
- 1十七、网上商城项目(1)_网上商城 项目
- 2本地图形客户端查看git提交历史 使用 TortoiseGit_tortisegit查看历史提交记录
- 3通俗易懂的KMP算法(C++)_kmp算法c++
- 4排序算法与复杂度介绍
- 5测试阶段与测试技术(一)概述_测试阶段技术。
- 6传神论文中心|第11期人工智能领域论文推荐_are long-llms a necessity for longcontext tasks gi
- 7python课设可视化答辩问题_浅析python 可视化
- 8Transfomer-学习笔记_transfomer 同时输入多少个词向量
- 9数据库-ElasticSearch入门(索引、文档、查询)_http获取索引的所有文档(1)_elasticsearch 获取索引
- 10YARA字符串匹配_yara strings
【数据结构与算法】04 哈希表 / 散列表 (哈希函数、哈希冲突、链地址法、开放地址法、SHA256)_hashmap 开放地址法与链表法
赞
踩
一种很好用,很高效,又一学就会的数据结构,你确定不看看?
一、哈希表 Hash Table
莫慌,每个概念都很好理解。
1.1 核心概念
哈希表(Hash Table),也称为散列表,是一种数据结构,用于存储键值对(key-value pairs)。
键值对是一种数据结构,用于将键(key)与对应的值(value)相关联。在键值对中,键用于唯一标识或索引值,而值则表示与该键相关联的数据。比如,“age”:18
键值对的特点包括:
- 唯一性:每个键必须是唯一的。同一个键在键值对中只能出现一次。
- 关联性:每个键都与一个对应的值相关联,可以通过键来获取或修改对应的值。
- 无序性:键值对的存储和检索是无序的,即没有固定的顺序。不同的编程语言或数据结构可能会提供特定的顺序保证,但通常情况下,键值对的顺序是不确定的。
哈希表通过将键映射到一个确定的位置来实现高效的数据访问。
Python中的字典就是一种哈希表的实现(我以前一直叫它键值对),由于字典使用哈希函数和桶的结构,它具有快速的插入、查找和删除操作的能力。通过哈希函数的作用,Python 可以在常数时间内(平均情况下)执行这些操作,使字典成为处理大量数据的理想选择。
哈希表的核心思想是使用哈希函数将键映射到一个特定的索引位置。哈希函数将键转换为一个固定大小的整数,该整数用作数组的索引。通过使用哈希函数,可以在常数时间内(O(1))找到存储或检索键值对的位置。
在哈希表中,通常使用数组来实现存储桶(buckets),每个桶存储一个或多个键值对。当插入一个键值对时,哈希函数计算键的哈希值,并将其映射到一个特定的桶。如果多个键的哈希值相同(即哈希冲突),则可以使用解决冲突的方法,如链地址法或开放寻址法。
存储桶:
桶(bucket)是指存储键值对的容器。哈希表使用桶来组织和存储数据,每个桶可以存储一个或多个键值对。
使用桶的好处是它们可以解决哈希冲突的问题。当发生哈希冲突时,即两个或多个键被映射到同一个位置时,桶可以用来存储这些冲突的键值对。常见的解决冲突的方法包括链地址法和开放寻址法。
在哈希表中,通过桶的使用,可以实现高效的数据存储和检索。通过哈希函数的作用,我们可以在常数时间内(平均情况下)找到存储或检索键值对的桶,进而提供快速的数据访问能力。
哈希表的性能与桶的数量有关。如果哈希表中的桶数量太少,可能会导致哈希冲突增多,从而影响性能。而桶的数量过多又可能浪费空间。因此,在设计哈希表时,需要考虑合适的桶的数量,以及解决冲突的方法,来平衡空间利用和性能的需求。
在哈希表中,常见的操作包括插入(Insertion)、查找(Lookup)和删除(Deletion)。通过使用哈希函数,这些操作可以在平均情况下在常数时间内完成,具有高效的性能。
哈希表在计算机科学中有广泛的应用,常用于缓存、数据库索引、字典等场景。它提供了快速的数据存储和检索能力,并且在适当选择哈希函数和解决冲突的方法的情况下,可以实现高效的性能。
哈希表的性能取决于哈希函数的选择和键的分布情况。不恰当的哈希函数或者键的分布不均匀可能导致哈希冲突增加,从而影响性能。因此,在设计和使用哈希表时,选择适当的哈希函数和解决冲突的方法非常重要。
1.2 哈希函数 Hash Function
哈希函数(Hash Function)是一种将数据(输入)映射到固定长度值(输出)的函数。它将任意大小的数据转换为固定大小的哈希值,通常是一个整数或一段二进制数据。
这个值通常作为数组的索引,通过这种方式,要查找一个特定键的值,只需要通过哈希函数就能得到他在数组中的下标,无须遍历,非常高效。
哈希函数的主要特点是:
- 一致性:对于相同的输入,哈希函数始终产生相同的哈希值。这意味着哈希函数具有确定性。
