
- 1程序员入门培训班多少钱?可以学到哪些东西?_程序员培训班要多少钱
- 2jwt 介绍_怎么查看一个浏览器网页的jwt
- 32021年危险化学品生产单位安全生产管理人员考试题库及危险化学品生产单位安全生产管理人员考试内容_人体是导体,在静电场中可能接触起电
- 4Vivado工程经验与时序收敛技巧_vivado fix cell
- 5算法——动态规划_完全加括号是什么意思
- 6git代码库迁移保留commit历史_Git 如何迁移仓库并保留 commit 记录
- 7RK3328 Debian安装OpenMediaVault
- 8git 拉取代码时显示Filename too long的解决办法_git file name too long
- 9系统盘50G,数据盘100G(需求:将数据磁盘扩容至1T)_系统盘和数据盘配比
- 10WooCommerce入门指南:简介
我们为什么要用本地大模型?如何搭建私有化大模型?
赞
踩
大模型,在2023年主要称之为大型语言模型(Large Language Models),是一种基于人工智能和机器学习技术构建的先进模型,旨在理解和生成自然语言文本。这些模型通过分析和学习海量的文本数据,掌握语言的结构、语法、语义和上下文等复杂特性,从而能够执行各种语言相关的任务。LLM的能力包括但不限于文本生成、问答、文本摘要、翻译、情感分析等。
我们最熟悉的大模型,莫过于CHATGPT。但我们最常用的大模型,未必是CHATGPT。
目前,相信所有的企业都有一个认知,在现在或者未来,我要在工作中使用AI,我的企业也要在运行中使用AI。
但是,由于每个人对大模型的认知程度不一,以上的“ 我要用AI!”其实就等于“我要进步”这种比较模糊的认知,真正到应用的时候,这种认知是不够的。
因此,我们有了下面这篇科普:
为什么GPT如此强大,我们还要用本地大模型?
这里的LLMs特指Llama2/3、Mistral、GLM3-6B等开源大模型
可用性
线上LLMs: 线上部署的LLMs提供即时访问和高可用性,基本实现7*24小时运作。一般好的模型服务商都直接提供API输出,他们赚的是token流量的钱。
本地LLMs: 本地部署的LLMs要求用户具备一定的技术知识,包括安装、配置和优化模型的能力。LLM的推理性能和速度直接受限于个人或组织的硬件配置,如处理器、内存和存储空间等。此外,虽然本地部署为用户提供了更大的控制空间,但用户可能需要自己进行额外的开发工作。
