
- 1【Node.js】实现微信小程序订阅消息推送功能_微信小程序消息推送,后端node
- 2大模型面试题目_温度系数和top p
- 3保姆级教程:如何用Python自制聊天机器人?_python 聊天机器人
- 4JS 实现3D立体效果的首页轮播图(瞬间让你的网站高大上,逼格满满)
- 5修改docker镜像_docker修改pull下来了镜像的dockerfile
- 6Hadoop大数据初入门----haddop伪分布式安装_哈度普 hadoop
- 7kafka-2.12使用记录_kafkaui-lite
- 8CSS中实现文字居中---笔记_css 文字居中
- 9《幻兽帕鲁(Palworld)》v0.1.2.0官方中文豪华版 一键安装硬盘版【百度/天翼】_palworld.exe
- 10An Improved Blockchain Consensus Algorithm Based on Raft(Raft算法改进区块链效率_raft共识算法改进
Hadoop集群环境配置及安装配置(详细过程包含安装包)_hadoop安装与配置(1)_hadoop安装方法
赞
踩

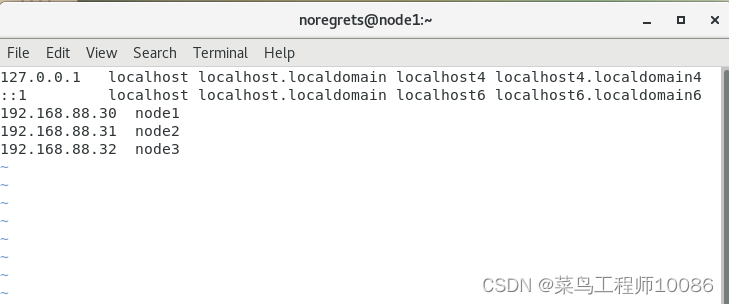
修改每台节点的hosts文件
命令为sudo vim /etc/hosts ,依次添加node1,node2,node3
4.ssh免密登录
1.命令:ssh-keygen -t rsa -b 4096 然后一路回车到底
在三台虚拟机依次执行

2.依次执行 ssh-copy-id node1 、ssh-copy-id node2 、ssh-copy-id node3。执行每一个命令后需要输入yes和id对应虚拟机的密码。
三、JDK安装部署(三台虚拟机都要安装)
JDK安装包链接:https://pan.baidu.com/s/1QxVCRdLcVaqD0kNXCrD3lg
提取码:1111
也可自行下载
1.创建一个文件夹 命令: mkdir -p /export/servers

2.上传文件,进入刚刚创建的文件夹,输入rz,找到JDK存放路径,选择JDK

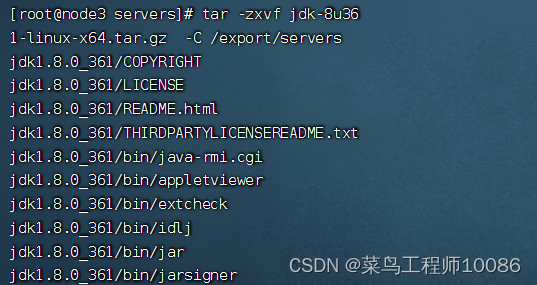
3.解压文件 命令: tar -zxvf jdk-8u361-linux-x64.tar.gz -C /export/servers
4.配置jdk软连接 命令:ln -s /export/servers/jdk1.8.0_361 /export/servers/jdk

5.配置JAVA_HOME环境变量
更改环境变量:sudo vim /etc/profile
#jdk环境变量
export JAVA_HOME=/export/servers/jdk
export PATH=
P
A
T
H
:
PATH:
PATH:JAVA_HOME/bin