- 均匀性:哈希函数应该尽可能地将输入的不同部分均匀地映射到输出的不同部分,以减少哈希冲突的概率。理想情况下,不同的输入应该得到不同的哈希值。
- 高效性:哈希函数的计算应该在较短的时间内完成,以保持高效的性能。
哈希函数在计算机科学中有广泛的应用,尤其在哈希表、数据加密、消息摘要、数据完整性校验等领域。
举个例子吧:数据完整性校验。在基于公钥和私钥的加密方式中,所有人都能用公钥来加密数据,但只有拥有私钥的人可以查看加密后的数据。这似乎还挺安全的。但是,如何确定收到的数据是我想要的人发给我的呢?这时,就可以使用哈希函数了,如果收到的内容通过哈希函数计算后的哈希值与收到的哈希值相同,则可以表明收到了想要的数据。
在哈希表中,哈希函数的作用是将键映射到桶的位置(索引),从而确定键值对在哈希表中的存储位置。一个好的哈希函数可以最大程度地减少哈希冲突(尽量不产生相同的哈希值),提供高效的数据存储和检索能力。
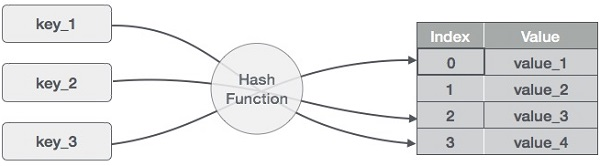
常见的哈希函数包括:
- 除法哈希法(Division Hashing):将键除以某个数并取余数作为哈希值。例如,
hash_value = key % table_size。 - 乘法哈希法(Multiplication Hashing):将键与某个常数相乘,并取小数部分作为哈希值。例如,hash_value = (a * key) % 1。
- 直接定址法(Direct Addressing):直接将键作为哈希值。适用于键空间较小且连续的情况。
- 哈希加密函数(Cryptographic Hash Functions):产生固定长度的哈希值,并具有抗碰撞(collision-resistant)和单向性(one-way)的特性。常用的哈希函数包括 MD5、SHA-1、SHA-256 等。
MD5(Message Digest Algorithm 5):MD5是一种广泛使用的哈希算法,但它已被认为存在安全漏洞,不再推荐用于加密安全目的。
SHA-1(Secure Hash Algorithm 1):SHA-1也是一种常见的哈希算法,但与MD5类似,它也被认为存在安全漏洞,并不适合用于加密安全目的。
SHA-256(Secure Hash Algorithm 256):SHA-256是SHA-2家族中的一员,提供了更高的安全性。它生成的哈希值长度为256位,被广泛应用于数字签名、证书验证等安全领域。SHA-3(Secure Hash Algorithm 3):SHA-3是美国国家标准与技术研究院(NIST)于2015年发布的新一代哈希算法。它提供了与SHA-2不同的设计原理和更好的安全性。
Blake2:Blake2是一种高速且安全的哈希函数,它具有较高的性能,并且适用于各种应用场景。
当我们在github下载一些文件时,有的开发者就会提供SHA-56值来供你验证(后面我会讲如何验证),比如:
选择适当的哈希函数取决于应用的需求和数据的特点。在设计和选择哈希函数时,需要综合考虑一致性、均匀性、高效性和安全性等因素,以满足具体的应用场景和性能要求。
1.3 哈希冲突 Hash Collision
哈希冲突(Hash Collision)指的是不同的键通过哈希函数映射到相同的哈希值,并尝试在哈希表中存储在同一个桶内的情况。
在哈希表中,通过哈希函数将键映射到特定的位置,也就是桶(比如数组)。由于哈希函数的输出范围通常比键的数量小得多,因此不同的键可能会映射到相同的位置,这就是哈希冲突。
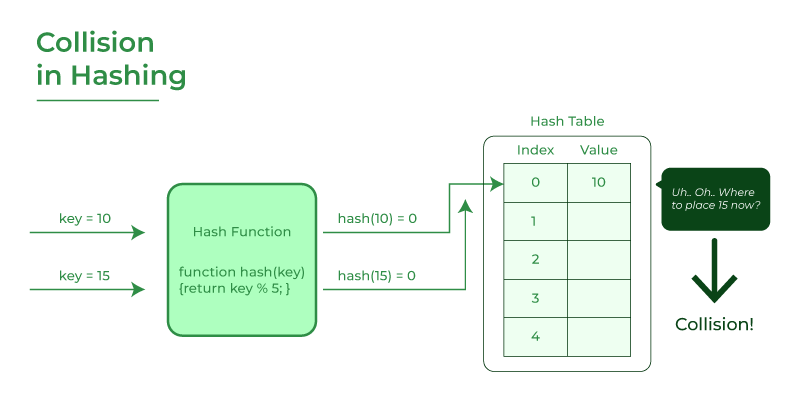
哈希冲突可能会导致以下问题:
-
冲突的键值对无法准确存储:当两个或多个键被映射到相同的位置时,哈希表需要找到一种方式来存储这些键值对。常见的方法包括链地址法和开放寻址法。
- 链地址法(Separate Chaining):每个桶内维护一个链表或其他数据结构,用于存储冲突的键值对。当发生哈希冲突时,新的键值对会添加到链表中。
- 开放寻址法(Open Addressing):在发生冲突时,通过线性探测、二次探测、双重散列等方法来寻找下一个可用的桶,直到找到一个空闲的桶来存储冲突的键值对。
-
性能下降:哈希冲突会增加插入、查找和删除操作的时间复杂度。当哈希表中存在大量冲突时,会导致桶中链表或探测过程变长,从而影响了操作的效率。
1.4 哈希冲突解决
1.41 方法概述
解决哈希冲突的常用方法包括链地址法(Separate Chaining)、开放寻址法(Open Addressing)和再哈希法(Rehashing)。
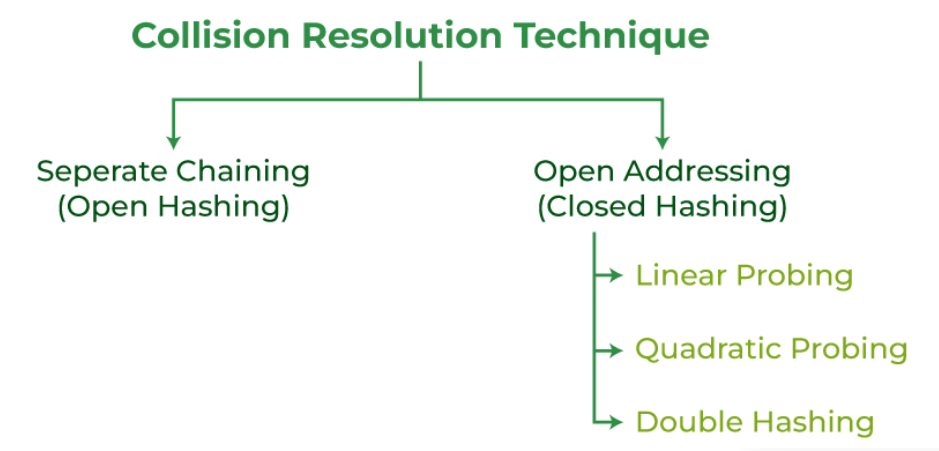
