
- 1ATT&CK-T1003-001-操作系统凭据转储:LSASS内存_comsvcs凭据访问
- 2服务器创建git仓库_git创建服务器仓库
- 3neo4j的基本使用_neo4j语法使用
- 4FPGA平台上基于DDS原理的信号发生器设计:Verilog HDL编程实现正弦波、方波、锯齿波和三角波,可调频率幅度_verilog 生成给定频率正弦波
- 5pinocchio计算MPC控制状态方程AB矩阵
- 6基于web农机农业设备在线租赁系统设计与实现
- 7DB-GPT 初体验chat data
- 8机器学习笔记——无监督学习下的k均值聚类
- 9一键解锁本地大型语言模型!Ollama框架让你轻松运行Gemma_ollama gemma win10
- 102024年史上最全的web前端面试题汇总及答案,前端开发好学么_2024年前端面试题
MSGAN用于多种图像合成的模式搜索生成对抗网络---解决模式崩塌问题_对抗生成网络msgan
赞
踩
文章目录
Abstract
大多数条件生成任务在给定单个条件上下文的情况下期望不同的输出。然而,条件生成对抗网络(CGAN)通常关注先验条件信息,而忽略输入噪声矢量,这会导致输出变化。最近解决CGAN模式崩溃问题的尝试通常是特定于任务的,并且计算成本很高。在这项工作中,我们提出了一个简单而有效的正则化项来解决CGAN的模式崩溃问题。该方法显式地最大化生成图像与相应潜在代码之间的距离比,从而鼓励生成器在训练期间探索更多的次要模式。这种模式搜索正则化项很容易适用于各种条件生成任务,无需增加训练开销或修改原始网络结构。我们在三个条件图像合成任务上验证了该算法,包括分类生成、图像到图像的翻译和具有不同基线模型的文本到图像的合成。定性和定量结果都证明了所提出的正则化方法在不损失质量的情况下改善多样性的有效性。
1. Introduction
生成对抗网络(GAN)[8]已被证明可以有效捕获复杂和高维的图像数据,并有许多应用。基于GAN,条件GAN(CGAN)[20]将外部信息作为额外输入。对于图像合成,CGAN可以应用于具有不同条件上下文的各种任务。通过类标签,CGAN可以应用于分类图像生成。对于文本句子,CGAN可以应用于文本到图像的合成[22,29]。对于图像,CGAN已用于图像到图像的翻译[10、11、14、16、31、32]、语义操作[28]和风格转换[15]等任务。
对于大多数条件生成任务,映射本质上是多模式的,即单个输入上下文对应于多个合理的输出。处理多模态的一种简单方法是将随机噪声矢量和条件上下文一起作为输入,其中上下文确定主要内容,噪声矢量负责变化。例如,在狗到猫的图像到图像的翻译任务[14]中,输入的狗图像决定了头部的方向和面部标志的位置等内容,而噪声向量有助于生成不同的物种。然而,CGAN通常存在模式崩溃[8,24]问题,其中生成器仅从单个或少数分布模式生成样本,而忽略其他模式。噪声向量被忽略或影响较小,因为CGAN更注重从高维和结构化的条件上下文中学习。
有两种主要的方法来解决GANs中的模式崩溃问题。许多方法通过引入不同的散度度量[1,18]和优化过程[6,19,24]来关注鉴别器。其他方法使用辅助网络,例如多个生成器[7、17]和附加编码器[2、4、5、25]。然而,在CGAN中对模式崩溃的研究相对较少。最近在图像到图像的翻译任务中进行了一些努力,以提高多样性[10,14,32]。与具有无条件设置的第二类类似,这些方法引入了额外的编码器和损失函数,以鼓励输出和潜在代码之间的一对一关系。这些方法要么需要大量的训练计算开销,要么需要辅助网络,这些网络通常是特定于任务的,不容易扩展到其他框架。
