------+--------------+ 4 rows in set (0.01 sec) 12.GROUP BY和GROUP_CONCAT()函数一起使用 GROUP_CONCAT()-------组连接 mysql> SELECT dep_id,GROUP_CONCAT(name) FROM employee5 GROUP BY dep_id; #以dep_id分的组,dep_id这个组里面都有谁 mysql> SELECT dep_id,GROUP_CONCAT(name) as emp_members FROM employee5 GROUP BY dep_id; #给组连接设置了一个别名 mysql> select count(name),group_concat(name) from employee5 where salary>5000; 查找 统计(条件:工资大于5000)的有几个人(count(name)),分别是谁(group_concat(name)) +-------------+----------------------------+ | count(name) | group_concat(name) | +-------------+----------------------------+ | 5 | tom,robin,alice,harry,emma | +-------------+----------------------------+ 想一想: 筛选出性别为男的员工数量,分别是谁? mysql> select count(name),group_concat(name) from employee5 where sex='male'; +-------------+--------------------------------------------+ | count(name) | group_concat(name) | +-------------+--------------------------------------------+ | 7 | jack,tom,robin,tianyun,harry,zhuzhu,gougou | +-------------+--------------------------------------------+ 查询薪资2200的,有多少人,分别是谁? mysql> select count(name),group_concat(name) from employee5 where salary=2200; 作业: mysql> create table student(id int primary key auto_increment, name varchar(10), class int(5), chinese intt(3), math int(3), english int(3), sport int(3) ); mysql> insert into student values(1,'tom',2202,80,90,85,70); mysql> insert into student values(2,'jack',2201,85,90,80,70); mysql> insert into student values(3,'james',2202,90,70,80,75); mysql> insert into student values(4,'alice',2201,95,75,85,75); 1.查看2202班有多少人 2.查看数学成绩90分有多少人? 3.查看数学成绩90分分别都有谁? 4.查看英语成绩大于80分的有多少人,分别都有谁? 5.查看语文总成绩有多人分? 6.查看数学总成绩有多人分? 7.查看班级2202 语文成绩大于90有多少人,都有谁 select count(name),group_concat(name) from student where chinese>90 and class=2201; 13.函数 max() 最大值 mysql> select max(salary) from employee5; 查询薪水最高的人的详细信息(子查询): mysql> select name,sex,hire_date,post,salary,dep_id from employee5 where salary = (SELECT MAX(salary) from employee5); min() 最小值 select min(salary) from employee5; avg() 平均值 select avg(salary) from employee5; now() 现在的时间 select now(); sum() 计算和 select sum(salary) from employee5 where post='sale';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
5.多表查询
概念:当在查询时,所需要的数据不在一张表中,可能在两张表或多张表中。此时需要同时操作这些表。即关联查询。 内连接/内键:在做多张表查询时,这些表中应该存在着有关联的两个字段,组合成一条记录。只连接匹配到的行 实战 准备两张表(表一) mysql> create database company; mysql> create table employee6( emp_id int auto_increment primary key not null, emp_name varchar(50), age int, dept_id int); Query OK, 0 rows affected (0.00 sec) mysql> desc employee6; +----------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +----------+-------------+------+-----+---------+----------------+ | emp_id | int(11) | NO | PRI | NULL | auto_increment | | emp_name | varchar(50) | YES | | NULL | | | age | int(11) | YES | | NULL | | | dept_id | int(11) | YES | | NULL | | +----------+-------------+------+-----+---------+----------------+ 4 rows in set (0.08 sec) 插入数据: mysql> insert into employee6(emp_name,age,dept_id) values('xiaoli',19,200),('tom',26,201),('jack',30,201),('alice',24,202),('robin',40,200),('zhangsan',28,204); Query OK, 6 rows affected (0.00 sec) Records: 6 Duplicates: 0 Warnings: 0 mysql> select * from employee6; +--------+----------+------+---------+ | emp_id | emp_name | age | dept_id | +--------+----------+------+---------+ | 1 | xiaoli | 19 | 200 | | 2 | tom | 26 | 201 | | 3 | jack | 30 | 201 | | 4 | alice | 24 | 202 | | 5 | robin | 40 | 200 | | 6 | zhangsan | 28 | 204 | +--------+----------+------+---------+ 6 rows in set (0.00 sec) (表二) mysql> create table department6(dept_id int, dept_name varchar(100)); Query OK, 0 rows affected (0.01 sec) mysql> desc department6; +-----------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-----------+--------------+------+-----+---------+-------+ | dept_id | int(11) | YES | | NULL | | | dept_name | varchar(100) | YES | | NULL | | +-----------+--------------+------+-----+---------+-------+ 2 rows in set (0.00 sec) mysql> insert into department6 values (200,'hr'), (201,'it'), (202,'sale'), (203,'op'); mysql> select * from department6; +---------+-----------+ | dept_id | dept_name | +---------+-----------+ | 200 | hr | | 201 | it | | 202 | sale | | 203 | op | +---------+-----------+ 4 rows in set (0.00 sec) 内连接(inner join)查询:只显示表中有匹配的数据 只找出有相同部门的员工 mysql> select employee6.emp_id,employee6.emp_name,employee6.age,department6.dept_name from employee6,department6 where employee6.dept_id = department6.dept_id; +--------+----------+------+-----------+ | emp_id | emp_name | age | dept_name | +--------+----------+------+-----------+ | 1 | xiaoli | 19 | hr | | 2 | tom | 26 | it | | 3 | jack | 30 | it | | 4 | alice | 24 | sale | | 5 | robin | 40 | hr | +--------+----------+------+-----------+ 5 rows in set (0.00 sec) 此条sql语句也可以这样写 mysql> select emp_id,emp_name,age,dept_name from employee6,department6 where employee6.dept_id=department6.dept_id; +--------+----------+------+-----------+ | emp_id | emp_name | age | dept_name | +--------+----------+------+-----------+ | 1 | xiaoli | 19 | hr | | 2 | tom | 26 | it | | 3 | jack | 30 | it | | 4 | alice | 24 | sale | | 5 | robin | 40 | hr | +--------+----------+------+-----------+ 5 rows in set (0.00 sec) 此条sql语句也可以这样写 —————————————————————————————————————— from 表1 inner join 表2 on 条件 —————————————————————————————————————— mysql> select employee6.emp_id,employee6.emp_name,employee6.age,department6.dept_name from employee6 inner join department6 on employee6.dept_id = department6.dept_id; +--------+----------+------+-----------+ | emp_id | emp_name | age | dept_name | +--------+----------+------+-----------+ | 1 | xiaoli | 19 | hr | | 2 | tom | 26 | it | | 3 | jack | 30 | it | | 4 | alice | 24 | sale | | 5 | robin | 40 | hr | +--------+----------+------+-----------+ 5 rows in set (0.00 sec) 此条sql语句也可以这样写 mysql> select a.emp_id,a.emp_name,a.age,b.dept_name from employee6 a inner join department6 b on a.dept_id = b.dept_id; +--------+----------+------+-----------+ | emp_id | emp_name | age | dept_name | +--------+----------+------+-----------+ | 1 | xiaoli | 19 | hr | | 2 | tom | 26 | it | | 3 | jack | 30 | it | | 4 | alice | 24 | sale | | 5 | robin | 40 | hr | +--------+----------+------+-----------+ 5 rows in set (0.00 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
外连接:在做多张表查询时,所需要的数据,除了满足关联条件的数据外,还有不满足关联条件的数据。此时需要使用外连接.外连接分为三种 左外连接:表A left [outer] join 表B on 关联条件,表A是主表,表B是从表 右外连接:表A right [outer] join 表B on 关联条件,表B是主表,表A是从表 全外连接:表A full [outer] join 表B on 关联条件,两张表的数据不管满不满足条件,都做显示。 案例:查找出所有员工及所属部门 1.左外链接 mysql> select emp_id,emp_name,dept_name from employee6 left join department6 on employee6.dept_id = department6.dept_id; +--------+----------+-----------+ | emp_id | emp_name | dept_name | +--------+----------+-----------+ | 1 | xiaoli | hr | | 5 | robin | hr | | 2 | tom | it | | 3 | jack | it | | 4 | alice | sale | | 6 | zhangsan | NULL | +--------+----------+-----------+ 6 rows in set (0.01 sec) 2.右外连接 案例:找出所有部门包含的员工 mysql> select emp_id,emp_name,dept_name from employee6 right join department6 on employee6.dept_id = department6.dept_id; +--------+----------+-----------+ | emp_id | emp_name | dept_name | +--------+----------+-----------+ | 1 | xiaoli | hr | | 2 | tom | it | | 3 | jack | it | | 4 | alice | sale | | 5 | robin | hr | | NULL | NULL | op | +--------+----------+-----------+ 6 rows in set (0.00 sec) 在左外连接和右外连接时都会以一张表为基表,该表的内容会全部显示,然后加上两张表匹配的内容。如果基表的数据在另一张表没有记录。那么在相关联的结果集行中列显示为空值(NULL)。 3.全外连接: mysql> select employee6.emp_id,employee6.emp_name,employee6.age,department6.dept_name from employee6 left join department6 on employee6.dept_id = department6.dept_id union select employee6.emp_id,employee6.emp_name,employee6.age,department6.dept_name from employee6 right join department6 on employee6.dept_id = department6.dept_id; +--------+----------+------+-----------+ | emp_id | emp_name | age | dept_name | +--------+----------+------+-----------+ | 1 | xiaoli | 19 | hr | | 5 | robin | 40 | hr | | 2 | tom | 26 | it | | 3 | jack | 30 | it | | 4 | alice | 24 | sale | | 6 | zhangsan | 28 | NULL | | NULL | NULL | NULL | op | +--------+----------+------+-----------+ 7 rows in set (0.00 sec) 也可以这样写: mysql> select emp_id,emp_name,age,dept_name from employee6 left join department6 on employee6.dept_id = department6.dept_id union select emp_id,emp_name,age,dept_name from employee6 right join department6 on employee6.dept_id = department6.dept_id;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
6.破解root密码
先将这个修改成简单密码注释掉
# vim /etc/my.cnf
- 1
root账户没了或者root密码丢失:
关闭Mysql使用下面方式进入Mysql直接修改表权限
5.6/5.7版本:
# mysqld --skip-grant-tables --user=mysql &
# mysql -uroot
mysql> UPDATE mysql.user SET authentication_string=password('QianFeng@123') WHERE user='root' AND host='localhost';
mysql> FLUSH PRIVILEGES;
#编辑配置文件将skip-grant-tables参数注释
#重启mysql
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Day03
七、MySQL 索引
索引作为一种数据结构,其用途是用于提升检索数据的效率。
- 1
1、MySQL 索引的分类
- 普通索引(INDEX):索引列值可重复
- 唯一索引(UNIQUE):索引列值必须唯一,可以为NULL
- 主键索引(PRIMARY KEY):索引列值必须唯一,不能为NULL,一个表只能有一个主键索引
- 全文索引(FULL TEXT):给每个字段创建索引
- 1
- 2
- 3
- 4
2、MySQL 不同类型索引用途和区别
- 普通索引常用于过滤数据。例如,以商品种类作为索引,检索种类为“手机”的商品。
- 唯一索引主要用于标识一列数据不允许重复的特性,相比主键索引不常用于检索的场景。
- 主键索引是行的唯一标识,因而其主要用途是检索特定数据。
- 全文索引效率低,常用于文本中内容的检索。
- 1
- 2
- 3
- 4
3、MySQL 使用索引
1、创建索引
1、普通索引(INDEX)
# 在创建表时指定 mysql> create table student1(id int not null, name varchar(100) not null, birthdy date, sex char(1) not null, index nameindex (name(50))); Query OK, 0 rows affected (0.02 sec) # 基于表结构创建 mysql> create table student2(id int not null, name varchar(100) not null, birthday date, sex char(1) not null); Query OK, 0 rows affected (0.01 sec) mysql> create index nameindex on student2(name(50)); # 修改表结构创建 mysql> create table student3(id int not null, name varchar(100) not null, birthday date, sex char(1) not null); Query OK, 0 rows affected (0.01 sec) mysql> ALTER TABLE student3 ADD INDEX nameIndex(name(50)); mysql> show index from student3; //查看某个表格中的索引
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
2、唯一索引(UNIQUE)
# 在创建表时指定
mysql> create table student4(id int not null, name varchar(100) not null, birthday date, sex char(1) not null, unique index id_idex (id));
Query OK, 0 rows affected (0.00 sec)
# 基于表结构创建
mysql> create table student5(id int not null, name varchar(100) not null, birthday date, sex char(1) not null);
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE unique INDEX idIndex ON student5(id);
# 基于表结构创建
mysql> create table student18(id int not null, name varchar(100) not null, birthday date, sex char(1) not null);
mysql> alter table student18 add unique index idIndex(id);
Query OK, 0 rows affected (0.02 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3、主键索引(PRIMARY KEY)
# 创建表时时指定
mysql> create table student6(id int not null, name varchar(100) not null, birthday date, sex char(1) not null, primary key (id));
Query OK, 0 rows affected (0.01 sec)
# 修改表结构创建
mysql> create table student7(id int not null, name varchar(100) not null, birthday date, sex char(1) not null);
Query OK, 0 rows affected (0.01 sec)
mysql> ALTER TABLE student7 ADD PRIMARY KEY (id);
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
主键索引不能使用基于表结构创建的方式创建。
2、删除索引
1、普通索引(INDEX)
# 直接删除
mysql> DROP INDEX nameIndex ON student1;
# 修改表结构删除
mysql> ALTER TABLE student2 DROP INDEX nameIndex;
- 1
- 2
- 3
- 4
- 5
2、唯一索引(UNIQUE)
# 直接删除
mysql> drop index id_idex on student4;
# 修改表结构删除
mysql> ALTER TABLE student5 DROP INDEX idIndex;
- 1
- 2
- 3
- 4
- 5
3、主键索引(PRIMARY KEY)
mysql> ALTER TABLE student7 DROP PRIMARY KEY;
- 1
主键不能采用直接删除的方式删除。
3、查看索引
mysql> SHOW INDEX FROM tab_name;
- 1
4、选择索引的原则
- 常用于查询条件的字段较适合作为索引,例如WHERE语句和JOIN语句中出现的列
- 唯一性太差的字段不适合作为索引,例如性别,年龄
- 更新过于频繁(更新频率远高于检索频率)的字段不适合作为索引
- 使用索引的好处是索引通过一定的算法建立了索引值与列值直接的联系,可以通过索引直接获取对应的行数据,而无需进行全表搜索,因而加快了检索速度
- 但由于索引也是一种数据结构,它需要占据额外的内存空间,并且读取索引也加会大IO资源的消耗,因而索引并非越多越好,且对过小的表也没有添加索引的必要
- 1
- 2
- 3
- 4
- 5
- 6
index(key)每张表可以有很多列做index,必须的起名
数据量较大的公司,300W行。100 1000 10000
面试题:
导致SQL执行慢的原因:
1.硬件问题。如网络速度慢,内存不足,I/O吞吐量小,磁盘空间满了等。
2.没有索引或者索引失效.