- 链地址法(Separate Chaining):
- 在哈希表中,每个桶维护一个链表或其他数据结构,用于存储冲突的键值对。
- 当发生哈希冲突时,新的键值对会添加到链表的末尾。
- 在查找时,首先通过哈希函数找到桶的位置,然后遍历链表查找目标键值对。
- 链地址法简单易实现,可以处理任意数量的冲突,但对于长链表的性能可能较低。
- 开放寻址法(Open Addressing):
- 在哈希表中,当发生哈希冲突时,会尝试找到下一个可用的桶来存储冲突的键值对,而不是使用链表。
- 常见的开放寻址法包括线性探测、二次探测、双重散列等。
- 线性探测(Linear Probing):逐个检查下一个桶,直到找到一个空闲的桶。
- 二次探测(Quadratic Probing):使用二次探测公式来查找下一个桶,以减少线性探测的线性效应。
- 双重散列(Double Hashing):使用第二个哈希函数计算下一个桶的位置,以解决线性探测带来的聚集效应。
- 开放寻址法避免了链表的使用,可以节省内存,但可能会出现聚集效应,影响性能。
- 再哈希法(Rehashing):
- 当哈希表中的负载因子(load factor)超过一定阈值时,可以选择重新调整哈希表的大小,以减少哈希冲突的概率。
- 重新调整哈希表大小时,会创建一个更大的哈希表,并将原有的键值对重新插入到新的哈希表中。
- 重新插入时,可能会选择不同的哈希函数,或者使用相同的哈希函数但调整哈希表的大小,以获得更好的分布效果。
1.42 链地址法 Separate Chaining
链地址法(Separate Chaining)使用链表或其他数据结构来处理冲突。
在链地址法中,哈希表中的每个桶都维护一个链表或其他数据结构。当发生哈希冲突时,新的键值对会添加到链表中,形成一个键值对的集合。
Example: hash function :“key mod 7” , and a sequence of keys are: 50, 700, 76, 85, 92, 73, 101(只是图示,实际上存储的是键值对)
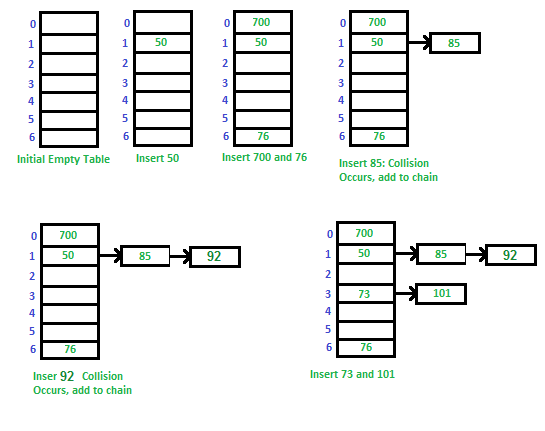
链地址法的基本工作原理:
- 初始化哈希表:创建一个具有固定数量的桶的哈希表,每个桶初始为空。
- 哈希函数映射:使用哈希函数将键映射到特定的桶位置。
- 冲突处理:如果多个键映射到同一个桶,即发生了哈希冲突,将新的键值对添加到桶中。可以使用链表、数组、树等数据结构来组织冲突的键值对集合。
- 插入操作:将新的键值对插入到相应的桶中的链表末尾。
- 查找操作:通过哈希函数找到键对应的桶,然后在桶内的链表上搜索目标键值对。
- 删除操作:在桶内的链表上查找并删除目标键值对。
链地址法的优点包括:
- 简单易实现:链地址法的实现相对简单,只需要在每个桶中维护一个链表或其他数据结构即可。
- 处理任意数量的冲突:链地址法可以处理任意数量的哈希冲突,因为链表可以动态增长。
- 空间效率较高:只需要为每个桶分配存储空间,可以根据实际需要进行调整。
然而,链地址法也存在一些缺点:
- 内存消耗较高:由于需要维护链表或其他数据结构,链地址法可能会占用较多的内存空间。
- 性能受链表长度影响:当链表长度较长时,插入和查找操作的效率可能下降,因为需要遍历整个链表。
为了提高性能,可以采取以下措施:
- 调整负载因子:当链表长度超过一定阈值时,可以考虑重新调整哈希表的大小,以减少链表的长度。
- 使用更好的哈希函数:选择合适的哈希函数可以更均匀地分布键值对,减少冲突的发生。
- 考虑其他解决冲突的方法:如果链表的长度较长,可以考虑使用其他解决哈希冲突的方法,如开放寻址法。
重要说明:
- 在普通哈希表中,不考虑哈希冲突时,通常用一个数组来存放键值对,key通过哈希函数计算得到的哈希值就是对应的value在数组中的下标,即一个桶就是一个数组,可以存放多个键值对;
- 而使用链地址法时,一个桶在没有发生哈希冲突时,只存放一个键值对;存放多个没有冲突的键值对时,需要多个桶,通常用数组来组织,数组每个元素(即桶)包含一个指向链表头部的指针,这样的数据结构称为“桶数组”。
- 不管什么样的哈希表,应当把键和值都存储进去(普通的哈希表你也可以只存value,如果可行)。
1.43 开放寻址法 Open Addressing
开放寻址法(Open Addressing)是一种解决哈希冲突的方法,与链地址法不同。在开放寻址法中,所有的键值对都直接存储在哈希表的数组中,而不是使用链表等数据结构。
具体来说,当发生哈希冲突时,开放寻址法会尝试找到下一个可用的空槽(数组位置),直到找到一个空槽来存储冲突的键值对。
开放寻址法有几种常见的策略来寻找下一个空槽:
- 线性探测(Linear Probing):如果发生冲突,依次检查下一个槽,直到找到一个空槽或遍历整个数组。常用的线性探测方法是逐个探测,即逐个地检查下一个槽,如果遇到空槽,则将键值对插入该槽。
- 二次探测(Quadratic Probing):如果发生冲突,使用二次探测来找到下一个槽,可以使用公式 (hash(key) + i^2) % size,其中 i 是冲突次数,size 是哈希表的大小。
- 双重哈希(Double Hashing):如果发生冲突,使用另一个哈希函数来计算步长(跳过的槽数),直到找到一个空槽。具体的步长计算公式为 (hash1(key)
- i * hash2(key)) % size,其中 i 是冲突次数,size 是哈希表的大小。
当需要查找键的值时,使用相同的哈希函数计算键的哈希值,并从对应的槽开始查找,直到找到匹配的键或遇到空槽。
开放寻址法的优点是避免了链表的额外存储空间,并且可以提高缓存的利用率。然而,它对于负载因子的控制较为敏感,当哈希表填充度过高时,性能可能会下降。此外,删除操作也较为复杂,需要标记删除或使用其他特殊的值来表示删除状态。
▶ 线性探测 Linear Probing
具体的线性探测过程如下:
- 使用哈希函数计算键的哈希值,并将其映射到哈希表的某个槽(数组位置)上。
- 如果哈希表中的该槽为空,则直接将键值对存储在该槽上。
- 如果哈希表中的该槽已经被占用(发生冲突),则从当前槽开始逐个检查下一个槽,直到找到一个空槽。
- 逐个检查下一个槽的方式是通过简单的线性增量。也就是说,下一个槽的位置是当前槽的位置加上一个固定的步长(通常是1),即当前位置加1。
- 重复步骤4,直到找到一个空槽。将键值对存储在找到的空槽上。
- 如果遍历整个数组都没有找到空槽,说明哈希表已满,无法插入更多的键值对。
当需要查找某个键的值时,使用相同的哈希函数计算键的哈希值,并从对应的槽开始查找。如果找到一个槽,且该槽中的键与目标键匹配,则返回对应的值。如果遇到空槽或遍历整个数组仍未找到匹配的键,说明该键不存在于哈希表中。
依然是前面那个例子: hash function :“key mod 7” , and a sequence of keys are: 50, 700, 76, 85, 92, 73, 101
- 插入key=50的键值对,50%7=1,插入位置下标是1;
- 插入key=700的键值对,700%7=0,插入位置下标是0;
- 插入key=76的键值对,76%7=6,插入位置下标是6;
- 插入key=85的键值对,85%7=1,出现冲突,查找下一个位置2,空闲,插入;
- 插入key=92的键值对,92%7=1,出现冲突,查找下一个位置2,不空闲,查找下一个位置3,空闲,插入;
- …
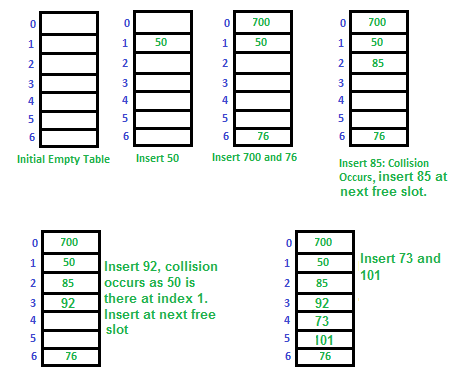
线性探测的优点是实现简单、内存效率高,并且易于缓存。
然而,它存在聚集问题(Clustering),即连续的哈希冲突会导致槽被线性地占据,形成长的连续探测序列,从而降低查找性能。为了减少聚集问题的影响,可以采用其他的探测策略,如二次探测或双重哈希。
线性探测的应用:
- 符号表:线性探测通常用于符号表,符号表用于编译器和解释器中以存储变量及其相关值。由于符号表可以动态增长,因此可以使用线性探测来处理冲突并确保有效存储变量。
- 缓存:线性探测可用于缓存系统,以将频繁访问的数据存储在内存中。当发生缓存未命中时,可以使用线性探测将数据加载到缓存中,而当发生冲突时,可以使用缓存中的下一个可用槽来存储数据。
- 数据库:线性探测可用于数据库中以存储记录及其相关键。当发生冲突时,可以使用线性探测来寻找下一个可用的槽来存储记录。
- 编译器设计:线性探测可用于编译器设计,以实现符号表、错误恢复机制和语法分析。
- 拼写检查:线性探测可用于拼写检查软件,以存储单词词典及其相关频率计数。当发生冲突时,可以使用线性探测将字存储在下一个可用槽中。
▶ 二次探测 Quadratic Probing
由于前面的线性探测会导致聚集问题,可以使用二次探测来缓解这个问题。
二次探测使用一个固定的步长公式,通常是 i 2 i^2 i2,其中 i 是冲突次数。也就是说,下一个槽的位置是当前槽的位置加上一个平方增量。 即 (hash(x) + i 2 i^2 i2) % size
Example: table Size = 7, hash function: Hash(x) = x % 7 , collision resolution strategy to be f ( i ) = i 2 f(i) = i^2 f(i)=i2 . Insert = 22, 30, and 50.