在这项工作中,我们提出了一种模式搜索正则化方法,可以应用于各种任务的CGAN,以缓解模式崩溃问题。给定两个潜在向量和相应的输出图像,我们建议最大化图像之间的距离与潜在向量之间的距离的比率。换句话说,该正则化项鼓励生成器在训练期间生成不同的图像。因此,生成器可以探索目标分布,并增加从不同模式生成样本的机会。另一方面,我们可以用不同生成的样本训练鉴别器,以提供可能被忽略的次要模式的梯度。这种模式搜索正则化方法会产生少量的计算开销,并且可以很容易地嵌入到不同的cGAN框架中,以提高合成图像的多样性。
我们通过对具有不同基线模型的三个条件图像合成任务的广泛评估来验证所提出的正则化算法。首先,对于分类图像生成,我们使用CIFAR-10[12]数据集将所提出的方法应用于DCGAN[21]。其次,对于图像到图像的转换,我们使用facades[3]、maps[11]、Y osemite[31]和cat将拟议的正则化方案嵌入到Pix2Pix[11]和DRIT[14]中⇋狗[14]数据集。第三,对于文本到图像的合成,我们使用CUB-200-2011[27]数据集将StackGAN++[29]与拟议的正则化项合并。我们使用感知距离度量来评估合成图像的多样性[30]。
然而,仅多样性度量不能保证生成图像的分布与真实数据的分布之间的相似性。因此,我们采用了两个最近提出的基于bin的度量[23],统计不同bin的数量(NDB)度量,用于确定由真实数据预先确定的样本落入集群的相对比例,以及Jensen-Shannon散度(JSD)距离,用于测量bin分布之间的相似性。此外,为了验证我们不会以牺牲真实性为代价实现多样性,我们使用弗雷切特初始距离(FID)[9]作为质量度量来评估我们的方法。实验结果表明,所提出的正则化方法可以帮助各种应用中的现有模型在不损失图像质量的情况下实现更好的多样性。图1显示了所提出的正则化方法对现有模型的有效性。
这项工作的主要贡献是:
- 我们提出了一种简单而有效的模式搜索正则化方法来解决CGAN中的模式崩溃问题。
- 这种正则化方案可以很容易地扩展到现有框架中,只需要少量的训练开销和修改
- 我们证明了所提出的正则化方法在三种不同的条件生成任务上的通用性:分类生成、图像到图像的翻译和文本到图像的合成
- 大量实验表明,该方法可以在不牺牲生成图像视觉质量的情况下,促进不同任务的现有模型实现更好的多样性。
- 我们的代码和预先训练的模型可在https://github.com/HelenMao/MSGAN/.
2. Related Work
条件生成对抗网络。
生成对抗网络[1、8、18、21]已广泛用于图像合成。通过对抗性训练,鼓励生成器捕捉真实图像的分布。在GANs的基础上,条件GANs根据各种上下文合成图像。例如,CGAN可以生成以低分辨率图像为条件的高分辨率图像[13],在不同的视觉域之间翻译图像[10、11、14、16、31、32],生成具有所需样式的图像[15],并根据句子[22、29]合成图像。虽然CGAN在各种应用中取得了成功,但现有方法存在模式崩溃问题。由于条件上下文为输出图像提供了强大的结构先验信息,并且具有比输入噪声向量更高的维数,因此生成器倾向于忽略导致生成图像变化的输入噪声向量。因此,生成器容易生成外观相似的图像。在这项工作中,我们旨在解决CGAN的模式崩溃问题。
减少模式崩溃。
