
- 12024年软件测试最新提高国内访问 GitHub 的速度的 9 种方案_github001,2024年最新软件测试开发面试题及答案_github加速 2024
- 2SpringBootWeb 篇-深入了解 Redis 五种类型命令与如何在 Java 中操作 Redis
- 3解决 Tomcat 跨域问题 - Tomcat 配置静态文件和 Java Web 服务(Spring MVC Springboot)同时允许跨域_tomcat配置跨域
- 4MySQL运维(二)MySQL分库分表概念及实战、读取分离详解_linux mysql 分库
- 5大量机器学习(Machine Learning)&深度学习(Deep Learning)资料_机器学习谁的课讲到最后
- 6记一次在ubuntu安装Mysql8修改lower_case_table_names =1的经历及最终解决方案_ubuntu已安装的mysql怎么重新初始化--lower-case-table-names=1
- 7【单片机笔记】基于XL4015的可调电源_xl4015可调降压电路图
- 8Windows安装PHP及在VScode中配置插件,使用PHP输出HelloWorld_windowsvscode php环境
- 9zookeeper知识点(一)_如何进入zk查看节点
- 10优化 CSS 代码的小技巧_html import的代替方案
架构决策之消息中间件MQ系列四-Kafka_kafka event bus
赞
踩
一、前言
什么是kafka,先看下官网的定义:
Apache Kafka is a distributed streaming platform.(kafka是一个分布式的流平台)
从这个定义我们可以认为,kafka是实现大数据传递的MQ,使用在日志收集,度量指标,流处理等场景。高吞吐,高可用,分布式是其主要的特征。
二、kafka架构
与ActiveMQ,RabbitMQ的主从架构不同,而kafka的采用的是分布式架构,我们来模拟推演下这个架构。
咱们一步一步来。最开始我们想到了这种模型

这个是最原始的生产消费模型,在一个进程内部经常使用这个模型进行事件的处理(比如EventBus),但是在作为系统间的消息分发中间件显然是不合适的,这种单节点的消息队列会成为瓶颈,流量增大的情况下,会被打爆,没法做到高可用。
既然单节点是瓶颈,那我们就扩消息队列的节点。

可以根据topic的数量扩展多个消息队列节点,每个节点保存不同的topic消息,这样就能均衡topic读写流量。但是这个同样存在问题
1、消息队列虽然是多个节点,但是对于每个topic消息,仍然是单点,无法实现高可用。
2、没有消息队列的协调者,生产者和消费者需要提前知道topic所在的消息队列。
我们再来改进下。

每个消息队列都全量保存topic消息,每个topic都有一个主,其他的都是备,主备间形成同步关系,主topic负责读写,一旦某个消息队列节点故障,可以快速切换到其他的消息队列上。同时增加一个controller,负责记录topic的主备关系,以及监控消息队列的状态。
这个是不是类似我们mysql的主备集群。看起来很不错了,但是还是有问题:
1、每个节点需要保存全量的topic数据,如果在海量数据的情况,单台的存储空间要求高。
2、每个消息队列节点,需要负责其所属所有主Topic的读写,如果Topic的并发不均衡,会导致消息队列的负载不均衡。比如Topic1的并发高,Topic2的并发低,就会导致消息队列1"很忙",而消息队列2"很闲"。
没关系,再来改进。

将Topic再拆成多个分区(Partition),以分区为物理存储单位,分布保存到队列节点上。每个Partition的leader作为读写的负载,follower作为副本,leader与follower间复制。这样一个主题的消息以分区为存储单元,均衡分布到相应的消息队列节点上,消息队列节点无需持有完整Topic的信息以及读写负载。
我们看下kafka的架构

Producer,生产者,负责将消息发布到特定的Topic上,并将消息均衡分布到所有的partition。
Broker Cluster,broker集群,由多个broker节点组成。
Broker,kafka的服务器节点,消息的物理存储,负责生产者和消费者的读写请求。
Broker controller,broker控制节点,实现broker基本功能,同时负责管理broker,包括partition的分配和选举,broker的监控(0.9版本之后新增)。
Zookeeper,集群的协调器,保存broker,主题和分区的元数据信息。
Consumer group,消费组,由一组消费者组成,负责均衡的消费Partition的消息。
Consumer,消费者,订阅一个或者多个主题,并按照顺序拉取消息并处理。