3.数据过多(分库分表、读写分离)
4.服务器调优及各个参数设置(调整my.cnf)
索引:当查询速度过慢可以通过建立优化查询速度,可以当作调优
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
八、权限管理
1.用户管理
1. 登录和退出MySQL
本地登录客户端命令:
# mysql -uroot -pqf123
远程登陆:
客户端语法:mysql -u 用户名 -p 密码 -h ip地址 -P端口号:如果没有改端口号就不用-P指定端口
# mysql -h192.168.246.253 -P 3306 -uroot -pqf123
- 1
- 2
- 3
- 4
- 5
- 6
- 7
如果报错进入server端服务器登陆mysql执行:
mysql> use mysql
mysql> update user set host = '%' where user = 'root';
mysql> flush privileges;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
# mysql -h192.168.246.253 -P 3306 -uroot -pqf123 -e 'show databases;'
-h 指定主机名 【默认为localhost】
-大P MySQL服务器端口 【默认3306】
-u 指定用户名 【默认root】
-p 指定登录密码 【默认为空密码】
-e 接SQL语句,可以写多条拿;隔开
# mysql -h192.168.246.253 -P 3306 -uroot -pqf123 -D mysql -e 'select * from user;'
此处 -D mysql为指定登录的数据库
修改端口rpm安装:vim /etc/my.cnf
在到【mysqld】标签下面添加port=指定端口。重启服务
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.创建用户
方法一:CREATE USER语句创建
mysql> create user tom@'localhost' identified by 'qf@123'; #创建用户为tom,并设置密码。
mysql> FLUSH PRIVILEGES; #更新授权表
注:
identified by :设置密码
在用户tom@' ' 这里 选择:
%:允许所有主机远程登陆,但不包括localhost。也可以指定某个ip,允许某个ip登陆。也可以是一个网段。
localhost:只允许本地用户登录
==客户端主机 % 所有主机远程登录
192.168.246.% 192.168.246.0网段的所有主机
192.168.246.252 指定主机
localhost 只允许本地用户登录
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
GRANT ---授权。
mysql> GRANT ALL ON *.* TO 'user3'@’localhost’;
#权限 库名.表名 账户名
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
- 1
- 2
- 3
- 4
- 5
修改远程登陆:
将原来的localhost修改为%或者ip地址
mysql> use mysql
mysql> update user set host = '192.168.246.%' where user = 'user3';
mysql> FLUSH PRIVILEGES;
- 1
- 2
- 3
- 4
- 5
3.刷新权限
修改表之后需要刷新权限
方式1:
mysql > flush privileges;
- 1
- 2
- 3
方式二:使用命令创建用户并授权:grant 也可创建新账户(不过后面的版本会移除这个功能,建议使用create user) 语法格式: grant 权限列表 on 库名.表名 to '用户名'@'客户端主机' IDENTIFIED BY 'Qf@123'; ==权限列表 all 所有权限(不包括授权权限) select,update select, insert #注意:root用授权时候grant授权权限不要给予 ==数据库.表名 *.* 所有库下的所有表 web.* web库下的所有表 web.stu_info web库下的stu_info表 #单独授权 给刚才创建的用户tom授权: mysql> grant select,insert on *.* to 'tom'@'localhost'; mysql> FLUSH PRIVILEGES;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
4.权限简介
权限简介 | 权限 | 权限级别 | 权限说明 | :--------------------- | :--------------------- | :------------------------------------ | CREATE | 数据库、表或索引 | 创建数据库、表或索引权限 | DROP | 数据库或表 | 删除数据库或表权限 | GRANT OPTION | 数据库、表或保存的程序 | 赋予权限选项 #小心给予 | ALTER | 表 | 更改表,比如添加字段、索引等 | DELETE | 表 | 删除数据权限 | INDEX | 表 | 索引权限 | INSERT | 表 | 插入权限 | SELECT | 表 | 查询权限 | UPDATE | 表 | 更新权限 | LOCK TABLES | 服务器管理 | 锁表权限 | CREATE USER | 服务器管理 | 创建用户权限 | REPLICATION SLAVE | 服务器管理 | 复制权限 | SHOW DATABASES | 服务器管理 | 查看数据库权限
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
5.查看权限
查看权限
1.看自己的权限:
mysql> SHOW GRANTS\G
*************************** 1. row ***************************
Grants for root@%: GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION
2.看别人的权限:
mysql> SHOW GRANTS FOR tom@'localhost'\G
*************************** 1. row ***************************
Grants for tom@localhost: GRANT SELECT, INSERT ON *.* TO 'tom'@'localhost'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
6.移除权限
移除用户权限
语法:REVOKE 权限 ON 数据库.数据表 FROM '用户'@'IP地址';
- 被回收的权限必须存在,否则会出错
- 整个数据库,使用 ON datebase.*;
- 特定的表:使用 ON datebase.table;
mysql> revoke select,delete on *.* from jack@'%'; #回收指定权限
mysql> revoke all privileges on *.* from jack@'%'; #回收所有权限
mysql> flush privileges;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
7.修改密码
===root修改自己密码
方法一:
语法: mysqladmin -uroot -p'123' password 'new_password' #123为旧密码
案例:
# mysqladmin -uroot -p'qf123' password 'qf@123';
方法二:
mysql>SET PASSWORD='new_password';
==root修改其他用户密码
mysql> use mysql
mysql> SET PASSWORD FOR user3@'localhost'='new_password';
用户 = 新密码
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
8.删除用户
方法一:DROP USER语句删除
DROP USER 'user3'@'localhost';
方法二:DELETE语句删除
DELETE FROM mysql.user WHERE user='tom' AND host='localhost';
更新授权表: FLUSH PRIVILEGES;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
9.查看密码复杂度
MySQL 5.7默认启用了密码复杂度设置,插件名字叫做 validate_password,初始化之后默认是安装的如果没有安装执行下面的命令会返回空或者没有值,这时需要安装该插件
安装插件
mysql> INSTALL PLUGIN validate_password SONAME 'validate_password.so';
- 1
- 2
1.查看密码复杂度 mysql> show variables like 'validate%'; +--------------------------------------+--------+ | Variable_name | Value | +--------------------------------------+--------+ | validate_password_check_user_name | OFF | | validate_password_dictionary_file | | | validate_password_length | 8 | | validate_password_mixed_case_count | 1 | | validate_password_number_count | 1 | | validate_password_policy | MEDIUM | | validate_password_special_char_count | 1 | +--------------------------------------+--------+ 参数解释: validate_password_length :#密码最少长度,默认值是8最少是0 validate_password_dictionary_file:#用于配置密码的字典文件,字典文件中存在的密码不得使用。 validate_password_policy: #代表的密码策略,默认是MEDIUM validate_password_number_count :#最少数字字符数,默认1最小是0 validate_password_mixed_case_count :#最少大写和小写字符数(同时有大写和小写),默认为1最少是0 validate_password_special_char_count :#最少特殊字符数,默认1最小是0 2.查看密码策略 mysql> select @@validate_password_policy; +----------------------------+ | @@validate_password_policy | +----------------------------+ | MEDIUM | +----------------------------+ 1 row in set (0.00 sec) 策略: - 0 or LOW 设置密码长度(由参数validate_password_length指定) - 1 or MEDIUM 满足LOW策略,同时还需满足至少有1个数字,小写字母,大写字母和特殊字符 - 2 or STRONG 满足MEDIUM策略,同时密码不能存在字典文件(dictionary file)中 3.查看密码的长度 mysql> select @@validate_password_length; +----------------------------+ | @@validate_password_length | +----------------------------+ | 8 | +----------------------------+ 1 row in set (0.00 sec) 4.设置密码复杂度 mysql> set global validate_password_length=1; #设置密码长度为1个 mysql> set global validate_password_number_count=2; #设置密码数字最少为2个 5.设置密码复杂性策略 mysql> set global validate_password_policy=LOW; 也可以是数字表示。#设置密码策略 mysql> flush privileges; #刷新授权
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
10.权限控制机制
四张表:user db tables_priv columns_priv 1.用户认证 查看mysql.user表 2.权限认证 以select权限为例: 1.先看 user表里的select_priv权限 Y:不会接着查看其他的表 拥有查看所有库所有表的权限 N:接着看db表 2.db表: #某个用户对一个数据库的权限。 Y:不会接着查看其他的表 拥有查看所有库所有表的权限 N:接着看tables_priv表 3.tables_priv表:#针对表的权限 tables_priv:如果这个字段的值里包括select 拥有查看这张表所有字段的权限,不会再接着往下看了 tables_priv:如果这个字段的值里不包括select,接着查看下张表还需要有column_priv字段权限 4.columns_priv:针对数据列的权限表 columns_priv:有select,则只对某一列有select权限 没有则对所有库所有表没有任何权限 注:其他权限设置一样。 # 授权级别排列 - mysql.user #全局授权 - mysql.db #数据库级别授权 - 其他 #表级,列级授权 案例: mysql> grant all privileges on qf.t1 to chenge@'localhost' identified by '123456'; 在user、db表中,均查询不到chenge用户有select权限。在tables_priv表中,可查询到
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
九、日志管理

1 错误日志 :启动,停止,关闭失败报错。rpm安装日志位置 /var/log/mysqld.log #默认开启
2 通用查询日志:所有的查询都记下来。 #默认关闭,一般不开启
3 二进制日志(bin log):实现备份,增量备份。只记录改变数据,除了select都记。
4 中继日志(Relay log):读取主服务器的binlog,在slave机器本地回放。保持与主服务器数据一致。
5 slow log:慢查询日志,指导调优,定义某一个查询语句,执行时间过长,通过日志提供调优建议给开发人员。
6 DDL log: 定义语句的日志。
- 1
- 2
- 3
- 4
- 5
- 6
Error Log
[root@chenge ~]# vim /etc/my.cnf
log-error=/var/log/mysqld.log
编译安装的在/usr/local/mysql/
Binary Log:前提需要开启
[root@chenge ~]# vim /etc/my.cnf
log-bin=/var/log/mysql-bin/mylog #如果不指定路径默认在/var/lib/mysql
server-id=1 #AB复制的时候使用,为了防止相互复制,会设置一个ID,来标识谁产生的日志
[root@chenge ~]# mkdir /var/log/mysql-bin
[root@chenge ~]# chown mysql.mysql /var/log/mysql-bin/
[root@chenge ~]# systemctl restart mysqld
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
查看binlog日志:开启之后等一会 [root@chenge mysql]# mysqlbinlog mylog.000001 -v # at 4 #时间的开始位置 # end_log_pos 319 #事件结束的位置(position) #190820 19:41:26 #时间点 注: 1. 重启mysqld 会截断 2. mysql> flush logs; 会截断 3. mysql> reset master; 删除所有binlog,不要轻易使用,相当于:rm -rf / 4. 删除部分 mysql> PURGE BINARY LOGS TO 'mylog.000004'; #删除mylog.000004之前的日志 5. 暂停 仅当前会话 SET SQL_LOG_BIN=0; #关闭 SET SQL_LOG_BIN=1; #开启 ===================================== 解决binlog日志不记录insert语句 登录mysql后,设置binlog的记录格式: mysql> set binlog_format=statement; 然后,最好在my.cnf中添加: binlog_format=statement 修改完配置文件之后记得重启服务 ================================================ Slow Query Log : 慢查询日志 slow_query_log=1 #开启 slow_query_log_file=/var/log/mysql-slow/slow.log long_query_time=3 #设置慢查询超时间,单位是秒 # mkdir /var/log/mysql-slow/ # chown mysql.mysql /var/log/mysql-slow/ # systemctl restart mysqld 验证查看慢查询日志 mysql> select sleep(6); # cat /var/log/mysql-slow/slow.log
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
expire_logs_days = 7 #binlog日志自动删除/过期的天数。默认值为0,表示不自动删除
- 1
扩展
UNIX Socket连接方式其实不是一个网络协议,所以只能在MySQL客户端和数据库实例在同一台服务器上的情况下使用。本地进程间通信的一种方式
通过socket方式登录
查看sock的存放路径
[root@qfedu ~]# cat /etc/my.cnf | grep sock
socket=/var/lib/mysql/mysql.sock
[root@qfedu ~]# mysql -uroot -p'QianFeng@123!' -S /var/lib/mysql/mysql.sock
- 1
- 2
- 3
- 4
- 5
Day04
十、数据备份与恢复
1、为什么要备份
- 备份:能够防止由于机械故障以及人为误操作带来的数据丢失,例如将数据库文件保存在了其它地方。
- 冗余: 数据有多份冗余,但不等备份,只能防止机械故障带来的数据丢失,例如主备模式、数据库集群。
2.MySQL数据备份需要重视的内容
备份内容 databases Binlog my.cnf
所有备份数据都应放在非数据库本地,而且建议有多份副本。
测试环境中做日常恢复演练,恢复较备份更为重要。
- 1
- 2
- 3
备份过程中必须考虑因素:
1. 数据的一致性
2. 服务的可用性
Mysql A (读写) 压力比较大
|
Mysql B (读) 压力比较小 从节点做备份
- 1
- 2
- 3
- 4
- 5
- 6
3、MySQL 备份类型
1.物理备份: 直接复制数据库文件,适用于大型数据库环境,不受存储引擎的限制,但不能恢复到不同的MySQL版本。 ####1、热备(hot backup) 在线备份,数据库处于运行状态,这种备份方法依赖于数据库的日志文件 - 对Mysql应用基本无影响(但是性能还是会有下降,所以尽量不要在主库上做备份,在从库上做) ####2、冷备(cold backup) 备份数据文件,需要停机,是在关闭数据库的时候进行的 - 备份 datadir 目录下的所有文件 ####3、温备(warm backup) - 针对myisam的备份(myisam不支持热备),备份时候实例只读不可写,数据库锁定表格(不可写入但可读)的状态下进行的 - 对应用影响很大 - 通常加一个读锁 2.逻辑备份: 备份的是建表、建库、插入等操作所执行SQL语句(DDL DML DCL),适用于中小型数据库,效率相对较低。 creat table t1 3.物理和逻辑备份的区别 | | 逻辑备份 | 物理备份 | ---------- | ------------------------------ | ---------------------- | 备份方式 | 备份数据库建表、建库、插入sql语句 | 备份数据库物理文件 | 优点 | 备份文件相对较小,只备份表中的数据与结构 | 恢复速度比较快 | 缺点 | 恢复速度较慢(需要重建索引,存储过程等) | 备份文件相对较大(备份表空间,包含数据与索引) | 对业务影响 | I/O负载加大 | I/O负载加大 | 代表工具 | mysqldump | ibbackup、xtrabackup开源,mysqlbackup
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
5、MySQL 备份工具
1、ibbackup - 官方备份工具 - 收费 - 物理备份 2、xtrabackup - 开源社区备份工具 - 开源免费,上面的免费版本(老版本有问题,备份出来的数据可能有问题) - 物理备份 3、mysqldump - 官方自带备份工具 开源免费 - 逻辑备份(速度慢) 4、mysqlbackup - mysql 官方备份工具 - innodb 引擎的表mysqlbackup可以进行热备 - 非innodb表mysqlbackup就只能温备 - 物理备份,备份还原速度快 - 适合大规模数据使用
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2.物理备份的方式
1.完全备份-----完整备份:
每次对数据进行完整的备份,即对整个数据库的备份、数据库结构和文件结构的备份,保存的是备份完成时刻的数据库,是差异备份与增量备份的基础。
优点:备份与恢复操作简单方便,恢复时一次恢复到位,恢复速度快
缺点:占用空间大,备份速度慢
- 1
- 2
- 3
- 4
2.增量备份: 每次备份上一次备份到现在产生的新数据
只有那些在上次完全备份或者增量备份后被修改的文件才会被备份。以上次完整备份或上次的增量备份的时间为时间点,仅备份这之间的数据变化.