一些方法关注具有不同优化过程[19]和散度度量[1,18]的鉴别器,以稳定训练过程。小批量鉴别方案[24]允许鉴别器在整个小批量样本之间而不是单个样本之间进行鉴别。在[6]中,Durugkar等人使用多个鉴别器来解决这个问题。其他方法使用辅助网络来缓解模式崩溃问题。ModeGAN[2]和VEEGAN[25]使用额外的编码器网络在输入噪声矢量和生成的图像之间执行双射映射。开发了多个生成器[7]和权重共享生成器[17],以捕获更多的分布模式。然而,这些方法要么需要大量的计算开销,要么需要修改网络结构,并且可能不容易适用于CGAN。
在CGAN领域,最近已经做出了一些努力[10,14,32]来解决图像到图像翻译任务中的模式崩溃问题。与ModeGAN和VEEGAN类似,引入了额外的编码器,以在生成的图像和输入噪声矢量之间提供双射约束。然而,这些方法需要其他特定于任务的网络和目标函数。额外的组件使方法不太通用,并在训练中产生额外的计算负载。相比之下,我们提出了一个简单的正则化项,该项不产生任何训练开销,并且不需要修改网络结构。因此,该方法可以很容易地应用于各种条件生成任务。
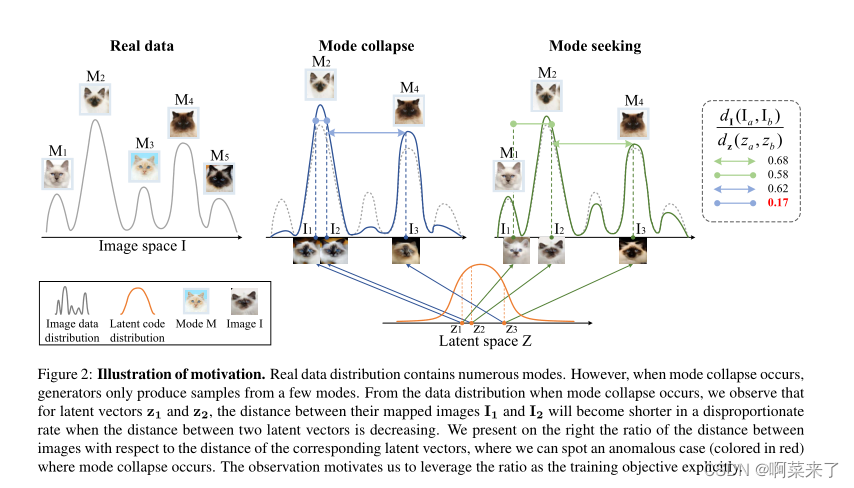
【图2:动机说明。真实数据分布包含多种模式。然而,当模式崩溃发生时,生成器仅从少数模式生成样本。从模式崩溃发生时的数据分布中,我们观察到,对于潜在向量z1和z2,当两个潜在向量之间的距离减小时,其映射图像I1和I2之间的距离将以不成比例的速率缩短。我们在右侧显示了图像之间的距离与相应潜在向量距离的比率,其中我们可以发现模式崩溃发生的异常情况(红色)。这一观察激励我们明确利用该比率作为训练目标。】
3. Diverse Conditional Image Synthesis
3.1. Preliminaries
GANs的训练过程可以表述为一个mini-max问题:鉴别器D通过向真实数据样本分配较高的判别值,并向生成的样本分配较低的判别值来学习成为分类器。同时,生成器G旨在通过合成实际示例来愚弄D。通过对抗训练,来自D的梯度将引导G生成分布类似于真实数据的样本。
GANs的模式崩溃问题在文献中是众所周知的。有几种方法[2、24、25]将缺失模式归因于出现此问题时没有惩罚。由于所有模式通常具有相似的判别值,因此通过基于梯度下降的训练过程,可能会青睐较大的模式。另一方面,很难从次要模式生成样本。
CGAN中的模式缺失问题变得更严重。一般来说,与噪声向量相反,条件语境是高维和结构化的(例如图像和句子)。因此,生成器可能会关注上下文,而忽略噪声向量,这说明了多样性。
3.2. Mode Seeking GANs
在这项工作中,我们建议从生成器的角度来缓解缺失模式问题。图2说明了我们方法的主要思想。将来自潜在代码空间z的潜在向量z映射到图像空间I。当发生模式崩溃时,将映射的图像折叠为几个模式。此外,当两个潜在代码z1和z2更接近时,映射图像I1=G(c,z1)和I2=G(c,z2)更有可能折叠到相同模式。为了解决这个问题,我们提出了一个模式搜索正则项,以直接最大化G(c,z1)和G(c,z2)之间的距离与z1和z2之间的距离的比率,
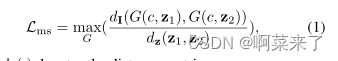
其中d∗(·)表示距离度量。
正则化项为训练CGAN提供了一个良性循环。它鼓励生成器探索图像空间,并增加生成次要模式样本的机会。另一方面,鉴别器被迫关注从次要模式生成的样本。图2显示了一种模式崩溃情况,其中两个闭合样本z1和z2映射到同一模式M2。然而,通过提出的正则化项,z1映射到I1,它属于未探索模式M1。通过对抗机制,生成器将有更好的机会在以下训练步骤中生成M1的样本。
