
热门标签
热门文章
- 1JNI中的log日志_jnilog1699437787981.txta
- 2人工智能和机器学习相关的比较活跃的论坛网址列表_人工智能论坛网站
- 3sklearn包中K近邻分类器 KNeighborsClassifier的使用_from sklearn.neighbors import kneighborsclassifier
- 4【demo】用opencv+qt识别人脸与眼睛_qt opencv获取瞳孔
- 5局域网安全17 dot1x
- 6androidStudio配置安装git以及下载项目_android studio从git上下载项目
- 7【Kafka】Kafka的重复消费和消息丢失问题_kafka重复消费
- 8使用STM32芯片ID作为MAC地址_0x1fff7a10
- 9韩国Meetup | Trias,区块链公链底层的一条“高速公路”
- 10如何在自定义数据集上训练YOLOv8的各个模型_yolov8训练示例
当前位置: article > 正文
消费者组重平衡如何避免吗?Rebalance_mq 上线rebalance规避
作者:Li_阴宅 | 2024-06-27 23:58:21
赞
踩
mq 上线rebalance规避
1.了解“协调者” Coordinator
在Kafka中"协调者",专门为消费组服务,负责为组执行Rebalance以及提供位移管理和组员管理等。
2.kafka确定消费组的协调者所在Broker的算法有2个步骤
步骤1
确定位移主题的那个分区来保存该Group组数据:通过分区策略(比如 轮询、随机)但是这里用的是HashPartitioner哈希
分区,partitionId=Math.abs(groupId.hashCode() % offsetsTopicPartitionCount)。通过hash值处于分区数进行。
- 1
- 2
步骤2
找出该分区的Leader副本所在Broker,该 Broker 即为对应的 Coordinator。
- 1
3.Rebalance的缺点
缺点也很简单,就是类似JVMGC 垃圾回收会停下手里的一切事去进行Rebalance,并且由于我们常用kafka的版本它进行rebalance会出现以下问题:
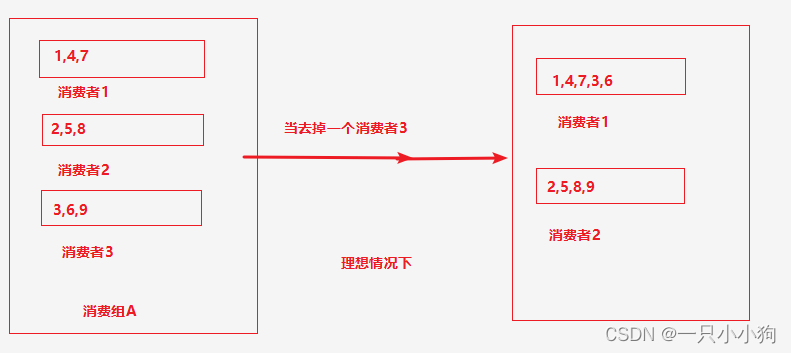
3.1 理想情况下
当消费者3倍踢出消费组的时候,协调者应该以最小的消耗去将多余消息分配给其余消费者,但是实际情况下不是这样。
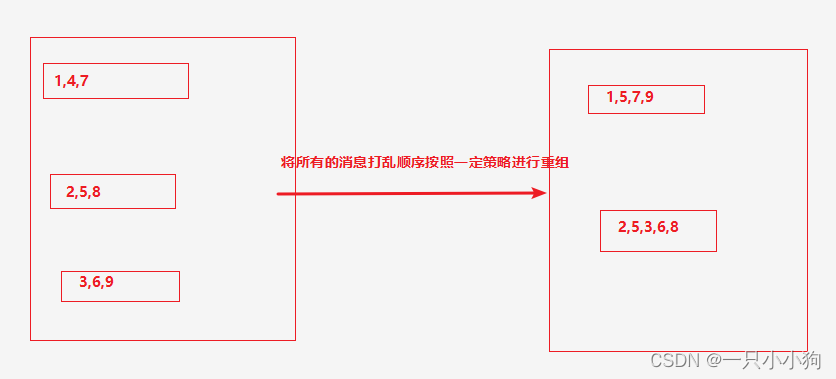
3.2 真实情况
将消费者3去掉后,是将所有的消息重组放入其余消费者中。
4.如何避免Rebalance 重平衡
我们站在消费端的角度来看(组成员数量发生变化)
4.1 第一类非必要 Rebalance ,未能及时发送心跳,导致 Consumer 被“踢出”Group而引发的
解决方法:
#单位ms 设置心跳传送时间几毫秒一次 ,默认是3000ms
heartbeat.interval.ms
#单位ms 多长时间没有心跳,后连接超时,默认10000ms
session.timeout.ms
- 1
- 2
- 3
- 4
- 5
比如
设置 session.timeout.ms = 6000。
设置 heartbeat.interval.ms = 2000。
这样就正常情况下最起码会发3次心跳给broker
4.2 第二类非必要 Rebalance 是 Consumer 消费时间过长导致的
这个参数最好设置大一些,比如你逻辑处理最长要10分钟,那你需要设置的比这个大为你的业务处理逻辑留下充足的时间,从而防止超时导致Rebalance。
#使用消费者组管理时调用 poll() 之间的最大延迟。这为消费者在获取更多记录之前可以空闲的时间量设置了上限。
#如果在此超时到期之前未调用 poll(),则认为消费者失败,组将重新平衡,以便将分区重新分配给另一个成员。
# 默认3000ms
max.poll.interval.ms
- 1
- 2
- 3
- 4
4.3 如果还有问题就考虑GC问题
由于频繁发生Full GC 而导致非预期的Rebalance
推荐阅读
相关标签