特点:因而备份的数据量小,占用空间小,备份速度快。但恢复时,需要从上一次的完整备份起按备份时间顺序,逐个备份版本进行恢复,恢复时间长,如中间某次的备份数据损坏,将导致数据的丢失。
- 1
- 2
- 3
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T2tZJp10-1692006783554)(https://yangge666.oss-cn-nanjing.aliyuncs.com/img/image-20230807233706850.png)]
3.差异备份:只备份跟完整备份不一样的
备份那些自从第一次次完全备份之后被修改过的所有文件,备份的时间起点是从第一次的完整备份起,且以后每次备份都是和第一次完整备份进行比较(注意是第一次,不是上一次),备份自第一次完整备份以来所有的修改过的文件。备份数据量会越来越大。
特点:占用空间比增量备份大,比完整备份小,恢复时仅需要恢复第一个完整版本和最后一次的差异版本,恢复速度介于完整备份和增量备份之间。
- 1
- 2
- 3
简单的讲,完整备份就是不管三七二十一,每次都把指定的备份目录完整的复制一遍,不管目录下的文件有没有变化;增量备份就是每次将之前(第一次、第二次、直到前一次)做过备份之后有变化的文件进行备份;差异备份就是每次都将第一次完整备份以来有变化的文件进行备份。
- 1
3、percona-xtrabackup 物理备份
Xtrabackup是开源免费的支持MySQL 数据库热备份的软件,在 Xtrabackup 包中主要有 Xtrabackup 和 innobackupex 两个工具。其中 Xtrabackup 只能备份 InnoDB 和 XtraDB 两种引擎; innobackupex则是封装了Xtrabackup,同时增加了备份MyISAM引擎的功能。它不暂停服务创建Innodb热备份;
1、安装xtrabackup
安装xtrabackup
# wget http://www.percona.com/downloads/percona-release/redhat/0.1-4/percona-release-0.1-4.noarch.rpm
# rpm -ivh percona-release-0.1-4.noarch.rpm
[root@mysql-server yum.repos.d]# vim percona-release.repo
- 1
- 2
- 3
- 4
修改如下内容:将原来的1改为0
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-32Jvo3oG-1692006783555)(https://yangge666.oss-cn-nanjing.aliyuncs.com/img/image-20230807233822408.png)]
[root@mysql-server yum.repos.d]# yum -y install percona-xtrabackup-24.x86_64 #一定要下载这个版本,其他版本不一定能对mysql5.7做备份,不兼容;
- 1
注意
如果安装不上报错:
Transaction check error:
file /etc/my.cnf from install of Percona-Server-shared-56-5.6.46-rel86.2.1.el7.x86_64 conflicts with file from package mysql-community-server-5.7.28-1.el7.x86_64
Error Summary #说是冲突
解决方式如下:
1.先安装yum install mysql-community-libs-compat -y #安装包
2.在安装yum -y install percona-xtrabackup-24.x86_64
参考:https://www.cnblogs.com/EikiXu/p/10217931.html
方式二:
1.先安装percona-xtrabackup
2.在安装mysql
或者先将mysql源back了,重新建立yum缓存。在安装percona-xtrabackup。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
以上安装方式如果失效,请用以下提供的方式:
======第一种======== [root@mysql-server ~]# vim /etc/yum.repos.d/Percona.repo [percona] name = CentOS $releasever - Percona baseurl=http://repo.percona.com/centos/$releasever/os/$basearch/ enabled = 1 gpgkey = file:///etc/pki/rpm-gpg/RPM-GPG-KEY-percona gpgcheck = 1 [root@mysql-server yum.repos.d]# vim /etc/pki/rpm-gpg/RPM-GPG-KEY-percona -----BEGIN PGP PUBLIC KEY BLOCK----- Version: GnuPG v1.4.9 (GNU/Linux) mQGiBEsm3aERBACyB1E9ixebIMRGtmD45c6c/wi2IVIa6O3G1f6cyHH4ump6ejOi AX63hhEs4MUCGO7KnON1hpjuNN7MQZtGTJC0iX97X2Mk+IwB1KmBYN9sS/OqhA5C itj2RAkug4PFHR9dy21v0flj66KjBS3GpuOadpcrZ/k0g7Zi6t7kDWV0hwCgxCa2 f/ESC2MN3q3j9hfMTBhhDCsD/3+iOxtDAUlPMIH50MdK5yqagdj8V/sxaHJ5u/zw YQunRlhB9f9QUFfhfnjRn8wjeYasMARDctCde5nbx3Pc+nRIXoB4D1Z1ZxRzR/lb 7S4i8KRr9xhommFnDv/egkx+7X1aFp1f2wN2DQ4ecGF4EAAVHwFz8H4eQgsbLsa6 7DV3BACj1cBwCf8tckWsvFtQfCP4CiBB50Ku49MU2Nfwq7durfIiePF4IIYRDZgg kHKSfP3oUZBGJx00BujtTobERraaV7lIRIwETZao76MqGt9K1uIqw4NT/jAbi9ce rFaOmAkaujbcB11HYIyjtkAGq9mXxaVqCC3RPWGr+fqAx/akBLQ2UGVyY29uYSBN eVNRTCBEZXZlbG9wbWVudCBUZWFtIDxteXNxbC1kZXZAcGVyY29uYS5jb20+iGAE ExECACAFAksm3aECGwMGCwkIBwMCBBUCCAMEFgIDAQIeAQIXgAAKCRAcTL3NzS79 Kpk/AKCQKSEgwX9r8jR+6tAnCVpzyUFOQwCfX+fw3OAoYeFZB3eu2oT8OBTiVYu5 Ag0ESybdoRAIAKKUV8rbqlB8qwZdWlmrwQqg3o7OpoAJ53/QOIySDmqy5TmNEPLm lHkwGqEqfbFYoTbOCEEJi2yFLg9UJCSBM/sfPaqb2jGP7fc0nZBgUBnFuA9USX72 O0PzVAF7rCnWaIz76iY+AMI6xKeRy91TxYo/yenF1nRSJ+rExwlPcHgI685GNuFG chAExMTgbnoPx1ka1Vqbe6iza+FnJq3f4p9luGbZdSParGdlKhGqvVUJ3FLeLTqt caOn5cN2ZsdakE07GzdSktVtdYPT5BNMKgOAxhXKy11IPLj2Z5C33iVYSXjpTelJ b2qHvcg9XDMhmYJyE3O4AWFh2no3Jf4ypIcABA0IAJO8ms9ov6bFqFTqA0UW2gWQ cKFN4Q6NPV6IW0rV61ONLUc0VFXvYDtwsRbUmUYkB/L/R9fHj4lRUDbGEQrLCoE+ /HyYvr2rxP94PT6Bkjk/aiCCPAKZRj5CFUKRpShfDIiow9qxtqv7yVd514Qqmjb4 eEihtcjltGAoS54+6C3lbjrHUQhLwPGqlAh8uZKzfSZq0C06kTxiEqsG6VDDYWy6 L7qaMwOqWdQtdekKiCk8w/FoovsMYED2qlWEt0i52G+0CjoRFx2zNsN3v4dWiIhk ZSL00Mx+g3NA7pQ1Yo5Vhok034mP8L2fBLhhWaK3LG63jYvd0HLkUFhNG+xjkpeI SQQYEQIACQUCSybdoQIbDAAKCRAcTL3NzS79KlacAJ0aAkBQapIaHNvmAhtVjLPN wke4ZgCePe3sPPF49lBal7QaYPdjqapa1SQ= =qcCk -----END PGP PUBLIC KEY BLOCK----- [root@mysql-server yum.repos.d]# yum -y install percona-xtrabackup-24.x86_64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
[root@mysql-server ~]# innobackupex -v
xtrabackup: recognized server arguments: --datadir=/var/lib/mysql
innobackupex version 2.4.23 Linux (x86_64) (revision id: 3320f39)
- 1
- 2
- 3
======第二种========
百度搜吧
访问以下链接:
https://zhuanlan.zhihu.com/p/140414143
- 1
- 2
- 3
- 4
- 5
下载完成,把包上传至服务器

[root@mysq-master2 ~]# wget https://repo.percona.com/yum/percona-release-latest.noarch.rpm [root@mysql-server ~]# rpm -ivh percona-release-latest.noarch.rpm [root@mysql-server ~]# yum -y install percona-xtrabackup-24.x86_64 #一定要下载这个版本(编译安装的Mysql基本这一步就ok了) 可能会出现报错: Transaction check error: file /etc/my.cnf from install of Percona-Server-shared-56-5.6.51-rel91.0.1.el7.x86_64 conflicts with file from package mysql-community-server-5.7.40-1.el7.x86_64 错误概要 ------------- 解决这个问题,需要安装mysql相关的libs-compat软件。 [root@mysql-server ~]# yum list | grep mysql | grep libs-compat [root@mysql-server ~]# yum -y install mysql-community-libs-compat.x86_64 #下载x86的版本 [root@mysql-server ~]# yum -y install percona-xtrabackup-24.x86_64 #下载我们需要的xtrabackup [root@mysql-server ~]# innobackupex -v xtrabackup: recognized server arguments: --datadir=/var/lib/mysql innobackupex version 2.4.23 Linux (x86_64) (revision id: 3320f39)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
2.完全备份流程:
创建备份目录:
[root@mysql-server ~]# mkdir /xtrabackup/full -p
备份之前,进入数据库,存入些数据
[root@mysql-server ~]# mysql -uroot -p'qf123'
mysql> create database chenge;
mysql> use chenge;
Database changed
mysql> create table t1(id int);
备份:
[root@mysql-server ~]# innobackupex --user=root --password='qf123' /xtrabackup/full
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
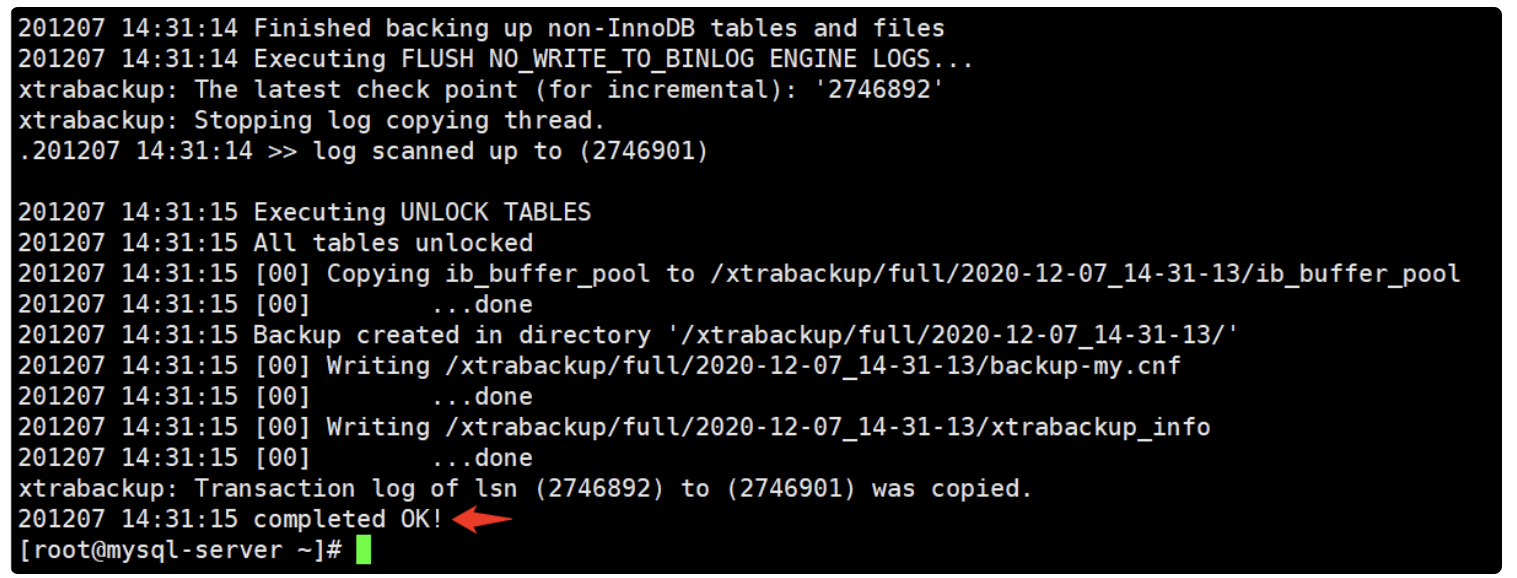
可以查看一下: [root@mysql-server ~]# cd /xtrabackup/full/ [root@mysql-server full]# ls 2021-12-07_14-31-13 ==================================================================================== 完全备份恢复流程 1. 停止数据库 2. 清理环境 3. 重演回滚--> 恢复数据 4. 修改权限 5. 启动数据库 1.关闭数据库: [root@mysql-server ~]# systemctl stop mysqld [root@mysql-server ~]# rm -rf /var/lib/mysql/* //删除所有数据 [root@mysql-server ~]# rm -rf /var/log/mysqld.log [root@mysql-server ~]# rm -rf /var/log/mysql-slow/slow.log 2.重演恢复: [root@mysql-server ~]# innobackupex --apply-log /xtrabackup/full/2021-12-07_14-31-13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
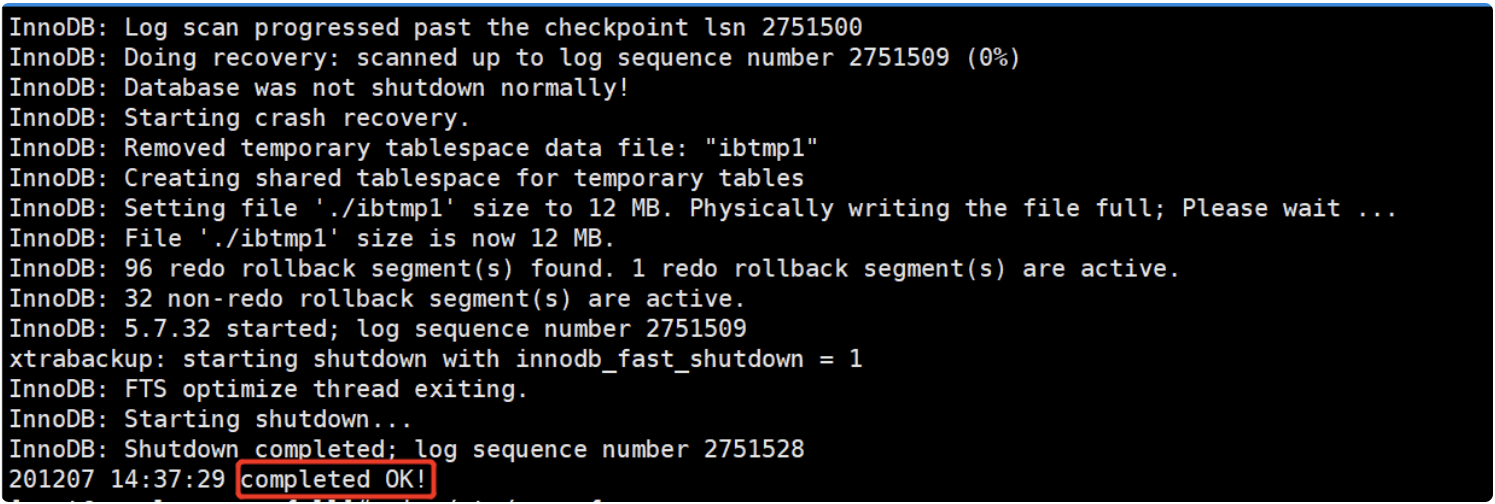
3.确认数据库目录:
恢复之前需要确认配置文件内有数据库目录指定,不然xtrabackup不知道恢复到哪里
# cat /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
4.恢复数据:
[root@mysql-server ~]# innobackupex --copy-back /xtrabackup/full/2021-12-07_14-31-13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
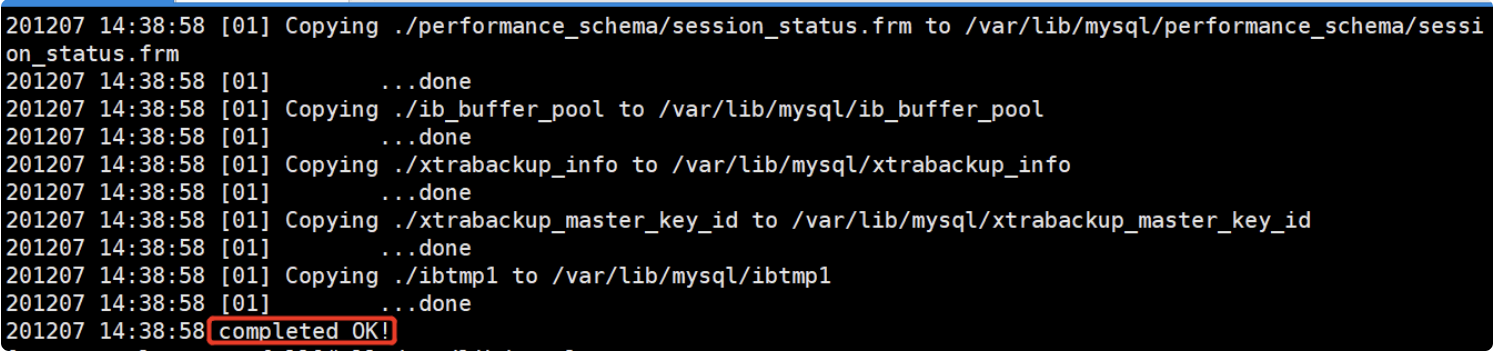