如图3所示,通过将建议的正则化项附加到原始目标函数,可以很容易地与现有的CGAN集成。
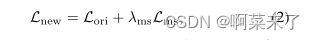
其中,Lori表示原始目标函数,λms表示控制正则化重要性的权重。在这里,Lori可以作为一个简单的损失函数。例如,在分类生成任务中,
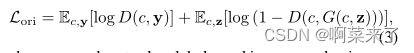
其中c、y、z分别表示类别标签、真实图像和噪声向量。在图像到图像的翻译任务[11]中,
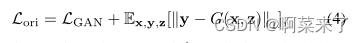
其中x表示输入图像,LGAN是典型的GAN损耗。Lori可以是来自任何任务的任意复杂目标函数,如图3(b)所示。我们将提出的方法命名为模式搜索GANs(MSGANs)。
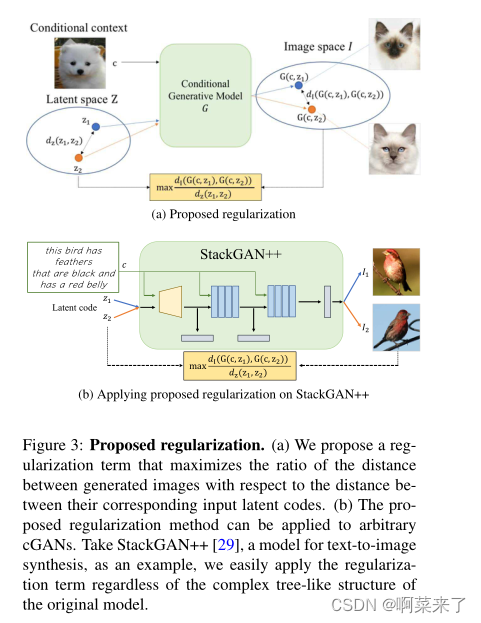
【图3:拟议的正则化。(a) 我们提出了一个正则化项,使生成的图像之间的距离与其相应的输入潜在代码之间的距离的比率最大化。(b) 所提出的正则化方法可以应用于任意CGAN。以StackGAN++[29]为例,这是一个用于文本到图像合成的模型,无论原始模型的复杂树状结构如何,我们都可以轻松地应用正则化项。】
4. Experiments
我们通过广泛的定量和定性评估来评估所提出的正则化方法。我们应用MSGANs到三个具有代表性的条件图像合成任务(分类生成、图像到图像的翻译和文本到图像的合成)到基线模型。注意,我们使用所提出的正则化项扩充了原始目标函数,同时保持了原始网络结构和超参数。我们使用L1范数距离作为dI和dz的距离度量,并在所有实验中设置超参数λms=1。更多实施和评估细节,请参阅补充材料。
4.1. Evaluation Metrics
我们使用以下指标进行评估。FID。为了评估生成图像的质量,我们使用FID[9]通过初始网络提取的特征来测量生成的分布与真实分布之间的距离[26]。FID值越低,生成的图像质量越好。
LPIPS。为了评估多样性,我们在[10,14,32]之后使用LPIP[30]。LIPIS测量生成样本之间的平均特征距离。LPIPS分数越高,生成的图像之间的多样性越好。
NDB和JSD。测量真实图像和生成图像之间距离的相似性。
我们采用了[23]中提出的两种基于bin的指标,NDB和JSD。这些指标评估生成模型的模式缺失程度。在[23]之后,首先使用K-均值将训练样本聚类到不同的箱中,这些箱可以被视为真实数据分布的模式。然后将生成的每个样本分配到其最近邻居的箱子。我们计算训练样本和合成样本的仓位比例,以评估生成的分布和真实数据分布之间的差异。然后计算非负分布分数和bin比例的JSD来测量模式崩溃。较低的NDB分数和JSD意味着通过拟合更多模式,生成的数据分布更接近真实数据分布。有关更多详细信息,请参阅[23]。
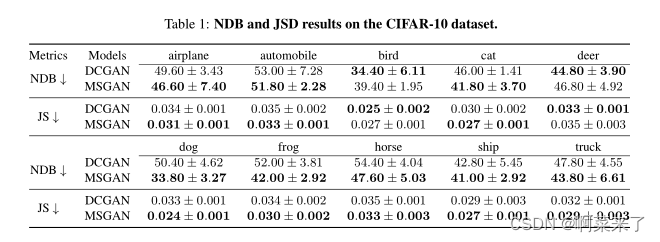
【表1:CIFAR-10数据集上的NDB和JSD结果。】

4.2. Conditioned on Class Label
我们首先在分类生成上验证了所提出的方法。在分类生成中,网络将类标签作为条件上下文来合成不同类别的图像。我们将正则化项应用于基线框架DCGAN[21]。
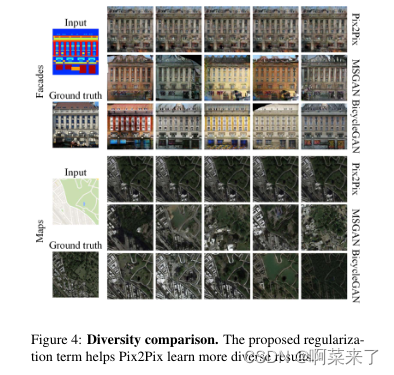
【图4:多样性比较。提出的正则化项有助于Pix2Pix学习更多不同的结果。】