Topic,主题,消息的逻辑归类,表示同一类消息,包含多个partition。
Partition,分区,消息存储的物理单位,是一个可追加的log文件,一个分区只归属某个主题。分区采用多副本机制(Replica),leader副本负责读写请求,follower副本同步leader副本数据,当leader副本出现故障,从follower中选举中选举一个,继续对外提供服务,实现失效转移。
三、生产消息
我们首先看下消息的生产和发送基本流程。

1、消息创建
生产者创建一条消息,消息需要包括Topic,Key(可以为null),Value信息,Partition可选。
首先将消息按照指定的序列化器对key,value进行分别序列化,将对象转化成字节数组(建议不要自定义的,一般使用StringSerializer)。
2、分区选择
一个Topic有多个分区,该消息到底要写入到哪个分区呢,如果分配不好,就会让某些partition很忙,某些partition很闲,这就涉及到partition负载均衡,有以下几种策略:
1、指定分区,也就是在消息创建的时候指定分区,此时分区器就不会处理,直接发往指定的分区即可。
2、根据key值指定,如果key为null,采用轮询的策略选择分区;如果key不为空,则采用默认的分区策略,对key进行散列化,映射到对应的分区上。因为相同的key值总会分配到同一分区上,默认策略可能会导致某个分区的的负载特点大,比如70%的消息都来自于某个客户,我们又使用了客户的id作为key,那么这些消息都会写入同一个partition,导致该partition的负载大。
3、自定义分区策略,可以自定义特定的算法进行处理,可以避免上述默认策略的问题。
3、消息发送
经过分区器的消息并没有立即发送给broker,而是先放到内存缓存区保存起来,当达缓存区大小到某个阀值(通过buffer.memory设定缓存区的大小),批量的发送给broker(leader分区所在的broker),这样设计的目的就是为了提高吞吐量,但是也不可避免的带来一定的延时。
批量消息可以通过同步/异步的方式发送给broker,同步模式会阻塞当前的线程,等待broker的响应;异步模式是通过回调的方式接受broker的结果。
4、消息确认
我们知道broker的分区是多副本的,写入多少个分区副本才算消息发送成功了呢,生产者通过设置acks参数决定。
1、acks=0,生产者在成功写入悄息之前不会等待任何来自服务器的响应,也就是发送出去后不关注broker有没有接受到。这种方式可以提高吞吐量,但是可靠性差,容易丢消息。
2、acks=1,生产者发送消息后,只要Leader副本接受到消息后,就算成功。这种吞吐量不如前一种,但是可靠性有提升,但也存在丢数据的风险,如果Leader副本接受到数据后,Follower还没来得及拉取,Leader副本就崩溃了,那么这些消息就会丢失。
3、acks=all,生产者发送消息后,需要所有可用的副本(ISR列表)都接受到信息,才算成功。很明显,这种模式的可靠性最高,但是会影响吞吐量。
5、元数据更新
其实还有一个问题没有回答,就是生产者如何知道主题,分区的信息,又是如何知道Leader副本的分布在哪些节点。这些都是通过生产者的元数据更新功能来完成。
元数据是指 Kafka 集群的元数据,这些元数据具体记录了集群中有哪些主题,这些主题有 哪些分区,每个分区的 leader 副本分配在哪个节点上, follower 副本分配在哪些节点上,控制器节点又是哪一个等信息。
这些数据在每个broker上都存在,生产者会挑选一个leastLoadedNode,向该节点发送元素请求进行更新。
四、存储消息
生产者将消息发送到broker(准确的说,是Leader分区所在的broker),broker持久化数据并同步到其他的副本。
1、写入
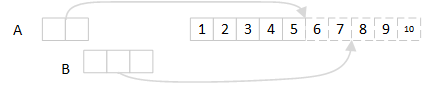
partition分区实质是日志存储文件(log),当接受到写入请求,将数据追加到日志文件的尾部。在写入的时候,确保顺序写入,比如上图中,A消息在B消息之前发送到broker,那么A消息会保存在B消息前。同一个partition中,使用偏移量(offset)记录消息的顺序,偏移量对于消息的消费和回溯非常重要,后面我们会重点介绍。
2、复制
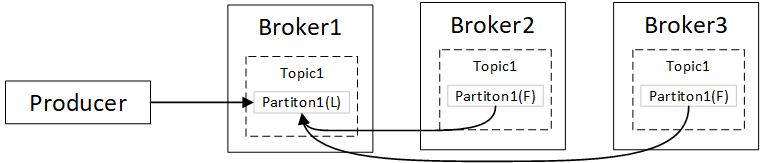
消息首先要写入到分区的Leader副本,Follower副本发起同步请求,复制数据。前面讲了,生产者对于acks有三种配置,acks=1,仅需要Leader写入成功即可,acks=all是需要所有可用的副本写入成功才能返回成功(有点类似mysql的半同步,同步概念)。那什么是可用的副本呢?