5.修改权限: [root@mysql-server ~]# chown mysql.mysql /var/lib/mysql -R 启动数据库: [root@mysql-server ~]# systemctl start mysqld 6.确认数据是否恢复 mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | chenge | | mysql | | performance_schema | | sys | +--------------------+ 5 rows in set (0.00 sec) mysql> use chenge; Database changed mysql> show tables; +--------------------+ | Tables_in_chenge | +--------------------+ | t1 | +--------------------+ 1 row in set (0.00 sec) ===可以看到数据已恢复===
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
3.增量备份流程
原理:每次备份上一次备份到现在产生的新数据
1.在数据库上面创建一个测试的库
- 1
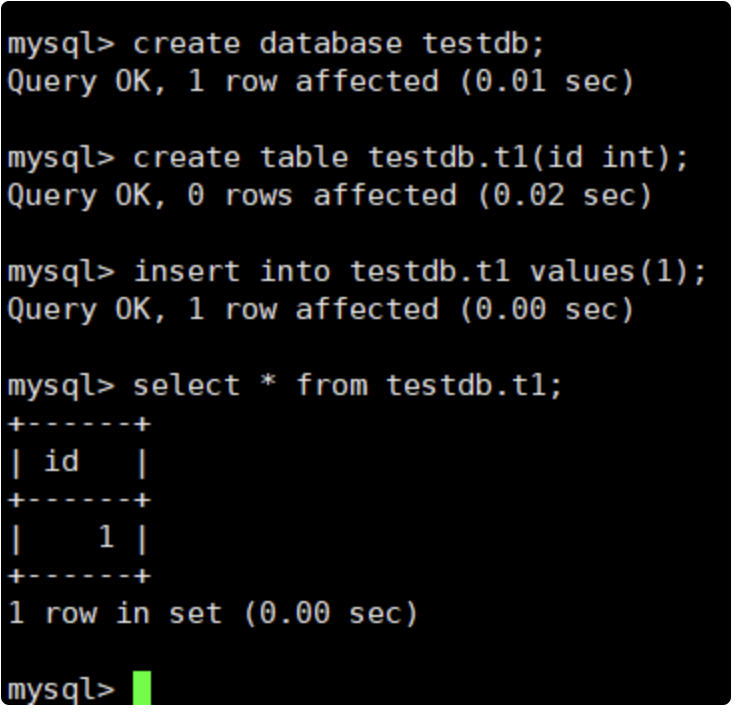
1.完整备份:周一
[root@mysql-server ~]# rm -rf /xtrabackup/*
[root@mysql-server ~]# innobackupex --user=root --password='qf123' /xtrabackup
[root@mysql-server ~]# cd /xtrabackup/
[root@mysql-server xtrabackup]# ls
2022-01-10_14-10-40
[root@mysql-server xtrabackup]# cd 2022-01-10_14-10-40/
[root@mysql-server 2022-01-10_14-10-40]# ls
backup-my.cnf ib_buffer_pool mysql sys testdb xtrabackup_info
company ibdata1 performance_schema test xtrabackup_checkpoints xtrabackup_logfile
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2、增量备份:周二 —— 周三
在数据库中插入周二的数据:
mysql> insert into testdb.t1 values(2); #模拟周二
[root@mysql-server ~]# innobackupex --user=root --password='qf123' --incremental /xtrabackup/ --incremental-basedir=/xtrabackup/2022-01-10_14-10-40/
--incremental-basedir:基于哪个增量
[root@mysql-server ~]# cd /xtrabackup/
[root@mysql-server xtrabackup]# ls
2022-01-10_14-10-40 2022-01-10_14-16-16 ---相当于周二的增量备份
- 1
- 2
- 3
- 4
- 5
- 6
- 7
在数据库中插入周三的数据:
mysql> insert into testdb.t1 values(3); #模拟周三
[root@mysql-server ~]# innobackupex --user=root --password='qf123' --incremental /xtrabackup/ --incremental-basedir=/xtrabackup/2022-01-10_14-16-16/ #基于前一天的备份为目录
[root@mysql-server ~]# cd /xtrabackup/
[root@mysql-server xtrabackup]# ls
2022-01-10_14-10-40 2022-01-10_14-16-16 2022-01-10_14-19-59 ---相当于周三的增量备份
- 1
- 2
- 3
- 4
- 5
- 6
查看一下备份目录:
[root@mysql-server ~]# ls /xtrabackup/
2022-01-10_14-10-40 2022-01-10_14-16-16 2022-01-10_14-19-59
全备周一 增量周二 增量周三
- 1
- 2
- 3
- 4
增量备份恢复流程
1. 停止数据库
2. 清理环境
3. 依次重演回滚redo log--> 恢复数据
4. 修改权限
5. 启动数据库
- 1
- 2
- 3
- 4
- 5
- 6
[root@mysql-server ~]# systemctl stop mysqld
[root@mysql-server ~]# rm -rf /var/lib/mysql/*
依次重演回滚redo log:
[root@mysql-server ~]# innobackupex --apply-log --redo-only /xtrabackup/2022-01-10_14-10-40
周二 --- 周三
[root@mysql-server ~]# innobackupex --apply-log --redo-only /xtrabackup/2019-08-20_14-51-35 --incremental-dir=/xtrabackup/2022-01-10_14-16-16
--incremental-dir:增量目录
[root@mysql-server ~]# innobackupex --apply-log --redo-only /xtrabackup/2019-08-20_14-51-35 --incremental-dir=/xtrabackup/2022-01-10_14-19-59/
恢复数据:
[root@mysql-server ~]# innobackupex --copy-back /xtrabackup/2022-01-10_14-10-40/
修改权限
[root@mysql-server ~]# chown -R mysql.mysql /var/lib/mysql
[root@mysql-server ~]# systemctl start mysqld
登陆上去看一下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
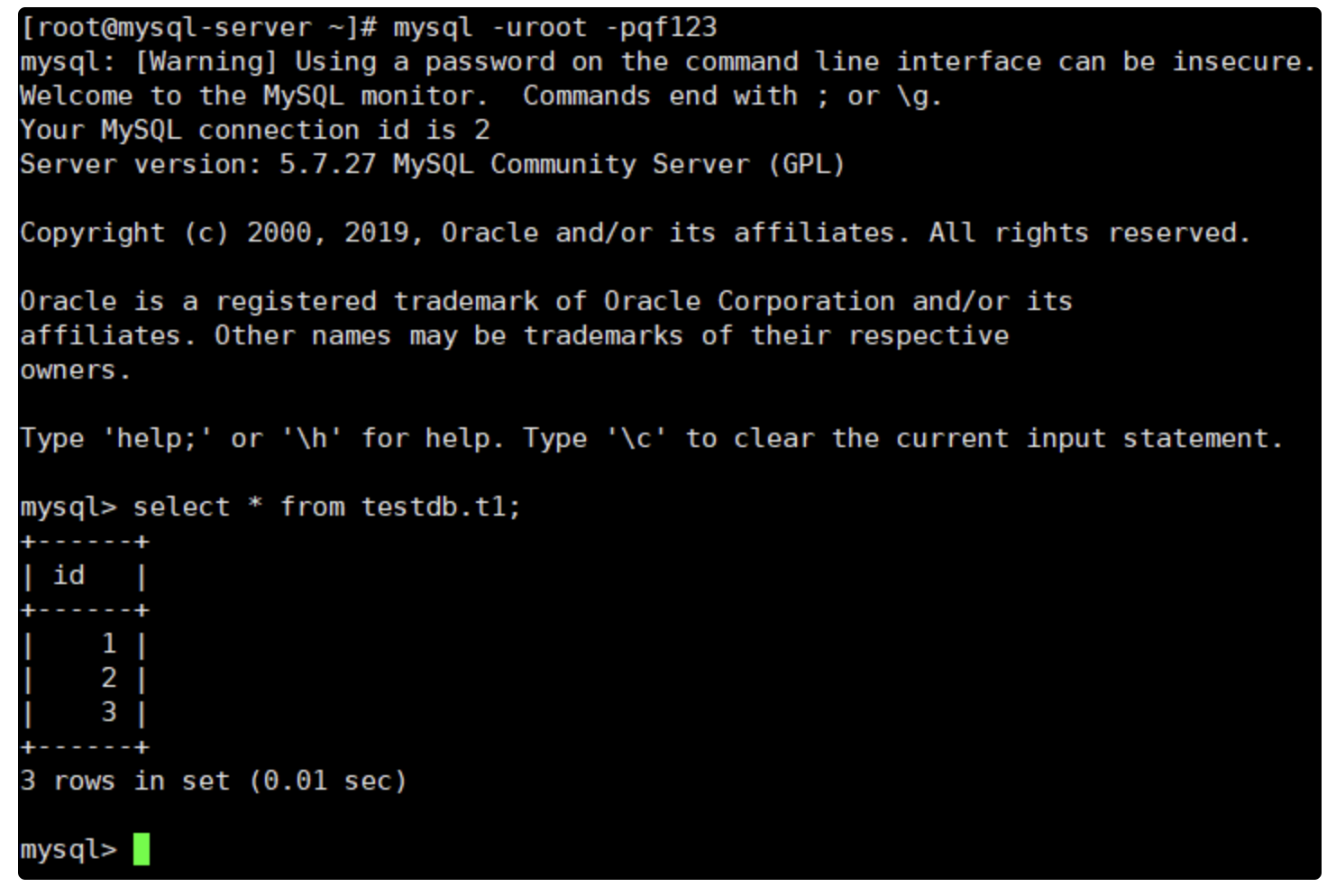
4.差异备份流程
清理备份的环境:
[root@mysql-server ~]# rm -rf /xtrabackup/* 登陆数据库,准备环境 mysql> delete from testdb.t1; mysql> insert into testdb.t1 values(1); #插入数据1,模拟周一 mysql> select * from testdb.t1; +------+ | id | +------+ | 1 | +------+ mysql> \q 查看时间: [root@mysql-server ~]# date Tue Aug 20 15:39:59 CST 2019 1、完整备份:周一 [root@mysql-server ~]# innobackupex --user=root --password='qf123' /xtrabackup 2、差异备份:周二 —— 周三 语法: # innobackupex --user=root --password=888 --incremental /xtrabackup --incremental-basedir=/xtrabackup/完全备份目录(周一) 3.修改时间: [root@mysql-server ~]# date 08211543 Wed Aug 21 15:43:00 CST 2019 4.在登陆mysql: mysql> insert into testdb.t1 values(2); #插入数据2,模拟周二 差异备份周二的 [root@mysql-server ~]# innobackupex --user=root --password='qf123' --incremental /xtrabackup --incremental-basedir=/xtrabackup/2022-01-10_14-34-07/ #备份目录基于周一的备份 5.再次登陆mysql mysql> insert into testdb.t1 values(3); #插入数据,模拟周三 6.在次修改时间 [root@mysql-server ~]# date 08221550 Thu Aug 22 15:50:00 CST 2019 7.在次差异备份 [root@mysql-server ~]# innobackupex --user=root --password='qf123' --incremental /xtrabackup --incremental-basedir=/xtrabackup/2022-01-10_14-34-07/ #还是基于周一的备份 8.延申到周四 mysql> insert into testdb.t1 values(4); 9.修改时间 [root@mysql-server ~]# date 08231553 Fri Aug 23 15:53:00 CST 2019 10.差异备份周四 [root@mysql-server ~]# innobackupex --user=root --password='qf123' --incremental /xtrabackup --incremental-basedir=/xtrabackup/2022-01-10_14-34-07/ #还是基于周一的备份 11.查看一下备份目录 [root@mysql-server ~]# ls /xtrabackup/ 2022-01-10_14-34-07 2022-01-10_14-36-09 2022-01-10_14-38-45 2022-01-10_14-39-18 周一 周二 周三 周四
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
差异备份恢复流程 1. 停止数据库 2. 清理环境 3. 重演回滚redo log(周一,某次差异)--> 恢复数据 4. 修改权限 5. 启动数据库 停止数据库 [root@mysql-server ~]# systemctl stop mysqld [root@mysql-server ~]# rm -rf /var/lib/mysql/* 1.恢复全量的redo log 语法: # innobackupex --apply-log --redo-only /xtrabackup/完全备份目录(周一) [root@mysql-server ~]# innobackupex --apply-log --redo-only /xtrabackup/2022-01-10_14-34-07/ 2.恢复差异的redo log 语法:# innobackupex --apply-log --redo-only /xtrabackup/完全备份目录(周一)--incremental-dir=/xtrabacku/某个差异备份 这里我们恢复周三的差异备份 [root@mysql-server ~]# innobackupex --apply-log --redo-only /xtrabackup/2022-01-10_14-34-07/ --incremental-dir=/xtrabackup/2022-01-10_14-38-45/ #我们恢复周三的差异备份 3.恢复数据 语法:# innobackupex --copy-back /xtrabackup/完全备份目录(周一) [root@mysql-server ~]# innobackupex --copy-back /xtrabackup/2022-01-10_14-34-07/ 修改权限: [root@mysql-server ~]# chown -R mysql.mysql /var/lib/mysql [root@mysql-server ~]# systemctl start mysqld
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
登陆mysql查看一下:
只有123.因为我们恢复的是周三的差异备份。
增量:基于上一次备份
innobackupex --user=root --password=‘qf123’ --incremental /xtrabackup --incremental-basedir=/xtrabackup/上一次备份的 文件/
差异:基于第一次完备
innobackupex --user=root --password=‘qf123’ --incremental /xtrabackup --incremental-basedir=/xtrabackup/完整备份的文件/
4.mysqldump逻辑备份 ---- 推荐优先使用
mysqldump 是 MySQL 自带的逻辑备份工具。可以保证数据的一致性和服务的可用性。
如何保证数据一致?在备份的时候进行锁表会自动锁表。锁住之后在备份。
本身为客户端工具:
远程备份语法: # mysqldump -h 服务器 -u用户名 -p密码 数据库名 > 备份文件.sql
本地备份语法: # mysqldump -u用户名 -p密码 数据库名 > 备份文件.sql
- 1
- 2
- 3
1.常用备份选项
-A, --all-databases #备份所有库
-B, --databases #备份多个数据库
-F, --flush-logs #备份之前刷新binlog日志
--default-character-set #指定导出数据时采用何种字符集,如果数据表不是采用默认的latin1字符集的话,那么导出时必须指定该选项,否则再次导入数据后将产生乱码问题。
--no-data,-d #不导出任何数据,只导出数据库表结构。
--lock-tables #备份前,锁定所有数据库表
--single-transaction #保证数据的一致性和服务的可用性
-f, --force #即使在一个表导出期间得到一个SQL错误,继续。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
注意
使用 mysqldump 备份数据库时避免锁表:
对一个正在运行的数据库进行备份请慎重!! 如果一定要 在服务运行期间备份,可以选择添加 --single-transaction选项,
类似执行: mysqldump --single-transaction -u root -p123456 dbname > mysql.sql
- 1
- 2
- 3
- 4
2.备份表
语法: # mysqldump -u root -p1 db1 t1 > /db1.t1.bak
[root@mysql-server ~]# mkdir /home/back #创建备份目录
[root@mysql-server ~]# mysqldump -uroot -p'qf123' company employee5 > /home/back/company.employee5.bak
备份多个表:
语法: mysqldump -u root -p1 db1 t1 t2 > /db1.t1_t2.bak
[root@mysql-server ~]# mysqldump -uroot -p'qf123' company new_t1 new_t2 > /home/back/company.new_t1_t2.bak
- 1
- 2
- 3
- 4
- 5
- 6
3、备份库
备份一个库:相当于将这个库里面的所有表全部备份。
语法: # mysqldump -u root -p1 db1 > /db1.bak
[root@mysql-server ~]# mysqldump -uroot -p'qf123' company > /home/back/company.bak
备份多个库:
语法:mysqldump -u root -p1 -B db1 db2 db3 > /db123.bak
[root@mysql-server ~]# mysqldump -uroot -p'qf123' -B company testdb > /home/back/company_testdb.bak
备份所有的库:
语法:# mysqldump -u root -p1 -A > /alldb.bak
[root@mysql-server ~]# mysqldump -uroot -p'qf123' -A > /home/back/allbase.bak
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
到目录下面查看一下:

4、恢复数据库和表
为保证数据一致性,应在恢复数据之前停止数据库对外的服务,停止binlog日志 因为binlog使用binlog日志恢复数据时也会产生binlog日志。
- 1
为实验效果先将刚才备份的数据库和表删除了。登陆数据库:
[root@mysql-server ~]# mysql -uroot -pqf123
mysql> show databases;
- 1
- 2
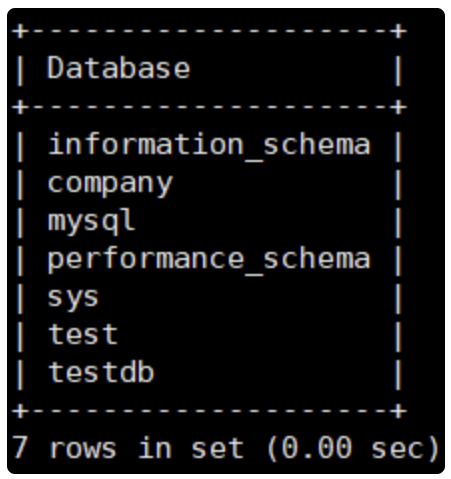
mysql> drop database company;
mysql> \q
- 1
- 2
5、恢复库
登陆mysql创建一个库
mysql> create database company;
恢复:
[root@mysql-server ~]# mysql -uroot -p'qf123' company < /home/back/company.bak
- 1
- 2
- 3
- 4
6、恢复表
登陆到刚才恢复的库中将其中的一个表删除掉 mysql> show databases; mysql> use company mysql> show tables; +-------------------+ | Tables_in_company | +-------------------+ | employee5 | | new_t1 | | new_t2 | +-------------------+ mysql> drop table employee5; 开始恢复: mysql> set sql_log_bin=0; #停止binlog日志 Query OK, 0 rows affected (0.00 sec) mysql> use company; mysql> source /home/back/company.employee5.bak; -------加路径和备份的文件 恢复方式二: # mysql -u root -p1 db1 < db1.t1.bak 库名 备份的文件路径 [root@mysql-server ~]# mysql -uroot -p'qf123' company < /home/back/company.employee5.bak
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
7、备份及恢复表结构
1.备份表结构:
语法:mysqldump -uroot -p123456 -d database table > dump.sql
[root@mysql-server ~]# mysqldump -uroot -p'qf123' -d company employee5 > /home/back/emp.bak
恢复表结构:
登陆数据库创建一个库
mysql> create database t1;
语法:# mysql -u root -p1 -D db1 < db1.t1.bak
[root@mysql-server ~]# mysql -uroot -p'qf123' -D t1 < /home/back/emp.bak
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
登陆数据查看:
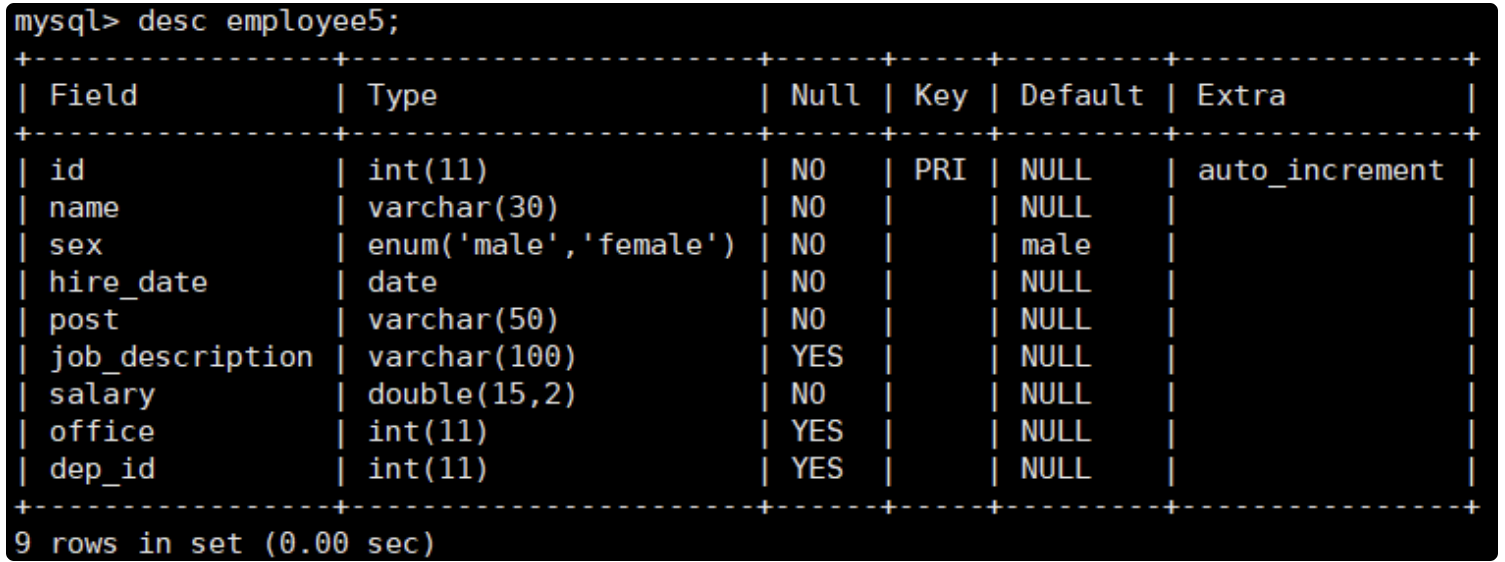
8、数据的导入导出,没有表结构。
表的导出和导入只备份表内记录,不会备份表结构,需要通过mysqldump备份表结构,恢复时先恢复表结构,再导入数据。
- 1
mysql> show variables like "secure_file_priv"; ----查询导入导出的目录。
- 1

修改安全文件目录:
1.创建一个目录:mkdir 路径目录
[root@mysql-server ~]# mkdir /sql
2.修改权限
[root@mysql-server ~]# chown mysql.mysql /sql
3.编辑配置文件:
vim /etc/my.cnf
在[mysqld]里追加
secure_file_priv=/sql
4.重新启动mysql.
# systemctl restart mysqld
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1.导出数据
登陆数据查看数据
mysql> show databases; #找到test库
mysql> use test #进入test库
mysql> show tables; #
mysql> select * from t3;
+------+
| id |
+------+
| 1 |
| 3 |
+------+
2 rows in set (0.00 sec)
mysql> select * from t3 into outfile '/sql/test.t3.bak';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2.数据的导入 先将原来表里面的数据清除掉,只保留表结构 mysql> delete from t3; mysql> load data infile '/sql/test.t3.bak' into table t3; mysql> select * from t3; +------+ | id | +------+ | 1 | | 3 | +------+ 2 rows in set (0.00 sec) 如果将数据导入别的表,需要创建这个表并创建相应的表结构。 只备份表结构 再备份表记录 只恢复表结构 再恢复表记录
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
5、通过binlog恢复数据
开启binlog日志:
[root@mysql-server ~]# vim /etc/my.cnf
log-bin=/var/log/sql-bin/mylog
server-id=1
binlog_format=statement
- 1
- 2
- 3
- 4
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-loNYE43E-1692006783559)(https://yangge666.oss-cn-nanjing.aliyuncs.com/img/image-20230807234405307.png)]
创建目录并修改权限
[root@mysql-server ~]# mkdir /var/log/sql-bin
[root@mysql-server ~]# chown mysql.mysql /var/log/sql-bin
[root@mysql-server ~]# systemctl restart mysqld
- 1
- 2
- 3

mysql> flush logs; #刷新binlog日志会截断产生新的日志文件
mysql> create table testdb.t3(id int); #创建一个表
- 1
- 2
- 3

根据位置恢复
找到要恢复的sql语句的起始位置、结束位置
[root@mysql-server sql-bin]# mysqlbinlog mylog.000002
- 1
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J8StSGd2-1692006783559)(https://yangge666.oss-cn-nanjing.aliyuncs.com/img/image-20230807234458447.png)]
测试
[root@mysql-server ~]# mysql -uroot -p'qf123'
mysql> drop table testdb.t3; #将这个表删除
Query OK, 0 rows affected (0.01 sec)
恢复:
[root@mysql-server ~]# cd /var/log/sql-bin/
[root@mysql-server sql-bin]# mysqlbinlog --start-position 219 --stop-position 321 mylog.000002 | mysql -uroot -p'qf123'
mysql: [Warning] Using a password on the command line interface can be insecure.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
查看:
Day05
十一、Mysql优化
引擎:
查看引擎:
mysql> show engines;
mysql> SHOW VARIABLES LIKE '%storage_engine%';
mysql> show create table t1; ---查看建表信息
临时指定引擎:
mysql> create table innodb1(id int)engine=innodb;
修改默认引擎:
/etc/my.cnf
[mysqld]
default-storage-engine=INNODB ----引擎
修改已经存在的表的引擎:
mysql> alter table t2 engine=myisam;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
优化:
调优思路:
1.数据库设计与规划--以后再修该很麻烦,估计数据量,使用什么存储引擎
2.数据的应用--怎样查询数据,sql语句的优化
3.mysql服务优化--内存的使用,磁盘的使用
4.操作系统的优化--内核,磁盘IO,内存
5.升级硬件设备
6.创建索引提升查询速度
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
mysql常用命令:
mysql> show warnings 查看最近一个sql语句产生的错误警告,看其他的需要看.err日志
mysql> show processlist 显示系统中正在运行的所有进程。
服务器很卡
top
显示Mysql占用cpu 内存都特别高,但是Mysql进程又不能杀死;
进入Mysql数据库交互模式,敲show processlist;查看当前正在运行的sql语句
发现某条语句一直在处于查询的状态,导致Mysql负载较大,所以占用系统资源过大;
与开发人员沟通,问清楚这是谁写的sql语句,是否能杀死,能,杀死 kill sql语句的ID即可;
但是要让开发人员,优化此条sql语句,未优化测试通过,不能再直接应用;
mysql> show errors 查看最近一个sql语句产生的错误信息
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
字符集设置
临时:
mysql> create database db1 CHARACTER SET = utf8;
mysql> create table t1(id int(10)) CHARACTER SET = utf8;
5.7/ 5.5版本设置:
[mysqld]
character_set_server = utf8
===========================================================================================
慢查询:
查看是否设置成功:
mysql> show variables like '%query%';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
当连接数的数值过小会经常出现ERROR 1040: Too many connections错误。
这是查询数据库当前设置的最大连接数
mysql> show variables like '%max_connections%';
强制限制mysql资源设置:
# vim /etc/my.cnf
max_connections = 1024 并发连接数,根据实际情况设置连接数。
connect_timeout = 5 单位秒 ----超时时间,默认30秒
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
innodb引擎:
innodb-buffer-pool-size //缓存 InnoDB 数据和索引的内存缓冲区的大小
innodb-buffer-pool-size=# ----值
这个值设得越高,访问表中数据需要得磁盘 I/O 越少。在一个专用的数据库服务器上,你可以设置这个参数达机器物理内存大小的 80%。
# vim /etc/my.cnf
innodb-buffer-pool-size=2G
- 1
- 2
- 3
- 4
- 5
- 6
十二、AB复制/主从复制
一、什么是主从复制?
1、主从复制,是用来建立一个和主数据库完全一样的数据库环境,称为从数据库;主数据库一般是准实时的业务数据库。
2、主从复制的作用
1.做数据的热备,作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失。
2.架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。
3.读写分离,使数据库能支撑更大的并发。
1--在从服务器可以执行查询工作(即我们常说的读功能),降低主服务器压力;(主库写,从库读,降压)。
2--在从服务器进行备份,避免备份期间影响主服务器服务;(确保数据安全)。
主节点 写
从节点1 从节点2 读 备份
从节点过多,导致数据同步较慢
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
二、主从复制原理
原理:
实现整个主从复制,需要由slave服务器上的IO进程和Sql进程共同完成.
