
- 1面试题:HTTP请求和响应(详细解析)
- 2Yarn集群架构和工作原理
- 3druid数据库密码加密_druid加密
- 4排序算法(4)之快速排序(1)
- 5python 爬虫——有道翻译_python爬虫有道翻译
- 6Linux 软件管理 YUM管理工具 配置本地YUM源_本地yum源iso文件存放在哪里
- 7AI创作教程之Stable Diffusion 与Photoshop融合使用(含安装方法)_stable diffusion ps
- 8【DL】YOLO_yolo是回归
- 9OpenSSL 3.x爆出漏洞,如何妥善应对?_openssl 安全漏洞(cve-2023-3817)
- 10docker 部署 redis ,并使用rdm连接redis_redis rdm
大模型训练加速之FlashAttention系列:爆款工作背后的产品观
赞
踩
知乎:方佳瑞
原文:https://zhuanlan.zhihu.com/p/664061672
纯学术分享,侵删
FlashAttention(FA)是一系列针对Transformer模型训练和推理加速方案。自从发布以来,历经了多次迭代,并借着其节省显存、加速计算、使用简单的特性,目前已经是大模型训练必备之良药。FA的论文,一年多就有242个引用,作为一个做底层优化的论文,也是前无古人了。
不过仔细研究背后的历史,你会发现FA没有任何没有独特的创新,甚至某G字大厂还更早公开过一模一样的工作,从某种角度来说FA有抄袭洗稿的嫌疑。FA的爆红出圈的背后,究竟隐藏着什么不为人知的秘密?是人性的扭曲,还是社区的沦丧。本文带你走进FlashAttention的世界,一起解密爆款AI Infra工具背后的故事。
一、产品思维成就爆款
本文先分析一下FA成功的原因,然后介绍一下技术细节。
首先,FA的发展线大概经历如下几个重要里程碑:
2022.6 FA最初版本arXiv文章(https://arxiv.org/abs/2205.14135v1)公开。
2022.7 使用OpenAI Triton实现的FA发布。
2022.11 MeurIPS 2022收录了 FA v1的论文,这个工作也出现在ICML Workshop中。FLASHATTENTION: Fast and Memory-Efficient Exact Attention with IO-Awareness(https://proceedings.neurips.cc/paper_files/paper/2022/file/67d57c32e20fd0a7a302cb81d36e40d5-Paper-Conference.pdf)
2022.12 Megatron-LM支持FA v1 [PR link] (https://github.com/NVIDIA/Megatron-LM/commit/d693034ecfb6ce62fbfe168004682dccee471f8c)。
2022.3 PyTorch 2.0集成FA。
2023.7 FA v2版本发布,更高的FLOPs利用率。Flashattention-2: Faster attention with better parallelism and work partitioning(https://arxiv.org/abs/2307.08691)
2023.10 Flash Decoding发布,针对长序列的推理。Flash-Decoding for long-context inference(https://crfm.stanford.edu/2023/10/12/flashdecoding.html)
去年我和身边同事说过,FlashAttention是我个人评选的2022年Infra类最佳的工作。在电影《死亡诗社》中,传统教科书中评判诗歌好坏的方式是画一个坐标轴,X轴是艺术性,Y是主题重要性,一首诗歌多优秀是它覆盖的面。类似方法,如果评价一个AI场景中”加速“类的工作,X轴是它的使用广泛性,Y轴是使用它带来的加速比,我想FA是一个非常优秀的工作。金杯银杯不如百姓的口碑,FA之所以被大家广泛使用,其本质原因是产品能力的胜利。