ISR(in-sync-replicas),同步副本。Follower副本同步Leader副本的数据是有一定的滞后的,当滞后在一定“容忍”范围,就认为是ISR;如果超出了“容忍”范围,就会从ISR清单中剔除出去,这样就能确保不会因为这些"坏"副本,导致迟迟无法返回响应。这个"容忍"度可以通过以下两个参数配置。
rerplica.lag.time.max.ms表示超过多少ms没有请求,那么leader就有理由认为这个follower是不是挂了。
rerplica.lag.max.messages表示落后多少条消息就会移除。(0.9之后版本将不用该参数了)
ISR列表是动态的,当某个Follower达到“容忍”的范围内,又会重新加入ISR列表。
同步副本个数是一个很重要的监控指标,同步副本数越少,表示该分区的高可用就越低,如果为0,表示所有Follower副本都不"可用",可靠性将无法得到保证。
3、存储与索引
在一个大文件中查找和删除消息是很费时的,kafka会把分区分成若干个片段保存,每个片段可以设置大小,当达到上限,就关闭当前文件,打开一个新的文件。

我们来测算下,比如每个片段大小为1GB,每天每个分区产生10GB的数据,并设置数据保留1天,单个分区保留10个分片,如果单台broker分配的分区个数为100,那就是1000个片段,broker会为分区的每个片段打开一个文件句柄(无论这些分片是不是在读写),就是1000个文件句柄,很可能就突破了linux的打开最大句柄数的限制(默认是1024,对于kafka一般要设置50W+)。所以,分区数不是越多也好,是有限制的。建议单台broker不要超过200个分区,否则会影响性能。
这么多片段文件,如何快速定位呢,比如需要找到分区0的偏移量为100的片段位置,为了解决这个问题,kafka为每个分区维护了一个索引,会把偏移量映射的片段文件保存在索引文件中,通过二分法能快速定位到片段文件。需要注意的是,索引文件也可以切片,每个分片也是一个打开的文件句柄,有会增加打开文件句柄的量。
4、清理
这些片段是不能永久保存的,达到一定的条件,就需要清理。目前主要包括基于时间,基于日志大小,基于日志偏移量三种模式。
1、基于时间模式,检查日志文件中是否有保留时间超过设定的的阀值(log.retention.hours, log.retention.minutes ,log.retention ms三个值配合),符合条件则删除。比如log.retention.hours设置为24,则保留仅1天的片段数据,其他的都删除。注意,活跃的片段(正在写入的片段)是无法删的,以下几种模式也一样。
2、基于日志大小模式,检查片段文件的大小是否超过设定的阀值(通过log.segment.bytes设置单个片段的大小),符合条件则删除。
3、基于日志起始偏移量模式,检查片段文件的偏移量(结束位置)是否小于设置的偏移量阀值,符合条件则删除。
五、消费消息
消费者通过订阅主题,轮询拉取broker的消息进行消费。
1、消费群组
业务的应用服务器为了实现高并发,一般都是集群化部署,每台应用服务器都可看做一个消费者,有些消息我们希望仅被消费一次(类似activemq的队列),比如说订单处理;有些消息则可以被重复消费(类似activemq的主题),比如说商品的价格,消费后放到本地缓存。那kafka是如何满足不同的消费模式呢?那就是消费组。
消费者从属于消费群组,主题的某个分区消息,只能被消费组下的某个消费者消费,某个消费者可已同时消费多个分区消息。由于在写入的时候,就保证了区分消息的唯一性,所以在从属群组的两个消费者不会重复消费到同一消息。
从属不同群组的消费者是没有这个限制,可以对同一主题下的分区消息进行消息。

可以看到,消费者如果大于分区数,那么多余的消费者是无法参与消费的,比如消费者4。
2、轮询拉取
消费者采用的轮询发送poll请求,批量拉取Leader分区消息。消费端和生产端一样,也是通过元数据更新,获取broker,主题,以及分区信息的,就不再详述。
消费者每次拉取的消息数据是可以根据实际情况设置的。
fetch.min.bytes表示一次拉取的最小字节数;