运行成本
本地模型部署,要保证速度,需要显卡和高速内存,一般而言,显卡是必须的**。
**
-
量化后的模型显存需求:即使是经过量化的模型(如ChatGLM2-6B INT4),也需要至少5GB以上的显存。
-
OLLAMA允许通过内存部署(代价是降低速度),不同规模模型的推荐配置:
-
对于70亿参数(7B)的模型,推荐至少配备16GB的系统内存(RAM)。
-
130亿参数(13B)的模型,则建议使用32GB的内存。
-
而对于700亿参数(70B)的模型,一般推荐使用64GB内存,尽管有报告称32GB内存也能运行,但可能会非常卡顿。
线上LLMs: 对个人用户来说,线上LLMs服务的按需计费模式提供了极大的灵活性和入门门槛较低的优势。个人用户可以根据自己的实际需求和使用频率选择合适的服务计划,避免了高昂的初始投资。目前,百万token的费用从十几块人民币到几百块人民币不等。
本地LLMs: 本地部署LLMs意味着需要一次性投资于高性能的计算硬件。尽管这可能增加一些用户的经济成本,但它提供了长期的成本效益,尤其是对于那些有持续高强度使用需求的用户。个人用户通过本地部署能够获得更大的控制权和自定义能力,这可能对于研究人员或开发者特别有价值。然而,需要注意的是,本地部署也意味着用户必须具备一定的技术能力来配置和维护系统。
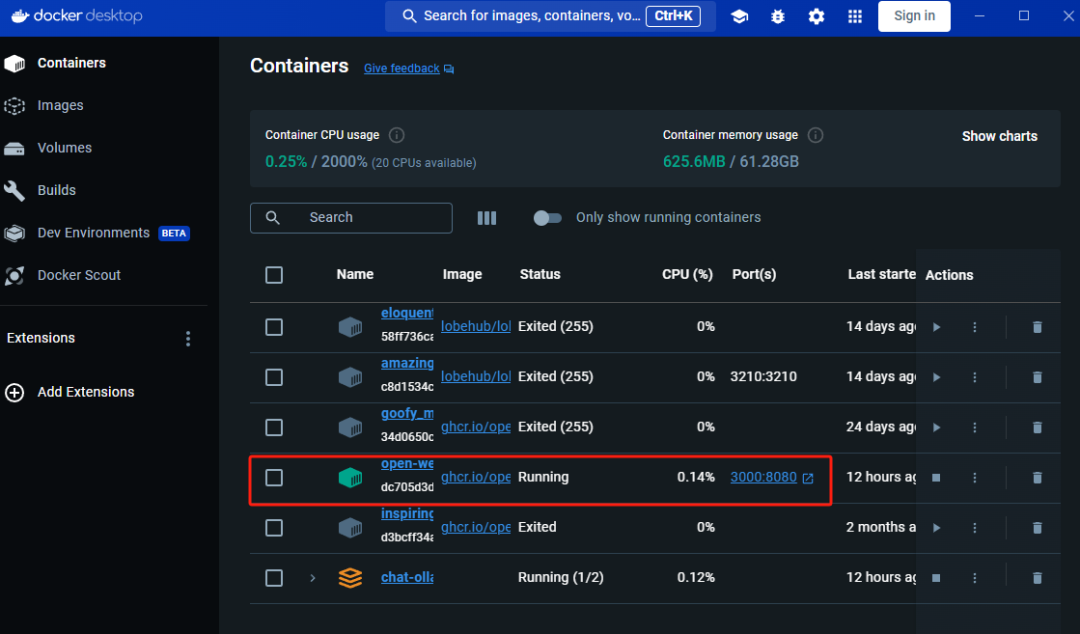
为了用好本地模型,我们一般采用docker部署各种不同的前端UI。
隐私性
线上LLMs: 当使用线上LLMs时,用户的数据需要传输到云服务器上进行处理,这引发了对数据隐私和安全的考量。虽然许多模型服务商承诺保护用户数据不被滥用或泄露,但这一过程仍然需要用户对提供商的数据处理和隐私政策有一定的信任基础。
本地LLMs: 相对于线上模型,本地部署的LLMs在隐私保护方面提供了更高级别的安全性,主要因为数据处理在用户的私有设备或内部服务器上完成,无需数据外传。这种部署方式让用户对数据的控制权大大增强,降低了数据泄露的风险。
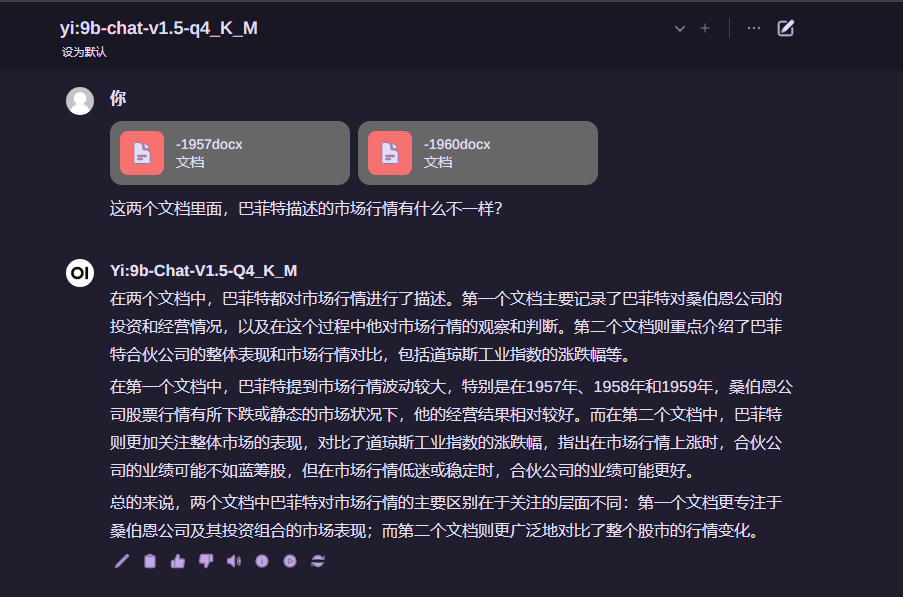
使用本地模型对比文档,无需担心文档泄露风险
依赖性和控制权