我们在CIFAR-10[12]数据集上进行了实验,该数据集包括十类图像。由于CIFAR-10数据集中的图像大小为32×32,上采样会降低图像质量,因此我们在本任务中不计算LPIP。表1和表2给出了NDB、JSD和FID的结果。MSGAN在保持图像质量的同时,缓解了大多数类中的模式崩溃问题。
4.3. Conditioned on Image
图像到图像的翻译旨在学习两个视觉域之间的映射。以源域的图像为条件,模型试图合成目标域中的响应图像。尽管图像到图像翻译任务具有多模态性质,但早期工作[11,31]放弃了噪声向量,并执行了一个图恩映射,因为在训练过程中很容易忽略潜在代码,如[11,32]所示。为了实现多模式,最近的几次尝试[10、14、32]引入了额外的编码器网络和目标函数,以在潜在代码空间和图像空间之间施加双射约束。为了证明其可推广性,我们使用配对训练数据将所提出的方法应用于单峰模型Pix2Pix[11],并使用未配对图像将多峰模型DRIT[14]应用于该模型。
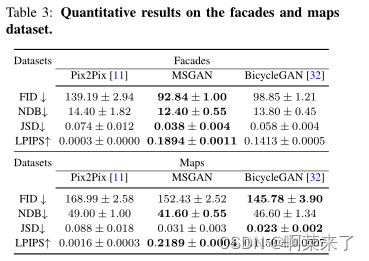
【表3:facades和maps数据集的定量结果】
4.3.1 Conditioned on Paired Images
我们将Pix2Pix作为基线模型。我们还将MSGAN与BicycleGAN[32]进行了比较,后者通过成对的训练图像生成不同的图像。为了公平比较,所有方法中的生成器和鉴别器的架构都遵循BicycleGAN[32]中的架构。

【图5:多样性比较。我们将MSGAN与DRIT on the dog to cat、cat to dog和winter to summer翻译任务进行了比较。我们的模型在DRIT上产生更多不同的样本】
我们在facades和maps数据集上进行了实验。与Pix2Pix相比,MSGAN在所有指标上都得到了一致的改进。此外,MSGAN与BicycleGAN具有相似的多样性,后者应用了额外的编码器网络。图4和表。3分别演示定性和定量结果。
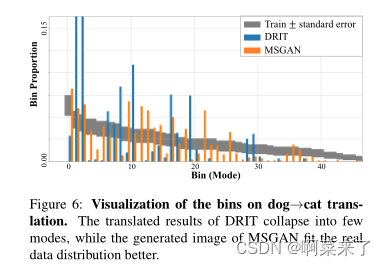
【图6:狗身上箱子的可视化→cat翻译。DRIT的转换结果塌陷为几个模式,而MSGAN生成的图像更符合真实数据分布。】
4.3.2 Conditioned on Unpaired Images
我们选择DRIT[14],这是一种最先进的框架,可以通过非配对训练生成各种图像数据,作为基线框架。虽然DRIT在大多数情况下会合成不同的图像,但在一些具有挑战性的形状变化情况下(例如,猫和狗之间的翻译)会发生模式崩溃。为了证明该方法的鲁棒性,我们对保形Y osemite(夏季)进行了评估⇋温特[31]数据集和猫⇋需要形状变化的狗[14]数据集。

【图7:多样性比较。我们在CUB-200-2011文本图像合成数据集上展示了StackGAN++[29]和MSGAN的示例。当文本代码固定时,MSGAN中的潜在代码有助于生成更多不同的鸟类外观和姿势以及不同的背景。】
如表所示的定量结果。4.MSGAN在两个数据集的所有指标上都优于DRIT。尤其是在挑战性的猫身上⇋在dog数据集上,MSGAN获得了大量的多样性增益。从统计角度来看,我们在图6中可视化了狗到猫翻译的bin比例。该图显示了DRIT的严重模式崩溃问题以及拟议正则化项的实质性改进。定性地说,图5表明,MSGAN在不损失视觉质量的情况下发现了更多模式。
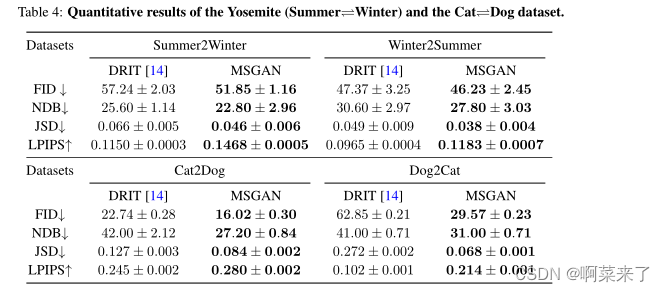
【表4:Y osemite(夏季)的定量结果⇋冬天)和猫⇋狗数据集。】