fetch.max.wait.ms表示当消息数据小于最小字节数时,等待的最大时长;
max.partition.fetch.bytes,每个分区返回给消费者的最大字节数。
消费者需要上报当前消费消息的分区偏移量,来记录消费的位置,以便下次从该位置继续消费。上报偏移量实际就是发送_consumer_offset特殊的主题消息,该消息包含每个分区的偏移量,在老的版本保存在zookeeper中,新版本保存在控制器broker中。目前有两种提交偏移量的方式。
1、自动提交,通过设置定时时间(参数auto.commit.interval.ms),自动上报上一次poll的消息的offset,无论该消息是否被处理。这种模式较简单,但是无法保证客户端最后处理消息偏移量和提交的偏移量的一致性。以下图为例:
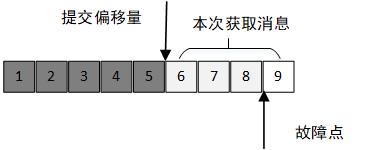
上次提交poll后的提交的偏移量是5,消费者已获取6-9的消息,但是在处理8的时候出现了故障。消费群组通过再均衡,分配其他的消费者继续消费,该消费者就会从6开始获取消息,这样就会导致6-8的消息有重复消费。
2、手动提交,通过调用接口,由客户端程序控制上报的时机,每次消息处理完成后,可以上报一次,最大程度上保证两者偏移量的一致性。
3、负载均衡
一个群组中有多个消费者,那么如何让每个消费者均衡的消费每个分区呢。主要有以下两种策略:
1、Range,该策略将每个主题下的分区平均分给消费者,比如主题A下有三个分区(分区0,分区1,分区2),消费群组包含两个消费者(消费者1,消费者2),那么消费者1分配到分区0,分区2,消费者2分配到分区1。这种策略比较简单,但是缺点也很明显,仅考虑到一个主题下分区均衡,如果群组消费多个主题,就无法保障均衡。
2、RangeRobin,该策略把群组内所有订阅的主题分区,以及所有消费者进行字典排序,通过轮询的方式依次分配给每个消费者,该策略综合考虑所有主题和消费者,最大程度上实现相对均衡。但是也不是最优的,如果消费者订阅的主题不同,那么也存在负载不均的情况。
其他的还有sticky策略,以及自定义策略。
4、再均衡(rebalance)
在消费者变化(正常或者异常退出,或者加入),主题或者分区发送变化时,协调器都会触发再均衡。最常见的情况,是消费者发送变化,比如消费者出现异常,服务在心跳间隔(参数session.timeout.ms)没有收到心跳请求;消费者接受消息后,处理的时间过长,下一次fetch的时间超时了设定阀值(max.poll.interval.ms)等。
rebalance会导致很多问题,包括重复消费,以及消息丢失。重复消费的场景我们在上面已经描述过了,再看下消息丢失的情况。
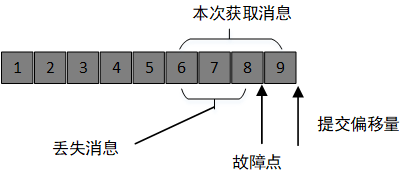
提交的消息偏移量大于客户端实际的处理消息,如图所示,6-8的消息会丢失。
对于重复消费,客户端需要进行幂等性保护;对于消息丢失,通过消息回溯的方式补偿。
一旦发送再均衡,同一消费组内的消费者需要重新协调分配,以便尽量保证公平性,这个过程会有一定的耗时,阻塞kafka的消费,影响吞吐量,所以需要根据场景分析,避免频繁的再均衡。
六、可靠性
在互联网的大型系统中,各业务交互错综复杂,不能因为组件某个节点的故障,导致全网的不可用,可靠性是对组件的基本要求。
kafka的架构设计中处处透露着可靠性的思想。
1、生产消息重发
前面在讲生产消息时,生产者可以通过acks配置实现不同的确认策略,我们说acks=all时,Leader和Follower分区副本都同步完成后, 才能返回确认,可靠性最高。但是无论哪一种策略,都会存在消息发送失败的情况。
如果消息发送失败,生产者会根据错误码以及错误类型进行不同的处理,可以分为可重试异常和不可重试异常两种。
比如对于一些临时性的错误(如网络抖动,leader选举等),生产者会尝试重发,重发的次数和间隔的时间可通过 retries 和 retry.backoff.ms设置,这对于消息的可靠性非常重要,这类称之为可重试异常;
有些机制性错误,比如消息太大,无论重试多少次都无可能解决的,这类称之为不可重试异常。对于这类异常需要进行调整,无法依靠kafka自身的机制解决。