从优化技术角度讲,FA采用的方法并不新颖,本质是对矩阵连乘问题进行定制化的的Tiling+重计算。同类的工作其实很多:一方面,这个经典并行问题是各种AI Compiler和JIT技术,比如Halide、TVM、torch.compile等,的射程范围之内的,甚至它们可以做到对矩阵维度参数泛化性更强。另一方面,xformers等精细的Kernel Fusion的技术也早已有之,和它们相比FA v1版本效率也并不是绝对最高的。
FA为何脱颖而出,成为训练场景下Multihead Attention(MHA)实现的事实标准,有以下几个原因。
1、简单易用:微信之父张小龙说过,把用户体验做到极致就是创新。FA使用非常简单,用户不需要了解任何GPU有关的细节,只需要pip install安装,用python替换掉原始的Multihead Attention代码,半个小时就能拿到显存和速度收益。这种好事,何乐而不为呢?假设FA要求用户本地编译CUDA代码,我相信会劝退90%用户,比如我无法理解Megatron-LM安装时候花五分钟本地编译cuda kernels的行为。
2、聚焦头部需求:与其一开始就充分考虑各种长尾需求,不如先把头部需求做到极致。FA把自己定位在面向特定型号GPU大模型训练框架的插件,只做MHA的正反向的实现。在2022年时间点,随着序列变长,MHA训练的内存和计算增长问题首当其冲。尽管算子优化在推理场景做是最顺手的,FA发布却只针对训练,从现在来看,这是很必要的,如果长序列模型训练不出来,哪有推理可言。而且,FA初始版本对于参数范围、GPU型号都有限制,不过作为一个MVP把最主流需求满足,长尾需求慢慢解决都来得及。
3、拥抱开源生态:Online Softmax+Tiling+Recompute几个核心技术都不是FA原创的。Google Research在2021年12月就有一个和FA一模一样的工作叫memory-efficient-attention(论文链接贴在下面)。看完这篇论文,你甚至说FA抄袭都不为过。可为什么后来大家只知FA,而不知MEA?我认为原因在拥抱开源力度的差距,MEA论文放出来时候没有一个官方开源实现,论文也是汇报的Jax实现结果,让大家觉得只是Google内部黑科技而已。而FA的官方PyTorch实现代码和论文一起放出来,和现有生态Megatron-LM完美兼容,易用性配合出色的效果自带传播属性。值得玩味的是,2022年早些时候MAE也被集成到PyTorch xformers项目里了,但大众认知里MHA优化还是FA先做的,MEA论文引用只有区区33个,而FA却有242个,这或许来源于开源那一刻的蝴蝶效应。最后,一个好名字对产品很重要,MEA听起来就很难记忆,而且没有体现它fast的特征,而Flash这个词就更能抓住人的记忆点。值得一提的是,在2023年3月和FA同时作为在2.0版本的功能发布。
Self-attention Does Not Need O(n^2) Memory (https://arxiv.org/abs/2112.05682)
4、保持更新:开源如逆水行舟,不进则退,FA没有发布即巅峰,不信可以看一下Dao-AILab(https://github.com/Dao-AILab/flash-attention)的Contributors变化曲线,作者一年多时间不断在commit新的代码。FA V2里也体现了作者对社区的改进的关注,比如对MQA、MGA、Mask等需求的支持相对比较及时,让用户感知到这个Library一直与时俱进很重要。
成功的产品都是相似的,失败的产品确实各有各的失败。聚焦主流需求、极致使用体验、出色的实用效果、兼容开源生态,让FA在大模型训练Infra这个极卷的红海领域里面成为爆品工作。
最后聊一聊FA的核心开发者Tri Dao,他去年刚博士毕业于Standford,之前一直做核方法之类的ML算法研究,发的都是NeurPS、ICLR会议,并不是Infra背景,FA似乎是他的第一个跨界工作。他博士毕业后作为togethercompute的首席科学家,最近要加入普林斯顿计算机系做助理教授。影响力如此大的AI Infra工作,是算法研究者跨界的结果,其背后原因值得做MLSys从业者深思。
二、FA学习路线
对FA技术细节解读很多,在知乎上有很多解读,比如这个问题下有很多非常好的答案:
FlashAttention 的速度优化原理是怎样的? (https://www.zhihu.com/question/611236756)
用户并不需要了解FA细节也可以很容易把FA当黑盒使用,这再次说明了FA产品设计的很好,把复杂度留给了自己,把简单交给了用户。但对于关注底层同学,还是需要好好掌握FA原理,从而进行二次开发和进一步优化工作。
我建议把FA设计和实现分开学习,FA迭代了三个版本了,而且除了Tri Dao维护的官方版本,还有Triton、PyTorch等版本实现。对于FA的设计思路,2023年我的建议是不要去读FA V1论文了,推荐学习路线:
1. 学习Online Softmax
Online normalizer calculation for softmax(https://arxiv.org/abs/1805.02867)
2. 看FlashAttention-2论文。因为FlashAttention V1的关键设计在V2中被推翻了,FA V2论文也介绍了FA V1。
3. 看Flash Decoding(不在本文介绍范围内)
我下面按照这个顺序,介绍FA的技术要点。这里尽量避免过分陷入细节中,因此不会过度出现复杂的伪代码和公式。
三、FA技术细节
3.1 问题定义
FA把优化目标是单个Head的Attention计算内,N是seqence length长度、d是hidden dimension大小。输入是Q、K、V 三个矩阵,输出是一个attention output矩阵O
三个矩阵,输出是一个attention output矩阵O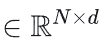 。
。
正向传播公式如下:
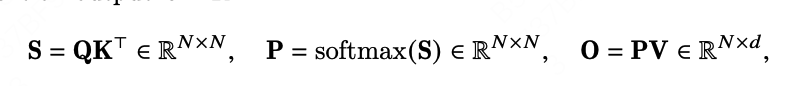
反向传播公式如下,dO :
:
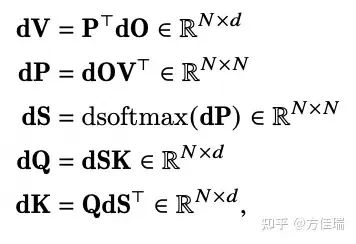
正向反向中,如果没有softmax的化,就是三个矩阵的连续乘法,如上公式所示,正向计算 (反向计算
(反向计算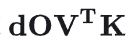 和
和 )。正向传播的优化方法在反向同样适用,因此只介绍正向就足够了。下图中间展示FA的对矩阵Tiling计算方法,如果没有softmax的话,我们可以把Q,K,V沿着N(seqence length维度)切成块,算完一块Q和一块K^T之后,立刻和一块V进行矩阵矩阵乘法运算(GEMM)。一方面,避免在HBM和SRAM中移动P矩阵了,另一方面,P矩阵也不需要被显式分配出来,消除了O(N^2) HBM存储的开销,从而达到了加速计算和节省显存的效果。
)。正向传播的优化方法在反向同样适用,因此只介绍正向就足够了。下图中间展示FA的对矩阵Tiling计算方法,如果没有softmax的话,我们可以把Q,K,V沿着N(seqence length维度)切成块,算完一块Q和一块K^T之后,立刻和一块V进行矩阵矩阵乘法运算(GEMM)。一方面,避免在HBM和SRAM中移动P矩阵了,另一方面,P矩阵也不需要被显式分配出来,消除了O(N^2) HBM存储的开销,从而达到了加速计算和节省显存的效果。
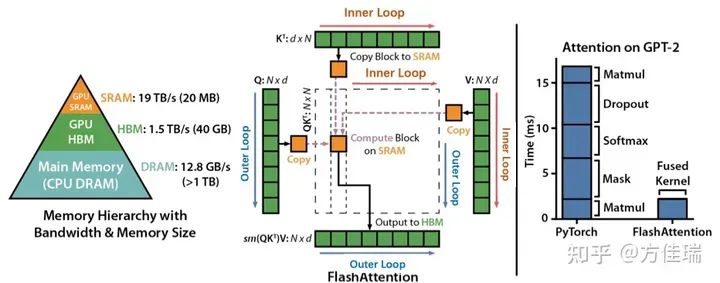
如果没有Softmax,那TVM、Halide之类的编译优化优化工具解决这个问题是是驾轻就熟的,如何对矩阵进行Tiling可以优化的明明白白。
可是麻烦出现在Softmax!Softmax需要对完整的QK^T结果矩阵(图上虚线部分正方形)沿着Inner Loop维度进行归一化。Softmax需要全局的max和sum结果才能scale每一个元素,因此本地算出一块QK^T的结果还不能立刻和V进行运算,还要等同一行的后面的QK^T都算完才能开始,这就造成依赖关系,影响计算的并行。
3.2 Online Softmax
为了能够并行计算Softmax,文章使用了Online Softmax的技巧。这个技巧simple but effective,值得我们单开一个小节,花5min时间理解其精髓。