6.生效环境变量,删除原有jdk,构建新的jdk软连接
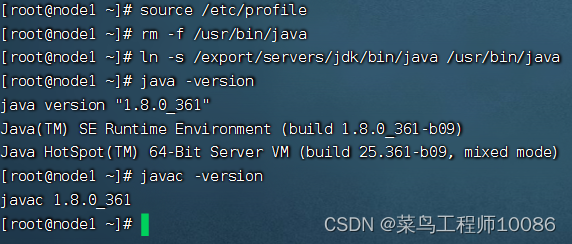
生效环境变量: source /etc/profile
删除原因jdk: rm -f /usr/bin/java
构建软连接: ln -s /export/servers/jdk/bin/java /usr/bin/java
验证jdk:java -version
javac -version
四.关闭防火墙和SElinux
1.关闭防火墙
systemctl stop firewalld
systemctl disable firewalld

2.关闭selinux
selinux,是用以限制用户和程序的相关权限,来确保系统的安全稳定。
命令:sudo vim /etc/sysconfig/selinux
将SELINUX=enforcing修改为SELINUX=disabled

五、修改时区并配置自动时间同步
1.安装ntp软件
yum install -y ntp
2.更新时区
删除原有时区:sudo rm -f /etc/localtime
加载新时区:sudo ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
更新时区: ntpdate -u ntp.aliyun.com
3.设置开机自启动
systemctl start ntpd
systemctl enable ntpd

Hadoop的前置环境基本配置完成,建议快照保存
六、Hadoop安装与部署
一、Hadoop安装包下载
Hadoop有自己官网(Apache Hadoop),可直接点击链接前往官网下载,或者链接: 链接:https://pan.baidu.com/s/1LFvqn7adVsA9nnoOVGIpdg?pwd=1111
提取码:1111
1.进入官方网站
在网站首页就有Download选项,点击download

2.进入download界面
会出现好几个版本,一般第一个为最新的版本,点击3.3.6的Binary download的第一个binary,这个是Hadoop的二进制发行版本包,source download是Hadoop的源代码。 3.点击下图框选部分链接下载Hadoop安装包
3.点击下图框选部分链接下载Hadoop安装包
二、Hadoop安装以及配置
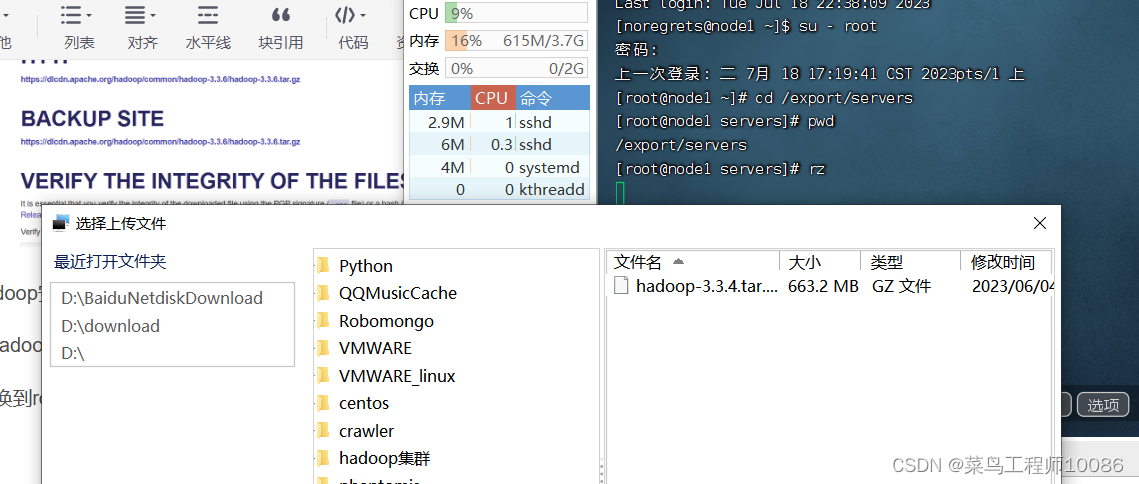
1.上传Hadoop安装包(node1进行)
进入/export/servers目录,输入rz,选择Hadoop下载文件夹进行上传。
2.解压Hadoop压缩包
命令:tar -zxvf hadoop-3.3.4.tar.gz -C /export/servers