2、分区均衡
分区有多个副本,那么这些副本在broker上如何分布就显得尤为重要,一方面解决读写负载均衡的问题,如果Leader分区不均衡,可能某些broker负载过大,某些broker又过于清闲;另一方面解决可靠性问题,Leader和Follower副本需要分布在不同的节点上,确保broker节点不可用时,转移到其他节点继续服务。
kafka首先对Leader分区副本以及broker进行排序,通过轮询的方式将leader分区均衡的分配到broker上,比如有4个分区(分区0,分区1,分区2,分区3),3个broker节点(brokerA,brokerB,brokerC),那么brokerA将分配分区0,分区3,brokerB将分配分区1,brokerC将分配分区2。
其次对Follower分区副本进行分配,采用Leader分区所在broker+1的方式。比如分区0有两个Follower副本(follower0,follower1),follower0副本将分配到到brokerB,follower1副本将分配到brokerC上,以此类推。
在实际的实施过程中,broker节点会部署不同的机架,分区均衡时,也需要考虑这些因素(设置broker.rack参数)。
3、控制器节点
分区变化时,谁来负责这些分区的均衡呢。在老版本中,是在协调器zookeeper实现,鉴于zookeeper的性能问题,在新版本中增加了控制器节点来实现该功能。
控制器节点其实也是普通的broker节点,只不过增加控制线程,也就是说任何一个broker节点都有资格成为控制器节点。当第一个broker启动后,会尝试到zookeeper注册,如果zookeeper发现还没有控制器,就会创建/controller目录,写入broker相关信息。其他节点启动后,也会尝试注册,但是发现已经被注册过了,就认可其结果。
控制节点负责分区的均衡以及分区的选举,是集群的"大脑",自身的高可用尤其重要。控制节点出现故障,或者网络故障与zookeeper失去联系,zookeeper会发出变更通知,其他的broker通过watch,得到通知后,尝试让自己成为新的控制节点,第一个在zookeeper创建成功的节点将成为新的控制节点,其他的节点将接受到"节点已存在"异常。
新的控制节点将拥有一个数值更大的controller epoch。当故障的控制节点恢复后,不知道已经改朝换代了,可能还认为自己是控制节点,但是其他节点发现其controller epoch较小,会拒绝承认,这样就避免了"脑裂"的情况。
控制节点除了负责分区的均衡,还需要完成其他重要的工作,其中一个就是分区的选举。
4、分区选举
为了确保分区的高可用,kafka对分区采用多副本的模式(默认是3,复制系数可以配置),控制器通过遍历获取每个broker,获取其副本情况。
当某个broker退出集群,该broker节点上的Leader分区副本也将不可用,就需要选举一个新的leader副本接替。前面讲过每个分区维护一个ISR(同步副本)列表,控制节点就会从该列表中挑选一个作为新Leader副本(一般是列表位置的第一个),并通知到其所在的broker以及其他Follower副本,新Leader副本接管读写请求,其他的Follower副本从新的Leader副本上同步。
一切看似柔丝般顺滑,其实暗藏玄机,比如同步副本为0怎么办?
这是就面临了一个两难的选择,如果从非同步副本中选取一个作为新Leader,该副本延迟同步的消息必将丢失;如果不选择新的leader,那么就无法读写,需要等Leader副本恢复,可用性差。
鱼和熊掌不可兼得,没有一个统一最优解决方案,需要结合应用的场景进行选择(设置unclean.leader.election.enable参数)。
就算同步副本不为0,如果生产者没有用acks=all的策略,在分区选举中,也可能会造成消息的丢失。对于可靠性要求高的系统,acks需要设置为all。
5、数据一致性
kafka的数据读写都是在Leader的副本上,这个和其他一些组件(比如zookeeper,mysql,redis)不一致,一般我们认为,读写分离能减轻主节点的负载,那kafka为何不这么做呢?