- 插入key=22的键值对,22%7=1,插入位置的下标是1;
- 插入key=30的键值对,30%7=2,插入位置的下标是2;
- 插入key=50的键值对,50%7=1,出现冲突;查找
1
+
1
2
=
2
1+1^2=2
1+12=2,这里已经存的有键值对了;继续查找
1
+
2
2
=
5
1+2^2=5
1+22=5,此处空闲,在此处插入。
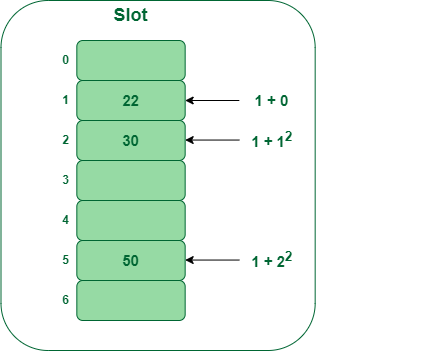
二次探测相比线性探测具有一定的优势,因为它可以避免线性探测中产生的聚集问题。然而,二次探测也可能导致新的聚集问题,即二次探测序列中的槽位置仍然被占用,导致槽的聚集性。为了避免这种情况,可以使用一个合适的步长公式和适当的哈希表大小来降低聚集性的影响。
为了保证二次探测的有效性,哈希表的大小通常选择为素数,这样可以更好地分布探测序列,减少聚集问题的发生。
▶ 双重哈希 Double Hashing
双重哈希(Double Hashing)使用两个不同的哈希函数来计算步长(跳过的槽数),以便找到下一个可用的空槽。
步骤:
- 使用第一个哈希函数计算键的哈希值,并将其映射到哈希表的某个槽(数组位置)上。
- 如果哈希表中的该槽为空,则直接将键值对存储在该槽上。
- 如果哈希表中的该槽已经被占用(发生冲突),则使用第二个哈希函数计算步长。
- 第二个哈希函数将键映射到一个正整数步长值,用于计算下一个槽的位置。常见的计算方式是通过取模运算,即
(hash2(key) * i) % size,或者(hash(x) + i*hash2(x)) % size,其中 hash2 是第二个哈希函数,i 是冲突次数,size 是哈希表的大小。- 如果下一个槽为空,则将键值对存储在该槽上。
- 如果下一个槽仍然被占用,则继续计算下一个槽,直到找到一个空槽或遍历整个数组。
- 如果遍历整个数组都没有找到空槽,说明哈希表已满,无法插入更多的键值对。
当需要查找某个键的值时,使用相同的哈希函数计算键的哈希值,并从对应的槽开始查找。如果找到一个槽,且该槽中的键与目标键匹配,则返回对应的值。如果遇到空槽或遍历整个数组仍未找到匹配的键,说明该键不存在于哈希表中。
双重哈希可以有效地解决哈希冲突,并且在适当的设计下能够提供较好的分布性和低碰撞率。选择合适的第二个哈希函数和适当的哈希表大小对于双重哈希的性能很重要。确保第二个哈希函数与第一个哈希函数有良好的独立性,以减少冲突的发生和聚集问题的影响。同时,哈希表的大小通常选择为素数,以便更好地分布探测序列,减少聚集性。
Example: Insert the keys 27, 43, 692, 72 into the Hash Table of size 7. where first hash-function is
h
1
(
k
)
=
h1(k) =
h1(k)=k mod 7 and second hash-function is
h
2
(
k
)
=
1
+
h2(k) = 1 +
h2(k)=1+ (k mod 5)
-
27 % 7 = 6, location 6 is empty so insert 27 into 6 slot.
-
43 % 7 = 1, location 1 is empty so insert 43 into 1 slot.