要实现主从复制,首先必须打开Master端的binary log(bin-log)功能,因为MySQL主从复制过程实际上就是Slave从Master端获取相应的二进制日志,然后再在自己slave端完全按照顺序执行日志中所记录的各种操作。
===========================================
1. 在主库上把数据更改(DDL DML DCL)记录到二进制日志(Binary Log)中。
2. 从库I/O线程将主库上的日志复制到自己的中继日志(Relay Log)中。
3. 从库SQL线程读取中继日志中的事件,将其执行到从数据库之上。
===========================================
master 负责写 -----A
slave relay-log -----B
I/O 负责通信读取binlog日志
SQL 负责写数据
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
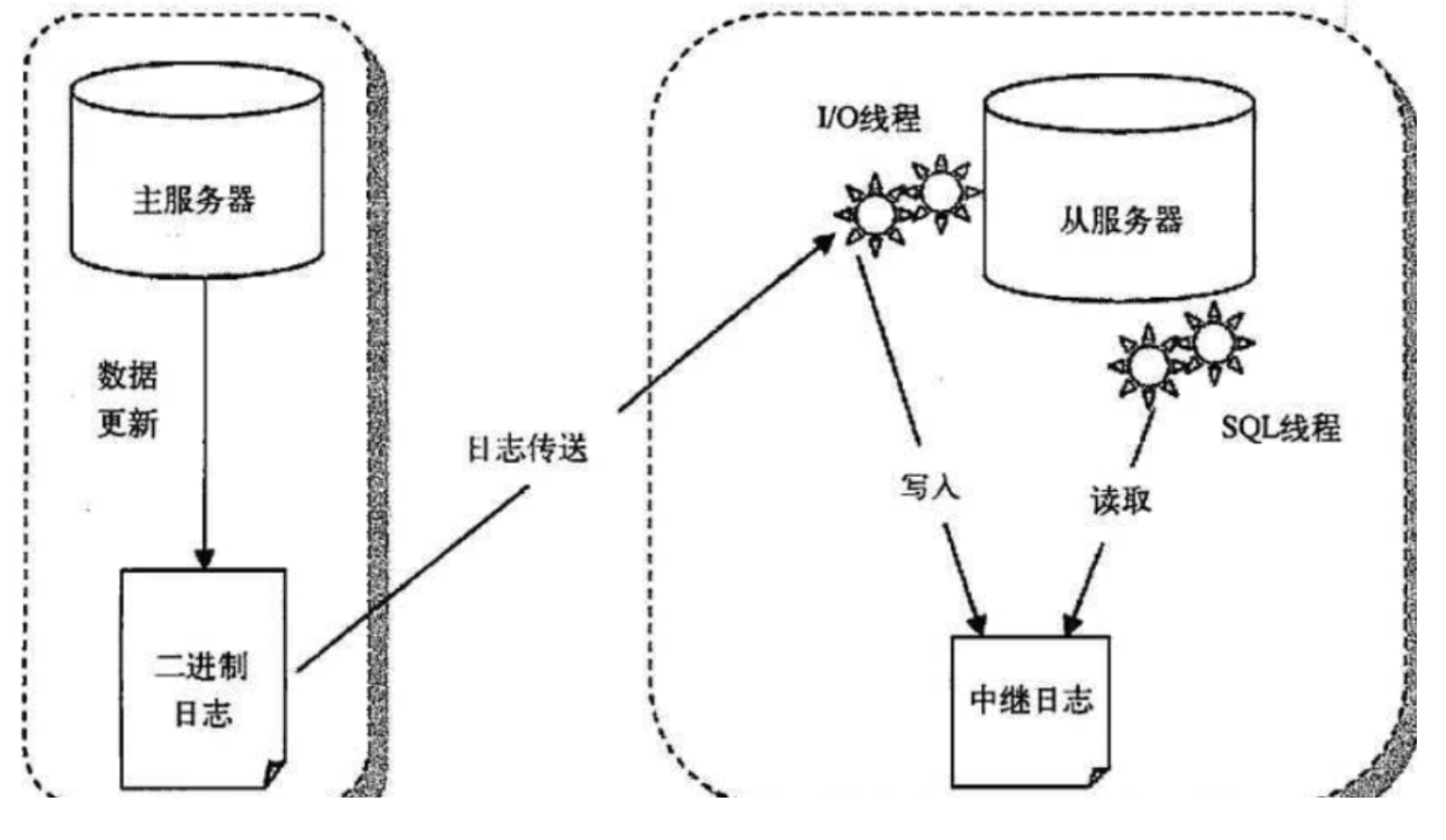
步骤一:主库db的更新事件(update、insert、delete)被写到binlog
步骤二:从库发起连接,连接到主库
步骤三:此时主库创建一个binlog dump thread线程,把binlog的内容发送到从库
步骤四:从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log.
步骤五:从库还会创建一个SQL线程,从relay log里面读取内容,将更新内容写入到slave的db.
- 1
- 2
- 3
- 4
- 5
面试:
1.主从复制延迟大比较慢原因:
主服务器配置高,从服务器的配置低。
并发量大导致主服务器读的慢。从服务器写的慢
网络延迟比较高
从服务器的读写速度慢
从节点过多
2.从数据库的读的延迟问题了解吗?如何解决?
解决方法:
半同步复制—解决数据丢失的问题
并行复制—-解决从库复制延迟的问题
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
三、M-S 架构GTID 基于事务ID复制
1、什么是GTID?
全局事务标识:global transaction identifiers
是用来代替传统复制的方法,GTID复制与普通复制模式的最大不同就是不需要指定二进制文件名和位置。
2、GTID工作原理
1、master更新数据时,会在事务前产生GTID,一同记录到binlog日志中。
2、slave端的i/o 线程将变更的binlog,写入到本地的relay log中。
3、sql线程从relay log中获取GTID,然后对比slave端的binlog是否有记录。
4、如果有记录,说明该GTID的事务已经执行,slave会忽略。
5、如果没有记录,slave就会从relay log中执行该GTID的事务,并记录到binlog。
- 1
- 2
- 3
- 4
- 5
3、部署主从复制
1、架构:
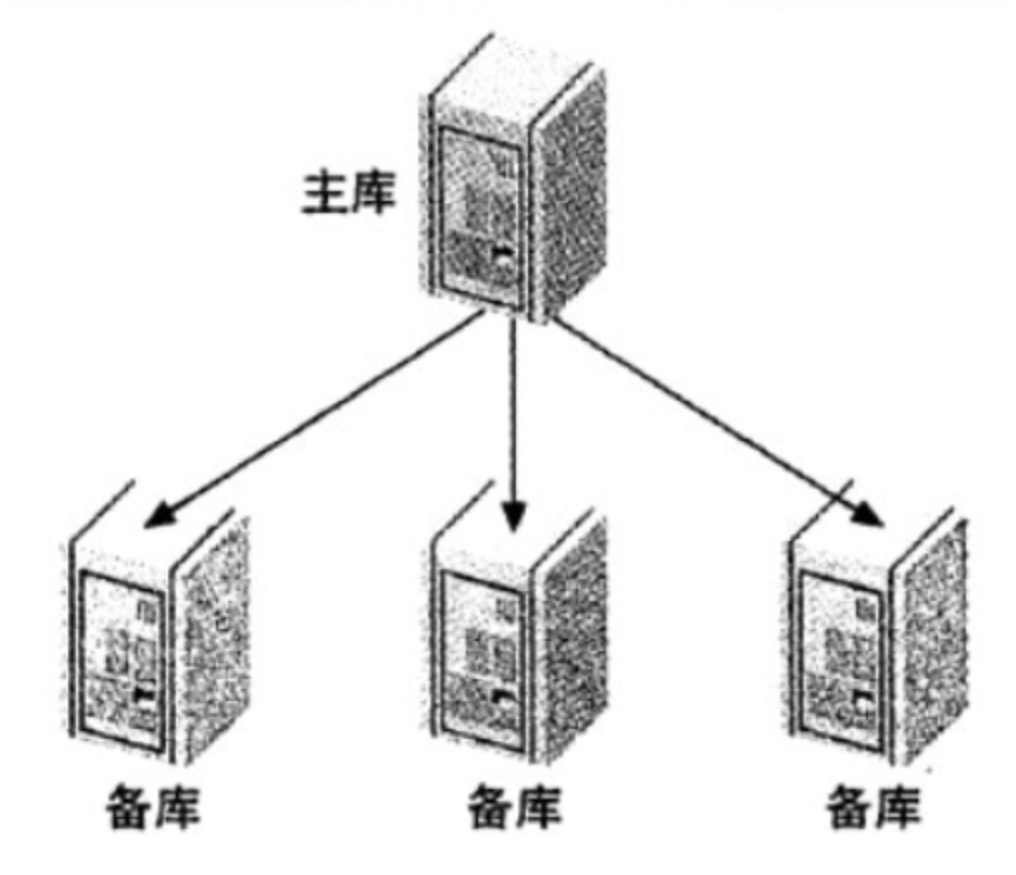
2、准备环境两台机器,关闭防火墙和selinux。---两台机器环境必须一致。时间也得一致
- 1
解析/etc/hosts
192.168.246.129 mysql-master
192.168.246.128 mysql-slave
- 1
- 2
- 3
两台机器安装mysql5.7
[root@mysql-master ~]# wget https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm
[root@mysql-master ~]# yum -y install mysql-community-server
安装略...
[root@mysql-master ~]# systemctl start mysqld
[root@mysql-master ~]# systemctl enable mysqld
[root@mysql-master ~]# netstat -lntp | grep 3306
tcp6 0 0 :::3306 :::* LISTEN 11669/mysqld
[root@mysql-slave ~]# netstat -lntp | grep 3306
tcp6 0 0 :::3306 :::* LISTEN 11804/mysqld
配置并修改密码
略....
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
master操作: [root@mysql-master ~]# vim /etc/my.cnf #在[mysqld]下添加如下内容 server-id=1 #定义server id master必写 log-bin = mylog #开启binlog日志,master比写 gtid_mode = ON #开启gtid enforce_gtid_consistency=1 #强制gtid [root@mysql-master ~]# systemctl restart mysqld #重启 主服务器创建用户: mysql> grant replication slave,reload,super on *.* to 'slave'@'%' identified by 'Qf@12345!'; #注:生产环境中密码采用高级别的密码,实际生产环境中将'%'换成slave的ip mysql> flush privileges; 注意:如果不成功删除以前的binlog日志 replication slave:拥有此权限可以查看从服务器,从主服务器读取二进制日志。 super权限:允许用户使用修改全局变量的SET语句以及CHANGE MASTER语句 reload权限:必须拥有reload权限,才可以执行flush [tables | logs | privileges]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
slave操作: [root@mysql-slave ~]# vim /etc/my.cnf #添加如下配置 server-id=2 gtid_mode = ON enforce_gtid_consistency=1 master-info-repository=TABLE relay-log-info-repository=TABLE [root@mysql-slave ~]# systemctl restart mysqld [root@mysql-slave ~]# mysql -uroot -p'qf123' #登陆mysql mysql> \e change master to master_host='master1', #主ip 地址 最好用域名 master_user='授权用户', #主服务上面创建的用户 master_password='授权密码', master_auto_position=1; -> ; Query OK, 0 rows affected, 2 warnings (0.02 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
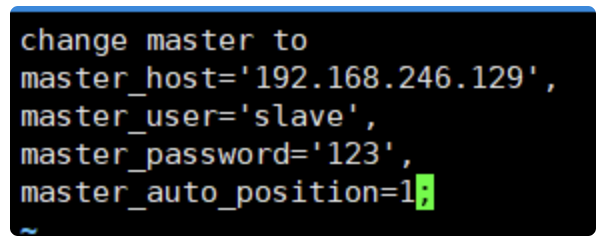
mysql> start slave; #启动slave角色
Query OK, 0 rows affected (0.00 sec)
mysql> show slave status\G #查看状态,验证sql和IO是不是yes。
- 1
- 2
- 3
- 4
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jHf5Stxk-1692006783560)(https://yangge666.oss-cn-nanjing.aliyuncs.com/img/image-20230807234648250.png)]
测试
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rz4470eu-1692006783560)(https://yangge666.oss-cn-nanjing.aliyuncs.com/img/image-20230807234708360.png)]
在slave上面查看一下有没有同步过去:
[root@mysql-slave ~]# mysql -uroot -p'qf123' mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | | test | +--------------------+ mysql> use test mysql> show tables; +----------------+ | Tables_in_test | +----------------+ | t1 | +----------------+ mysql> select * from t1; +------+ | id | +------+ | 1 | +------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
如果同步效果不正常,进行以下操作: 在2台机器数据保持一致的情况下。 从节点: stop slave; #停止同步 reset slave; #清除主节点信息 主节点: reset master; #清除binlog日志 再来到从节点: change master to ####问题1####(防火墙,异常停止同步) Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Slave has more GTIDs than the master has, using the master's SERVER_UUID. This may indicate that the end of the binary log was truncated or that the last binary log file was lost, e.g., after a power or disk failure when sync_binlog != 1. ##解决方案 mysql> reset master; Query OK, 0 rows affected (0.30 sec) mysql> start slave; Query OK, 0 rows affected (0.07 sec) ####问题2####uuid Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work. ##解决方案 [root@server ~]# mv /var/lib/mysql/auto.cnf /var/lib/mysql/auto.cnf.bk [root@server ~]# /etc/init.d/mysqld restart ####问题3#### Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.' ##解决方案 去主库,查看当前的gitd标识 mysql> show global variables like '%gtid%'; +----------------------------------+------------------------------------------+ | Variable_name | Value | +----------------------------------+------------------------------------------+ | binlog_gtid_simple_recovery | ON | | enforce_gtid_consistency | ON | | gtid_executed | 155a9c3f-9ae7-11e8-a22e-5254009cc2bc:1-3 | | gtid_executed_compression_period | 1000 | | gtid_mode | ON | | gtid_owned | | | gtid_purged | 155a9c3f-9ae7-11e8-a22e-5254009cc2bc:1-3 | | session_track_gtids | OFF | +----------------------------------+------------------------------------------+ 返回从库 mysql> stop slave; Query OK, 0 rows affected (0.01 sec) mysql> set global gtid_purged='155a9c3f-9ae7-11e8-a22e-5254009cc2bc:1-3'; ##会跳过一些事务,强同步 Query OK, 0 rows affected (0.08 sec) mysql> start slave; Query OK, 0 rows affected (0.04 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
主从同步完成。
注意: 在关闭和启动mysql服务的时候按顺序先启动master。
可以测试,先将slave库停掉,再停止master库。启动先启动master库,再启动slave库,如果数据没发生改变,也就意味着binlog日志位置没有变化,主从理论上不会失效
面试题
mysql主从,master宕机,如何进行切换?
主机故障或者宕机:
1)在salve执行:
mysql> stop slave;
mysql> reset master;
2)查看是否只读模式:show variables like 'read_only';
只读模式需要修改my.cnf文件,注释read-only=1并重启mysql服务。
或者不重启使用命令关闭只读,但下次重启后失效:set global read_only=off;
3)查看show slave status \G;
4)在程序中将原来主库IP地址改为现在的从库IP地址,测试应用连接是否正常
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
四、主从复制binlog日志方式
192.168.246.135 mysql-master
192.168.246.136 mysql-slave
准备两台机器,关闭防火墙和selinux。---两台机器环境必须一致。时间也得一致
- 1
- 2
- 3
两台机器配置hosts解析
192.168.246.135 mysql-master
192.168.246.136 mysql-slave
两台机器安装mysql
# wget https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm
略...
[root@mysql-master ~]# systemctl start mysqld
[root@mysql-master ~]# systemctl enable mysqld
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
开始配置主服务
1、在主服务器上,必须启用二进制日志记录并配置唯一的服务器ID。需要重启Mysql服务。
- 1
编辑主服务器的配置文件 my.cnf,添加如下内容
添加配置
[mysqld]
log-bin=/var/log/mysql/mysql-bin
server-id=1
- 1
- 2
- 3
- 4
创建日志目录并赋予权限
[root@mysql-master ~]# mkdir /var/log/mysql
[root@mysql-master ~]# chown -R mysql.mysql /var/log/mysql
- 1
- 2
重启服务
[root@mysql-master ~]# systemctl restart mysqld
- 1
查找密码
[root@mysql-master ~]# grep pass /var/log/mysqld.log
- 1
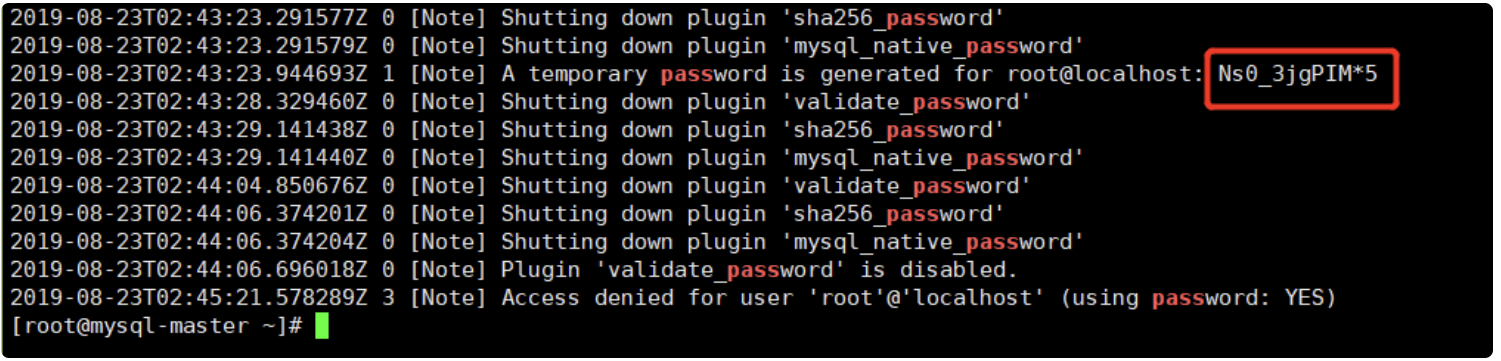
修改密码
[root@mysql-master ~]# mysqladmin -uroot -p'Ns0_3jgPIM*5' password 'Qf@12345!'