线上LLMs: 使用线上服务,用户依赖服务提供商确保服务的可用性和性能。这种模式简化了使用流程,允许用户专注于模型的应用而非其维护。然而,这也意味着在系统提示、上下文管理及模型响应定制方面,用户的直接控制能力有所限制。尽管线上服务提供一定程度的配置选项,但它们可能不足以满足所有特定需求,特别是在需要高度定制化输出的场景中。
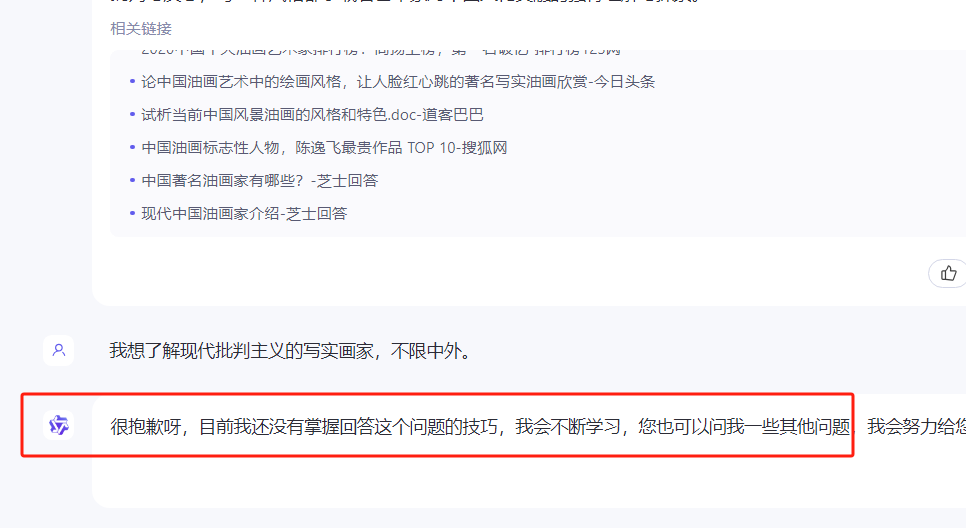
线上模型根据法规,有部分内容进行了屏蔽

不管是百度还是阿里还是字节,这种模型输出内容的限制都是存在的。
本地LLMs: 本地部署的模型让用户享有更高的控制权,包括对数据处理、模型配置和系统安全的管理。用户可以根据需要深度定制系统提示和上下文处理策略,这在特定应用场景下可能非常重要。然而,这种控制权和灵活性的增加伴随着更高的技术要求和可能的初期设置复杂性。尽管本地部署允许高度定制,但它也要求用户具备相应的技术能力来实现这些定制化的解决方案。

相比之下,本地模型如果用的好,基本上百无禁忌。
透明度
线上LLMs: 线上LLMs服务由第三方提供,可能会在模型的工作原理和数据处理方式上给某些用户带来透明度的担忧。服务提供商通常会努力提供模型训练、数据处理和隐私政策等方面的文档,旨在提高透明度。然而,由于商业保密和操作复杂性,用户可能无法获得模型内部机制的完全细节。这要求用户信任服务提供商,并依赖其提供的信息和控制措施来保障数据安全和隐私。
本地LLMs: 本地部署的LLMs允许用户直接访问模型,提供了更高程度的透明度。用户可以自行检查、修改和优化模型,从而深入理解其工作原理并根据需求调整其行为。这种直接控制确保了对模型的完全理解和定制能力,特别适合对数据安全、隐私保护有高要求或需遵循特定法规的组织。然而,这也意味着用户需要承担更大的责任,包括维护模型的透明度和确保其符合伦理和法律标准。
所以,你会选择本地大模型还是在线大模型呢?
既然大模型现在这么火热,各行各业都在开发搭建属于自己企业的私有化大模型,那么势必会需要大量大模型人才,同时也会带来大批量的岗位?“雷军曾说过:站在风口,猪都能飞起来”可以说大模型这对于我们来说就是一个机会,一个可以改变自身的机会,就看我们能不能抓住了。
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