4.4. Conditioned on Text
文本到图像合成的目标是生成以文本描述为条件的图像。我们使用CUB200-2011[27]数据集在StackGAN++[29]上集成了拟议的正则化项。为了提高多样性,StackGAN++引入了条件增强(CA)模块,将文本描述重新参数化为高斯分布的文本代码。我们没有将正则化项应用于语义有意义的文本代码,而是将重点放在利用从中随机采样的潜在代码上先验分布。然而,为了公平比较,我们在两种设置下评估了MSGAN和StackGAN++:1)在不固定文本描述的文本代码的情况下执行生成。在这种情况下,文本代码还为输出图像提供变体。2) 使用固定文本代码执行生成。在此设置中,排除了文本代码的影响。
桌子5给出了MSGAN和StackGAN++之间的定量比较。MSGAN改进了StackGAN++的多样性,并保持了视觉质量。为了更好地说明潜在代码对多样性所起的作用,我们对固定文本代码进行了定性比较。在此设置中,我们不考虑CA产生的多样性。图7说明了StackGAN++的潜在代码对图像变化的影响较小。相反,MSGAN的潜在代码导致了鸟类的各种外观和姿势。
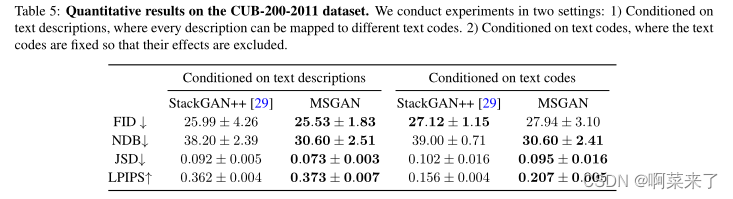
【表5:CUB-200-2011数据集的定量结果。我们在两种环境下进行实验:1)以文本描述为条件,其中每个描述可以映射到不同的文本代码。2) 以文本代码为条件,其中文本代码是固定的,以便排除其影响。】

【图8:MSGAN中两个潜在代码之间的线性插值。图像合成的结果是狗到猫翻译和文本到图像合成中两个潜在代码之间的线性插值。】
4.5. Interpolation of Latent Space in MSGANs
我们在两个给定的潜在代码之间执行线性插值,并生成相应的图像,以更好地了解MSGAN如何利用潜在空间。图8显示了dogto-cat翻译和文本到图像合成任务的插值结果。在狗到猫的翻译中,我们可以看到皮毛颜色和图案随着潜在向量平滑变化。在文本到图像合成中,随着潜在代码的变化,鸟的方向和立足点的外观都会逐渐变化。
5. Conclusions
在这项工作中,我们在生成器上提出了一个简单但有效的模式搜索正则化项,以解决CGAN中的模型崩溃问题。通过最大化生成图像之间相对于相应潜在代码之间的距离,正则化项迫使生成器探索更多次要模式。所提出的正则化方法可以很容易地与现有的cGANs框架集成,而不需要增加训练开销和修改网络结构。我们证明了该方法在三种不同的条件生成任务上的通用性,包括分类生成、图像到图像的翻译和文本到图像的合成。定性和定量结果均表明,提出的正则化项有助于基线框架在不牺牲生成图像视觉质量的情况下提高多样性。
参考
致谢。这项工作得到了美国国家科学基金会职业基金会(1149783)的部分支持,V erisk、Adobe和NEC的捐赠,中国国家基础研究计划(973计划,2015CB351800),中国国家自然科学基金会(61632001),以及北京大学高性能计算平台,对此表示感谢。我们还感谢NVIDIA通过NV AIL计划慷慨提供DGX-1超级计算机和支持。
References
[1] Martin Arjovsky, Soumith Chintala, and Léon Bottou.
Wasserstein generative adversarial networks. In ICML,
2017.
[2] Tong Che, Y anran Li, Athul Paul Jacob, Y oshua Bengio,