3.构建软连接
命令: cd /export/servers
ln -s /export/servers/hadoop-3.3.4 hadoop
4.进入Hadoop目录,查看文件是否正确
各个文件夹含义如下
• bin ,存放 Hadoop 的各类程序(命令)
• etc ,存放 Hadoop 的配置文件
• include , C 语言的一些头文件
• lib ,存放 Linux 系统的动态链接库( .so 文件)
• libexec ,存放配置 Hadoop 系统的脚本文件( .sh和 .cmd )
• licenses-binary ,存放许可证文件
• sbin ,管理员程序( super bin )
• share ,存放二进制源码( Java jar 包)

5.修改配置文件
配置 HDFS 集群,我们主要涉及到如下文件的修改:
• workers : 配置从节点( DataNode )有哪些
• hadoop-env.sh : 配置 Hadoop 的相关环境变量
• core-site.xml : Hadoop 核心配置文件
• hdfs-site.xml : HDFS 核心配置文件
上述文件存放在以下目录
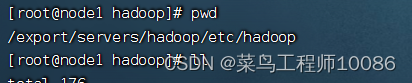
(1)workers文件配置
#填充内容如下
node1
node2
node3
表明集群记录了三个从节点(DataNode)
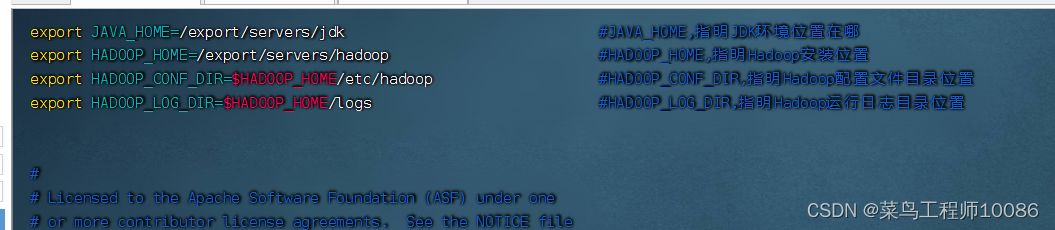
(2)配置hadoop-env.sh文件
#填充内容如下(在任意空白处填充即可)
export JAVA_HOME=/export/servers/jdk
export HADOOP_HOME=/export/servers/hadoop
export HADOOP_CONF_DIR=
H
A
D
O
O
P
_
H
O
M
E
/
e
t
c
/
h
a
d
o
o
p
e
x
p
o
r
t
H
A
D
O
O
P
_
L
O
G
_
D
I
R
=
HADOOP\_HOME/etc/hadoop export HADOOP\_LOG\_DIR=
HADOOP_HOME/etc/hadoop exportHADOOP_LOG_DIR=HADOOP_HOME/logs
(3)配置core-site.xml文件
#填充内容如下(在configuration内填充即可)
fs.defaultFS
hdfs://node1:8020

解释:
·key:fs.defaultFS
含义:HDFS文件系统的网络通信路径
值:协议为hdfs://
namenode为node1
namenode通讯端口为8020
·key:io.file.buffer.size
含义:io操作文件缓冲区大小
值:131072bit
hdfs://node1:8020为整个HDFS内部的通讯地址,应用协议为hdfs://(Hadoop内部协议)
表明DataNode将和node1的端口通讯,node1是NameNode所在机器
此配置固定了node1必须启动NameNode进程
(4)配置hdfs-site.xml文件
#填充内容如下
dfs.datanode.data.dir.perm #hdfs文件系统默认创建文件权限设置
700
dfs.namenode.name.dir #NameNode元数据的存储位置
/data/nn
dfs.namenode.hosts #NameNode运行哪些节点的DataNode连接
node1,node2,node3
dfs.blocksize #hdfs默认大小256MB
268435456
dfs.namenode.handler.count #namenode处理的开发线程数
100
dfs.datanode.data.dir #从节点datanode的数据存储目录
/data/dn
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)

g-2JmbxU4e-1712519887726)]
[外链图片转存中…(img-ret1kqDc-1712519887727)]
[外链图片转存中…(img-6UNTC9cL-1712519887727)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-DC2SQgkY-1712519887727)]