-
692 % 7 = 6, but location 6 is already being occupied and this is a collision
hnew = [h1(692) + i * (h2(692)] % 7
= [6 + 1 * (1 + 692 % 5)] % 7
= 9% 7
= 24.72 % 7 = 2, but location 2 is already being occupied and this is a collision.
hnew = [h1(72) + i * (h2(72)] % 7
= [2 + 1 * (1 + 72 % 5)] % 7
= 5 % 7
= 5,
Now,

1.44 哈希冲突会导致操作的时间复杂度增加
当哈希表发生冲突时,无论使用哪种解决冲突的方法(如线性探测、二次探测、双重哈希或链地址法),操作的时间复杂度都有可能增加。
在理想情况下,哈希表的插入和查找操作的时间复杂度是常数级别的 O(1),即平均情况下的操作时间是固定的。但是,当发生哈希冲突时,需要额外的操作来解决冲突,这会导致操作的时间复杂度增加。
-
对于开放寻址法中的线性探测、二次探测和双重哈希,冲突解决的操作涉及遍历数组、计算新的槽位置等,这些操作的时间复杂度与哈希表的填充度和哈希表的大小有关。随着哈希表的填充度增加,发生冲突的概率增加,解决冲突的操作次数也会增加,导致操作的时间复杂度增加。
-
在链地址法中,发生冲突时需要在桶(链表)中进行插入或查找操作。在没有哈希冲突的情况下,插入和查找操作的时间复杂度是常数级别的 O(1)。但是,当哈希冲突发生时,需要遍历链表来查找或插入特定的键值对,这会导致操作的时间复杂度取决于链表的长度。
因此,无论使用哪种解决哈希冲突的方法,操作的时间复杂度都可能增加。在选择哈希表实现和解决冲突的方法时,需要综合考虑数据集的特征、操作的频率和性能要求,以平衡操作的效率和空间利用。
1.45 再哈希法 Rehashing
再哈希法(Rehashing)是一种解决哈希冲突的方法,它基于多个哈希函数和哈希表的扩容操作。当哈希表发生冲突且达到一定负载因子时,使用再哈希法进行扩容和重新哈希。
具体的再哈希法过程如下:
- 初始化一个初始大小的哈希表,选择一个哈希函数进行键的映射。
- 当哈希表的负载因子达到一定阈值(如0.7)时,触发扩容操作。
- 创建一个更大的哈希表,通常是当前哈希表大小的两倍或更大。
- 选择一个新的哈希函数进行键的重新映射,与初始哈希函数不同。
- 遍历旧哈希表中的每个槽,将其中的键值对重新插入到新哈希表中。
- 在新哈希表中使用新的哈希函数计算键的哈希值,并将键值对存储在相应的槽上。
- 完成所有键值对的重新插入后,替换旧哈希表为新哈希表,释放旧哈希表的内存。
再哈希法的关键在于扩容操作和键的重新映射。通过使用新的哈希函数,重新映射键可以减少冲突的发生,并且将键均匀地分布在新的哈希表中。这样可以提高哈希表的性能和避免聚集问题。
再哈希法的时间复杂度取决于扩容和重新插入的操作。通常情况下,扩容操作需要分配新的内存空间,并且需要遍历旧哈希表中的所有键值对进行重新插入。因此,再哈希法的时间复杂度与哈希表中键值对的数量相关,可以近似为 O(n),其中 n 是键值对的数量。
再哈希法可能会引起一段时间内的性能下降,因为在扩容和重新插入期间,哈希表需要同时维护旧表和新表。因此,在设计哈希表时,需要合理选择扩容阈值和新表的大小,以平衡哈希表的性能和内存利用率。
二、C语言实现
2.1 普通哈希表
使用key的字符ascii码之和 mod 哈希表表大小 作为哈希值。
下面的例子简化了很多内容,比如插入的时候判断哈希表是否已满,没有解决哈希冲突,相同哈希值的键值对会覆盖旧的。
#include <stdio.h> #include <stdbool.h> #include <string.h> #define TABLE_SIZE 10 typedef struct { char key[20]; int value; } KeyValuePair; typedef struct { KeyValuePair table[TABLE_SIZE]; } HashTable; unsigned int hash(const char* key) { unsigned int hashValue = 0; for (int i = 0; key[i] != '\0'; i++) { hashValue += key[i]; } return hashValue % TABLE_SIZE; } void insert(HashTable* hashTable, const char* key, int value) { unsigned int index = hash(key); strcpy(hashTable->table[index].key, key); hashTable->table[index].value = value; } void get(HashTable* hashTable, const char* key) { bool flag; int value; unsigned int index = hash(key); if (strcmp(hashTable->table[index].key, key) == 0 && hashTable->table[index].key[0] != '\0') { value = hashTable->table[index].value; flag=true; } else flag=false; if(flag) printf("Value for %s:%d\n",key,value); else printf("key %s not found.\n",key); } int main() { HashTable hashTable; memset(hashTable.table, 0, sizeof(hashTable.table)); insert(&hashTable, "apple", 1); insert(&hashTable, "apple",88); insert(&hashTable, "banana", 2); insert(&hashTable, "orange", 3); get(&hashTable,"apple"); get(&hashTable, "orange"); return 0; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
如图,产生冲突时,会覆盖数据。

2.2 可以处理哈希冲突的哈希表
链地址法中,一个桶存储一个链表;哈希表是一个通数组。
开放地址法中:哈希表是一个桶,即用一个数组存放键值对。
2.21 链地址法
#include <stdio.h> #include <stdlib.h> #define SIZE 10 // 哈希表节点结构 typedef struct Node { int key; int value; struct Node* next; } Node; // 哈希表结构 typedef struct HashTable { // 桶数组,里面有SIZE个链表 Node* buckets[SIZE]; } HashTable; // 创建哈希表 HashTable* createHashTable() { HashTable* hashtable = (HashTable*)malloc(sizeof(HashTable)); for (int i = 0; i < SIZE; i++) { hashtable->buckets[i] = NULL; } return hashtable; } // 哈希函数 int hashFunction(int key) { return key % SIZE; } // 向哈希表中插入键值对 void insert(HashTable* hashtable, int key, int value) { int index = hashFunction(key); // 创建新节点 Node* newNode = (Node*)malloc(sizeof(Node)); newNode->key = key; newNode->value = value; newNode->next = NULL; // 如果桶为空,则直接插入新节点 if (hashtable->buckets[index] == NULL) { hashtable->buckets[index] = newNode; } else { // 否则,在链表末尾插入新节点 Node* current = hashtable->buckets[index]; while (current->next != NULL) { current = current->next; } current->next = newNode; } } // 根据键查找哈希表中的值 int search(HashTable* hashtable, int key) { int index = hashFunction(key); // 查找链表中对应的节点 Node* current = hashtable->buckets[index]; while (current != NULL) { if (current->key == key) { return