创建主从同步的用户:
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%' identified by 'Qf@12345!';
mysql> flush privileges;
- 1
- 2
- 3
- 4
在主服务器上面操作
mysql> show master status\G
- 1
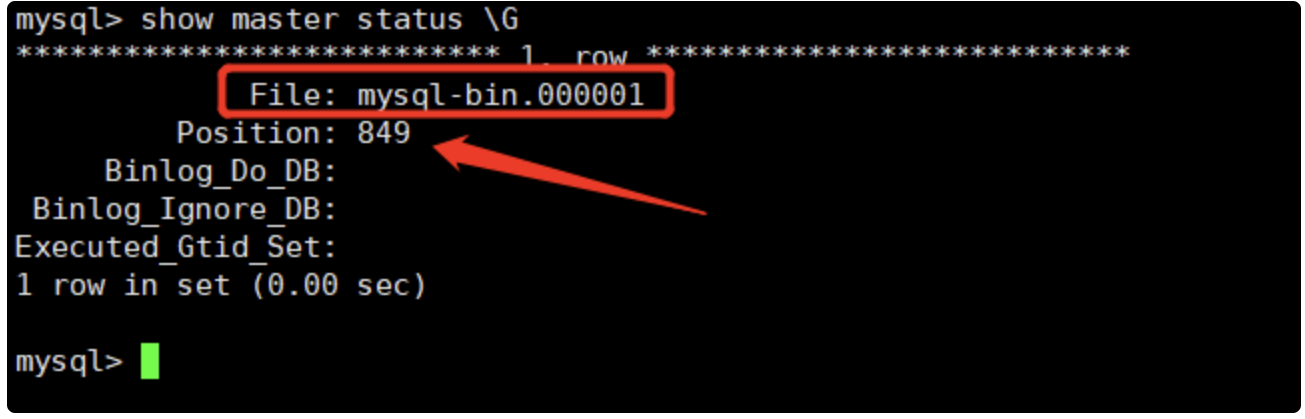
在从服务上面操作:
my.cnf配置文件
[mysqld] server-id=2 重启服务 [root@mysql-slave ~]# systemctl restart mysqld 设置密码 [root@mysql-slave ~]# grep pass /var/log/mysqld.log [root@mysql-slave ~]# mysqladmin -uroot -p'ofeUcgA)4/Yg' password 'Qf@12345!' 登录mysql [root@mysql-slave ~]# mysql -uroot -p'Qf@12345!' mysql> \e CHANGE MASTER TO MASTER_HOST='mysql-master', MASTER_USER='repl', MASTER_PASSWORD='Qf@12345!', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=849; -> ; mysql> start slave; mysql> show slave status\G
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
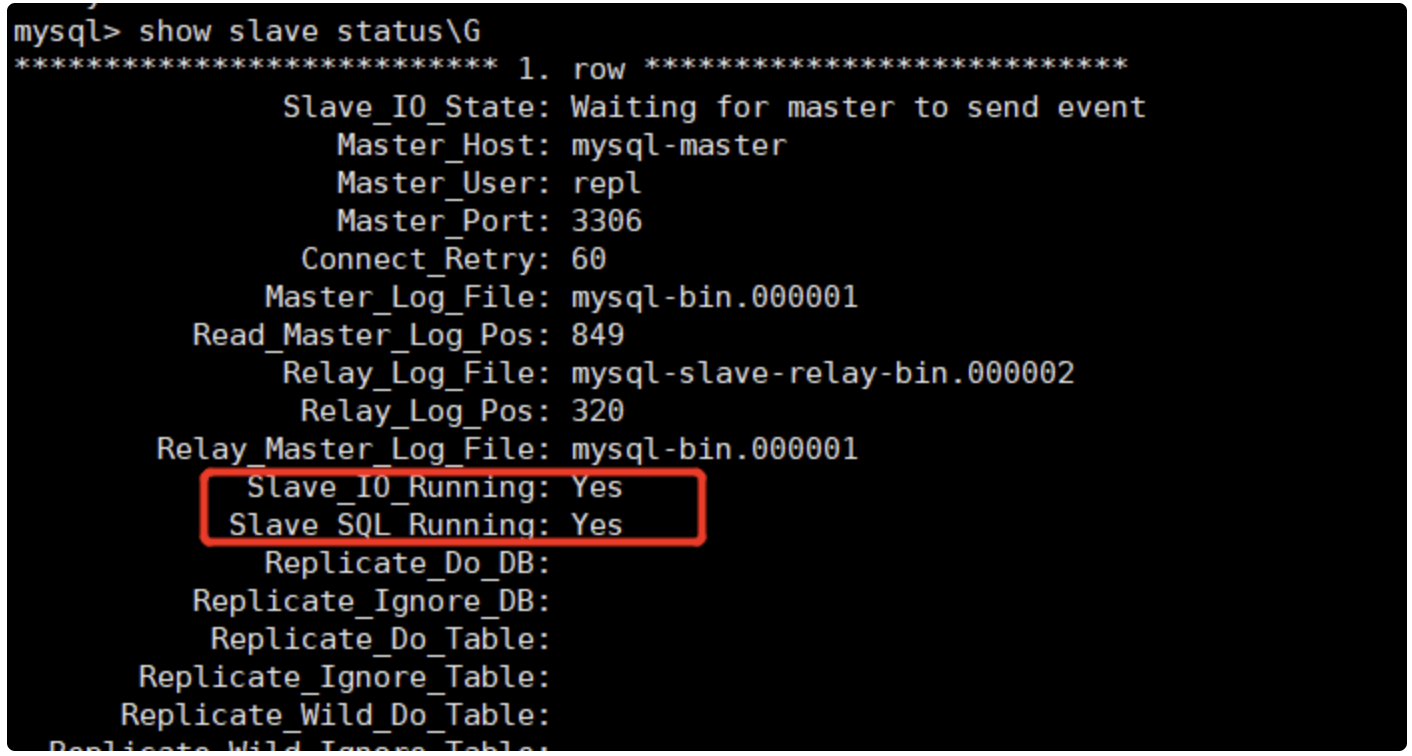
参数解释:
CHANGE MASTER TO
MASTER_HOST='master2.example.com', #主服务器ip
MASTER_USER='replication', #主服务器用户
MASTER_PASSWORD='password', #用户密码
MASTER_PORT=3306, #端口
MASTER_LOG_FILE='master2-bin.001', #binlog日志文件名称
MASTER_LOG_POS=4, #日志位置
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在master上面执行:
mysql> create database testdb; #创建一个库
Query OK, 1 row affected (0.10 sec)
mysql> \q
- 1
- 2
- 3
- 4
故障排错
#### UUID一致,导致主从复制I/O线程不是yes > Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work 致命错误:由于master和slave具有相同的mysql服务器uuid,导致I/O线程不进行;这些uuid必须不同才能使复制工作。 问题提示主从使用了相同的server UUID,一个个的检查: 检查主从server_id 主库: mysql> show variables like 'server_id'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | server_id | 1 | +---------------+-------+ 1 row in set (0.01 sec) 从库: mysql> show variables like 'server_id'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | server_id | 2 | +---------------+-------+ 1 row in set (0.01 sec) server_id不一样,排除。 检查主从状态: 主库: mysql> show master status; +------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------+ | mysql-bin.000001 | 154 | | | | +------------------+----------+--------------+------------------+-------------------+ 1 row in set (0.00 sec) 从库: mysql> show master status; +------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------+ | mysql-bin.000001 | 306 | | | | +------------------+----------+--------------+------------------+-------------------+ 1 row in set (0.00 sec) File一样,排除。 最后检查发现他们的auto.cnf中的server-uuid是一样的。。。 [root@localhost ~]# vim /var/lib/mysql/auto.cnf [auto] server-uuid=4f37a731-9b79-11e8-8013-000c29f0700f 修改uuid并重启服务
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
作业
一主双从(gtid方式),binlog日志方式:
在准备一台虚拟机做为slave2,关闭防火墙和selinux
192.168.246.130 #mysql-slave2
- 1
- 2
1.由于刚才测试已经有了数据,需要先将master服务上面的数据备份出来。导入slave2的mysql中。这样才能保证集群中的机器环境一致。
在master操作:
[root@mysql-master ~]# mysqldump -uroot -p'qf123' --set-gtid-purged=OFF test > test.sql
[root@mysql-master ~]# ls
test.sql
[root@mysql-master ~]# scp test.sql 192.168.246.130:/root/ #拷贝到slave2
- 1
- 2
- 3
- 4
- 5
- 6
#### 开启 GTID 后的导出导入数据的注意点
> Warning: A partial dump from a server that has GTIDs will by default include the GTIDs of all transactions, even those that changed suppressed parts of the database. If you don't want to restore GTIDs, pass --set-gtid-purged=OFF. To make a complete dump, pass --all-databases --triggers --routines --events
意思是: 当前数据库实例中开启了 GTID 功能, 在开启有 GTID 功能的数据库实例中, 导出其中任何一个库, 如果没有显示地指定--set-gtid-purged参数, 都会提示这一行信息. 意思是默认情况下, 导出的库中含有 GTID 信息, 如果不想导出包含有 GTID 信息的数据库, 需要显示地添加--set-gtid-purged=OFF参数.
mysqldump -uroot -p --set-gtid-purged=OFF --all-databases > alldb.db
导入数据是就可以相往常一样导入了。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
slave2操作:
安装mysql5.7
[root@mysql-slave2 ~]# wget https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm
[root@mysql-slave2 ~]# yum -y install mysql-community-server
[root@mysql-slave2 ~]# systemctl start mysqld
[root@mysql-slave2 ~]# systemctl enable mysqld
登陆mysql创建一个test的库
[root@mysql-slave2 ~]# mysql -uroot -p'Qf@12345!'
mysql> create database test;
[root@mysql-slave2 ~]# mysql -uroot -p'Qf@12345!' test < test.sql #将数据导入。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
开始配置slave2 [root@mysql-slave2 ~]# vim /etc/my.cnf server-id=3 #每台机器的id不一样 gtid_mode = ON enforce_gtid_consistency=1 master-info-repository=TABLE relay-log-info-repository=TABLE [root@mysql-slave2 ~]# systemctl restart mysqld [root@mysql-slave2 ~]# mysql -uroot -p'Qf@12345!' mysql> \e change master to master_host='192.168.246.129', master_user='slave', master_password='123', master_auto_position=1; -> ; mysql> start slave; #将slave启动起来 mysql> show slave status\G #查看一下状态
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
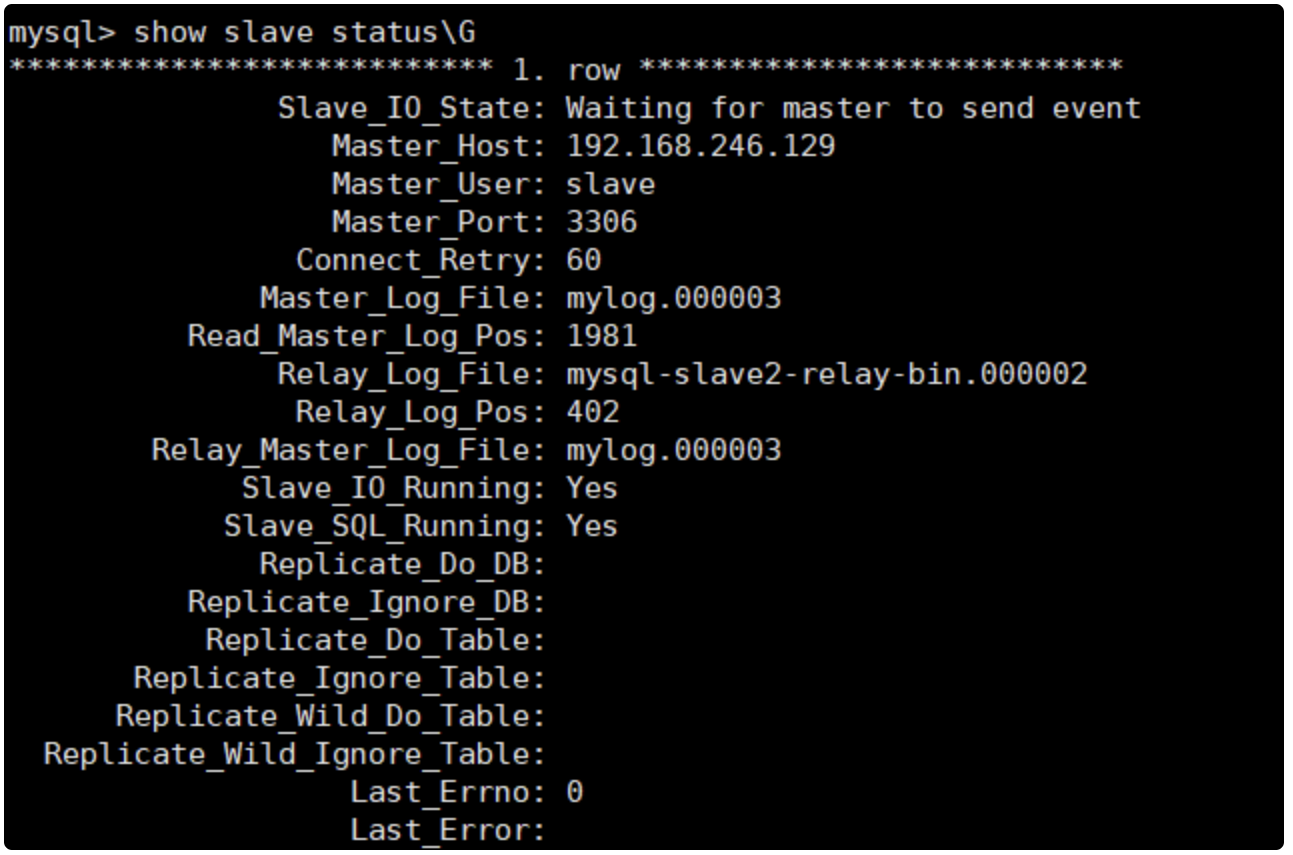
测试:
在master上面在创建一个库:
[root@mysql-master ~]# mysql -uroot -p'qf123'
mysql> create database qfedu;
mysql> create table qfedu.t1(id int);
mysql> insert into qfedu.t1 values (1);
mysql>
- 1
- 2
- 3
- 4
- 5
两台slave
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iouhJVrV-1692006783562)(https://yangge666.oss-cn-nanjing.aliyuncs.com/img/image-20230807234953776.png)]
主从同步完成!