and Wenjie Li. Mode regularized generative adversarial net-
works. In ICLR, 2017.
[3] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo
Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe
Franke, Stefan Roth, and Bernt Schiele. The cityscapes
dataset for semantic urban scene understanding. In CVPR,
2016.
[4] Jeff Donahue, Philipp Krähenbühl, and Trevor Darrell. Ad-
versarial feature learning. In ICLR, 2017.
[5] Vincent Dumoulin, Ishmael Belghazi, Ben Poole, Olivier
Mastropietro, Alex Lamb, Martin Arjovsky, and Aaron
Courville. Adversarially learned inference. In ICLR, 2017.
[6] Ishan Durugkar, Ian Gemp, and Sridhar Mahadevan. Gener-
ative multi-adversarial networks. In ICLR, 2017.
[7] Arnab Ghosh, Viveka Kulharia, Vinay Namboodiri,
Philip H.S. Torr, and Puneet K. Dokania. Multi-agent di-
verse generative adversarial networks. In CVPR, 2018.
[8] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing
Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and
Y oshua Bengio. Generative adversarial nets. In NIPS, 2014.
[9] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner,
Bernhard Nessler, and Sepp Hochreiter. GANs trained by
a two time-scale update rule converge to a local nash equi-
librium. In NIPS, 2017.
[10] Xun Huang, Ming-Y u Liu, Serge Belongie, and Jan Kautz.
Multimodal unsupervised image-to-image translation. In
ECCV, 2018.
[11] Phillip Isola, Jun-Y an Zhu, Tinghui Zhou, and Alexei A.
Efros. Image-to-image translation with conditional adver-
sarial networks. In CVPR, 2017.
[12] Alex Krizhevsky. Learning multiple layers of features from
tiny images. Technical report, Citeseer, 2009.
[13] Christian Ledig, Lucas Theis, Ferenc Huszár, Jose Caballero,
Andrew Cunningham, Alejandro Acosta, Andrew Aitken,
Alykhan Tejani, Johannes Totz, Zehan Wang, and Wenzhe
Shi. Photo-realistic single image super-resolution using a
generative adversarial network. In CVPR, 2017.
[14] Hsin-Ying Lee, Hung-Y u Tseng, Jia-Bin Huang, Ma-
neesh Kumar Singh, and Ming-Hsuan Y ang. Diverse image-
to-image translation via disentangled representations. In
ECCV, 2018.
[15] Chuan Li and Michael Wand. Precomputed real-time texture
synthesis with markovian generative adversarial networks. In
ECCV, 2016.
[16] Ming-Y u Liu, Thomas Breuel, and Jan Kautz. Unsupervised
image-to-image translation networks. In NIPS, 2017.
[17] Ming-Y u Liu and Oncel Tuzel. Coupled generative adversar-
ial networks. In NIPS, 2016.
[18] Xudong Mao, Qing Li, Haoran Xie, Raymond YK, Zhen
Wang, and Stephen Paul Smolley. Least squares generative
adversarial networks. In ICCV, 2017.
[19] Luke Metz, Ben Poole, David Pfau, and Jascha Sohl-
Dickstein. Unrolled generative adversarial networks. In
ICLR, 2017.
[20] Mehdi Mirza and Simon Osindero. Conditional generative
adversarial nets. arXiv preprint arXiv:1411.1784, 2014.
[21] Alec Radford, Luke Metz, and Soumith Chintala. Unsuper-
vised representation learning with deep convolutional gener-
ative adversarial networks. In ICLR, 2016.
[22] Scott Reed, Zeynep Akata, Xinchen Y an, Lajanugen Lo-
geswaran, Bernt Schiele, and Honglak Lee. Generative ad-
versarial text to image synthesis. In ICML, 2016.
[23] Eitan Richardson and Y air Weiss. On GANs and GMMs. In
NIPS, 2018.
[24] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki
Cheung, Alec Radford, and Xi Chen. Improved techniques
for training GANs. In NIPS, 2016.
[25] Akash Srivastava, Lazar V alkoz, Chris Russell, Michael U.
Gutmann, and Charles Sutton. VEEGAN: Reducing mode
collapse in GANs using implicit variational learning. In
NIPS, 2017.
[26] Christian Szegedy, Wei Liu, Y angqing Jia, Pierre Sermanet,
Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent
V anhoucke, and Andrew Rabinovich. Going deeper with
convolutions. In CVPR, 2015.
[27] Catherine Wah, Steve Branson, Peter Welinder, Pietro Per-
ona, and Serge Belongie. The caltech-ucsd birds-200-2011
dataset. Technical Report CNS-TR-2011-001, California In-
stitute of Technology, 2011.
[28] Ting-Chun Wang, Ming-Y u Liu, Jun-Y an Zhu, Andrew Tao,
Jan Kautz, and Bryan Catanzaro. High-resolution image syn-
thesis and semantic manipulation with conditional GANs. In
CVPR, 2018.
[29] Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiao-
gang Wang, Xiaolei Huang, and Dimitris Metaxas. Stack-
GAN++: Realistic image synthesis with stacked generative
adversarial networks. TPAMI, 2018.
[30] Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shecht-
man, and Oliver Wang. The unreasonable effectiveness of
deep features as a perceptual metric. In CVPR, 2018.
[31] Jun-Y an Zhu, Taesung Park, Phillip Isola, and Alexei A.
Efros. Unpaired image-to-image translation using cycle-
consistent adversarial networks. In ICCV, 2017.
[32] Jun-Y an Zhu, Richard Zhang, Deepak Pathak, Trevor Dar-
rell, Alexei A. Efros, Oliver Wang, and Eli Shechtman.
Toward multimodal image-to-image translation. In NIPS,
2017.