current->value; } current = current->next; } // 若未找到,返回-1 return -1; } // 从哈希表中删除键值对 void delete(HashTable* hashtable, int key) { int index = hashFunction(key); // 查找链表中对应的节点 Node* current = hashtable->buckets[index]; Node* prev = NULL; while (current != NULL) { if (current->key == key) { if (prev == NULL) { // 若为头节点,直接修改桶指针 hashtable->buckets[index] = current->next; } else { // 否则修改前一个节点的指针 prev->next = current->next; } free(current); return; } prev = current; current = current->next; } } // 销毁哈希表 void destroyHashTable(HashTable* hashtable) { for (int i = 0; i < SIZE; i++) { Node* current = hashtable->buckets[i]; while (current != NULL) { Node* temp = current; current = current->next; free(temp); } } free(hashtable); } int main() { HashTable* hashtable = createHashTable(); // 插入键值对 insert(hashtable, 1, 10); insert(hashtable, 11, 20); insert(hashtable, 21, 30); // 查找值 int value =search(hashtable, 11); if(value) printf("Find key =11 ,value = %d\n",value); else printf("key=11 not exist.\n"); // 销毁哈希表 destroyHashTable(hashtable); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127

2.22 开放地址法
▶ 线性探测
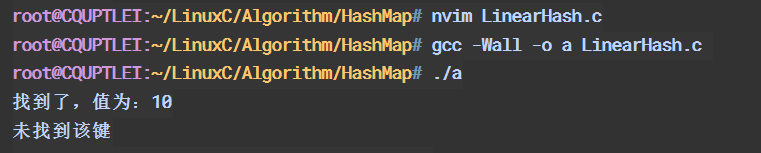
// 线性探测法 #include <stdio.h> #include <stdlib.h> #define SIZE 10 // 哈希表节点结构 typedef struct { int key; int value; } Node; // 哈希表结构 typedef struct { Node* data[SIZE]; } HashTable; // 创建哈希表 HashTable* createHashTable() { HashTable* hashtable = (HashTable*)malloc(sizeof(HashTable)); for (int i = 0; i < SIZE; i++) { hashtable->data[i] = NULL; } return hashtable; } // 哈希函数 int hashFunction(int key) { return key % SIZE; } // 向哈希表中插入键值对 void insert(HashTable* hashtable, int key, int value) { int index = hashFunction(key); // 寻找下一个可用的位置 while (hashtable->data[index] != NULL) { index = (index + 1) % SIZE; } // 创建新节点 Node* newNode = (Node*)malloc(sizeof(Node)); newNode->key = key; newNode->value = value; // 插入新节点 hashtable->data[index] = newNode; } // 根据键查找哈希表中的值 int search(HashTable* hashtable, int key) { int index = hashFunction(key); int originalIndex = index; // 从哈希表中寻找对应的键值对 while (hashtable->data[index] != NULL) { if (hashtable->data[index]->key == key) { return hashtable->data[index]->value; } index = (index + 1) % SIZE; // 如果回到原始位置,则说明未找到 if (index == originalIndex) { break; } } // 若未找到,返回-1 return -1; } // 从哈希表中删除键值对 void delete(HashTable* hashtable, int key) { int index = hashFunction(key); int originalIndex = index; // 从哈希表中寻找对应的键值对 while (hashtable->data[index] != NULL) { if (hashtable->data[index]->key == key) { free(hashtable->data[index]); hashtable->data[index] = NULL; return; } index = (index + 1) % SIZE; // 如果回到原始位置,则说明未找到 if (index == originalIndex) { break; } } } // 销毁哈希表 void destroyHashTable(HashTable* hashtable) { for (int i = 0; i < SIZE; i++) { if (hashtable->data[i] != NULL) { free(hashtable->data[i]); } } free(hashtable); } int main() { HashTable* hashtable = createHashTable(); // 插入键值对 insert(hashtable, 1, 10); insert(hashtable, 11, 20); insert(hashtable, 21, 30); // 查找值 int value = search(hashtable, 1); if (value != -1) { printf("找到了,值为:%d\n", value); } else { printf("未找到该键\n"); } // 删除键值对 delete(hashtable, 1); // 再次查找 value = search(hashtable, 1); if (value != -1) { printf("找到了,值为:%d\n", value); } else { printf("未找到该键\n"); } // 销毁哈希表 destroyHashTable(hashtable); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
▶ 二次探测
改一下插入和查找。
// 二次探测 #include <stdio.h> #include <stdlib.h> #define SIZE 10 // 哈希表节点结构 typedef struct { int key; int value; } Node; // 哈希表结构 typedef struct { Node* data[SIZE]; } HashTable; // 创建哈希表 HashTable* createHashTable() { HashTable* hashtable = (HashTable*)malloc(sizeof(HashTable)); for (int i = 0; i < SIZE; i++) { hashtable->data[i] = NULL; } return hashtable; } // 哈希函数 int hashFunction(int key) { return key % SIZE; } // 向哈希表中插入键值对 void insert(HashTable* hashtable, int key, int value) { int index = hashFunction(key); int step = 1; // 寻找下一个可用的位置 while (hashtable->data[index] != NULL) { index = (index + step * step) % SIZE; step++; } // 创建新节点 Node* newNode = (Node*)malloc(sizeof(Node)); newNode->key = key; newNode->value = value; // 