注意: 在关闭和启动mysql服务的时候按顺序先启动master。
- 1
十三、读写分离
1.什么是读写分离
- **在数据库集群架构中,让主库负责处理写入操作,而从库只负责处理select查询,让两者分工明确达到提高数据库整体读写性能。**当然,主数据库另外一个功能就是负责将数据变更同步到从库中,也就是写操作。
2. 读写分离的好处
1. 分摊服务器压力,提高机器的系统处理效率。
2. 在写入不变,大大分摊了读取,提高了系统性能。另外,当读取被分摊后,又间接提高了写入的性能。所以,总体性能提高了。
3. 增加冗余,提高服务可用性,当一台数据库服务器宕机后可以调整另外一台从库以最快速度恢复服务。
- 1
- 2
- 3
Mycat 数据库中间件
Mycat 是一个开源的数据库系统,但是由于真正的数据库需要存储引擎,而 Mycat 并没有存储引擎,所以并不是完全意义的数据库系统。 那么 Mycat 是什么?Mycat 是数据库中间件,就是介于数据库与应用之间,进行数据处理与交互的中间服务是实现对主从数据库的读写分离、读的负载均衡。
常见的数据库中间件:

MyCAT 是使用 JAVA 语言进行编写开发,使用前需要先安装 JAVA 运行环境(JRE),由于 MyCAT 中使用了 JDK7 中的一些特性,所以要求必须在 JDK7 以上的版本上运行。
准备一台新的主机放到master的前面做代理
192.168.246.133 mysql-mycat
并将三台机器互做本地解析
- 1
- 2
- 3
架构
这里是在mysql主从复制实现的基础上,利用mycat做读写分离,架构图如下
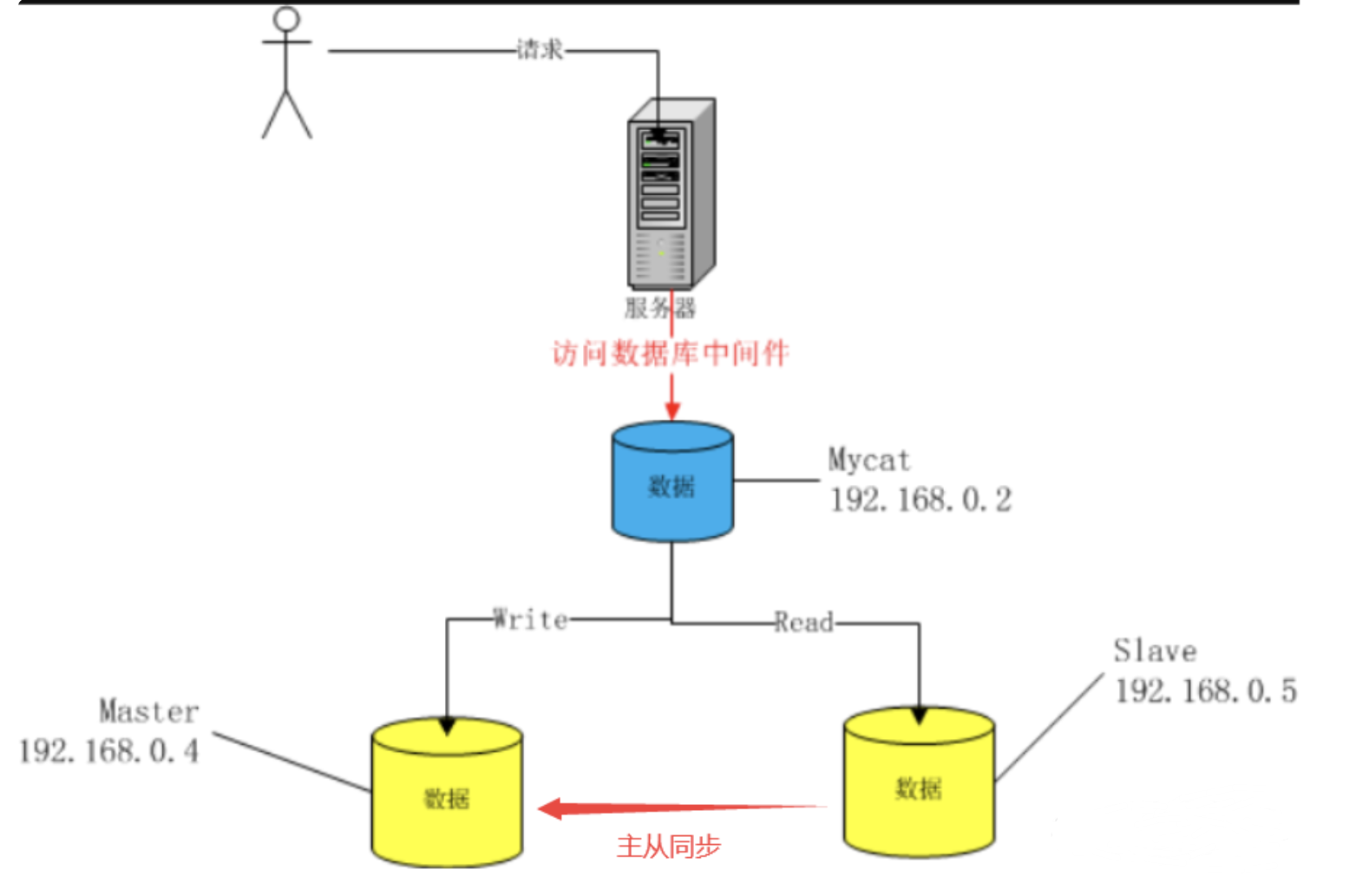
部署环境:
安装jdk
下载jdk账号:
账号:liwei@xiaostudy.com
密码:OracleTest1234
将jdk上传到服务器中,
[root@mycat ~]# tar xzf jdk-8u221-linux-x64.tar.gz -C /usr/local/
[root@mycat ~]# cd /usr/local/
[root@mycat local]# mv jdk1.8.0_221/ java
设置环境变量
[root@mycat local]# vim /etc/profile #添加如下内容,
JAVA_HOME=/usr/local/java
PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
[root@mycat local]# source /etc/profile
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
部署mycat
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pXwVPYGe-1692006783563)(https://cdn.nlark.com/yuque/0/2022/png/25576613/1667116134577-c3ea9553-77c8-4e08-bce6-09f37f22f4a9.png)]
下载
[root@mycat ~]# wget http://dl.mycat.io/1.6.5/Mycat-server-1.6.5-release-20180122220033-linux.tar.gz
解压
[root@mycat ~]# tar xf Mycat-server-1.6.5-release-20180122220033-linux.tar.gz -C /usr/local/
- 1
- 2
- 3
- 4
配置mycat
认识配置文件
MyCAT 目前主要通过配置文件的方式来定义逻辑库和相关配置:
/usr/local/mycat/conf/server.xml #定义用户以及系统相关变量,如端口等。其中用户信息是前端应用程序连接 mycat 的用户信息。
/usr/local/mycat/conf/schema.xml #定义逻辑库,表、分片节点等内容。
- 1
- 2
- 3
- 4
- 5
- 6
配置server.xml
以下为代码片段
下面的用户和密码是应用程序连接到 MyCat 使用的,可以自定义配置
而其中的schemas 配置项所对应的值是逻辑数据库的名字,也可以自定义,但是这个名字需要和后面
schema.xml 文件中配置的一致。
[root@mycat ~]# cd /usr/local/mycat/conf/ [root@mycat conf]# vim server.xml ... <!--下面的用户和密码是应用程序连接到 MyCat 使用的.schemas 配置项所对应的值是逻辑数据库的名字,这个名字需要和后面 schema.xml 文件中配置的一致。--> <user name="root" defaultAccount="true"> <property name="password">Qf@12345!</property> <property name="schemas">testdb</property> <!-- 表级 DML 权限设置 --> <!-- <privileges check="false"> <schema name="TESTDB" dml="0110" > <table name="tb01" dml="0000"></table> <table name="tb02" dml="1111"></table> </schema> </privileges> --> </user> <!-- <!--下面是另一个用户,并且设置的访问 TESTED 逻辑数据库的权限是 只读。可以注释掉 <user name="user"> <property name="password">user</property> <property name="schemas">TESTDB</property> <property name="readOnly">true</property> </user> --> </mycat:server>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
== 上面的配置中,假如配置了用户访问的逻辑库,那么必须在 schema.xml 文件中也配置这个逻辑库,否则报错,启动 mycat 失败 ==
我特意更换的配置:

配置schema.xml
以下是配置文件中的每个部分的配置块儿
逻辑库和分表设置
<schema name="testdb" // 逻辑库名称,与server.xml的一致
checkSQLschema="false" // 不检查sql
sqlMaxLimit="100" // 最大连接数
dataNode="dn1"> // 数据节点名称
<!--这里定义的是分表的信息-->
</schema>
- 1
- 2
- 3
- 4
- 5
- 6
数据节点
<dataNode name="dn1" // 此数据节点的名称
dataHost="localhost1" // 主机组虚拟的
database="testdb" /> // 真实的数据库名称
- 1
- 2
- 3
主机组
<dataHost name="localhost1" // 主机组
maxCon="1000" minCon="10" // 连接
balance="0" // 负载均衡
writeType="0" // 写模式配置
dbType="mysql" dbDriver="native" // 数据库配置
switchType="1" slaveThreshold="100">
<!--这里可以配置关于这个主机组的成员信息,和针对这些主机的健康检查语句-->
</dataHost>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
balance 属性
负载均衡类型,目前的取值有 3 种:
1. balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。
2. balance="1", 全部的 readHost 与 writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡。
3. balance="2", 所有读操作都随机的在 writeHost、readhost 上分发。
4. balance="3", 所有读请求随机的分发到 wiriterHost 对应的 readhost 执行,writerHost 不负担读压力, #注意 balance=3 只在 1.4 及其以后版本有,1.3 没有。
writeType 属性
负载均衡类型
1. writeType="0", 所有写操作发送到配置的第一个 writeHost,第一个挂了切换到还生存的第二个writeHost,重新启动后已切换后的为准.
2. writeType="1",所有写操作都随机的发送到配置的 writeHost,#版本1.5 以后废弃不推荐。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
健康检查
<heartbeat>select user()</heartbeat> #对后端数据进行检测,执行一个sql语句,user()内部函数
- 1
读写配置
<writeHost host="hostM1" url="192.168.246.135:3306" user="mycat" password="Qf@12345!">
<!-- can have multi read hosts -->
<readHost host="hostS2" url="192.168.246.136:3306" user="mycat" password="Qf@12345!" />
</writeHost>
- 1
- 2
- 3
- 4
以下是组合为完整的配置文件,适用于一主一从的架构
[root@mycat ~]# cd /usr/local/mycat/conf/ [root@mycat conf]# cp schema.xml schema.xml.bak [root@mycat conf]# vim schema.xml <?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="testdb" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"> </schema> <dataNode name="dn1" dataHost="localhost1" database="testdb" /> <dataHost name="localhost1" maxCon="1000" minCon="10" balance="3" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <writeHost host="mysql-master" url="mysql-master:3306" user="mycat" password="Qf@1234!"> <!-- can have multi read hosts --> <readHost host="mysql-slave" url="mysql-slave:3306" user="mycat" password="Qf@1234!" /> </writeHost> </dataHost> </mycat:schema>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
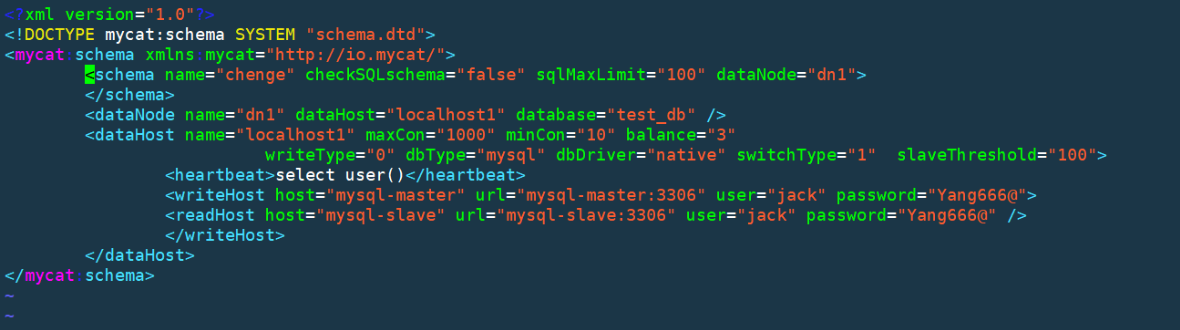
在真实的 master 数据库上创建测试库和记录并且给用户授权
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YTtWhSzN-1692006783564)(https://cdn.nlark.com/yuque/0/2022/png/25576613/1667116031433-365f9b2f-aa2f-494f-86f7-c4563e8cb520.png)]
mysql> grant all on testdb.* to mycat@'%' identified by 'Qf@456789';
mysql> flush privileges;
- 1
- 2
在mycat的机器上面测试mycat用户登录:
安装mysql的客户端:
# yum install -y mysql
# mysql -umycat -p'Qf@456789' -h mysql-master
- 1
- 2
- 3
- 4
启动Mycat
启动之前需要调整JVM
在wrapper.conf中添加
[root@mycat mycat]# cd conf/
[root@mycat conf]# vim wrapper.conf #在设置JVM哪里添加如下内容
wrapper.startup.timeout=300 //超时时间300秒
wrapper.ping.timeout=120
启动:
[root@mycat conf]# /usr/local/mycat/bin/mycat start #需要稍微等待一会
Starting Mycat-server...
[root@mycat ~]# jps #查看mycat是否启动
13377 WrapperSimpleApp
13431 Jps
[root@mycat ~]# netstat -lntp | grep java
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

测试mycat
将master当做mycat的客户端
[root@mysql-master ~]# mysql -uroot -h mysql-mycat -p'Qf@456789' -P 8066
- 1
- 2
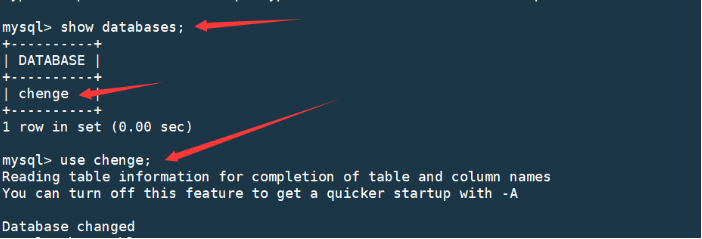
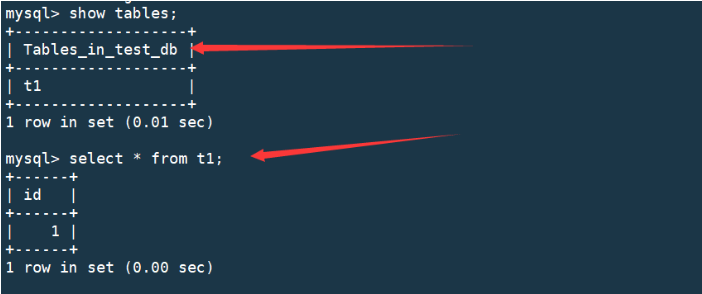
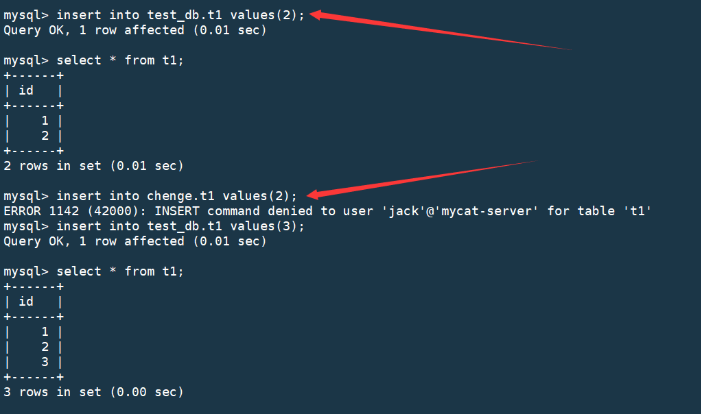
如果在show table报错:
mysql> show tables;
ERROR 3009 (HY000): java.lang.IllegalArgumentException: Invalid DataSource:0
- 1
- 2
- 3
- 4
解决方式:
登录master服务将mycat的登录修改为%
mysql> update user set Host = '%' where User = 'jack' and Host = 'localhost';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> flush privileges;
或者在授权用户mycat权限为*.*
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1.JDBC连接Mysql5
mysql [详细] 赞
踩