Online normalizer calculation for softmax
Naive的Softmax公式
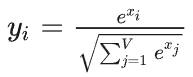
算法流程如下,需要两个循环,先算分母,再scale每一个元素。

但是,line 3指数相加容易浮点溢出,所以Safe Softmax需要把每个元素减去所有元素最大值
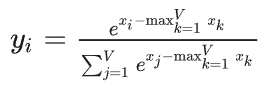
,算法流程如下,需要三层循环,分别求max,sum,然后scale每一个元素。

三个循环需要从内存读写4次向量。因此,下面算法用一个循环同时计算了最大值m和归一化项d,它将Softmax函数评估的内存访问从4减少到每个向量元素的3次。它用前一个迭代的d和当前m,计算当前迭代的m。



3.3 FA的online softmax应用
Online softmax可以打破之前必须先算完一整行的QK^T结果,再和V相乘的依赖关系。算出local softmax结果立刻和V的分块运算,后面再通过乘系数矫正即可。

有了online softmax + tiling,我们就可以按照outer loop切分,row-wise地并行地执行图1的流程。
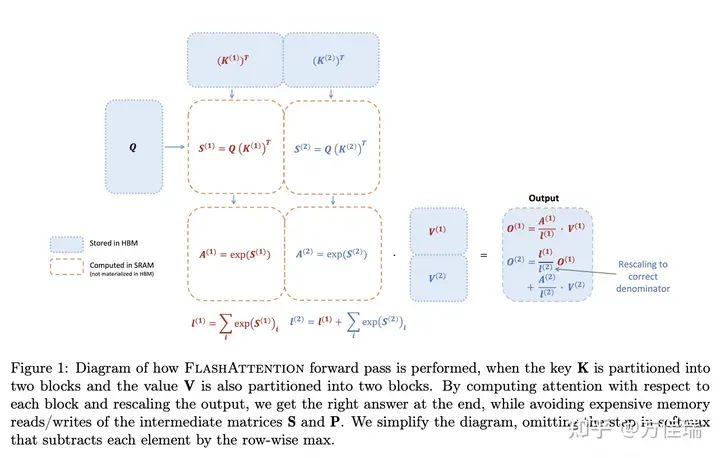
3.4 反向重计算
回顾之前反向计算的一组公式,第一行计算dV需要P矩阵,而正向计算时FA不会存储P,在反向时重计算P的值来节省内存。这个方法就是MXNet提出的经典activation checkpointing技术。
3.5 FA V2其他优化
今年7月发布的V2版本是在V1基础上融合了社区的一些改进,实现了FLOPs利用率的飞跃。
我觉得V2最重要的提升点是参考Phil Tillet的Tirton版本,更改了Tiling循环的顺序,也就是笔者本文图1的效果。V1版本循环顺序设计是outer和inner loop和图1反过来,在outer loop扫描时做softmax的规约,这导致outer loop必须在一个thread block里才能共享softmax计算中间结果的信息,从而只能对batch * head维度上以thread block为粒度并行切分。V2中调换了循环顺序,使outer loop每个迭代计算没有依赖,可以发送给不同的thread block并行执行,也就是可以对batch* head* sequence三层循环以thread block为粒度并行切分,从而显著增加GPU的吞吐。反向遵循同样的原理,不要把inner loop放在softmax规约的维度,因此正向反向的循环顺序是不同的。
说实话,我看V1论文中原始图1就觉得循环顺序很不合理,我盯着循环执行的zigzag顺序图看了一下午,百思不得其解。现在FA github readme里还不把这个图改过来,有点说不过去。另外,个人推测V2性能最大的提升就是来源是来自这个循环顺序的调换,Tri Dao大佬把OpenAI Triton的作者Phil Tillet挂在coauthor位置一点也不过分。所以,看到很多报道FA V2的新闻都用“斯坦福博士一己之力让Attention提速9倍!XXX“的标题,细心的读者会觉得比较扎心。
随着循环顺序调换之后,一个thread block内warps粒度的划分也需要改进,作者把V1版本沿着K切分共享Q,改为沿着Q切分共享K。
另外作者做了提取公因式数学变换,减少了一些non-matmul FLOPs,调优了thread block size。最终更达到了最优情况下72% A100 FLOPs利用率的效果。
写到这,文章有点长了,笔者已经写不动了,对于推理的Flash Decoding优化我今后再单开一篇文章解读。
总结
FlashAttention是近一年来影响力最大的训练框架层加速工作了。它爆红出圈,算法工程师几乎人尽皆知,人皆可用。可是,FA的优化方法并没有任何创新性可言,它爆红的背后是产品设计上的胜利。聚焦主流需求、极致使用体验、出色的实用效果、兼容开源生态,让FA在大模型训练Infra这个极卷的红海领域里面成为爆品工作。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