插入新节点 hashtable->data[index] = newNode; } // 根据键查找哈希表中的值 int search(HashTable* hashtable, int key) { int index = hashFunction(key); int step = 1; // 从哈希表中寻找对应的键值对 while (hashtable->data[index] != NULL) { if (hashtable->data[index]->key == key) { return hashtable->data[index]->value; } index = (index + step * step) % SIZE; step++; } // 若未找到,返回-1 return -1; } // 从哈希表中删除键值对 void delete(HashTable* hashtable, int key) { int index = hashFunction(key); int step = 1; // 从哈希表中寻找对应的键值对 while (hashtable->data[index] != NULL) { if (hashtable->data[index]->key == key) { free(hashtable->data[index]); hashtable->data[index] = NULL; return; } index = (index + step * step) % SIZE; step++; } } // 销毁哈希表 void destroyHashTable(HashTable* hashtable) { for (int i = 0; i < SIZE; i++) { if (hashtable->data[i] != NULL) { free(hashtable->data[i]); } } free(hashtable); } int main() { HashTable* hashtable = createHashTable(); // 插入键值对 insert(hashtable, 1, 10); insert(hashtable, 11, 20); insert(hashtable, 21, 30); // 查找值 int value = search(hashtable, 1); if (value != -1) { printf("找到了,值为:%d\n", value); } else { printf("未找到该键\n"); } // 删除键值对 delete(hashtable, 1); // 再次查找 value = search(hashtable, 1); if (value != -1) { printf("找到了,值为:%d\n", value); } else { printf("未找到该键\n"); } // 销毁哈希表 destroyHashTable(hashtable); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
▶ 双重哈希
// 双重哈希 #include <stdio.h> #include <stdlib.h> #define SIZE 10 // 哈希表节点结构 typedef struct { int key; int value; } Node; // 哈希表结构 typedef struct { Node* data[SIZE]; } HashTable; // 创建哈希表 HashTable* createHashTable() { HashTable* hashtable = (HashTable*)malloc(sizeof(HashTable)); for (int i = 0; i < SIZE; i++) { hashtable->data[i] = NULL; } return hashtable; } // 哈希函数1 int hashFunction1(int key) { return key % SIZE; } // 哈希函数2 int hashFunction2(int key) { return 1 + (key % (SIZE - 1)); } // 向哈希表中插入键值对 void insert(HashTable* hashtable, int key, int value) { int index = hashFunction1(key); int step = hashFunction2(key); // 寻找下一个可用的位置 while (hashtable->data[index] != NULL) { index = (index + step) % SIZE; } // 创建新节点 Node* newNode = (Node*)malloc(sizeof(Node)); newNode->key = key; newNode->value = value; // 插入新节点 hashtable->data[index] = newNode; } // 根据键查找哈希表中的值 int search(HashTable* hashtable, int key) { int index = hashFunction1(key); int step = hashFunction2(key); // 从哈希表中寻找对应的键值对 while (hashtable->data[index] != NULL) { if (hashtable->data[index]->key == key) { return hashtable->data[index]->value; } index = (index + step) % SIZE; } // 若未找到,返回-1 return -1; } // 从哈希表中删除键值对 void delete(HashTable* hashtable, int key) { int index = hashFunction1(key); int step = hashFunction2(key); // 从哈希表中寻找对应的键值对 while (hashtable->data[index] != NULL) { if (hashtable->data[index]->key == key) { free(hashtable->data[index]); hashtable->data[index] = NULL; return; } index = (index + step) % SIZE; } } // 销毁哈希表 void destroyHashTable(HashTable* hashtable) { for (int i = 0; i < SIZE; i++) { if (hashtable->data[i] != NULL) { free(hashtable->data[i]); } } free(hashtable); } int main() { HashTable* hashtable = createHashTable(); // 插入键值对 insert(hashtable, 1, 10); insert(hashtable, 11, 20); insert(hashtable, 21, 30); // 查找值 int value = search(hashtable, 1); if (value != -1) { printf("找到了,值为:%d\n", value); } else { printf("未找到该键\n"); } // 删除键值对 delete(hashtable, 1); // 再次查找 value = search(hashtable, 1); if (value != -1) { printf("找到了,值为:%d\n", value); } else { printf("未找到该键\n"); } // 销毁哈希表 destroyHashTable(hashtable); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
三、Python 字典
Python可以使用字典(Dictionary)数据结构来实现哈希表。字典是Python内置的数据类型,它使用键-值(key-value)对来存储和检索数据。
# 创建一个空的哈希表 hash_table = {} # 添加键值对到哈希表 hash_table['apple'] = 5 hash_table['banana'] = 2 hash_table['orange'] = 8 # 通过键来访问值 print(hash_table['apple']) # 输出:5 # 检查键是否存在 if 'banana' in hash_table: print("键 'banana' 存在于哈希表中") # 删除键值对 del hash_table['orange'] # 遍历哈希表的键值对 for key, value in hash_table.items(): print(key, value)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
Python大法好 本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