首先,kafka的基于partition的设计,每个broker均衡分布分区的Leader副本,没有所谓主从节点的概念,使得broker的读写的负载是相对均衡的。
其次,Leader副本读写能确保数据的一致性,follower副本同步有一定的延时性,如果多个消费者从不同的follower读取数据,无法保证数据的一致性。从leader副本消费时,有个高水位偏移量的限制,不能超过这个偏移量,如图所示。
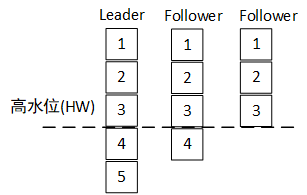
Leader副本以延时最大的Follower的消息偏移量为基准(高水位),作为消费端可消费的最大偏移量。
6、消息回溯
消息写入broker后,会保存一段时间。在这段时间内,如果消费者导致消息丢失(比如消费者过早的提交了偏移量,发送故障,进行rebalance),可以通过发送seek指令到消费者,告诉其从具体的偏移量开始重新消费。
7、小结
所谓可靠性都是相对的,不能简单的说"是"或者"否",在使用场景或者方式的提前下,最大程度提高可靠性。另外,如果一味强调可靠性,那么必定会损失其他方面的性能。
比如acks设置为all,由于Follower同步的延迟性,会影响吞吐量;设置Follower副本数过多,写入时同步延迟增加,同时也会导致打开的文件句柄超限;分区选举时,unclean.leader.election.enable设置为false,可能会导致无法读写;
所以,世间没有统一的招式,没有统一的打法,唯一不变的就是变化,顺势而为,根据不同的场景,要求选择适合自己的策略。
七、高吞吐
kafka是用来做日志收集等大数据流式传递的工具,每秒处理几十万条数据,所以高吞吐是其天然的基因,我们从其设计架构上看如何实现这点的。
1、多分区
将主题的消息分成多个分区,并均衡负载到各个broker节点上,通过横向扩展broker,增加分区的个数,就能大大提升了读写的吞吐。前面我们讲过由于文件句柄的问题,单个broker节点的分区数不能过多;另外分区过多,同步和选举的时间也会拉长。那一个主题下分配多少分区是合适的呢,我们需要综合考虑一下几个因素
1、主题的吞吐量
2、单个broker包含分区数
3、单个分区读写的吞吐量
比如有10个生产者,每个每秒生产100MB的数据,也就是每秒总生产1GB的数据。单个broker写入数据200MB/s,平均分布4个Leader分区,也就是每个分区的写入速度为50MB/s,不考虑带宽的影响,如果不让消息在产生端有积压,需要20分区。再假设每个消费者读取的速率是20MB/s,那就需要有50个消费者,也就是对应50个分区,才能让50个消费者同时读取。综合评估下来,实现1GB/s的读写吞吐量,需要50个分区。
分区数建议提前规划好,无法缩容,只能扩容,且扩容时会带来分区以及消费者的rebalance,对于负载不均的情况,还需要手工调整,成本较高。
2、顺序写入
kafka采用的是追加的方式顺序写入数据,它并没有像其他组件先写入应用缓存,然后刷盘到磁盘,而是直接写入到文件系统(仅依靠操作系统的页面缓存)。

码农做久了,就会产生一些定式思维,比如缓存的读写一定比磁盘的快,多线程一定比单线程性能高,实际上,这些都是有前提条件,或者场景约束的,顺序磁盘写入就比随机内存写入快,而kafka正是顺序写入,另外操作系统的页面缓存也提升了写入速度,所以这个比不是kafka高吞吐的瓶颈。
kafka这么设计目的是减少成本,内存的成本要远远大于磁盘的成本。
3、零拷贝
所谓的零拷贝就是将数据从磁盘文件直接复制到网卡设备中,而不需要经由应用程序转发。

从上图可知,零拷贝可以节省两次拷贝,通过DMA ( Direct Memory Access )技术将文件内容复制到内核模式下的Read
Buffer 中,没有数据被复制到Socket Buffer,仅有包含数据的位置和长度的信息的文件描述符被加到Socket Buffer 中。零拷贝在内核模式下完成数据的传递,效率非常高。
kafka为何能采用零拷贝,这是因为kafka不对消息做任何处理,包括解析,拆包,序列化等,生产出的消息时什么样子,读取的时候也是这个样子,仅做消息的搬运工。
八、总结
本文首先介绍了消息的生产,包括消息创建,分区选择,消息发送和确认。
存储阶段介绍了分区间的数据同步,以及物理的存储方式,消息清理。
消费阶段,包括消息组概念,负载均衡以及再均衡方式。
可靠性方面,包括消息重发,分区均衡和选举,数据一致性以及消息回溯等。
高吞吐方面,包括多分区,顺序写入,零拷贝等。
附录:


